最近、OpenAIはPro/Business/EnterpriseおよびEduプラン向けにChatGPT向けのカスタムコネクター機能を発表しました。これは、Gmail、GitHub、Dropboxなどのデータを活用するためのすぐに使えるコネクターへの追加となります。MCPサーバーを使用してカスタムコネクターを作成できます。
カスタムコネクターを使用すると、既存のChatGPTコネクターをElasticsearchなどの追加のデータソースと組み合わせて、包括的な回答を得ることができます。
この記事では、内部のGitHubの課題とプルリクエストに関する情報を含むElasticsearchインデックスにChatGPTを接続するMCPサーバーを構築します。これにより、Elasticsearchデータを使用して自然言語クエリに回答できるようになります。
Google ColabのFastMCPとngrokを使ってMCPサーバーをデプロイし、ChatGPTが接続できる公開URLを取得し、複雑なインフラ構築の必要性を排除します。
MCPとそのエコシステムの包括的な概要については、MCPの現在の状態をご参照ください。
要件
始める前に必要なものは次のとおりです。
- Elasticsearchクラスター(8.X以降)
- インデックスへの読み取りアクセス権を持つ Elasticsearch APIキー
- Googleアカウント(Google Colab用)
- Ngrokアカウント(無料プランでも可)
- Pro/Enterprise/BusinessまたはEduプランのChatGPTアカウント
ChatGPT MCPコネクターの要件を理解する
ChatGPT MCPコネクターには、searchとfetchの2つのツールを実装する必要があります。詳細については、OpenAIドキュメントをご覧ください。
検索ツール
ユーザークエリに基づいて、Elasticsearchインデックスから関連する結果のリストを返します。
受け取るもの:
- ユーザーの自然言語クエリを含む単一の文字列。
- 例:「Elasticsearch移行に関連するイシューを見つけて」
返されるもの:
- 結果オブジェクトの配列を含む
resultキーを持つオブジェクト。各結果には以下が含まれます。id- 一意の文書識別子title- イシューまたはPRタイトルurl- イシュー/PRへのリンク
実装内容:
フェッチ・ツール
特定の文書の完全な内容を取得します。
受け取るもの:
- 検索結果からElasticsearch文書IDを入力する単一の文字列
- 例:「PR-578の詳細を教えてください。」
返されるもの:
- 以下を含む完全な文書オブジェクト:
id- 一意の文書識別子title- イシューまたはPRタイトルtext- 完全なイシュー・PRの説明と詳細url- イシュー/PRへのリンクtype- 文書の種類(issue, pull_request)status- 現在のステータス(open, in_progress, resolved)priority- 優先度レベル(low, medium, high, critical)assignee- イシュー/PRの担当者created_date- 作成された時期resolved_date- 解決された時期(該当する場合)labels文書に関連するタグrelated_pr- 関連するプルリクエストID
注:この例では、すべてのフィールドがルートレベルにあるフラット構造を使用しています。OpenAIの要件は柔軟で、ネストされたメタデータオブジェクトもサポートしています。
GitHubのデータセットとプルリクエストデータセット
このチュートリアルでは、イシューとプルリクエストを含む内部GitHubデータセットを使用します。これは、ChatGPTを通じてプライベートな内部データをクエリするシナリオを表しています。
データセットはこちらからご覧いただけます。そして、Bulk APIを使ってデータのインデックスを更新します。
このデータセットには以下が含まれます。
- 説明、ステータス、優先順位、担当者に関する問題
- コード変更、レビュー、導入情報を含むプルリクエスト
- イシューとPRの関係(例:PR-578がISSUE-1889を修正)
- ラベル、日付、その他のメタデータ
インデックスマッピング
インデックスは、ELSERとのハイブリッド検索をサポートするために以下のマッピングを使用します。text_semanticはセマンティック検索に使用され、他のフィールドはキーワード検索を可能にします。
MCPサーバーを構築する
当社のMCPサーバーは、OpenAI仕様に従って2つのツールを実装しています。ハイブリッド検索を使用してセマンティックマッチングとテキストマッチングを組み合わせることで、より良い結果が得られます。
検索ツール
RRF(相互ランク融合)を用いたハイブリッド検索を使用し、セマンティック検索とテキストマッチングを組み合わせています。
主なポイント:
- RRFを用いたハイブリッド検索: より良い結果を得るために、セマンティック検索(ELSER)とテキスト検索(BM25)を組み合わせます。
- 複数一致クエリ:ブースティングを使用して複数のフィールドを検索します(title^3, text^2, assignee^2)。キャレット記号(^)は関連性スコアを乗算し、コンテンツよりもタイトルの一致を優先します。
- あいまい一致:
fuzziness: AUTOは近似一致を許可することでタイプミスやスペルミスを処理します。 - RRFのパラメーター調整:
rank_window_size: 50- マージする前に、各リトリーバー(セマンティックとテキスト)からの上位結果をいくつ考慮するかを指定します。rank_constant: 60- この値は、個々の結果セット内の文書が最終的なランク付け結果にどの程度影響を与えるかを決定します。
- 必須フィールドのみを返す:
id、title、urlはOpenAIの仕様に従い、追加のフィールドを不必要に公開しないようにします。
フェッチ・ツール
文書IDが存在する場合は、そのIDで文書の詳細を取得します。
主なポイント:
- 文書IDのフィールドで検索:カスタム
idフィールドに用語クエリを使用します - 完全な文書を返す: すべてのコンテンツを含む完全な
textフィールドが含まれます - フラットな構造:すべてのフィールドがルートレベルにあり、Elasticsearchのドキュメント構造に一致します。
Google Colabにデプロイする
Google Colabを使用してMCPサーバーを実行し、ngrokで公開することで、ChatGPTが接続できるようにします。
ステップ1:Google Colabノートブックを開く
事前設定されたノートブックElasticsearch MCP for ChatGPTにアクセスします。
ステップ2:認証情報を設定する
次の3つの情報が必要になります。
- Elasticsearch URL:お客様のElasticsearchクラスタリングURL。
- Elasticsearch API キー:インデックスへの読み取りアクセス権を持つAPIキー。
- Ngrok認証トークン:ngrokからの無料トークン。ngrokを使ってMCPのURLをインターネットに公開し、ChatGPTが接続できるようにします。
ngrokトークンの取得
Google Colabにシークレットを追加する
Google Colabノートブック内で:
- 左側のサイドバーにあるキーアイコンをクリックして、シークレットを開きます。
- 次の3つのシークレットを追加します。
3. 各シークレットのノートブックアクセスを有効にします。

