Dans la discipline émergente de l'ingénierie contextuelle, il est crucial de fournir aux agents d'IA les bonnes informations au bon moment. L'un des aspects les plus importants de l'ingénierie contextuelle est la gestion de la mémoire d'une IA. Tout comme les humains, les systèmes d'IA s'appuient à la fois sur une mémoire à court terme et sur une mémoire à long terme pour se souvenir des informations. Si nous voulons que les agents à grand modèle de langage (LLM) poursuivent des conversations logiques, se souviennent des préférences des utilisateurs ou s'appuient sur des résultats ou des réponses antérieurs, nous devons les doter de mécanismes de mémoire efficaces.
Après tout, tout ce qui figure dans le contexte influence les réponses de l’IA. Le principe de l'entrée et de la sortie des déchets est vrai.
Dans cet article, nous allons présenter ce que signifie la mémoire à court et à long terme pour les agents IA, en particulier :
- La différence entre la mémoire à court terme et la mémoire à long terme.
- Comment elles se rapportent aux techniques de génération augmentée de récupération (RAG) avec des bases vectorielles, comme Elasticsearch, et pourquoi une gestion attentive de la mémoire est nécessaire.
- Les risques liés à la négligence de la mémoire, y compris le débordement de contexte et l'empoisonnement contextuel.
- Les bonnes pratiques, telles que l'élagage du contexte, la synthèse et la récupération uniquement des informations pertinentes, permettent de maintenir la mémoire de l'agent à la fois utile et sécurisée.
- Enfin, nous examinerons comment la mémoire peut être partagée et propagée dans les systèmes multi-agents pour permettre une collaboration sans confusion grâce à Elasticsearch.
Mémoire à court terme versus mémoire à long terme dans les agents d’IA
La mémoire à court terme dans un agent IA fait généralement référence au contexte ou à l’état immédiat de la conversation — essentiellement, l’historique de discussion actuel ou les messages récents dans la session active. Cela inclut la dernière requête de l’utilisateur et les échanges récents d’allers-retours. C’est très similaire aux informations qu’une personne garde en tête lors d’une conversation en cours.
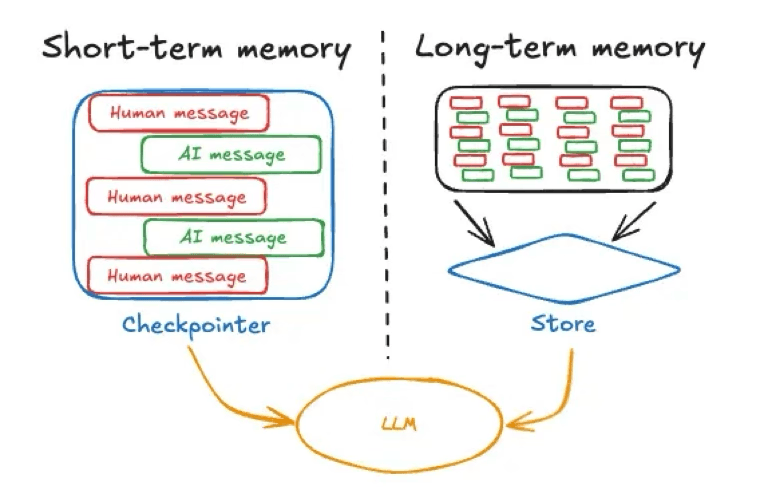
Source de l'image : https://langchain.ai.github.io/langgraphjs/concepts/memory
Les frameworks d'IA maintiennent souvent cette mémoire transitoire dans l'état de l'agent (par exemple, en utilisant un pointeur de contrôle pour stocker l'état de la conversation, comme le montre cet exemple de LangGraph). La mémoire à court terme est limitée à une session, c'est-à-dire qu'elle existe dans le cadre d'une conversation ou d'une tâche unique et qu'elle est réinitialisée ou effacée à la fin de cette session, à moins qu'elle ne soit explicitement sauvegardée ailleurs. Un exemple de mémoire à court terme liée à une session serait le chat temporaire disponible dans ChatGPT.
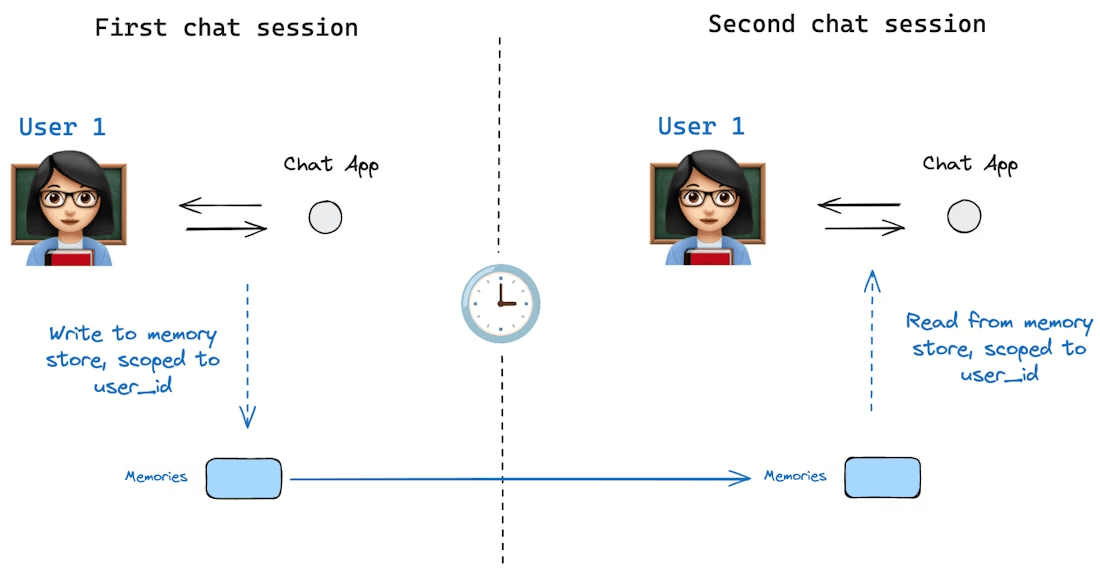
Source de l’image : https://docs.langchain.com/oss/python/langgraph/persistence#memory-store
La mémoire à long terme, en revanche, désigne les informations qui persistent au fil des conversations ou des sessions. Il s'agit des connaissances qu'un agent conserve au fil du temps, des faits qu'il a appris précédemment, des préférences de l'utilisateur ou de toute autre donnée que nous lui avons demandé de garder en mémoire de manière permanente.
La mémoire à long terme est généralement mise en œuvre en stockant et en récupérant les données à partir d'une source externe, telle qu'un fichier ou une base vectorielle située en dehors de la fenêtre contextuelle immédiate. Contrairement à l'historique de discussion à court terme, la mémoire à long terme n’est pas automatiquement incluse dans chaque requête. Au lieu de cela, sur la base d'un scénario donné, l'agent doit le rappeler ou le retrouver lorsque les outils pertinents sont invoqués. En pratique, la mémoire à long terme peut inclure les informations de profil de l’utilisateur, des réponses ou analyses antérieures produites par l’agent, ou une base de connaissances que l’agent peut consulter.
Par exemple, si vous avez un agent planificateur de voyage, la mémoire à court terme contiendrait les détails de la demande de voyage actuelle (dates, destination, budget) et toutes les questions de suivi dans cette conversation ; tandis que la mémoire à long terme pourrait stocker les préférences générales de voyage de l'utilisateur, les itinéraires passés et d'autres faits partagés lors de sessions précédentes. Lorsque l'utilisateur revient plus tard, l'agent peut puiser dans cette base de données à long terme (par exemple, l'utilisateur aime les plages et les montagnes, dispose d'un budget moyen de 100 000 INR, a une liste de lieux à visiter et préfère découvrir l'histoire et la culture plutôt que les attractions pour enfants) afin de ne pas traiter l'utilisateur comme une page blanche à chaque fois.
