はじめに
世界中のユーザーがいる世界では、言語間情報検索 (CLIR) が非常に重要です。CLIR を使用すると、検索を 1 つの言語に限定するのではなく、あらゆる言語で情報を検索できるため、ユーザー エクスペリエンスが向上し、操作が効率化されます。電子商取引の顧客が自分の言語で商品を検索でき、事前にデータをローカライズする必要なく、適切な結果が表示されるグローバル市場を想像してみてください。あるいは、情報源が別の言語であっても、学術研究者がニュアンスや複雑さを含めて母国語で論文を検索できる場所です。
多言語テキスト埋め込みモデルを使用すると、まさにそれが実現できます。埋め込みは、テキストの意味を数値ベクトルとして表現する方法です。これらのベクトルは、同様の意味を持つテキストが高次元空間内で互いに近く配置されるように設計されています。多言語テキスト埋め込みモデルは、特に、異なる言語間で同じ意味を持つ単語やフレーズを同様のベクトル空間にマッピングするように設計されています。
オープンソースの Multilingual E5 のようなモデルは、多くの場合、対照学習などの手法を使用して、大量のテキスト データでトレーニングされます。このアプローチでは、モデルは類似した意味を持つテキストのペア (肯定的なペア) と類似しない意味を持つテキストのペア (否定的なペア) を区別することを学習します。モデルは、正のペア間の類似性が最大化され、負のペア間の類似性が最小化されるように、生成するベクトルを調整するようにトレーニングされます。多言語モデルの場合、このトレーニング データには、相互に翻訳された異なる言語のテキスト ペアが含まれており、モデルが複数の言語の共有表現空間を学習できるようになります。結果として得られる埋め込みは、クエリの言語に関係なく、テキスト埋め込み間の類似性を使用して関連するドキュメントを検索するクロスリンガル検索を含むさまざまな NLP タスクに使用できます。
