最近のアップデートで、ElasticsearchはHugging Face Inference Serviceでホストされているモデルに接続するためのネイティブ統合機能を導入しました。この記事では、この統合を構成し、大規模言語モデル(LLM)を使用して簡単なAPI呼び出しを通じて推論を実行する方法を探ります。リソース使用量と解答品質のバランスが取れた軽量汎用モデルであるSmolLM3-3Bを使用します。
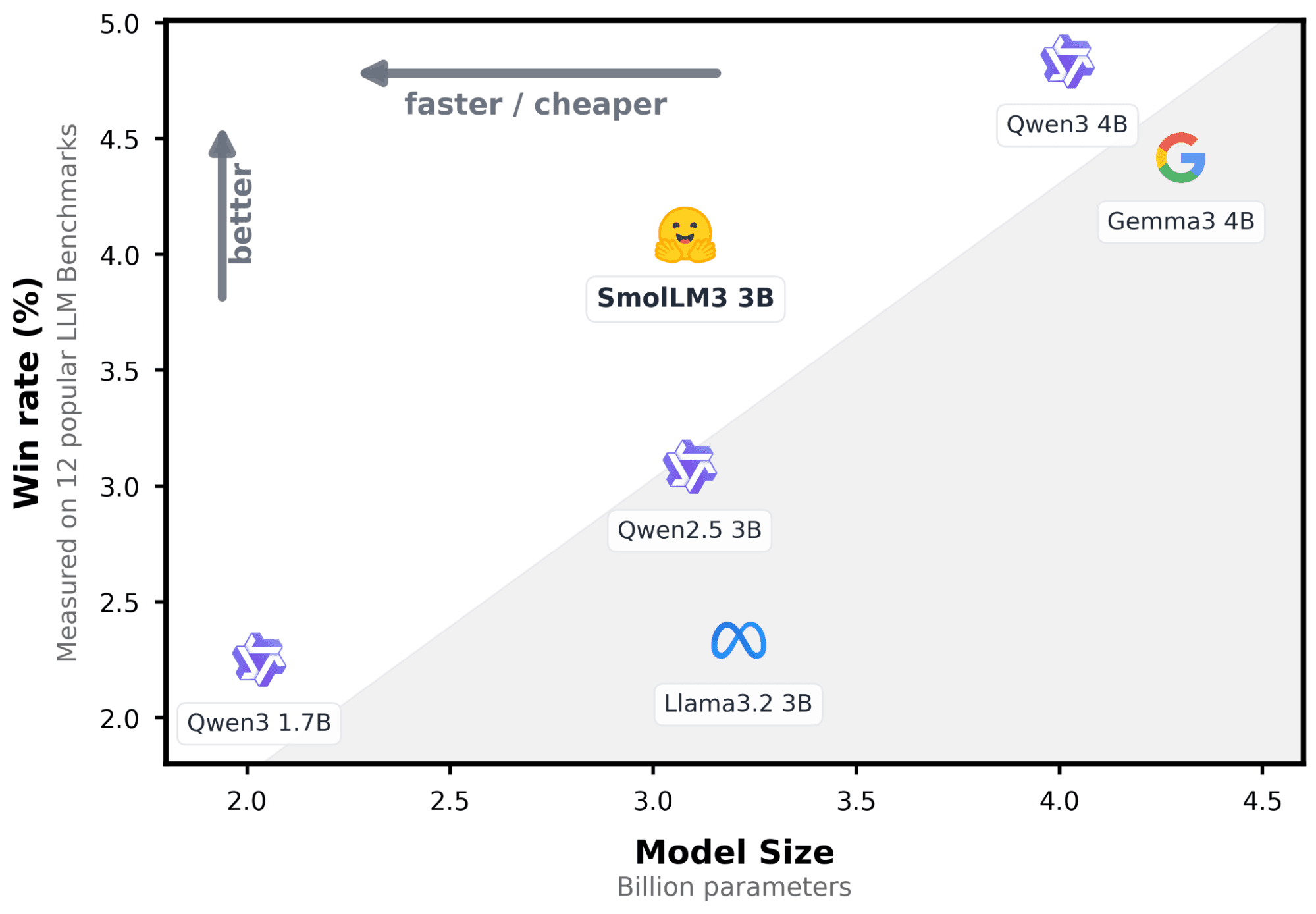
要件
- Elasticsearch 9.3またはElastic Cloud Serverless:これらの指示に従ってクラウド導入を作成することもできますし、
start-localクイックスタートを使うこともできます。 - Python 3.12:Pythonはこちらからダウンロードしてください。
- Hugging Faceアクセストークン。
Hugging Face推論エンドポイントを使用したチャットの完了
まず、ElasticsearchをHugging Faceの推論エンドポイントに接続し、ブログ記事のコレクションからAIを活用したレコメンデーションを生成する実践的な例を作成します。アプリのナレッジベースには、会社のブログ記事のデータセットを使用します。これには価値のある情報が含まれていますが、多くの場合、見つけるのが困難です。
このエンドポイントでは、セマンティック検索が指定されたクエリに対して最も関連性の高い記事を取得し、Hugging Face LLMがそれらの結果に基づいて短いコンテキスト推奨を生成します。
これから構築する情報フローの概要を見ていきましょう。
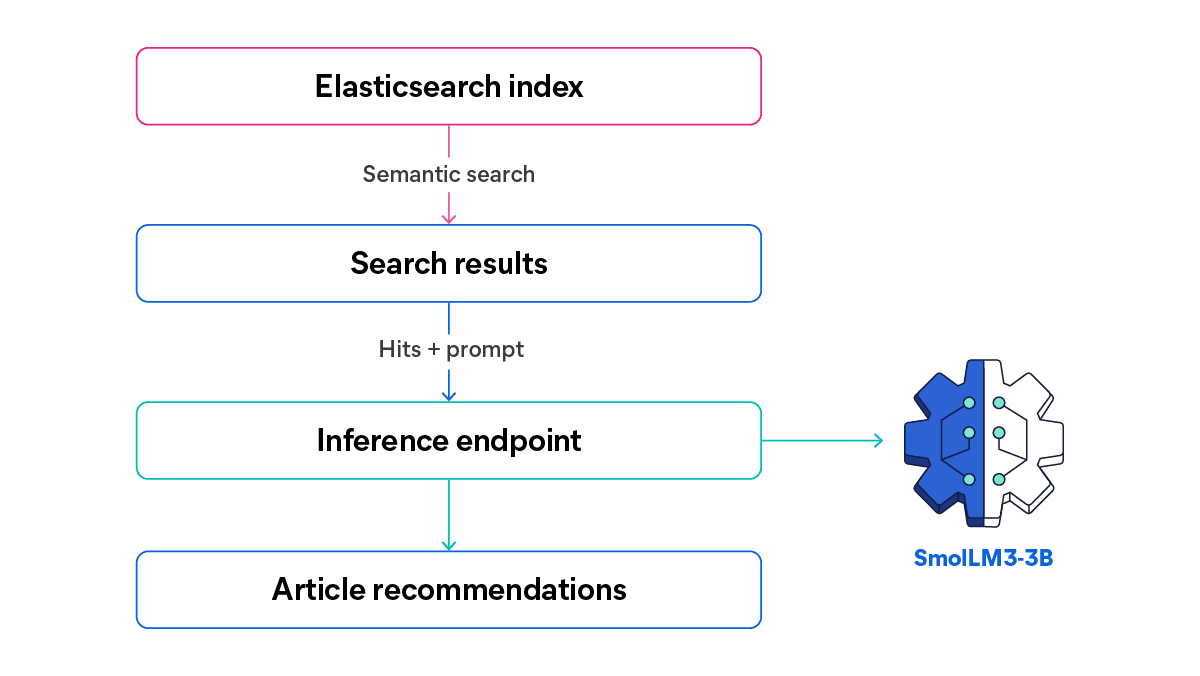
この記事では、コンパクトなサイズと強力な多言語推論能力・ツール呼び出し能力を組み合わせたSmolLM3-3Bの性能を検証します。検索クエリに基づいて、一致するすべてのコンテンツ(英語とスペイン語)をLLMに送信し、検索クエリと結果に基づいたカスタムメイドの説明を含むおすすめ記事のリストを生成します。
AIによる推奨生成システムを備えた記事サイトのUIは次のようになります。

