Na disciplina emergente da engenharia de contexto, é fundamental fornecer aos agentes de IA as informações certas no momento certo. Um dos aspectos mais importantes da engenharia de contexto é o gerenciamento da memória de uma IA. Assim como os humanos, sistemas de IA dependem tanto de memória de curto prazo quanto de memória de longo prazo para recordar informações. Se quisermos que agentes de grandes modelos de linguagem (LLM) mantenham conversas lógicas, lembrem das preferências do usuário ou construam sobre resultados ou respostas anteriores, precisamos equipá-los com mecanismos de memória eficazes.
Afinal, tudo no contexto influencia as respostas da IA. O princípio Lixo entra, lixo saí continua válido.
Neste artigo, vamos apresentar o que as memórias de curto e longo prazo significam para agentes de IA, especificamente:
- A diferença entre memória de curto e longo prazo.
- Como elas se relacionam com as técnicas de Retrieval-Augmented Generation (RAG) com bancos de dados vetoriais, como o Elasticsearch, e por que é necessário um gerenciamento cuidadoso da memória.
- Os riscos de negligenciar a memória, incluindo transbordamento de contexto e envenenamento do contexto.
- Boas práticas, como a eliminação do contexto, o resumo e a recuperação apenas do que é relevante, visam manter a memória de um agente útil e segura.
- Por fim, vamos abordar como a memória pode ser compartilhada e propagada em sistemas multiagente para permitir que agentes colaborem sem confusão usando o Elasticsearch.
Memória de curto prazo versus memória de longo prazo em agentes de IA
Memória de curto prazo em um agente de IA geralmente se refere ao contexto conversacional imediato ou estado — essencialmente, o histórico atual da conversa ou mensagens recentes na sessão ativa. Isso inclui a consulta mais recente do usuário e as trocas de mensagens recentes. É muito semelhante à informação que uma pessoa mantém em mente durante uma conversa em andamento.
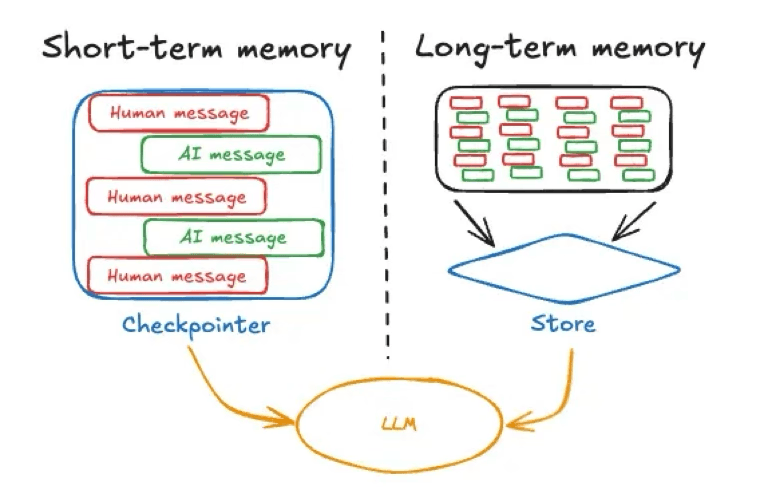
Fonte da imagem: https://langchain.ai.github.io/langgraphjs/concepts/memory
Frameworks de IA frequentemente mantêm essa memória transitória como parte do estado do agente (por exemplo, usando um mecanismo de ponto de verificação para armazenar o estado da conversa, conforme abordado por este exemplo do LangGraph). A memória de curto prazo tem escopo de sessão, ou seja, existe em uma única conversa ou tarefa e é redefinida ou apagada quando a sessão termina, a menos que seja explicitamente salva em outro lugar. Um exemplo de memória de curto prazo ligada a sessões seria o chat temporário disponível no ChatGPT.
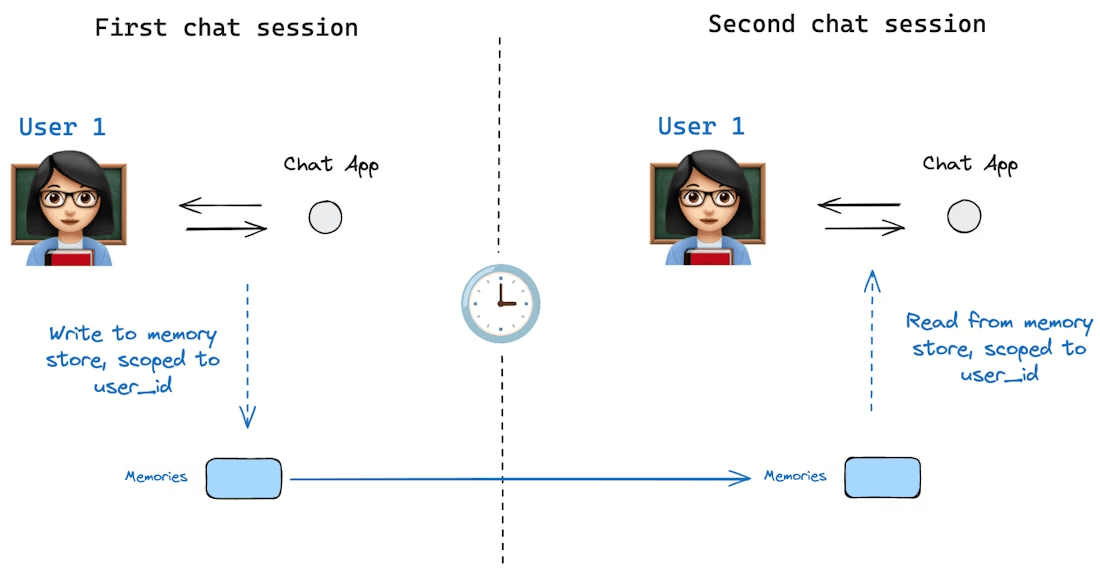
Fonte da imagem: https://docs.langchain.com/oss/python/langgraph/persistence#memory-store
A memória de longo prazo, por outro lado, refere-se a informações que persistem ao longo de conversas ou sessões. Este é o conhecimento que um agente retém ao longo do tempo, fatos que aprendeu anteriormente, preferências do usuário ou quaisquer dados que pedimos para ele lembrar permanentemente.
A memória de longo prazo geralmente é implementada armazenando e recuperando dados de uma fonte externa, como um arquivo ou banco de dados vetorial fora do contexto imediato da janela. Diferentemente do histórico de chats de curto prazo, a memória de longo prazo não é incluída automaticamente em todas as solicitações. Em vez disso, com base em um determinado cenário, o agente deve recordá-lo ou recuperá-lo quando as ferramentas relevantes forem invocadas. Na prática, a memória de longo prazo pode incluir informações de perfil do usuário, respostas ou análises anteriores produzidas pelo agente, ou uma base de conhecimento que o agente pode consultar.
Por exemplo, se você tiver um agente de planejamento de viagens, a memória de curto prazo conterá detalhes da consulta de viagem atual (datas, destino, orçamento) e quaisquer perguntas subsequentes feitas durante o chat; enquanto a memória de longo prazo poderá armazenar as preferências gerais de viagem do usuário, itinerários anteriores e outros dados compartilhados em sessões anteriores. Quando o usuário retornar posteriormente, o agente poderá recorrer a esse histórico (por exemplo, o usuário adora praias e montanhas, tem um orçamento médio de 100.000 rúpias indianas, possui uma lista de lugares para visitar antes de morrer e prefere vivenciar história e cultura em vez de atrações voltadas para crianças), de modo que não trate o usuário como uma folha em branco a cada vez.