多言語ベクター検索のメリット
- ニュアンス: ベクター検索は、キーワードのマッチングを超えて、意味を捉えることに優れています。これは、文脈や言語の微妙なニュアンスを理解する必要があるタスクにとって非常に重要です。
- クロスリンガル理解: クエリとドキュメントが異なる語彙を使用している場合でも、言語間で効果的な情報検索を可能にします。
- 関連性: クエリとドキュメント間の概念的な類似性に焦点を当てることで、より関連性の高い結果を提供します。
たとえば、さまざまな国における「ソーシャル メディアが政治的議論に与える影響」を研究している学術研究者を考えてみましょう。ベクトル検索を使用すると、「l'impatto dei social media sul discorso politico」(イタリア語)または「ảnh hưởng của mạng xã hội đối với diễn ngôn chính trị」(ベトナム語)などのクエリを入力し、英語、スペイン語などで関連する論文を見つけることができます。他のインデックス付き言語。これは、ベクトル検索では、正確なキーワードを含む論文だけでなく、ソーシャル メディアの政治への影響の概念について議論している論文も特定されるためです。これにより、研究の幅と深さが大幅に向上します。
使い始める
Elasticsearch を使用して CLIR を設定する方法 (すぐに使用できる E5 モデルを使用) を次に示します。複数の言語の画像キャプションを含むオープンソースの多言語 COCO データセットを使用して、2 種類の検索を視覚化します。