La mémoire à court terme (historique des conversations) fournit un contexte immédiat et une continuité, tandis que la mémoire à long terme fournit un contexte plus large dans lequel l'agent peut puiser en cas de besoin. Les cadres d'agents d'IA les plus avancés permettent les deux : ils gardent la trace des dialogues récents pour maintenir le contexte et proposent des mécanismes pour rechercher ou stocker des informations dans un référentiel à plus long terme. La gestion de la mémoire à court terme garantit qu'elle reste dans la fenêtre de contexte, tandis que la gestion de la mémoire à long terme aide l'agent à ancrer les réponses sur la base d'interactions et de personas antérieures.
Mémoire et RAG en ingénierie contextuelle
Source de l’image : https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-03-own-your-context-window.md
Comment pouvons-nous donner à un agent IA une mémoire à long terme utile en pratique ?
La mémoire sémantique, souvent mise en œuvre par le biais de la retrieval-augmented generation (RAG), constitue l'une des principales approches pour la mémoire à long terme. Cela consiste à couler le LLM avec un stockage de connaissances externe ou un datastore vectoriel, comme Elasticsearch. Lorsque le LLM a besoin d'informations au-delà de ce qui est contenu dans l'invite ou dans son entraînement intégré, il effectue une récupération sémantique contre Elasticsearch et injecte les résultats les plus pertinents dans l'invite en tant que contexte. Ainsi, le contexte effectif du modèle inclut non seulement la conversation récente (mémoire à court terme), mais aussi des faits pertinents à long terme récupérés à la volée. Le LLM fonde ensuite sa réponse sur son propre raisonnement et les informations récupérées, combinant efficacement la mémoire à court terme et la mémoire à long terme pour produire une réponse plus précise et contextuelle.
Elasticsearch peut être utilisé pour mettre en place une mémoire à long terme pour les agents d’IA. Voici un exemple de haut niveau montrant comment le contexte peut être récupéré depuis Elasticsearch pour la mémoire à long terme.
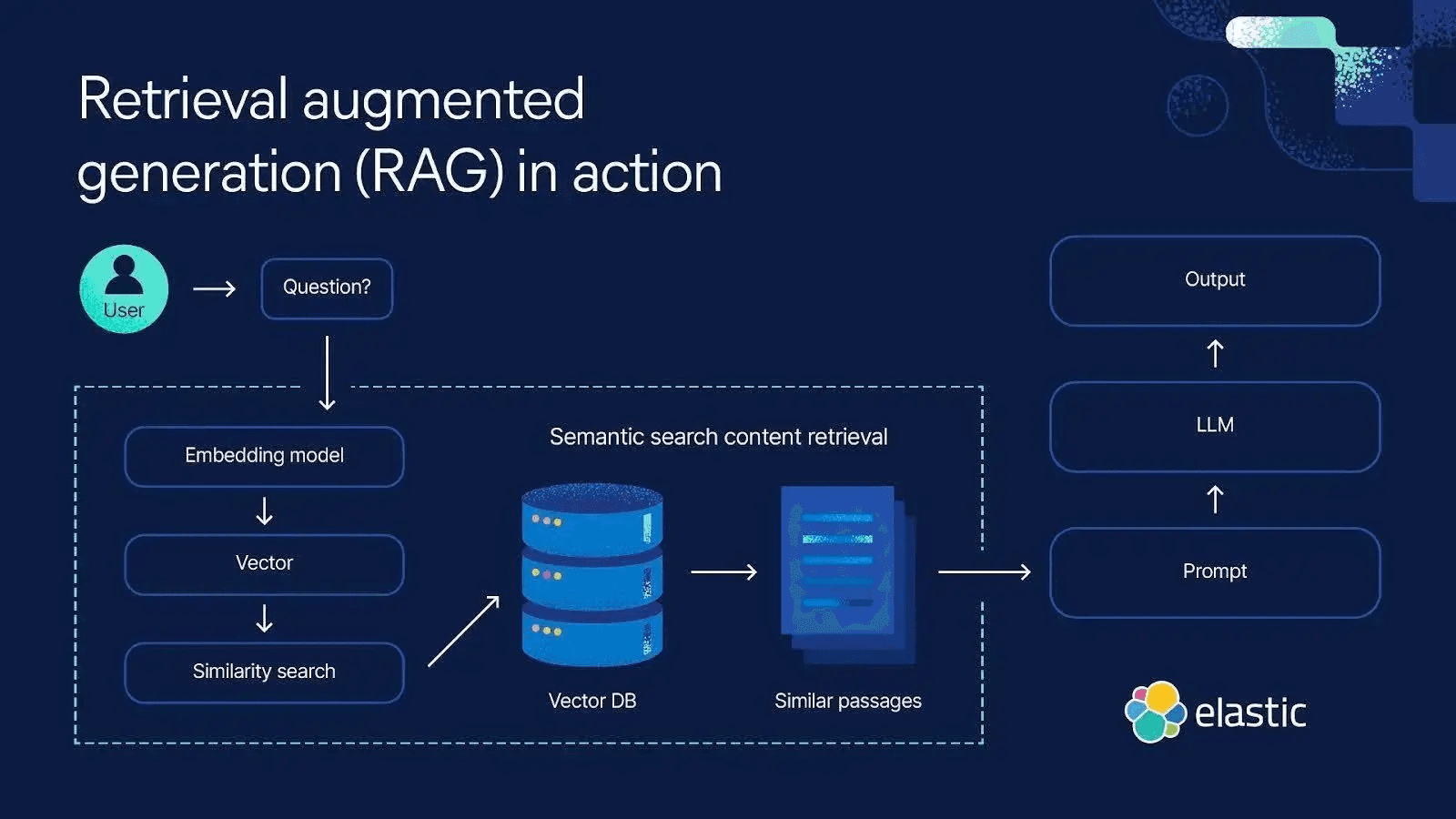
De cette façon, l’agent « se souvient » en recherchant des données pertinentes plutôt que de tout stocker dans son invite limitée, ce qui entraîne différents risques.
L'utilisation de RAG avec Elasticsearch ou tout stockage de vecteurs offre de multiples avantages :
Premièrement, il étend la connaissance du modèle au-delà de son seuil d'apprentissage. L’agent peut récupérer des informations à jour ou des données spécifiques au domaine que le LLM pourrait ne pas connaître. Ceci est crucial pour les questions concernant des événements récents ou des sujets spécialisés.
Deuxièmement, récupérer le contexte à la demande aide à réduire les hallucinations, surtout que les LLM ne sont pas entraînés sur des données propriétaires ou très spécialisées par rapport à votre cas d'utilisation spécifique, ce qui est très susceptible de les exposer à des hallucinations. Au lieu que le LLM devine ou invente de nouvelles informations comme il a été incité par évaluation, comme l’a souligné un article récent d’OpenAI (Why Language Models Hallucinate), le modèle peut être fondé sur des références factuelles provenant d’Elasticsearch. Bien entendu, le LLM dépend de la fiabilité des données du référentiel vectoriel pour prévenir véritablement la désinformation, et les données pertinentes sont extraites conformément aux mesures de pertinence fondamentales.
Troisièmement, RAG permet à un agent de travailler avec des bases de connaissances bien plus vastes que tout ce que vous pourriez inclure dans une invite. Au lieu d'insérer des documents entiers, comme de longs documents de recherche ou des documents politiques, dans la fenêtre contextuelle et de risquer une surcharge ou un empoisonnement du contexte du raisonnement du modèle par une information non pertinente, RAG s'appuie sur le découpage. Les documents volumineux sont divisés en morceaux plus petits et sémantiquement significatifs, et le système ne récupère que les quelques segments les plus pertinents pour la requête. Ainsi, le modèle n'a pas besoin d'un contexte d'un million de mots pour paraître bien informé ; il lui suffit d'avoir accès aux bons morceaux d'un corpus beaucoup plus vaste.
