In der aufstrebenden Disziplin des Context Engineering ist es entscheidend, KI-Agenten zur richtigen Zeit mit den richtigen Informationen zu versorgen. Einer der wichtigsten Aspekte von Context Engineering ist die Verwaltung des Gedächtnisses der KI. Ähnlich wie Menschen sind KI-Systeme sowohl auf ein Kurzzeitgedächtnis als auch auf ein Langzeitgedächtnis angewiesen, um Informationen abzurufen. Wenn wir wollen, dass große Sprachmodellagenten (LLM) logische Gespräche führen, sich an Nutzerpräferenzen erinnern oder auf früheren Ergebnissen oder Reaktionen aufbauen, müssen wir sie mit effektiven Gedächtnismechanismen ausstatten.
Schließlich beeinflusst der gesamte Kontext die Reaktionen der KI. Was man hinein gibt, kommt auch wieder heraus trifft in diesem Fall zu.
In diesem Artikel stellen wir vor, was Kurzzeit- und Langzeitgedächtnis für KI-Agenten bedeuten, insbesondere:
- Der Unterschied zwischen Kurz- und Langzeitgedächtnis.
- Wie sie sich auf Retrieval-Augmented Generation (RAG) Techniken mit Vektordatenbanken wie Elasticsearch beziehen und warum ein sorgfältiges Gedächtnismanagement notwendig ist.
- Die Risiken der Vernachlässigung des Gedächtnisses, einschließlich Kontextüberlauf und Kontextvergiftung.
- Best Practices wie Kontextbereinigung, Zusammenfassung und Abruf nur relevanter Daten, damit das Gedächtnis eines Agenten sowohl nützlich als auch sicher bleibt.
- Abschließend werden wir darauf eingehen, wie das Gedächtnis in Systemen mit mehreren Agenten gemeinsam genutzt und weitergegeben werden kann, damit Agenten mithilfe von Elasticsearch problemlos zusammenarbeiten können.
Kurzzeit- versus Langzeitgedächtnis bei KI-Agenten
Das Kurzzeitgedächtnis eines KI-Agenten bezieht sich in der Regel auf den unmittelbaren Gesprächskontext oder -zustand – im Wesentlichen auf den aktuellen Chatverlauf oder die letzten Nachrichten in der aktiven Sitzung. Dies umfasst die letzte Anfrage des Nutzers und den jüngsten Nachrichtenaustausch. Es ähnelt den Informationen, die eine Person während eines Gesprächs im Kopf hat.
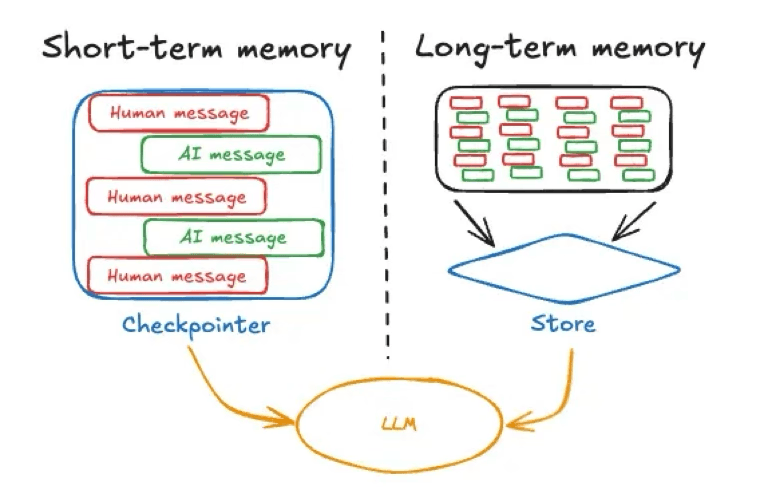
Bildquelle: https://langchain.ai.github.io/langgraphjs/concepts/memory
KI-Frameworks pflegen häufig dieses vorübergehende Gedächtnis als Teil des Agentenzustands (zum Beispiel durch die Verwendung eines Checkpointers, um den Konversationszustand zu speichern, wie in diesem Beispiel von LangGraph beschrieben). Das Kurzzeitgedächtnis ist sitzungsbezogen, das heißt, es existiert innerhalb einer einzelnen Diskussion oder Aufgabe und wird zurückgesetzt oder gelöscht, wenn diese Sitzung endet, es sei denn, sie wird explizit an anderer Stelle gespeichert. Ein Beispiel für ein sitzungsgebundenes Kurzzeitgedächtnis wäre der temporäre Chat, der in ChatGPT verfügbar ist.
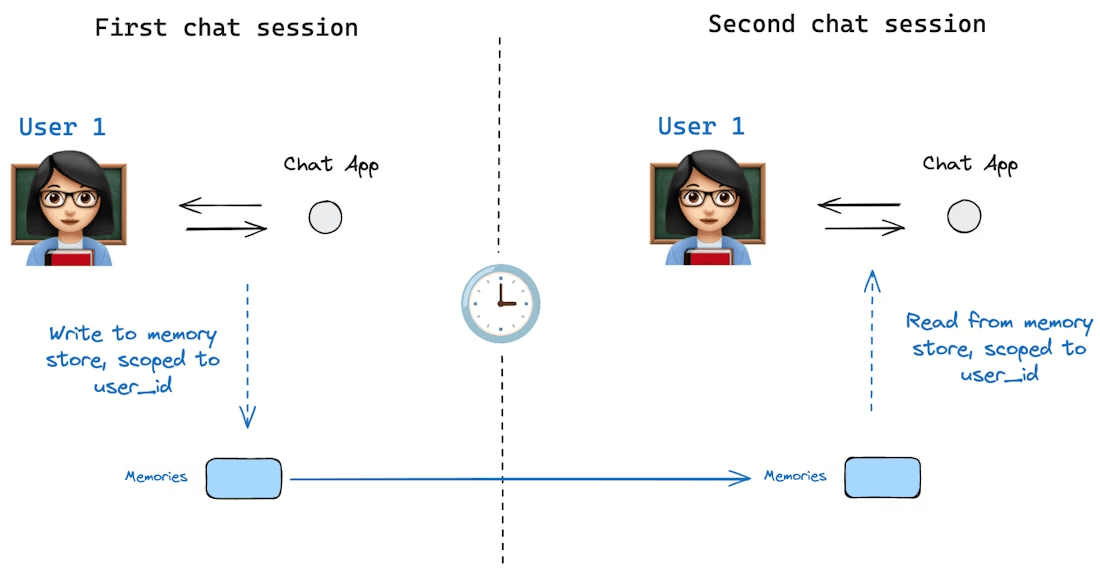
Bildquelle: https://docs.langchain.com/oss/python/langgraph/persistence#memory-store
Das Langzeitgedächtnis hingegen bezeichnet Informationen, die über Gespräche oder Sitzungen hinweg erhalten bleiben. Dies ist das Wissen, das ein Agent im Laufe der Zeit behält: Fakten, die er zuvor gelernt hat, Nutzerpräferenzen oder alle Daten, die wir ihm zum dauerhaften Speichern gegeben haben.
Das Langzeitgedächtnis wird in der Regel durch Speichern und Abrufen aus einer externen Quelle implementiert, z.B. einer Datei oder einer Vektordatenbank, die sich außerhalb des unmittelbaren Kontextfensters befindet. Im Gegensatz zum kurzfristigen Chatverlauf wird das Langzeitgedächtnis nicht automatisch in jeden Prompt einbezogen. Stattdessen muss der Agent es auf der Grundlage eines bestimmten Szenarios zurückrufen oder abrufen, wenn die entsprechenden Tools aufgerufen werden. In der Praxis könnte das Langzeitgedächtnis beispielsweise Nutzerprofilinformationen, frühere Antworten oder Analysen des Agenten oder eine Wissensdatenbank umfassen, die der Agent abfragen kann.
Nehmen Sie als Beispiel einen Reiseplaner-Agenten, bei dem das Kurzzeitgedächtnis Details der aktuellen Reiseanfrage (Daten, Ziel, Budget) und alle Folgefragen in diesem Chat enthält, während das Langzeitgedächtnis die allgemeinen Reisepräferenzen des Nutzers, vergangene Reisepläne und andere Fakten, die in vorherigen Sitzungen geteilt wurden, speichern könnte. Wenn der Nutzer später zurückkehrt, kann der Agent auf dieses Langzeitgedächtnis zurückgreifen (zum Beispiel, dass der Nutzer Strände und Berge liebt, über ein durchschnittliches Budget von 100.000 INR verfügt, eine Liste mit Zielen hat, die er besuchen möchte, und lieber Geschichte und Kultur als kinderfreundliche Attraktionen erleben möchte), sodass der Nutzer nicht jedes Mal als unbeschriebenes Blatt behandelt wird.
