En la disciplina emergente de ingeniería de contexto, proporcionar a los agentes de IA la información correcta en el momento adecuado es crucial. Uno de los aspectos más importantes de la ingeniería de contexto es gestionar la memoria de una IA. Al igual que los seres humanos, los sistemas de IA dependen tanto de la memoria a corto plazo como de la memoria a largo plazo para recordar información. Si queremos que los agentes de grandes modelos de lenguaje (LLM) mantengan conversaciones lógicas, recuerden las preferencias del usuario o construyan sobre resultados o respuestas previas, necesitamos equiparlos con mecanismos de memoria efectivos.
Después de todo, todo en el contexto influye en las respuestas de la IA. Es cierto lo que dicen: "Lo que das es lo que recibes".
En este artículo, presentaremos lo que significan la memoria a corto y a largo plazo para los agentes de IA, específicamente:
- La diferencia entre la memoria a corto y a largo plazo.
- Cómo se relacionan con las técnicas de RAG con bases de datos vectoriales, como Elasticsearch, y por qué es necesaria una gestión cuidadosa de la memoria.
- Los riesgos de descuidar la memoria, como el desbordamiento de contexto y el envenenamiento por contexto.
- Las mejores prácticas, como podar el contexto, resumir y recuperar solo lo relevante, para mantener la memoria de un agente útil y segura.
- Finalmente, hablaremos sobre cómo compartir y propagar la memoria en sistemas multiagente para que los agentes colaboren sin confusión mediante Elasticsearch.
Memoria a corto plazo frente a memoria a largo plazo en los agentes de IA
La memoria a corto plazo en un agente de IA suele referirse al contexto o estado conversacional inmediato, es decir, al historial de chat actual o a los mensajes recientes de la sesión activa. Esto incluye la última consulta del usuario y los intercambios recientes. Es muy similar a la información que una persona tiene en mente durante una conversación.
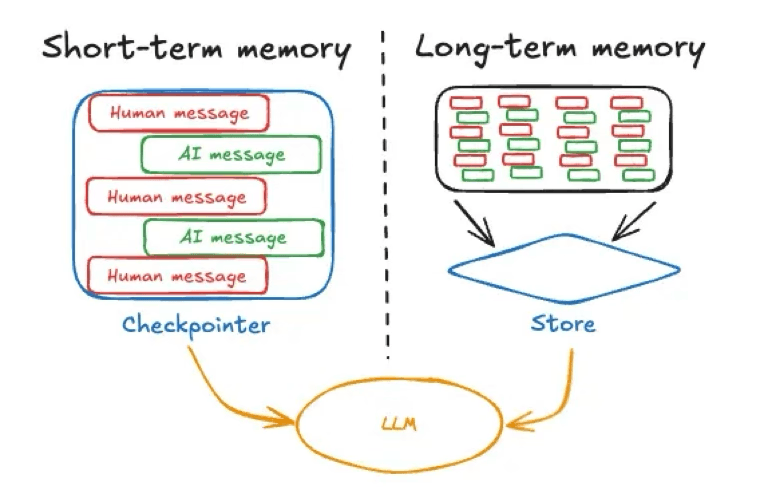
Fuente de la imagen: https://langchain.ai.github.io/langgraphjs/concepts/memory
Los marcos de trabajo de IA suelen mantener esta memoria transitoria como parte del estado del agente (por ejemplo, al utilizar un checkpointer para almacenar el estado de la conversación, como se muestra en este ejemplo de LangGraph). La memoria a corto plazo es de sesión; es decir, existe dentro de una sola conversación o tarea y se restablece o borra cuando esa sesión termina, a menos que se guarde explícitamente en otro lugar. Un ejemplo de memoria a corto plazo limitada a sesiones sería el chat temporal disponible en ChatGPT.
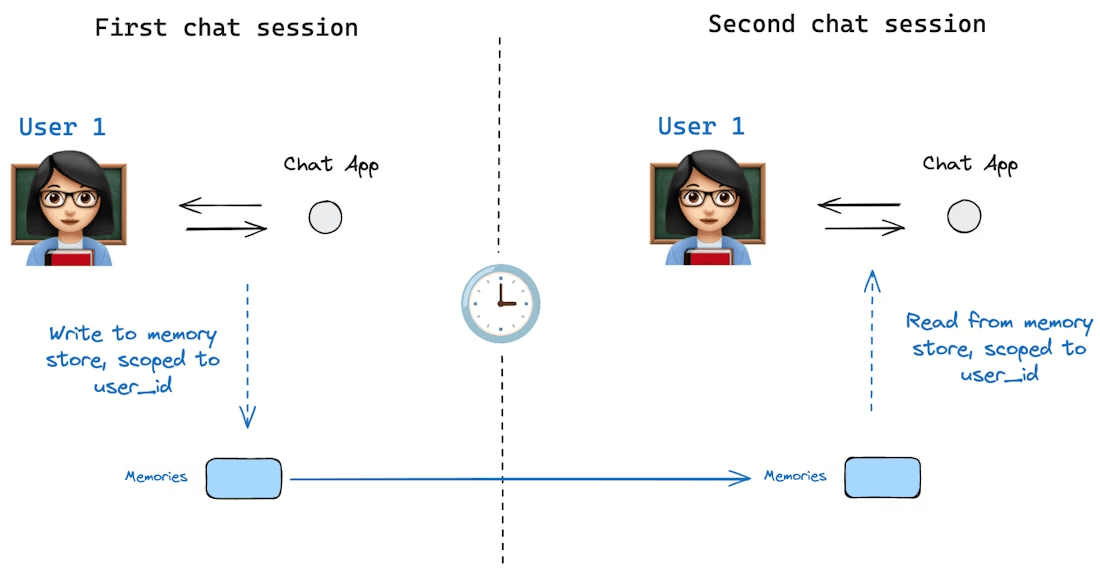
Fuente de la imagen: https://docs.langchain.com/oss/python/langgraph/persistence#memory-store
Memoria a largo plazo, por otro lado, se refiere a la información que persiste a través de conversaciones o sesiones. Este es el conocimiento que un agente conserva a lo largo del tiempo, los datos que aprendió antes, las preferencias del usuario o cualquier dato que le hayamos dicho que recuerde permanentemente.
La memoria a largo plazo generalmente se implementa almacenándola y recuperándola de una fuente externa, como un archivo o una base de datos vectorial que está fuera de la ventana de contexto inmediata. A diferencia de la memoria de chat a corto plazo, la memoria a largo plazo no se incluye automáticamente en cada solicitud. En cambio, basado en un escenario dado, el agente debe recuperarla u obtenerla cuando se invocan las herramientas relevantes. En la práctica, la memoria a largo plazo puede incluir la información del perfil del usuario, respuestas o análisis previos realizados por el agente, o una base de conocimientos que el agente puede consultar.
Por ejemplo, si tienes un agente planificador de viajes, la memoria a corto plazo contendría detalles de la consulta actual del viaje (fechas, destino, presupuesto) y cualquier pregunta de seguimiento en esa conversación; mientras que la memoria a largo plazo podría almacenar las preferencias generales de viaje del usuario, itinerarios pasados y otros datos compartidos en sesiones anteriores. Cuando el usuario regresa más tarde, el agente puede extraer de este almacenamiento a largo plazo (por ejemplo, al usuario le encantan las playas y las montañas, tiene un presupuesto promedio de 100 000 INR, tiene una lista de deseos de lugares para visitar y prefiere experimentar la historia y la cultura en lugar de atracciones para niños) de modo que no trate al usuario como una pizarra en blanco todo el tiempo.
La memoria a corto plazo (historial de chat) proporciona un contexto inmediato y continuidad, mientras que la memoria a largo plazo proporciona un contexto más amplio del que el agente puede extraer cuando sea necesario. La mayoría de los marcos de trabajo de agentes de IA avanzados permiten ambas posibilidades: realizan un seguimiento de los diálogos recientes para mantener el contexto y ofrecen mecanismos para buscar o almacenar información en un repositorio a más largo plazo. La gestión de la memoria a corto plazo garantiza que se mantenga dentro de la ventana de contexto, mientras que la gestión de la memoria a largo plazo ayuda al agente a fundamentar las respuestas basadas en interacciones previas y personalidades.
