Wie heutzutage alle anderen setzen auch wir bei Elastic voll auf Chat, Agenten und RAG. In der Suchabteilung haben wir kürzlich an einem Agent Builder und einer Tool Registry gearbeitet, alles mit dem Ziel, die Interaktion mit Ihren Daten in Elasticsearch so einfach wie möglich zu gestalten.
Lesen Sie den Blogbeitrag „Building AI Agentic Workflows with Elasticsearch“, um mehr über das Gesamtbild dieser Bemühungen zu erfahren, oder „Your First Elastic Agent: From a Single Query to an AI-Powered Chat“ für eine praxisorientiertere Einführung.
In diesem Blogbeitrag wollen wir uns jedoch etwas genauer mit einem der ersten Dinge befassen, die beim Starten eines Chats passieren, und Ihnen einige der kürzlich vorgenommenen Verbesserungen vorstellen.
Was geschieht hier?

Wenn Sie mit Ihren Elasticsearch-Daten interagieren, durchläuft unser standardmäßiger KI-Agent diesen Standardablauf:
- Überprüfen Sie die Eingabeaufforderung.
- Ermitteln Sie, welcher Index wahrscheinlich die Antworten auf diese Frage enthält.
- Erstelle eine Abfrage für diesen Index basierend auf der Eingabeaufforderung.
- Durchsuchen Sie diesen Index mit dieser Suchanfrage.
- Die Ergebnisse zusammenfassen.
- Können die Ergebnisse die Fragestellung beantworten? Falls ja, antworten Sie bitte. Wenn nicht, wiederholen Sie den Vorgang, aber versuchen Sie etwas anderes.
Das sollte nicht allzu neuartig aussehen – es ist einfach nur Retrieval Augmented Generation (RAG). Wie zu erwarten, hängt die Qualität Ihrer Antworten stark von der Relevanz Ihrer ersten Suchergebnisse ab. Während wir an der Verbesserung unserer Antwortqualität gearbeitet haben, haben wir den Abfragen, die wir in Schritt 3 generiert und in Schritt 4 ausgeführt haben, sehr große Aufmerksamkeit geschenkt. Und wir haben ein interessantes Muster festgestellt.
Oftmals lag es bei unseren ersten, „schlechten“ Antworten nicht daran, dass wir eine fehlerhafte Abfrage ausgeführt hatten. Das lag daran, dass wir den falschen Index für die Abfrage ausgewählt hatten . Die Schritte 3 und 4 waren normalerweise nicht unser Problem – es war Schritt 2.
Was haben wir gemacht?
Unsere erste Implementierung war einfach. Wir hatten ein Tool (namens index_explorer) entwickelt, das effektiv eine _cat/indices -Auflistung aller verfügbaren Indizes durchführt und anschließend den LLM auffordert, denjenigen dieser Indizes zu ermitteln, der am besten zur Nachricht/Frage/Aufforderung des Benutzers passt. Die ursprüngliche Implementierung können Sie hier einsehen.
Wie gut funktionierte das? Wir waren uns nicht sicher! Wir hatten klare Beispiele, wo es nicht gut funktionierte, aber unsere eigentliche erste Herausforderung bestand darin, unseren aktuellen Zustand zu quantifizieren.
Festlegung einer Ausgangsbasis
Es beginnt mit Daten
Was wir brauchten, war ein Referenzdatensatz, um die Effektivität eines Tools bei der Auswahl des richtigen Index anhand einer Benutzereingabe und einer bereits vorhandenen Menge von Indizes zu messen. Und wir hatten keinen solchen Datensatz zur Hand. Also haben wir einen generiert.
Hinweis: Wir wissen, dass dies nicht die „Best Practice“ ist. Manchmal ist es aber besser, vorwärts zu gehen, als auf der Stelle zu treten. Fortschritt, schlichte Perfektion.
Wir haben mithilfe dieser Eingabeaufforderung Startindizes für verschiedene Domänen generiert. Anschließend generierten wir für jede generierte Domäne mithilfe dieser Eingabeaufforderung einige weitere Indizes (Ziel war es, das LLM mit schwierigen Negativen und schwer zu klassifizierenden Beispielen zu verwirren). Anschließend haben wir jeden generierten Index und seine Beschreibungen manuell bearbeitet. Abschließend generierten wir mithilfe dieser Eingabeaufforderung Testabfragen. Dies ergab Beispieldaten wie:

und Testfälle wie:
Anfertigung eines Testgeschirrs
Der weitere Ablauf war von hier an sehr einfach. Entwerfen Sie ein Tool, das Folgendes kann:
- Erstellen Sie eine saubere Ausgangsbasis mit einem Elasticsearch-Zielcluster.
