新興の分野であるコンテキストエンジニアリングでは、AIエージェントに適切なタイミングで適切な情報を提供することが極めて重要です。コンテキストエンジニアリングの最も重要な側面の1つは、AIのメモリを管理することです。人間と同じように、AIシステムは情報を思い出すために短期記憶と長期記憶の両方に依存しています。大規模言語モデル(LLM)エージェントに論理的な会話をさせたり、ユーザーの好みを覚えたり、以前の結果や対応に基づいて構築させたりしたい場合は、効果的な記憶メカニズムをエージェントに装備する必要があります。
結局のところ、コンテキスト内のすべてがAIの応答に影響を与えます。「ゴミを入れたらゴミが出てくる」は真実です。
この記事では、AIエージェントにとって短期記憶と長期記憶が何を意味するのか、具体的に紹介します。
- 短期記憶と長期記憶の違い。
- Elasticsearchのようなベクトルデータベースを使用したRetrieval-Augmented Generation(RAG)手法との関係、そして慎重なメモリ管理が必要な理由。
- コンテキストオーバーフローやコンテキストポイズニングなど、メモリを軽視することによるリスク。
- エージェントのメモリを有用かつ安全に保つベストプラクティス(コンテキストのプルーニング、要約、関連するもののみの取得など)
- 最後に、Elasticsearchを使用してエージェントが混乱することなく協力できるように、マルチエージェントシステムでメモリを共有および伝播する方法について説明します。
AIエージェントにおける短期記憶と長期記憶の違い
AIエージェントの短期記憶は通常、直前の会話のコンテキストや状態を指します。本質的には、アクティブなセッションにおける現在のチャット履歴や最近のメッセージです。ユーザーの最新のクエリと最近のやり取りが含まれ、人が会話中に心に留めている情報と非常に似ています。
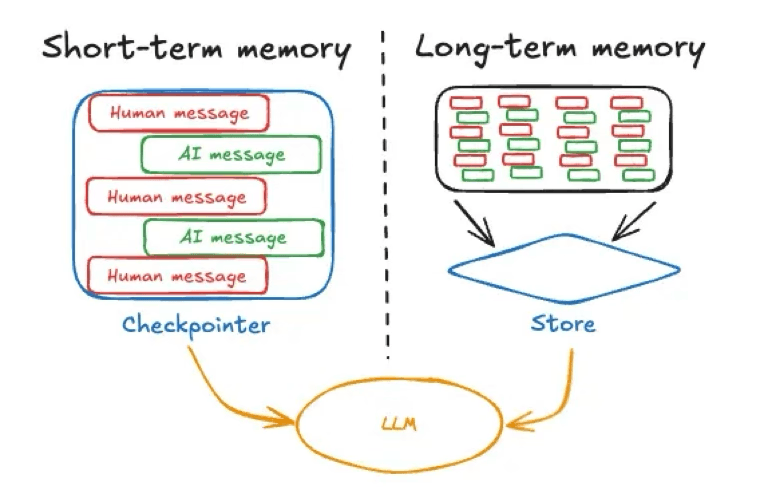
画像出典:https://langchain.ai.github.io/langgraphjs/concepts/memory
AIフレームワークは、エージェントの状態の一部としてこの一時的なメモリを保持することがよくあります(例えば、LangGraphのこの例のように、会話の状態を格納するためにチェックポインタを使用します)。短期記憶はセッション範囲に限定されます。つまり、短期記憶は単一の会話またはタスク内に存在し、明示的に他の場所に保存されない限り、そのセッションが終了するとリセットまたはクリアされます。セッションに縛られた短期記憶の例としては、ChatGPTで利用可能な一時的なチャットが挙げられます。
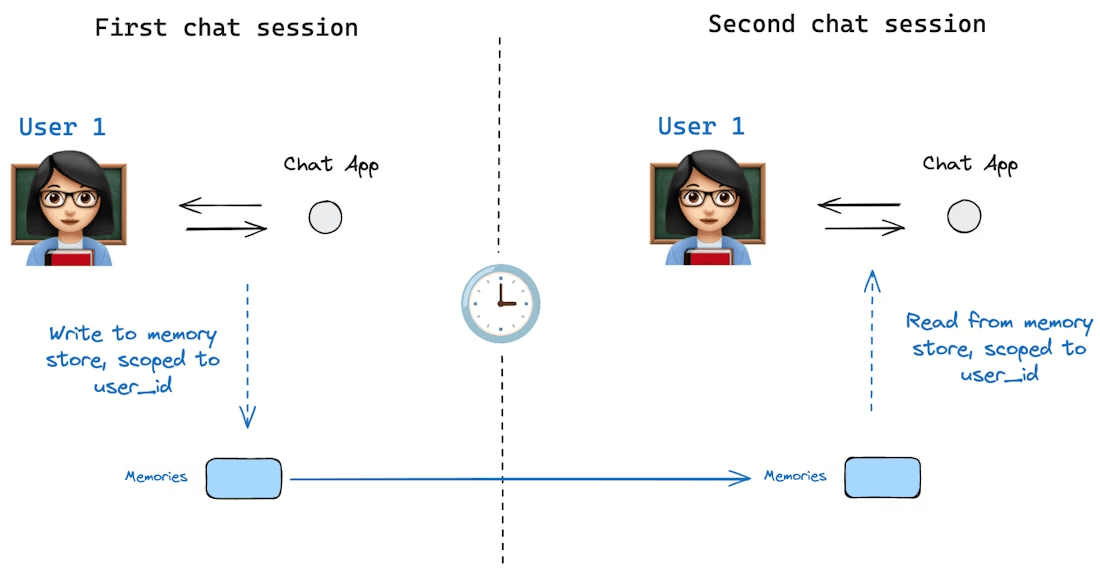
