Bei der Optimierung von Elasticsearch für Workloads mit hoher Parallelität besteht der Standardansatz darin, den Arbeitsspeicher zu maximieren, um den Arbeitsdatensatz im Speicher zu halten und so eine geringe Suchlatenz zu erreichen. Daher wird best_compression selten für Such-Workloads berücksichtigt, da es in erster Linie als Speichereinsparungsmaßnahme für Elastic Observability und Elastic Security betrachtet wird, in denen Speichereffizienz Vorrang hat.
In diesem Blog zeigen wir, dass, wenn die Datensatzgröße den OS-Seitencache deutlich übersteigt, best_compression die Suchleistung und Ressourceneffizienz verbessert, indem der I/O-Engpass reduziert wird.
Das Setup
Unser Anwendungsfall ist eine Suchanwendung mit hoher Parallelität, die auf Elastic Cloud CPU-optimierten Instanzen ausgeführt wird.
- Datenvolumen: ~500 Millionen Dokumente
- Infrastruktur: 6 Elastic Cloud (Elasticsearch Service)-Instanzen (jede Instanz: 1,76 TB Speicher | 60 GB RAM | 31,9 vCPUs)
- Verhältnis von Arbeitsspeicher zu Speicher: Ungefähr 5 % des gesamten Datensatzes passen in den Arbeitsspeicher
Die Symptome: hohe Latenz
Wir haben beobachtet, dass sich die Suchlatenz deutlich verschlechterte, wenn die Anzahl der aktuellen Anfragen um 19:00 Uhr stark anstieg. Wie in Abbildung 1 und Abbildung 2 zu sehen ist, erreichte der Datenverkehr einen Spitzenwert von 400 Anfragen pro Minute und Elasticsearch-Instanz, während die durchschnittliche Abfragezeit auf über 60 ms sank.
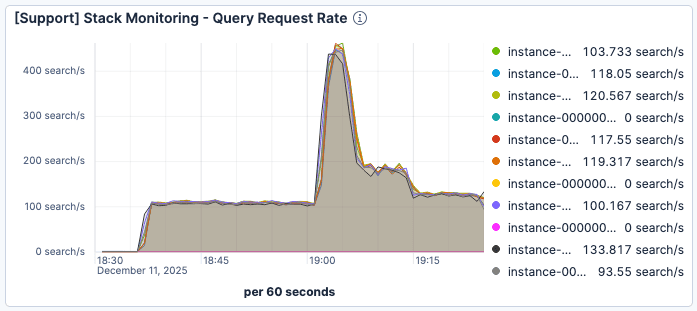
Abbildung 1: Die Anfragen pro Minute pro Elasticsearch-Instanz erreichten kurz nach 19:00 Uhr mit etwa 400 ihren Höhepunkt.
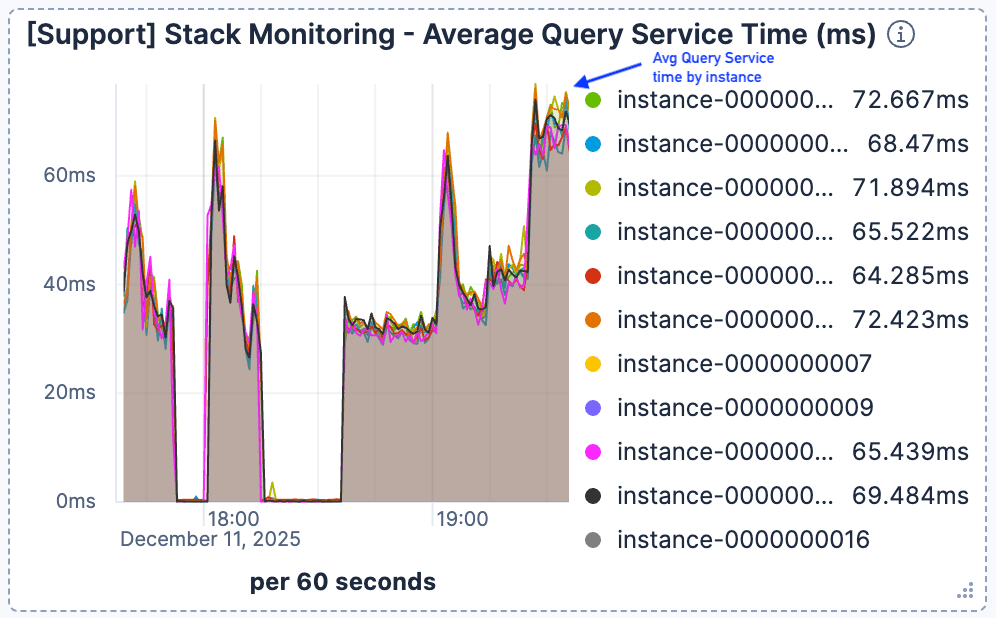
Abbildung 2. Die durchschnittliche Bearbeitungszeit der Anfragen stieg sprunghaft an und blieb bei über 60 ms.