Das Kurzzeitgedächtnis (Chatverlauf) bietet unmittelbaren Kontext und Kontinuität, während das Langzeitgedächtnis einen umfassenderen Kontext bereitstellt, auf den der Agent bei Bedarf zurückgreifen kann. Die fortschrittlichsten KI-Agenten-Frameworks ermöglichen beides: Sie verfolgen aktuelle Dialoge, um den Kontext zu pflegen, und bieten Mechanismen, um Informationen in einem längerfristigen Repository nachzuschlagen oder zu speichern. Die Verwaltung des Kurzzeitgedächtnisses stellt sicher, dass es innerhalb des Kontextfensters bleibt, während die Verwaltung des Langzeitgedächtnisses dem Agenten hilft, die Antworten auf der Grundlage früherer Interaktionen und Personas zu fundieren.
Speicher und RAG im Kontext-Engineering
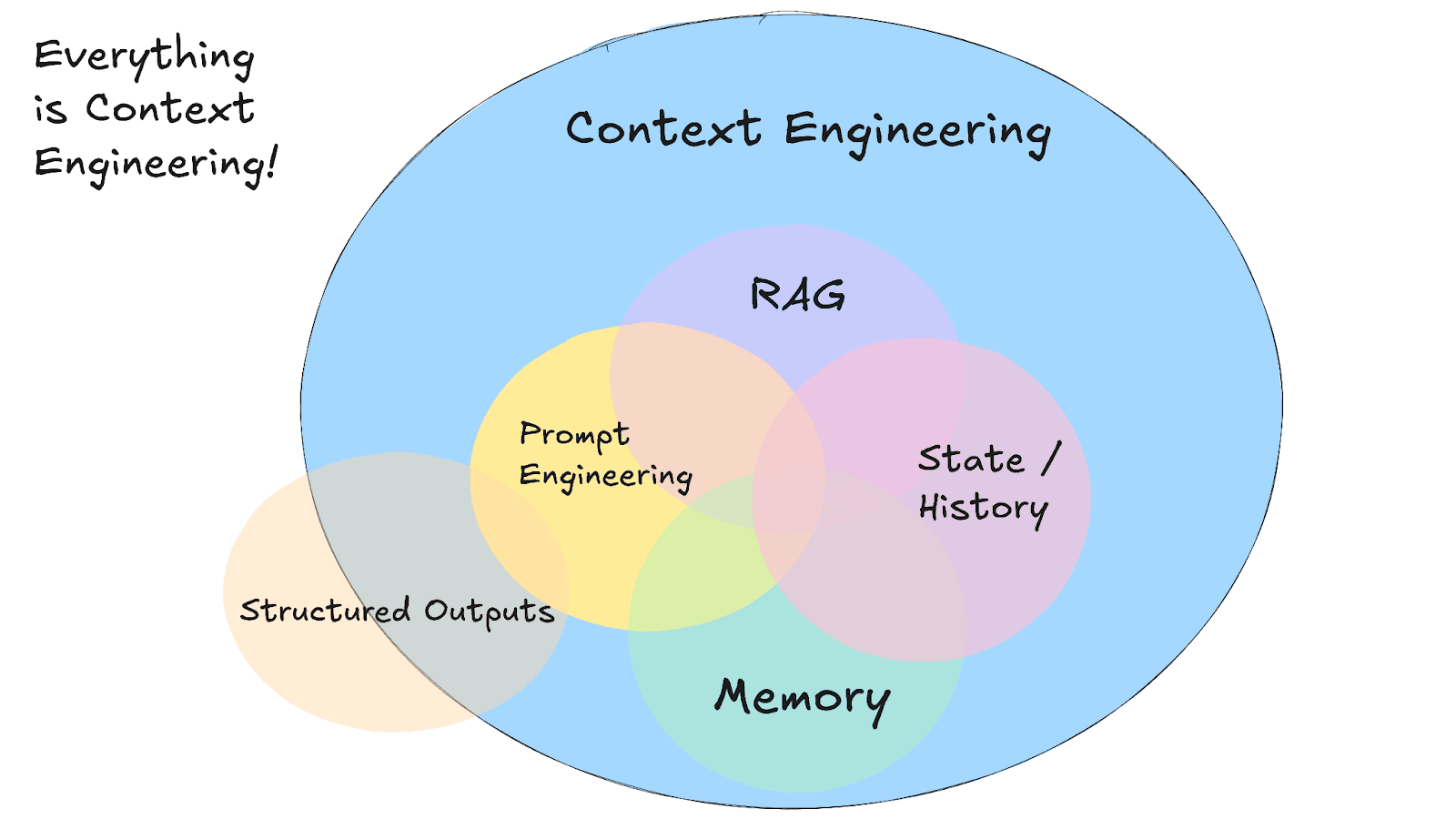
Bildquelle: https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-03-own-your-context-window.md
Wie geben wir einem KI-Agenten in der Praxis ein nützliches Langzeitgedächtnis?
Ein bedeutender Ansatz für das Langzeitgedächtnis ist das semantische Gedächtnis, das oft über Retrieval-Augmented Generation (RAG) implementiert wird. Dabei wird der LLM an einen externen Wissensspeicher oder einem vektorfähigen Datenspeicher wie Elasticsearch gekoppelt. Wenn das LLM Informationen benötigt, die über das hinausgehen, was im Prompt oder im integrierten Training enthalten ist, führt es eine semantische Suche in Elasticsearch durch und fügt die relevantesten Ergebnisse als Kontext in den Prompt ein. Auf diese Weise umfasst der effektive Kontext des Modells nicht nur das aktuelle Gespräch (Kurzzeitgedächtnis), sondern auch relevante, kurzfristig abgerufene Langzeitfakten. Das LLM stützt seine Reaktion dann sowohl auf eigene Schlussfolgerungen als auch auf die abgerufenen Informationen und kombiniert so effektiv Kurzzeitgedächtnis und Langzeitgedächtnis, um eine genauere, kontextbezogene Reaktion zu erzeugen.
Elasticsearch kann verwendet werden, um das Langzeitgedächtnis für KI-Agenten zu implementieren. Hier ist ein Beispiel dafür, wie der Kontext aus Elasticsearch für das Langzeitgedächtnis abgerufen werden kann.
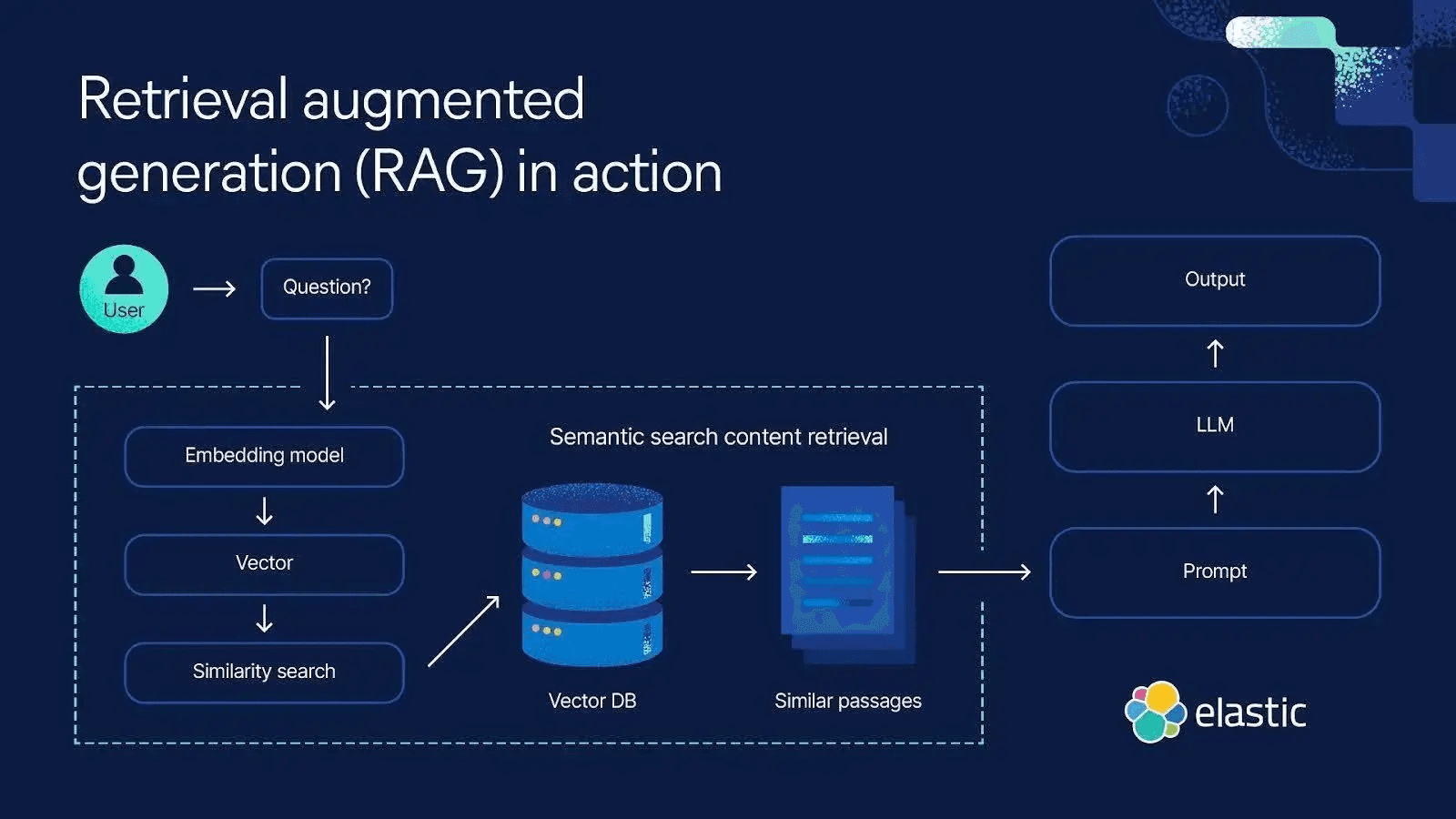
Auf diese Weise „erinnert“ sich der Agent, indem er nach relevanten Daten sucht, anstatt alles in seinem begrenzten Prompt zu speichern, wo es zu verschiedenen Risiken kommen kann.