画像出典:https://docs.langchain.com/oss/python/langgraph/persistence#memory-store
一方、長期記憶とは、会話やセッションを超えて持続する情報を指します。これは、エージェントが長期にわたって保持する知識、以前に学習した事実、ユーザーの選好、または永続的に覚えておくように指示されたデータです。
長期記憶は通常、ファイルやベクトルデータベースなどの即時コンテキストウィンドウの外部にある外部ソースに格納・取得することで実装されます。短期的なチャット履歴とは異なり、長期記憶はすべてのプロンプトに自動的に含まれるわけではありません。代わりに、特定のシナリオに基づいて、エージェントは関連するツールが呼び出されたときにそれを想起したり取得したりする必要があります。実際には、長期記憶にはユーザーのプロフィール情報、エージェントが生成した過去の回答や分析、またはエージェントがクエリを実行できるナレッジベースが含まれる可能性があります。
例えば、旅行プランナーエージェントの場合、短期メモリには現在の旅行の問い合わせの詳細(日付、目的地、予算)とそのチャットでのフォローアップの質問が格納され、長期メモリにはユーザーの一般的な旅行の好み、過去の旅程、および以前のセッションで共有されたその他の事実が格納されます。ユーザーが後で戻ってきたときに、エージェントはこの長期格納場所から情報を引き出すことができます(そのユーザーはビーチや山が好きで、平均予算はINR 100,000で、行きたい場所のリストがあり、子供向けのアトラクションよりも歴史や文化を体験することを好むなど)。そのため、エージェントは毎回ユーザーを白紙の状態として扱うことはありません。
短期記憶(チャット履歴)は即時のコンテキストと継続性を提供し、長期記憶はエージェントが必要なときに利用できるより広範なコンテキストを提供します。ほとんどの先進的なAIエージェントフレームワークは、その両方を可能にします。コンテキストを保守するために最近の対話を追跡し、かつより長期的なリポジトリに情報を検索または格納するメカニズムを提供します。短期記憶を管理することで、コンテキストウィンドウ内に留まることを確保し、長期記憶を管理することで、エージェントは過去のやり取りやペルソナに基づいて回答を裏付けることができます。
コンテキストエンジニアリングにおけるメモリとRAG
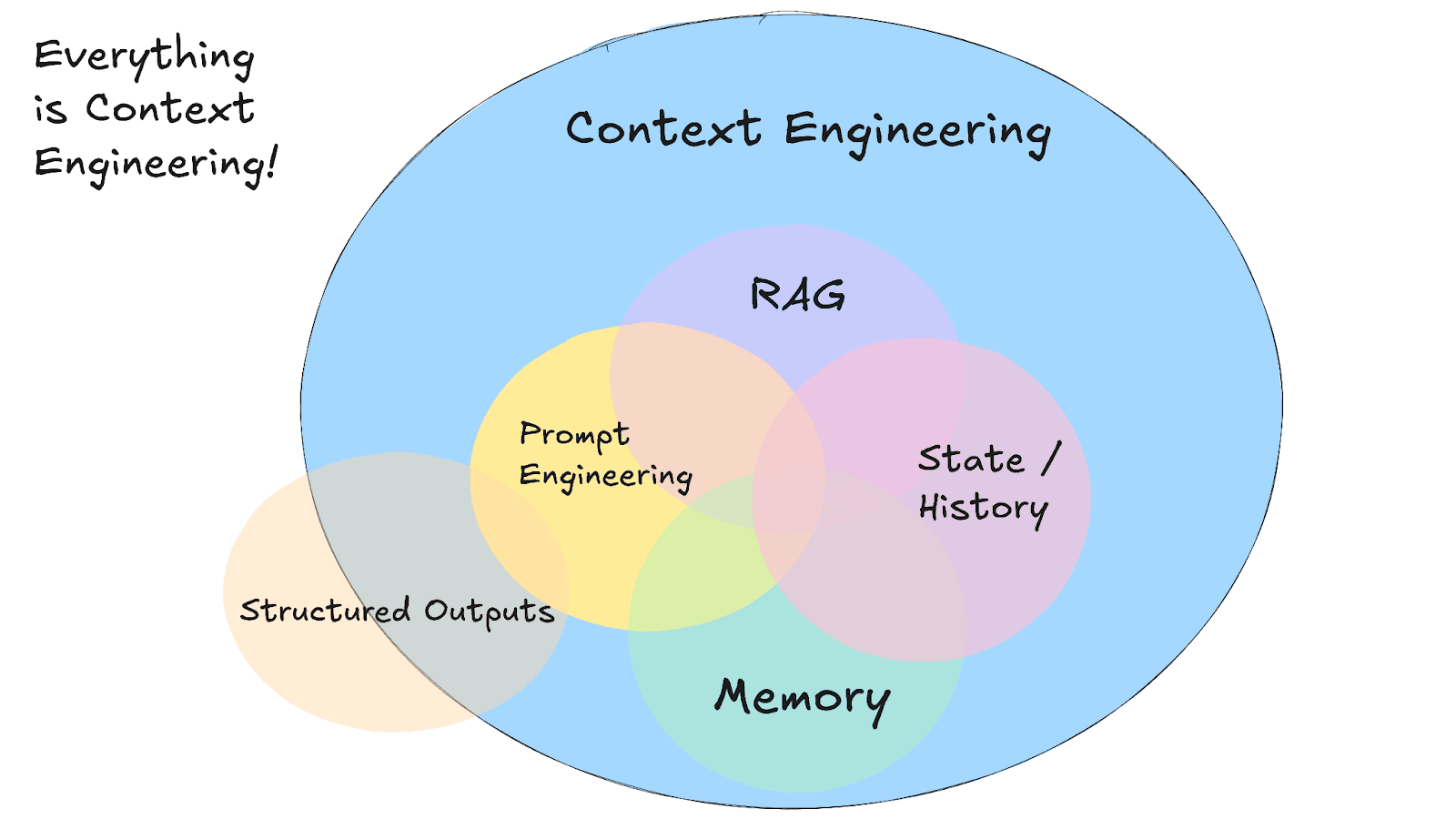
画像出典:https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-03-own-your-context-window.md
実際にAIエージェントに有用な長期記憶を与えるにはどうすればよいでしょうか?