Memoria y RAG en ingeniería de contexto
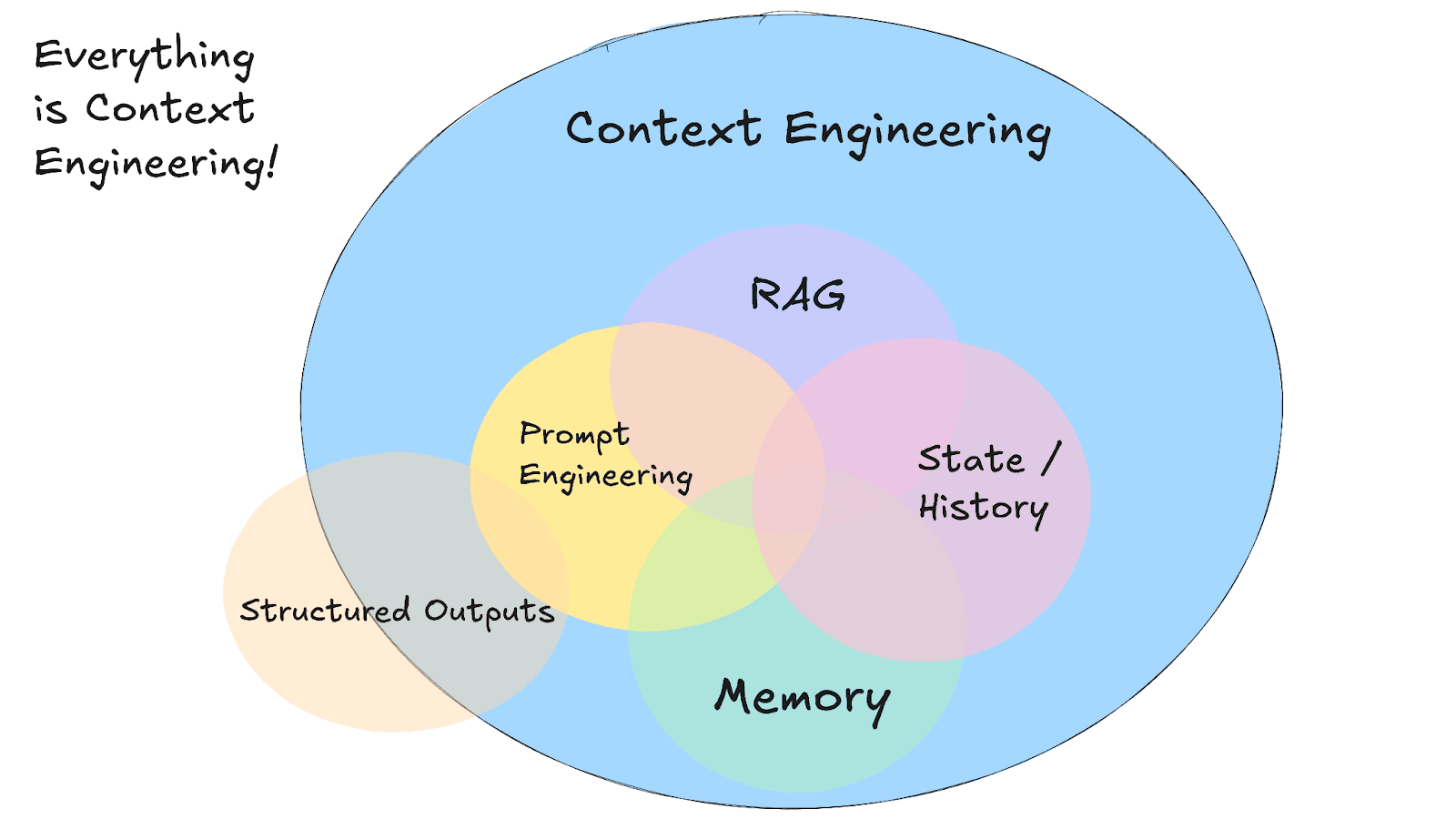
Fuente de la imagen: https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-03-own-your-context-window.md
¿Cómo le damos a un agente de IA una memoria útil a largo plazo en la práctica?
Un enfoque destacado para la memoria a largo plazo es la memoria semántica, que a menudo se implementa mediante generación aumentada de recuperación (RAG). Esto implica acoplar el LLM con una tienda de conocimiento externa o un almacén de datos habilitado para vectores, como Elasticsearch. Cuando el LLM necesita información más allá de lo que aparece en el prompt o en su entrenamiento integrado, realiza una recuperación semántica contra Elasticsearch e inyecta los resultados más relevantes en el prompt como contexto. De esta manera, el contexto efectivo del modelo incluye no solo la conversación reciente (memoria a corto plazo), sino también datos pertinentes a largo plazo que se obtienen sobre la marcha. A continuación, el LLM basa su respuesta tanto en su propio razonamiento como en la información recuperada, combinando eficazmente la memoria a corto plazo y la memoria a largo plazo para producir una respuesta más precisa y consciente del contexto.
Elasticsearch puede emplearse para implementar memoria a largo plazo para agentes de IA. Aquí hay un ejemplo de alto nivel de cómo se puede recuperar el contexto de Elasticsearch para la memoria a largo plazo.
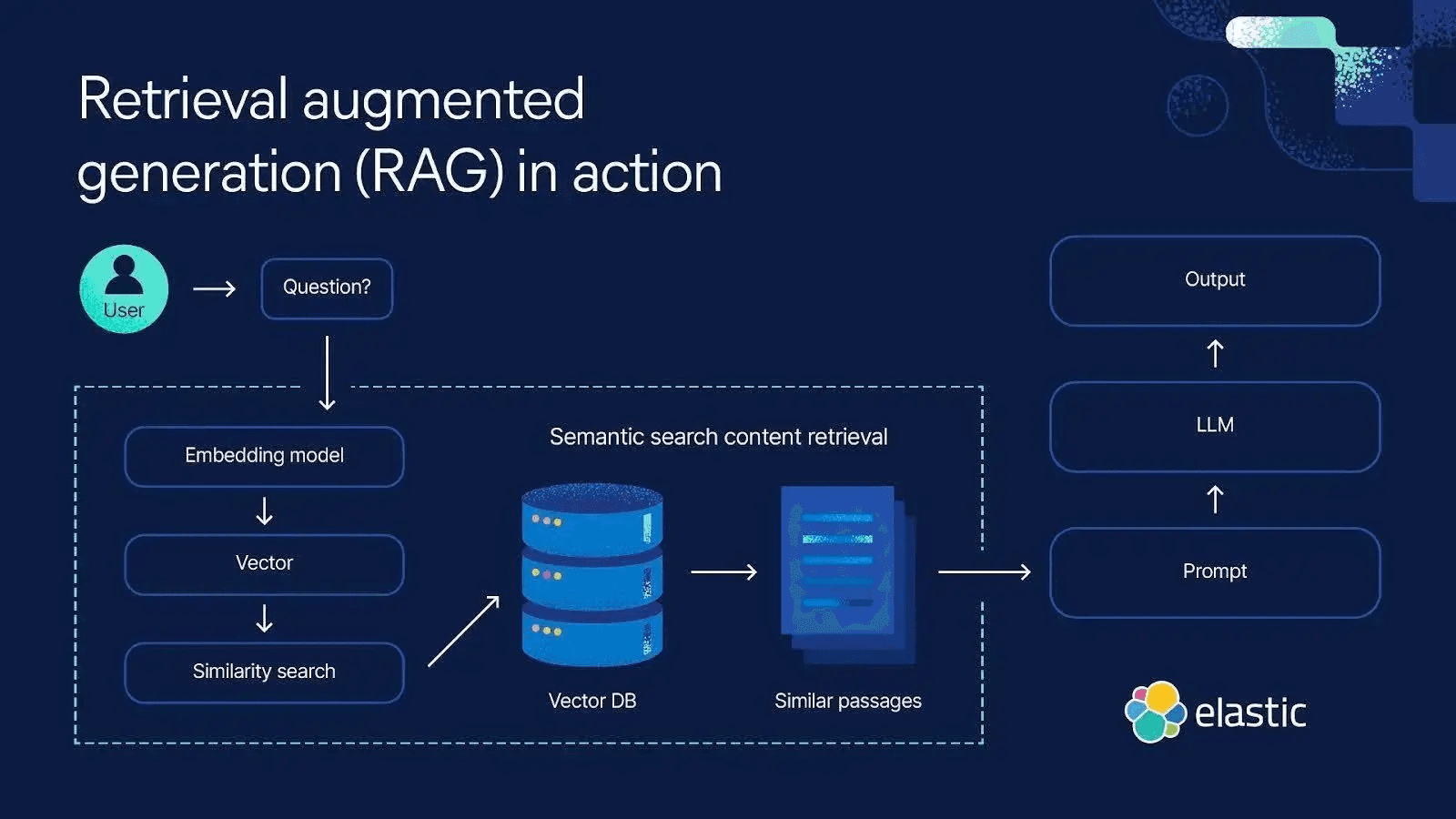
De esta manera, el agente "recuerda" al buscar datos relevantes en lugar de almacenar todo en su limitado prompt, lo que conduce a diferentes riesgos.
