Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
TLDR: Elasticsearch is up to 12x faster - We at Elastic have received numerous requests from our community to clarify the performance differences between Elasticsearch and OpenSearch, particularly in the realm of Semantic Search / Vector Search, so we have undertaken this performance testing to provide a clear, data-driven comparison — no ambiguity, just straightforward facts to inform our users. The results show that Elasticsearch is up to 12x faster than OpenSearch for vector search and therefore requires fewer computational resources. This reflects Elastic's focus on consolidating Lucene as the best vector database for search and retrieval use cases.
Vector search is revolutionizing the way we conduct similarity searches, particularly in fields like AI and machine learning. With the increasing adoption of vector embedding models, the ability to efficiently search through millions of high-dimension vectors becomes critical.
When it comes to powering vector databases, Elastic and OpenSearch have taken notably different approaches. Elastic has invested heavily in optimizing Apache Lucene together with Elasticsearch to elevate them as the top-tier choice for vector search applications. In contrast, OpenSearch has broadened its focus, integrating other vector search implementations and exploring beyond Lucene's scope. Our focus on Lucene is strategic, enabling us to provide highly integrated support in our version of Elasticsearch, resulting in an enhanced feature set where each component complements and amplifies the capabilities of the other.
This blog presents a detailed comparison between Elasticsearch 8.14 and OpenSearch 2.14 accounting for different configurations and vector engines. In this performance analysis, Elasticsearch proved to be the superior platform for vector search operations, and upcoming features will widen the differences even more significantly. When pitted against OpenSearch, it excelled in every benchmark track — offering 2x to 12x faster performance on average. This was across scenarios using varying vector amounts and dimensions including so_vector (2M vectors, 768D), openai_vector (2.5M vectors, 1536D), and dense_vector (10M vectors, 96D), all available in this repository alongside the Terraform scripts for provisioning all the required infrastructure on Google Cloud and Kubernetes manifests for running the tests.
The results detailed in this blog complement the results from a previously published and third-party validated study that shows Elasticsearch is 40%–140% faster than OpenSearch for the most common search analytics operations: Text Querying, Sort, Range, Date Histogram and Terms filtering. Now we can add another differentiator: Vector Search.
Up to 12x faster out-of-the-box
Our focused benchmarks across the four vector data sets involved both Approximate KNN and Exact KNN searches, considering different sizes, dimensions and configurations, totaling 40.189.820 uncached search requests. The results: Elasticsearch is up to 12x faster than OpenSearch for vector search and therefore requires fewer computational resources.

Figure 1: Grouped tasks for ANN and Exact KNN across different combinations in Elasticsearch and OpenSearch.
The groups like knn-10-100 means KNN search with and . In HNSW vector search, determines the number of nearest neighbors to retrieve for a query vector. It specifies how many similar vectors to find as a result. sets the number of candidate vectors to retrieve at each segment. More candidates can enhance accuracy but require greater computational resources.
We also tested with different quantization techniques and leveraged engine-specific optimizations, the detailed results for each track, task and vector engine are available below.
Exact KNN and Approximate KNN
When dealing with varying data sets and use cases, the right approach for vector search will differ. In this blog all tasks stated as knn-* like knn-10-100 use Approximate KNN and script-score-* refer to Exact KNN, but what is the difference between them, and why are they important?
In essence, if you're handling more substantial data sets, the preferred method is the Approximate K-Nearest Neighbor (ANN) due to its superior scalability. For more modest data sets that may require a filtration process, Exact KNN method is ideal.
Exact KNN uses a brute-force method, calculating the distance between one vector and every other vector in the data set. It then ranks these distances to find the nearest neighbors. While this method ensures an exact match, it suffers from scalability challenges for large, high-dimensional data sets. However, there are many cases in which Exact KNN is needed:
- Rescoring: In scenarios involving lexical or semantic searches followed by vector-based rescoring, Exact KNN is essential. For example, in a product search engine, initial search results can be filtered based on textual queries (e.g., keywords, categories), and then vectors associated with the filtered items are used for a more accurate similarity assessment.
- Personalization: When dealing with a large number of users, each represented by a relatively small number (like 1 million) of distinct vectors, sorting the index by user-specific metadata (e.g., user_id) and brute-force scoring with vectors becomes efficient. This approach allows for personalized recommendations or content delivery based on precise vector comparisons tailored to individual user preferences.
Exact KNN therefore ensures that the final ranking and recommendations based on vector similarity are precise and tailored to user preferences.