長期記憶のための一つの顕著なアプローチはセマンティック記憶であり、しばしば検索拡張生成(RAG)を介して実装されます。これには、LLMを外部のナレッジストアやElasticsearchなどのベクトル対応データストアと結合することが含まれます。LLMは、プロンプトや組み込みのトレーニングの内容以外の情報を必要とする場合、Elasticsearchに対してセマンティック検索を実行し、最も関連性の高い結果をコンテキストとしてプロンプトに注入します。このように、モデルの効果的なコンテキストには、最近の会話(短期記憶)だけでなく、その場で得られた関連する長期的事実も含まれます。その後、LLMは、独自の推論と取得した情報の両方に基づいて回答を決定し、短期記憶と長期記憶を効果的に組み合わせて、より正確でコンテキストを意識した応答を生成します。
ElasticsearchはAIエージェントの長期記憶実装にも利用できます。長期記憶のためにElasticsearchからコンテキストを取得する方法の高次的な例を示します。
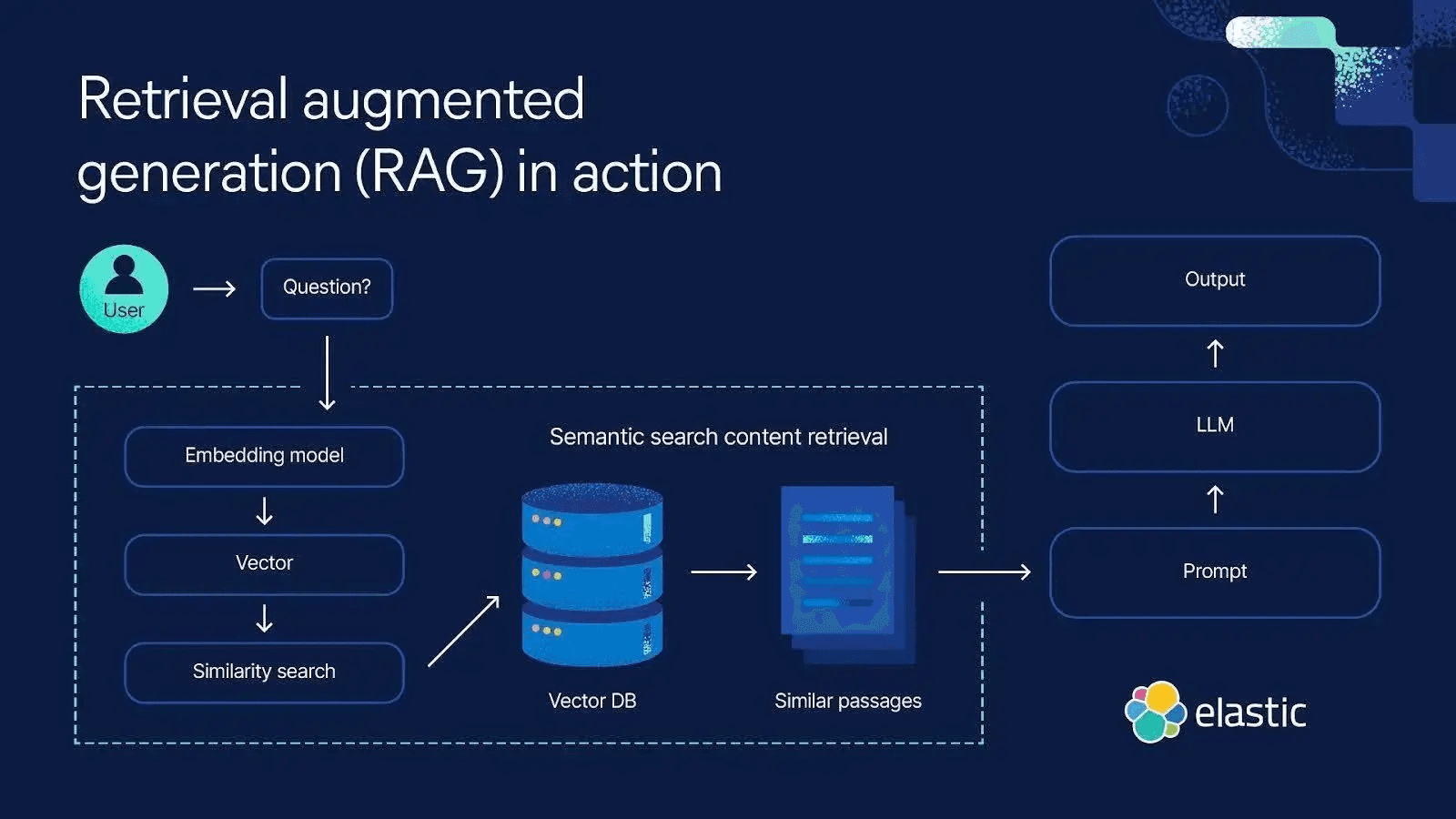
このように、エージェントはさまざまなリスクにつながる限られたプロンプト内にすべてを格納するのではなく、関連するデータを検索することによって「思い出し」ます。
RAGをElasticsearchや任意のベクトルストアで使用することで、多くの利点が得られます。
第一に、モデルのトレーニングのカットオフを超えて知識を拡張できます。エージェントは、LLMが知らない可能性のある最新の情報やドメイン固有のデータを取得できます。これは最近の出来事や専門的なトピックに関する質問に非常に重要です。
第二に、オンデマンドでコンテキストを取得することで、ハルシネーションを減らすことができます。特に、LLMはニッチなユースケースに関連する独自データや高度に専門化されたデータでトレーニングされていないため、ハルシネーションが発生する可能性が非常に高いです。LLMが評価によって推測や新しい情報を作り出すのではなく、最近のOpenAIの論文(Why Language Models Hallucinate)で指摘されているように、このモデルはElasticsearchの事実に基づく参照に基づいています。当然ながら、LLMはベクトルストアのデータの信頼性に依存しており、誤情報を確実に防御するために、コアの関連性指標に基づいて関連データが取得されます。
第三に、RAGを使用すると、エージェントはプロンプトに収めることができるものよりもはるかに大きなナレッジベースを扱うことができます。長い研究論文や政策文書のように、文書全体をコンテキストウィンドウに押し込んで過剰負荷や無関係な情報コンテキストがモデルの推論を損なうコンテキストポイズニングを招くことなく、RAGはチャンク化に依存します。大きな文書は意味的に意味のある小さな部分に分割され、システムはクエリに最も関連性の高い少数のチャンクのみを取得します。この方法では、モデルが知識豊富であることを示すために100万トークンのコンテキストを必要とせず、はるかに大規模なコーパスの適切なチャンクにアクセスするだけで済みます。
注目すべきは、LLMのコンテキストウィンドウが拡大し(一部のモデルは現在、数十万または数百万のトークンをサポート)、RAGの「終焉」についての議論が起きたことです。なぜすべてのデータをプロンプトに押し込まないのでしょうか。同じようにお考えなら、同僚のJeffrey RengifoとEduard Martinによるこの素晴らしい記事「コンテキストは長ければよいわけではない:RAGが引き続き重要な理由」を参照してください。これにより、「ゴミを入れればゴミが出てくる」問題を回避できます。LLMは、ノイズを処理するのではなく、重要な少数のチャンクに焦点を合わせ続けます。
とはいえ、Elasticsearchやその他のベクトルストアをAIエージェントのアーキテクチャに統合することで、長期記憶が可能になります。エージェントは知識を外部に格納し、必要に応じてメモリコンテキストとして取り込みます。これは、各ユーザークエリの後、エージェントがElasticsearchで関連情報を検索し、LLMを呼び出す前にプロンプトに上位の結果を追加するアーキテクチャとして実装することができます。応答に新しい有用な情報が含まれている場合、その応答は長期保存されることもあります(学習のフィードバックループが作成されます)。そのような検索ベースのメモリを使用することで、エージェントは、コンテキストウィンドウが100万トークンをサポートしている場合であっても、常に情報を得て最新の状態を保ちながら、すべての知識をすべてのプロンプトに詰め込む必要がなくなります。この技術は、情報検索と生成AIの強みを組み合わせたコンテキストエンジニアリングの基礎となるものです。
これは、セッション中の短期記憶にLangGraphのチェックポイントシステムを使用して管理されたメモリ内会話状態の例です。(当社のコンテキストエンジニアリングをサポートするアプリを参照してください。)
checkpointの格納方法は以下の通りです。
長期記憶については、Elasticsearchでセマンティック検索を実行し、チェックポイントを要約して Elasticsearchにインデックス付けした後、ベクトル埋め込みを使用して関連する以前の会話を取得する方法を次に示します。
ElasticsearchのLangGraphのチェックポイントを使用して、短期記憶と長期記憶がどのようにインデックス化され、取得されるかを調べてきました。さて、少し時間を取って、会話全体をインデキシングしてダンプすることがなぜ危険なのかを理解しましょう。
コンテキストメモリを管理しないことのリスク
