ベクトル検索からパワフルなREST APIまで、Elasticsearchは最も広範な検索ツールキットを開発者に提供します。Elasticsearch Labsリポジトリのサンプルノートで新しいことに挑戦してみましょう。また、無料トライアルを始めるか、ローカルでElasticsearchを実行することもできます。
まとめ:Elasticsearchは最大12倍高速 - Elasticでは、特にセマンティック検索/ベクトル検索のレルムにおけるElasticsearchとOpenSearch のパフォーマンスの違いを明確にしてほしいというリクエストをコミュニティから多数受けていました。そこで、このパフォーマンステストを実施して、明確でデータに基づく比較を提供しました。曖昧さはなく、ユーザーに伝えるための単純な事実です。結論としては、Elasticsearchはベクトル検索においてOpenSearchより最大12倍高速であるため、必要な計算リソースが少なくなります。これは、ElasticがLuceneを検索および取得ユースケースに最適なベクトルデータベースとして統合することに重点を置いていることを反映しています。
ベクトル検索は、特にAIや機械学習のフィールドで、類似性検索の方法に革命をもたらしています。ベクトル埋め込みモデルの採用が増えるにつれ、何百万もの高次元ベクトルを効率的に検索する機能が重要になっています。
ベクトルデータベースの実現方法に関して、ElasticとOpenSearchは著しく異なるアプローチを採用しています。Elasticは、Apache LuceneとElasticsearchがベクトル検索アプリケーションにおけるトップクラスの選択肢となるべく、これらの最適化に多額の投資を行ってきました。対照的に、OpenSearchは焦点を広げ、他のベクトル検索実装を統合し、Luceneの対象範囲を超えて模索を行っています。Elasticは戦略的にLuceneへと焦点を合わせており、弊社版Elasticsearchにおいて高度に統合されたサポートを提供できるため、各コンポーネントが他のコンポーネントの機能を補完および増幅できるという特徴が強化されています。
このブログでは、Elasticsearch 8.14とOpenSearch 2.14の詳細な比較を、異なる構成とベクトルエンジンを考慮して紹介します。このパフォーマンス分析では、Elasticsearch がベクトル検索操作に優れたプラットフォームであることが証明されました。今後追加予定の機能によりその差はさらに拡大するでしょう。OpenSearchと比較すると、すべてのベンチマークトラックで優れた結果を示し、平均で2倍から12倍高速なパフォーマンスを実現しました。これは、so_vector(2Mベクトル、768D)、openai_vector(2.5Mベクトル、1536D)、およびdense_vector(10Mベクトル、96D)を含む、さまざまなベクトル量と次元を使用したシナリオ全体で行われました。これらはすべて、Google Cloudで必要なインフラストラクチャーをプロビジョニングするためのTerraformスクリプトと、テストを実行するためのKubernetesマニフェストと共に、このリポジトリで利用可能です。
