En actualizaciones recientes, Elasticsearch introdujo una integración nativa para conectar a modelos hospedados en el servicio de inferencia Hugging Face. En esta publicación, veremos cómo configurar esta integración y realizar inferencias mediante llamadas a la API sencillas utilizando un modelo de lenguaje grande (LLM). Usaremos SmolLM3-3B, un modelo ligero de propósito general con un buen equilibrio entre el uso de recursos y la calidad de las respuestas.
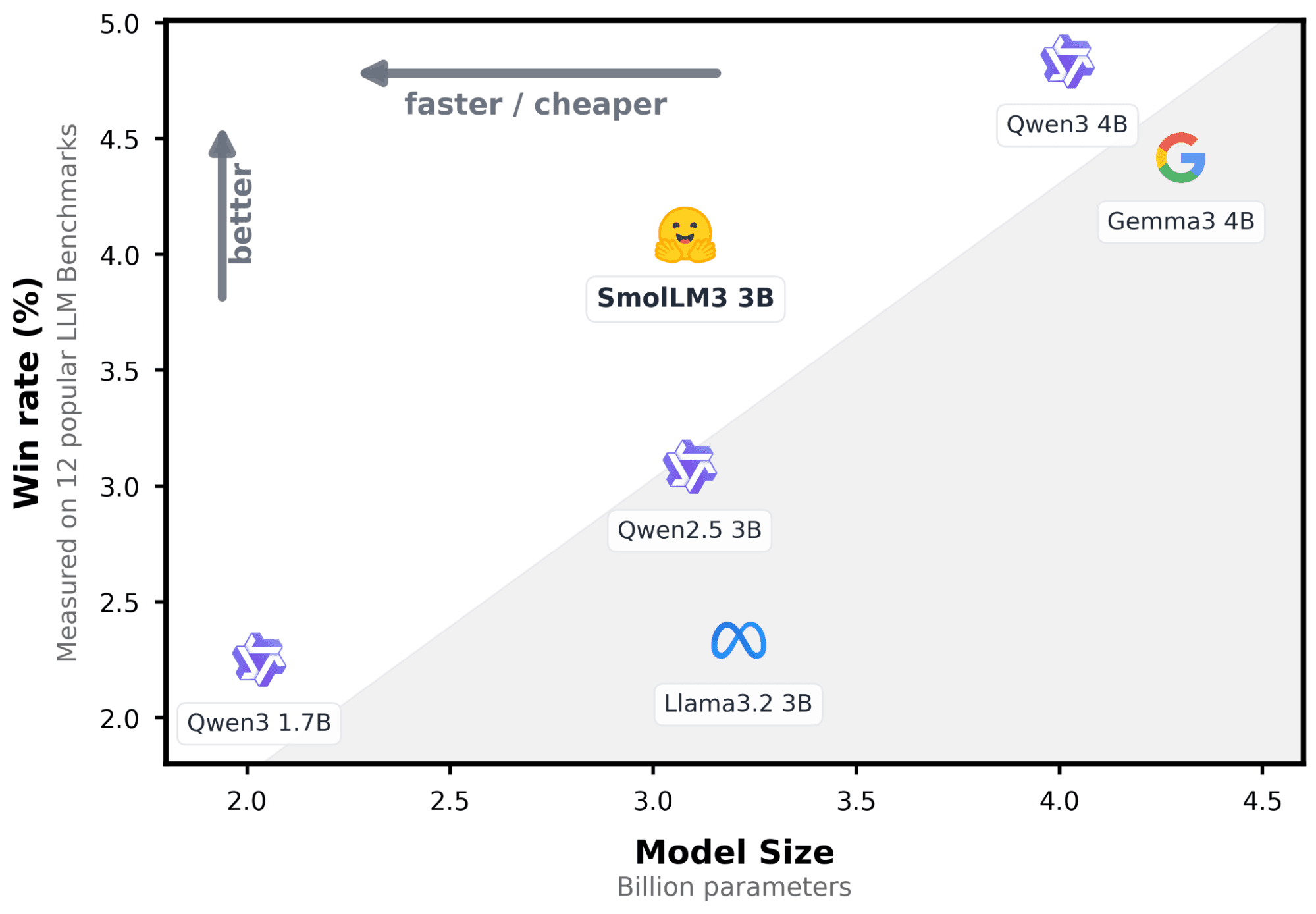
Requisitos previos
- Elasticsearch 9.3 o Elastic Cloud Serverless: puedes crear un despliegue en la cloud siguiendo estas instrucciones, o bien puedes utilizar la guía de inicio rápido de
start-local. - Python 3.12: Descarga Python aquí.