- 1つの英語データセット上の他の言語のクエリと検索用語、および
- 複数の言語のドキュメントを含むデータセットに対する複数の言語でのクエリ。
次に、ハイブリッド検索と再ランキングの力を活用して、検索結果をさらに改善します。
要件
- Python 3.6以上
- Elasticsearch 8以上
- Elasticsearch Pythonクライアント: pip install elasticsearch
データセット
COCO データセットは、大規模なキャプション データセットです。データセット内の各画像には複数の異なる言語でキャプションが付けられており、言語ごとに複数の翻訳が利用可能です。デモンストレーションの目的で、各翻訳を個別のドキュメントとしてインデックス化し、参照用に最初の利用可能な英語の翻訳もインデックス化します。
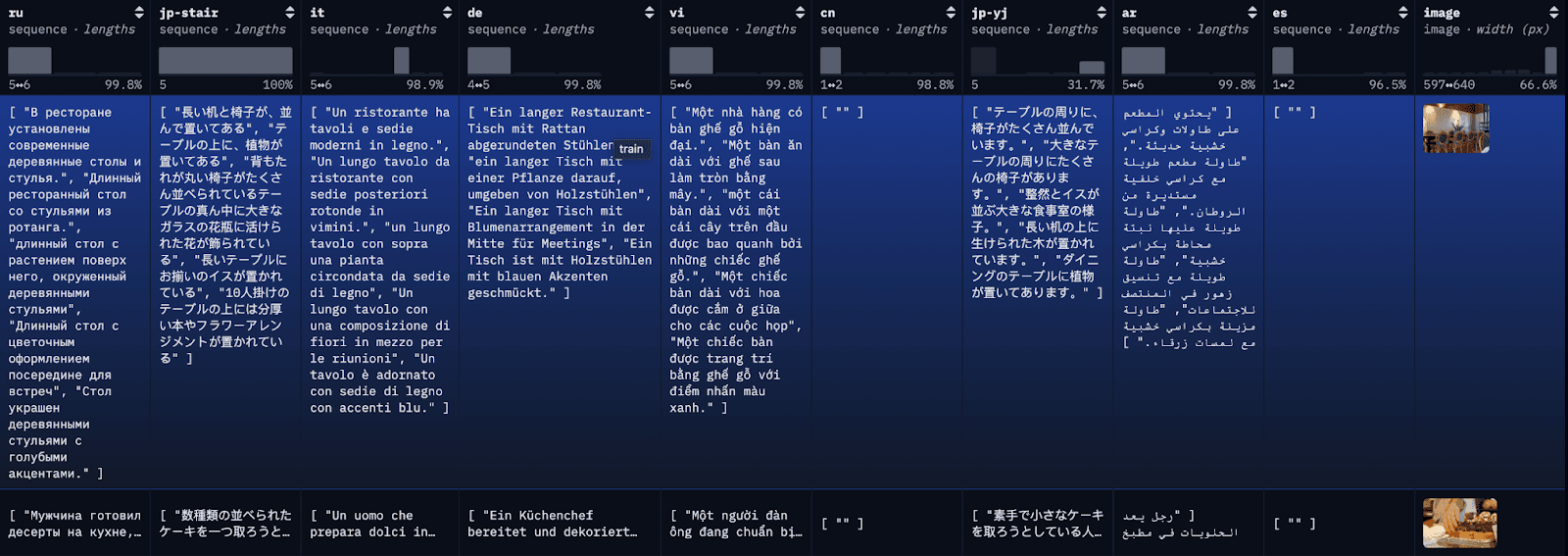
ステップ1: 多言語COCOデータセットをダウンロードする
ブログを簡素化し、理解しやすくするために、ここでは、単純な API 呼び出しを使用して、restval の最初の 100 行をローカル JSON ファイルに読み込みます。あるいは、HuggingFace のライブラリ データセットを使用して、完全なデータセットまたはデータセットのサブセットを読み込むこともできます。
データが JSON ファイルに正常に読み込まれると、次のようなものが表示されます。
Data successfully downloaded and saved to multilingual_coco_sample.json