Die Verwendung von RAG mit Elasticsearch oder einem beliebigen Vektorspeicher bietet mehrere Vorteile:
Erstens erweitert es das Wissen des Modells über seinen Trainingsschnitt hinaus. Der Agent kann aktuelle Informationen oder domänenspezifische Daten abrufen, die das LLM möglicherweise nicht kennt. Dies ist besonders bei Fragen zu aktuellen Ereignissen oder speziellen Themen der Fall.
Zweitens hilft das Abrufen von Kontext nach Bedarf, Halluzinationen zu reduzieren, besonders da LLMs nicht auf proprietären oder hochspezialisierten Daten im Zusammenhang mit Nischenanwendungsfällen trainiert sind, was sehr wahrscheinlich Halluzinationen zur Folge hat. Damit das LLM nicht rät oder neue Informationen erfindet, da es durch die Bewertung einen Anreiz erhalten hat, wie in dem kürzlich erschienenen OpenAI-Paper (Why Language Models Hallucinate) hervorgehoben wird, kann das Modell durch faktische Referenzen aus Elasticsearch geerdet werden. Natürlich hängt das LLM von der Zuverlässigkeit der Daten im Vektorspeicher ab, damit Fehlinformationen wirklich verhindert und die relevanten Daten gemäß den Kernrelevanzmaßen abgerufen werden.
Drittens ermöglicht RAG es Agenten, mit Wissensdatenbanken zu arbeiten, die weit größer sind als alles, was man jemals in einen Prompt einfügen könnte. Anstatt ganze Dokumente, wie lange Forschungsarbeiten oder politische Dokumente, in das Kontextfenster zu schieben und das Risiko einer Überlastung oder Kontextvergiftung durch irrelevante Informationen bei Schlussfolgerungen des Modells einzugehen, verlässt sich RAG auf Chunking. Große Dokumente werden in kleinere, semantisch bedeutungsvolle Teile zerlegt, und das System ruft nur die wenigen für die Anfrage relevantesten Abschnitte ab. Auf diese Weise benötigt das Modell keinen Kontext von einer Million Token, um kompetent zu wirken, sondern lediglich Zugriff auf die richtigen Teile eines viel größeren Korpus.
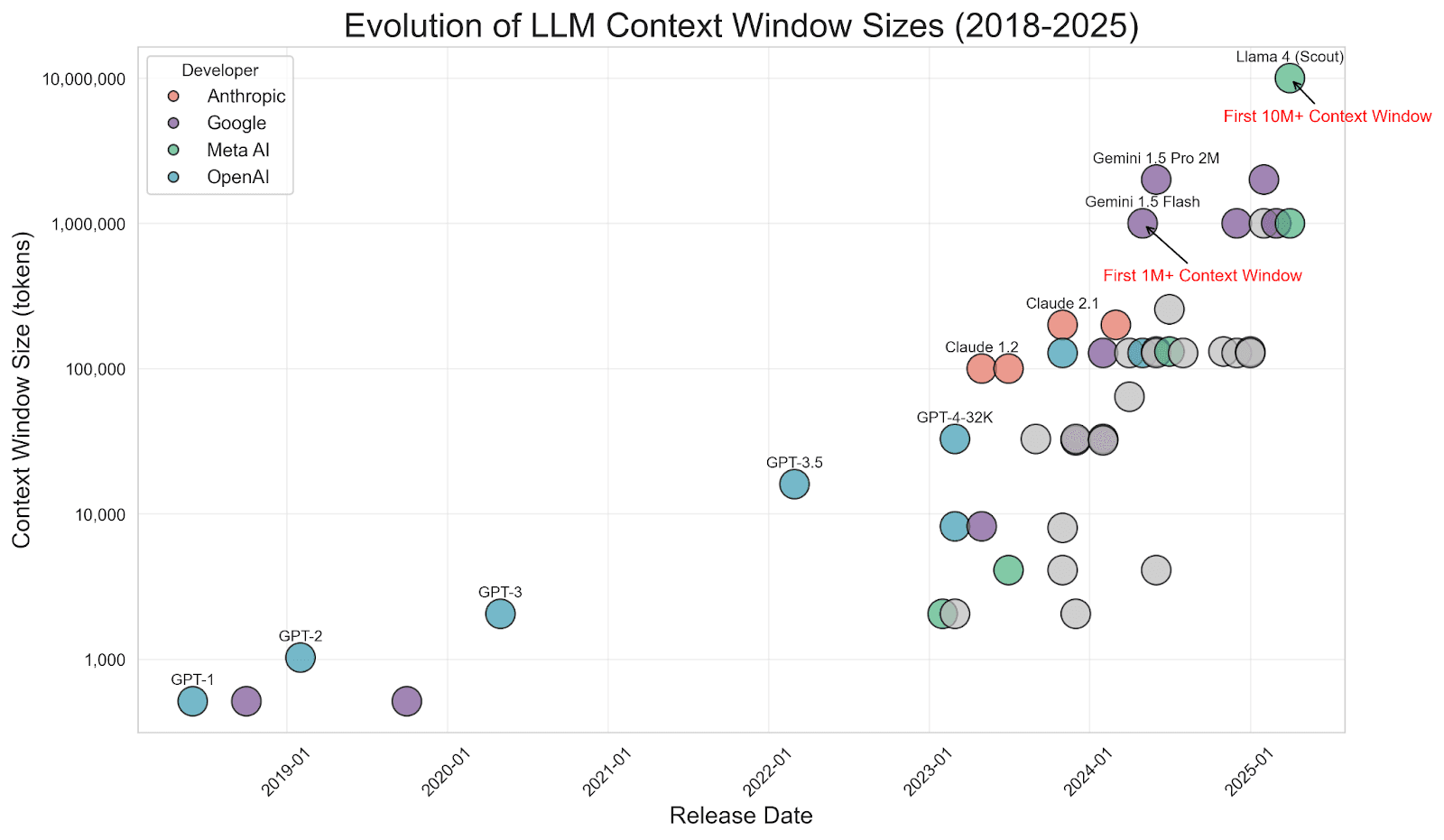
Es ist erwähnenswert, dass mit dem Wachstum der LLM-Fenster (einige Modelle unterstützen inzwischen Hunderttausende oder sogar Millionen von Token) eine Debatte darüber entstanden ist, ob RAG „tot“ ist. Warum nicht alle Daten in den Prompt einfügen? Wenn Sie das ähnlich sehen, lesen Sie diesen wunderbaren Artikel meiner Kollegen Jeffrey Rengifo und Eduard Martin: Longer context ≠ better: Why RAG still matters. Dies vermeidet das „Was man hinein gibt, kommt auch wieder heraus“-Problem: Das LLM bleibt auf die wenigen wichtigen Teile fokussiert, anstatt sich durch Rauschen zu arbeiten.
Nichtsdestotrotz bietet die Integration von Elasticsearch oder einem beliebigen Vektorspeicher in eine KI-Agentenarchitektur ein Langzeitgedächtnis. Der Agent speichert Wissen extern und ruft es bei Bedarf als Gedächtniskontext ab. Dies könnte als Architektur implementiert werden, bei der der Agent nach jeder Nutzeranfrage in Elasticsearch nach relevanten Informationen sucht und dann die Top-Ergebnisse an den Prompt anhängt, bevor er das LLM aufruft. Die Reaktion kann auch wieder in das Langzeitgedächtnis gespeichert werden, wenn sie nützliche neue Informationen enthält (wodurch ein Feedback-Loop des Learnings entsteht). Durch die Nutzung eines solchen abrufbasierten Gedächtnisses bleibt der Agent informiert und auf dem neuesten Stand, ohne alles, was er weiß, in jeden Prompt quetschen zu müssen, obwohl das Kontextfenster eine Million Token unterstützt. Diese Technik ist ein Eckpfeiler des Kontext-Engineerings und kombiniert die Stärken von Information Retrieval und generativer KI.
Hier ist ein Beispiel für einen verwalteten In-Memory-Gesprächszustand, der das Checkpoint-System von LangGraph für das Kurzzeitgedächtnis während der Sitzung verwendet. (Mehr dazu in unserer unterstützenden Context Engineering-App.)
So werden Checkpoints gespeichert:
Für das Langzeitgedächtnis führen wir mit Elasticsearch eine semantische Suche durch, um relevante vorherige Gespräche mithilfe von Vektoreinbettungen abzurufen, nachdem wir die Checkpoints in Elasticsearch zusammengefasst und indexiert haben.
