Von der Vektorsuche bis hin zu leistungsstarken REST-APIs bietet Elasticsearch Entwicklern das umfangreichste Toolkit für Suchvorgänge. Entdecken Sie unsere Beispiel-Notebooks im Elasticsearch Labs Repository, um etwas Neues auszuprobieren. Sie können auch heute noch Ihre kostenlose Testphase starten oder Elasticsearch lokal ausführen.
Die Vektorsuche bildet die Grundlage für die Implementierung der semantischen Suche nach Text oder der Ähnlichkeitssuche nach Bildern, Videos oder Audio. Bei der Vektorsuche handelt es sich bei den Vektoren um mathematische Darstellungen von Daten, die sehr groß und manchmal langsam sein können. Die bessere binäre Quantisierung (im Folgenden als BBQ bezeichnet) funktioniert als Komprimierungsmethode für Vektoren. Es ermöglicht Ihnen, die richtigen Übereinstimmungen zu finden und gleichzeitig die Vektoren zu verkleinern, damit sie schneller durchsucht und verarbeitet werden können. Dieser Artikel behandelt BBQ und rescore_vector, ein Feld, das nur für quantisierte Indizes verfügbar ist und Vektoren automatisch neu bewertet.
Alle vollständigen Abfragen und Ausgaben, die in diesem Artikel erwähnt werden, finden Sie in unserem Elasticsearch Labs-Code-Repository.
Warum sollten Sie Better Binary Quantization (BBQ) in Ihrem Anwendungsfall einsetzen?
Hinweis: Um ein tieferes Verständnis der Mathematik hinter BBQ zu erhalten, lesen Sie bitte den Abschnitt „Weiterführende Informationen“ weiter unten. Für die Zwecke dieses Blogs liegt der Schwerpunkt auf der Implementierung.
Die mathematischen Hintergründe sind zwar faszinierend, aber unerlässlich, wenn Sie vollständig verstehen wollen, warum Ihre Vektorsuchen präzise bleiben. Letztendlich dreht sich alles um Komprimierung, da sich herausgestellt hat, dass man mit den aktuellen Vektorsuchalgorithmen durch die Lesegeschwindigkeit der Daten begrenzt ist. Wenn Sie also all diese Daten im Arbeitsspeicher unterbringen können, erzielen Sie im Vergleich zum Lesen vom Speicher eine erhebliche Geschwindigkeitssteigerung (der Arbeitsspeicher ist etwa 200-mal schneller als SSDs).