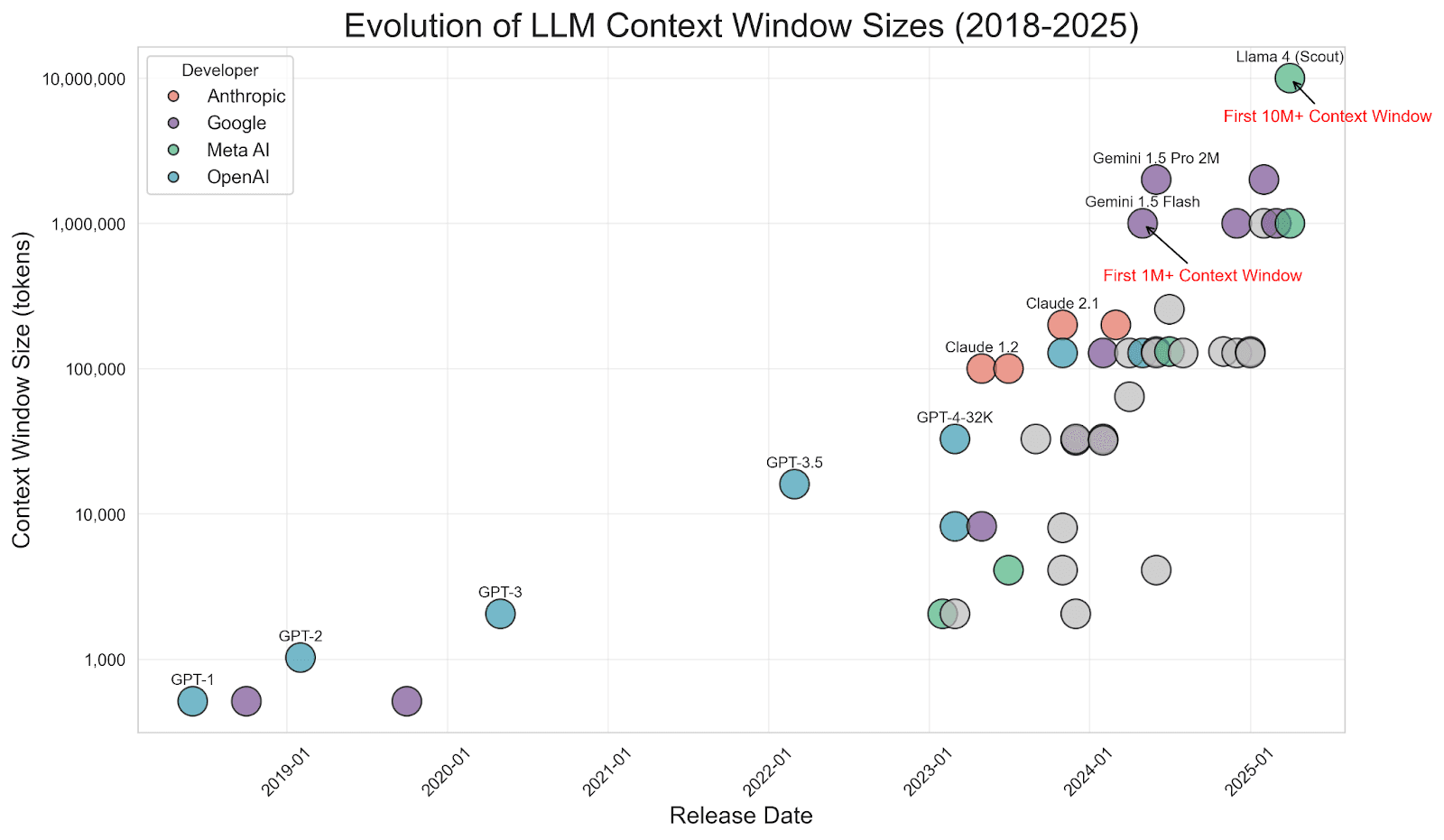
Source de l'image : https://www.meibel.ai/post/understanding-the-impact-of-increasing-llm-context-windows
Il est important de noter qu’à mesure que les fenêtres contextuelles des LLM se sont agrandies (certains modèles supportent désormais des centaines de milliers, voire des millions de jetons), un débat a surgi sur la question de savoir si RAG est « mort ». Pourquoi ne pas intégrer toutes les données dans l'invite ? Si vous êtes du même avis, reportez-vous à cet excellent article de mes collègues Jeffrey Rengifo et Eduard Martin, Longer context ≠ better : Why RAG still matters. Cela évite le problème du « déchets en entrée, déchets en sortie » : le LLM reste concentré sur les quelques morceaux qui comptent, plutôt que de parcourir du bruit.
Cela dit, l'intégration d'Elasticsearch ou de n'importe quelle mémoire vectorielle dans une architecture d'agent d'IA offre une mémoire à long terme. L'agent stocke les connaissances à l'extérieur et les intègre au contexte de la mémoire en cas de besoin. Cela pourrait être implémenté sous forme d’architecture, où après chaque requête utilisateur, l’agent effectue une recherche sur Elasticsearch pour des informations pertinentes puis ajoute les premiers résultats à l’invite avant d’appeler le LLM. La réponse peut également être enregistrée dans le stockage à long terme si elle contient de nouvelles informations utiles (création d'une boucle d'apprentissage). En utilisant cette mémoire basée sur la récupération, l’agent reste informé et à jour, sans avoir à tout condenser dans chaque invite, même si la fenêtre de contexte prend en charge un million de tokens. Cette technique est une pierre angulaire de l'ingénierie contextuelle, combinant les forces de la récupération d'informations et de l'IA générative.
Voici un exemple d'état de conversation géré en mémoire utilisant le système de points de contrôle de LangGraph pour la mémoire à court terme pendant la session. (Reportez-vous à notre application d'ingénierie contextuelle.)
Voici comment il stocke les points de contrôle :
Pour la mémoire à long terme, voici comment nous effectuons une recherche sémantique sur Elasticsearch pour récupérer des conversations précédentes pertinentes en utilisant des vecteurs d'intégration après la résumé et l'indexation des points de contrôle dans Elasticsearch.
Maintenant que nous avons exploré comment la mémoire à court terme et la mémoire à long terme sont indexées et récupérées à l’aide des points de contrôle de LangGraph dans Elasticsearch, prenons un moment pour comprendre pourquoi l'indexation et le vidage des conversations complètes peut être risqué.
Risques liés à une mauvaise gestion de la mémoire de contexte
Alors que nous parlons beaucoup d’ingénierie du contexte, ainsi que de la mémoire à court et à long terme, comprenons ce qui se passe si nous ne gérons pas bien la mémoire et le contexte d’un agent.
Malheureusement, de nombreux problèmes peuvent survenir lorsque le contexte d’une IA devient extrêmement long ou contient des informations erronées. Au fur et à mesure que les fenêtres contextuelles s’agrandissent, de nouveaux modes de défaillance apparaissent, comme :
- Empoisonnement contextuel
- Distraction contextuelle
- Confusion de contexte
- Conflit de contexte
- Fuite de contexte et conflits de connaissances
- Hallucinations et désinformation.
Examinons ces problèmes et les autres risques qui découlent d'une mauvaise gestion du contexte :
Empoisonnement contextuel
L'empoisonnement du contexte fait référence au fait que des informations incorrectes ou nuisibles apparaissent dans le contexte et « empoisonne » les sorties ultérieures du modèle. Un exemple courant est une hallucination du modèle qui est traitée comme un fait et insérée dans l'historique de la conversation. Le modèle pourrait alors s'appuyer sur cette erreur dans les réponses ultérieures, aggravant la faute. Dans les boucles itératives d'agents, une fois qu'une fausse information s'est intégrée dans le contexte partagé (par exemple, dans un résumé des notes de travail de l'agent), elle peut être renforcée à maintes reprises.