- Erstelle alle im Zieldatensatz definierten Indizes.
- Führen Sie für jedes Testszenario das Tool i
ndex_exploreraus (praktischerweise verfügen wir über eine Execute Tool API). - Vergleiche den Ergebnisindex mit dem erwarteten Index und speichere das Ergebnis.
- Nachdem alle Testszenarien abgeschlossen sind, werden die Ergebnisse tabellarisch erfasst.
Laut einer Umfrage…
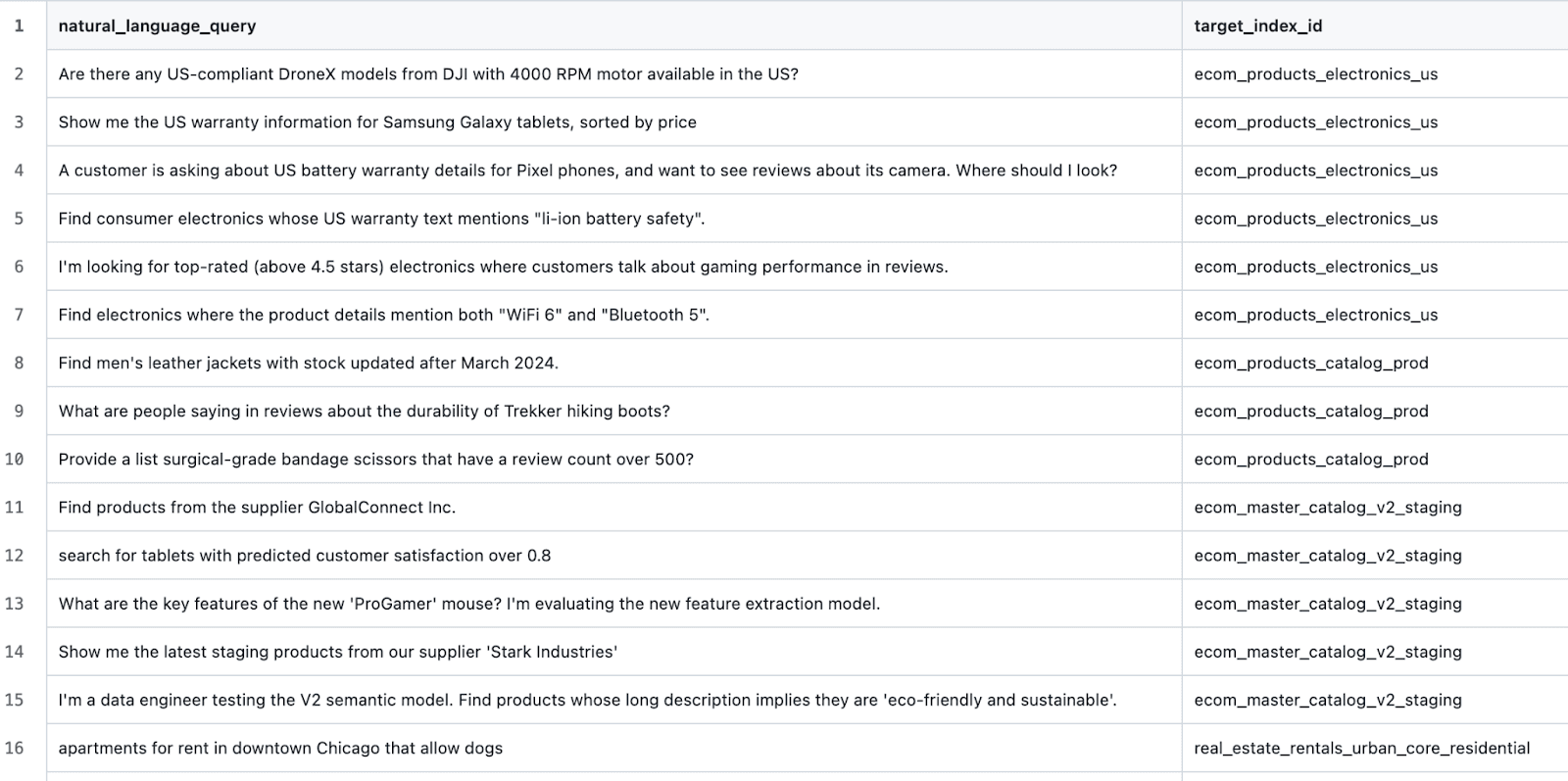
Die ersten Ergebnisse waren wenig überraschend mittelmäßig.