Nachdem wir untersucht haben, wie Kurzzeit- und Langzeitgedächtnis mithilfe der Checkpoints von LangGraph in Elasticsearch indexiert und abgerufen werden, wollen wir uns etwas Zeit nehmen, um zu verstehen, warum das Indexieren und Speichern der kompletten Konversationen riskant sein kann.
Risiken der fehlenden Verwaltung des Kontextgedächtnisses
Da wir viel über Kontextgestaltung sowie Kurzzeit- und Langzeitgedächtnis sprechen, ist es wichtig, zu verstehen, was passiert, wenn wir Gedächtnis und Kontext eines Agenten nicht effektiv verwalten.
Leider kann vieles schiefgehen, wenn der Kontext einer KI extrem lang wird oder falsche Informationen enthält. Wenn die Kontextfenster größer werden, tauchen neue Fehlerarten auf, zum Beispiel:
- Kontextvergiftung
- Kontextablenkung
- Kontextverwirrung
- Kontextkonflikt
- Kontextlecks und Wissenskonflikte
- Halluzinationen und Fehlinformationen
Werfen wir einen Blick auf diese Probleme und andere Risiken, die durch schlechtes Kontextmanagement entstehen:
Kontextvergiftung
Kontextvergiftung bezieht sich darauf, wenn falsche oder schädliche Informationen in den Kontext gelangen und die nachfolgenden Ausgänge des Modells „vergiften“. Ein häufiges Beispiel ist eine Halluzination des Modells, die als Tatsache behandelt und in den Gesprächsverlauf eingefügt wird. Das Modell könnte dann in späteren Reaktionen auf diesem Fehler aufbauen und den Fehler verstärken. In iterativen Agenten-Loops kann eine falsche Information, sobald sie in den gemeinsamen Kontext gelangt (zum Beispiel in einer Zusammenfassung der Arbeitsnotizen des Agenten), immer wieder verstärkt werden.
Forscher von DeepMind haben dies bei der Veröffentlichung des Gemini 2.5-Berichts (TL;DR, mehr dazu hier) bei einem langjährig Pokémon-spielenden Agenten beobachtet: Wenn der Agent einen falschen Spielzustand halluzinierte und dieser in seinem Kontext (seinem Gedächtnis für Ziele) aufgezeichnet wurde, bildete der Agent unsinnige Strategien um ein unmögliches Ziel herum und blieb stecken. Mit anderen Worten: Ein vergiftetes Gedächtnis kann den Agenten auf unbestimmte Zeit auf den falschen Weg bringen.
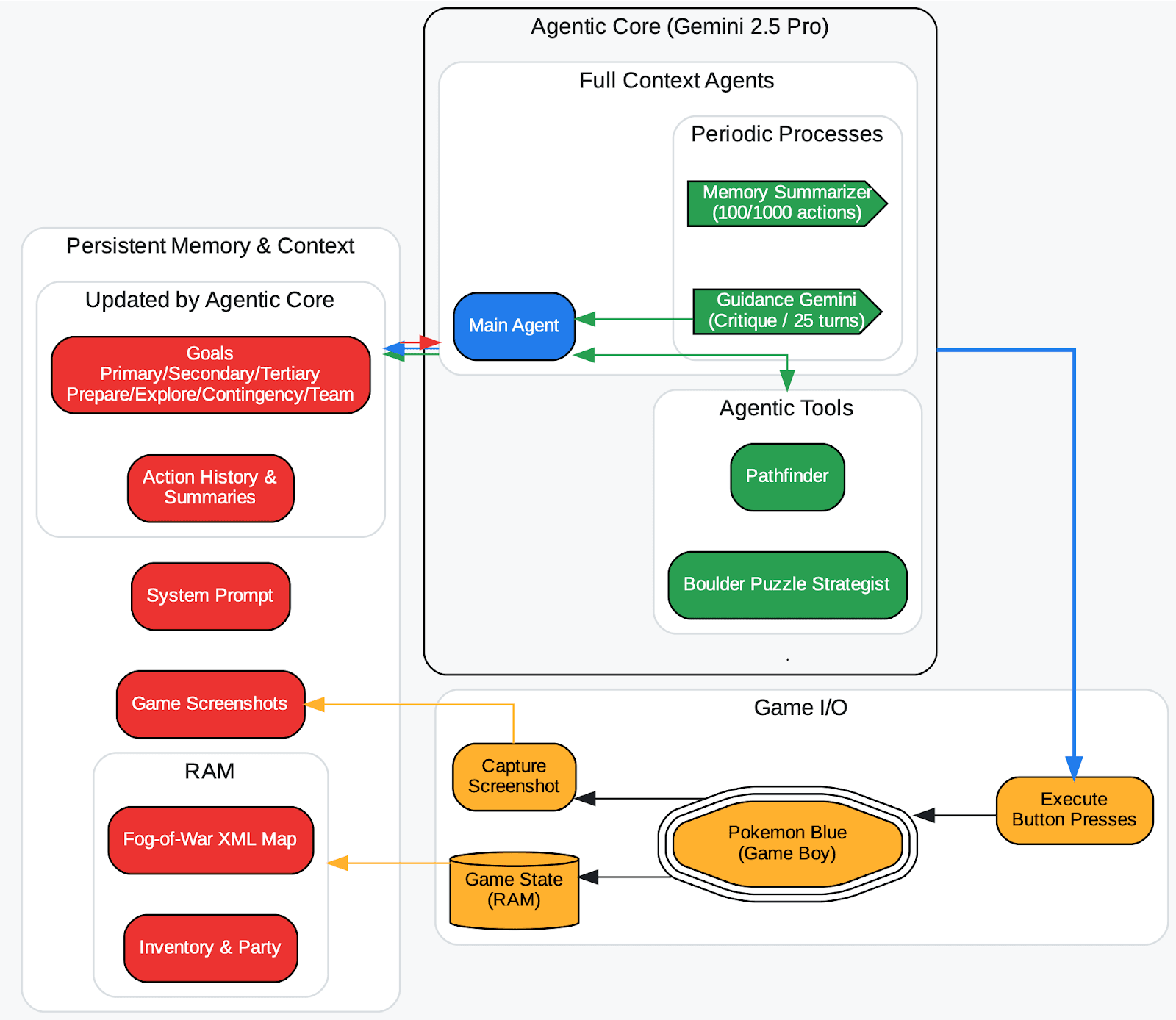
An overview of the agent harness (Zhang, 2025). Die Kriegsnebelkarte in der Oberwelt speichert automatisch ein Feld nach Erkundung und kennzeichnet es mit einem besuchten Zähler. Der Typ der Kachel wird aus dem RAM aufgezeichnet. Die agentischen Tools (pathfinder, boulder_puzzle_strategist) sind angeforderte Instanzen von Gemini 2.5 Pro. pathfinder wird für die Navigation verwendet und boulder_puzzle_strategist löst Felsrätsel im Victory Road Dungeon.
Bildquelle: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf – Seite 68.
Kontextvergiftung kann aus Versehen oder auch böswillig geschehen, zum Beispiel durch Prompt-Injection-Angriffe, bei denen ein Nutzer oder Dritter eine versteckte Anweisung oder falsche Tatsache einschleust, die der Agent dann erinnert und befolgt.
Empfohlene Gegenmaßnahmen:
Basierend auf Einblicken von Wiz, Zerlo und Anthropic konzentrieren sich Gegenmaßnahmen gegen Kontextvergiftung darauf, zu verhindern, dass falsche oder irreführende Informationen in den Prompt, das Kontextfenster oder die Abrufpipeline eines LLM gelangen. Wichtige Schritte umfassen:
- Überprüfen Sie den Kontext regelmäßig: Überwachen Sie die Konversation oder den abgerufenen Text auf alles Verdächtige oder Schädliche, nicht nur den anfänglichen Prompt.
- Verwenden Sie vertrauenswürdige Quellen: Bewerten oder kennzeichnen Sie Dokumente basierend auf ihrer Glaubwürdigkeit, damit das System zuverlässige Informationen bevorzugt und Daten mit niedriger Bewertung ignoriert.
- Achten Sie auf ungewöhnliche Daten: Verwenden Sie Tools, die ungewöhnliche, unpassende oder manipulierte Inhalte erkennen, und entfernen Sie diese, bevor das Modell sie verwendet.
- Filtern Sie Eingänge und Ausgänge: Integrieren Sie Schutzvorkehrungen, damit schädliche oder irreführende Texte nicht so leicht in das System gelangen oder vom Modell wiederholt werden können.
- Halten Sie das Modell mit sauberen Daten auf dem neuesten Stand: Aktualisieren Sie das System regelmäßig mit verifizierten Informationen, um etwaigen fehlerhaften Daten entgegenzuwirken, die durchgerutscht sind.
- Human-in-the-loop: Lassen Sie wichtige Ausgänge von Menschen überprüfen oder mit bekannten, vertrauenswürdigen Quellen vergleichen.
Auch einfache Nutzergewohnheiten helfen, wie das Zurücksetzen langer Chats, das Teilen nur relevanter Informationen, das Aufteilen komplexer Aufgaben in kleinere Schritte und die Pflege sauberer Notizen außerhalb des Modells.