このブログで詳述されている結果は、以前に公開され、サードパーティによって検証された調査の結果を補完するものであり、最も一般的な検索分析操作(テキストクエリ、並べ替え、範囲、日付ヒストグラム、用語フィルタリング)では、ElasticsearchがOpenSearchよりも40%–140%高速であることが示されています。これに、別の差別化要因であるベクトル検索を追加します。
デフォルトの設定で最大12倍高速
4つのベクトルデータセットにわたる重点的なベンチマークには、さまざまなサイズ、次元、構成を考慮した近似KNN検索と正確なKNN検索の両方が含まれ、合計40.189.820のキャッシュされていない検索要求がありました。結果:Elasticsearchはベクトル検索においてOpenSearchより最大12倍高速であるため、必要な計算リソースが少なくなります。

図1:ElasticsearchおよびOpenSearchにおけるさまざまなタスクについて、ANNと厳密なKNNをグループ化した図。
knn-10-100のようなグループは、およびのKNN検索を意味します。HNSWベクトル検索では、はクエリベクトルから取得する最近傍の数を決定します。結果として検索する類似ベクトルの数を指定します。は各セグメントで取得する候補ベクトルの数を設定します。候補の数を増やすと精度は向上しますが、より多くの計算リソースが必要になります。
また、さまざまな量子化手法とエンジン固有の最適化を活用してテストしました。各トラック、タスク、ベクトルエンジンの詳細な結果を以下に示します。
厳密なKNNと近似KNN
さまざまなデータセットとユースケースを扱う場合、ベクトル検索に適したアプローチは異なります。このブログでは、knn-10-100のようにknn-*と記載されているすべてのタスクは近似KNNを使用し、script-score-*は正確なKNNを参照していますが、それらの違いは何で、なぜ重要なのでしょうか。
基本的に、より大規模なデータセットを扱う場合、優れた拡張性のある近似K-最近傍法(ANN)が推奨されます。フィルタリング処理が必要な場合のある、より小規模なデータセットの場合、厳密なKNN法が最適です。
正確なKNNでは、ブルートフォース法を使用して、データセット内の1つのベクトルと他のすべてのベクトルとの間の距離を計算します。次に、これらの距離を順位付けして、の最も近い近傍を見つけます。この方法では正確な一致が保証されますが、大規模で高次元のデータセットでは拡張性の課題があります。ただし、正確なKNNが必要なケースは数多くあります。
- 再スコアリング:語彙検索または意味検索の後にベクトルベースの再スコアリングを行うシナリオでは、正確なKNNが不可欠です。例えば、製品検索エンジンでは、テキストクエリ(キーワードやカテゴリなど)に基づいて最初の検索結果をフィルタリングし、フィルタリングされたアイテムに関連付けられたベクトルを使用して、より正確な類似性評価を行うことができます。
- パーソナライゼーション:多数のユーザーを扱う際、それぞれが比較的少数(100万個など)の個別のベクトルで表される場合、ユーザー固有のメタデータ(例:user_id)でインデックスをソートし、ベクトルを使用したブルートフォーススコアリングが効率的になります。このアプローチにより、個々のユーザーの好みに合わせた正確なベクトル比較に基づいて、パーソナライズされたレコメンデーションやコンテンツ配信が可能になります。
したがって、厳密なKNNでは、ベクトルの類似性に基づく最終的な順位付けと推奨が正確なものとなり、ユーザーの好みに合わせて調整されるようになります。