A memória de curto prazo (histórico de chats) fornece contexto e continuidade imediatos, enquanto a memória de longo prazo fornece um contexto mais amplo que o agente pode usar quando necessário. Os frameworks de agentes de IA mais avançados permitem ambas as coisas: mantêm o controle dos diálogos recentes para manter o contexto e oferecem mecanismos para consultar ou armazenar informações em um repositório de longo prazo. O gerenciamento da memória de curto prazo garante que ela permaneça dentro da janela de contexto, enquanto o gerenciamento da memória de longo prazo ajuda o agente a basear as respostas com base em interações e personalidades anteriores.
Memória e RAG na engenharia de contexto
Fonte da imagem: https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-03-own-your-context-window.md
Como damos a um agente de IA uma memória útil de longo prazo na prática?
Uma abordagem proeminente para a memória de longo prazo é a memória semântica, frequentemente implementada por meio de retrieval-augmented generation (RAG). Isso envolve acoplar o LLM a um armazenamento de conhecimento externo ou a um datastore habilitado por vetor, como o Elasticsearch. Quando o LLM precisa de informações além do que está no prompt ou em seu treinamento integrado, ele realiza uma recuperação semântica contra o Elasticsearch e injeta os resultados mais relevantes no prompt como contexto. Dessa forma, o contexto efetivo do modelo inclui não apenas a conversa recente (memória de curto prazo), mas também fatos pertinentes de longo prazo obtidos em tempo real. O LLM então fundamenta sua resposta tanto em seu próprio raciocínio quanto nas informações recuperadas, combinando efetivamente memória de curto prazo e memória de longo prazo para produzir uma resposta mais precisa e consciente do contexto.
O Elasticsearch pode ser usado para implementar memória de longo prazo para agentes de IA. Aqui está um exemplo de alto nível de como o contexto pode ser recuperado do Elasticsearch para memória de longo prazo.
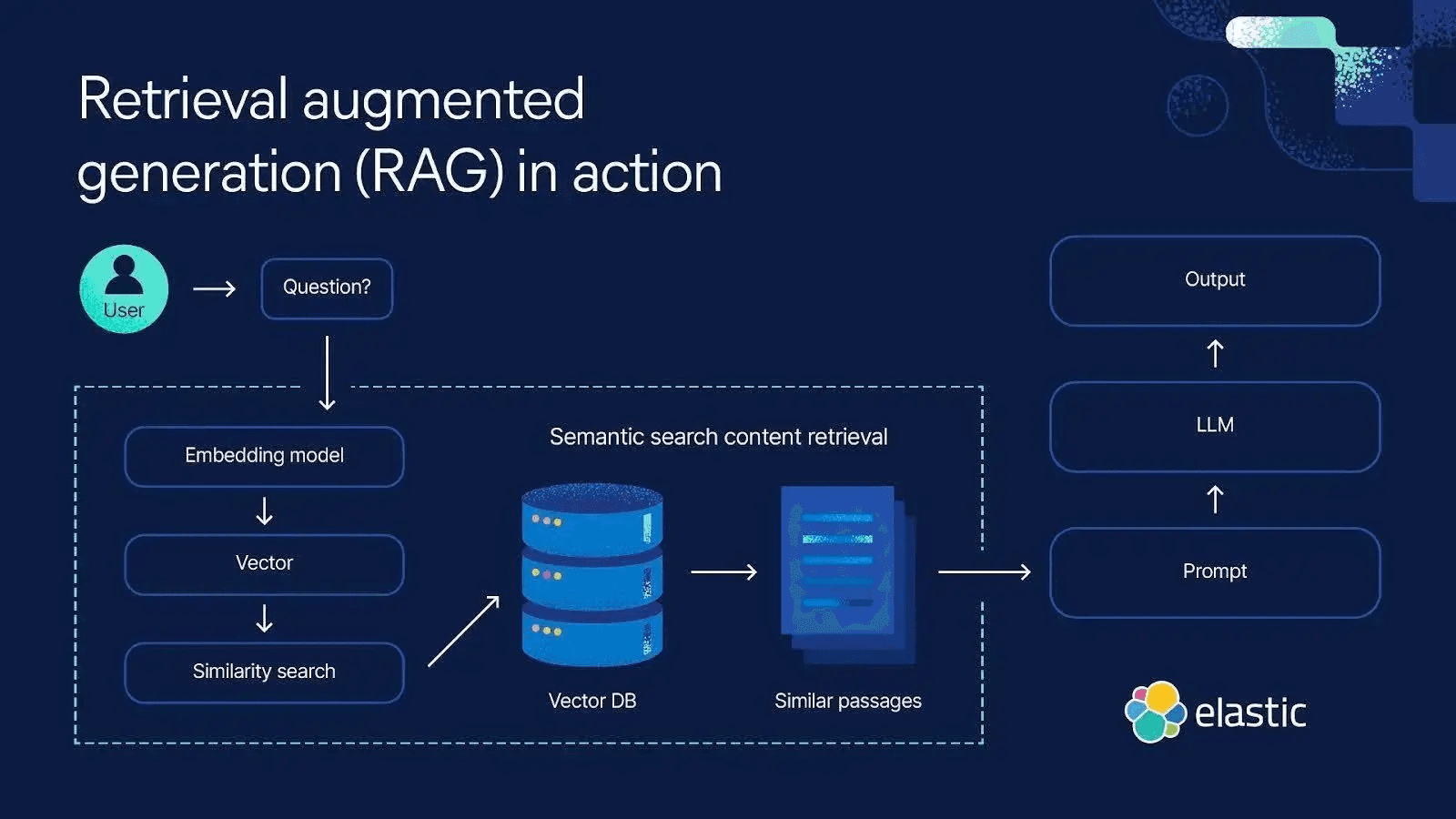
Dessa forma, o agente "se lembra" pesquisando dados relevantes em vez de armazenar tudo em seu prompt limitado, onde isso leva a diferentes riscos.
Usar RAG com o Elasticsearch ou qualquer armazenamento vetorial oferece múltiplos benefícios:
Primeiro, ele amplia o conhecimento do modelo além do limite de treinamento. O agente pode recuperar informações atualizadas ou dados específicos do domínio que o LLM talvez não conheça. Isso é crucial para perguntas sobre eventos recentes ou tópicos especializados.
Em segundo lugar, recuperar o contexto sob demanda ajuda a reduzir alucinações, especialmente porque os LLMs não são treinados com dados proprietários ou altamente especializados relativos ao seu caso de uso específico, o que é muito provável que os exponha a alucinações. Em vez de o LLM adivinhar ou inventar novas informações, como tem sido incentivado pela avaliação, conforme destacado em um artigo recente da OpenAI (Why Language Models Hallucinate), o modelo pode ser fundamentado em referências factuais do Elasticsearch. Naturalmente, o LLM depende da confiabilidade dos dados no armazenamento vetorial para realmente evitar desinformação e os dados relevantes são recuperados de acordo com as medidas de relevância do núcleo.