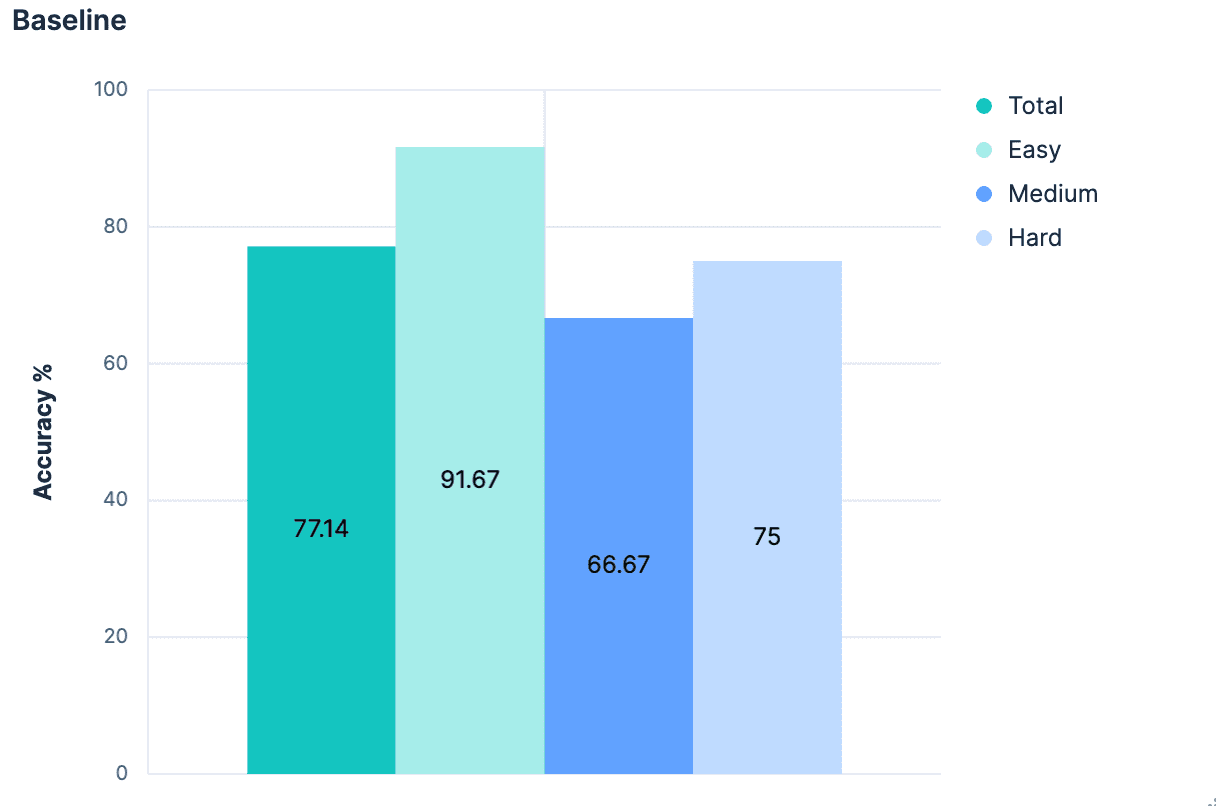
Insgesamt lag die Trefferquote bei der Identifizierung des richtigen Index bei 77,14 %. Und das war ein „Best-Case“-Szenario, in dem alle Indizes gute, semantisch aussagekräftige Namen haben. Jeder, der schon einmal `PUT test2/_doc/foo {...}` ausgeführt hat, weiß, dass die Indizes nicht immer aussagekräftige Namen haben.