In Kombination bilden diese Maßnahmen einen mehrschichtigen Schutz, der LLMs vor Kontextvergiftung schützt und die Genauigkeit und Vertrauenswürdigkeit der Ausgänge gewährleistet.
Ohne Gegenmaßnahmen, wie hier erwähnt, könnte sich ein Agent an Anweisungen erinnern, z. B. vorherige Richtlinien zu ignorieren oder unwichtige Fakten, die ein Angreifer eingefügt hat, was zu schädlichen Ausgängen führen könnte.
Kontextablenkung
Kontextablenkung liegt vor, wenn ein Kontext so lang wird, dass sich das Modell zu sehr auf den Kontext konzentriert und vernachlässigt, was es während des Trainings gelernt hat. In extremen Fällen ähnelt dies katastrophalem Vergessen. Das heißt, das Modell „vergisst“ effektiv sein zugrunde liegendes Wissen und konzentriert sich übermäßig auf die Informationen, die ihm präsentiert werden. Frühere Studien haben gezeigt, dass LLM oft den Fokus verlieren, wenn der Prompt extrem lang ist.
Der Gemini 2.5-Agent zum Beispiel unterstützte ein Million-Token-Fenster, aber sobald sein Kontext über einen bestimmten Punkt hinauswuchs (etwa 100.000 Token in einem Experiment), begann er, sich darauf zu fixieren, seine früheren Aktionen zu wiederholen , anstatt neue Lösungen zu finden. In gewisser Weise wurde der Agent zum Gefangenen seiner umfangreichen Geschichte. Er betrachtete kontinuierlich seinen langen Log früherer Aktionen (den Kontext) und ahmte diese nach, anstatt sein zugrunde liegendes Trainingswissen zu nutzen, um frische und neuartige Strategien zu entwickeln.

Bildquelle: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf – Seite 18.
Das ist kontraproduktiv. Wir wollen, dass das Modell den relevanten Kontext zur Unterstützung des Denkens nutzt, nicht aber seine Denkfähigkeit außer Kraft setzt. Bemerkenswerterweise zeigen selbst Modelle mit riesigen Fenstern diesen Kontextverfall: Ihre Leistung verschlechtert sich ungleichmäßig, wenn mehr Token hinzugefügt werden. Es scheint ein Aufmerksamkeitsbudget zu geben. Wie Menschen mit begrenztem Gedächtnis hat ein LLM begrenzte Kapazitäten, sich um Token zu kümmern, und wenn dieses Budget überlastet ist, sinken Präzision und Fokus.
Kontextablenkung verhindern Sie durch Chunking, die Entwicklung der richtigen Informationen, regelmäßige Kontextzusammenfassungen sowie Bewertungs- und Überwachungstechniken zur Messung der Genauigkeit der Reaktion mittels Scoring.
Diese Methoden halten das Modell sowohl im relevanten Kontext als auch in seinem zugrundeliegenden Training verankert, wodurch das Risiko von Ablenkungen reduziert und die Gesamtqualität des Schlussfolgerns verbessert wird.
Kontextverwirrung
Kontextverwirrung liegt vor, wenn überflüssiger Inhalt im Kontext vom Modell verwendet wird, um eine Reaktion von geringer Qualität zu generieren. Ein gutes Beispiel ist, einem Agenten eine große Auswahl an Tools oder API-Definitionen zu geben, die er verwenden könnte. Wenn viele dieser Tools nichts mit der aktuellen Aufgabe zu tun haben, kann das Modell dennoch versuchen, sie in unangemessener Weise zu verwenden, einfach weil sie im Kontext vorhanden sind. Experimente haben gezeigt, dass die Bereitstellung weiterer Tools oder Dokumente die Leistung beeinträchtigen kann, wenn sie nicht alle benötigt werden. Der Agent beginnt Fehler zu machen, z. B. die falsche Funktion aufzurufen oder auf irrelevanten Text zu verweisen.
In einem Fall scheiterte ein kleines Llama 3.1 8B Modell an einer Aufgabe, wenn es 46 Tools zu berücksichtigen hatte, war aber erfolgreich, wenn es nur 19 Tools gab. Die zusätzlichen Tools sorgten für Verwirrung, obwohl der Kontext innerhalb der Längenbeschränkungen lag. Das zugrunde liegende Problem ist, dass alle Informationen in der Aufforderung vom Modell bearbeitet werden. Wenn es nicht weiß, dass es etwas ignorieren soll, könnte genau dieser Punkt seinen Ausgang auf unerwünschte Weise beeinflussen. Irrelevante Teile können „einen Teil der Aufmerksamkeit des Modells stehlen“ und es in die Irre führen (zum Beispiel könnte ein irrelevantes Dokument den Agenten dazu veranlassen, eine andere Frage zu beantworten als die gestellte). Kontextverwirrung äußert sich oft darin, dass das Modell eine minderwertige Reaktion produziert, die einen nicht zusammenhängenden Kontext integriert. Mehr dazu in der Forschungsarbeit: Less is More: Optimizing Function Calling for LLM Execution on Edge Devices.
Es erinnert uns daran, dass mehr Kontext nicht immer besser ist, vor allem, wenn er nicht nach Relevanz kuratiert ist.
Kontextkonflikt
Kontextkonflikte treten auf, wenn Teile des Kontexts sich widersprechen, was interne Abweichungen verursacht, die die Argumentation des Modells entgleisen lassen. Ein Konflikt kann auftreten, wenn der Agent mehrere Informationen ansammelt, die miteinander im Konflikt stehen.
Stellen Sie sich zum Beispiel einen Agenten vor, der Daten aus zwei Quellen abruft: Laut der einen startet Flug A um 17 Uhr, laut der anderen startet Flug A um 18 Uhr. Wenn beide Fakten im Kontext vorkommen, hat das mangelhafte Modell keine Möglichkeit zu wissen, welche richtig ist. Es kann verwirrt werden oder eine falsche oder unähnliche Antwort liefern.
Kontextkonflikte treten auch häufig in Mehrrundengesprächen auf, bei denen die früheren Antworten des Modells noch im Kontext verweilen, zusammen mit später verfeinerten Informationen.

Bildquelle: LLMS gets lost in the mult-turn conversation (Seite 04)
Eine Studie von Microsoft und Salesforce zeigt, dass die Endgenauigkeit deutlich sinkt, wenn man eine komplexe Abfrage in mehrere Chatbot-Durchläufe aufteilt (wobei Details schrittweise hinzugefügt werden). Warum ist das so? Weil die frühen Durchläufe partielle oder inkorrekte Zwischenantworten des Modells enthalten und diese im Kontext verbleiben. Wenn das Modell später versucht, mit allen Informationen zu antworten, enthält sein Gedächtnis immer noch diese falschen Versuche, die mit den korrigierten Informationen kollidieren und es vom Kurs abbringen. Im Grunde genommen widerspricht sich der Kontext des Gesprächs selbst. Das Modell kann versehentlich einen veralteten Kontext (aus einem früheren Durchlauf) verwenden, der nach dem Hinzufügen neuer Informationen nicht mehr zutrifft.
In Agentensystemen sind Kontextkonflikte besonders gefährlich, weil ein Agent Ausgänge verschiedener Tools oder Unteragenten kombinieren kann. Wenn diese Ausgänge nicht übereinstimmen, ist der aggregierte Kontext unbeständig. Der Agent könnte dann stecken bleiben oder sinnlose Ergebnisse produzieren, wenn er versucht, die Widersprüche in Einklang zu bringen. Um Kontextkonflikte zu verhindern, muss sichergestellt werden, dass der Kontext aktuell und konstant ist, zum Beispiel dass alle veralteten Informationen gelöscht oder aktualisiert wurden und Quellen, die nicht auf Konstanz überprüft wurden, nicht miteinander kombiniert werden.
Kontextlecks und Wissenskonflikte
In Systemen, in denen mehrere Agenten oder Nutzer einen Speicher teilen, besteht das Risiko, dass Informationen auf andere Kontexte übergehen.
Wenn sich beispielsweise die Daten-Einbettungen zweier separater Nutzer in derselben Vektordatenbank ohne ordnungsgemäße Zugriffskontrolle befinden, könnte ein Agent, der die Anfrage von Nutzer A beantwortet, versehentlich einen Teil des Speichers von Nutzer B abrufen. Diese kontextübergreifenden Lecks können private Informationen offenlegen oder einfach für Verwirrung bei Reaktionen sorgen.