- Token de acceso Hugging Face.
Finalización de chat usando un endpoint de inferencia de Hugging Face
Primero, vamos a crear un ejemplo práctico que conecte Elasticsearch con un endpoint de inferencia de Hugging Face para generar recomendaciones basadas en IA a partir de una colección de publicaciones de blog. Para la base de conocimientos de la app, usaremos un set de datos de artículos del blog de la compañía, que contiene información valiosa pero a menudo difícil de navegar.
Con este endpoint, la búsqueda semántica recupera los artículos más relevantes para una consulta dada, y un LLM de Hugging Face genera recomendaciones breves y contextuales basadas en esos resultados.
Echemos un vistazo a una visión general de alto nivel del flujo de información que vamos a construir:
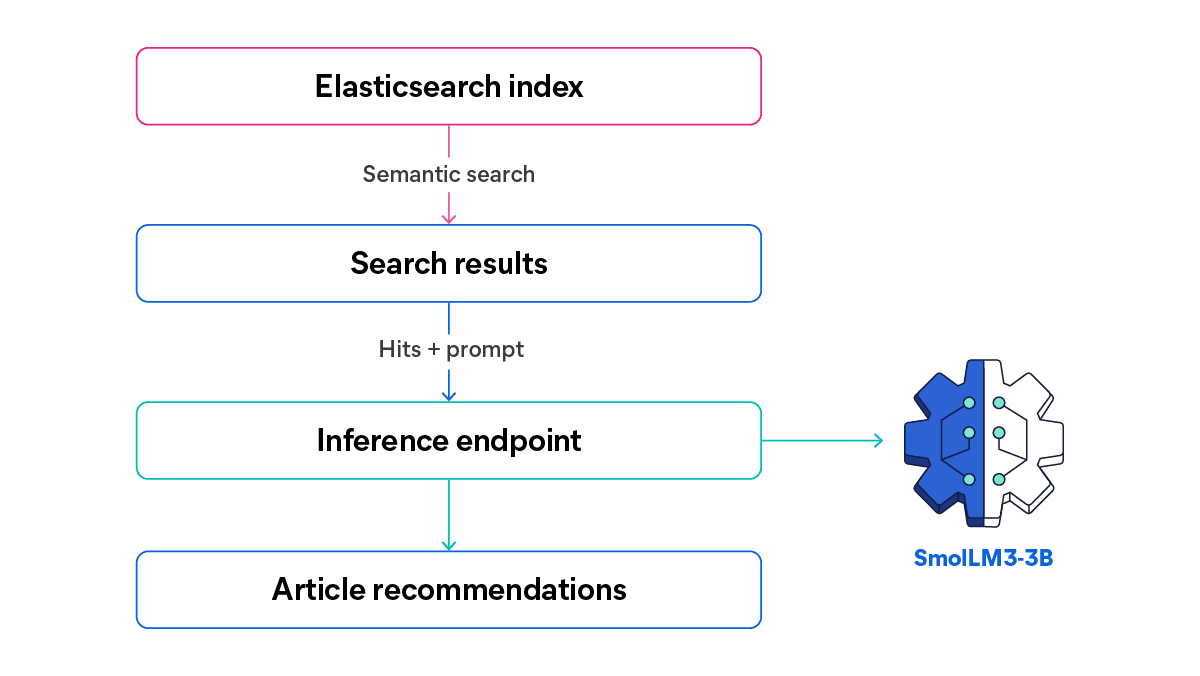
En este artículo, probaremos la capacidad de SmolLM3-3B para combinar su tamaño compacto con fuertes capacidades multilingües de razonamiento y llamadas a herramientas. A partir de una búsqueda, enviaremos todo el contenido correspondiente (en inglés y español) al LLM para generar una lista de artículos recomendados con una descripción personalizada basada en la búsqueda y los resultados.