Wir haben also einen Ausgangspunkt, und dieser zeigt, dass es noch viel Raum für Verbesserungen gibt. Nun war es Zeit für etwas Wissenschaft! 🧪
Experimentieren
Hypothese 1: Kartierungen werden helfen
Das Ziel hierbei ist es, einen Index zu identifizieren, der Daten enthält, die für die ursprüngliche Fragestellung relevant sind. Und der Teil eines Index, der die darin enthaltenen Daten am besten beschreibt, sind die Indexzuordnungen. Selbst ohne Stichproben aus dem Indexinhalt zu entnehmen, lässt die Tatsache, dass der Index ein Preisfeld vom Typ double besitzt, darauf schließen, dass die Daten etwas darstellen, das verkauft werden soll. Ein Autorenfeld vom Typ Text impliziert unstrukturierte Sprachdaten. Die Kombination der beiden Begriffe könnte darauf hindeuten, dass es sich bei den Daten um Bücher/Geschichten/Gedichte handelt. Allein aus der Kenntnis der Eigenschaften eines Index lassen sich viele semantische Hinweise ableiten. In einem lokalen Branch habe ich also unsere `.index_explorer`-Methode angepasst. Tool zum Senden der vollständigen Zuordnungen eines Index (samt Namen) an das LLM zur Entscheidungsfindung.
Das Ergebnis (aus den Kibana-Protokollen):
Die ursprünglichen Entwickler des Tools hatten dies vorhergesehen. Während die Zuordnung eines Index eine wahre Fundgrube an Informationen darstellt, ist sie gleichzeitig ein ziemlich umfangreicher JSON-Block. Und in einem realistischen Szenario, in dem man zahlreiche Indizes vergleicht (unser Evaluierungsdatensatz definiert 20), summieren sich diese JSON-Blobs. Wir möchten dem LLM also mehr Kontext für seine Entscheidung geben als nur Indexnamen für alle Optionen, aber nicht so sehr die vollständigen Zuordnungen jeder einzelnen.
Hypothese 2: „Vereinfachte“ Zuordnungen (Feldlisten) als Kompromiss
Wir gingen von der Annahme aus, dass Indexersteller semantisch aussagekräftige Indexnamen verwenden würden. Was wäre, wenn wir diese Annahme auch auf Feldnamen ausdehnen würden? Unser vorheriges Experiment scheiterte, weil Mapping-JSON eine Menge überflüssiger Metadaten und Boilerplate-Code enthält.
Der obige Block beispielsweise umfasst 236 Zeichen und definiert lediglich ein einzelnes Feld in einem Elasticsearch-Mapping. Die Zeichenkette „description_text“ hingegen umfasst nur 16 Zeichen. Das entspricht einer fast 15-fachen Erhöhung der Zeichenanzahl, ohne dass sich die semantische Aussagekraft dieses Feldes hinsichtlich der verfügbaren Daten sinnvoll verbessert. Was wäre, wenn wir Zuordnungen für alle Indizes abrufen, diese aber vor dem Senden an das LLM zu einer Liste ihrer Feldnamen „vereinfachen“ würden?
Wir haben es versucht.

Das ist großartig! Durchweg Verbesserungen. Aber könnten wir es besser machen?
Hypothese 3: Beschreibungen in der Mapping-Datei _meta
Wenn schon Feldnamen ohne zusätzlichen Kontext einen so großen Sprung verursachen, wäre das Hinzufügen von substanziellem Kontext vermutlich noch besser! Es ist nicht unbedingt üblich, jedem Index eine Beschreibung beizufügen, aber es ist möglich, dem _meta-Objekt der Zuordnung Metadaten auf Indexebene jeglicher Art hinzuzufügen. Wir haben unsere generierten Indizes erneut aufgerufen und jedem Index in unserem Datensatz eine Beschreibung hinzugefügt. Solange die Beschreibungen nicht übermäßig lang sind, sollten sie weniger Tokens verwenden als die vollständige Zuordnung und einen deutlich besseren Einblick in die im Index enthaltenen Daten bieten. Unser Experiment bestätigte diese Hypothese.
Eine kleine Verbesserung, und wir liegen jetzt durchweg bei über 90 % Genauigkeit.
