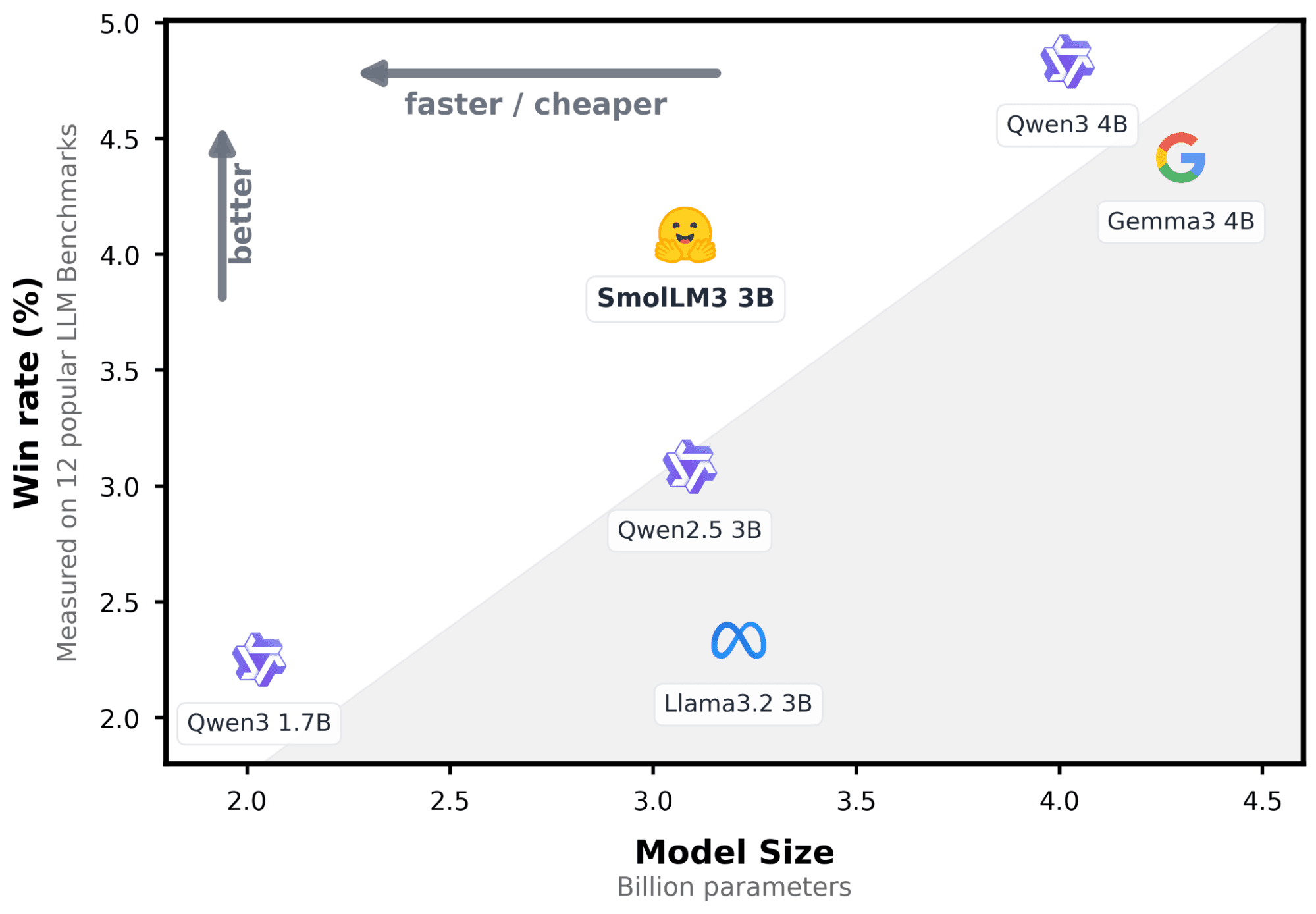
In den letzten Aktualisierungen hat Elasticsearch eine native Integration eingeführt, um sich mit Modellen zu verbinden, die auf dem Hugging Face Inference Service gehostet werden. In diesem Beitrag erfahren Sie, wie Sie diese Integration konfigurieren und über einfache API-Aufrufe mithilfe eines großen Sprachmodells (LLM) Inferenzen durchführen können. Wir verwenden SmolLM3-3B, ein leichtes Allzweckmodell mit einem ausgewogenen Gleichgewicht zwischen Ressourcenverbrauch und Antwortqualität.