Así podría ser la UI de un sitio web de artículos con un sistema de generación de recomendaciones basado en inteligencia artificial.

Puedes encontrar la implementación completa de esta aplicación en el cuaderno adjunto.
Configurar endpoints de inferencia de Elasticsearch
Para usar el endpoint de inferencia Elasticsearch Hugging Face, necesitamos dos elementos importantes: una clave API de Hugging Face y una URL del endpoint de Hugging Face en funcionamiento. Debería verse así:
El endpoint de inferencia Hugging Face en Elasticsearch admite diferentes tipos de tareas: text_embedding, completion, chat_completion y rerank. En esta publicación de blog, usamos chat_completion porque necesitamos que el modelo genere recomendaciones conversacionales basadas en los resultados de búsqueda y una solicitud del sistema. Este endpoint nos permite realizar finalizaciones de chat directamente desde Elasticsearch de una manera sencilla empleando la API de Elasticsearch:
Esto servirá como núcleo de la aplicación, recibirá la indicación y los resultados de búsqueda que pasarán por el modelo. Ya abordamos la teoría, ahora comencemos a implementar la aplicación.
Configuración de un endpoint de inferencia en Hugging Face
Para desplegar el modelo de Hugging Face, vamos a usar despliegues con un clic de Hugging Face, un servicio fácil y rápido para desplegar endpoints de modelos. Ten en cuenta que este es un servicio de pago y que su uso puede generar costos adicionales. En este paso se creará la instancia del modelo que se usará para generar las recomendaciones de artículos.
Puedes elegir un modelo del catálogo de un clic:
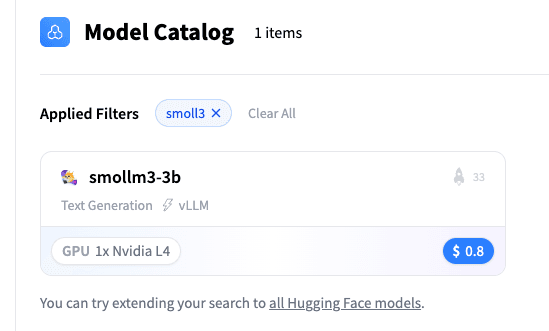
Vamos a elegir el modelo SmolLM3-3B:

Desde aquí, copia la URL del endpoint de Hugging Face:
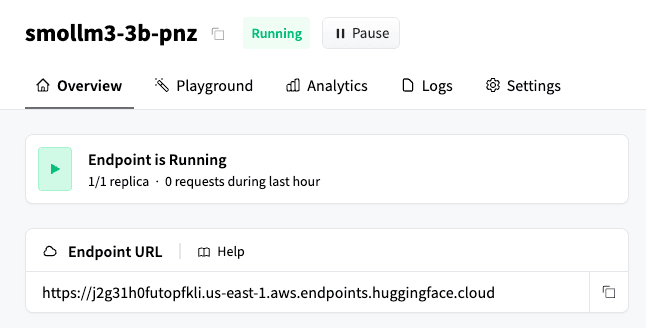
Como se menciona en la documentación de endpoints de inferencia Hugging Face de Elasticsearch, la generación de texto requiere un modelo compatible con la API de OpenAI. Por esa razón, necesitamos anexar la ruta secundaria /v1/chat/completions a la URL del endpoint de Hugging Face. El resultado final se verá así:
Ahora que está todo listo, podemos empezar a programar en un cuaderno de Python.
Generando clave API de Hugging Face
Crea una cuenta en Hugging Face y obtén un token de API siguiendo estas instrucciones. Puedes elegir entre tres tipos de token: detallado (recomendado para producción, ya que proporciona acceso solo a recursos específicos); lectura (para acceso de solo lectura); o escritura (para acceso de lectura y escritura). Para este tutorial, un token de lectura es suficiente, ya que solo necesitamos llamar al endpoint de inferencia. Guarda esta clave para el siguiente paso.