コンテキストエンジニアリング、短期記憶、長期記憶について詳しく説明しているので、エージェントのメモリとコンテキストを適切に管理しないと何が起こるかを理解しましょう。
残念ながら、AIのコンテキストが非常に長くなったり、悪い情報が含まれたりすると、多くの問題が発生する可能性があります。コンテキストウィンドウが大きくなるにつれて、次のような新しい障害モードが発生します。
- コンテキストポイズニング
- コンテキストの逸脱
- コンテキストの混乱
- コンテキストの衝突
- コンテキスト漏洩と知識対立
- ハルシネーションと誤情報
これらの問題や、不適切なコンテキスト管理から生じるその他のリスクを分解して見ていきましょう。
コンテキストポイズニング
コンテキストポイズニングとは、不正確または有害な情報がコンテキストに入り込み、モデルのその後の出力を「汚染」してしまうことを指します。よくある例としては、モデルによるハルシネーションが事実として扱われ、会話履歴に挿入されることがあります。モデルはその後、そのエラーを元に対応を構築し、誤りを複合化させることがあります。反復的なエージェントループでは、共有コンテキスト(エージェントの作業メモの要約など)に誤った情報が入ると、その情報が何度も強化されることがあります。
DeepMindの研究者は、Gemini 2.5レポート(概略はここをチェック)のリリース時に長年ポケモンをプレイしているエージェントでこれを観察しました。エージェントが間違ったゲーム状態のハルシネーションを起こし、それがそのコンテキスト(ゴールの記憶)に記録された場合、エージェントは不可能な目標に関する無意味な戦略を立て、行き詰まってしまいます。言い換えれば、汚染された記憶はエージェントを永久に誤った道へと導く可能性があるのです。
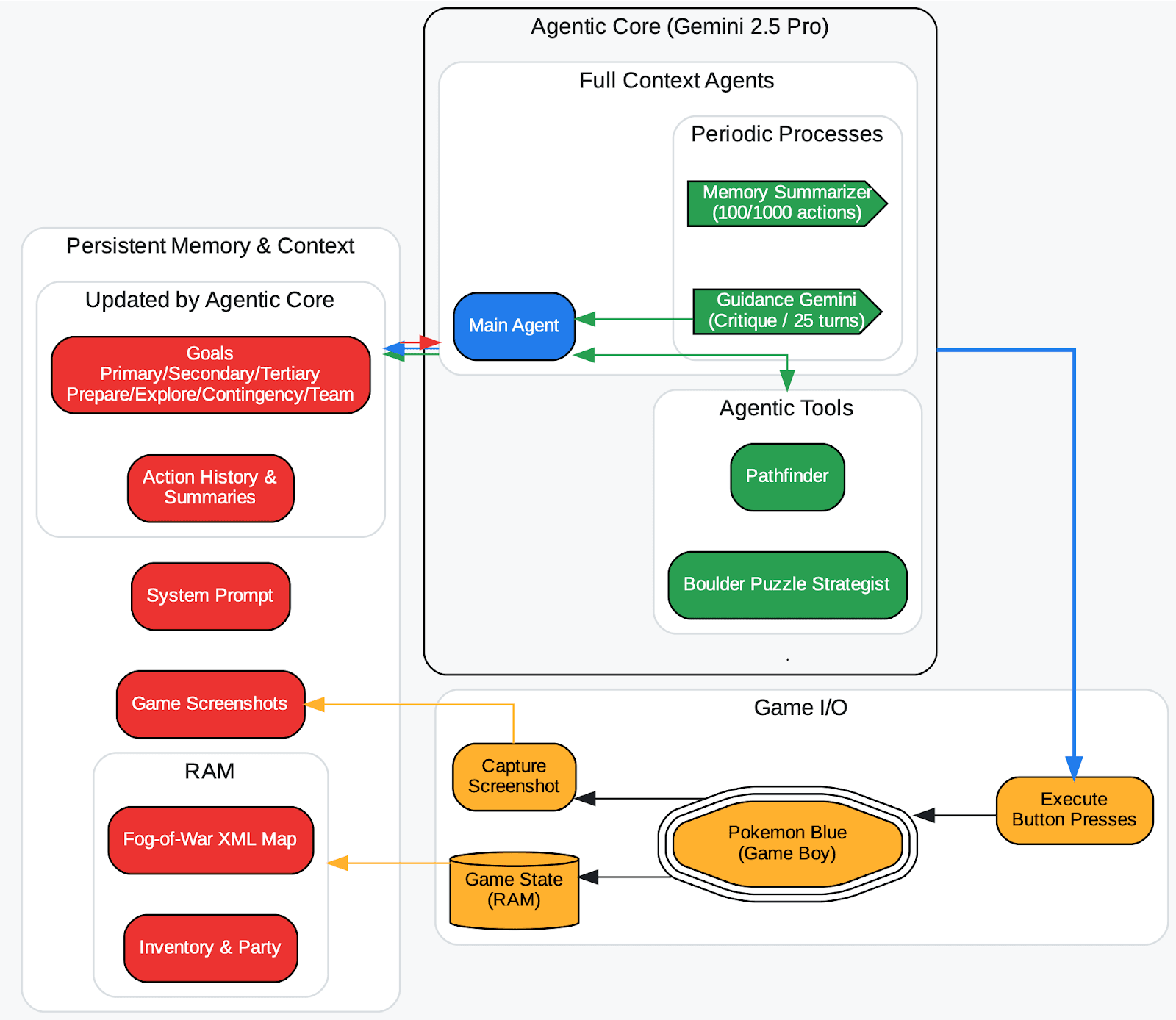
エージェントハーネスの概要(Zhang, 2025)。オーバーワールドのフォグ・オブ・ウォーマップでは、探索したタイルが自動的に保存され、訪問済みカウンターでラベル付けされます。タイルの種類はRAMから記録されます。エージェントツール(pathfinder、 boulder_puzzle_strategist)はGemini 2.5 Proのプロンプトインスタンスです。pathfinderはナビゲーションに使用され、 boulder_puzzle_strategist Victory Roadダンジョンのボルダーパズルを解きます。
画像出典:https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - ページ68
コンテキストポイズニングは、無意識のうちに(誤って)発生する可能性があるだけでなく、悪意を伴ってを発生する可能性もあります。例えば、プロンプトインジェクション攻撃では、ユーザーや第三者が隠れた指示や虚偽の事実を忍び込ませ、エージェントがそれを記憶し、従うようにします。
推奨される対策:
Wiz、Zerlo、Anthropicからの洞察に基づき、コンテキストポイズニングの対策は、LLMのプロンプト、コンテキストウィンドウ、検索パイプラインに悪い情報や誤解を招く情報が入らないようにすることに重点を置いています。主な手順は次のとおりです。
- 常にコンテキストを確認する:開始プロンプトだけでなく、不審な点や有害な点がないか、会話や検索されたテキストを監視します。
- 信頼できるソースを使用する:信頼性に基づいて文書にスコアを付けたりラベルを付けたりすることで、システムは信頼性の高い情報を優先し、スコアの低いデータを無視します。
- 異常なデータを見つける:奇妙なもの、場違いなもの、または操作されたコンテンツを検出するツールを使用し、モデルが使用する前に削除します。
- 入力と出力をフィルターする: 有害または誤解を招くテキストがシステムに簡単に入力されたり、モデルによって繰り返されたりしないようにガードレールを追加します。
- モデルをクリーンなデータで最新の状態に保つ:検証済みの情報で定期的にシステムを更新して、流出してしまった不良データに対処します。
- 人間が関与する:重要な出力を人間が確認したり、既知の信頼できるソースと比較したりします。
長いチャットをリセットし、関連情報のみを共有し、複雑なタスクを小さなステップに分割し、モデル外で明確なメモを維持するなど、使用時のシンプルな習慣も役立ちます。
これらの対策を組み合わせることで、コンテキストポイズニングからLLMを保護し、出力の正確性と信頼性を維持する階層化された防御が実現します。
ここに記載されている対策を講じないと、エージェントは以前のガイドラインや攻撃者が挿入した些細な事実を無視するなどの指示を覚えてしまい、有害な出力につながることがあります。
コンテキストの逸脱
コンテキストの逸脱とは、コンテキストが長くなりすぎて、モデルがコンテキストに過度に集中し、トレーニング中に学習した内容を無視してしまうことです。極端な場合、これは壊滅的な忘却のようになります。この場合、モデルは基本的な知識を「忘れ」、目の前にある情報に過度に依存するようになります。過去の研究では、プロンプトが非常に長いとLLMが焦点を失うことが多いことが示されています。
例えば、Gemini 2.5エージェントは100万トークンのウィンドウをサポートしていましたが、そのコンテキストが特定のポイント(実験では約10万トークン)を超えると、新しいソリューションを思いつく代わりに、過去の行動を繰り返すことに固執し始めました。ある意味、エージェントはその長い歴史の囚人となったのです。基礎となるトレーニング知識を活用して斬新な戦略を考案するのではなく、以前の動作の長いログ(コンテキスト)を見てそれを真似し続けました。