一方、近似KNN(またはANN)は、特に大規模で高次元のデータセットにおいて、厳密なKNNよりも高速かつ効率的にデータ検索を行う方法を採用しています。ANNは、クエリとすべての点の間の正確な最も近い距離を測定することにより計算やスケーリングの問題につながるブルートフォース的なアプローチではなく、特定の手法を使用してデータセットにおける検索可能なベクトルのインデックスと次元を効率的に再構築します。これにより若干の不正確さが生じる可能性がありますが、検索処理速度が大幅に向上するため、大規模なデータセットを処理するための効果的な代替手段となります。
このブログでは、knn-*として記載されているすべてのタスクはknn-10-100のように近似KNNを使用し、script-score-*は正確なKNNを参照します。
テスト手法
ElasticsearchとOpenSearchはBM25検索操作のAPIにおいては似ていますが、後者が前者のフォークであるため、フォーク後に導入されたベクトル検索には当てはまりません。OpenSearchはアルゴリズムに関してElasticsearchとは異なるアプローチを取り、luceneとは別にnmslibとfaissの2つのエンジンを導入しました。それぞれに特定の構成と制限があります(例:OpenSearchのnmslibでは、多くのユースケースで不可欠な機能であるフィルターが許可されていません)。
3つのエンジンはいずれも、階層型ナビゲート可能スモールワールド(HNSW)アルゴリズムを使用しています。このアルゴリズムは近似最近傍を検索するのに効率的で、特に高次元データを扱う際に強力です。faissは第2のアルゴリズムivfもサポートしていますが、データセットの事前トレーニングが必要なため、ここではHNSWのみに焦点を当てます。HNSWの中心的な考え方は、データを複数の接続されたグラフのレイヤーに整理し、各レイヤーがデータセットの異なる粒度を表すことです。検索は最も粗いビューの最上位レイヤーから始まり、ベースレベルに到達するまで、より細かいレイヤーへと進みます。
公平なテストの場を確保するために、両方の検索エンジンは制御された環境内で同一の条件下でテストされました。適用された方法は、Elasticsearch、OpenSearch、Rally専用のノードプールを使用した以前に公開されたパフォーマンス比較と似ています。terraformスクリプトは(すべてのソースとともに)Kubernetesクラスターを提供するために利用可能です。
- Elasticsearch用の3台の
e2-standard-32マシン(128GB RAM、32CPU)を持つ1つのNodeプール - OpenSearch用の3台の
e2-standard-32マシン(128GB RAM、32CPU)を持つ1つのNodeプール - Rally用の2台の
t2a-standard-16マシン(64GB RAM、16CPU)を持つ1つのNodeプール
各「トラック」(またはテスト)を、異なるエンジン、異なる設定、異なるベクトルタイプを含む各設定に対して10回実行しました。各トラックには、トラックにより1000回から10000回まで繰り返すタスクがあります。ネットワークのタイムアウトなどでトラック内のタスクの1つが失敗した場合はすべてのタスクを無視したため、すべての結果は問題なく開始して終了したトラックを表します。すべてのテスト結果は統計的に検証されており、改善が偶然ではないことが保証されています。