Die CPU-Auslastung blieb nach der anfänglichen Verarbeitung der Verbindungen relativ niedrig, was darauf hindeutet, dass die Rechenleistung nicht der Engpass war.
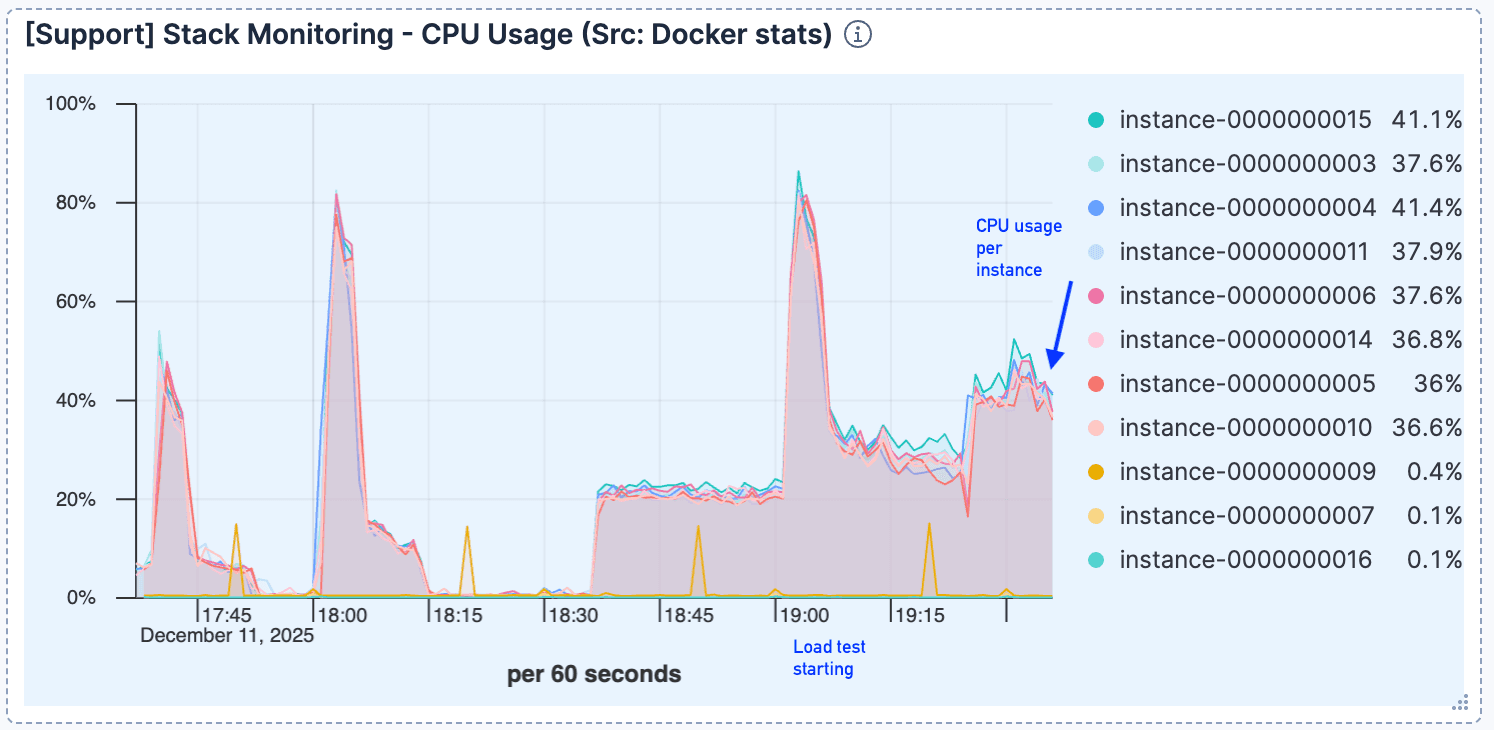
Abbildung 3: Nach dem ersten Sprung bleibt die CPU-Auslastung relativ niedrig.