Hypothese 4: Das Ganze ist größer als seine Teile
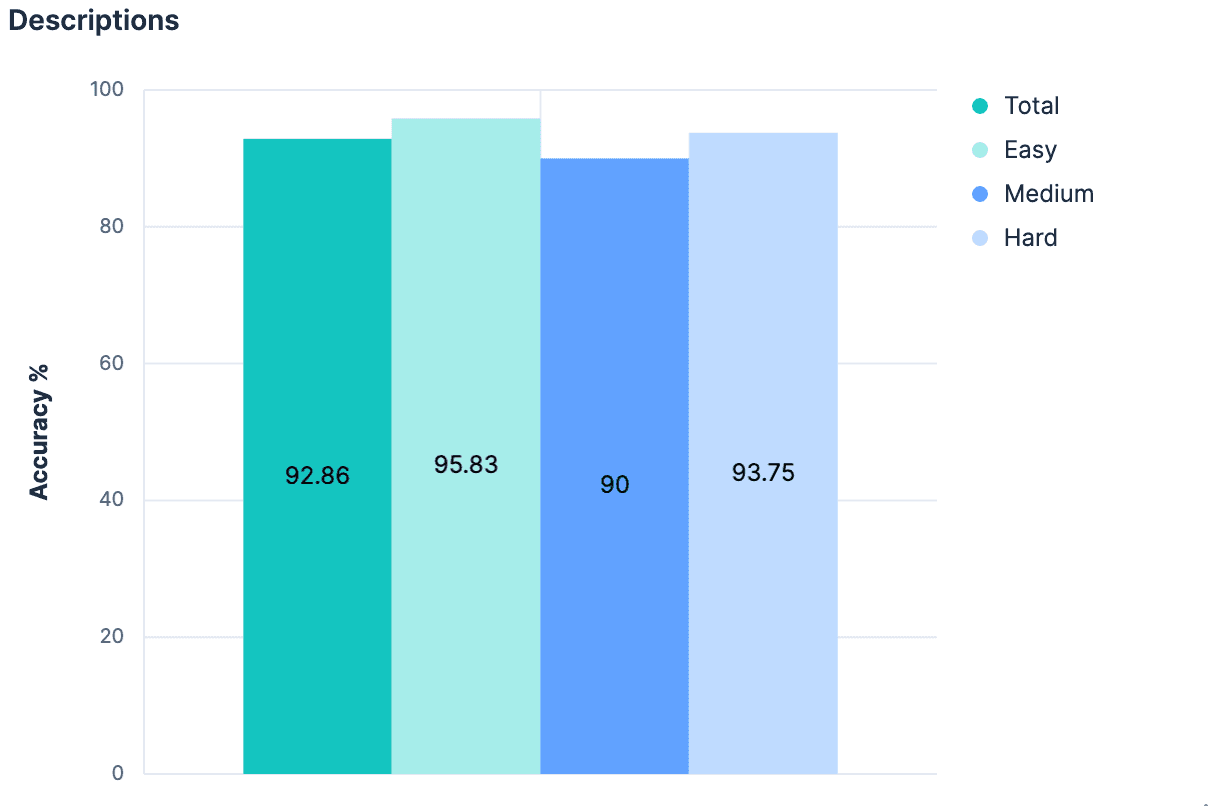
Feldnamen haben unsere Ergebnisse verbessert. Die Beschreibungen verbesserten unsere Ergebnisse. Die Verwendung von Beschreibungen UND Feldnamen sollte also noch bessere Ergebnisse liefern, richtig?
Die Daten ergaben „nein“ (keine Veränderung gegenüber dem vorherigen Experiment). Die vorherrschende Theorie hierbei war, dass, da die Beschreibungen von vornherein aus den Indexfeldern/Zuordnungen generiert wurden, zwischen diesen beiden Kontextelementen nicht genügend unterschiedliche Informationen vorhanden sind, um bei ihrer Kombination etwas „Neues“ hinzuzufügen. Darüber hinaus wird die Nutzlast, die wir für unsere 20 Testindizes senden, ziemlich groß. Der Gedankengang, dem wir bisher gefolgt sind, ist nicht skalierbar. Tatsächlich gibt es guten Grund zu der Annahme, dass keines unserer bisherigen Experimente auf Elasticsearch-Clustern funktionieren würde, bei denen Hunderte oder Tausende von Indizes zur Auswahl stehen. Ein Ansatz, der die Größe der an den LLM gesendeten Nachricht linear mit der Gesamtzahl der Indizes erhöht, dürfte wahrscheinlich keine allgemein anwendbare Strategie darstellen.
Was wir wirklich brauchen, ist ein Ansatz, der uns hilft, eine große Anzahl von Kandidaten auf die relevantesten Optionen zu reduzieren…
Wir haben es hier mit einem Suchproblem zu tun.
Hypothese 5: Selektion durch semantische Suche
Wenn der Name eines Indexes eine semantische Bedeutung hat, dann kann er als Vektor gespeichert und semantisch durchsucht werden.