詳細な調査結果
平均レイテンシではなく99パーセンタイルを使用して比較するのはなぜでしょうか。特定の地域の平均住宅価格の例を想像してみましょう。平均価格によれば高価な地域となっていても、よく調べてみると、ほとんどの住宅の価値ははるかに低く、わずかな高級物件が平均値を膨らませていることがわかるかもしれません。これは、平均価格がその地域の住宅価値の全範囲を正確に表現できない可能性があることを示しています。同じようなことが、応答時間についても言えます。平均値が重要な問題を隠してしまうことがあるのです。
タスク
- 近似KNN(k:10 n:50)
- 近似KNN(k:10 n:100)
- 近似KNN(k:100 n:1000)
- 近似KNN(k:10 n:50、キーワードフィルター併用)
- 近似KNN(k:10 n:100、キーワードフィルター併用)
- 近似KNN(k:100 n:1000、キーワードフィルター併用)
- 近似KNN(k:10 n:100、インデックス作成と同時実行)
- 厳密なKNN(スクリプトスコア)
ベクトルエンジン
lucene(ElasticsearchとOpenSearchにおいて、両方ともバージョン9.10)faiss(OpenSearchにおいて)nmslib(OpenSearchにおいて)
ベクトルの種類
hnsw(ElasticsearchとOpenSearchにおいて)int8_hnswElasticsearch内(自動8ビット量子化を備えたHNSW:リンク)sq_fp16 hnswOpenSearch内(自動16ビット量子化を備えたHNSW:リンク)
すぐに使える同時セグメント検索
ご存知かと思いますが、LuceneはJavaで記述された高性能なテキスト検索エンジンライブラリであり、Elasticsearch、OpenSearch、Solrなどの多くの検索プラットフォームのバックボーンとして機能します。Luceneは本質的に、データをセグメントに整理します。セグメントは本質的には自己完結型のインデックスであり、Luceneがより効率的に検索を実行できるようにします。そのため、Luceneベースの検索エンジンに検索を発行すると、検索はそれらのセグメントで順次または並行して実行されます。
OpenSearchは同時セグメント検索をオプションのフラグとして導入しましたが、デフォルトでは使用されません。特別なインデックス設定index.search.concurrent_segment_search.enabledを使用して有効にする必要があります。詳細はこちらをご覧ください。ただし、いくつかの制限があります。
一方、Elasticsearchはすぐに使用できる状態でセグメントを同時に検索するため、このブログでの比較では、さまざまなベクトルエンジンとベクトルタイプに加えて、さまざまな構成も考慮に入れます。
- Elasticsearch ootb:同時セグメント検索検索を備えたデフォルト設定のElasticsearch
- OpenSearch ootb:同時セグメント検索が有効でない状態
- OpenSearch css:同時セグメント検索が有効な状態
それでは、テストした各ベクトルデータセットの詳細な結果を見てみましょう。
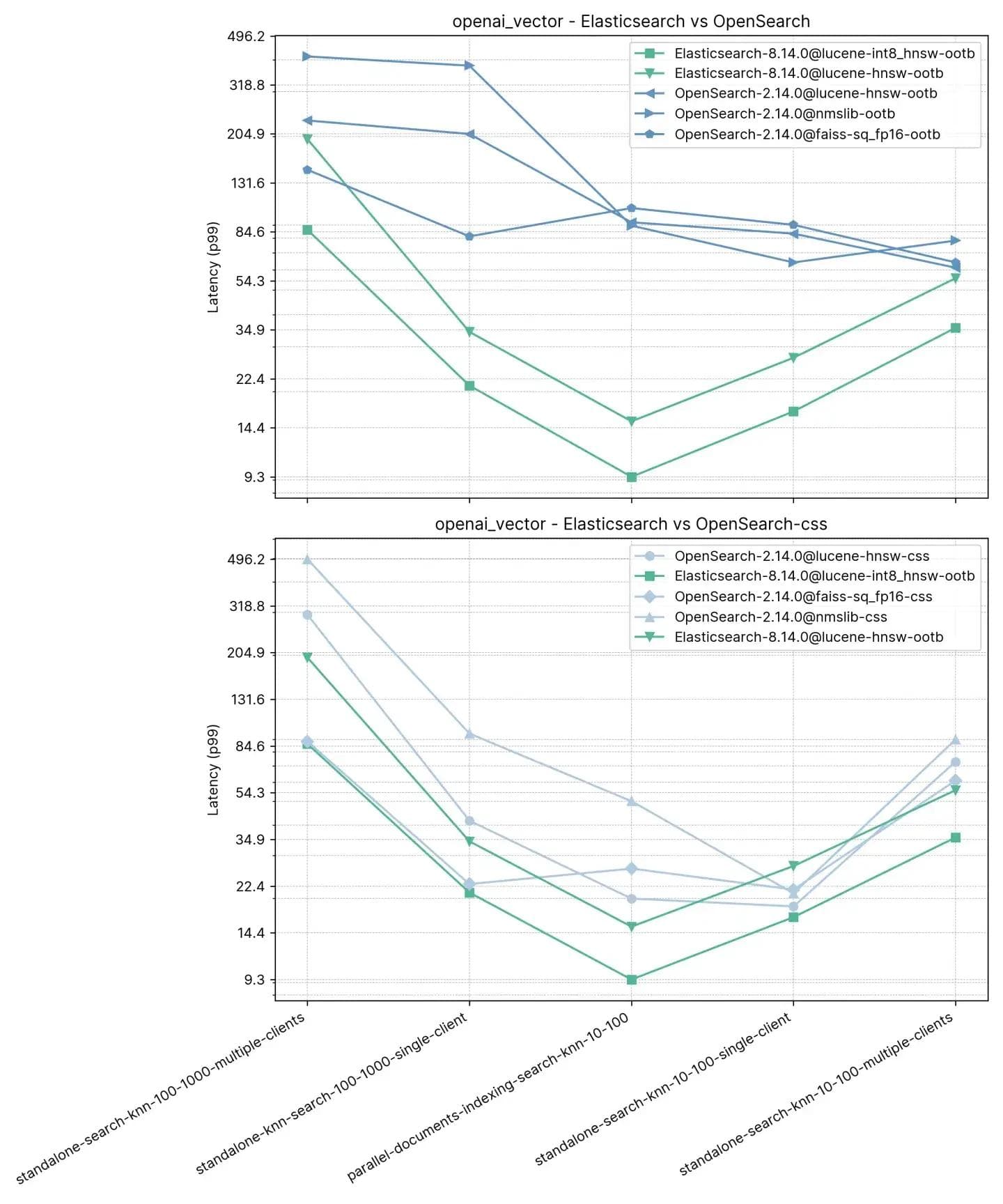
250万ベクトル、1536次元(openai_vector)