Approximate KNN (or ANN) on the other hand employs methods to make data searching faster and more efficient than Exact KNN, especially in large, high-dimensional data sets. Instead of a brute-force approach, which measures the exact nearest distance between a query and all points leading to computation and scaling challenges, ANN uses certain techniques to efficiently restructure the indexes and dimensions of searchable vectors in the data set. While this may cause a slight inaccuracy, it significantly boosts the speed of the search process, making it an effective alternative for dealing with large data sets.
In this blog all tasks stated as knn-* like knn-10-100 use Approximate KNN and script-score-* refer to Exact KNN.
Testing methodology
While Elasticsearch and OpenSearch are similar in terms of API for BM25 search operations, since the latter is a fork of the former, it is not the case for Vector Search, which was introduced after the fork. OpenSearch took a different approach than Elasticsearch when it comes to algorithms, by introducing two other engines — nmslib and faiss — apart from lucene, each with their specific configurations and limitations (e.g., nmslib in OpenSearch does not allow for filters, an essential feature for many use cases).
All three engines use the Hierarchical Navigable Small World (HNSW) algorithm, which is efficient for approximate nearest neighbor search, and especially powerful when dealing with high-dimensional data. It's important to note that faiss also supports a second algorithm, ivf, but since it requires pre-training on the data set, we are going to focus solely on HNSW. The core idea of HNSW is to organize the data into multiple layers of connected graphs, with each layer representing a different granularity of the data set. The search begins at the top layer with the coarsest view and progresses down to finer and finer layers until reaching the base level.
Both search engines were tested under identical conditions in a controlled environment to ensure fair testing grounds. The method applied is similar to this previously published performance comparison, with dedicated node pools for Elasticsearch, OpenSearch, and Rally. The terraform script is available (alongside all sources) to provision a Kubernetes cluster with:
- 1 Node pool for Elasticsearch with 3
e2-standard-32machines (128GB RAM and 32 CPUs) - 1 Node pool for OpenSearch with 3
e2-standard-32machines (128GB RAM and 32 CPUs) - 1 Node pool for Rally with 2
t2a-standard-16machines (64GB RAM and 16 CPUs)
Each "track" (or test) ran for 10 times for each configuration, which included different engines, different configurations and different vector types. The tracks have tasks that repeat between 1000 and 10000 times, depending on the track. If one of the tasks in a track failed for instance due to a network timeout, then all tasks were discarded, so all results represent tracks that started and finished without problems. All test results are statistically validated, ensuring that improvements aren’t coincidental.
Detailed findings
Why compare using the 99th percentile and not the average latency? Consider a hypothetical example of average house prices in a certain neighborhood. The average price may indicate an expensive area, but on closer inspection, it may turn out that most homes are valued much lower, with only a few luxury properties inflating the average figure. This illustrates how the average price can fail to accurately represent the full spectrum of house values in the area. This is akin to examining response times, where the average can conceal critical issues.
Tasks
- Approximate KNN with k:10 n:50
- Approximate KNN with k:10 n:100
- Approximate KNN with k:100 n:1000
- Approximate KNN with k:10 n:50 and keyword filters
- Approximate KNN with k:10 n:100 and keyword filters
- Approximate KNN with k:100 n:1000 and keyword filters
- Approximate KNN with k:10 n:100 in conjunction with indexing
- Exact KNN (script score)
Vector engines
lucenein Elasticsearch and OpenSearch, both on version 9.10faissin OpenSearchnmslibin OpenSearch
Vector types
hnswin Elasticsearch and OpenSearchint8_hnswin Elasticsearch (HNSW with automatic 8 bit quantization: link)sq_fp16 hnswin OpenSearch (HNSW with automatic 16 bit quantization: link)
Out-of-the-box and Concurrent Segment Search
As you probably know, Lucene is a highly performant text search engine library written in Java that serves as the backbone for many search platforms like Elasticsearch, OpenSearch, and Solr. At its core, Lucene organizes data into segments, which are essentially self-contained indices that allow Lucene to execute searches more efficiently. So when you issue a search to any Lucene-based search engine, your search will end up being executed in those segments, either sequentially or in parallel.
OpenSearch introduced concurrent segment search as an optional flag, and does not use it by default, you must enable it using a special index setting index.search.concurrent_segment_search.enabled as detailed here, with some limitations.