ステップ3:ノートブックを実行する
- ランタイムをクリックし、次にすべて実行をクリックして、すべてのセルを実行します。
- サーバーの起動を待ちます(約30秒)。
- 公開ngrok URLを示す出力を探します。

4. 出力は次のようになります。

ChatGPTに接続する
次に、MCPサーバーをあなたのChatGPTアカウントに接続します。
- ChatGPTを開き、設定に移動します。
- コネクターに移動します。Proアカウントを使用している場合は、コネクタで開発者モードをオンにする必要があります。
ChatGPT EnterpriseまたはBusinessを使用している場合は、コネクターを職場に公開する必要があります。
3. 作成をクリックします。

注:Business、Enterprise、Eduワークスペースでは、ワークスペースの所有者、管理者、およびそれぞれの設定が有効になっているユーザー(Enterprise/Eduの場合)のみがカスタムコネクターを追加できます。通常のメンバーロールのユーザーには、自分でカスタムコネクターを追加する権限がありません。
コネクターが所有者または管理者ユーザーによって追加され有効化されると、ワークスペースのすべてのメンバーが使用できるようになります。
4. 必要な情報と、/sse/で終わるngrokのURLを入力します。「sse」の後の「/」に注意してください。これがない場合、動作しません。
- Name: Elasticsearch MCP
- Description: GitHubの内部情報を検索および取得するためのカスタムMCP。