Es gibt ein paar Dinge zu beachten:
- Graphenbasierte Indizes wie HNSW (Hierarchical Navigable Small World) sind für die Vektorabfrage am schnellsten.
- HNSW: Ein ungefährer Suchalgorithmus für den nächsten Nachbarn, der eine mehrschichtige Graphstruktur erstellt, um effiziente hochdimensionale Ähnlichkeitssuchen zu ermöglichen.
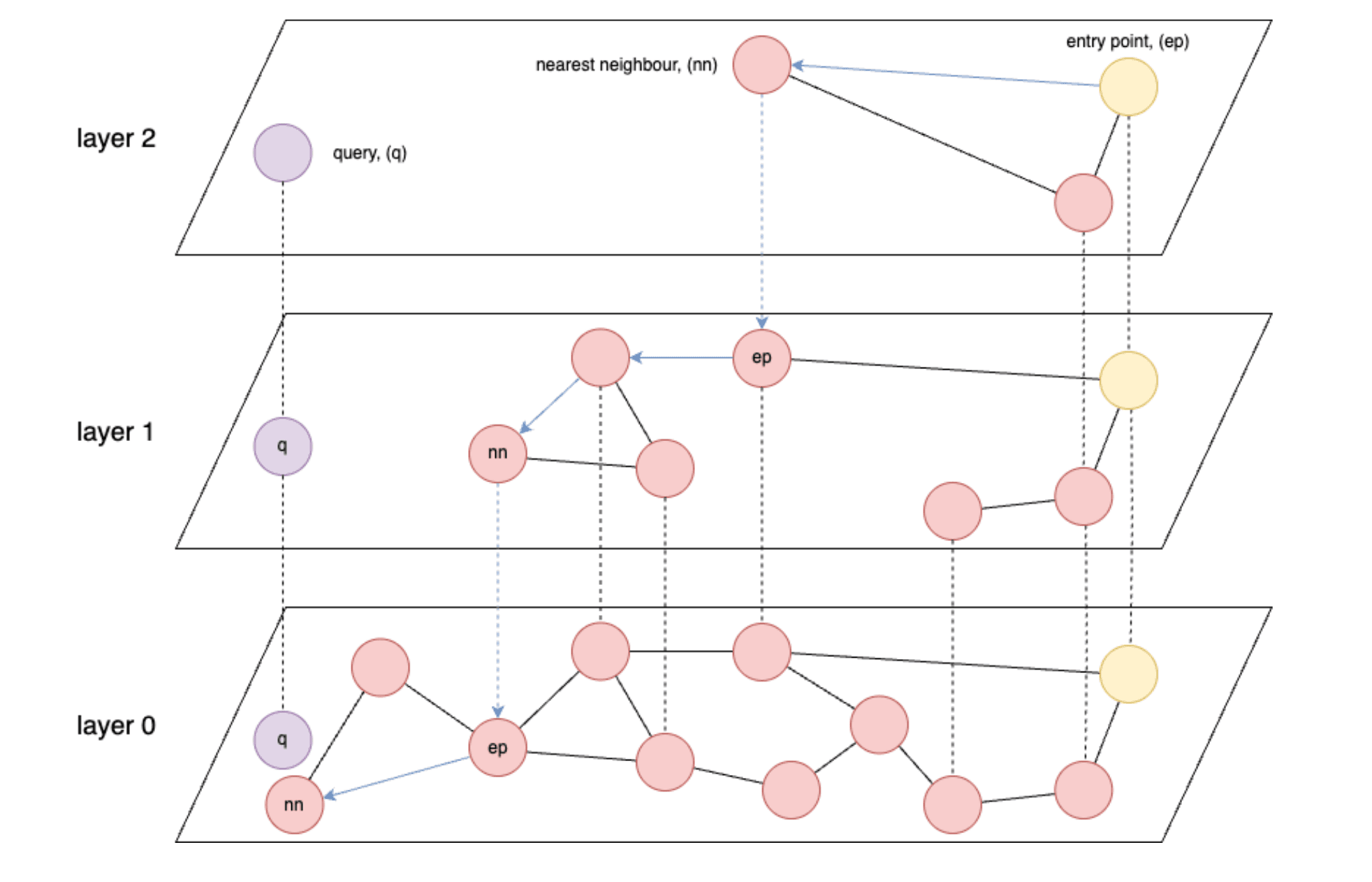
- Die Geschwindigkeit von HNSW wird grundsätzlich durch die Datenlesegeschwindigkeit aus dem Speicher oder im schlimmsten Fall aus dem Speicher begrenzt.
- Idealerweise möchten Sie alle Ihre gespeicherten Vektoren in den Speicher laden können.
- Einbettungsmodelle erzeugen im Allgemeinen Vektoren mit Float32-Präzision, 4 Bytes pro Gleitkommazahl.
- Und schließlich kann es, je nachdem, wie viele Vektoren und/oder Dimensionen Sie haben, sehr schnell passieren, dass Ihnen nicht genügend Speicher zur Verfügung steht, um alle Ihre Vektoren zu speichern.
Wenn man dies als gegeben voraussetzt, erkennt man, dass schnell ein Problem entsteht, wenn man Millionen oder sogar Milliarden von Vektoren mit jeweils potenziell Hunderten oder sogar Tausenden von Dimensionen verarbeitet. Der Abschnitt „ Ungefähre Zahlen zu den Kompressionsverhältnissen“ enthält einige grobe Zahlen.
Was brauchen Sie für den Anfang?
Für den Anfang benötigen Sie Folgendes:
- Wenn Sie Elastic Cloud oder vor Ort verwenden, benötigen Sie eine höhere Version von Elasticsearch als 8.18. Während BBQ in 8.16 eingeführt wurde, verwenden Sie in diesem Artikel
vector_rescore, das in 8.18 eingeführt wurde. - Darüber hinaus müssen Sie sicherstellen, dass in Ihrem Cluster ein Knoten für maschinelles Lernen (ML) vorhanden ist. (Hinweis: Zum Laden des Modells ist ein ML-Knoten mit mindestens 4 GB erforderlich, für die vollständige Produktionsarbeitslast werden Sie jedoch wahrscheinlich viel größere Knoten benötigen.)
- Wenn Sie Serverless verwenden, müssen Sie eine Instanz auswählen, die für Vektoren optimiert ist.