Usar RAG con Elasticsearch o cualquier almacén vectorial ofrece múltiples beneficios:
Primero, amplía el conocimiento del modelo más allá de su límite de entrenamiento. El agente puede recuperar información actualizada o datos específicos del dominio que el LLM podría desconocer. Esto es crucial para preguntas sobre eventos recientes o temas especializados.
Segundo, obtener contexto bajo demanda ayuda a reducir las alucinaciones, especialmente porque los LLM no están capacitados con datos propietarios o altamente especializados en relación con tu caso de uso específico, lo que probablemente los exponga a alucinaciones. En lugar de que el LLM adivine o invente nueva información como se incentivó mediante la evaluación, como se destaca en un reciente artículo de OpenAI (Por qué alucinan los modelos de lenguaje), el modelo puede basarse en referencias factuales de Elasticsearch. Naturalmente, el LLM depende de la fiabilidad de los datos almacenados en el vector para realmente prevenir la desinformación, y los datos relevantes se recuperan según las medidas de relevancia de núcleo.
Tercero, la RAG permite que un agente trabaje con bases de conocimientos mucho más grandes de lo que podrías incluir en un prompt. En lugar de enviar documentos completos, como largos trabajos de investigación o documentos de políticas, a la ventana de contexto y correr el riesgo de que la sobrecarga o el contexto de información irrelevante envenene el razonamiento del modelo, la RAG se basa en la fragmentación. Los documentos grandes se dividen en piezas más pequeñas y semánticamente significativas, y el sistema recupera solo los fragmentos más relevantes para la consulta. De esta manera, el modelo no necesita un contexto de un millón de tokens para parecer conocedor; solo necesita acceso a los fragmentos correctos de un corpus mucho más grande.
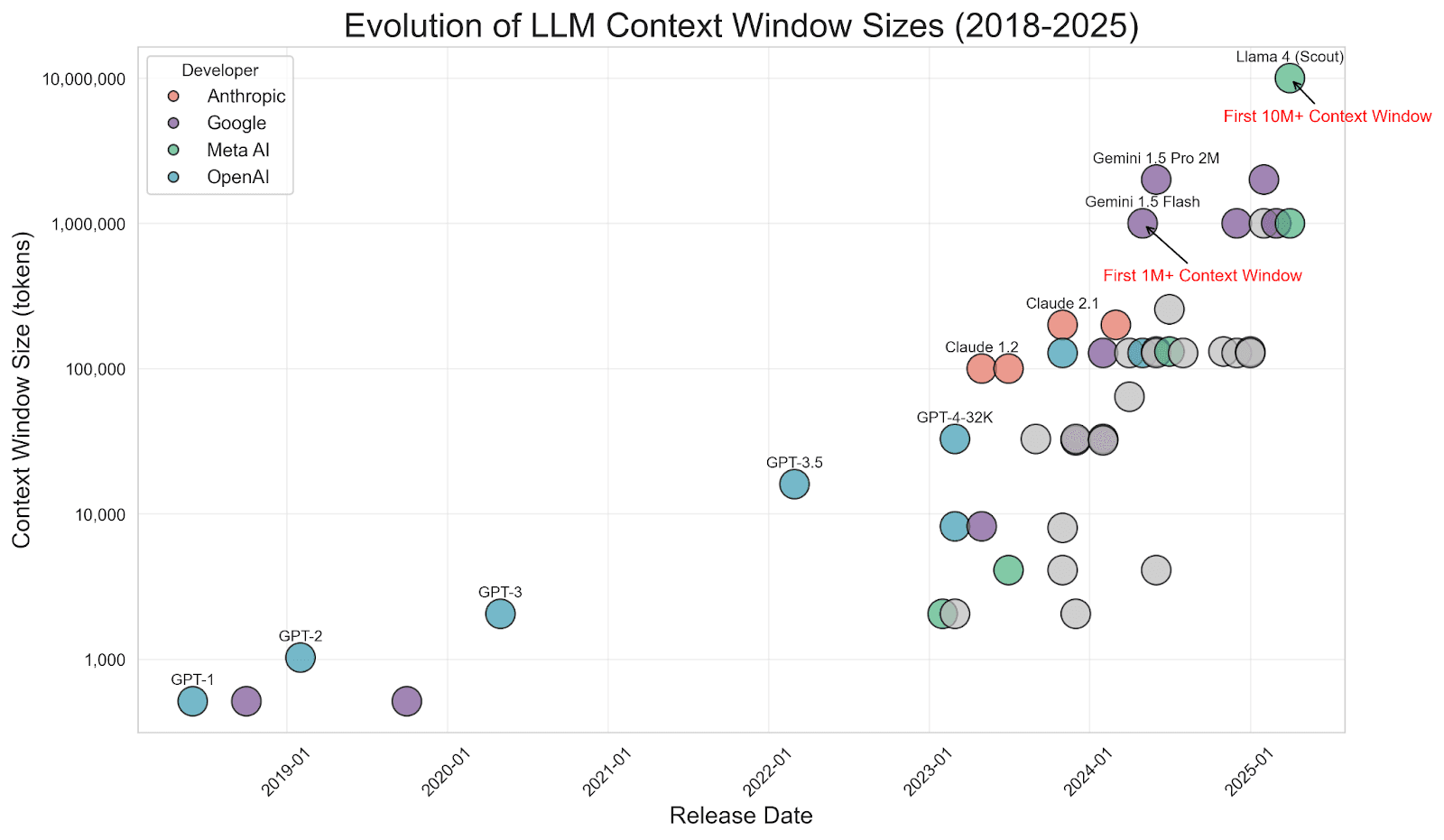
Fuente de la imagen: https://www.meibel.ai/post/understanding-the-impact-of-increasing-llm-context-windows
Vale la pena señalar que, a medida que las ventanas de contexto de LLM crecieron (algunos modelos ahora admiten cientos de miles o incluso millones de tokens), surgió un debate sobre si la RAG está "muerta". ¿Por qué no enviar todos los datos al prompt? Si te preguntas lo mismo, consulta este maravilloso artículo de mis colegas, Jeffrey Rengifo y Eduard Martin, Contexto más largo ≠ mejor: Por qué la RAG sigue siendo importante. Esto evita el problema de la "Lo que das es lo que recibes": El LLM se mantiene enfocado en los pocos fragmentos que importan, en lugar de ejecutarse a través del ruido.