最も単純なトラックで、かつ次元の点でも最大のopenai_vectorから始めます。これは、OpenAIのtext-embedding-ada-002モデルを使用して生成された埋め込みで強化されたNQデータセットを使用します。これは、近似KNNのみをテストし、タスクが5つしかないため、最も単純です。スタンドアロン(インデキシングなし)でのテストと、インデキシングと並行してのテストが可能で、単一クライアントと8つの同時クライアントを使用します。
タスク
- standalone-search-knn-10-100-multiple-clients:8クライアントで250万ベクトルを同時に検索、k: 10およびn:100
- standalone-search-knn-100-1000-multiple-clients:8クライアントで250万ベクトルを同時に検索、k: 100およびn:1000
- standalone-search-knn-10-100-single-client:単一クライアントで250万ベクトルを検索、k: 10およびn:100
- standalone-search-knn-100-1000-single-client:単一クライアントで250万ベクトルを検索、k: 100およびn:1000
- parallel-documents-indexing-search-knn-10-100:250万ベクトルを検索しながら追加の10万ドキュメントをインデキシング、k:10およびn:100
p99の平均パフォーマンスの概要は次のとおりです。

ここで、 :10、:100でベクトル検索とインデックス作成(つまり読み取り+書き込み)を実行した場合、ElasticsearchはOpenSearchよりも3~8倍高速であり、kとnが同一のインデックス作成なしの場合には2~3倍高速であることがわかりました。:100 および:1000(standalone-search-knn-100-1000-single-clientおよびstandalone-search-knn-100-1000-multiple-clients)の場合、Elasticsearchは平均して OpenSearch より2倍から7倍高速です。
詳細な結果には、比較された具体的なケースとベクトルエンジンが示されています。
リコール
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0.969485 | 0.995138 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0.781445 | 0.784817 |
| OpenSearch-2.14.0@lucene-hnsw | 0.96519 | 0.995422 |
| OpenSearch-2.14.0@faiss | 0.984154 | 0.98049 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0.980012 | 0.97721 |
| OpenSearch-2.14.0@nmslib | 0.982532 | 0.99832 |
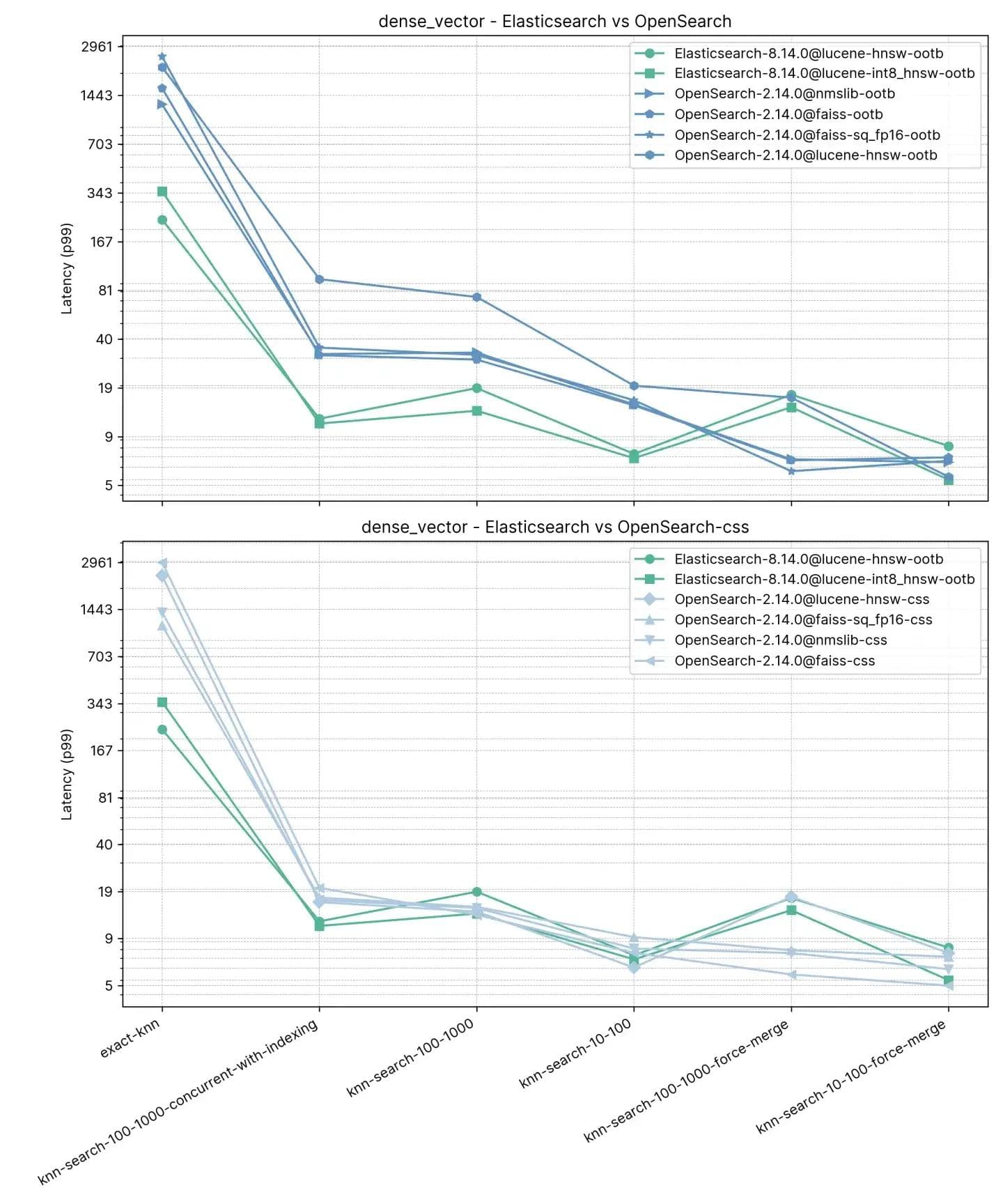
1,000万ベクトル、96次元(dense_vector)