Terceiro, o RAG permite que um agente trabalhe com bases de conhecimento muito maiores do que qualquer coisa que você poderia encaixar em um prompt. Em vez de inserir documentos inteiros, como longos artigos de pesquisa ou documentos de políticas, na janela de contexto e correr o risco de sobrecarga ou de informações irrelevantes contaminarem o raciocínio do modelo, o RAG se baseia em fragmentação. Documentos grandes são divididos em partes menores e semanticamente significativas, e o sistema recupera apenas os poucos trechos mais relevantes para a consulta. Dessa forma, o modelo não precisa de um contexto de um milhão de tokens para parecer conhecedor; ele só precisa de acesso aos pedaços certos de um corpus muito maior.
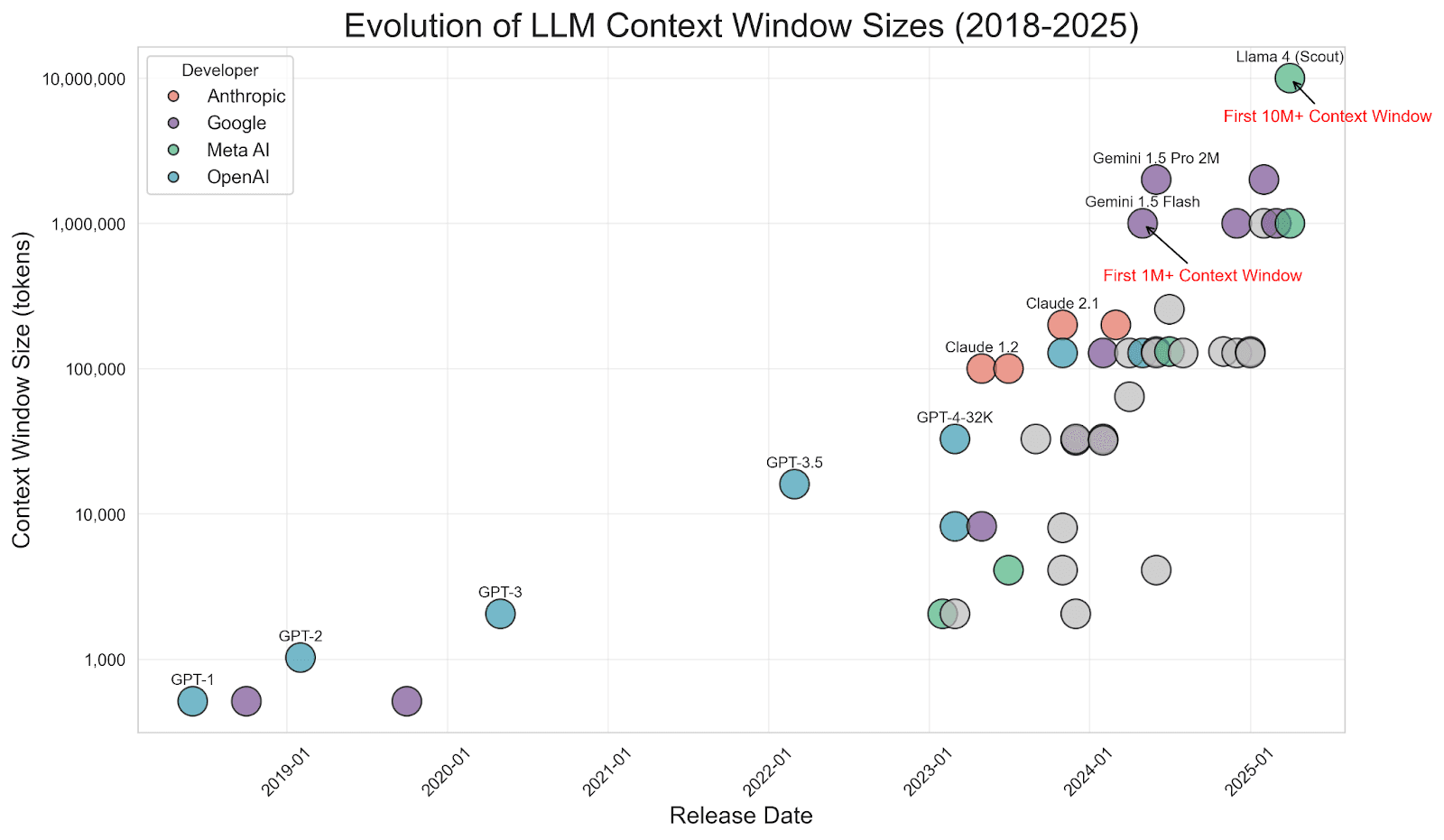
Fonte da imagem: https://www.meibel.ai/post/understanding-the-impact-of-increasing-llm-context-windows
Vale ressaltar que, com o aumento das janelas de contexto do LLM (alguns modelos agora suportam centenas de milhares ou até milhões de tokens), surgiu um debate sobre se o RAG está "morto". Por que não enviar todos os dados para o prompt? Se você pensa da mesma forma, consulte este maravilhoso artigo de meus colegas Jeffrey Rengifo e Eduard Martin, Longer context ≠ better: Why RAG still matters. Isso evita o problema de "lixo entra, lixo sai": o LLM fica focado nos poucos pedaços que importam, em vez de passar por meio de ruído.
Dito isso, integrar o Elasticsearch ou qualquer armazenamento vetorial em uma arquitetura de agente de IA fornece memória de longo prazo. O agente armazena conhecimento externamente e o recolhe como contexto de memória quando necessário. Isso poderia ser implementado como uma arquitetura, onde, após cada consulta do usuário, o agente realiza uma busca no Elasticsearch por informações relevantes e então adiciona os principais resultados ao prompt antes de chamar o LLM. A resposta também pode ser salva de volta no armazenamento de longo prazo se contiver informações novas úteis (criando um ciclo de retroalimentação de aprendizado). Ao usar essa memória baseada em recuperação, o agente permanece informado e atualizado, sem precisar condensar tudo o que sabe em cada prompt, mesmo que a janela de contexto suporte um milhão de tokens. Essa técnica é uma pedra angular da engenharia de contexto, combinando os pontos fortes da recuperação de informação e da IA generativa.
Aqui está um exemplo de um estado gerenciado de conversa em memória usando o sistema de ponto de verificação do LangGraph para memória de curto prazo durante a sessão. (Consulte nosso app de engenharia de contexto de suporte).
Veja como ele armazena pontos de verificação:
Para a memória de longo prazo, veja como realizamos a busca semântica no Elasticsearch para recuperar conversas anteriores relevantes usando embeddings de vetor após resumir e a indexar pontos de verificação no Elasticsearch.
Agora que exploramos como a memória de curto prazo e a memória de longo prazo são indexadas e buscadas usando os pontos de verificação do LangGraph no Elasticsearch, vamos tirar um tempo para entender por que a indexação e o despejo das conversas completas podem ser arriscados.
Riscos de não gerenciar a memória de contexto
Como estamos falando muito sobre engenharia de contexto, junto com memória de curto e longo prazo, vamos entender o que acontece se não gerenciarmos bem a memória e o contexto de um agente.
Infelizmente, muitas coisas podem dar errado quando o contexto de uma IA se torna extremamente longo ou contém informações erradas. À medida que as janelas de contexto aumentam, surgem novos modos de falha, como:
- Envenenamento de contexto
- Distração contextual
- Confusão de contexto
- Conflito de contexto
- Vazamento de contexto e conflitos de conhecimento
- Alucinações e desinformação
Vamos analisar esses problemas e outros riscos que surgem do gerenciamento inadequado de contexto:
Envenenamento de contexto
O envenenamento do contexto refere-se a quando informações incorretas ou prejudiciais acabam no contexto e "envenenam" as saídas subsequentes do modelo. Um exemplo comum é uma alucinação do modelo que é tratada como fato e inserida no histórico da conversa. O modelo pode então construir sobre esse erro em respostas posteriores, agravando o erro. Em ciclos iterativos de agentes, uma vez que uma informação falsa entra no contexto compartilhado (por exemplo, em um resumo das notas de trabalho do agente), ela pode ser reforçada repetidamente.