Voraussetzungen
- Elasticsearch 9.3 oder Elastic Cloud Serverless: Sie können ein Cloud-Deployment erstellen, indem Sie diese Anweisungen befolgen, oder stattdessen den
start-localQuickstart verwenden. - Python 3.12: Laden Sie Python hier herunter.
- Hugging Face Zugriffstoken.
Chat-Abschlüsse unter Verwendung eines Inferenz-Endpoints von Hugging Face
Zuerst erstellen wir ein praktisches Beispiel, das Elasticsearch mit einem Hugging Face Inferenz-Endpoint verbindet, um KI-gestützte Empfehlungen aus einer Reihe von Blogbeiträgen zu generieren. Für die Wissensdatenbank der App verwenden wir einen Datensatz mit Blogartikeln des Unternehmens, der wertvolle, aber oft schwer zugängliche Informationen enthält.
Bei diesem Endpoint ruft die semantische Suche die relevantesten Artikel für eine gegebene Abfrage ab, und ein Hugging Face LLM generiert kurze, kontextuelle Empfehlungen basierend auf diesen Ergebnissen.
Verschaffen wir uns einen groben Überblick über den Informationsfluss, den wir entwickeln werden:
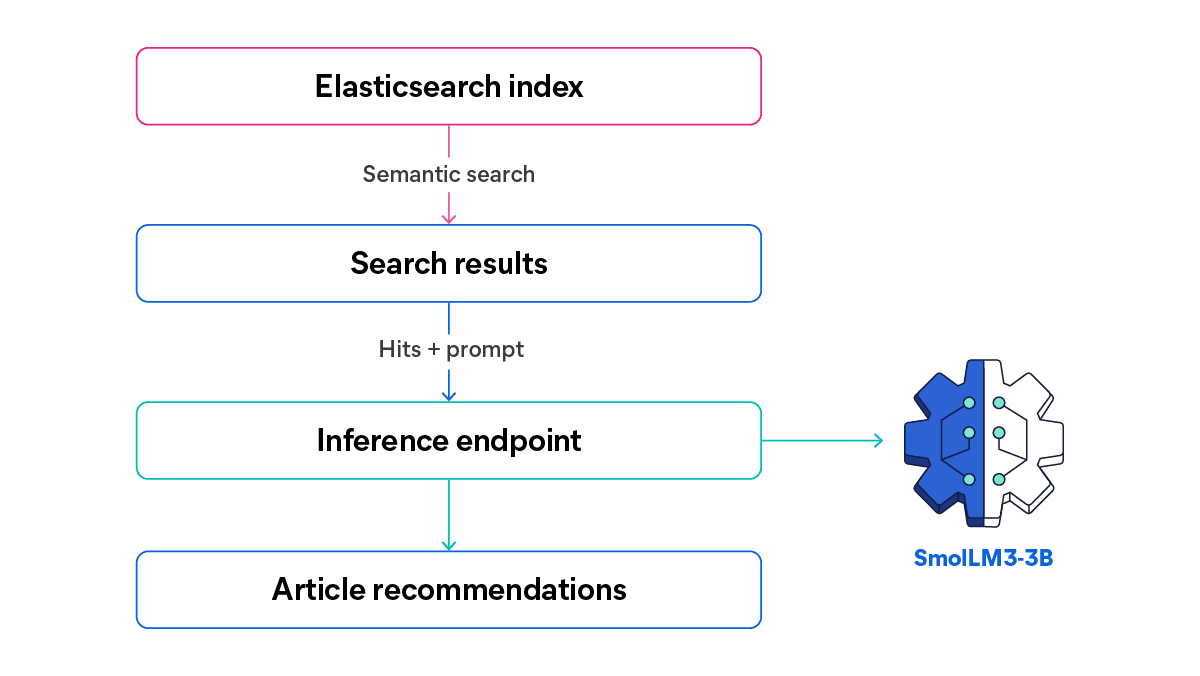
In diesem Artikel testen wir die Fähigkeit von SmolLM3-3B und kombinieren seine kompakte Größe mit einer starken mehrsprachigen Argumentations- und Tool-Aufruffunktion. Basierend auf einer Suchabfrage senden wir alle passenden Inhalte (auf Englisch und Spanisch) an das LLM, um eine Liste empfohlener Artikel mit einer individuell erstellten Beschreibung basierend auf der Suchanfrage und den Ergebnissen zu erstellen.
So könnte die Benutzeroberfläche einer Artikelseite mit einem System zur Generierung von KI-Empfehlungen aussehen.