Dicho esto, integrar Elasticsearch o cualquier almacén vectorial en una arquitectura de agente de IA proporciona memoria a largo plazo. El agente almacena el conocimiento externamente y lo recupera como contexto de memoria cuando es necesario. Esto se podría implementar como una arquitectura, en la que, tras cada consulta de usuario, el agente realiza una búsqueda en Elasticsearch para obtener información relevante y luego agrega los primeros resultados al prompt antes de llamar al LLM. La respuesta también podría guardarse en el almacén a largo plazo si contiene nueva información útil (lo que crea un bucle de retroalimentación de aprendizaje). Al usar una memoria basada en recuperación, el agente se mantiene informado y actualizado, sin tener que abarrotar todo lo que sabe en cada solicitud, a pesar de que la ventana de contexto admite un millón de tokens. Esta técnica es una piedra angular de la ingeniería de contexto, ya que combina las ventajas de la recuperación de información y la IA generativa.
Aquí hay un ejemplo de un estado de conversación gestionado en memoria usando el sistema de puntos de control de LangGraph para la memoria a corto plazo durante la sesión. (Consulta nuestra app de ingeniería de contexto de apoyo).
Así es como almacena los puntos de control:
Para la memoria a largo plazo, así es como realizamos la búsqueda semántica en Elasticsearch para recuperar conversaciones previas relevantes usando embeddings vectoriales tras resumir e indexar los puntos de control en Elasticsearch.
Ahora que hemos explorado cómo se indexan y recuperan la memoria a corto y largo plazo usando los puntos de control de LangGraph en Elasticsearch, tomemos un momento para entender por qué indexar y eliminar las conversaciones completas puede ser riesgoso.
Riesgos de no gestionar la memoria de contexto
Como hablamos mucho sobre ingeniería de contexto, junto con la memoria a corto y largo plazo, entendamos qué sucede si no gestionamos bien la memoria y el contexto de un agente.
Desafortunadamente, muchas cosas pueden salir mal cuando el contexto de una IA se vuelve extremadamente largo o contiene información errónea. A medida que las ventanas de contexto se agrandan, surgen nuevos tipos de falla, como:
- Envenenamiento por contexto
- Distracción del contexto
- Confusión de contexto
- Choque de contexto
- Fuga de contexto y conflictos de conocimiento
- Alucinaciones e información errónea
Hagamos un desglose de estos problemas y otros riesgos que surgen de una mala gestión del contexto:
Envenenamiento por contexto
El envenenamiento por contexto se refiere a cuando la información incorrecta o dañina termina en el contexto y "envenena" las salidas posteriores del modelo. Un ejemplo común es una alucinación del modelo que se trata como un hecho y se inserta en el historial de conversaciones. El modelo podría entonces aprovechar ese error en respuestas posteriores, lo que agravaría el error. En los bucles iterativos de agentes, una vez que una información falsa se introduce en el contexto compartido (por ejemplo, en un resumen de las notas de trabajo del agente), puede reforzarse una y otra vez.
Los investigadores de DeepMind, en la publicación del reporte Gemini 2.5 (TL;DR, consulta aquí), observaron esto en un agente que jugaba a Pokémondesde hacía mucho tiempo: si el agente alucinaba un estado de juego erróneo y eso quedaba registrado en su contexto (su memoria de objetivos), el agente formaba estrategias sin sentido en torno a un objetivo imposible y se quedaba atascado. En otras palabras, un recuerdo contaminado puede llevar al agente por el camino equivocado de forma indefinida.
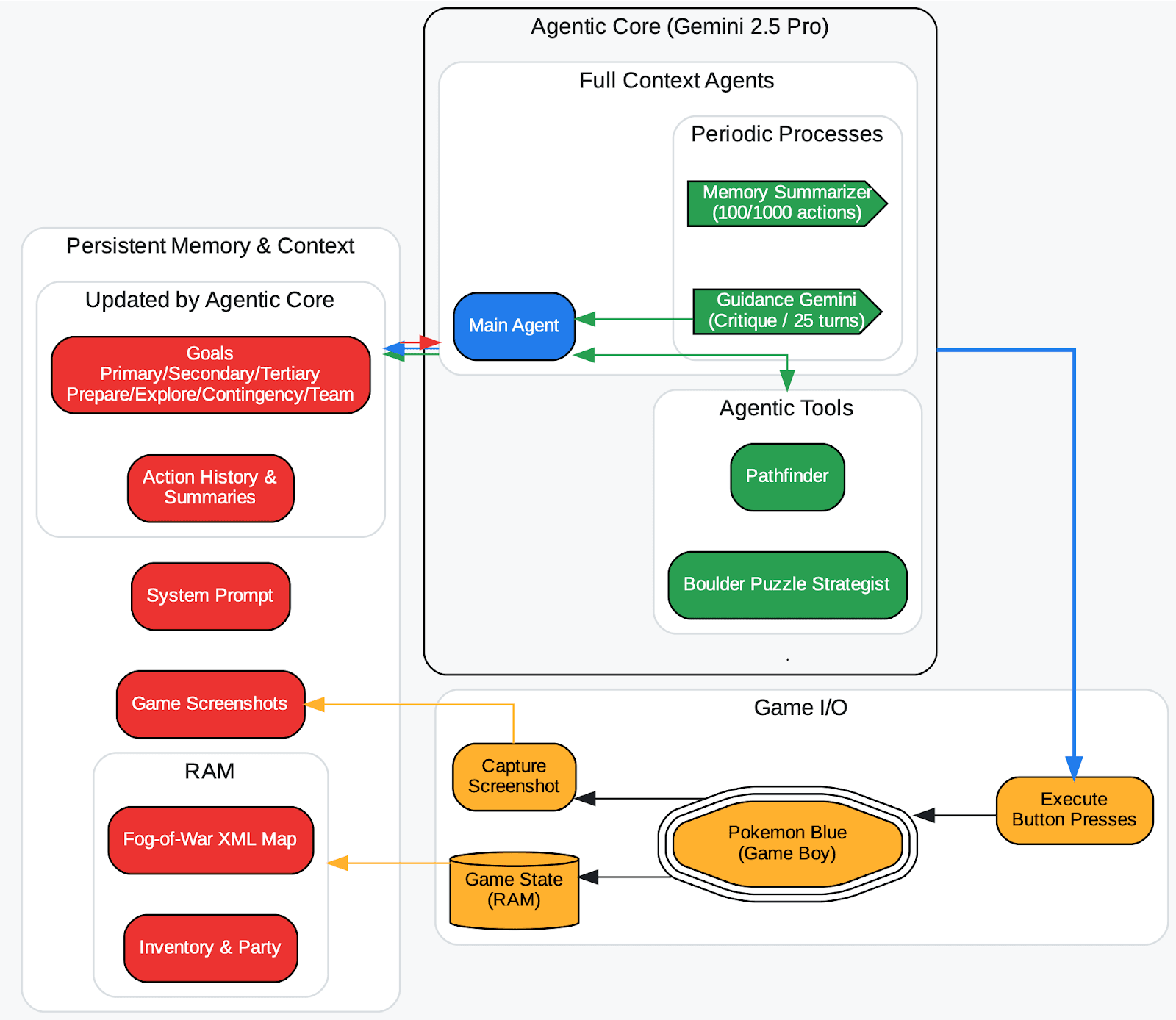
Una visión general del arnés del agente (Zhang, 2025). El mapa de niebla de guerra del mundo superior almacena automáticamente un mosaico una vez explorado y lo etiqueta con un contador de visitas. El tipo de mosaico se registra desde la RAM. Las herramientas agenticas (pathfinder, boulder_puzzle_strategist) son instancias activadas de Gemini 2.5 Pro. pathfinder se usa para navegación y boulder_puzzle_strategist resuelve rompecabezas de roca en la mazmorra de Victory Road.
Fuente de la imagen: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - página 68.
El envenenamiento del contexto puede ocurrir de forma inocente (por error) o incluso maliciosa, por ejemplo, mediante ataques de inyección de prompt donde un usuario o un tercero introduce una instrucción oculta o un hecho falso que el agente luego recuerda y sigue.