Pesquisadores da DeepMind, no lançamento do relatório Gemini 2.5 (TL;DR, veja aqui), observaram o seguinte em um agente que jogava Pokémon: se o agente alucinasse um estado incorreto de jogo e isso fosse registrado em seu contexto (a memória de objetivos), o agente criaria estratégias sem sentido em torno de um objetivo impossível e ficaria preso. Em outras palavras, uma memória envenenada pode levar o agente pelo caminho errado indefinidamente.
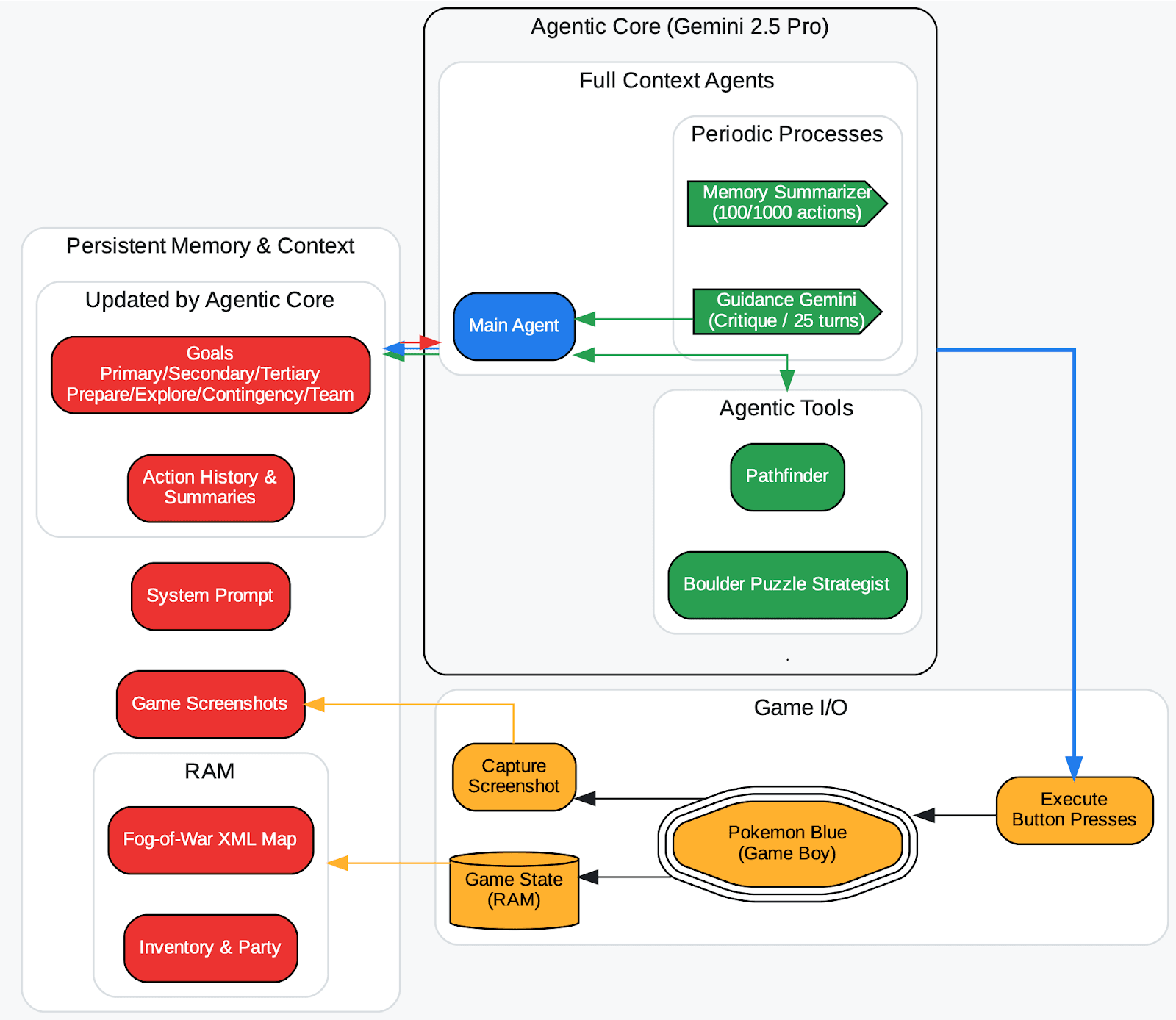
Uma visão geral do arcabouço do agente (Zhang, 2025). O mapa de neblina de guerra do mundo aberto armazena automaticamente um bloco após ser explorado e o rotula com um contador de visitas. O tipo de bloco é registrado a partir da RAM. As ferramentas agentivas (pathfinder, boulder_puzzle_strategist) são instâncias solicitadas do Gemini 2.5 Pro. pathfinder é usado para navegação e boulder_puzzle_strategist resolve quebra-cabeças de pedras na masmorra da Estrada da Vitória.
Fonte da imagem: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - página 68.
O envenenamento de contexto pode acontecer inocentemente (por engano) ou até mesmo de forma mal-intencionada, por exemplo, por meio de ataques de injeção de prompt, onde um usuário ou terceiro introduz uma instrução oculta ou um fato falso que o agente então lembra e segue.
Contramedidas recomendadas:
Com base nos insights de Wiz, Zerlo e Anthropic, as contramedidas para envenenamento de contexto se concentram em evitar que informações ruins ou enganosas entrem no prompt, na janela de contexto ou no pipeline de recuperação de um LLM. Os principais passos incluem:
- Verifique o contexto constantemente: monitore a conversa ou o texto recuperado para qualquer coisa suspeita ou prejudicial, não apenas o prompt inicial.
- Use fontes confiáveis: pontue ou rotule documentos com base na credibilidade para que o sistema prefira informações confiáveis e ignore dados com pontuação baixa.
- Identifique dados incomuns: use ferramentas que detectem conteúdo estranho, fora de lugar ou manipulado, e remova-o antes que o modelo os utilize.
- Filtre entradas e saídas: adicione proteções de segurança para que textos prejudiciais ou enganosos não possam entrar facilmente no sistema ou ser repetidos pelo modelo.
- Mantenha o modelo atualizado com dados limpos: atualize regularmente o sistema com informações verificadas para combater qualquer dado errado que tenha escapado.
- Com supervisão humana: peça para as pessoas revisarem as saídas importantes ou compará-las com fontes conhecidas e confiáveis.
Hábitos simples do usuário também ajudam, como redefinir chats longos, compartilhar apenas informações relevantes, dividir tarefas complexas em etapas menores e manter anotações claras fora do modelo.
Juntas, essas medidas criam uma defesa em camadas que protege os LLMs contra envenenamento do contexto e mantém as saídas precisas e confiáveis.
Sem contramedidas mencionadas aqui, um agente pode lembrar-se de instruções, como ignorar diretrizes anteriores ou fatos triviais inseridos por um invasor, levando a saídas prejudiciais.