Laut den OWASP Top 10 für LLM-Anwendungen müssen Multi-Tenant-Vektordatenbanken gegen solche Lecks schützen:
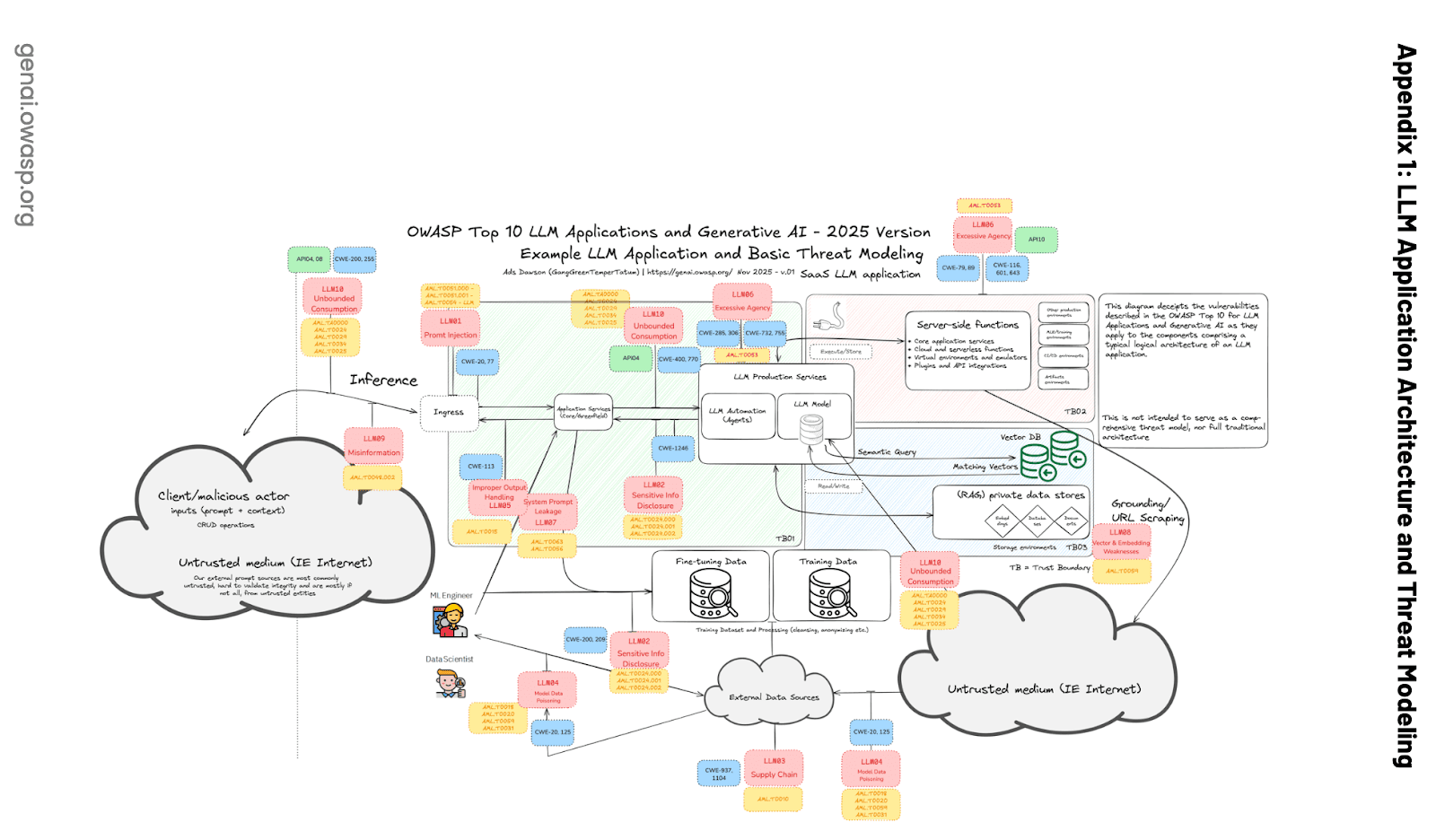
Laut LLM08:2025 Vector and Embedding Weaknesses, ist eines der häufigsten Risiken die Leckage von Kontextinformationen:
In Multi-Tenant-Umgebungen, in denen mehrere Klassen von Nutzern oder Anwendungen dieselbe Vektordatenbank nutzen, besteht die Gefahr von Kontextlecks zwischen Nutzern oder Abfragen. Fehler bei der Datenföderation können auftreten, wenn Daten aus mehreren Quellen einander widersprechen. Das kann auch passieren, wenn ein LLM altes Wissen, das es während des Trainings gelernt hat, nicht mit den neuen Daten aus Retrieval Augmentation ersetzen kann.
Ein weiterer Aspekt ist, dass ein LLM Schwierigkeiten haben könnte, sein integriertes Wissen mit neuen Informationen aus dem Gedächtnis zu überschreiben. Wenn das Modell auf eine bestimmte Tatsache trainiert wurde und der abgerufene Kontext das Gegenteil aussagt, kann das Modell verwirrt sein, welcher Aussage es vertrauen soll. Ohne eine geeignete Konzeption könnte der Agent Kontexte verwechseln oder altes Wissen nicht mit neuen Erkenntnissen aktualisieren, was zu veralteten oder falschen Antworten führen könnte.
Halluzinationen und Fehlinformationen
Die Halluzination (das LLM erfindet plausibel klingende, aber falsche Informationen) ist zwar auch ohne lange Kontexte ein bekanntes Problem, aber schlechtes Gedächtnismanagement kann es verstärken.
Wenn im Gedächtnis des Agenten eine entscheidende Tatsache fehlt, kann das Modell die Lücke einfach mit einer Vermutung füllen, und wenn diese Vermutung dann in den Kontext einfließt (ihn vergiftet), bleibt der Fehler bestehen.
Der OWASP LLM-Sicherheitsbericht (LLM09:2025 Misinformation) hebt Fehlinformationen als Kernschwachstelle hervor: LLMs können zuverlässige, aber erfundene Antworten liefern, und Nutzer könnten ihnen zu sehr vertrauen. Ein Agent mit einem schlechten oder veralteten Langzeitgedächtnis könnte getrost etwas zitieren, das im letzten Jahr gestimmt hat, jetzt aber falsch ist, es sei denn, sein Gedächtnis wird auf dem neuesten Stand gehalten.
Eine übermäßige Abhängigkeit vom Ausgang der KI (entweder durch den Nutzer oder den Agenten selbst in einer Schleife) kann dies verschlimmern. Wenn niemand die Informationen im Gedächtnis überprüft, kann der Agent Unwahrheiten ansammeln. Dies ist der Grund, warum RAG oft verwendet wird, um Halluzinationen zu reduzieren: Durch den Abruf einer maßgeblichen Quelle muss das Modell keine Fakten erfinden. Wenn Sie jedoch ein falsches Dokument abrufen (z. B. eines, das Fehlinformationen enthält) oder wenn eine frühe Halluzination nicht entfernt wird, kann das System diese Fehlinformation in seinen Aktionen weitergeben.
Fazit: Wird das Gedächtnis nicht verwaltet, kann dies zu falschen und irreführenden Ausgängen führen, was womöglich Schäden zur Folge hat, besonders wenn viel auf dem Spiel steht (z. B. schlechte Ratschläge in einem Finanz- oder medizinischen Bereich). Ein Agent benötigt Mechanismen, um seinen Speicherinhalt zu überprüfen oder zu korrigieren, anstatt bedingungslos allem zu vertrauen, was im Kontext steht.
Zusammengefasst ist es kein Erfolgsrezept, einem KI-Agenten ein unendlich langes Gedächtnis zu geben oder alles Mögliche in seinen Kontext zu werfen.
Best Practices für das Gedächtnismanagement in LLM-Anwendungen
Um die oben genannten Fallstricke zu vermeiden, haben Entwickler und Forscher eine Reihe von Best Practices für die Verwaltung von Kontext und Gedächtnis in KI-Systemen entwickelt. Diese Praktiken zielen darauf ab, den Arbeitskontext der KI übersichtlich, relevant und auf dem neuesten Stand zu halten - hier sind einige der wichtigsten Strategien und Beispiele dafür, wie sie helfen können.
RAG: Gezielten Kontext verwenden
Ein Großteil der RAG wurde bereits im vorangegangenen Abschnitt behandelt, so dass dieser Abschnitt eine kurze Zusammenfassung praktischer Hinweise bietet:
- Verwenden Sie gezieltes Abrufen, nicht Bulk-Loading: Rufen Sie nur die relevantesten Teile ab, anstatt ganze Dokumente oder vollständige Konversationsverläufe in den Prompt zu laden.
- Behandeln Sie RAG wie einen bedarfsgerechten Gedächtnisabruf: Rufen Sie den Kontext nur dann ab, wenn er benötigt wird, anstatt bei jedem Abruf alles zu verwenden.
- Bevorzugen Sie relevanzbasierte Abrufstrategien: Ansätze wie Top-k semantische Suche, Reciprocal Rank Fusion oder Tool-Loadout-Filterung helfen, Rauschen zu reduzieren und die Verankerung zu verbessern.
- Größere Kontextfenster beseitigen nicht die Notwendigkeit von RAG: Zwei hochrelevante Absätze sind fast immer effektiver als 20 lose zusammenhängende Seiten.
Allerdings geht es bei RAG nicht darum, mehr Kontext, sondern den richtigen Kontext hinzuzufügen.