Les chercheurs de DeepMind, dans la publication du rapport Gemini 2.5 (TL;DR, consultez ici), ont observé ce phénomène chez un agent joueur de Pokémon delongue date : si l'agent hallucinait un état de jeu erroné et que celui-ci était enregistré dans son contexte (sa mémoire des objectifs), il formait des stratégies absurdes autour d'un objectif impossible et se retrouvait bloqué. En d'autres termes, une mémoire empoisonnée peut envoyer l'agent sur la mauvaise voie indéfiniment.
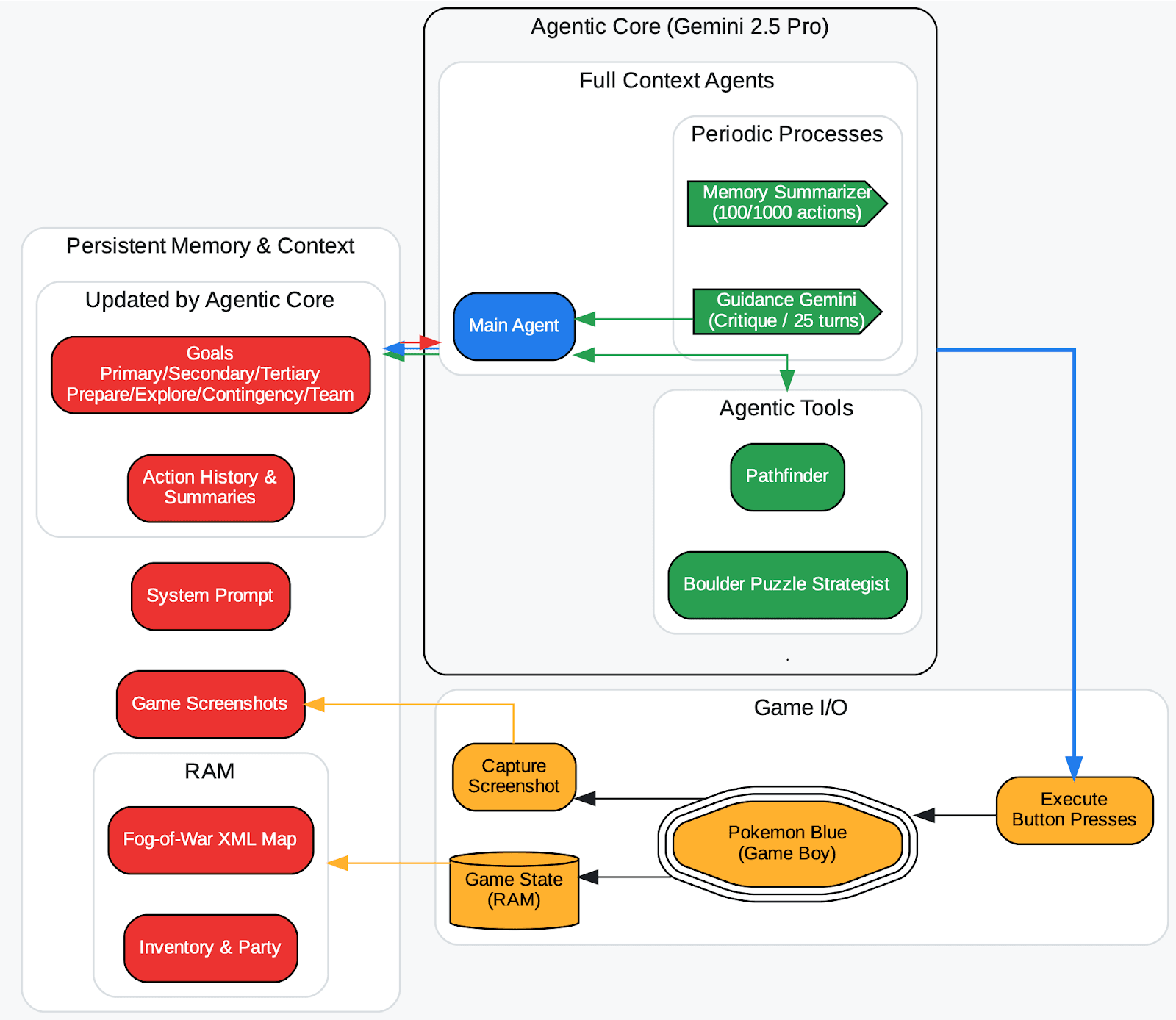
Un aperçu du harnais d’agent (Zhang, 2025). La carte du monde avec brouillard de guerre stocke automatiquement une case une fois explorée et l'étiquette avec un compteur de cases visitées. Le type de tuile est enregistré depuis la RAM. Les outils agentiques (pathfinder, boulder_puzzle_strategist) sont des instances invitées de Gemini 2.5 Pro. pathfinder est utilisé pour la navigation et boulder_puzzle_strategist permet de résoudre des énigmes de rochers dans le donjon de Victory Road.
Source de l’image : https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - page 68.
L'empoisonnement du contexte peut se produire de manière innocente (par erreur) ou même de manière malveillante, par exemple via des attaques par injection de requêtes où un utilisateur ou un tiers introduit une instruction cachée ou une fausse information que l'agent mémorise ensuite et suit.
Contre-mesures recommandées :
S’appuyant sur les informations de Wiz, Zerlo et Anthropic, les contre-mesures contre l’empoisonnement du contexte visent à empêcher que des informations erronées ou trompeuses ne pénètrent dans l’invite, la fenêtre de contexte ou le pipeline de récupération d’un LLM. Parmi les principales étapes, citons :
- Vérifiez constamment le contexte : surveillez la conversation ou le texte récupéré afin de détecter tout élément suspect ou nuisible, et pas seulement l’invite de départ.
- Utilisez des sources fiables : attribuez une note ou un label aux documents en fonction de leur crédibilité afin que le système privilégie les informations fiables et ignore les données mal notées.
- Repérez les données inhabituelles : utilisez des outils qui détectent les contenus bizarres, déplacés ou manipulés, et supprimez-les avant que le modèle ne les utilise.
- Filtrez les entrées et les sorties : ajoutez des garde-fous pour que les textes nuisibles ou trompeurs ne puissent pas facilement entrer dans le système ou être répétés par le modèle.
- Mettez le modèle à jour avec des données propres : actualisez régulièrement le système avec des informations vérifiées afin de corriger les éventuelles données erronées.
- Supervision humaine : faites examiner les sorties importantes par des personnes ou comparez-les à des sources connues et fiables.
De simples habitudes utilisateur sont également utiles : réinitialiser les longues conversations, ne partager que les informations pertinentes, découper les tâches complexes en étapes plus simples et conserver des notes claires en dehors du modèle.
Ensemble, ces mesures créent une défense en couches qui protège les LLM contre l'empoisonnement du contexte et maintient les sorties précises et dignes de confiance.
Sans les contre-mesures mentionnées ici, un agent pourrait se souvenir d'instructions, comme ignorer des lignes directrices antérieures ou des faits triviaux insérés par un attaquant, ce qui conduirait à des sorties nuisibles.
Distraction contextuelle
On parle de distraction contextuelle lorsqu'un contexte devient si long que le modèle se concentre excessivement sur le contexte, négligeant ce qu'il a appris pendant la formation. Dans les cas extrêmes, cela ressemble à un oubli catastrophique, c'est-à-dire que le modèle « oublie » effectivement ses connaissances sous-jacentes et s'attache excessivement aux informations qui lui sont présentées. Des études précédentes ont montré que les LLM perdent souvent leur concentration lorsque l'invite est extrêmement longue.