Configuración del endpoint de inferencia de Elasticsearch
Primero, declaremos un cliente de Python para Elasticsearch:
A continuación, vamos a crear un endpoint de inferencia de Elasticsearch que use el modelo Hugging Face. Este endpoint nos permitirá generar respuestas basadas en las entradas del blog y en el prompt que se pasó al modelo.
Set de datos
El conjunto de datos contiene las publicaciones de blog que se consultarán, representando un conjunto de contenido multilingüe utilizado a lo largo del flujo de trabajo:
Mappings de Elasticsearch
Una vez definido el set de datos, necesitamos crear un esquema de datos que se ajuste correctamente a la estructura de la publicación de blog. Se emplearán las siguientes mappings de índices para almacenar los datos en Elasticsearch:
Aquí, podemos ver mejor cómo se estructuran los datos. Usaremos la búsqueda semántica para recuperar resultados basados en lenguaje natural, junto con la propiedad copy_to para copiar el contenido del campo en el campo semantic_text. Además, el campo title contiene dos subcampos: el subcampo original almacena el título en inglés o español, dependiendo del idioma original del artículo; y el subcampo translated_title está presente solo para artículos en español y contiene la traducción al inglés del título original.
Ingesta de datos
El siguiente fragmento de código ingesta el conjunto de datos de las publicaciones de blog en Elasticsearch mediante la API de bulk:
Ahora que tenemos los artículos ingeridos en Elasticsearch, necesitamos crear una función capaz de buscar en el campo semantic_text :
También necesitamos una función que llame al endpoint de inferencia. En este caso, llamaremos al endpoint usando el tipo de tarea chat_completion para obtener respuestas de transmisión:
Ahora podemos escribir una función que llame a la función de búsqueda semántica, junto con el endpoint de inferencia chat_completions y el endpoint de recomendaciones, para generar los datos que se asignarán en las tarjetas:
Por último, extrae la información y dale formato para imprimirla:
Pongámoslo a prueba haciendo una pregunta sobre las publicaciones de blog de seguridad:
Aquí podemos ver las tarjetas de la consola generadas por el flujo de trabajo:

Puedes ver los resultados completos, incluso todas las coincidencias y la respuesta del LLM, en este archivo.
Estamos solicitando artículos relacionados con: “Seguridad y vulnerabilidades”. Esta pregunta se emplea como consulta de búsqueda en los documentos almacenados en Elasticsearch. Los resultados obtenidos se pasan al modelo, el cual genera recomendaciones basadas en su contenido. Como podemos ver, el modelo hizo un excelente trabajo generando textos cortos y atractivos que pueden motivar al lector a hacer clic en ellos.
Conclusión
Este ejemplo muestra cómo se pueden combinar Elasticsearch y Hugging Face para crear un sistema centralizado rápido y eficiente para aplicaciones de IA. Este enfoque reduce el esfuerzo manual y proporciona flexibilidad, gracias al extenso catálogo de modelos de Hugging Face. El uso de SmolLM3-3B, en particular, muestra cómo los modelos compactos y multilingües aún pueden ofrecer razonamiento significativo y generación de contenido cuando se combinan con la búsqueda semántica. En conjunto, estas herramientas ofrecen una base escalable y eficaz para construir análisis de contenidos inteligentes y aplicaciones multilingües.
Contenido relacionado

11 de mayo de 2026
Potenciando Elasticsearch: agregamos soporte nativo de la API de Prometheus
Realiza una búsqueda en Elasticsearch directamente desde clientes compatibles con Prometheus a través de endpoints nativos de PromQL, descubrimiento y metadatos. Envía datos a Elasticsearch con Prometheus Remote Write.

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.
17 de marzo de 2026
Extensión CLI de Gemini para Elasticsearch con herramientas y habilidades
Te presentamos la extensión de Elastic para la CLI de Gemini de Google, que te permite hacer búsquedas, recuperar y analizar datos de Elasticsearch en flujos de trabajo de desarrollo y de agentes.