Es zeigte sich eine starke Korrelation zwischen dem Abfragevolumen und den Seitenfehlern. Mit zunehmenden Anfragen beobachteten wir einen proportionalen Anstieg der Seitenfehler, mit einem Höchststand von etwa 400.000 pro Minute. Dies deutete darauf hin, dass der aktive Datensatz nicht in den Seitencache passte.
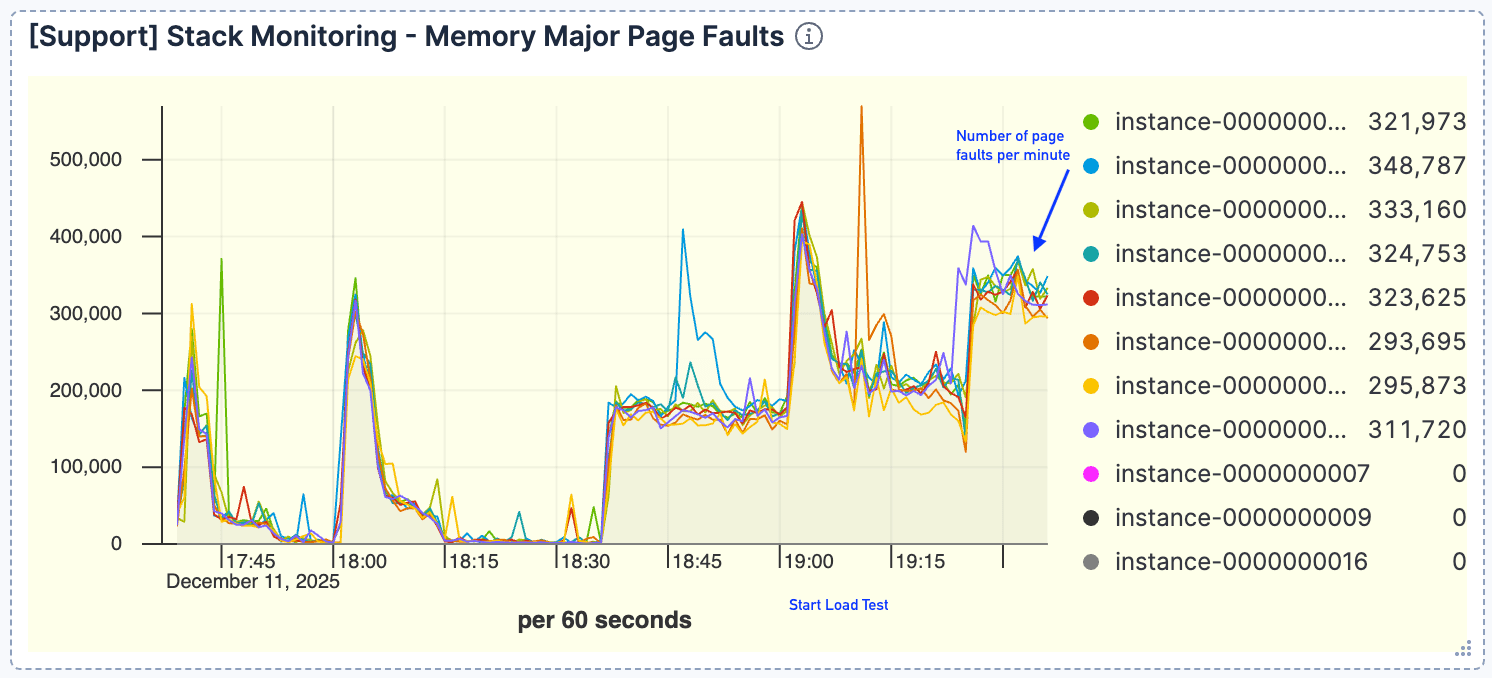
Abbildung 4. Die Anzahl der Seitenfehler war hoch, mit einem Höchststand von etwa 400.000/Minute.
Gleichzeitig schien die Heap-Nutzung der JVM normal und unauffällig zu sein. Dies schloss Probleme mit der Garbage Collection aus und bestätigte, dass der Engpass I/O war.