L'agent Gemini 2.5, par exemple, prenait en charge une fenêtre d'un million de jetons, mais dès que son contexte dépassait un certain seuil (de l'ordre de 100 000 jetons dans une expérience), il commençait à s'attacher à répéter ses actions passées au lieu de proposer de nouvelles solutions. En un sens, l’agent est devenu prisonnier de sa longue histoire. Il a continué à regarder son long log de mouvements précédents (le contexte) et à les imiter, plutôt que d'utiliser ses connaissances d'entraînement sous-jacentes pour concevoir des stratégies nouvelles et inédites.

Source de l'image : https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - page 18.
C'est contreproductif. Nous voulons que le modèle utilise un contexte pertinent pour faciliter le raisonnement, et non qu'il prenne le pas sur sa capacité de réflexion. Fait notable, même les modèles disposant de fenêtres très larges présentent une forme de dégradation du contexte : leurs performances se détériorent de manière non uniforme à mesure que le nombre de jetons augmente. Il semble exister un budget d’attention : tout comme les humains ont une mémoire de travail limitée, un LLM dispose d’une capacité finie pour traiter les jetons, et plus ce budget est sollicité, plus sa précision et sa concentration diminuent.
Pour atténuer ce problème, vous pouvez empêcher la distraction contextuelle en utilisant la segmentation, en concevant les bonnes informations, en résumant régulièrement le contexte et en appliquant des techniques d’évaluation et de surveillance pour mesurer la précision de la réponse à l’aide de la notation.
Ces méthodes permettent au modèle de rester ancré dans un contexte pertinent et dans sa formation sous-jacente, ce qui réduit le risque de distraction et améliore la qualité globale du raisonnement.
Confusion de contexte
La confusion contextuelle se produit lorsque le modèle utilise du contenu superflu dans le contexte pour générer une réponse de faible qualité. Un bon exemple est de fournir à un agent un large éventail d'outils ou de définitions d'API qu'il peut utiliser. Si bon nombre de ces outils n'ont aucun rapport avec la tâche en cours, le modèle peut tout de même essayer de les utiliser de manière inappropriée, simplement parce qu'ils sont présents dans le contexte. Les expériences ont montré que fournir plus d'outils ou de documents peut nuire aux performances s'ils ne sont pas tous nécessaires. L’agent commence à faire des erreurs, comme appeler la mauvaise fonction ou référer un texte sans importance.
Dans un cas, un petit modèle Llama 3.1 8B a échoué à une tâche lorsqu'on lui a donné 46 outils à prendre en compte, mais a réussi lorsqu'on ne lui a donné que 19 outils. Ces outils supplémentaires ont créé de la confusion, même si le contexte respectait les limites de longueur. Le problème sous-jacent est que toute information contenue dans l'invite sera prise en compte par le modèle. Si un système ne sait pas ignorer quelque chose, ce quelque chose pourrait influencer sa sortie de manière indésirable. Des éléments non pertinents peuvent « détourner » une partie de l'attention du modèle et l'induire en erreur (par exemple, un document non pertinent pourrait amener l'agent à répondre à une question différente de celle posée). La confusion contextuelle se manifeste souvent par la production, par le modèle, d'une réponse de faible qualité intégrant un contexte non pertinent. Se référer à l'article de recherche : Less is More: Optimizing Function Calling for LLM Execution on Edge Devices.
Cela nous rappelle qu'il n'est pas toujours préférable d'avoir plus de contexte, surtout si ce n'est pas organisé pour des raisons de pertinence.
Conflit de contexte
Il y a conflit de contexte lorsque des éléments du contexte se contredisent, provoquant des incohérences internes qui font dérailler le raisonnement du modèle. Un conflit peut survenir si l'agent accumule plusieurs éléments d'information qui sont en conflit.
Par exemple, imaginez un agent qui a récupéré des données de deux sources : l'une dit Le vol A part à 17 h, et l'autre dit Le vol A part à 18 h. Si les deux faits se retrouvent dans le contexte, le modèle pauvre n'a aucun moyen de savoir lequel est correct ; il peut s'embrouiller ou produire une réponse incorrecte ou non similaire.
Le conflit de contexte se produit aussi fréquemment dans les conversations à plusieurs tours, lorsque les tentatives de réponse antérieures du modèle sont encore présentes dans le contexte avec des informations affinées ultérieurement.

Source de l'image : le LLMS se perd dans la conversation sur le multi-tour (Page 04)
Une étude menée par Microsoft et Salesforce montre que si l'on divise une requête complexe en plusieurs échanges avec un chatbot (en ajoutant progressivement des détails), la précision finale diminue considérablement, comparée à la fourniture de tous les détails en une seule requête. Pourquoi ? Parce que les premiers tours contiennent des réponses intermédiaires partielles ou incorrectes du modèle, et que celles-ci restent dans le contexte. Lorsque le modèle tente par la suite de répondre avec toutes les informations, sa mémoire contient encore ces tentatives erronées, qui entrent en conflit avec les informations corrigées et l'éloignent de la bonne voie. En substance, le contexte de la conversation entre en conflit avec lui-même. Le modèle peut utiliser par inadvertance un élément de contexte obsolète (d'un tour précédent) qui ne s'applique plus après l'ajout de nouvelles informations.
Dans les systèmes agents, le conflit de contexte est particulièrement dangereux, car un agent peut combiner des sorties provenant de différents outils ou sous-agents. Si ces sorties divergent, le contexte agrégé est incohérent. L'agent pourrait alors se retrouver bloqué ou produire des résultats absurdes en essayant de réconcilier les contradictions. Prévenir les conflits de contexte implique de s’assurer que le contexte est frais et cohérent, par exemple en effaçant .ou en mettant à jour toute information obsolète et en ne mélangeant pas les sources qui n’ont pas été vérifiées pour leur cohérence.
Fuite de contexte et conflits de connaissances
Dans les systèmes où plusieurs agents ou utilisateurs partagent un stockage de mémoire, il existe un risque de fuite d'informations entre les contextes.
Par exemple, si les intégrations de données de deux utilisateurs distincts résident dans la même base vectorielle sans un contrôle d’accès approprié, un agent répondant à la requête de l’utilisateur A pourrait accidentellement récupérer une partie de la mémoire de l’utilisateur B. Cette fuite intercontextuelle peut révéler des informations privées ou simplement créer de la confusion dans les réponses.