Elasticsearch on the other hand searches on segments concurrently out-of-the-box, therefore the comparisons we make in this blog will take into consideration, on top of the different vector engines and vector types, also the different configurations:
- Elasticsearch ootb: Elasticsearch out-of-the-box, with concurrent segment search;
- OpenSearch ootb: without concurrent segment search enabled;
- OpenSearch css: with concurrent segment search enabled
Now, let’s dive into some detailed results for each vector data set tested:
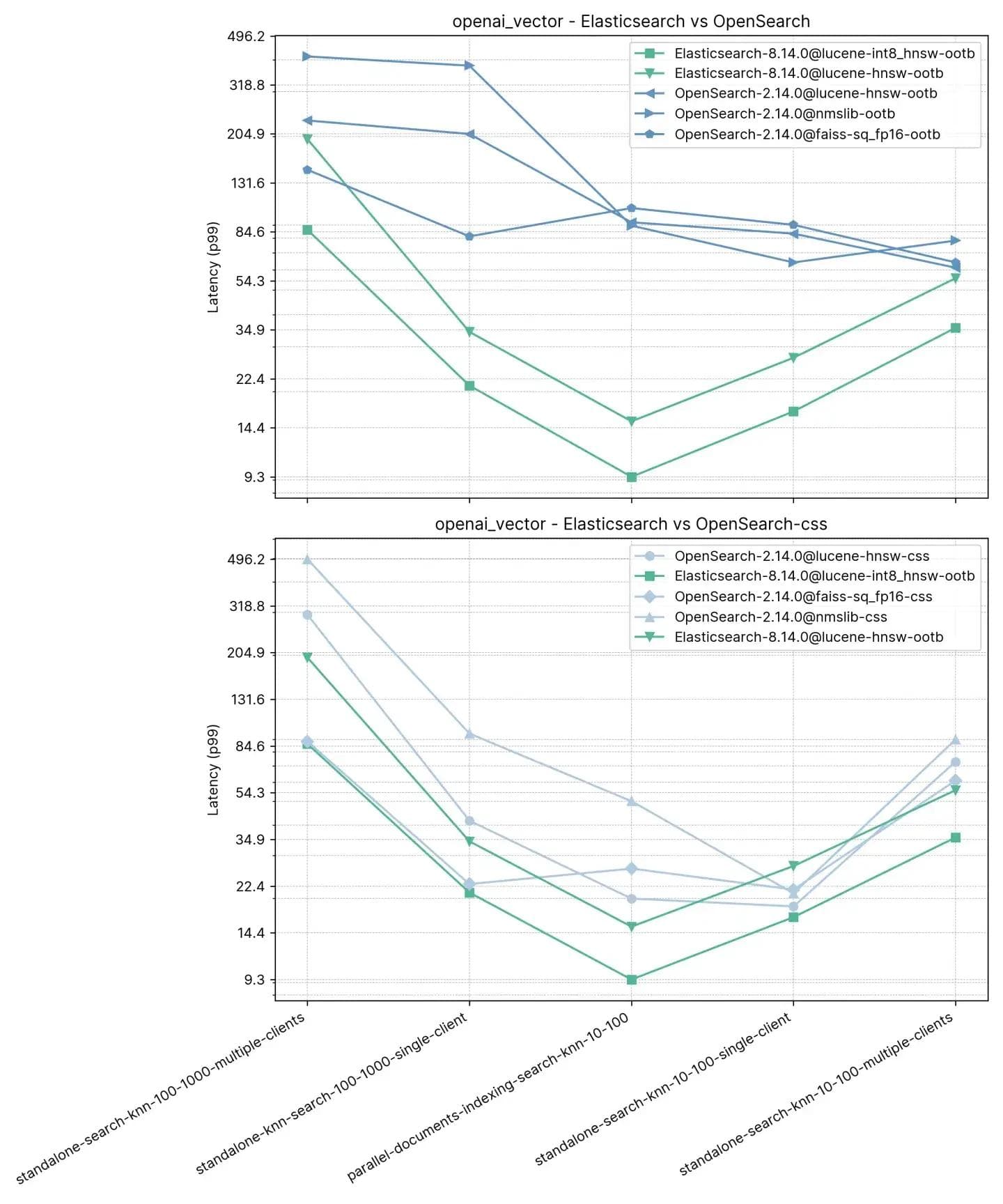
2.5 million vectors, 1536 dimensions (openai_vector)
Starting with the simplest track, but also the largest in terms of dimensions, openai_vector - which uses the NQ data set enriched with embeddings generated using OpenAI's text-embedding-ada-002 model. It is the simplest since it tests only Approximate KNN and has only 5 tasks. It tests in standalone (without indexing) as well as alongside indexing, and using a single client and 8 simultaneous clients.