これでは逆効果です。私たちは、モデルが思考能力を無効にするのではなく、推論を助けるために関連コンテキストを使用することを望んでいます。注目すべきは、巨大なウィンドウを持つモデルでさえ、トークンが追加されるにつれて、パフォーマンスが不均一に低下するというコンテキスト腐敗を示すことです。ここには注意予算が見られるようです。つまり、人間の作業記憶が限られているように、LLMがトークンに注意を払う能力も有限であり、その予算が限界に達すると、その精度と焦点が低下します。
緩和策として、チャンキング、適切な情報のエンジニアリング、定期的なコンテキストの要約、応答の正確性を測定するための評価とモニタリング技術を使用して、コンテキストの逸脱を防止できます。
これらの方法により、モデルは関連するコンテキストとその基礎となるトレーニングの両方に基盤を置くようになり、逸脱のリスクが軽減され、全体的な推論品質が向上します。
コンテキストの混乱
コンテキストの混乱とは、コンテキスト内の余分なコンテンツがモデルによって使用され、低品質の対応が生成されることです。代表的な例としては、エージェントが使用する可能性のある大量のツールやAPI定義をエージェントに提供することが挙げられます。それらのツールの多くが現在のタスクと無関係であっても、モデルはコンテキスト内に存在するという理由だけで、それらを不適切に使用しようとする可能性があります。実験によると、必要でないツールやドキュメントを多く提供すると、パフォーマンスが低下することがわかっています。エージェントは、間違った関数を呼び出したり、無関係なテキストを参照したりするなどの間違いを犯し始めます。
あるケースでは、小型のLlama 3.1 8Bモデルは、検討すべきツールが46個与えられたときにはタスクに失敗しましたが、19個のツールしか与えられなかったときには成功しました。コンテキストが長さ制限内であったにもかかわらず、追加のツールによって混乱が生じました。根本的な問題は、プロンプト内のすべての情報がモデルに処理されることです。何かを無視するべきことを認識していない場合、その何かが望ましくない方法で出力に影響を及ぼす可能性があります。無関係な部分がモデルの注意の一部を「奪い」、誤った方向に導くことがあります(無関係な文書によってエージェントが尋ねられた質問とは異なる質問に答えるなど)。コンテキストの混乱は、しばしばモデルが無関係なコンテキストを統合した低品質の応答を生成することとして現れます。研究論文「Less is More: Optimizing Function Calling for LLM Execution on Edge Devices.」を参照してください。
これは、特に関連性を重視して厳選されていない場合、コンテキストが多ければ多いほど良いとは限らないことを想起させます。
コンテキストの衝突
コンテキストの衝突は、コンテキストの部分が互いに矛盾し、モデルの推論を脱線させる内部不整合が発生するときに起こります。エージェントが矛盾する複数の情報を蓄積すると、衝突が発生することがあります。
例えば、あるエージェントが2つのソースからデータを取得したとします。1つは午後5時にA便が出発するというもので、もう1つは午後6時にA便が出発するというものです。両方の事実がコンテキスト内に存在する場合、貧弱なモデルではどちらが正しいのかを判断できず、混乱したり、不正確な回答や類似しない回答を生成したりする可能性があります。
コンテキストの衝突は、モデルの過去の回答の試みが、その後の洗練された情報とともにコンテキスト内に残っている、マルチターンの会話でも頻繁に発生します。

画像出典:LLMS gets lost in the mult-turn conversation (ページ4)
MicrosoftとSalesforceの研究によると、複雑なクエリを複数のチャットボットターンに分割して詳細を徐々に追加すると、単一のプロンプトですべての詳細を伝える場合と比べて、最終的な精度が大幅に低下することが示されています。なぜでしょうか。初期のターンにモデルからの部分的なまたは不正確な中間回答が含まれており、それらはコンテキスト内に残るためです。モデルが後ですべての情報を使用して回答しようとすると、そのメモリにはまだそれらの誤った試行が含まれており、修正された情報と矛盾して軌道から外れてしまいます。本質的に、会話のコンテキストが自己衝突しているのです。このモデルは、新しい情報が追加された後には適用されない古いコンテキスト(以前のターンからの)を誤って使用してしまう可能性があります。
エージェントが異なるツールやサブエージェントからの出力を組み合わせる可能性があるエージェントシステムでは、コンテキストの衝突は特に危険です。これらの出力が一致しない場合、集約された文脈は一貫性がありません。すると、エージェントは行き詰まったり、矛盾を調整しようとして無意味な結果を生成する可能性があります。コンテキストの衝突を防ぐには、コンテキストが新鮮で一貫していること、例えば、古い情報をクリアまたは更新し、一貫性がないソースを混ぜないことが重要です。
コンテキスト漏洩と知識対立
システムで複数のエージェントやユーザーがメモリストアを共有する場合、コンテキスト間で情報が漏れるリスクがあります。
例えば、適切なアクセス制御がないまま、2人の異なるユーザーのデータ埋め込みが同じベクトルデータベースに存在する場合、ユーザーAのクエリに応答するエージェントが、誤ってユーザーBのメモリの一部を取得する可能性があります。この クロスコンテキスト漏洩 は、個人情報を漏洩させたり、対応に混乱を生じさせたりする可能性があります。
OWASP Top 10 for LLM Applicationsによれば、マルチテナントベクトルデータベースは次のような漏洩を防ぐ必要があります。
LLM08:2025 Vector and Embedding Weaknessesによると、一般的なリスクの1つはコンテキストの漏洩です。