Wenn die Feldnamen eines Index eine semantische Bedeutung haben, dann können sie als Vektoren gespeichert und semantisch durchsucht werden.
Wenn ein Index eine Beschreibung mit semantischer Bedeutung besitzt, kann auch diese als Vektor gespeichert und semantisch durchsucht werden.
Aktuell sind diese Informationen mit Elasticsearch-Indizes nicht durchsuchbar (vielleicht sollten wir das ändern!), aber es war relativ einfach, etwas zusammenzubasteln , das diese Lücke umgehen konnte. Mithilfe des Connector-Frameworks von Elastic habe ich einen Connector erstellt, der für jeden Index in einem Cluster ein Dokument ausgibt. Die Ausgabedokumente würden etwa so aussehen:
Ich habe diese Dokumente in einen neuen Index verschoben, in dem ich die Zuordnung manuell wie folgt definiert habe:
Dadurch entsteht ein einzelnes semantisches Inhaltsfeld, in dem alle anderen Felder mit semantischer Bedeutung zusammengefasst und indiziert werden. Die Suche in diesem Index wird trivial, mit lediglich:
Das modifizierte index_explorer -Tool ist jetzt wesentlich schneller, da es keine Anfrage an ein LLM stellen muss, sondern stattdessen eine einzelne Einbettung für die gegebene Anfrage anfordern und eine effiziente Vektorsuche durchführen kann. Wenn wir den Spitzenreiter als unseren ausgewählten Index verwenden, erhalten wir folgende Ergebnisse:

Dieser Ansatz ist skalierbar. Diese Vorgehensweise ist effizient. Dieser Ansatz ist aber kaum besser als unser Ausgangszustand. Das ist allerdings nicht überraschend; der Suchansatz ist hier unglaublich naiv. Da gibt es keine Nuancen. Es wird nicht anerkannt, dass der Name und die Beschreibung eines Index mehr Gewicht haben sollten als ein beliebiger Feldname, der im Index enthalten ist. Es besteht keine Möglichkeit, exakte lexikalische Übereinstimmungen gegenüber synonymen Übereinstimmungen zu gewichten. Allerdings müsste man für die Erstellung einer hochdifferenzierten Abfrage eine Menge Annahmen über die vorliegenden Daten treffen. Bis jetzt haben wir bereits einige große Annahmen darüber getroffen, dass Index- und Feldnamen eine semantische Bedeutung haben, aber wir müssten noch einen Schritt weiter gehen und anfangen anzunehmen, wie viel Bedeutung sie haben und wie sie zueinander in Beziehung stehen. Ohne dies zu tun, können wir wahrscheinlich nicht zuverlässig die beste Übereinstimmung als unser Top-Ergebnis identifizieren, sondern können eher sagen, dass die beste Übereinstimmung irgendwo unter den Top N Ergebnissen liegt. Wir benötigen etwas, das semantische Informationen in dem Kontext, in dem sie existieren, verarbeiten, mit einer anderen Entität vergleichen kann, die sich möglicherweise auf eine semantisch unterschiedliche Weise darstellt, und zwischen ihnen urteilen kann. Wie ein LLM.
Hypothese 6: Reduktion der Kandidatenmenge
Es gab noch einige weitere Experimente, die ich hier nur kurz erwähnen werde, aber der entscheidende Durchbruch bestand darin, den Wunsch aufzugeben, die beste Übereinstimmung ausschließlich anhand einer semantischen Suche auszuwählen, und stattdessen die semantische Suche als Filter zu nutzen, um irrelevante Indizes aus der Betrachtung des LLM auszusortieren. Wir kombinierten Linear Retrievers, Hybrid Search mit RRF und semantic_text für unsere Suche und beschränkten die Ergebnisse auf die Top 5 übereinstimmenden Indizes.