Tasks
- standalone-search-knn-10-100-multiple-clients: searching on 2.5 million vectors with 8 clients simultaneously, k: 10 and n:100
- standalone-search-knn-100-1000-multiple-clients: searching on 2.5 million vectors with 8 clients simultaneously, k: 100 and n:1000
- standalone-search-knn-10-100-single-client: searching on 2.5 million vectors with a single client, k: 10 and n:100
- standalone-search-knn-100-1000-single-client: searching on 2.5 million vectors with a single client, k: 100 and n:1000
- parallel-documents-indexing-search-knn-10-100: searching on 2.5 million vectors while also indexing additional 100000 documents, k:10 and n:100
The averaged p99 performance is outlined below:

Here we observed that Elasticsearch is between 3x-8x faster than OpenSearch when performing vector search alongside indexing (i.e. read+write) with :10 and :100 and 2x-3x faster without indexing for the same k and n. For :100 and :1000 (standalone-search-knn-100-1000-single-client and standalone-search-knn-100-1000-multiple-clients Elasticsearch is 2x to 7x faster than OpenSearch, on average.
The detailed results show the exact cases and vector engines compared:
Recall
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0.969485 | 0.995138 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0.781445 | 0.784817 |
| OpenSearch-2.14.0@lucene-hnsw | 0.96519 | 0.995422 |
| OpenSearch-2.14.0@faiss | 0.984154 | 0.98049 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0.980012 | 0.97721 |
| OpenSearch-2.14.0@nmslib | 0.982532 | 0.99832 |
10 million vectors, 96 dimensions (dense_vector)
In dense_vector with 10M vectors and 96 dimensions. It is based on the Yandex DEEP1B image data set. The data set is created from the first 10 million vectors of the "sample data" file called learn.350M.fbin. The search operations use vectors from the "query data" file query.public.10K.fbin.
Both Elasticsearch and OpenSearch perform very well on this data set, especially after a force merge which is usually done on read-only indices and it’s similar to defragmenting the index to have a single "table" to search on.
Tasks
Each task warms up for 100 requests and then 1000 requests are measured
- knn-search-10-100: searching on 10 million vectors, k: 10 and n:100
- knn-search-100-1000: searching on 10 million vectors, k: 100 and n:1000
- knn-search-10-100-force-merge: searching on 10 million vectors after a force merge, k: 10 and n:100
- knn-search-100-1000-force-merge: searching on 10 million vectors after a force merge, k: 100 and n:1000
- knn-search-100-1000-concurrent-with-indexing: searching on 10 million vectors while also updating 5% of the data set, k: 100 and n:1000
- script-score-query: Exact KNN search of 2000 specific vectors.
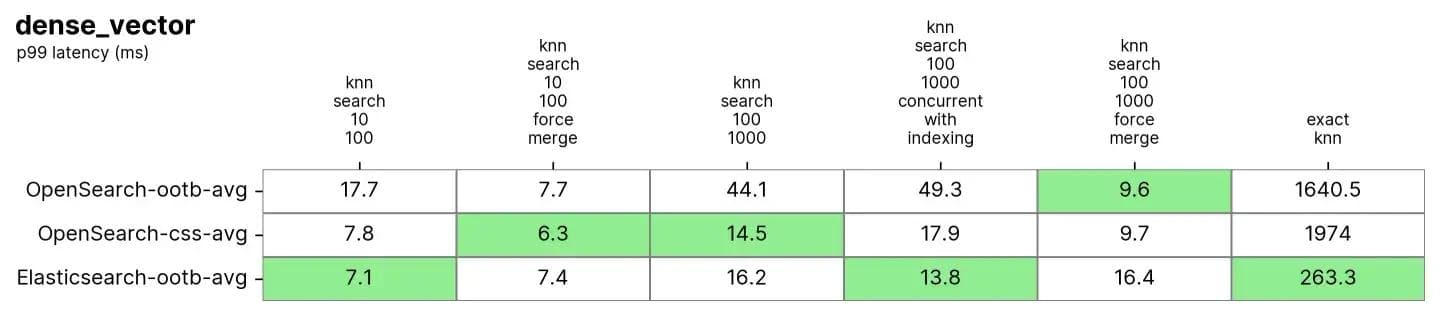
Both Elasticsearch and OpenSearch performed well for Approximate KNN. When the index is merged (i.e. has just a single segment) in knn-search-100-1000-force-merge and knn-search-10-100-force-merge, OpenSearch performs better than the others when using nmslib and faiss, even though they are all around 15ms and all very close.