Distração contextual
A distração de contexto ocorre quando um contexto se alonga tanto que o modelo foca demais no contexto, negligenciando o que aprendeu durante o treinamento. Em casos extremos, isso se assemelha ao esquecimento catastrófico; ou seja, o modelo efetivamente "esquece" seu conhecimento subjacente e fica excessivamente apegado à informação que lhe é apresentada. Estudos anteriores mostraram que LLMs frequentemente perdem o foco quando o prompt é extremamente longo.
O agente Gemini 2.5, por exemplo, suportava uma janela de um milhão de tokens, mas quando seu contexto crescia além de um certo ponto (na ordem de 100.000 tokens em um experimento), ele começava a se fixar em repetir suas ações passadas em vez de apresentar novas soluções. De certa forma, o agente tornou-se prisioneiro de sua extensa história. Ele continuava observando seu longo log de movimentos anteriores (o contexto) e imitando-os, em vez de usar seu conhecimento de treinamento subjacente para criar estratégias novas e inovadoras.

Fonte da imagem: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - página 18.
Isso é contraproducente. Queremos que o modelo use o contexto relevante para ajudar no raciocínio, não para sobrepor sua capacidade de pensar. Notavelmente, mesmo modelos com janelas enormes exibem essa deterioração de contexto: seu desempenho se degrada de forma não uniforme à medida que mais tokens são adicionados. Parece haver um orçamento de atenção. Como humanos com memória de trabalho limitada, um LLM tem uma capacidade finita para atender a tokens, e à medida que esse orçamento é esticado, sua precisão e foco caem.
Como mitigação, você pode evitar distração do contexto usando fragmentação, engenharia das informações corretas, resumo regular do contexto e técnicas de avaliação e monitoramento para medir a precisão da resposta usando pontuação.
Esses métodos mantêm o modelo baseado no contexto relevante e em seu treinamento subjacente, reduzindo o risco de distração e melhorando a qualidade geral do raciocínio.
Confusão de contexto
A confusão de contexto ocorre quando o conteúdo supérfluo no contexto é usado pelo modelo para gerar uma resposta de baixa qualidade. Um ótimo exemplo é fornecer a um agente um grande conjunto de ferramentas ou definições de API que ele pode usar. Se muitas dessas ferramentas não estiverem relacionadas à tarefa atual, o modelo ainda pode tentar usá-las de forma inadequada, simplesmente porque elas estão presentes no contexto. Experimentos descobriram que fornecer mais ferramentas ou documentos pode prejudicar o desempenho se não forem todos necessários. O agente começa a cometer erros, como chamar a função errada ou fazer referência a um texto irrelevante.
Em um caso, um pequeno modelo Llama 3.1 8B falhou em uma tarefa ao receber 46 ferramentas para considerar, mas teve sucesso quando recebeu apenas 19 ferramentas. As ferramentas extras criaram confusão, mesmo que o contexto estivesse dentro dos limites de duração. A questão subjacente é que qualquer informação no prompt será atendida pelo modelo. Se não souber ignorar algo, esse algo pode influenciar sua saída de maneiras indesejadas. Pedaços irrelevantes podem “roubar” parte da atenção do modelo e desviá-lo (por exemplo, um documento irrelevante pode fazer com que o agente responda a uma pergunta diferente da feita). A confusão de contexto frequentemente se manifesta como o modelo produzindo uma resposta de baixa qualidade que integra contextos não relacionados. Consulte o trabalho de pesquisa: Menos é mais: otimizando a chamada de funções para execução LLM em dispositivos de borda.
Isso nos lembra que mais contexto nem sempre é melhor, especialmente se não for selecionado para ser relevante.
Conflito de contexto
O conflito de contexto ocorre quando partes do contexto se contradizem, causando inconsistências internas que comprometem o raciocínio do modelo. Um conflito pode acontecer se o agente acumular várias informações que estão em conflito.
Por exemplo, imagine um agente que obteve dados de duas fontes: uma diz que o voo A parte às 17h, e a outra diz que o voo A parte às 18h. Se ambos os fatos estiverem presentes no contexto, o modelo inadequado não terá como saber qual está correto; poderá ficar confuso ou produzir uma resposta incorreta ou não similar.
O conflito de contexto também ocorre com frequência em conversas com várias interações, em que as tentativas anteriores de resposta do modelo ainda permanecem no contexto junto com informações refinadas posteriormente.

Fonte da imagem: LLMS se perde na conversa de várias interações (Página 04)
Um estudo realizado pela Microsoft e pela Salesforce mostra que, ao dividir uma consulta complexa em várias interações com o chatbot (adicionando detalhes gradualmente), a precisão final cai significativamente em comparação com a apresentação de todos os detalhes em uma única solicitação. Por quê? Porque as primeiras interações contêm respostas intermediárias parciais ou incorretas do modelo, e essas permanecem no contexto. Quando o modelo tenta responder posteriormente com todas as informações, sua memória ainda inclui as tentativas erradas, que entram em conflito com as informações corrigidas e o desviam do caminho. Basicamente, o contexto da conversa entra em conflito consigo mesmo. O modelo pode, sem querer, usar um contexto desatualizado (de uma interação anterior) que não se aplica depois que novas informações são adicionadas.
Em sistemas de agentes, o choque de contexto é especialmente perigoso, pois um agente pode combinar saídas de diferentes ferramentas ou subagentes. Se essas saídas discordarem, o contexto agregado será inconsistente. O agente pode, então, ficar travado ou produzir resultados sem sentido ao tentar conciliar as contradições. Evitar conflitos de contexto envolve garantir que o contexto seja novo e consistente, por exemplo, limpar ou atualizar qualquer informação desatualizada e não misturar fontes que não tenham sido verificadas quanto à consistência.
Vazamento de contexto e conflitos de conhecimento
Em sistemas onde múltiplos agentes ou usuários compartilham um estoque de memória, há o risco de informações transbordarem entre os contextos.
Por exemplo, se os dados de embeddings de dois usuários diferentes residirem no mesmo banco de dados vetorial sem o devido controle de acesso, um agente que responde à consulta do Usuário A pode, acidentalmente, recuperar parte da memória do Usuário B. Esse vazamento entre contextos pode expor informações privadas ou apenas criar confusão nas respostas.