マルチテナント環境では、複数のクラスのユーザーやアプリケーションが同じベクトルデータベースを共有するため、ユーザーやクエリ間でコンテキストが漏洩するリスクがあります。データフェデレーション知識の矛盾エラーは、複数のソースからのデータが矛盾し合う場合に発生します。これは、LLMがトレーニング中に学習した古い知識を検索拡張からの新しいデータで置き換えることができない場合にも発生する可能性があります。
もう一つの側面は、LLMがメモリからの新しい情報で組み込まれた知識を上書きするのに苦労する可能性があることです。モデルが何らかの事実に基づいてトレーニングされていて、取得したコンテキストが逆の場合、モデルはどちらを信頼すべきか混乱する可能性があります。適切な設計がないと、エージェントがコンテキストを混同したり、古い知識を新しい証拠で更新できなかったりして、古くなった回答や間違った回答につながる可能性があります。
ハルシネーションと誤情報
ハルシネーション(LLM がもっともらしく聞こえるが誤った情報を生成すること)は、コンテキストが長くなくても既知の問題ですが、メモリ管理が不十分だと増幅される可能性があります。
エージェントのメモリに重要な事実が欠けている場合、モデルは単にその空白を推測で埋める可能性があり、その推測がコンテキストに入り込む(汚染)と、エラーが持続します。
OWASPのLLMセキュリティレポート(LLM09:2025 Misinformation)では、誤情報が主な脆弱性として強調されています。LLMは自信を持って虚偽の回答を生成する可能性があり、ユーザーはそれらを過度に信頼する可能性があります。長期記憶が不良または古くなっているエージェントは、その記憶が最新の状態に保たれていない限り、昨年は真実であったが現在は間違っていることを自信を持って引用する可能性があります。
(ループ内のユーザーまたはエージェント自体による)AIの出力への過度の依存は、この問題を悪化させる可能性があります。誰もメモリの情報を確認しなければ、エージェントは虚偽を蓄積してしまう可能性があります。RAGがハルシネーションを抑えるためによく使われるのはこのためです。信頼できる情報源を検索することで、モデルは事実を捏造する必要がなくなります。しかし、検索によって間違った文書(誤った情報が含まれている文書など)が取得されたり、初期のハルシネーションが除去されなかったりすると、システムはその誤った情報をその動作全体に伝播してしまう可能性があります。
肝心なことは、メモリの管理に失敗すると、不正確で誤解を招く出力につながる可能性があり、特にリスクが高い場合(金融や医療分野での誤ったアドバイスなど)には損害を与える可能性があります。エージェントには、コンテキスト内のあらゆるものを無条件に信頼するだけでなく、メモリの内容を検証または修正するためのメカニズムが必要です。
まとめると、成功の秘訣は、AIエージェントに無限に長いメモリを与えたり、ありとあらゆるものをそのコンテキストに放り込んだりすることではありません。
LLMアプリケーションにおけるメモリ管理のベストプラクティス
上記の陥穽を避けるために、開発者と研究者はAIシステムでコンテキストとメモリを管理するためのベストプラクティスをいくつか考案しました。これらのプラクティスは、AIの動作コンテキストを無駄なく、関連性があり、最新の状態に保つことを目的としています。ここでは、いくつかの重要な戦略と、それがどのように役立つかの例を示します。
RAG:ターゲットを絞ったコンテキストを使用する
RAGの大部分についてはすでに前のセクションで説明しましたので、このセクションは実用的な注意事項を簡潔にまとめたものです。
- ターゲットを絞った検索を使用し、一括読み込みは避ける:全文書や会話の履歴全体をプロンプトにプッシュするのではなく、最も関連性の高い部分のみを取得します。
- RAGをジャストインタイムのメモリ呼び出しとして扱う:ターンを超えてすべてを転送するのではなく、必要なときにのみコンテキストを取得します。
- 関連性に注意した検索戦略を優先する:トップkセマンティック検索、逆順位融合、ツールロードアウトフィルタリングなどのアプローチは、ノイズを減らし、グラウンディングを改善するのに役立ちます。
- コンテキストウィンドウが大きくなってもRAGは必要:2つの非常に関連性の高い段落は、20の緩く関連したページよりもほとんど常に効果的です。
つまり、RAGではコンテキストを増やすことではなく、適切なコンテキストを追加することが重要なのです。
ツールのロードアウト
ツールのロードアウトとは、モデルにタスクに実際に必要なツールのみを与えることです。この用語はゲームに由来し、状況に合った装備を選ぶというものです。ツールが多すぎると作業が遅くなり、間違ったツールを使用すると失敗の原因になります。研究論文「Less is more」によると、LLMも同様に動作します。ツールが30個を超えると、説明が重複し始め、モデルが混乱します。ツールの数が約100個を超えると、失敗はほぼ確実です。これはコンテキストウィンドウの問題ではなく、コンテキストの混乱です。
シンプルで効果的な解決策となるのがRAG-MCPです。すべてのツールをプロンプトにダンプする代わりに、ツールの説明はベクトルデータベースに保存され、リクエストごとに最も関連性の高いものだけが取得されます。実際には、これにより、ロードアウトが小さく集中したものになり、プロンプトが大幅に短縮され、ツール選択の精度が最大3倍向上します。
小型モデルでは、この壁にぶつかるのがさらに早くなります。調査によると、8Bモデルは数十個のツールでは失敗しますが、ロードアウトを調整すると成功します。場合によっては最初にLLMを使用して、必要と思われるツールを動的に選択すると、パフォーマンスが44%向上し、電力使用量とレイテンシも削減されます。重要な点は、ほとんどのエージェントはわずかなツールしか必要としないものの、システムが成長するにつれて、ツールのロードアウトとRAG-MCPが第一の設計上の決定事項になるということです。