- Darüber hinaus benötigen Sie Grundkenntnisse im Umgang mit Vektordatenbanken. Wenn Sie mit den Konzepten der Vektorsuche in Elastic noch nicht vertraut sind, sollten Sie sich zunächst die folgenden Ressourcen ansehen:
Verbesserte Binärquantisierung (BBQ)-Implementierung
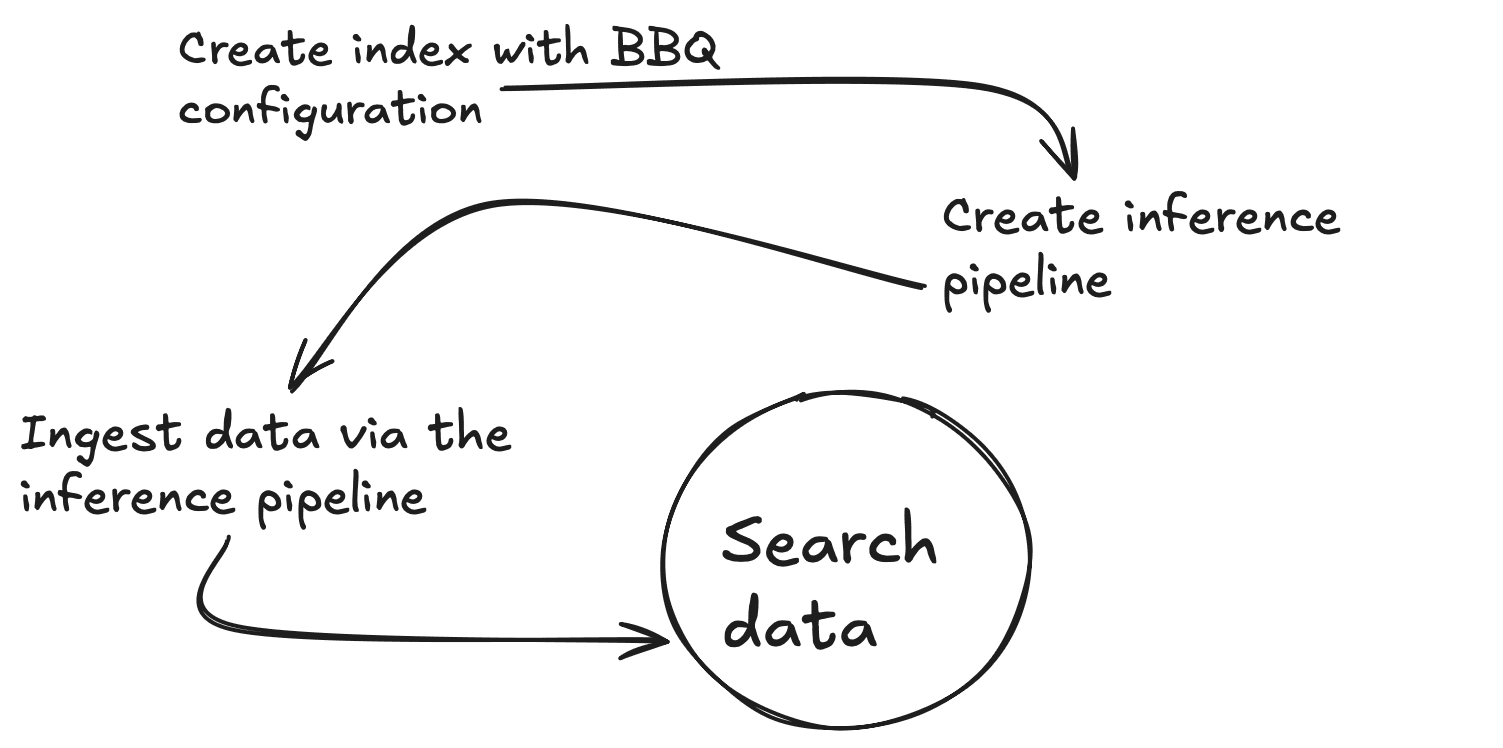
Um diesen Blog einfach zu halten, verwenden Sie integrierte Funktionen, wenn diese verfügbar sind. In diesem Fall verfügen Sie über das Vektor-Einbettungsmodell .multilingual-e5-small , das direkt in Elasticsearch auf einem Machine-Learning-Knoten ausgeführt wird. Beachten Sie, dass Sie das Modell text_embedding durch den Embedder Ihrer Wahl ersetzen können (OpenAI, Google AI Studio, Cohere und viele mehr). Wenn Ihr bevorzugtes Modell noch nicht integriert ist, können Sie auch Ihre eigenen dichten Vektoreinbettungen mitbringen.)
Zuerst müssen Sie einen Inferenzendpunkt erstellen, um Vektoren für einen bestimmten Textabschnitt zu generieren. Sie führen alle diese Befehle von der Kibana Dev Tools-Konsole aus. Dieser Befehl lädt .multilingual-e5-small herunter. Wenn es noch nicht vorhanden ist, wird Ihr Endpunkt eingerichtet. Dies kann eine Minute dauern. Sie können die erwartete Ausgabe in der Datei 01-create-an-inference-endpoint-output.json im Ordner „Outputs“ sehen.