De acordo com o OWASP Top 10 for LLM Applications, os bancos de dados vetoriais multilocatários devem se proteger contra esse tipo de vazamento:
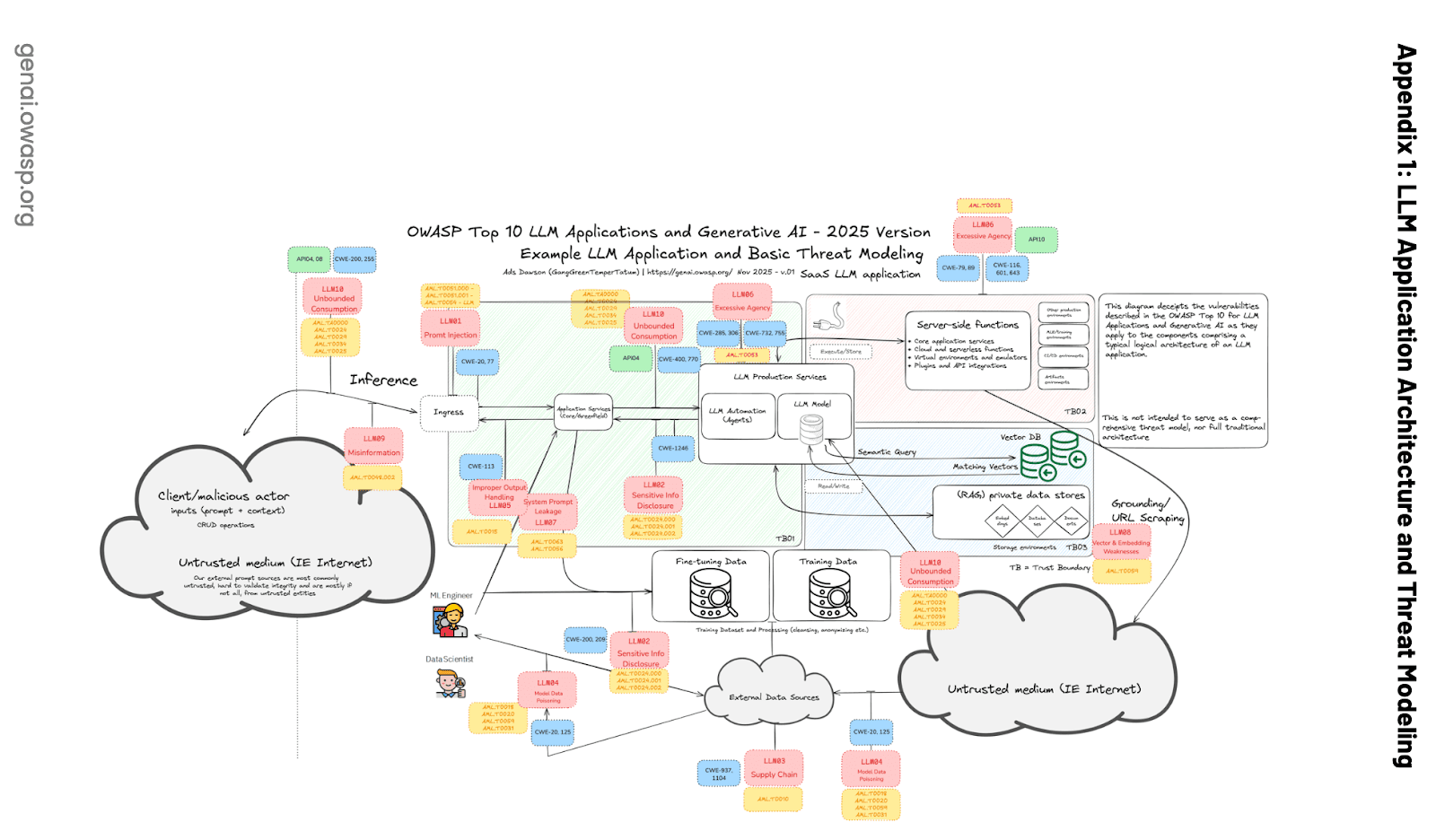
De acordo com LLM08:2025 — Fraquezas em Vetores e Embeddings, um dos riscos comuns é o vazamento de contexto:
Em ambientes multi-inquilinos onde várias classes de usuários ou aplicativos compartilham o mesmo banco de dados vetorial, existe o risco de vazamento de contexto entre usuários ou consultas. Erros de conflito de conhecimento na federação de dados podem ocorrer quando dados de múltiplas fontes se contradizem. Isso também pode ocorrer quando um LLM não consegue substituir o conhecimento antigo que aprendeu durante o treinamento pelos novos dados do Retrieval Augmentation.
Outro aspecto é que um LLM pode ter dificuldade em substituir seu conhecimento integrado por novas informações da memória. Se o modelo foi treinado em algum fato e o contexto recuperado diz o oposto, o modelo pode ficar confuso sobre qual confiar. Sem um design adequado, o agente pode misturar contextos ou não conseguir atualizar o conhecimento antigo com novas evidências, levando a respostas desatualizadas ou incorretas.
Alucinações e desinformação
Embora a alucinação (o LLM inventando informações plausíveis, mas falsas) seja um problema conhecido, mesmo sem contextos longos, o gerenciamento inadequado da memória pode amplificá-lo. Você pode ter que se preocupar com o fato de que o LLM não está preparado para isso.
Se faltar um fato crucial na memória do agente, o modelo pode simplesmente preencher a lacuna com um palpite e, se esse palpite entrar no contexto (envenenando-o), o erro persistirá.
O relatório de segurança OWASP LLM (LLM09:2025 — Desinformação) destaca a desinformação como uma vulnerabilidade central: os modelos de aprendizagem de linguagem (LLMs) podem produzir respostas confiantes, porém fabricadas, e os usuários podem confiar excessivamente nelas. Um agente com uma memória de longo prazo ruim ou desatualizada pode citar com segurança algo que era verdadeiro no ano passado, mas é falso agora, a menos que sua memória seja mantida atualizada.
A dependência excessiva da saída da IA (seja pelo usuário ou pelo próprio agente em um loop) pode piorar isso. Se ninguém nunca conferir as informações na memória, o agente pode acumular falsidades. É por isso que o RAG é frequentemente usado para reduzir alucinações: ao recuperar uma fonte autoritativa, o modelo não precisa inventar fatos. Mas se sua recuperação extrair o documento errado (digamos, um que contenha informações erradas) ou se uma alucinação precoce não for eliminada, o sistema poderá propagar essa desinformação por meio de suas ações.
O resultado final: deixar de gerenciar a memória pode levar a saídas incorretas e enganosas, o que pode ser prejudicial, especialmente se os riscos forem altos (por exemplo, conselhos ruins em um domínio financeiro ou médico). Um agente precisa de mecanismos para verificar ou corrigir seu conteúdo de memória, não apenas confiar incondicionalmente em qualquer coisa que esteja no contexto.
Em resumo, dar a um agente de IA uma memória infinitamente longa ou despejar todas as coisas possíveis em seu contexto não é uma receita para o sucesso.
Práticas recomendadas para o gerenciamento de memória em aplicações LLM
Para evitar as armadilhas acima, os desenvolvedores e pesquisadores criaram uma série de práticas recomendadas para gerenciar o contexto e a memória nos sistemas de IA. Essas práticas visam manter o contexto de trabalho da IA enxuto, relevante e atualizado. Aqui estão algumas das principais estratégias, além de exemplos de como elas ajudam.
RAG: use contexto direcionado
Grande parte do conceito RAG já foi abordada na seção anterior, portanto, este texto serve como um conjunto conciso de lembretes práticos:
- Use recuperação direcionada, não carregamento em massa: recupere apenas os trechos mais relevantes em vez de enviar documentos inteiros ou históricos completos de conversas para o prompt.
- Considere o RAG como uma recuperação de memória sob demanda: busque o contexto apenas quando necessário, em vez de carregar tudo adiante entre as interações.
- Prefira estratégias de recuperação com base na relevância: abordagens como busca semântica top k, fusão de classificação recíproca ou filtragem de carga de ferramentas ajudam a reduzir o ruído e melhorar o aterramento.
- Janelas de contexto maiores não eliminam a necessidade do RAG: dois parágrafos altamente relevantes quase sempre são mais eficazes do que 20 páginas vagamente relacionadas.
Dito isso, o RAG não se trata de adicionar mais contexto; trata-se de adicionar o contexto certo.
Configuração de ferramentas
O carregamento de ferramentas consiste em fornecer a um modelo apenas as ferramentas de que ele realmente precisa para uma tarefa. O termo vem de jogos: você escolhe um carregamento que se adequa à situação. Muitas ferramentas atrasam você; as erradas causam falhas. LLMs se comportam da mesma forma, segundo o artigo Menos é mais. Depois que você passa por ~30 ferramentas, as descrições começam a se sobrepor e o modelo fica confuso. Depois de ~100 ferramentas, o fracasso é quase garantido. Isso não é um problema de janela de contexto, é confusão de contexto.