Abbildung 5. Die Heap-Nutzung blieb konstant.
Die Diagnose: I/O gebunden
Das System war I/O-gebunden. Elasticsearch nutzt den OS-Seitencache, um Indexdaten aus dem Speicher bereitzustellen. Wenn der Index zu groß für den Cache ist, lösen Abfragen kostspielige Festplatten-Lesevorgänge aus. Während die typische Lösung darin besteht, horizontal zu skalieren (Nodes/RAM hinzufügen), wollten wir zunächst alle Möglichkeiten zur Effizienzsteigerung unserer bestehenden Ressourcen ausschöpfen.
Die Lösung
Standardmäßig verwendet Elasticsearch LZ4-Kompression für seine Indexsegmente und findet so ein Gleichgewicht zwischen Geschwindigkeit und Größe. Wir stellten die Hypothese auf, dass ein Wechsel zu best_compression (das zstd verwendet) die Größe der Indizes verringern würde. Durch den geringeren Speicherbedarf kann ein größerer Prozentsatz des Index im Seitencache gespeichert werden, wodurch ein vernachlässigbarer Anstieg der CPU-Auslastung (für die Dekomprimierung) gegen eine Reduzierung der Festplatten-I/O eingetauscht wird.
Um best_compressionzu aktivieren, haben wir die Daten mit der Indexeinstellung index.codec: best_compressionneu indexiert. Alternativ könnte dasselbe Ergebnis erreicht werden, indem der Index geschlossen, der Indexcodec auf best_compressionzurückgesetzt und dann eine Segmentzusammenführung durchgeführt wird.
Die Ergebnisse
Die Ergebnisse bestätigten unsere Hypothese: Die verbesserte Speichereffizienz führte direkt zu einer erheblichen Steigerung der Suchleistung, ohne dass die CPU-Auslastung anstieg.
Durch die Anwendung von best_compression wurde die Indexgröße um etwa 25 % reduziert. Obwohl die Reduzierung geringer ausfiel als bei sich wiederholenden Log-Daten, erhöhte diese 25%ige Reduzierung effektiv unsere Seitencache-Kapazität um denselben Faktor.
Beim nächsten Auslastungstest (ab 17:00 Uhr) war der Traffic sogar noch höher und erreichte seinen Höhepunkt bei 500 Anfragen pro Minute pro Elasticsearch-Node.
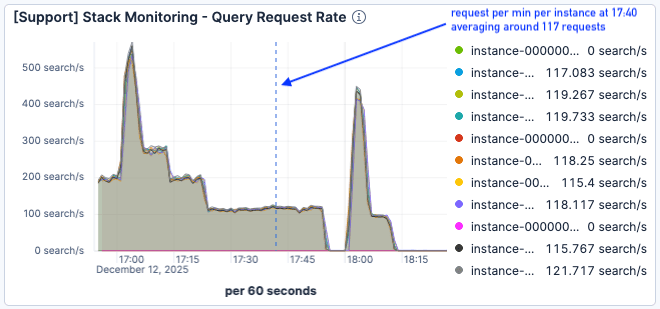
Abbildung 6: Der Belastungstest begann gegen 17:00 Uhr.
Trotz der höheren Last war die CPU-Auslastung geringer als in der vorherigen Ausführung. Die erhöhte Nutzung im früheren Test war wahrscheinlich auf den Overhead durch übermäßige Seitenfehlerbehandlung und Festplatten-I/O-Verwaltung zurückzuführen.
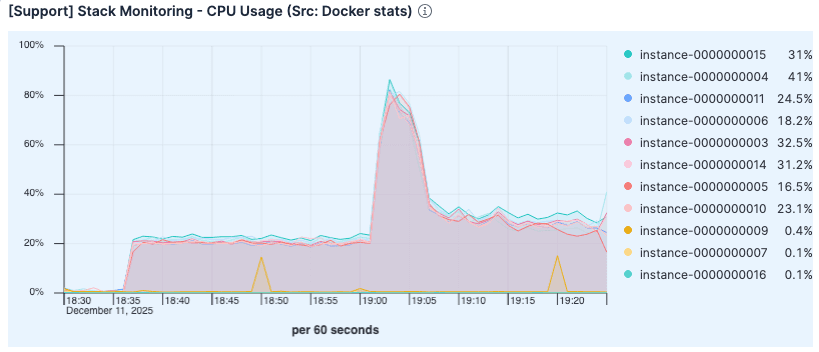
Abbildung 7. Die CPU-Auslastung war niedriger als bei der vorherigen Ausführung.