dense_vectorには、1,000万ベクトルと96次元があります。これはYandex DEEP1B画像データセットに基づいています。データセットは、「sample data」ファイルlearn.350M.fbinの最初の1,000万ベクトルから作成されます。検索操作では、「query data」ファイルクエリのベクトルを使用します。public.10K.fbin。
ElasticsearchとOpenSearchの両方がこのデータセットで非常に優れたパフォーマンスを発揮します。特に、通常読み取り専用のインデックスで実行されるforce mergeの後では顕著です。これは、インデックスをデフラグして検索用の単一の「テーブル」を作成するのと似ています。
タスク
各タスクは100リクエストでウォームアップされ、その後1000リクエストが測定されます。
- knn-search-10-100: 1000万ベクトルを検索、k: 10およびn:100
- knn-search-100-1000:1000万ベクトルを検索、k: 100およびn:1000
- knn-search-10-100-force-merge:強制マージ後の1000万ベクトルの検索、k: 10およびn:100
- knn-search-100-1000-force-merge:強制マージ後の1000万ベクトルの検索、k: 100およびn:1000
- knn-search-100-1000-concurrent-with-indexing:1000万ベクトルを検索しながらデータセットの5%を更新、k: 100およびn:1000
- script-score-query:特定の2000ベクトルの正確なKNN検索。
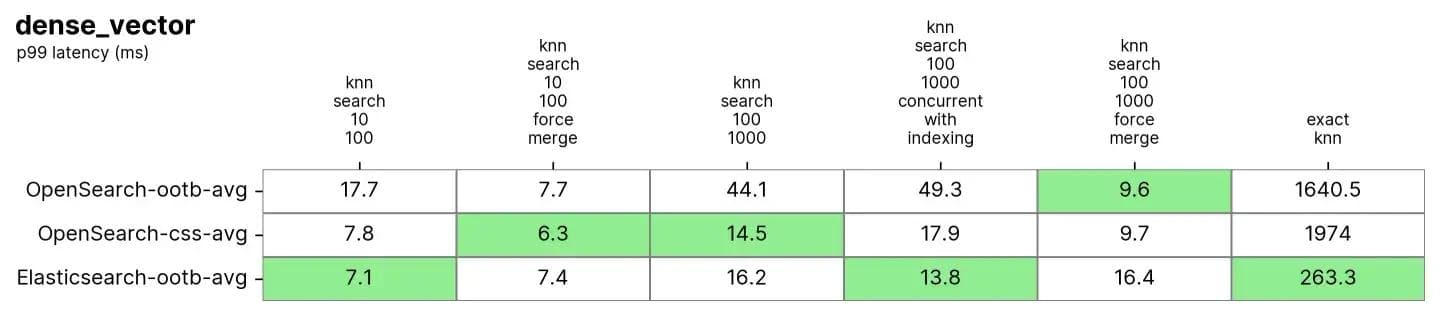
ElasticsearchとOpenSearchはどちらも近似KNNに対して良好なパフォーマンスを示しました。knn-search-100-1000-force-mergeおよびknn-search-10-100-force-mergeでインデックスが結合されている場合(つまり、セグメントが1つだけの場合)、nmslibおよびfaissを使用すると、いずれも約15ミリ秒で非常に近い値であるにもかかわらず、OpenSearchのパフォーマンスは他よりも優れています。
ただし、インデックスに複数のセグメントがある場合(インデックスがドキュメントの更新を受け取る典型的な状況)において、knn-search-10-100とknn-search-100-1000では、Elasticsearchは遅延を約7ミリ秒と16ミリ秒に保ちますが、他のすべてのOpenSearchエンジンはより遅くなります。
また、インデックスが検索され、同時に書き込まれる場合(knn-search-100-1000-concurrent-with-indexing)、Elasticsearchはレイテンシを15ミリ秒以下に保守し(13.8ミリ秒)、OpenSearchの出荷時(49.3ミリ秒)よりも4倍近く高速であり、同時セグメント検索が有効な場合でも(17.9ミリ秒)、依然として高速ですが、有意差があるほどではありません。
正確なKNNに関しては、その差はさらに大きくなります。Elasticsearch は OpenSearch よりも6 倍高速です(約 260 ミリ秒対約 1600 ミリ秒)。
リコール
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0.969843 | 0.996577 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0.775458 | 0.840254 |