However, when the index has multiple segments (a typical situation where an index receives updates to its documents) in knn-search-10-100 and knn-search-100-1000, Elasticsearch keeps the latency in about ~7ms and ~16ms, while all other OpenSearch engines are slower.
Also when the index is being searched and written to at the same time (knn-search-100-1000-concurrent-with-indexing), Elasticsearch maintains the latency below 15ms (at 13.8ms), being almost 4x faster than OpenSearch out-of-the-box (49.3ms) and still faster when concurrent segment search is enabled (17.9ms), but too close to be significative.
As for Exact KNN, the difference is much larger: Elasticsearch is 6x faster than OpenSearch (~260ms vs ~1600ms).
Recall
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0.969843 | 0.996577 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0.775458 | 0.840254 |
| OpenSearch-2.14.0@lucene-hnsw | 0.971333 | 0.996747 |
| OpenSearch-2.14.0@faiss | 0.9704 | 0.914755 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0.968025 | 0.913862 |
| OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 |
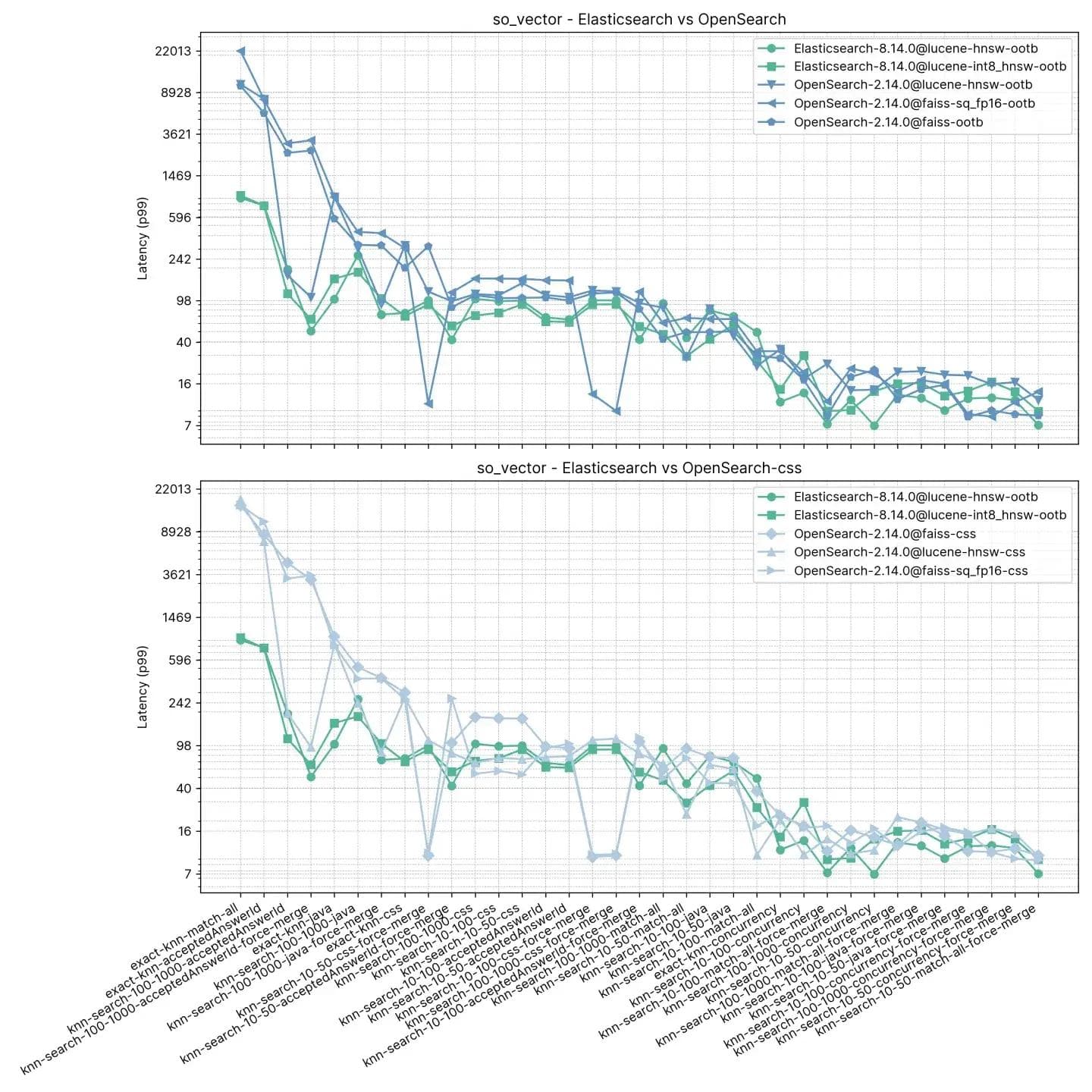
2 million vectors, 768 dimensions (so_vector)
This track, so_vector, is derived from a dump of StackOverflow posts downloaded on April, 21st 2022. It only contains question documents — all documents representing answers have been removed. Each question title was encoded into a vector using the sentence transformer model multi-qa-mpnet-base-cos-v1. This data set contains the first 2 million questions.