Contramedidas recomendadas:
Basándose en la información de Wiz, Zerlo y Anthropic, las contramedidas para el envenenamiento del contexto se centran en prevenir que la información errónea o engañosa entre en la ventana de contexto, el pipeline de recuperación o la ventana de contexto de un LLM. Los pasos clave incluyen:
- Revisa el contexto constantemente: monitoriza la conversación o el texto recuperado para detectar cualquier cosa sospechosa o dañina, no solo el prompt inicial.
- Utiliza fuentes confiables: Puntúa o etiqueta los documentos según su credibilidad para que el sistema prefiera la información confiable e ignore los datos con baja puntuación.
- Detecta datos inusuales: usa herramientas que detecten contenido extraño, fuera de lugar o manipulado, y elimínalo antes de que el modelo lo use.
- Filtra entradas y salidas: Añade salvaguardas para que el texto dañino o engañoso no pueda entrar fácilmente en el sistema ni ser repetido por el modelo.
- Mantén el modelo actualizado con datos limpios: actualiza regularmente el sistema con información verificada para contrarrestar cualquier dato incorrecto que haya pasado desapercibido.
- Intervención humana: Haz que las personas revisen las salidas importantes o las comparen con fuentes conocidas y confiables.
Los hábitos sencillos de los usuarios también ayudan, como restablecer los chats largos, compartir solo información relevante, dividir las tareas complejas en pasos más pequeños y mantener notas claras fuera del modelo.
En conjunto, estas medidas crean una defensa en capas que protege a los LLMs del envenenamiento del contexto y mantiene las salidas precisas y fiables.
Sin contramedidas como las mencionadas aquí, un agente podría recordar instrucciones, como ignorar directrices previas o datos triviales que un atacante introdujo, lo que podría provocar salidas dañinas.
Distracción del contexto
Distracción por contexto es cuando un contexto crece tanto que el modelo se sobreenfoca en el contexto, y descuida lo que aprendió durante el entrenamiento. En casos extremos, esto se asemeja al olvido catastrófico; es decir, el modelo efectivamente "olvida" su conocimiento subyacente y se apega demasiado a la información colocada frente a él. Estudios previos han demostrado que los LLM a menudo pierden el enfoque cuando la solicitud es extremadamente larga.
El agente Gemini 2.5, por ejemplo, admitía una ventana de un millón de tokens, pero una vez que su contexto creció más allá de cierto punto (del orden de 100 000 tokens en un experimento), comenzó a fijarse en repetir sus acciones pasadas en lugar de encontrar nuevas soluciones. En cierto sentido, el agente se convirtió en prisionero de su extensa historia. Siguió mirando su largo log de movimientos anteriores (el contexto) e imitándolos, en lugar de usar su conocimiento de entrenamiento subyacente para diseñar estrategias nuevas y novedosas.

Fuente de la imagen: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - página 18.
Esto es contraproducente. Queremos que el modelo emplee el contexto relevante para ayudar al razonamiento, no para anular su capacidad de pensamiento. Cabe destacar que incluso los modelos con ventanas enormes presentan esta podredumbre contextual: su rendimiento se degrada de forma no uniforme a medida que se agregan más tokens. Parece haber un presupuesto de atención. Al igual que los humanos con memoria de trabajo limitada, un LLM tiene una capacidad finita para atender a los tokens, y a medida que ese presupuesto se estira, su precisión y enfoque disminuyen.
Como medida de mitigación, puedes prevenir la distracción del contexto usando fragmentación, ingeniería de la información correcta, resumen regular del contexto y técnicas de evaluación y seguimiento para medir la precisión de la respuesta mediante puntaje.
Estos métodos mantienen el modelo basado tanto en el contexto relevante como en su entrenamiento subyacente, lo que reduce el riesgo de distracción y mejora la calidad general del razonamiento.
Confusión de contexto
La confusión de contexto ocurre cuando el modelo emplea contenido superfluo en el contexto para generar una respuesta de baja calidad. Un ejemplo claro es dar a un agente un gran conjunto de herramientas o definiciones de API que podría emplear. Si muchas de esas herramientas no están relacionadas con la tarea actual, el modelo puede intentar usarlas de forma inapropiada, simplemente porque están presentes en contexto. Los experimentos demostraron que proporcionar más herramientas o documentos puede perjudicar el rendimiento si no se necesitan todos. El agente empieza a cometer errores, como llamar a la función equivocada o referenciar texto irrelevante.
En un caso, un pequeño modelo Llama 3.1 8B falló en una tarea cuando se le dieron 46 herramientas para considerar, pero tuvo éxito cuando se le dieron solo 19 herramientas. Las herramientas adicionales crearon confusión, a pesar de que el contexto se ajustaba a los límites de longitud. El problema subyacente es que cualquier información en el mensaje será atendida por el modelo. Si no sabe ignorar algo, ese algo podría influir en su salida de maneras no deseadas. Los elementos irrelevantes pueden "robar" parte de la atención del modelo y llevarlo por el camino equivocado (por ejemplo, un documento irrelevante podría hacer que el agente responda a una pregunta diferente a la que se le hizo). La confusión contextual a menudo se manifiesta cuando el modelo produce una respuesta de baja calidad que integra contextos no relacionados. Consulta el artículo de investigación: Menos es más: optimización de la llamada de funciones para la ejecución de LLM en dispositivos periféricos.
Nos recuerda que más contexto no siempre es mejor, especialmente si no está curado para que sea relevante.
Choque de contexto
Choque de contexto ocurre cuando partes del contexto se contradicen entre sí, lo que causa inconsistencias internas que desvían el razonamiento del modelo. Puede producir un choque si el agente acumula múltiples piezas de información que están en conflicto.
Por ejemplo, imagina un agente que obtuvo datos de dos fuentes: una dice que el vuelo A sale a las 5 p. m. y la otra dice que el vuelo A sale a las 6 p. m. Si ambos hechos terminan en el contexto, el pobre modelo no tiene forma de saber cuál es el correcto; puede confundirse o producir una respuesta incorrecta o no similar.
El choque de contexto también ocurre frecuentemente en conversaciones de múltiples turnos donde los intentos anteriores del modelo de responder todavía persisten en el contexto junto con información refinada posterior.

Fuente de la imagen: Los LLM se pierden en la conversación de múltiples turnos (Página 04)
Un estudio de investigación realizado por Microsoft y Salesforce muestra que si divides una consulta compleja en múltiples turnos de chatbot (agregando detalles gradualmente), la precisión final disminuye significativamente, en comparación con dar todos los detalles en un solo mensaje. ¿Por qué? Porque las primeras vueltas contienen respuestas intermedias parciales o incorrectas del modelo, y estas permanecen en el contexto. Cuando el modelo luego intenta responder con toda la información, su memoria aún incluye esos intentos incorrectos, que entran en conflicto con la información corregida y lo desvían del camino. Básicamente, el contexto de la conversación entra en conflicto consigo mismo. El modelo puede usar inadvertidamente una pieza de contexto desactualizada (de un turno anterior) que no se aplica después de que se agrega nueva información.
En los sistemas de agentes, el choque de contexto es especialmente peligroso porque un agente puede combinar las salidas de diferentes herramientas o subagentes. Si esas salidas no coinciden, el contexto agregado es inconsistente. El agente podría entonces quedarse atascado o producir resultados absurdos al tratar de conciliar las contradicciones. La prevención del choque de contexto implica asegurarse de que el contexto sea fresco y consistente, por ejemplo, borrar o actualizar cualquier información obsoleta y no mezclar fuentes que no hayan sido objeto de un estudio de consistencia.
Fuga de contexto y conflictos de conocimiento
En los sistemas en los que varios agentes o usuarios comparten un almacén de memoria, existe el riesgo de que la información se filtre entre contextos.
Por ejemplo, si las incrustaciones de datos de dos usuarios distintos residen en la misma base de datos vectorial sin un control de acceso adecuado, un agente que responda a la consulta del usuario A podría recuperar accidentalmente parte de la memoria del usuario B. Esta fuga entre contextos puede exponer información privada o simplemente crear confusión en las respuestas.