Entscheidend ist, dass die Seitenfehler deutlich zurückgingen. Selbst bei höherem Durchsatz lagen die Fehler bei etwa <200.000 pro Minute, verglichen mit >300.000 im Basistest.
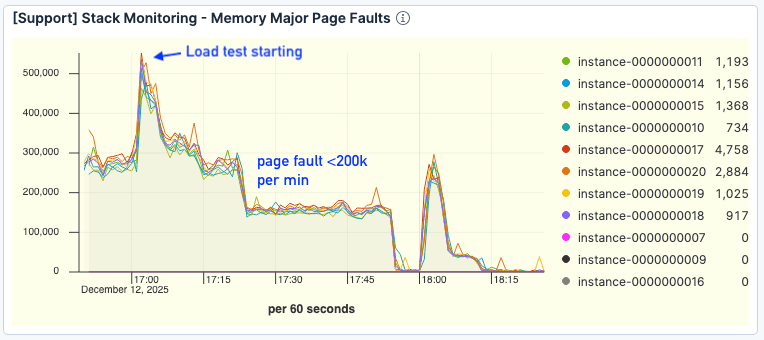
Abbildung 8. Die Anzahl der Seitenfehler hat sich deutlich verbessert.
Obwohl die Seitenfehlerergebnisse immer noch nicht optimal waren, wurde die Abfragedienstzeit um etwa 50 % reduziert und lag selbst bei höherer Last unter 30 ms.
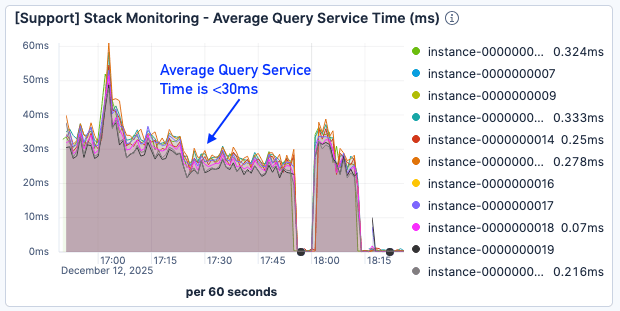
Abbildung 9. Die durchschnittliche Abfragedienstzeit betrug <30 ms.
Fazit: best_compression zum Suchen
Für Such-Anwendungsfälle, in denen das Datenvolumen den verfügbaren physischen Speicher übersteigt, ist best_compression ein kraftvoller Hebel zur Leistungsoptimierung.
Die herkömmliche Lösung für Cache-Fehler besteht darin, den Arbeitsspeicher (RAM) zu skalieren. Allerdings haben wir durch die Reduzierung der Indexgröße das gleiche Ziel erreicht: Maximierung der Dokumentanzahl im Seiten-Cache. Unser nächster Schritt ist es, die Indexsortierung zu untersuchen, um den Speicher weiter zu optimieren und noch mehr Leistung aus unseren bestehenden Ressourcen herauszuholen.
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

26. März 2026
Ankündigung von Leseberechtigungen für Kibana-Dashboards
Einführung von schreibgeschützten Dashboards in Kibana, die den Erstellern von Dashboards granulare Freigabekontrollen bieten, um die Ergebnisse korrekt zu halten und vor unerwünschten Änderungen zu schützen.
2. März 2026
Adaptive vorzeitige Beendigung für HNSW in Elasticsearch
Einführung einer neuen adaptiven Strategie zur vorzeitigen Beendigung von HNSW in Elasticsearch.

11. Dezember 2025
Bewertung der Relevanz von Suchanfragen mit Bewertungslisten
Erfahren Sie, wie Sie Bewertungslisten erstellen, um die Relevanz von Suchanfragen objektiv zu bewerten und Leistungsmetriken wie den Recall zu verbessern – für skalierbare Suchtests in Elasticsearch.

11. November 2025
Konfiguration der rekursiven Segmentierung für strukturierte Dokumente in Elasticsearch
Erfahren Sie, wie Sie rekursives Chunking in Elasticsearch mit Chunk-Größe, Trenngruppen und benutzerdefinierten Trennlisten für eine optimale strukturierte Dokumentenindizierung konfigurieren.