| OpenSearch-2.14.0@lucene-hnsw | 0.971333 | 0.996747 |
| OpenSearch-2.14.0@faiss | 0.9704 | 0.914755 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0.968025 | 0.913862 |
| OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 |
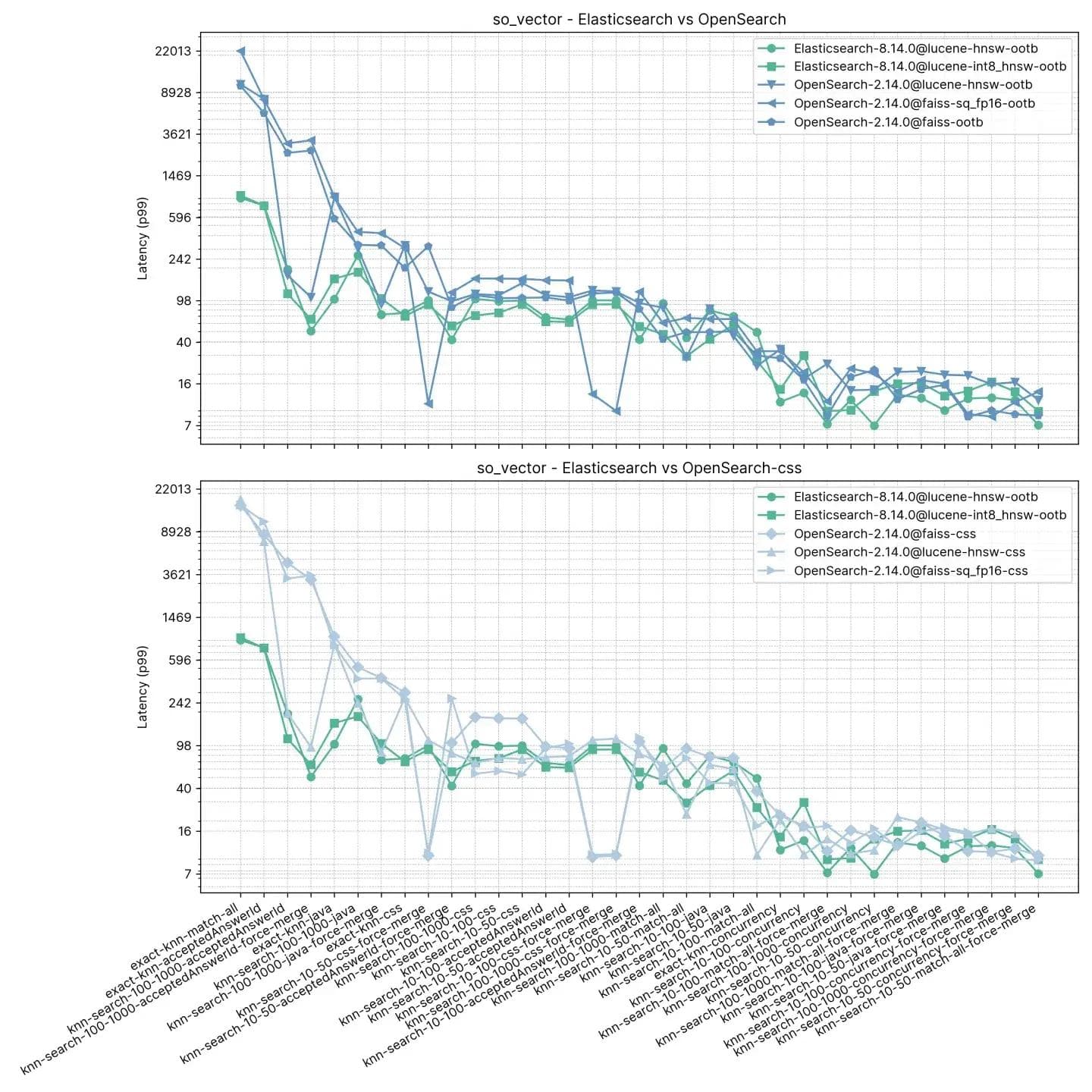
200万ベクトル、768次元(so_vector)
このトラック、so_vector、は2022年4月21日にダウンロードされたStackOverflowの投稿のダンプから派生しています。質問文書のみが含まれており、回答を表す文書はすべて削除されています。各質問タイトルは、文変換モデルmulti-qa-mpnet-base-cos-v1を使用してベクトルにエンコードされました。このデータセットには最初の200万件の質問が含まれています。
前のトラックとは異なり、ここでの各ドキュメントには、フィルタリングとハイブリッド検索を備えた近似KNNなどのテスト機能をサポートするためのベクトル以外のフィールドも含まれています。OpenSearchのnmslibはフィルターをサポートしていないため、このテストには含まれていません。
タスク
各タスクは100件のリクエストに対してウォームアップされ、その後100件のリクエストが測定されます。テストには16種類の検索タイプ*2つの異なるk値*3つの異なるn値が含まれているため、簡潔にするためにタスクがグループ化されていることに注意してください。
- knn-10-50:フィルターなしで200万ベクトルを検索、k:10およびn:50
- knn-10-50-filtered:200万ベクトルをフィルターを使用して検索、k:10およびn:50
- knn-10-50-after-force-merge:200万ベクトルを強制マージ後にフィルターを使用して検索、k:10およびn:50
- knn-10-100:フィルターなしで200万ベクトルを検索、k:10およびn:100
- knn-10-100-filtered:200万ベクトルをフィルターを使用して検索、k:10およびn:100
- knn-10-100-after-force-merge:200万ベクトルを強制マージ後にフィルターを使用して検索、k:10およびn:100
- knn-100-1000:フィルターなしで200万ベクトルを検索、k:100およびn:1000
- knn-100-1000-filtered:200万ベクトルをフィルターを使用して検索、k:100およびn:1000
- knn-100-1000-after-force-merge:200万ベクトルを強制マージ後にフィルターを使用して検索、k:100およびn:1000
- exact-knn:フィルターあり、フィルターなしの正確なKNN検索。

このテストでは、ElasticsearchはOpenSearchよりも一貫して高速であり、OpenSearchの方が高速なのは2つのケースのみで、その差はそれほど大きくありません(knn-10-100とknn-100-1000)。knn-10-50、knn-10-100、knn-100-1000をフィルターと組み合わせて使用するタスクでは、最大7倍(112ミリ秒対803ミリ秒)の差が見られます。