Según el Top 10 de OWASP para aplicaciones LLM, las bases de datos vectoriales de usuarios múltiples deben protegerse contra este tipo de fugas:
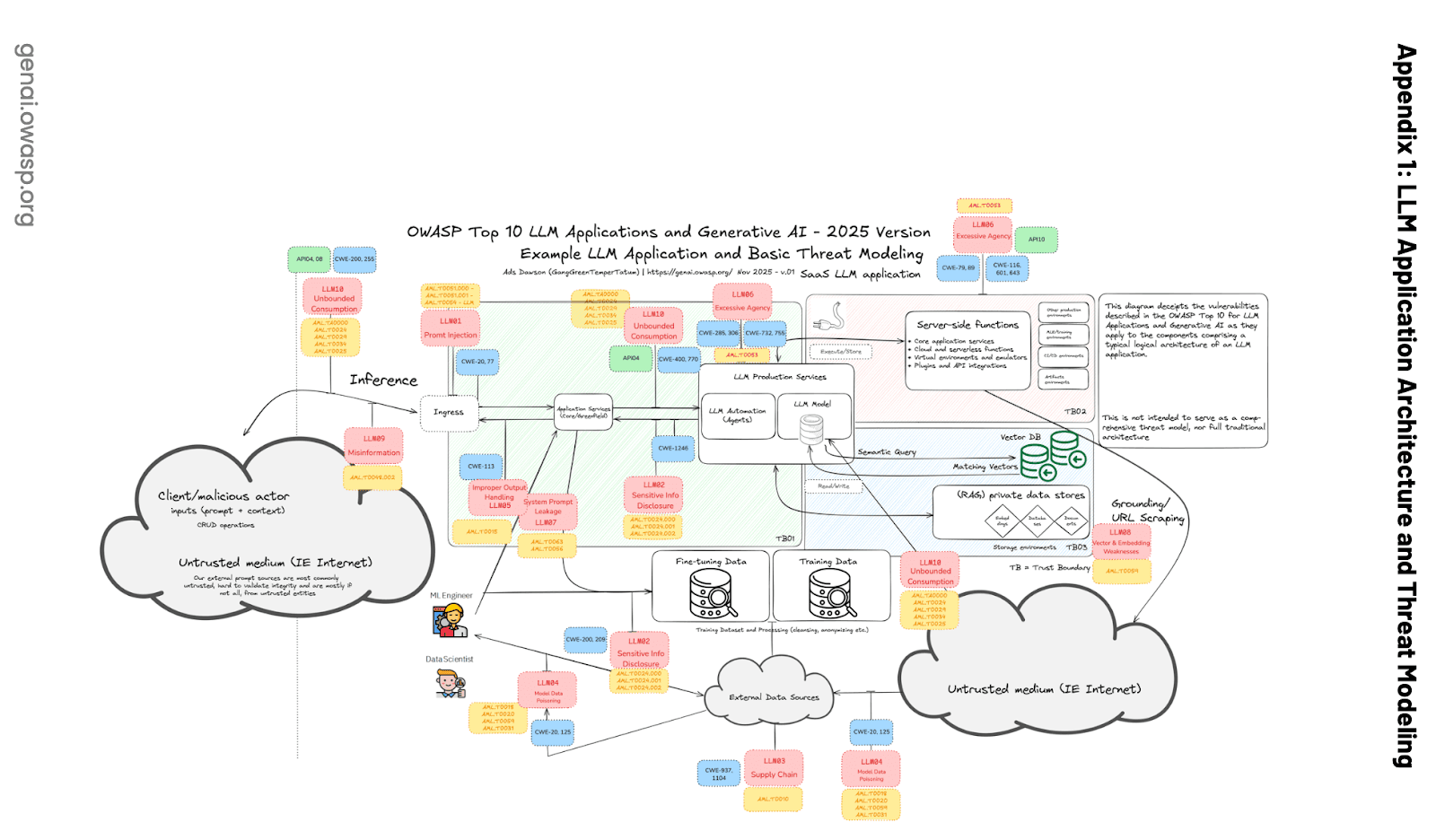
Fuente de la imagen: https://wtit.com/blog/2025/04/17/owasp-top-10-for-llm-applications-2025
Según LLM08:2025 Debilidades de Vectores y Embedding, uno de los riesgos comunes es la fuga de contexto:
En entornos de múltiples usuarios donde varias clases de usuarios o aplicaciones comparten la misma base de datos vectorial, existe el riesgo de pérdida de contexto entre usuarios o consultas. Los errores de conflicto de conocimiento en la federación de datos pueden ocurrir cuando los datos de múltiples fuentes se contradicen entre sí. Esto también puede suceder cuando un LLM no puede reemplazar el conocimiento antiguo que aprendió durante el entrenamiento con los nuevos datos de generación aumentada.
Otro aspecto es que un LLM podría tener problemas para anular su conocimiento integrado con nueva información de memoria. Si el modelo fue entrenado con algún hecho y el contexto recuperado dice lo contrario, el modelo puede confundirse sobre cuál confiar. Sin un diseño adecuado, el agente podría confundir contextos o no actualizar el conocimiento antiguo con nueva evidencia, lo que llevaría a respuestas obsoletas o incorrectas.
Alucinaciones e información errónea
Mientras que una alucinación (el LLM inventa información plausible pero falsa) es un problema conocido incluso sin contextos largos, una mala gestión de la memoria puede amplificarlo.
Si la memoria del agente carece de un hecho crucial, el modelo puede llenar el vacío con una suposición, y si esa suposición entra en el contexto (envenenándolo), el error persiste.
El informe de seguridad de los LLM OWASP (LLM09:2025 Desinformación) destaca la desinformación como una vulnerabilidad de núcleo: los LLM pueden ofrecer respuestas seguras pero fabricadas, y los usuarios pueden confiar demasiado en ellos. Un agente con una memoria a largo plazo deficiente o desactualizada podría citar con confianza algo que era cierto el año pasado pero que ahora es falso, a menos que su memoria se mantenga actualizada.
La dependencia excesiva en la salida de la IA (ya sea por parte de los usuarios o del propio agente en un bucle) puede empeorar esta situación. Si nadie revisa nunca la información almacenada en la memoria, el agente puede acumular falsedades. Esta es la razón por la que la RAG se usa a menudo para reducir las alucinaciones: al recuperar una fuente autorizada, el modelo no tiene que inventar hechos. Pero si tu recuperación trae el documento incorrecto (digamos, uno que contiene información errónea) o si una alucinación temprana no se poda, el sistema puede propagar esa información errónea a través de sus acciones.
La conclusión: no administrar la memoria puede conducir a salidas incorrectas y engañosas, lo que puede ser perjudicial, especialmente si hay mucho en juego (por ejemplo, malos consejos en un dominio financiero o médico). Un agente necesita mecanismos para verificar o corregir su contenido de memoria, no solo confiar incondicionalmente en lo que esté en el contexto.
En resumen, darle a un agente de IA una memoria infinitamente larga o volcar cada cosa posible en su contexto no es una receta para el éxito.
Mejores prácticas para la gestión de memoria en aplicaciones LLM
Para evitar las trampas anteriores, los desarrolladores e investigadores idearon una serie de mejores prácticas para administrar el contexto y la memoria en sistemas de IA. Estas prácticas tienen como objetivo mantener el contexto de trabajo de la IA ágil, relevante y actualizado. Aquí hay algunas de las estrategias clave, junto con ejemplos de cómo ayudan.
RAG: Utiliza un contexto específico.
Gran parte de la RAG ya se ha cubierto en la sección anterior, así que esto sirve como un conjunto conciso de recordatorios prácticos:
- Usa la recuperación dirigida, no la carga masiva: Recupera solo los fragmentos más relevantes en lugar de insertar documentos enteros o historiales de conversación completos en el prompt.
- Trata la RAG como una recuperación de memoria justo a tiempo: Obtén el contexto solo cuando sea necesario, en lugar de traer todo en cada turno.
- Prefiere estrategias de recuperación conscientes de la relevancia: enfoques como la búsqueda semántica top-k, la fusión de rango recíproco o el filtrado de carga de herramientas ayudan a reducir el ruido y mejorar la conexión a tierra.