Selon le Top 10 de l'OWASP pour les applications LLM, les bases vectorielles multitenant doivent se prémunir contre de telles fuites :
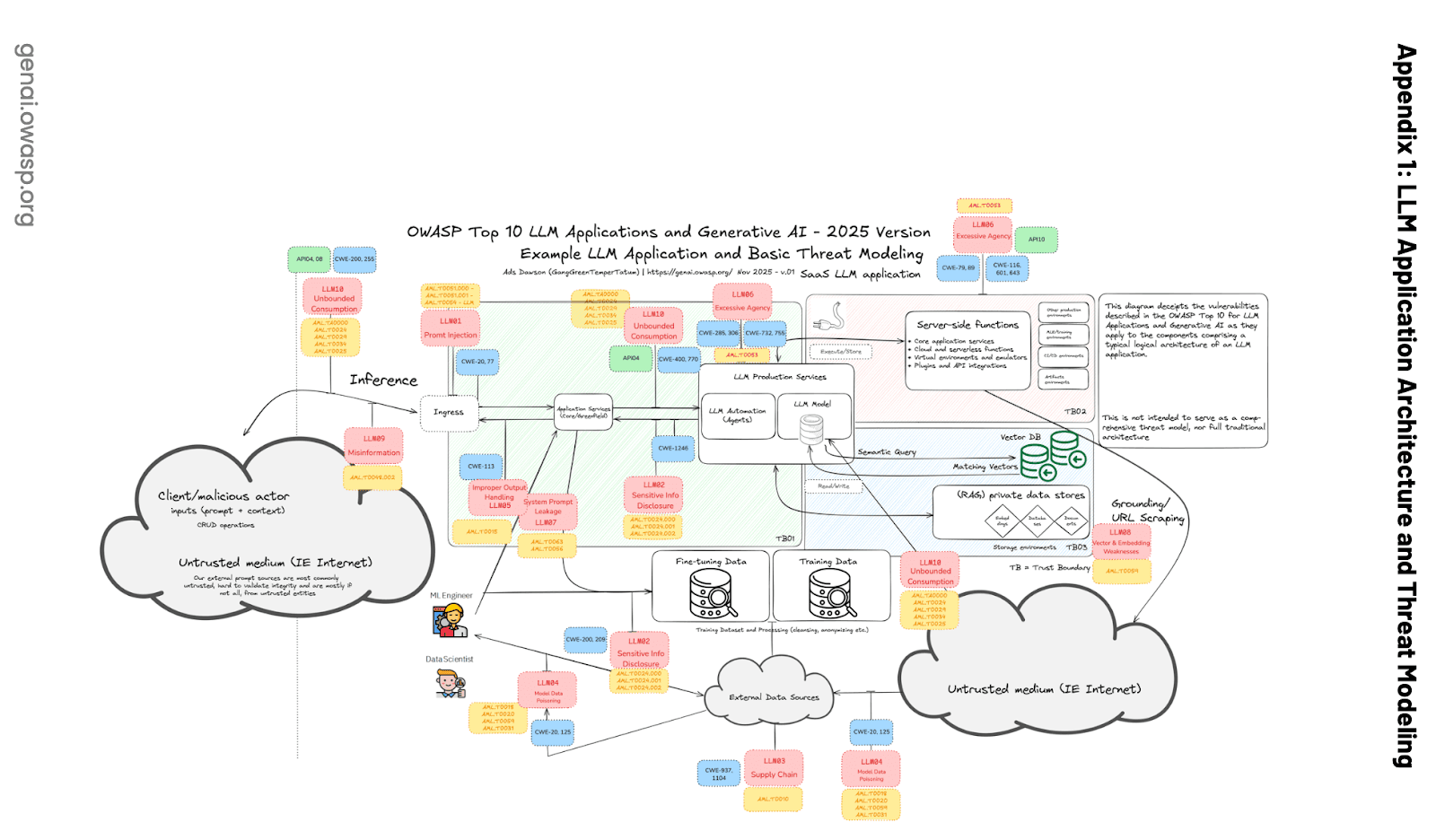
Source de l’image : https://wtit.com/blog/2025/04/17/owasp-top-10-for-llm-applications-2025
Selon LLM08:2025 Vector and Embedding Weaknesses, l'un des risques courants est la fuite de contexte :
Dans les environnements multi-locataires où plusieurs classes d’utilisateurs ou d’applications partagent la même base vectorielle, il existe un risque de fuite de contexte entre utilisateurs ou requêtes. Les erreurs de conflit de connaissances dans la fédération de données peuvent survenir lorsque les données provenant de sources multiples se contredisent les unes les autres. Cela peut également se produire lorsqu'un LLM ne peut pas remplacer les anciennes connaissances qu'il a acquises pendant la formation par les nouvelles données issues de l'augmentation de la récupération.
Un autre aspect est qu'un LLM peut avoir du mal à remplacer ses connaissances intégrées par de nouvelles informations de mémoire. Si le modèle a été formé sur la base d'un fait et que le contexte retrouvé dit le contraire, le modèle peut ne pas savoir à quoi se fier. Sans une conception appropriée, l'agent pourrait confondre les contextes ou ne pas mettre à jour les anciennes connaissances avec de nouvelles preuves, conduisant à des réponses obsolètes ou incorrectes.
Hallucinations et désinformation.
Si l'hallucination (le LLM invente des informations plausibles mais fausses) est un problème connu, même sans contexte prolongé, une mauvaise gestion de la mémoire peut l'amplifier.
Si la mémoire de l'agent manque d'un fait crucial, le modèle peut simplement combler cette lacune par une supposition, et si cette supposition entre ensuite dans le contexte (en l'empoisonnant), l'erreur persiste.
Le rapport de sécurité OWASP LLM (LLM09:2025 Désinformation) met en évidence la désinformation comme une vulnérabilité fondamentale : les LLM peuvent produire des réponses confiantes mais fabriquées, et les utilisateurs peuvent leur accorder trop de crédit. Un agent dont la mémoire à long terme est mauvaise ou obsolète peut citer en toute confiance une information qui était vraie l'année dernière mais qui est fausse aujourd'hui, à moins que sa mémoire ne soit mise à jour.
Une dépendance excessive à la sortie de l'IA (par l'utilisateur ou l'agent lui-même dans la boucle) peut aggraver cette situation. Si personne ne vérifie jamais les informations en mémoire, l'agent peut accumuler de fausses informations. C’est pourquoi la méthode RAG est souvent utilisée pour réduire les hallucinations : en se référant à une source faisant autorité, le modèle n’a pas besoin d’inventer des faits. Mais si votre recherche aboutit au mauvais document (par exemple, un document contenant des informations erronées) ou si une hallucination précoce n'est pas élaguée, le système peut propager ces informations erronées dans toutes ses actions.
En résumé : une mauvaise gestion de la mémoire peut conduire à des sorties incorrectes et trompeuses, ce qui peut être préjudiciable, surtout si les enjeux sont importants (par exemple, de mauvais conseils dans le domaine financier ou médical). Un agent doit disposer de mécanismes pour vérifier ou corriger le contenu de sa mémoire, et non simplement faire confiance de manière inconditionnelle à ce qui se trouve dans le contexte.
En résumé, doter un agent d'IA d'une mémoire infiniment longue ou déverser tout ce qui est possible dans son contexte n' est pas une recette pour le succès.
Bonnes pratiques pour la gestion de la mémoire dans les applications LLM
Pour éviter les pièges ci-dessus, les développeurs et les chercheurs ont élaboré un certain nombre de bonnes pratiques pour gérer le contexte et la mémoire dans les systèmes d'IA. Ces pratiques visent à maintenir le contexte de travail de l'IA allégé, pertinent et actualisé. Voici quelques-unes des stratégies clés, accompagnées d'exemples de leur utilité.
RAG : utiliser le contexte ciblé.
Une grande partie de RAG a déjà été abordée dans la section précédente, ceci constitue donc un rappel pratique et concis :
- Utilisez une récupération ciblée, pas un chargement en masse : récupérez uniquement les extraits les plus pertinents au lieu d'insérer des documents entiers ou des historiques de conversation complets dans l'invite.
- Considérez RAG comme un rappel de mémoire à la demande : récupérez le contexte uniquement lorsqu’il est nécessaire, plutôt que de tout conserver d’un échange à l’autre.
- Privilégiez des stratégies de récupération sensibles à la pertinence : des approches telles que la recherche sémantique top-k, la fusion de rangs réciproques (Reciprocal Rank Fusion) ou le filtrage par configuration d’outils permettent de réduire le bruit et d’améliorer l’ancrage.
- Des fenêtres de contexte plus larges ne suppriment pas le besoin de RAG : deux paragraphes hautement pertinents sont presque toujours plus efficaces que 20 pages vaguement liées.
Cela dit, RAG ne vise pas à ajouter plus de contexte ; il s’agit d’ajouter le bon contexte.
Chargement des outils
Le loadout d’outils consiste à donner à un modèle uniquement les outils dont il a réellement besoin pour une tâche. Le terme vient du jeu : vous choisissez une configuration qui convient à la situation. Trop d'outils vous ralentissent ; les mauvais sont à l'origine de l'échec. Les LLM se comportent de la même manière, selon l'article de recherche Less is more. Une fois que vous dépassez ~30 outils, les descriptions commencent à se chevaucher et le modèle se trouve dérouté. Plus de 100 outils, l'échec est presque garanti. Ce n’est pas un problème de fenêtre contextuelle, c’est une confusion de contexte.