このアプリケーションの完全な実装は、リンク先のノートブックで確認できます。
Elasticsearch推論エンドポイントの構成
Elasticsearch Hugging Face推論エンドポイントを使用するには、2つの重要な要素(Hugging Face APIキーと実行中のHugging FaceエンドポイントURL)が必要です。下の画像のように表示されるはずです。
Hugging FaceのElasticsearchにおける推論エンドポイントは、 text_embedding, completion, chat_completion, と rerankの異なるタスクタイプをサポートしています。このブログ記事では、検索結果とシステムプロンプトに基づいて会話形式のレコメンデーションをモデルに生成させる必要があるため、chat_completion を使用します。このエンドポイントを使用すると、Elasticsearch APIを使用してElasticsearchから直接チャットの完了を簡単に実行できます。
これはアプリケーションのコアとして機能し、モデルを通過するプロンプトと検索結果を受け取ります。理論について説明したので、アプリケーションの実装を始めましょう。
Hugging Faceでの推論エンドポイントの設定
Hugging Faceモデルをデプロイするために、モデルのエンドポイントをデプロイするための簡単で高速なサービスHugging Faceワンクリック導入を使用します。これは有料サービスであり、利用には追加料金が発生する可能性があることにご注意ください。このステップでは、記事の推奨を生成するために使うモデルインスタンスが作成されます。
ワンクリックカタログからモデルを選択できます。
SmolLM3-3Bモデルを選択します。