Tool-Loadout
Tool-Loadout bedeutet, einem Modell nur die Tools zu geben, die es tatsächlich für eine Aufgabe benötigt. Der Begriff stammt aus dem Gaming-Bereich: Sie wählen ein Loadout, das zur Situation passt. Zu viele Tools verlangsamen den Fortschritt, die falschen führen zum Scheitern. LLM verhalten sich genauso, wie das Forschungspaper Less is more besagt. Sobald Sie ~30 Tools durchgegeben haben, überschneiden sich die Beschreibungen und das Modell ist verwirrt. Nach etwa 100 Tools ist ein Ausfall nahezu garantiert. Das ist kein Problem mit dem Kontextfenster, sondern eine Kontextverwirrung.
Eine einfache und effektive Lösung ist RAG-MCP. Anstatt jedes Tool in den Prompt zu laden, werden die Tool-Beschreibungen in einer Vektordatenbank gespeichert und nur die relevantesten werden pro Anfrage abgerufen. In der Praxis hält das den Loadout klein und konzentriert, die Prompts werden drastisch verkürzt und die Genauigkeit der Tool-Auswahl kann um das bis zu Dreifache verbessert werden.
Kleinere Modelle stoßen noch früher an diese Grenze. Die Forschung zeigt, dass ein 8B-Modell mit Dutzenden von Tools versagt, jedoch Erfolg zeigt, sobald das Loadout reduziert wird. Durch die dynamische Auswahl von Tools, in Fällen zunächst mit einem LLM, und die Überlegung, was benötigt wird, kann die Leistung um 44 % gesteigert werden, während gleichzeitig Stromverbrauch und Latenz reduziert werden. Daraus ist zu erkennen, dass die meisten Agenten nur wenige Tools benötigen, mit dem Wachstum Ihres Systems jedoch Tool-Loadout und RAG-MCP zu erstrangigen Designentscheidungen werden.
Kontextbereinigung: Begrenzung der Länge des Chatverlaufs
Wenn sich ein Gespräch über mehrere Ausführungen erstreckt, kann der angesammelte Chatverlauf zu viel Platz einnehmen, was zu einem Kontextüberlauf führt oder das Modell zu sehr abgelenkt wird.
Trimming bedeutet, programmatisch weniger wichtige Teile des Dialogs zu entfernen oder zu kürzen, während er wächst. Eine einfache Form besteht darin, die ältesten Runden der Konversation abzubrechen, wenn ein bestimmtes Limit erreicht ist, sodass nur die letzten N Nachrichten gespeichert werden. Eine ausgefeiltere Bereinigung könnte irrelevante Abschweifungen oder frühere Anweisungen entfernen, die nicht mehr benötigt werden. Das Ziel ist es, dass das Kontextfenster übersichtlich bleibt, ohne alte Nachrichten.
Wenn der Agent beispielsweise vor 10 Ausführungen ein Teilproblem gelöst hat und seitdem fortgefahren wurde, könnten wir diesen Teil des Verlaufs aus dem Kontext löschen (vorausgesetzt, er wird nicht mehr benötigt). Viele Chat-basierte Implementierungen bieten ein fortlaufendes Fenster mit den neuesten Nachrichten.
Beim Trimming handelt es sich im Grunde um das „Vergessen“ der ersten Teile eines Gesprächs, sobald diese zusammengefasst wurden oder als irrelevant erachtet werden. Dadurch verringern wir das Risiko von Kontextüberlauffehlern und reduzieren auch die Kontextablenkung, sodass das Modell nicht von alten oder themenfremden Inhalten gestört und abgelenkt wird. Dieser Ansatz ähnelt sehr der Art und Weise, wie Menschen sich vielleicht nicht an jedes Wort aus einem einstündigen Vortrag erinnern, aber die Höhepunkte im Gedächtnis behalten.
Falls Sie die Kontextbereinigung noch nicht ganz verstanden haben, kann, wie der Autor Drew Breunig hier hervorhebt, die Verwendung des Provence-Modells (naver/provence-reranker-debertav3-v1), ein leichter (1,75 GB), effizienter und genauer Kontext-Pruners für die Beantwortung von Fragen gut geeignet sein. Er kann große Dokumente auf nur den relevantesten Text für eine bestimmte Abfrage reduzieren. Sie können ihn in bestimmten Abständen aufrufen.
So rufen wir das Provence-Reranker-Modell in unserem Code auf, um den Kontext zu bereinigen:
Wir verwenden das Provence-Reranker-Modell (naver/provence-reranker-debertav3-v1), um die Satzrelevanz zu bewerten. Durch eine schwellenwertbasierte Filterung werden Sätze oberhalb der Relevanzschwelle beibehalten. Außerdem führen wir einen Fallback-Mechanismus ein, bei dem wir zum ursprünglichen Kontext zurückkehren, wenn die Bereinigung fehlschlägt. Zu guter Letzt verfolgt das Statistik-Logging den Reduktionsanteil im ausführlichen Modus.
Kontextzusammenfassung: Fassen Sie ältere Informationen zusammen, anstatt sie ganz wegzulassen
Die Zusammenfassung ist eine Ergänzung zum Trimming. Wenn der Verlauf oder die Wissensdatenbank zu umfangreich wird, können Sie das LLM einsetzen, um eine kurze Zusammenfassung der wichtigen Punkte zu erstellen und diese anstelle des vollständigen Inhalts verwenden, so wie in unserem obigen Code geschehen.
Wenn zum Beispiel ein KI-Assistent ein Gespräch mit 50 Runden geführt hat, könnte das System, anstatt alle 50 Runden an das Modell in Runde 51 zu senden (was wahrscheinlich nicht passt), die Runden 1–40 übernehmen, das Modell diese in einem Absatz zusammenfassen lassen und dann nur diese Zusammenfassung plus die letzten 10 Runden im nächsten Prompt bereitstellen. Auf diese Weise weiß das Modell immer noch, was besprochen wurde, ohne jedes Detail zu benötigen. Frühe Chatbot-Nutzer taten dies manuell, indem sie fragten: „Können Sie zusammenfassen, worüber wir bisher gesprochen haben?“ und dann in einer neuen Sitzung mit der Zusammenfassung fortfuhren. Nun kann dies automatisiert werden. Zusammenfassungen sparen nicht nur Platz im Kontextfenster, sondern können auch Kontextverwirrung und -ablenkung verringern, indem zusätzliche Details entfernt und nur die wichtigsten Fakten erhalten bleiben.
Hier ist unsere Vorgehensweise: Wir nutzen OpenAI-Modelle (Sie können beliebige LLMs verwenden), um den Kontext zu verdichten und gleichzeitig alle relevanten Informationen zu bewahren, wodurch Redundanz und Duplikate vermieden werden.
Wenn der Kontext zusammengefasst wird, ist es weniger wahrscheinlich, dass das Modell von unwichtigen Details oder vergangenen Fehlern überwältigt wird (vorausgesetzt, die Zusammenfassung ist korrekt).
Die Zusammenfassung muss jedoch sorgfältig erfolgen. Eine schlechte Zusammenfassung könnte ein entscheidendes Detail auslassen oder sogar zu einem Fehler führen. Es ist im Grunde eine weitere Aufforderung an das Modell („fassen Sie das zusammen“), sodass es zu Halluzinationen oder Nuancierungen kommen kann. Es empfiehlt sich, bei der Zusammenfassung schrittweise vorzugehen und möglicherweise autorisierte Fakten nicht in die Zusammenfassung einzubinden.
Dennoch hat sich dies als sehr nützlich erwiesen. Im Gemini-Agenten-Szenario war die Zusammenfassung des Kontexts alle ~100.000 Token eine Möglichkeit, der Wiederholungstendenz des Modells entgegenzuwirken. Die Zusammenfassung wirkt wie ein komprimierter Speicher des Gesprächs oder der Daten. Als Entwickler können wir dies umsetzen, indem ein Agent periodisch eine Zusammenfassungsfunktion (vielleicht ein kleineres LLM oder eine eigene Routine) aus dem Gesprächsverlauf oder einem langen Dokument aufruft. Die resultierende Zusammenfassung ersetzt den Originalinhalt im Prompt. Diese Taktik wird häufig verwendet, um Kontexte in Grenzen zu halten und die Informationen zusammenzufassen.
Kontextquarantäne: Kontexte nach Möglichkeit isolieren
Dies ist insbesondere bei komplexen Agentensystemen oder mehrstufigen Workflows relevant. Die Idee der Kontextsegmentierung besteht darin, eine große Aufgabe in kleinere, isolierte Aufgaben aufzuteilen, von denen jede ihren eigenen Kontext hat, um nicht zu viel Kontext mit umfassendem Inhalt anzuhäufen. Jeder Unteragent oder jede Teilaufgabe bearbeitet einen Bereich des Problems in einem fokussierten Kontext, anschließend integriert ein übergeordneter Agent, Supervisor oder Koordinator die Ergebnisse.