Anschließend haben wir für jede Übereinstimmung den Namen des Index, die Beschreibung und die Feldnamen zu einer Nachricht für das LLM hinzugefügt. Die Ergebnisse waren fantastisch:
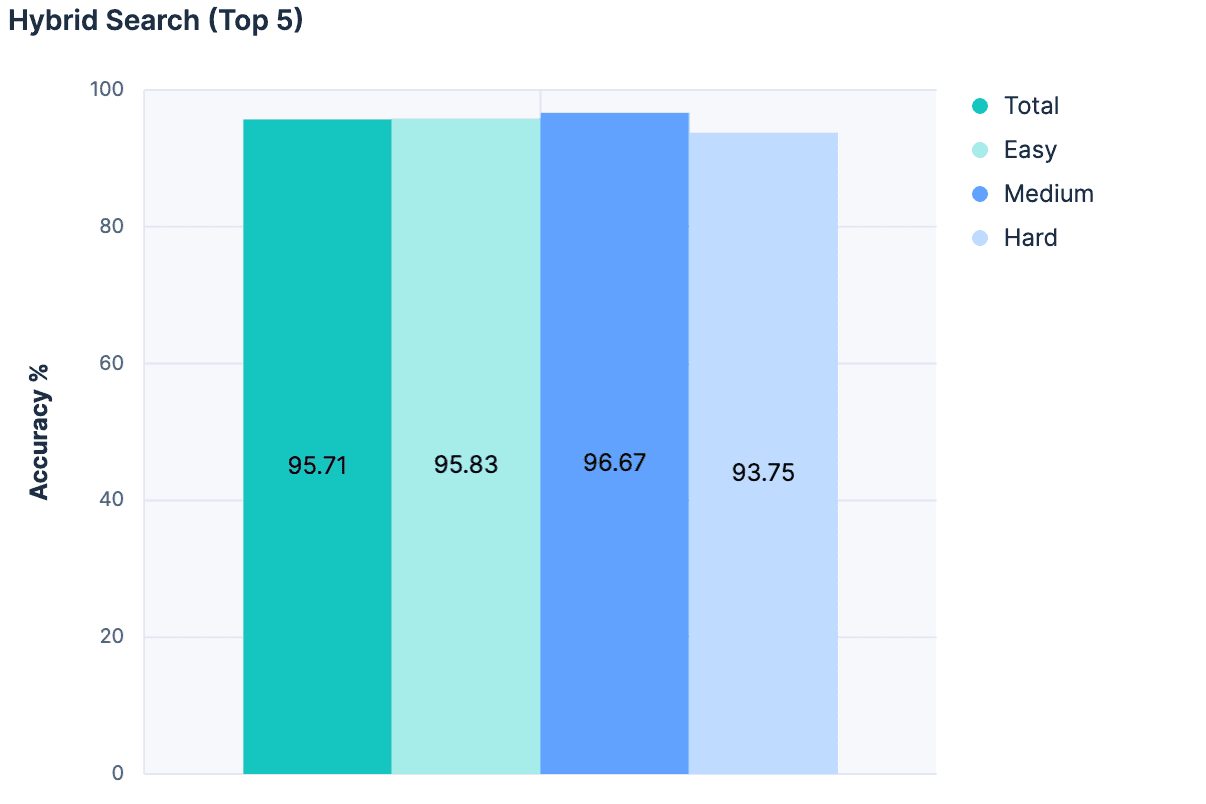
Die höchste Genauigkeit, die je in einem Experiment erzielt wurde! Und weil bei diesem Ansatz die Nachrichtengröße nicht proportional zur Gesamtzahl der Indizes ansteigt, ist dieser Ansatz weitaus besser skalierbar.