Uma solução simples e eficaz é o RAG-MCP. Em vez de inserir todas as ferramentas no prompt, as descrições das ferramentas são armazenadas em um banco de dados vetorial e somente as mais relevantes são recuperadas por solicitação. Na prática, isso mantém o carregamento pequeno e focado, encurta drasticamente os prompts e pode melhorar a precisão da seleção de ferramentas em até 3 vezes.
Modelos menores batem nessa barreira ainda mais cedo. A pesquisa mostra que um modelo 8B falha com dezenas de ferramentas, mas tem sucesso assim que o equipamento é cortado. Selecionar ferramentas dinamicamente, às vezes primeiro com um LLM, raciocinar sobre o que ele acha que precisa, pode aumentar o desempenho em 44%, além de reduzir o consumo de energia e a latência. A conclusão é que a maioria dos agentes precisa apenas de algumas ferramentas, mas à medida que seu sistema cresce, o carregamento de ferramentas e o RAG-MCP se tornam decisões de design de primeira ordem.
Eliminação de contexto: limite o tempo do histórico de chat
Se uma conversa continuar por várias interações, o histórico de chat acumulado pode ficar muito extenso, causando um excesso de contexto ou distraindo demais o modelo.
Aparar significa remover ou encurtar programaticamente as partes menos importantes do diálogo à medida que ele cresce. Uma forma simples é eliminar as interações mais antigas da conversa quando você atingir um determinado limite, mantendo apenas as N mensagens mais recentes. Uma eliminação mais sofisticada pode remover digressões irrelevantes ou instruções anteriores que não são mais necessárias. O objetivo é manter a janela de contexto desobstruída de notícias antigas.
Por exemplo, se o agente resolveu um subproblema há 10 interações e nós seguimos em frente desde então, podemos excluir essa parte do histórico do contexto (assumindo que não será mais necessário). Muitas implementações baseadas em chat fazem isso: elas mantêm uma janela móvel de mensagens recentes.
Aparar pode ser tão simples quanto "esquecer" as partes mais iniciais de uma conversa depois que elas foram resumidas ou consideradas irrelevantes. Ao fazer isso, reduzimos o risco de erros de excesso de contexto e também diminuímos a distração do contexto, para que o modelo não veja e se distraia com conteúdo antigo ou fora do tema. Essa abordagem é muito parecida com como os humanos podem não lembrar cada palavra de uma conversa de uma hora, mas manterão os destaques.
Se você está confuso sobre a eliminação de contexto, como destacado pelo autor Drew Breunig aqui, o uso do modelo Provence (`naver/provence-reranker-debertav3-v1`), um eliminador de contexto leve (1,75 GB), eficiente e preciso para resposta a perguntas, pode fazer a diferença. Ele pode reduzir documentos grandes apenas para o texto mais relevante para uma determinada consulta. Você pode chamá-lo em intervalos específicos.
Veja como invocamos o modelo 'provence-reranker' em nosso código para eliminar o contexto:
Usamos o modelo Provence reranker (`naver/provence-reranker-debertav3-v1`) para pontuar a relevância da frase. A filtragem baseada em limiar mantém as sentenças acima do limiar de relevância. Além disso, introduzimos um mecanismo de fallback, no qual retornamos ao contexto original se a eliminação falhar. Por fim, o logging de estatísticas acompanha a porcentagem de redução em modo detalhado.
Resumo do contexto: condense informações antigas em vez de descartá-las completamente
O resumo é um complemento para redução. Quando a história ou a base de conhecimento se tornar muito grande, você pode usar o LLM para gerar um breve resumo dos pontos importantes e usar esse resumo no lugar do conteúdo completo daqui para frente, como fizemos no código acima.
Por exemplo, se um assistente de IA tiver tido uma conversa de 50 interações, em vez de enviar todas as 50 interações para o modelo na interação 51 (o que provavelmente não caberia), o sistema poderia pegar as interações de 1 a 40, fazer com que o modelo as resumisse em um parágrafo e, em seguida, fornecer apenas esse resumo mais as 10 últimas interações na próxima solicitação. Dessa forma, o modelo ainda sabe o que foi discutido sem precisar de todos os detalhes. Os primeiros usuários de chatbots faziam isso manualmente perguntando: "Você pode resumir o que discutimos até agora?" e então continuando em uma nova sessão com o resumo. Agora isso pode ser automatizado. O resumo não apenas economiza espaço na janela de contexto, mas também pode reduzir a confusão/distração do contexto ao eliminar detalhes extras e reter apenas os fatos mais importantes.
Veja como usamos modelos OpenAI (você pode usar qualquer LLMs) para condensar o contexto preservando todas as informações relevantes, eliminando redundância e duplicação.
É importante ressaltar que, quando o contexto é resumido, o modelo tem menos probabilidade de ser sobrecarregado por detalhes triviais ou erros passados (presumindo que o resumo seja preciso).
No entanto, o resumo deve ser feito com cuidado. Um resumo ruim pode omitir um detalhe crucial ou até mesmo introduzir um erro. É basicamente mais um prompt para o modelo ("resuma isso"), então ele pode alucinar ou perder nuances. A melhor prática é resumir de forma incremental e talvez manter alguns fatos canônicos sem resumo.
Ainda assim, tem se mostrado muito útil. No cenário do agente Gemini, resumir o contexto a cada ~100k tokens era uma forma de combater a tendência do modelo de se repetir. O resumo funciona como uma memória comprimida da conversa ou dos dados. Como desenvolvedores, podemos implementar isso fazendo com que um agente chame periodicamente uma função de resumo (talvez um LLM menor ou uma rotina dedicada) no histórico de conversas ou em um documento longo. O resumo resultante substitui o conteúdo original no prompt. Essa tática é amplamente usada para manter os contextos dentro de limites e destilar as informações.
Quarentena de contexto: isole contextos sempre que possível
Isso é mais relevante em sistemas de agentes complexos ou fluxos de trabalho de múltiplas etapas. A ideia da segmentação de contexto é dividir uma grande tarefa em tarefas menores e isoladas, cada uma com seu próprio contexto, de modo que você nunca acumule um contexto enorme que contenha tudo. Cada subagente ou subtarefa trabalha em uma parte do problema com um contexto focado e, em seguida, um agente, supervisor ou coordenador de nível superior integra os resultados.