ステップ2: (Elasticsearchを起動) Elasticsearchでデータをインデックスする
a) ローカル Elasticsearch サーバーを起動します。
b) Elasticsearch クライアントを起動します。
c) インデックスデータ
データがインデックスされると、次のようなものが表示されます。
Successfully bulk indexed 4840 documents
Indexing complete!
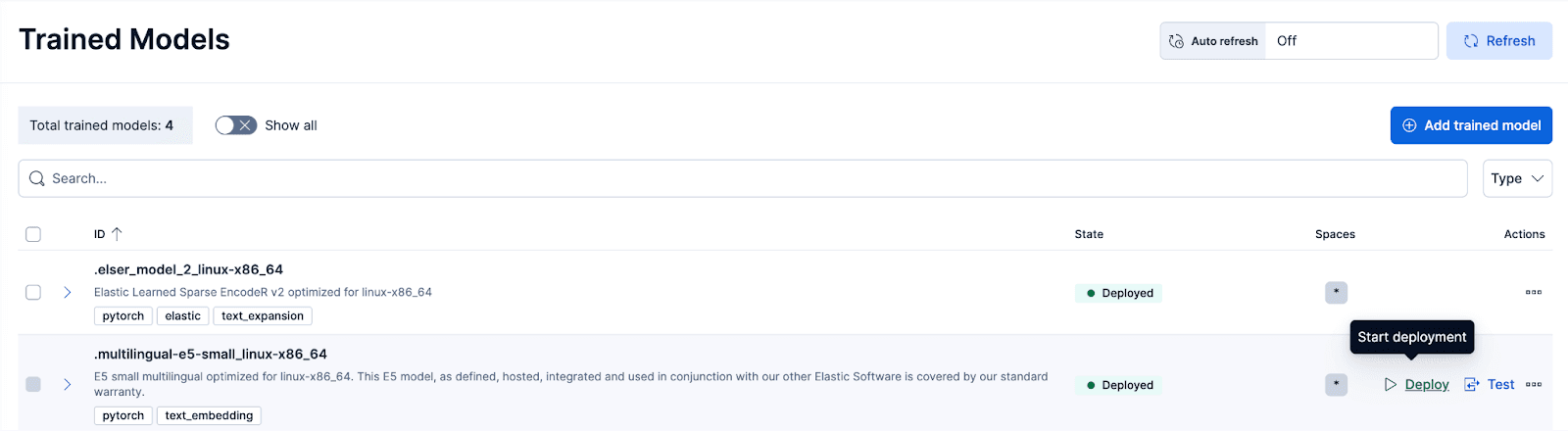
ステップ3: E5トレーニング済みモデルをデプロイする
Kibanaで、スタック管理 >トレーニング済みモデルページに移動し、.multilingual-e5-small_linux-x86_64のデプロイをクリックします。オプション。この E5 モデルは、linux-x86_64 向けに最適化された小型の多言語モデルで、そのまま使用できます。「デプロイ」をクリックすると、デプロイ設定または vCPU 構成を調整できる画面が表示されます。簡単にするために、デフォルト オプションを使用し、適応型リソースを選択します。これにより、使用状況に応じてデプロイメントが自動的にスケーリングされます。
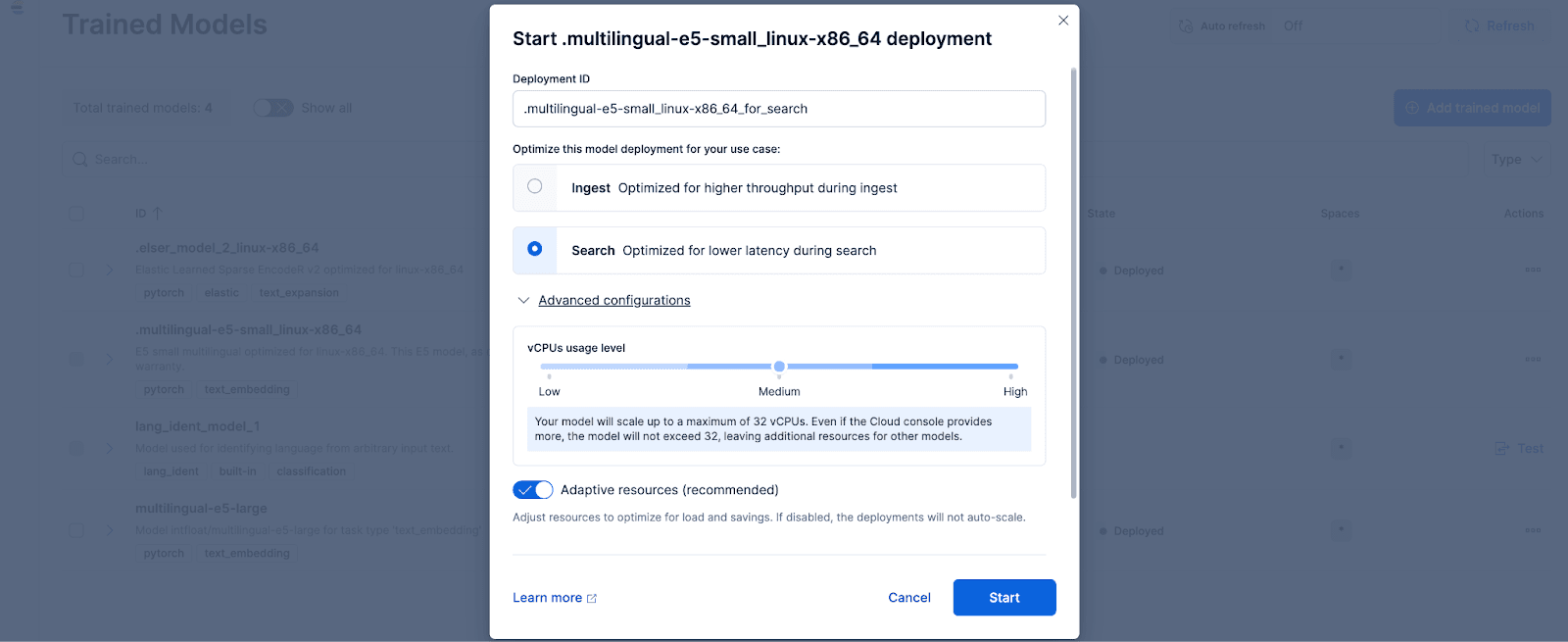
オプションとして、他のテキスト埋め込みモデルを使用することもできます。たとえば、BGE-M3 を使用するには、 Elastic の Eland Python クライアントを使用して HuggingFace からモデルをインポートできます。