- Las ventanas de contexto más grandes no eliminan la necesidad de RAG: dos párrafos muy relevantes son casi siempre más efectivos que 20 páginas poco relacionadas.
Dicho esto, la RAG no se trata de agregar más contexto; se trata de agregar el contexto adecuado.
Carga de herramientas
Configuración de herramientas se trata de darle a un modelo solo las herramientas que realmente necesita para una tarea. El término proviene de los juegos: Eliges un equipo que se ajuste a la situación. Demasiadas herramientas te ralentizan; las incorrectas causan fallas. Los LLM se comportan de la misma manera, según el documento de investigación Menos es más. Una vez que pasas de unas 30 herramientas, las descripciones empiezan a solaparse y el modelo se confunde. Después de ~100 herramientas, el fracaso está casi garantizado. Esto no es un problema de ventana de contexto, es confusión de contexto.
Una solución simple y efectiva es RAG-MCP. En lugar de poner todas las herramientas en el mensaje, las descripciones de las herramientas se almacenan en una base de datos vectorial y solo se recuperan las más relevantes por solicitud. En la práctica, esto permite mantener un equipamiento reducido y específico, acorta considerablemente los tiempos de respuesta y puede mejorar hasta tres veces la precisión en la selección de herramientas.
Los modelos más pequeños alcanzan este límite incluso antes. La investigación muestra que un modelo 8B falla con docenas de herramientas, pero tiene éxito una vez que se reduce la carga. La selección dinámica de herramientas, a veces con un LLM primero, razonando sobre lo que cree que necesita, puede aumentar el rendimiento en un 44%, al tiempo que reduce el uso de poder y la latencia. La clave es que la mayoría de los agentes solo necesitan unas pocas herramientas, pero a medida que tu sistema crece, la carga de herramientas y el RAG-MCP se convierten en decisiones de diseño de primer orden.
Poda de contexto: limita la duración del historial de chat
Si una conversación se prolonga durante muchos turnos, el historial de chat acumulado puede llegar a ser demasiado grande para caber, lo que provoca un desbordamiento del contexto o distrae demasiado al modelo.
Recortar significa eliminar o acortar programáticamente las partes menos importantes del diálogo a medida que crece. Una forma simple es descartar los turnos más antiguos de la conversación cuando alcanzas un cierto límite, manteniendo solo los últimos N mensajes. Una poda más sofisticada podría eliminar digresiones irrelevantes o instrucciones previas que ya no son necesarias. El objetivo es mantener la ventana de contexto despejada de noticias antiguas.
Por ejemplo, si el agente resolvió un subproblema hace 10 turnos y hemos seguido adelante desde entonces, podríamos eliminar esa parte del historial del contexto (asumiendo que ya no será necesaria). Muchas implementaciones basadas en chat hacen esto: mantienen una ventana móvil con los mensajes recientes.
Recortar puede ser tan simple como "olvidar" las primeras partes de una conversación una vez que se han resumido o se consideran irrelevantes. De esta manera, reducimos el riesgo de errores por exceso de contexto y también reducimos la distracción del contexto, por lo que el modelo no verá contenido antiguo o fuera de tema ni se distraerá con él. Este enfoque es muy similar a cómo los humanos podrían no recordar cada palabra de una charla de una hora, pero retendrán los puntos destacados.
Si tienes dudas acerca de la poda de contexto, como lo destaca el autor Drew Breunig aquí, el uso del modelo Provence (`naver/provence-reranker-debertav3-v1`), un podador de contexto ligero (1.75 GB), eficiente y preciso para la respuesta a preguntas, puede marcar la diferencia. Puedes reducir documentos grandes a solo el texto más relevante para una búsqueda determinada. Puedes llamarlo en intervalos específicos.
Así es como invocamos el modelo `provence-reranker` en nuestro código para podar el contexto:
Empleamos el modelo de reranking de Provenza (`naver/provence-reranker-debertav3-v1`) para calificar la relevancia de las oraciones. El filtrado basado en umbrales mantiene las oraciones por encima del umbral de relevancia. Además, introducimos un mecanismo de respaldo, donde volvemos al contexto original si la poda falla. Finalmente, el logging de estadísticas rastrea el porcentaje de reducción en el modo detallado.
Resumen de contexto: Condensa la información antigua en lugar de eliminarla por completo
El resumen es un complemento al recorte. Cuando la historia o la base de conocimientos se vuelve demasiado grande, puedes emplear el LLM para generar un breve resumen de los puntos importantes y usar ese resumen en lugar del contenido completo en el futuro, como realizamos en nuestro código anterior.
Por ejemplo, si un asistente de IA tuvo una conversación de 50 turnos, en lugar de enviar los 50 turnos al modelo en el turno 51 (que probablemente no encaje), el sistema podría tomar los turnos 1 a 40, hacer que el modelo los resuma en un párrafo y luego solo proporcionar ese resumen más los últimos 10 turnos en el siguiente mensaje. De esta manera, el modelo aún sabe lo que se discutió sin necesidad de conocer todos los detalles. Los primeros usuarios del chatbot lo hacían manualmente preguntando: "¿Puedes resumir lo que hablamos hasta ahora?" y luego continuaban en una nueva sesión con el resumen. Ahora se puede automatizar. El resumen no solo ahorra espacio en la ventana de contexto, sino que también puede reducir la confusión y distracción del contexto al eliminar detalles adicionales y conservar solo los hechos más importantes.
Aquí es cómo usamos los modelos de OpenAI (puedes usar cualquier LLM) para condensar el contexto a la vez que preservamos toda la información relevante, lo que elimina la redundancia y la duplicación.
Es importante destacar que cuando se resume el contexto, es menos probable que el modelo se vea abrumado por detalles triviales o errores pasados (suponiendo que el resumen sea exacto).
Sin embargo, el resumen debe hacerse con cuidado. Un mal resumen puede omitir un detalle crucial o incluso provocar un error. Es esencialmente otro mensaje para el modelo ("resume esto"), por lo que puede alucinar o perder matices. La mejor práctica es resumir de forma incremental y quizás mantener algunos hechos canónicos sin resumir.
No obstante, ha demostrado ser muy útil. En el escenario del agente Gemini, resumir el contexto cada ~100k tokens era una forma de contrarrestar la tendencia del modelo a repetir. El resumen actúa como una memoria comprimida de la conversación o los datos. Como desarrolladores, podemos implementar esto haciendo que un agente llame periódicamente a una función de resumen (tal vez un LLM más pequeño o una rutina dedicada) en el historial de la conversación o en un documento largo. El resumen resultante reemplaza el contenido original en el prompt. Esta táctica se utiliza ampliamente para mantener los contextos dentro de unos límites y sintetizar la información.
Cuarentena de contexto: aislar los contextos cuando sea posible
Esto es más relevante en sistemas de agentes complejos o flujos de trabajo de varios pasos. La idea de la segmentación del contexto es dividir una tarea grande en tareas más pequeñas e independientes, cada una con su propio contexto, para que nunca acumules un contexto enorme que lo contenga todo. Cada subagente o subtarea trabaja en una parte del problema con un contexto enfocado, y luego un agente de nivel superior, o supervisor o coordinador integra los resultados.