Unlike the previous track, each document here contains other fields besides vectors to support testing features like Approximate KNN with filtering and hybrid search. nmslib for OpenSearch is notably absent in this test since it does not support filters.
Tasks
Each task warms up for 100 requests and then 100 requests are measured. Note the tasks were grouped for sake of simplicity, since the test contains 16 search types * 2 different k values * 3 different n values.
- knn-10-50: searching on 2 million vectors without filters, k:10 and n:50
- knn-10-50-filtered: searching on 2 million vectors with filters, k:10 and n:50
- knn-10-50-after-force-merge: searching on 2 million vectors with filters and after a force merge, k:10 and n:50
- knn-10-100: searching on 2 million vectors without filters, k:10 and n:100
- knn-10-100-filtered: searching on 2 million vectors with filters, k:10 and n:100
- knn-10-100-after-force-merge: searching on 2 million vectors with filters and after a force merge, k:10 and n:100
- knn-100-1000: searching on 2 million vectors without filters, k:100 and n:1000
- knn-100-1000-filtered: searching on 2 million vectors with filters, k:100 and n:1000
- knn-100-1000-after-force-merge: searching on 2 million vectors with filters and after a force merge, k:100 and n:1000
- exact-knn: Exact KNN search with and without filters.

Elasticsearch is consistently faster than OpenSearch out-of-the-box on this test, only in two cases OpenSearch is faster, and not by much (knn-10-100 and knn-100-1000). Tasks involving knn-10-50, knn-10-100 and knn-100-1000 in combination with filters show a difference of up to 7x (112ms vs 803ms).
The performance of both solutions seems to even out after a "force merge", understandably, as evidenced by knn-10-50-after-force-merge, knn-10-100-after-force-merge and knn-100-1000-after-force-merge. On those tasks faiss is faster.
The performance for Exact KNN once again is very different, Elasticsearch being 13 times faster than OpenSearch this time (~385ms vs ~5262ms).
Recall
| knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0.986667 | 1 |
| OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
| OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 | 0.976394 |
Elasticsearch and Lucene as clear victors
At Elastic, we are relentlessly innovating Apache Lucene and Elasticsearch to ensure we are able to provide the premier vector database for search and retrieval use cases, including RAG (Retrieval Augmented Generation). Our recent advancements have dramatically increased performance, making vector search faster and more space efficient than before, building upon the gains from Lucene 9.10. This blog presented a study that shows when comparing up-to-date versions Elasticsearch is up to 12 times faster than OpenSearch.
It's worth noting both products use the same version of Lucene (Elasticsearch 8.14 Release Notes and OpenSearch 2.14 Release Notes).
The pace of innovation at Elastic will deliver even more not only for our on-premises and Elastic Cloud customers but those using our stateless platform. Features like support for scalar quantization to int4 will be offered with rigorous testing to ensure customers can utilize these techniques without a significant drop in recall, similar to our testing for int8.
Vector search efficiency is becoming a non-negotiable feature in modern search engines due to the proliferation of AI and machine learning applications. For organizations looking for a powerful search engine capable of keeping up with the demands of high-volume, high-complexity vector data, Elasticsearch is the definitive answer.
Whether expanding an established platform or initiating new projects, integrating Elasticsearch for vector search needs is a strategic move that will yield tangible, long-term benefits. With its proven performance advantage, Elasticsearch is poised to underpin the next wave of innovations in search.
Related Content

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

July 13, 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

July 21, 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

July 10, 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.