Une solution simple et efficace est RAG-MCP. Au lieu de saisir tous les outils dans l'invite, les descriptions d'outils sont stockées dans une base vectorielle et seuls les outils les plus pertinents sont récupérés par demande. En pratique, cela permet de réduire la taille de l'équipement et de le concentrer, de raccourcir considérablement les instructions et d'améliorer la précision de la sélection des outils jusqu'à 3 fois.
Les modèles plus petits atteignent ce plafond encore plus tôt. La recherche montre qu'un modèle 8B échoue avec des dizaines d'outils mais réussit une fois que la configuration est réduite. La sélection dynamique des outils, parfois précédée d’une réflexion par un LLM sur ce dont il pense avoir besoin, peut améliorer les performances de 44 %, tout en réduisant la consommation d’énergie et la latence. La principale leçon est que la plupart des agents n’ont besoin que de quelques outils, mais à mesure que votre système se développe, la configuration des outils et le RAG-MCP deviennent des choix de conception de premier ordre.
Élagage du contexte : limiter la longueur de l'historique de conversation
Si une conversation se poursuit sur de nombreux tours, l'historique de discussion accumulé peut devenir trop volumineux pour tenir, entraînant un débordement de contexte ou devenant trop distrayant pour le modèle.
Le rognage consiste à supprimer ou à raccourcir par programmation les parties les moins importantes du dialogue au fur et à mesure qu'il grandit. Une forme simple consiste à supprimer les tours de parole les plus anciens lorsque vous atteignez une certaine limite, en ne conservant que les N derniers messages. Un élagage plus sophistiqué pourrait supprimer les digressions non pertinentes ou les instructions précédentes devenues inutiles. L'objectif est de ne pas encombrer la fenêtre contextuelle par les anciennes actualités.
Par exemple, si l’agent a résolu un sous-problème il y a 10 échanges et que nous sommes passés à autre chose depuis, nous pourrions supprimer cette partie de l’historique du contexte (en supposant qu’elle ne sera plus nécessaire). De nombreuses implémentations basées sur le chat font cela : elles assurent la maintenance d'une fenêtre dynamique de messages récents.
La suppression peut être aussi simple que le fait d’« oublier » les premières parties d’une conversation une fois qu’elles ont été résumées ou jugées non pertinentes. Ce faisant, nous réduisons le risque d'erreurs de débordement du contexte et nous réduisons également la distraction du contexte, de sorte que le modèle ne voit pas et ne se laisse pas distraire par un contenu ancien ou hors sujet. Cette approche ressemble beaucoup à celle des humains, qui ne se souviennent peut-être pas de chaque mot d’une conférence d’une heure, mais en retiennent les points essentiels.
Si vous avez des doutes sur l'élagage de contexte, comme le souligne l'auteur Drew Breunig ici, l'utilisation du modèle Provence (`naver/provence-reranker-debertav3-v1`), un élagueur de contexte léger (1,75 Go), efficace et précis pour la réponse aux questions, peut faire la différence. Il peut réduire de gros documents à seulement le texte le plus pertinent pour une requête donnée. Vous pouvez l'appeler à des intervalles précis.
Voici comment nous invoquons le modèle `provence-reranker` dans notre code pour élaguer le contexte :
Nous utilisons le modèle de reranker Provence (`naver/provence-reranker-debertav3-v1`) pour évaluer la pertinence des phrases. La filtration basée sur des seuils conserve les phrases au-dessus du seuil de pertinence. Nous introduisons également un mécanisme de repli, qui permet de revenir au contexte d'origine en cas d'échec de l'élagage. Enfin, le logging des statistiques permet de suivre le pourcentage de réduction en mode verbeux.
Synthèse du contexte : condenser les anciennes informations au lieu de les supprimer entièrement
Le résumé va de pair avec le découpage. Lorsque l’historique ou la base de connaissances devient trop vaste, vous pouvez utiliser le LLM pour générer un bref résumé des points importants et utiliser ce résumé à la place du contenu complet par la suite, comme nous l’avons fait dans notre code ci-dessus.
Par exemple, si un assistant IA a eu une conversation de 50 tours, au lieu d'envoyer tous les 50 tours au modèle au tour 51 (ce qui ne rentrera probablement pas), le système pourrait prendre les tours 1 à 40, demander au modèle de les résumer en un paragraphe, et ensuite ne fournir que ce résumé plus les 10 derniers tours dans la prochaine invite. De cette façon, le modèle reste conscient de ce qui a été discuté sans avoir besoin de tous les détails. Les premiers utilisateurs de chatbots faisaient cela manuellement en demandant : « Pouvez-vous résumer ce dont nous avons parlé jusqu'à présent ? » puis en continuant dans une nouvelle session avec le résumé. Maintenant, cela peut être automatisé. Le résumé permet non seulement d'économiser de l'espace dans la fenêtre contextuelle, mais aussi de réduire la confusion et la distraction en éliminant les détails supplémentaires et en ne conservant que les faits saillants.
Voici comment nous utilisons les modèles OpenAI (vous pouvez utiliser n’importe quel LLM) pour condenser le contexte tout en préservant toutes les informations pertinentes, en éliminant la redondance et la duplication.
Il est important de noter que lorsque le contexte est résumé, le modèle est moins susceptible d'être submergé par des détails insignifiants ou des erreurs passées (en supposant que le résumé soit exact).
Cependant, le résumé doit être fait avec soin. Un mauvais résumé peut omettre un détail crucial ou même introduire une erreur. Il s’agit essentiellement d’une autre invite adressée au modèle (« résumez ceci »), ce qui peut entraîner des hallucinations ou une perte de nuances. Une bonne pratique consiste à résumer de manière incrémentielle et peut-être conserver certains faits canoniques non résumés.
Néanmoins, il s'est avéré très utile. Dans le scénario de l'agent Gemini, le fait de résumer le contexte tous les 100 000 jetons environ a permis de contrecarrer la tendance du modèle à se répéter. Le résumé agit comme une mémoire compressée de la conversation ou des données. En tant que développeurs, nous pouvons mettre cela en œuvre en demandant à un agent d'appeler périodiquement une fonction de résumé (peut-être un LLM plus petit ou une routine dédiée) sur l'historique de la conversation ou un long document. Le résumé résultant remplace le contenu original dans la consigne. Cette tactique est largement utilisée pour limiter les contextes et distiller l'information.
Quarantaine contextuelle : isolez les contextes lorsque c'est possible
Cela est plus pertinent dans les systèmes d'agents complexes ou les workflows à plusieurs étapes. L'idée de la segmentation du contexte est de diviser une grande tâche en sous-tâches plus petites et isolées, chacune ayant son propre contexte, de sorte que vous n'accumuliez jamais un contexte énorme qui contient tout. Chaque sous-agent ou sous-tâche travaille sur une partie du problème dans un contexte précis, puis un agent de niveau supérieur, un superviseur ou un coordinateur intègre les résultats.