ここから、Hugging FaceのエンドポイントURLを取得します。
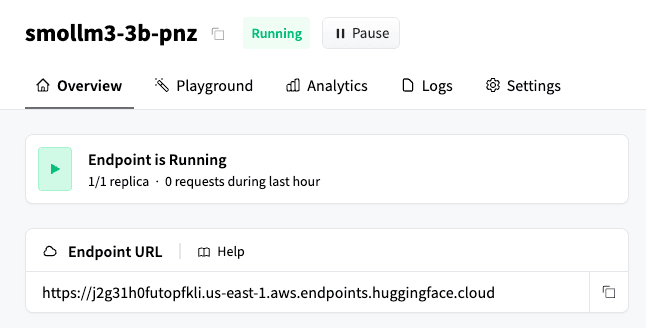
Elasticsearch Hugging Faceの推論エンドポイントのドキュメントで述べられているように、テキスト生成にはOpenAI APIと互換性のあるモデルが必要です。そのため、/v1/chat/completionsのサブパスをHugging FaceのエンドポイントURLに追加する必要があります。最終的な結果は次のようになります。
これで準備が整いましたので、Pythonノートブックでコーディングを開始できます。
Hugging Face APIキーの生成
Hugging Faceアカウントを作成し、以下の指示に従ってAPIトークンを取得してください。トークンの種類は、fine-grained(本番環境に推奨。特定のリソースへのアクセスのみを提供)、read(読み取り専用アクセス用)、write(読み取りおよび書き込みアクセス用)の3つから選択できます。このチュートリアルでは、推論エンドポイントを呼び出すだけでよいので、readトークンで十分です。次のステップのために、このキーを保存しておいてください。
Elasticsearch推論エンドポイントの設定
まず、Elasticsearch Pythonクライアントを宣言します。
次に、Hugging Faceモデルを使用するElasticsearch推論エンドポイントを作成します。このエンドポイントを使用すると、ブログ記事とモデルに渡されたプロンプトに基づいて応答を生成できます。
データセット
このデータセットには、クエリの対象となるブログ記事が含まれており、ワークフロー全体で使用される多言語コンテンツセットを表しています。
Elasticsearch マッピング
データセットが定義されたので、ブログ記事の構造に適切にフィットするデータスキーマを作成する必要があります。Elasticsearchにデータを格納するために以下のインデックスマッピングが使用されます。
ここで、データがどのように構造化されているかをより明確に見ることができます。セマンティック検索を使用して自然言語に基づいて結果を取得し、copy_toプロパティを使用してフィールドの内容をsemantic_textフィールドにコピーします。さらに、titleフィールドには2つのサブフィールドが含まれています。originalサブフィールドは、記事の元の言語に応じて英語またはスペイン語でタイトルを格納し、translated_titleサブフィールドはスペイン語の記事にのみ存在し、元のタイトルの英語訳が含まれています。
データの取り込み
以下のコードスニペットはbulk APIを使用してブログ投稿データセットをElasticsearchに取り込みます。
Elasticsearchに記事を取り込んだので、次にsemantic_textフィールドに対して検索できる関数を作成する必要があります:
推論エンドポイントを呼び出す関数も必要です。この場合、chat_completion タスクタイプを使用してエンドポイントを呼び出し、ストリーミング応答を取得します。
ここで、 chat_completions 推論エンドポイントと推薦エンドポイントを合わせてセマンティック検索関数を呼び出し、カードに割り当てられるデータを生成する関数を書くことができます。
最後に、情報を抽出して出力できるようにフォーマットする必要があります。
セキュリティブログの投稿について質問して、これをテストしてみましょう。
ここでは、ワークフローによって生成されたコンソール内のカードを確認できます。

すべてのヒットとLLMの対応を含む完全な結果をこのファイルでご覧いただけます。
「Security and vulnerabilities」に関連する記事をクエリしています。この質問は、Elasticsearchに保存されているドキュメントに対する検索クエリとして使用されます。取得された結果はモデルに渡され、モデルはその内容に基づいてレコメンデーションを生成します。ご覧の通り、このモデルは読者がクリックする動機付けとなる魅力的な短いテキストを非常にうまく生成しています。
まとめ
この例では、ElasticsearchとHugging Faceを組み合わせて、AIアプリケーション向けの高速で効率的な集中型システムを構築する方法を示します。Hugging Faceの豊富なモデルカタログにより、このアプローチでは手作業を削減し、柔軟性を確保できます。特にSmolLM3-3Bを使用すると、コンパクトな多言語モデルでも、セマンティック検索と組み合わせることで有意義な推論とコンテンツ生成を実現できることがわかります。これらのツールを組み合わせることで、インテリジェントなコンテンツ分析と多言語アプリケーションを構築するための、拡張性が高く効果的な基盤を提供できます。
関連記事

2026年5月11日
Elasticsearchに火を灯す:Prometheus APIのネイティブサポートを追加
Prometheus互換のクライアントから、ネイティブのPromQL、ディスカバリー、メタデータエンドポイント経由でElasticsearchに直接クエリを実行できます。Prometheus Remote WriteでElasticsearchにデータを送信します。

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。
ElasticsearchのGemini CLI拡張機能(ツールとスキル付き)
GoogleのGemini CLIでElasticsearchのデータを検索、取得、分析するためのElasticの拡張機能(開発者およびエージェントのワークフロー向け)をご紹介します。