Sie können die vollständige Implementierung dieser Anwendung im verlinkten Notizbuch finden.
Konfiguration der Elasticsearch Inferenz-Endpoints
Um den Elasticsearch Hugging Face Inferenz-Endpoint zu verwenden, benötigen wir zwei wichtige Elemente: einen Hugging Face API-Schlüssel und eine ausgeführte Hugging Face Endpoint-URL. Dies sollte so aussehen:
Der Hugging Face Inferenz-Endpoint in Elasticsearch unterstützt verschiedene Aufgabentypen: text_embedding, completion, chat_completion und rerank. In diesem Blogbeitrag verwenden wir chat_completion, weil das Modell Gesprächsempfehlungen basierend auf den Suchergebnissen und einem Systemprompt generieren kann. Dieser Endpoint ermöglicht es uns, Chatabschlüsse direkt von Elasticsearch aus auf einfache Weise mit der Elasticsearch-API durchzuführen:
Dies dient als Kern der Anwendung, der den Prompt und die Suchergebnisse empfängt, die durch das Modell laufen werden. Nachdem die Theorie geklärt ist, können wir mit der Implementierung der Anwendung beginnen.
Einrichten des Inferenz-Endpoints auf Hugging Face
Um das Hugging Face Modell bereitzustellen, werden wir Hugging Face One-Click-Deployments verwenden, einen einfachen und schnellen Service für die Bereitstellung von Modell-Endpoints. Beachten Sie bitte, dass es sich um einen kostenpflichtigen Service handelt, durch dessen Nutzung zusätzliche Kosten entstehen können. In diesem Schritt wird die Modellinstanz erstellt, die zur Generierung der Empfehlungen für die Artikel verwendet wird.
Sie können ein Modell aus dem Ein-Klick-Katalog aussuchen:
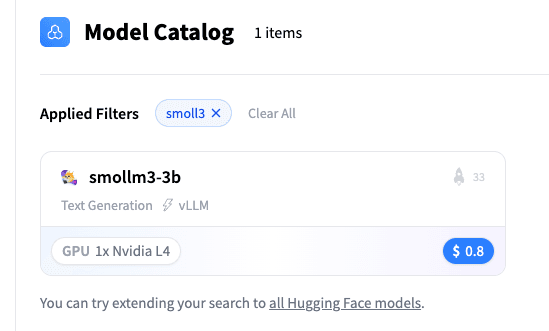
Wählen Sie das SmolLM3-3B Modell:

Hier können Sie die URL des Hugging Face Endpoints abrufen:
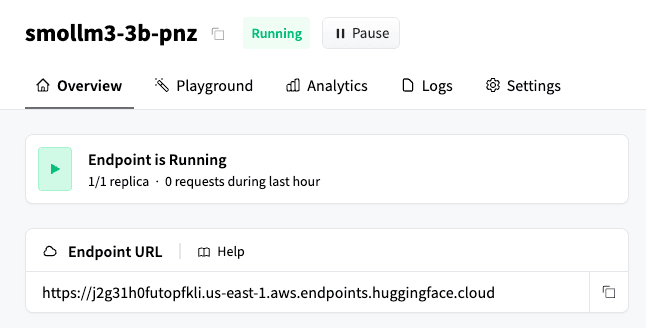
Wie in der Dokumentation zu den Hugging Face Inferenz-Endpunkten von Elasticsearch erwähnt, erfordert die Textgenerierung ein Modell, das mit der OpenAI-API kompatibel ist. Aus diesem Grund müssen wir den /v1/chat/completions-Subpfad an die Hugging Face Endpoint-URL anhängen. Das Ergebnis sieht wie folgt aus:
Mit dieser Voraussetzung können wir mit dem Codieren in einem Python-Notebook beginnen.
API-Schlüssel für Hugging Face generieren
Erstellen Sie ein Hugging Face Konto und erhalten Sie ein API-Token, indem Sie diesen Anweisungen folgen. Man kann zwischen drei Token-Typen wählen: detailliert (empfohlen für die Produktion, da es nur Zugriff auf bestimmte Ressourcen bietet); Lesezugriff (schreibgeschützt); oder Schreibzugriff (für Lese- und Schreibzugriff). Für dieses Tutorial ist ein Lesezugriffstoken ausreichend, da wir nur den Inferenz-Endpoint aufrufen müssen. Speichern Sie diesen Code für den nächsten Schritt.