5. 作成を押してカスタムMCPを保存します。

サーバーが稼働していれば、接続は瞬時に完了します。追加の認証は不要で、Elasticsearch APIキーはサーバー上で設定されています。
MCPサーバーをテストする
質問する前に、ChatGPTが使用するコネクターを選択する必要があります。

プロンプト1:イシューを検索する
「Elasticsearchの移行に関連するイシューを見つけて」と質問し、アクションツールの呼び出しを確認します。
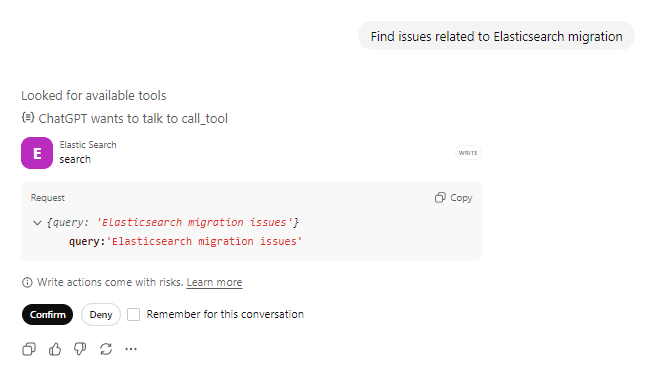
ChatGPT はクエリを使用してsearchツールを呼び出します。利用可能なツールを検索し、Elasticsearchツールを呼び出す準備をし、ツールに対して何らかのアクションを実行する前にユーザーに確認していることがわかります。
ツール呼び出しリクエスト:
ツールの応答:
ChatGPTは結果を処理し、自然で会話的な形式で提示します。

仕組み
プロンプト:「Elasticsearch移行に関連するイシューを見つけて」
1. ChatGPTの呼び出し search(“Elasticsearch migration”)
2. Elasticsearchがハイブリッド検索を実行する
- セマンティック検索は「アップグレード」や「バージョン互換性」などの概念を理解します。
- テキスト検索で「Elasticsearch」と「migration」の完全一致を見つけます。
- RRFは両方のアプローチの結果を組み合わせてランク付けします。
3. id、titleを含むトップ10のマッチングイベントを返します。 url
4. ChatGPTは「ISSUE-1712: migrate from Elasticsearch 7.x to 8.x」を最も関連性の高い結果として特定します。
プロンプト2:完全な詳細を取得する
質問:「ISSUE-1889の詳細を教えて」

ChatGPTは、あなたが特定のイシューに関する詳細な情報を求めていることを認識し、fetchツールを呼び出し、ツールに対して何らかのアクションを起こす前にユーザーに確認します。
ツール呼び出しリクエスト:
ツールの応答:
ChatGPTは情報を統合し、明確に提示します。


仕組み
プロンプト:「ISSUE-1889の詳細を教えて」
- ChatGPT呼び出し
fetch(“ISSUE-1889”) - Elasticsearchが完全な文書を取得する
- すべてのフィールドがルートレベルにある完全な文書を返す
- ChatGPTは情報を統合し、適切な引用で回答する
まとめ
この記事では、専用の検索およびフェッチMCPツールを使用してChatGPTをElasticsearchに接続するカスタムMCPサーバーを構築し、プライベートデータに対する自然言語クエリを可能にしました。
このMCPパターンは、自然言語を使用してクエリしたい任意のElasticsearchインデックス、ドキュメント、製品、ログ、またはその他のデータで機能します。
関連記事

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

Elasticsearch Inference APIとHugging Faceモデルを組み合わせて使用
推論エンドポイントを使用してElasticsearchをHugging Faceモデルに接続する方法と、セマンティック検索とチャット補完機能を備えた多言語ブログ推奨システムを構築する方法を学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。