コンテキストのプルーニング:チャット履歴の長さを制限する
会話が何ターンも続くと、蓄積されたチャット履歴が大きすぎて収まらなくなり、コンテキストがオーバーフローしたり、モデルの注意が散漫になったりします。
トリミングとは、会話が長くなるにつれて、重要度の低い部分をプログラムで削除または短縮することを指します。単純な形式としては、一定の制限に達したときに会話の最も古いターンを削除し、最新のN件のメッセージのみを保持する方法があります。より高度なプルーニングにより、無関係な余談や不要になった以前の指示を削除することもあります。目標は、コンテキストウィンドウが古いニュースで煩雑にならないようにすることです。
例えば、エージェントが10ターン前にサブ問題を解決し、その後先に進んだ場合、コンテキストから履歴のその部分を(それ以上必要ないという前提で)削除することがあります。多くのチャットベースの実装では、最近のメッセージのローリングウィンドウを維持することでこれを実行します。
トリミングは、会話の最初の部分を、要約したり、無関係だと判断したりした後に「忘れる」という単純な作業である場合もあります。そうすることで、コンテキストオーバーフローエラーのリスクが軽減され、コンテキストの逸脱も軽減されるため、モデルが古いコンテンツやトピック外のコンテンツを見つけて脇道に逸れることがなくなります。このアプローチは、人間が1時間の講演のすべての単語を覚えているわけではないものの、重要な部分は覚えているということと非常によく似ています。
作者のDrew Breunigがここで強調しているように、コンテキストプルーニングについて混乱している場合は、質問応答用の軽量(1.75 GB)、効率的で正確なコンテキストプルーナーであるProvence(`naver/provence-reranker-debertav3-v1`)モデルを使用すると違いが出る可能性があります。大きな文書を特定のクエリに最も関連性の高いテキストだけに絞り、特定の間隔で呼び出すことができます。
コード内で`provence-reranker`モデルを呼び出してコンテキストをプルーニングする方法は次のとおりです。
文の関連性のスコア付けにはProvenceリランカーモデル(`naver/provence-reranker-debertav3-v1`)を使用します。しきい値ベースのフィルタリングにより、関連性しきい値を超える文が保持されます。また、プルーニングが失敗した場合に元のコンテキストに戻るフォールバックメカニズムも導入します。最後に、統計ログが詳細モードで削減率を追跡します。
コンテキストの要約:古い情報を完全に削除するのではなく、要約する
要約はトリミングの相棒です。履歴やナレッジベースが大きくなりすぎた場合は、LLMを使用して重要なポイントの簡単な要約を作成し、上記のコードで実行したように、今後のコンテンツ全体の代わりにその要約を使用できます。
例えば、AIアシスタントが50ターンの会話を行った場合、51ターン目に50ターンすべてをモデルに送信するのではなく(おそらく収まりません)、システムは1ターン目から40ターン目までを取得し、モデルにそれらを段落に要約させてから、次のプロンプトでその要約と最後の10ターンのみを提供する可能性があります。こうすることで、モデルはすべての詳細を必要とせずに議論内容を把握できます。初期のチャットボットのユーザーは、「これまでの話を要約してくれますか?」と尋ね、要約した内容を新しいセッションで継続することで、これを手動で行っていました。今ではこれを自動化できます。要約はコンテキストウィンドウのスペースを節約するだけでなく、余分な詳細を削除して重要な事実だけを保持することでコンテキストの逸脱や混乱を減らすこともできます。
OpenAIのモデル(どんなLLMでも使用可能)を使って、すべての関連情報を保持しながらコンテキストを凝縮し、冗長性や重複を排除する方法を紹介します。
重要なのは、コンテキストを要約すると、モデルが些細な詳細や過去のエラーに圧倒されにくくなることです(要約が正確であれば)。
しかし、要約は慎重に行わなければなりません。悪い要約は重要な部分を省略したり、エラーを生じさせたりすることがあります。これは本質的にはモデルに対する別のプロンプト(「これを要約してください」)なので、ハルシネーションを起こしたり、ニュアンスが失われたりする可能性があります。ベストプラクティスとしては、段階的に要約し、一部の標準的な事実は要約しないままにしておくことが挙げられます。
それでも非常に有用であることが証明されています。Geminiエージェントのシナリオでは、約10万トークンごとにコンテキストを要約することが、モデルの繰り返し傾向に対抗する方法でした。要約は会話やデータの圧縮された記憶のように機能します。開発者としては、エージェントに会話履歴や長いドキュメントの要約機能(おそらく小さなLLMまたは専用ルーティン)を定期的に呼び出させることでこれを実装できます。結果の要約はプロンプト内の元のコンテンツに置き換えられます。この戦術は、コンテキストを制限内に保ち、情報を精査するために広く使用されています。
コンテキストの隔離:可能な限りコンテキストを隔離する
これは複雑なエージェントシステムや多段階のワークフローでより重要です。コンテキストセグメンテーションの考え方は、大きなタスクを、それぞれ独自のコンテキストを持つ小さな独立したタスクに分割し、すべてが含まれる1つの巨大なコンテキストが蓄積されないようにすることです。各サブエージェントまたはサブタスクは、焦点を絞ったコンテキストで問題の一部に取り組み、その後、上位レベルのエージェント、スーパーバイザー、またはコーディネーターが結果を統合します。