Einrichten des Elasticsearch Inferenz-Endpoints
Zunächst legen wir einen Elasticsearch-Python-Client fest:
Danach erstellen wir einen Elasticsearch Inferenz-Endpoint, der das Hugging Face Modell verwendet. Dieser Endpoint ermöglicht es uns, Reaktionen zu generieren, die auf den Blogbeiträgen und dem an das Modell übergebenen Prompt basieren.
Datensatz
Der Datensatz enthält die Blogbeiträge, die abgefragt werden, und repräsentiert einen mehrsprachigen Inhaltssatz, der im gesamten Workflow verwendet wird:
Elasticsearch-Mappings
Mit dem definierten Datensatz müssen wir ein Datenschema erstellen, das der Struktur des Blogbeitrags entspricht. Die folgenden Index-Mappings werden verwendet, um die Daten in Elasticsearch zu speichern:
Hier können wir klar erkennen, wie die Daten strukturiert sind. Wir werden die semantische Suche verwenden, um Ergebnisse basierend auf natürlicher Sprache abzurufen, zusammen mit der copy_to-Eigenschaft, um den Feldinhalt in das semantic_text-Feld zu kopieren. Zusätzlich enthält das title-Feld zwei Unterfelder: Das original-Unterfeld speichert den Titel entweder auf Englisch oder Spanisch, abhängig von der Originalsprache des Artikels, und das translated_title-Unterfeld ist nur für spanische Artikel vorhanden und enthält die englische Übersetzung des Originaltitels.
Ingestieren von Daten
Der folgende Code-Schnipsel überträgt den Datensatz des Blogbeitrags in Elasticsearch mithilfe der Bulk-API:
Nun, da wir die Artikel in Elasticsearch aufgenommen haben, müssen wir eine Funktion erstellen, die nach dem Feld semantic_text sucht:
Wir benötigen außerdem eine Funktion, die den Endpoint aufruft. In diesem Fall rufen wir den Endpoint mit dem chat_completion Aufgabentyp auf, um Streaming-Antworten zu erhalten:
Nun können wir eine Funktion schreiben, die die semantische Suchfunktion, den chat_completions Inferenz-Endpoint und den Empfehlungs-Endoint aufruft, um die Daten zu generieren, die in den Karten angezeigt werden:
Abschließend müssen wir die Informationen extrahieren und formatieren, um sie zu drucken:
Wir führen einen Test durch, indem wir eine Frage zu den Sicherheitsblogbeiträgen stellen:
Hier sehen wir die vom Workflow in der Konsole generierten Karten:

Die vollständigen Ergebnisse, einschließlich aller Treffer und der LLM-Reaktion, können Sie in dieser Datei sehen.
Wir bitten um Artikel zum Thema: „Sicherheit und Schwachstellen“. Diese Frage wird als Suchabfrage gegen die in Elasticsearch gespeicherten Dokumente verwendet. Die abgerufenen Ergebnisse werden dann an das Modell weitergegeben, das basierend auf ihrem Inhalt Empfehlungen generiert. Wie wir sehen können, hat das Modell gute Arbeit geleistet und einen ansprechenden kurzen Text erstellt, der den Leser zum Anklicken motivieren kann.
Fazit
Dieses Beispiel zeigt, wie Elasticsearch und Hugging Face kombiniert werden können, um ein schnelles und effizientes zentrales System für KI-Anwendungen zu schaffen. Dieser Ansatz reduziert den manuellen Aufwand und bietet dank des umfangreichen Modellkatalogs von Hugging Face mehr Flexibilität. Insbesondere die Verwendung von SmolLM3-3B zeigt, wie kompakte, mehrsprachige Modelle in Kombination mit semantischer Suche weiterhin sinnvolles Schlussfolgern und Content-Generierung liefern können. Zusammen bieten diese Tools eine skalierbare und effektive Grundlage für die Entwicklung intelligenter Inhaltsanalysen und mehrsprachiger Anwendungen.
Zugehörige Inhalte

11. Mai 2026
Mehr Power für Elasticsearch: native Prometheus-API-Unterstützung hinzufügen
Elasticsearch kann direkt von Prometheus-kompatiblen Clients über native PromQL-, Discovery- und Metadaten-Endpunkte abgefragt werden. Senden Sie Daten an Elasticsearch mit Prometheus Remote Write.

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.
17. März 2026
Die Gemini CLI-Erweiterung für Elasticsearch mit Tools und Fähigkeiten
Wir stellen die Erweiterung von Elastic für Googles Gemini CLI vor, mit der Elasticsearch-Daten in Entwickler- und agentischen Workflows gesucht, abgerufen und analysiert werden können.