Ergebnisse
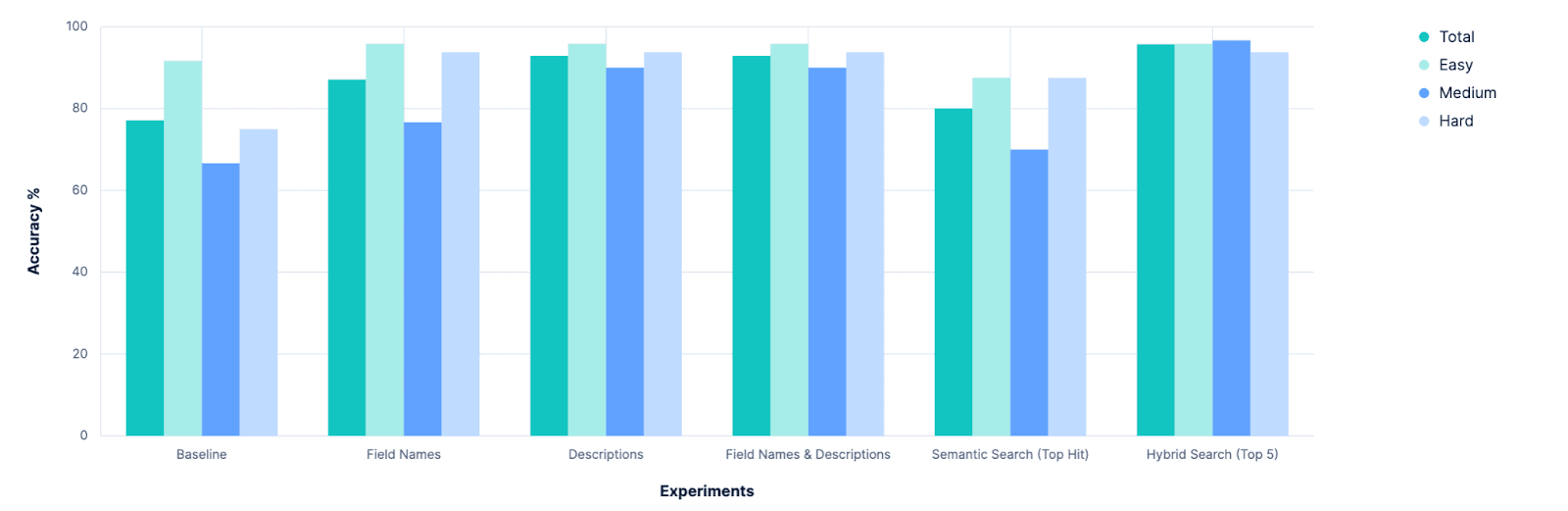
Das erste eindeutige Ergebnis war, dass unsere Ausgangslage verbessert werden kann . Dies erscheint im Nachhinein offensichtlich, aber bevor die Experimente begannen, gab es ernsthafte Diskussionen darüber, ob wir unser index_explorer -Tool ganz aufgeben und uns auf eine explizite Konfiguration durch den Benutzer verlassen sollten, um den Suchraum einzuschränken. Auch wenn dies nach wie vor eine praktikable und gültige Option darstellt, zeigt diese Studie, dass es vielversprechende Wege zur Automatisierung der Indexauswahl gibt, wenn solche Benutzereingaben nicht verfügbar sind.
Das nächste eindeutige Ergebnis war, dass das bloße Hinzufügen weiterer beschreibender Zeichen zur Lösung des Problems immer weniger Nutzen bringt. Vor dieser Studie hatten wir darüber diskutiert, ob wir in den Ausbau der Elasticsearch-Funktionalität zur Speicherung von Metadaten auf Feldebene investieren sollten. Heute sind diese meta -Werte auf 50 Zeichen begrenzt, und es gab die Annahme, dass wir diesen Wert erhöhen müssten, um ein semantisches Verständnis unserer Felder zu erlangen. Dies ist eindeutig nicht der Fall, und das LLM scheint mit reinen Feldnamen recht gut zurechtzukommen. Wir werden dies möglicherweise später noch genauer untersuchen, aber es erscheint uns momentan nicht dringlich.
Umgekehrt hat dies deutlich gezeigt, wie wichtig „durchsuchbare“ Indexmetadaten sind. Für diese Experimente haben wir einen Index von Indizes gehackt. Aber das ist etwas, was wir untersuchen könnten, indem wir es direkt in Elasticsearch integrieren, APIs zur Verwaltung erstellen oder zumindest eine Konvention dafür festlegen. Wir werden unsere Optionen abwägen und intern diskutieren, also bleiben Sie gespannt.
Letztendlich hat diese Anstrengung den Wert darin bestätigt, uns Zeit für Experimente zu nehmen und datengestützte Entscheidungen zu treffen. Tatsächlich hat es uns geholfen, erneut zu bestätigen, dass unser Agent Builder-Produkt robuste, im Produkt integrierte Evaluierungsfunktionen benötigt. Wenn wir ein komplettes Test-Framework nur für ein Tool entwickeln müssen, das Indizes auswählt, benötigen unsere Kunden unbedingt Möglichkeiten, ihre kundenspezifischen Tools qualitativ zu bewerten, während sie iterative Anpassungen vornehmen.
Ich bin gespannt, was wir bauen werden, und ich hoffe, Sie auch!
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

26. März 2026
Ankündigung von Leseberechtigungen für Kibana-Dashboards
Einführung von schreibgeschützten Dashboards in Kibana, die den Erstellern von Dashboards granulare Freigabekontrollen bieten, um die Ergebnisse korrekt zu halten und vor unerwünschten Änderungen zu schützen.