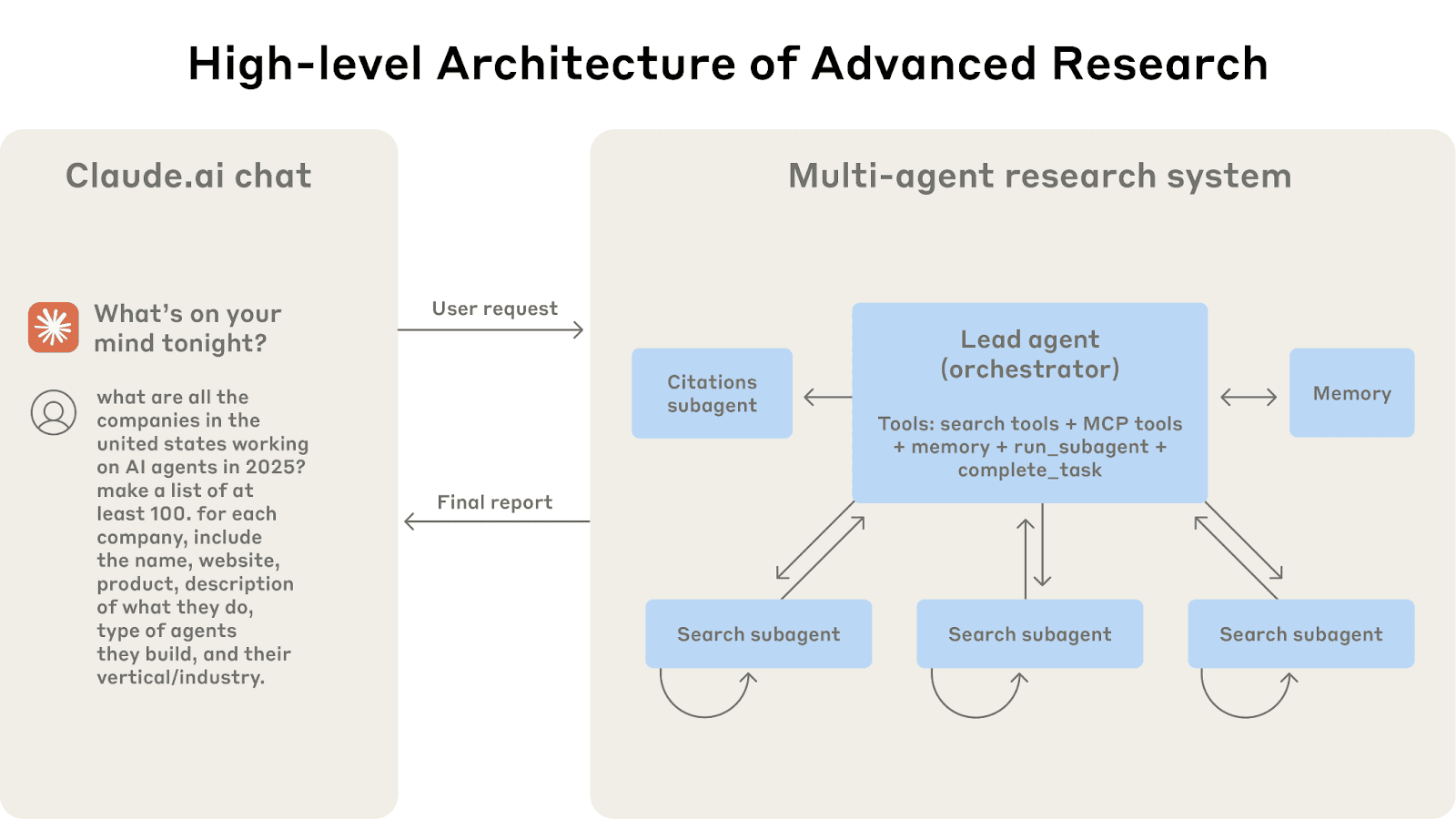
La arquitectura multiagente en acción: las consultas de los usuarios fluyen a través de un agente principal que crea subagentes especializados para la búsqueda de diferentes aspectos en paralelo.
Fuente de la imagen: https://www.anthropic.com/engineering/multi-agent-research-system
La estrategia de investigación de Anthropic emplea múltiples subagentes, cada uno investigando un aspecto diferente de una pregunta, con sus propias ventanas de contexto, y un agente principal que lee los resultados destilados de esos subagentes. Este enfoque paralelo y modular significa que ninguna ventana de contexto individual se vuelve demasiado voluminosa. También reduce la posibilidad de que se mezcle información irrelevante, cada hilo se mantiene en el tema (sin confusión de contexto) y no lleva equipaje innecesario al responder su subpregunta específica. En cierto sentido, es como ejecutar hilos separados de pensamiento que solo comparten sus resultados, no todo su proceso de pensamiento.
En sistemas multiagente, este enfoque es esencial. Si el agente A se encarga de la tarea A y el agente B se encarga de la tarea B, no hay razón para que ninguno de los dos consuma todo el contexto del otro, a menos que sea realmente necesario. En cambio, los agentes pueden intercambiar solo la información necesaria. Por ejemplo, el agente A puede pasar un resumen consolidado de sus hallazgos al agente B a través de un agente supervisor, mientras que cada subagente mantiene su propio hilo de contexto dedicado. Esta configuración no requiere intervención humana; se basa en un agente supervisor con herramientas habilitadas y con un intercambio de contexto mínimo y controlado.
No obstante, diseñar tu sistema de manera que los agentes o herramientas operen con la mínima superposición de contexto necesaria puede mejorar considerablemente la claridad y el rendimiento. Piensa en ello como microservicios para IA, cada componente se ocupa de su contexto y pasa mensajes entre ellos de una manera controlada, en lugar de un contexto monolítico. Estas mejores prácticas a menudo se usan en combinación. Además, esto te da la flexibilidad de recortar historiales triviales, resumir mensajes o conversaciones antiguas importantes, transferir los registros detallados a Elasticsearch para contexto a largo plazo y usar la recuperación para recuperar cualquier cosa relevante cuando sea necesario.
Como se mencionó aquí, el principio rector es que el contexto es un recurso limitado y valioso. Quieres que cada token del prompt se gane su conservación, lo que significa que debería contribuir a la calidad de la salida. Si algo en la memoria no está cumpliendo con su función (o peor aún, está causando confusión), entonces debe ser eliminado, resumido o descartado.
Como desarrolladores, ahora podemos programar el contexto igual que programamos el código, decidiendo qué información incluir, cómo formatearla y cuándo omitirla o actualizarla. Siguiendo estas prácticas, podemos proporcionar a los agentes LLM el contexto necesario para realizar tareas sin caer en los modos de fallo descritos anteriormente. El resultado son agentes que recuerdan lo que deben, olvidan lo que no necesitan y recuperan lo que requieren justo a tiempo.
Conclusión
La memoria no es algo que añades a un agente; es algo que diseñas. La memoria a corto plazo es el bloc de notas de trabajo del agente, y la memoria a largo plazo es su almacén duradero de conocimiento. La RAG es el puente entre los dos, ya que convierte un almacén de datos pasivo, como Elasticsearch, en un mecanismo de recuperación activo que puede conectar a tierra las salidas y mantener el agente actualizado.
Pero la memoria es un arma de doble filo. En el momento en que dejas que el contexto crezca sin control, invitas al envenenamiento, la distracción, la confusión y los choques, y en los sistemas compartidos, incluso la fuga de datos. Por eso, el trabajo de memoria más importante no es "almacenar más", sino "seleccionar mejor": recuperar selectivamente, podar agresivamente, resumir cuidadosamente y evitar mezclar contextos no relacionados a menos que la tarea realmente lo demande.
En la práctica, una buena ingeniería de contexto parece un buen diseño de sistemas: contextos más pequeños y suficientes, interfaces controladas entre componentes y una clara separación entre el estado crudo y el estado destilado que realmente quieres que vea el modelo. Si se hace correctamente, no terminas con un agente que lo recuerda todo, sino con un agente que recuerda las cosas adecuadas, en el momento adecuado, por la razón correcta.
Contenido relacionado

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

23 de marzo de 2026
Uso de la API de inferencia de Elasticsearch junto con modelos de Hugging Face
Aprende a conectar Elasticsearch a modelos de Hugging Face usando endpoints de inferencia y crea un sistema multilingüe de recomendación de blogs con búsqueda semántica y finalización de chat.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.
17 de marzo de 2026
Extensión CLI de Gemini para Elasticsearch con herramientas y habilidades
Te presentamos la extensión de Elastic para la CLI de Gemini de Google, que te permite hacer búsquedas, recuperar y analizar datos de Elasticsearch en flujos de trabajo de desarrollo y de agentes.