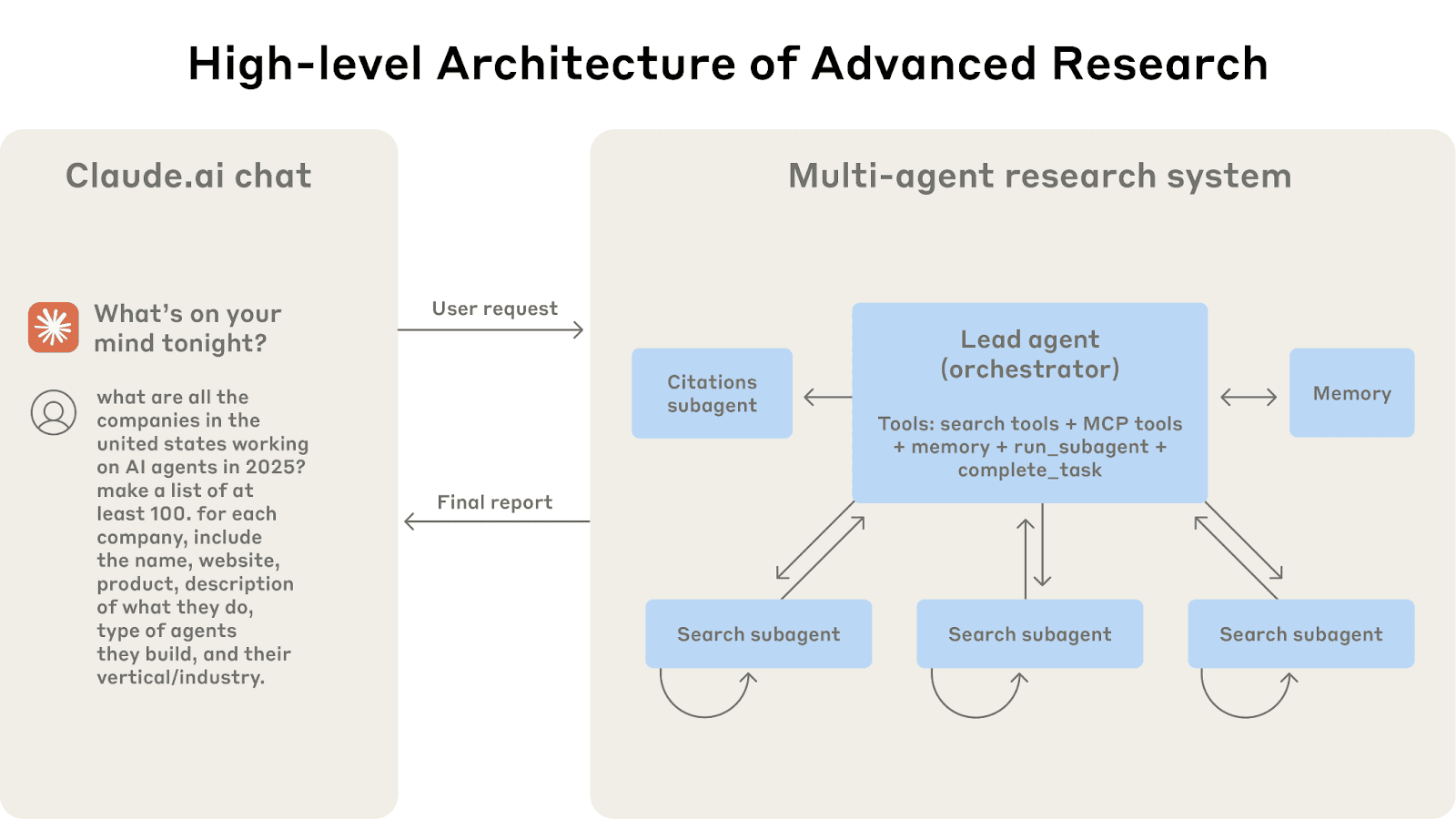
マルチエージェントアーキテクチャの動作:ユーザークエリは、リードエージェントを通過し、異なる側面を並行して検索する特殊なサブエージェントを作成します。
画像出典:https://www.anthropic.com/engineering/multi-agent-research-system
Anthropicの研究戦略はそれぞれが異なる質問の側面を調査し、それぞれのコンテキストウィンドウを持つ複数のサブエージェントと、そのサブエージェントから抽出された結果を読み取るリードエージェントを用います。この並列のモジュール方式のアプローチにより、単一のコンテキストウィンドウが肥大化することはありません。また、無関係な情報が混ざる可能性も減り、各スレッドはトピックに沿って進み(コンテキストの混乱がなく)、特定のサブ質問に答えるときに不必要な負担がかかりません。ある意味、それは思考プロセス全体ではなく、結果だけを共有する別々の思考スレッドを実行するようなものです。
マルチエージェントシステムでは、このアプローチは不可欠です。エージェントAがタスクAを処理し、エージェントBがタスクBを処理する場合、本当に必要な場合を除き、どちらのエージェントも他方のエージェントの完全なコンテキストを使用する理由はありません。代わりに、エージェントは必要な情報だけを交換できます。例えば、エージェントAは、その調査結果の統合された要約をスーパーバイザーエージェントを介してエージェントBに渡すことができますが、各サブエージェントは独自の専用コンテキストスレッドを維持します。この設定では、人間による介入は必要ありません。最小限かつ制御されたコンテキスト共有を備えたツールが有効になっているスーパーバイザーエージェントに依存します。
にもかかわらず、エージェントやツールが最小限の必要なコンテキストオーバーラップで動作するようにシステムを設計することで、明確さとパフォーマンスを大幅に向上させることができます。これをAI用のマイクロサービスと考えると、各コンポーネントがそれぞれのコンテキストを処理し、1 つのモノリシックなコンテキストではなく、制御された方法でコンポーネント間でメッセージを渡すことができます。これらのベストプラクティスは、多くの場合、組み合わせて使用されます。また、これにより、些細な履歴をトリミングしたり、重要な古いメッセージや会話を要約したり、長期的なコンテキストのために詳細なログをElasticsearchにオフロードしたり、必要なときに関連するものを取得して戻したりする柔軟性が得られます。
ここで述べたように、コンテキストは限られた貴重なリソースであるというのが基本原則です。プロンプト内のすべてのトークンがその価値を生むようにし、出力の品質に貢献させる必要があります。メモリ内の何かが役に立たない場合(さらに悪いことに、積極的に混乱を引き起こしている場合も)、そのメモリは削除、要約、削除する必要があります。
開発者として、現在の私たちは、コードをプログラムするのと同じようにコンテキストをプログラムし、含める情報、そのフォーマット方法、および省略または更新するタイミングを決定できます。これらのプラクティスに従うことで、LLMエージェントに、前述の障害モードの被害に遭うことなくタスクを実行するために必要なコンテキストを提供できます。その結果、エージェントは必要なことを記憶し、不要なことを忘れ、必要な情報を必要なタイミングで取得できるようになります。
まとめ
メモリはエージェントに追加するものではなく、設計するものです。短期メモリはエージェントの一時的な作業領域であり、長期メモリはその永続的な知識格納場所です。RAGは2つの間の架け橋であり、Elasticsearchのようなパッシブデータストアを、出力を接地してエージェントを最新の状態に保つことができるアクティブリコールメカニズムに変えます。
しかし、メモリは両刃の剣です。コンテキストを制御せずに放置すると、ポイズニング、逸脱、混乱、衝突を引き起こし、共有システムではデータ漏洩さえも招く可能性があります。だからこそ、メモリに関する最も重要な作業は「より多くを格納する」のではなく、「よりよくキュレーションする」ことです。選択的に取り出し、積極的にプルーニングし、慎重に要約し、タスクが真に要求する場合を除いて、無関係なコンテキストを混ぜ合わせることを避けます。
実際には、優れたコンテキストエンジニアリングは、優れたシステム設計のように見えます。具体的には、コンテキストが小さく十分であり、コンポーネント間のインターフェイスが制御され、モデルに実際に表示したい生の状態と精製された状態が明確に区別された状態です。適切に実行すれば、すべてを記憶するエージェントではなく、適切な理由で適切なタイミングで適切なことを記憶するエージェントが得られます。
関連記事

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

Elasticsearch Inference APIとHugging Faceモデルを組み合わせて使用
推論エンドポイントを使用してElasticsearchをHugging Faceモデルに接続する方法と、セマンティック検索とチャット補完機能を備えた多言語ブログ推奨システムを構築する方法を学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。
ElasticsearchのGemini CLI拡張機能(ツールとスキル付き)
GoogleのGemini CLIでElasticsearchのデータを検索、取得、分析するためのElasticの拡張機能(開発者およびエージェントのワークフロー向け)をご紹介します。