Sobald dies zurückgegeben wurde, ist Ihr Modell eingerichtet und Sie können mit dem folgenden Befehl testen, ob das Modell wie erwartet funktioniert. Sie können die erwartete Ausgabe in der Datei 02-embed-text-output.json im Ordner „Outputs“ sehen.
Wenn bei Ihnen Probleme auftreten, weil Ihr trainiertes Modell keinem Knoten zugewiesen wird, müssen Sie Ihr Modell möglicherweise manuell starten.
Erstellen wir nun eine neue Zuordnung mit 2 Eigenschaften, einem Standardtextfeld (my_field) und einem dichten Vektorfeld (my_vector) mit 384 Dimensionen, um der Ausgabe des Einbettungsmodells zu entsprechen. Sie werden auch index_options.type to bbq_hnsw überschreiben. Sie können die erwartete Ausgabe in der Datei 03-create-byte-qauntized-index-output.json im Ordner „Outputs“ sehen.
Um sicherzustellen, dass Elasticsearch Ihre Vektoren generiert, können Sie eine Ingest-Pipeline verwenden. Diese Pipeline erfordert drei Dinge: den Endpunkt (model_id), die input_field , für die Sie Vektoren erstellen möchten, und die output_field , in der diese Vektoren gespeichert werden. Der erste Befehl unten erstellt eine Inferenz-Ingest-Pipeline, die den Inferenzdienst im Hintergrund verwendet, und der zweite testet, ob die Pipeline ordnungsgemäß funktioniert. Sie können die erwartete Ausgabe in der Datei 04-create-and-simulate-ingest-pipeline-output.json im Ordner „Outputs“ sehen.
Sie können nun mit den ersten beiden Befehlen unten einige Dokumente hinzufügen und mit dem dritten Befehl testen, ob Ihre Suchvorgänge funktionieren. Sie können die erwartete Ausgabe in der Datei 05-bbq-index-output.json im Ordner „Outputs“ überprüfen.
Wie in diesem Beitrag empfohlen, sind Neubewertung und Überabtastung ratsam, wenn Sie auf nicht triviale Datenmengen skalieren, da sie dazu beitragen, eine hohe Rückrufgenauigkeit aufrechtzuerhalten und gleichzeitig von den Komprimierungsvorteilen zu profitieren. Ab Elasticsearch Version 8.18 können Sie dies auf diese Weise mit rescore_vector tun. Die erwartete Ausgabe befindet sich in der Datei 06-bbq-search-8-18-output.json im Ordner „Outputs“.
Wie schneiden diese Werte im Vergleich zu denen ab, die Sie für Rohdaten erhalten würden? Wenn Sie alles oben Gesagte noch einmal machen, aber mit index_options.type: hnsw, werden Sie sehen, dass die Ergebnisse sehr vergleichbar sind. Sie können die erwartete Ausgabe in der Datei 07-raw-vector-output.json im Ordner „Outputs“ sehen.
Ungefähre Zahlen zu den Kompressionsverhältnissen
Bei der Arbeit mit der Vektorsuche können Speicher- und Arbeitsspeicheranforderungen schnell zu einer erheblichen Herausforderung werden. Die folgende Aufschlüsselung veranschaulicht, wie verschiedene Quantisierungstechniken den Speicherbedarf von Vektordaten drastisch reduzieren.
| Vektoren (V) | Abmessungen (D) | roh (V x D x 4) | int8 (V x (D x 1 + 4)) | int4 (V x (D x 0,5 + 4)) | Grill (V x (D x 0,125 + 4)) |
|---|---|---|---|---|---|
| 10.000.000 | 384 | 14,31 GB | 3,61 GB | 1,83 GB | 0,58 GB |
| 50.000.000 | 384 | 71,53 GB | 18,07 GB | 9,13 GB | 2,89 GB |
| 100.000.000 | 384 | 143,05 GB | 36,14 GB | 18,25 GB | 5,77 GB |
Fazit
BBQ ist eine Optimierung, die Sie zur Komprimierung Ihrer Vektordaten anwenden können, ohne die Genauigkeit zu beeinträchtigen. Dabei werden Vektoren in Bits umgewandelt, sodass Sie die Daten effektiv durchsuchen und Ihre KI-Workflows skalieren können, um die Suche zu beschleunigen und die Datenspeicherung zu optimieren.
Weiterführendes Lernen
Wenn Sie mehr über BBQ erfahren möchten, sehen Sie sich unbedingt die folgenden Ressourcen an:
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

20. März 2026
Schnell vs. genau: Messung der Recall-Rate bei der quantisierten Vektorsuche
Eine Erklärung, wie der Recall für die Vektorsuche in Elasticsearch mit minimalem Aufwand gemessen werden kann.