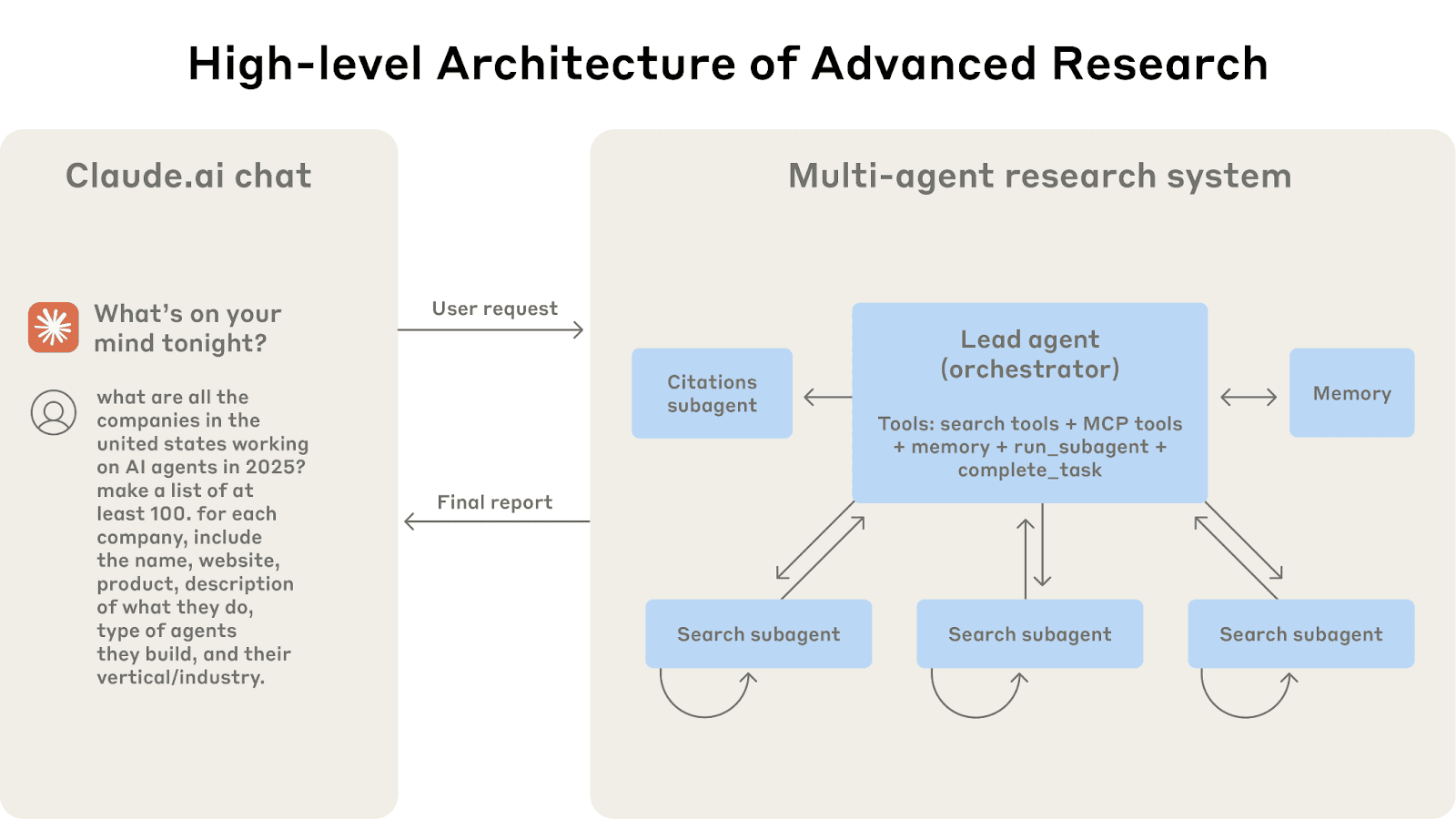
L'architecture multi-agents en action : les requêtes des utilisateurs passent par un agent principal qui crée des sous-agents spécialisés pour rechercher différents aspects en parallèle.
Source de l’image : https://www.anthropic.com/engineering/multi-agent-research-system
La stratégie de recherche d’Anthropic utilise plusieurs sous-agents, chacun examinant un aspect différent d’une question, avec ses propres fenêtre de contexte, et un agent principal qui lit les résultats synthétisés de ces sous-agents. Cette approche parallèle et modulaire signifie qu'aucune fenêtre contextuelle unique ne devient trop volumineuse. Cela réduit également le risque de mélange d'informations non pertinentes, chaque fil de discussion reste sur le sujet (pas de confusion de contexte), et il ne transporte pas de bagages superflus lors de la réponse à sa sous-question spécifique. Dans un sens, c'est comme suivre des fils de réflexion distincts qui ne partagent que leurs résultats, et non l'ensemble de leur processus de réflexion.
Dans les systèmes multi-agents, cette approche est essentielle. Si l'agent A gère la tâche A et l'agent B gère la tâche B, il n'y a aucune raison pour que l'un ou l'autre agent consomme le contexte complet de l'autre, sauf si c'est vraiment nécessaire. Les agents ne peuvent échanger que les informations nécessaires. Par exemple, l'agent A peut transmettre un résumé consolidé de ses résultats à l'agent B via un agent superviseur, tandis que chaque sous-agent assure la maintenance de son propre fil de contexte dédié. Cette configuration ne nécessite pas d'intervention humaine ; elle repose sur un agent de supervision doté d'outils activés avec un partage de contexte minimal et contrôlé.
Néanmoins, concevoir votre système de manière à ce que les agents ou les outils fonctionnent avec un chevauchement minimal du contexte nécessaire peut grandement améliorer la clarté et les performances. Pensez-y comme à des microservices pour l'IA, chaque composant s'occupe de son contexte, et vous passez des messages entre eux de manière contrôlée, au lieu d'un contexte monolithique. Ces bonnes pratiques sont souvent utilisées de manière combinée. Cela vous offre également la possibilité de supprimer l'historique trivial, de résumer les anciens messages ou conversations importants, de décharger les logs détaillés vers Elasticsearch pour un contexte à long terme et d'utiliser la récupération pour retrouver tout élément pertinent en cas de besoin.
Comme indiqué ici, le principe directeur est que le contexte est une ressource limitée et précieuse. Vous souhaitez que chaque élément de l'invite soit utile, c'est-à-dire qu'il contribue à la qualité de la sortie. Si quelque chose en mémoire ne joue pas son rôle (ou pire, provoque activement de la confusion), alors il devrait être élagué, résumé ou tenu à l'écart.
En tant que développeurs, nous pouvons désormais programmer le contexte comme nous programmons du code, en décidant quelles informations inclure, comment les formater et quand les omettre ou les mettre à jour. En suivant ces pratiques, nous pouvons fournir aux agents LLM le contexte indispensable pour effectuer des tâches sans être victimes des modes de défaillance décrits précédemment. Le résultat : des agents qui retiennent ce qu’ils doivent, oublient ce qui leur est inutile et récupèrent ce dont ils ont besoin juste à temps.
Conclusion
La mémoire n'est pas quelque chose que l'on ajoute à un agent, c'est quelque chose que l'on développe. La mémoire à court terme est le bloc-notes de travail de l'agent, et la mémoire à long terme est son stock de connaissances durable. RAG est le pont entre les deux, transformant un datastore passif, comme Elasticsearch, en un mécanisme de rappel actif qui peut ancrer les sorties et maintenir l'agent à jour.
Mais la mémoire est une arme à double tranchant. Dès que vous laissez le contexte se développer sans contrôle, vous invitez l'empoisonnement, la distraction, la confusion et les conflits, et dans les systèmes partagés, même des fuites de données. C’est pourquoi le travail de mémoire le plus important n’est pas de « stocker davantage », mais de « mieux sélectionner » : récupérer de manière sélective, élaguer avec rigueur, résumer avec soin et éviter de mélanger des contextes non liés, sauf si la tâche l’exige réellement.
En pratique, une bonne ingénierie du contexte ressemble à une bonne conception de systèmes : des contextes plus petits et suffisants, des interfaces contrôlées entre les composants, et une séparation claire entre l'état brut et l'état distillé que vous voulez réellement que le modèle voie. Si l'on procède correctement, on ne se retrouve pas avec un agent qui se souvient de tout, mais avec un agent qui se souvient des bonnes choses, au bon moment et pour la bonne raison.
Pour aller plus loin

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.
17 mars 2026
L'extension Gemini CLI pour Elasticsearch avec des outils et des fonctionnalités
Présentation de l’extension Elastic pour le CLI Gemini de Google, afin de rechercher, récupérer et analyser les données Elasticsearch dans les workflows des développeurs et des agents.