当然ながら、knn-10-50-after-force-merge、knn-10-100-after-force-merge、knn-100-1000-after-force-mergeで証明されているように、両方のソリューションのパフォーマンスは「強制マージ」後に均等になるようです。これらのタスクでは、 faissの方が高速です。
Exact KNNのパフォーマンスは今回も大きく異なり、ElasticsearchはOpenSearchより13倍高速です(約385ミリ秒対約5262ミリ秒)。
リコール
| knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0.986667 | 1 |
| OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
| OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 | 0.976394 |
ElasticsearchとLuceneが明確な勝者に
Elasticでは、Apache LuceneとElasticsearchを絶え間なく革新し、RAG(Retrieval-Augmented Generation)を含む検索および取得のユースケースに最適なベクトルデータベースを提供できるようにしています。最近の進歩により、パフォーマンスが大幅に改善され、ベクトル検索が以前よりも高速かつスペース効率的になりました。これはLucene 9.10からの成果を基に構築されています。このブログでは、最新バージョンを比較すると、ElasticsearchがOpenSearchよりも最大12倍高速であることを示す調査を紹介しました。
両方の製品が同じバージョンのLucene(Elasticsearch 8.14リリースノートおよびOpenSearch2.14 リリースノート)を使用していることは注目に値します。
Elasticのイノベーションのペースは、オンプレミスおよびElastic Cloudのお客様だけでなく、ステートレスプラットフォームを使用しているお客様にもさらに多くの成果をもたらします。int4へのスカラー量子化のサポートなどの機能は、int8のテストと同様に、顧客が再現率を大幅に低下させることなくこれらの手法を利用できるように、厳格なテストを経て提供されます。
AIおよび機械学習アプリケーションの急増により、ベクトル検索の効率は現代の検索エンジンでは交渉の余地のない機能になりつつあります。大量で複雑なベクトルデータの要求に対応できる強力な検索エンジンを探している組織にとって、Elasticsearchは決定的な答えです。
確立されたプラットフォームを拡張する場合でも、新しいプロジェクトを開始する場合でも、ベクトル検索のニーズに合わせてElasticsearchを統合することは、具体的かつ長期的なメリットをもたらす戦略的な動きです。実証済みのパフォーマンス上の優位性を備えたElasticsearchは、検索における次のイノベーションの波を支える態勢が整っています。
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。