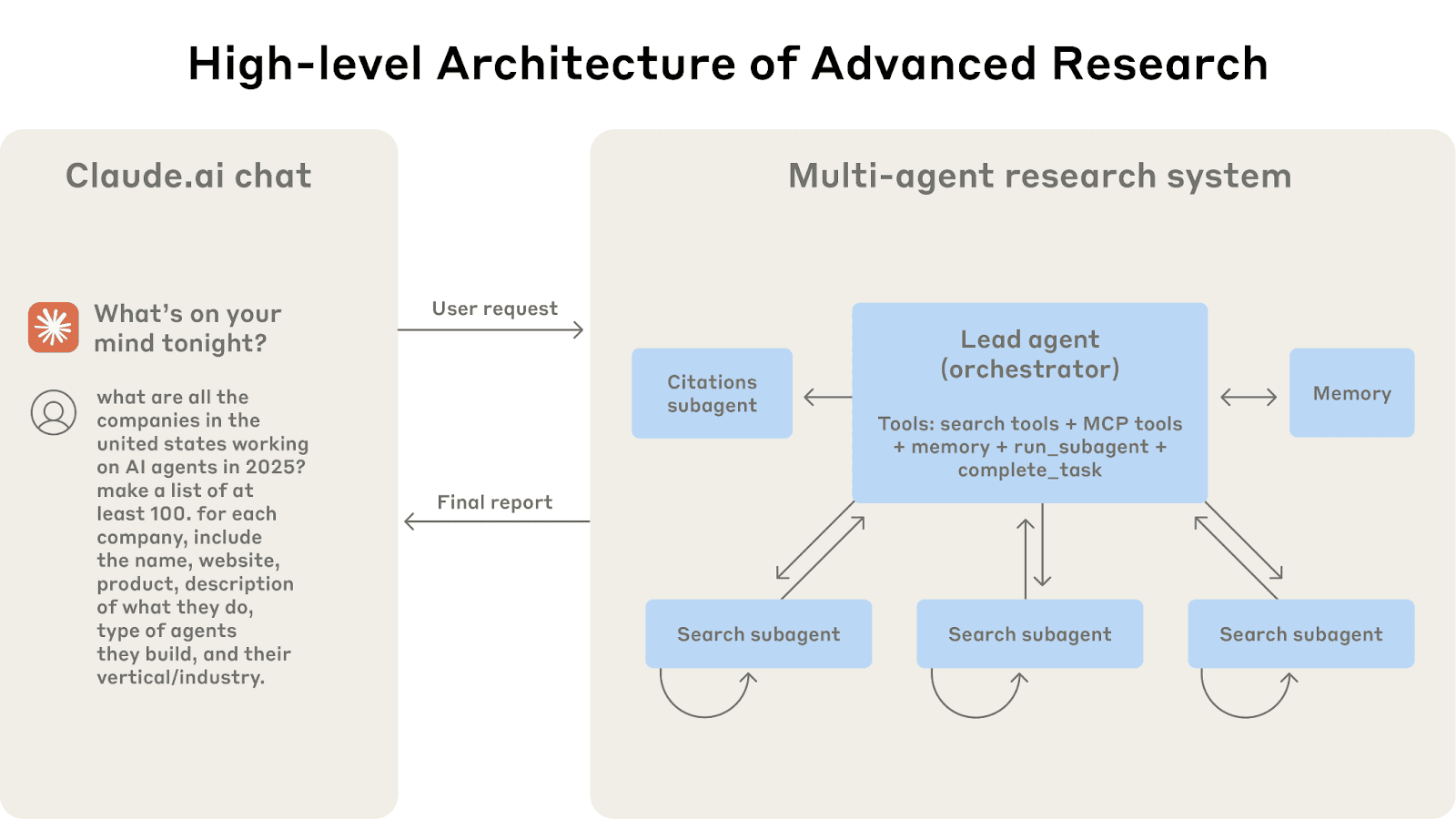
Die Multi-Agent-Architektur in Aktion: Nutzeranfragen werden über einen Hauptagenten geleitet, der spezialisierte Unteragenten erstellt, um parallel nach verschiedenen Aspekten zu suchen.
Bildquelle: https://www.anthropic.com/engineering/multi-agent-research-system
Die Forschungsstrategie von Anthropic verwendet mehrere Unteragenten, die jeweils einen anderen Aspekt einer Frage mit eigenen Kontextfenstern untersuchen, und einen Leitagenten, der die zusammengefassten Ergebnisse dieser Unteragenten ausliest. Dieser parallele, modulare Ansatz bedeutet, dass kein einzelnes Kontextfenster zu groß wird. Es reduziert auch die Wahrscheinlichkeit, dass irrelevante Informationen sich vermischen, jeder Thread bleibt beim Thema (keine Kontextverwirrung) und trägt keine unnötige Last, wenn er seine spezifische Teilfrage beantwortet. In gewisser Weise ist es, als würde man separate Gedankenstränge ausführen, die nur ihre Ergebnisse teilen, nicht ihren gesamten Denkprozess.
In Systemen mit mehreren Agenten ist dieser Ansatz unerlässlich. Wenn Agent A Aufgabe A und Agent B Aufgabe B bearbeitet, besteht für keinen Agenten der Grund, den vollständigen Kontext des anderen zu verwenden, es sei denn, dies ist unbedingt erforderlich. Stattdessen können Agenten nur die notwendigen Informationen austauschen. Zum Beispiel kann Agent A eine konsolidierte Zusammenfassung seiner Ergebnisse an Agent B über einen Supervisor-Agenten weitergeben, während jeder Unteragent seinen ganz eigenen Kontext-Thread pflegt. Bei diesem System ist kein menschliches Eingreifen erforderlich. Es basiert auf einem Überwachungsagenten mit aktivierten Tools, die einen minimalen und kontrollierten Kontextaustausch ermöglichen.
Dennoch kann die Gestaltung Ihres Systems, sodass Agenten oder Tools mit minimaler notwendiger Kontextüberschneidung arbeiten, die Klarheit und Leistung erheblich verbessern. Das kann man sich wie einen Microservices für KI vorstellen. Jede Komponente befasst sich mit ihrem Kontext, und Sie leiten Nachrichten zwischen ihnen auf kontrollierte Weise weiter, anstatt in einem monolithischen Kontext. Diese Best Practices werden oft in Kombination miteinander verwendet. Außerdem verleiht es Ihnen die Flexibilität, überflüssige Verläufe zu kürzen, wichtige ältere Nachrichten oder Unterhaltungen zusammenzufassen, detaillierte Protokolle für langfristigen Kontext an Elasticsearch zu übergeben und bei Bedarf mit Abruf alles Relevante zurückzuholen.
Wie hier erwähnt, ist das Leitprinzip, dass der Kontext eine begrenzte und wertvolle Ressource ist. Jeder Token im Prompt sollte sein Geld wert sein, d.h. er sollte zur Qualität des Ausgangs beitragen. Wenn etwas im Gedächtnis seine Funktion nicht erfüllt (oder schlimmer noch, aktiv Verwirrung stiftet), dann sollte es bereinigt, zusammengefasst oder beseitigt werden.
Als Entwickler können wir nun den Kontext genauso programmieren wie den Code und entscheiden, welche Informationen einbezogen, wie sie formatiert und wann sie weggelassen oder aktualisiert werden sollen. Mithilfe dieser Methoden können wir die LLM-Agenten mit dem dringend benötigten Kontext versorgen, um Aufgaben auszuführen, ohne den zuvor beschriebenen Fehlermodi zum Opfer zu fallen. Daraus resultieren Agenten, die sich an nötige Aufgaben erinnern, unnötige Aufgaben vergessen und alles Nötige gerade rechtzeitig abrufen.
Fazit
Erinnerungsvermögen wird Agenten nicht einfach hinzufügt, es muss entwickelt werden. Das Kurzzeitgedächtnis ist der Notizblock für die Arbeit des Agenten, das Langzeitgedächtnis sein dauerhafter Wissensspeicher. RAG dient als Verbindung zwischen den beiden und verwandelt einen passiven Datenspeicher wie Elasticsearch in einen aktiven Abrufmechanismus, der Ausgänge erden und den Agenten auf dem neuesten Stand halten kann.
Erinnerungsvermögen ist jedoch ein zweischneidiges Schwert. Sobald man zulässt, dass der Kontext unkontrolliert wächst, ist mit Vergiftung, Ablenkung, Verwirrung und Konflikten zu rechnen, in gemeinsam genutzten Systemen sogar mit Datenlecks. Deshalb ist die wichtigste Aufgabe hierbei nicht „mehr speichern“, sondern „besser kuratieren“: Selektiv abrufen, aktiv bereinigen, sorgfältig zusammenfassen und das Kombinieren unzusammenhängender Kontexte vermeiden, es sei denn, die Aufgabe erfordert dies wirklich.
In der Praxis ähnelt gutes Kontext-Engineering einem guten Systemdesign: kleinere, ausreichende Kontexte, kontrollierte Schnittstellen zwischen Komponenten und eine klare Trennung zwischen dem Rohzustand und dem destillierten Zustand, den das Modell tatsächlich sehen soll. Wenn man es richtig macht, führt dies nicht zu einem Agenten, der sich an alles erinnert, sondern zu einem Agenten, der sich zum richtigen Zeitpunkt und aus dem richtigen Grund an die richtigen Dinge erinnert.
Zugehörige Inhalte

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.
17. März 2026
Die Gemini CLI-Erweiterung für Elasticsearch mit Tools und Fähigkeiten
Wir stellen die Erweiterung von Elastic für Googles Gemini CLI vor, mit der Elasticsearch-Daten in Entwickler- und agentischen Workflows gesucht, abgerufen und analysiert werden können.