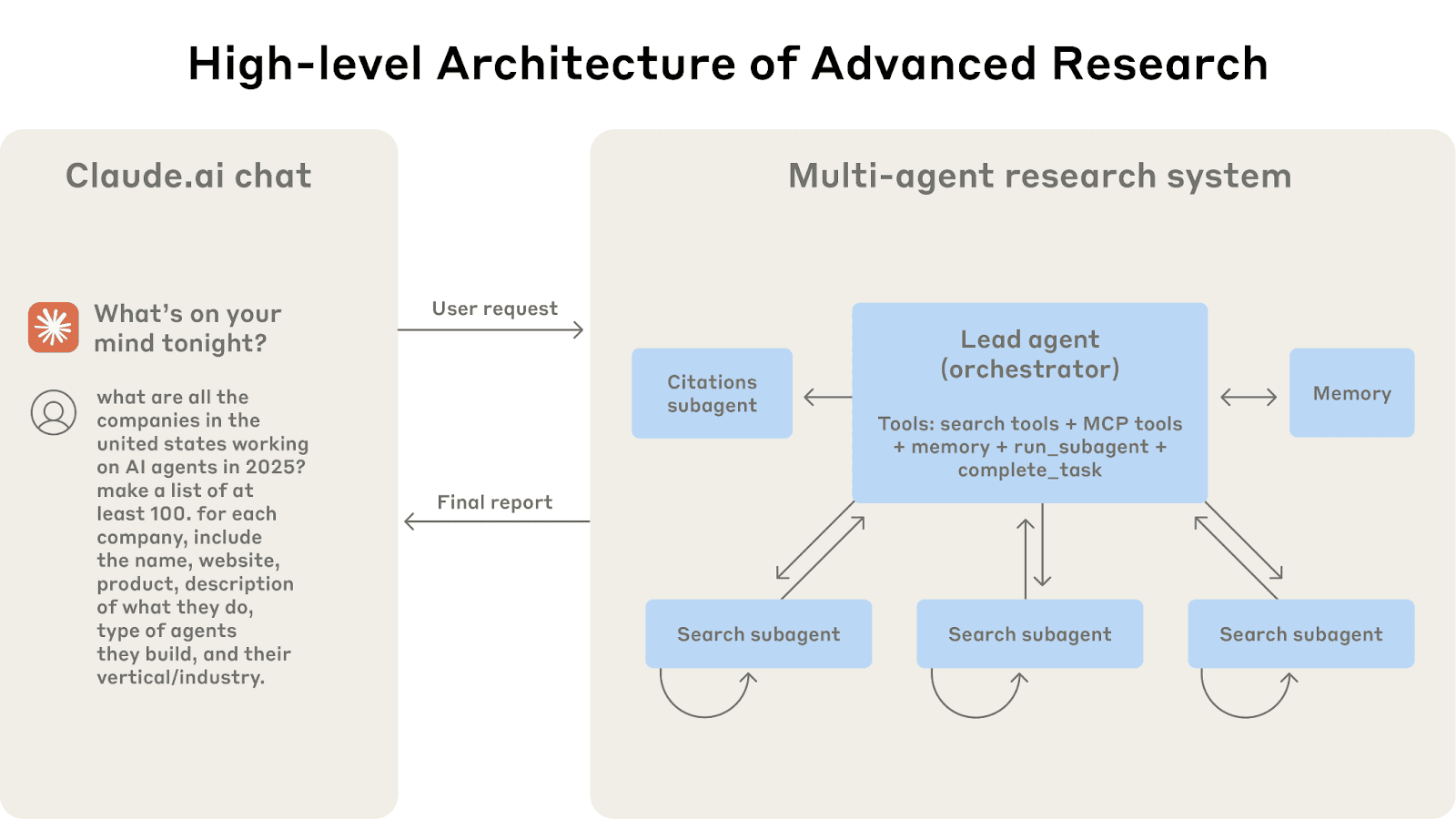
A arquitetura multiagente em ação: as consultas do usuário fluem por meio de um agente principal que cria subagentes especializados para pesquisar diferentes aspectos em paralelo.
Fonte da imagem: https://www.anthropic.com/engineering/multi-agent-research-system
A estratégia de pesquisa da Anthropic utiliza múltiplos subagentes, cada um investigando um aspecto diferente de uma questão, com suas próprias janelas de contexto, e um agente líder que lê os resultados sintetizados desses subagentes. Essa abordagem paralela e modular significa que nenhuma janela de contexto única fica excessivamente inchada. Também reduz a chance de mistura de informações irrelevantes, cada tópico permanece no tópico (sem confusão de contexto) e não carrega bagagem desnecessária ao responder sua subpergunta específica. De certa forma, é como seguir fios de pensamento separados que só compartilham seus resultados, não todo o processo de pensamento.
Em sistemas multiagente, essa abordagem é essencial. Se o Agente A estiver lidando com a tarefa A e o Agente B estiver lidando com a tarefa B, não há motivo para que um dos agentes consuma o contexto completo do outro, a menos que seja realmente necessário. Em vez disso, os agentes podem trocar apenas as informações necessárias. Por exemplo, o Agente A pode passar um resumo consolidado de suas descobertas para o Agente B por meio de um agente supervisor, enquanto cada subagente mantém seu próprio thread de contexto dedicado. Essa configuração não exige supervisão; ela depende de um agente supervisor com ferramentas habilitadas e compartilhamento de contexto mínimo e controlado.
No entanto, projetar seu sistema de modo que agentes ou ferramentas operem com a sobreposição mínima necessária de contexto pode aumentar muito a clareza e o desempenho. Pense nisso como microsserviços para IA, cada componente lida com seu contexto e você passa mensagens entre eles de forma controlada, em vez de um contexto monolítico. Essas práticas recomendadas são frequentemente usadas em combinação. Além disso, isso dá a você a flexibilidade de cortar histórico trivial, resumir mensagens ou conversas antigas importantes, transferir os logs detalhados para o Elasticsearch para contexto de longo prazo e usar a recuperação para trazer de volta qualquer coisa relevante quando necessário.
Como mencionado aqui, o princípio orientador é que o contexto é um recurso limitado e precioso. Você quer que cada token do prompt ganhe seu valor, ou seja, ele deve contribuir para a qualidade da saída. Se algo na memória não está fazendo sua parte (ou pior, causando confusão ativamente), então deve ser eliminado, resumido ou mantido fora.
Como desenvolvedores, agora podemos programar o contexto da mesma forma que programamos o código, decidindo quais informações incluir, como formatá-las e quando omiti-las ou atualizá-las. Seguindo essas práticas, podemos fornecer aos agentes LLM o contexto necessário para executar tarefas sem incorrer nas falhas descritas anteriormente. O resultado são agentes que lembram do que deveriam, esquecem o que não precisam e recuperam o que precisam a tempo.
Conclusão
Memória não é algo que você adiciona a um agente; é algo que você projeta. A memória de curto prazo é o bloco de trabalho do agente, e a memória de longo prazo é seu armazenamento de conhecimento duradouro. O RAG serve de ponte entre os dois, transformando um armazenamento de dados passivo, como o Elasticsearch, em um mecanismo de recuperação ativo que pode ancorar as saídas e manter o agente atualizado.
Mas a memória é uma faca de dois gumes. No momento em que você deixa o contexto crescer sem controle, você gera envenenamento, distração, confusão e conflitos e, em sistemas compartilhados, até mesmo vazamento de dados. Por isso, o trabalho mais importante com a memória não é "armazenar mais", mas sim "selecionar melhor": recuperar seletivamente, eliminar agressivamente, resumir cuidadosamente e evitar misturar contextos não relacionados, a menos que a tarefa realmente o exija.
Na prática, uma boa engenharia de contexto se assemelha a um bom projeto de sistemas: contextos menores e suficientes, interfaces controladas entre os componentes e uma clara separação entre o estado bruto e o estado refinado que você realmente deseja que o modelo veja. Se feito corretamente, você não acaba com um agente que lembra de tudo — você acaba com um agente que lembra das coisas certas, na hora certa, pelo motivo certo.
Conteúdo relacionado

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.
17 de março de 2026
A extensão Gemini CLI para Elasticsearch com ferramentas e recursos
Apresentamos a extensão da Elastic para a CLI Gemini do Google, que permite buscar, extrair e analisar dados do Elasticsearch em fluxos de trabalho de desenvolvedores e agentes.