次に、「トレーニング済みモデル」ページに移動し、インポートしたモデルを必要な構成でデプロイします。
ステップ4: デプロイされたモデルを使用して元のデータをベクトル化または埋め込みを作成する
埋め込みを作成するには、まずテキストを取得して推論テキスト埋め込みモデルに通すことができる取り込みパイプラインを作成する必要があります。これは、Kibana のユーザー インターフェースまたは Elasticsearch の API を通じて実行できます。
Kibana インターフェース経由でこれを行うには、トレーニング済みモデルをデプロイした後、 [テスト]ボタンをクリックします。これにより、生成された埋め込みをテストおよびプレビューできるようになります。cocoの新しいデータビューを作成します インデックスを作成し、データ ビューを新しく作成した coco データ ビューに設定し、フィールドをdescriptionに設定します。これは、埋め込みを生成するフィールドだからです。
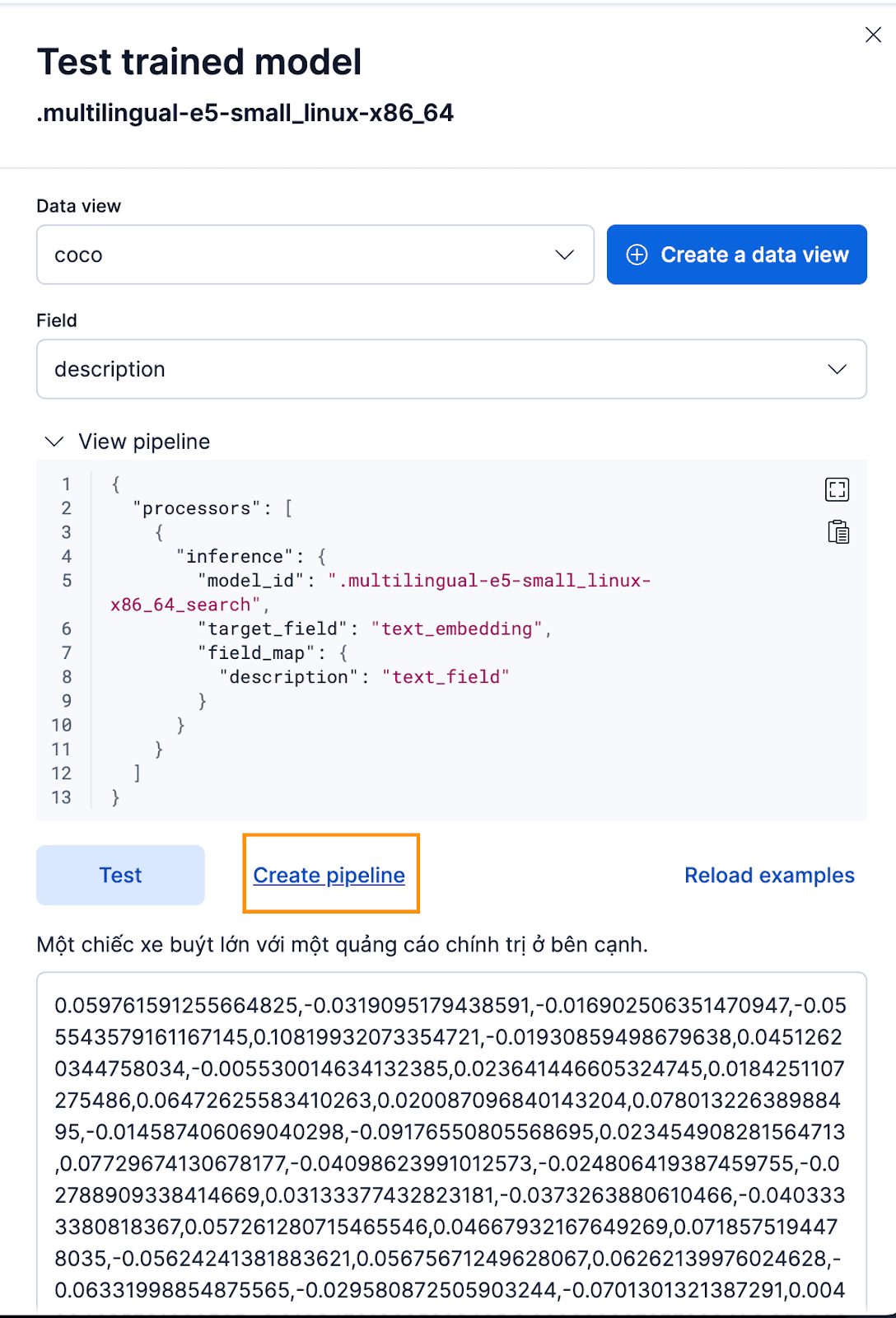
それは素晴らしいですね!これで、取り込みパイプラインの作成に進み、元のドキュメントのインデックスを再作成し、パイプラインに渡して、埋め込みを含む新しいインデックスを作成できます。これを実現するには、 「パイプラインの作成」をクリックします。これにより、埋め込みの作成に必要なプロセッサが自動的に入力され、パイプラインの作成プロセスがガイドされます。
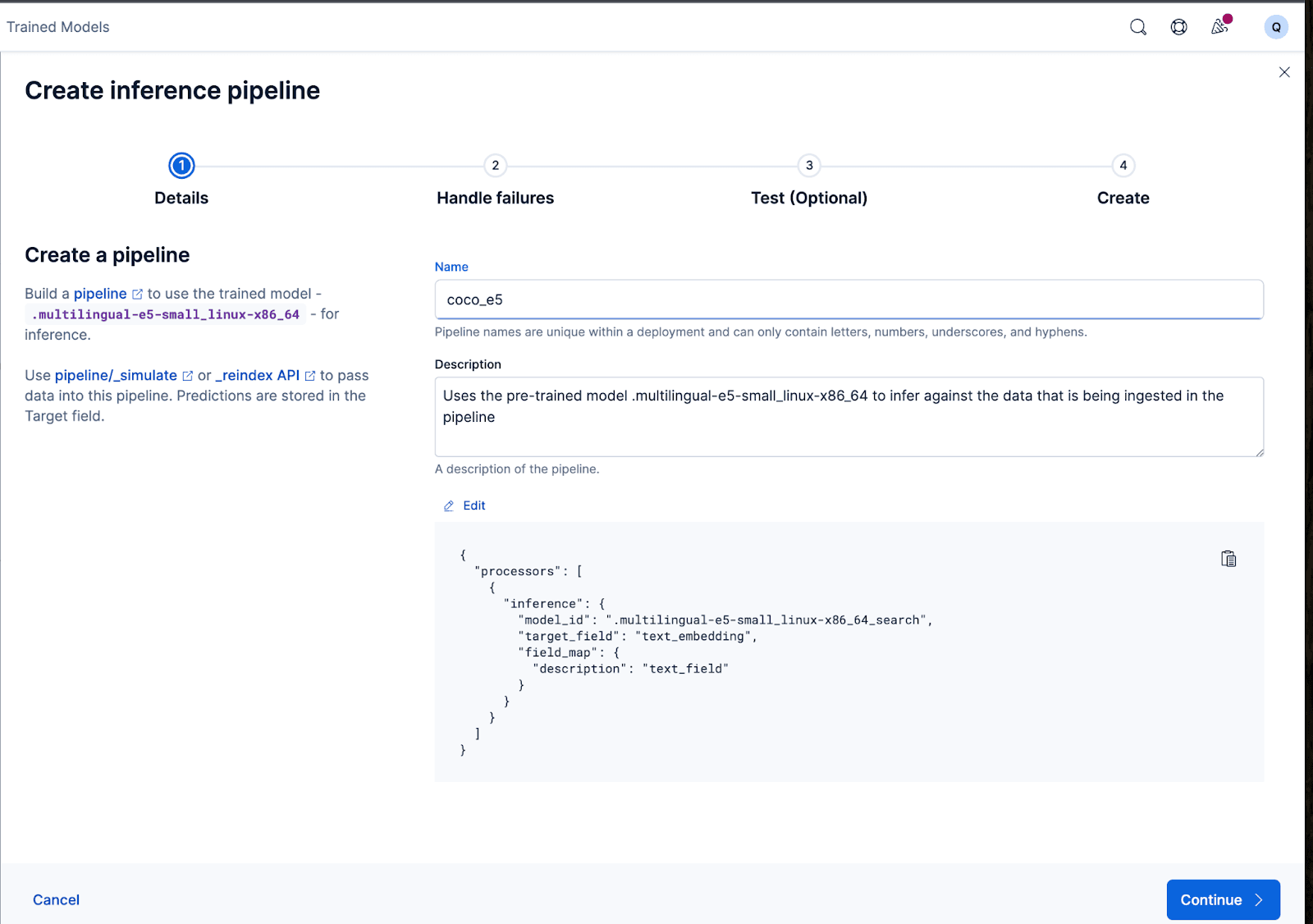
ウィザードでは、データの取り込みと処理中に障害を処理するために必要なプロセッサを自動的に入力することもできます。
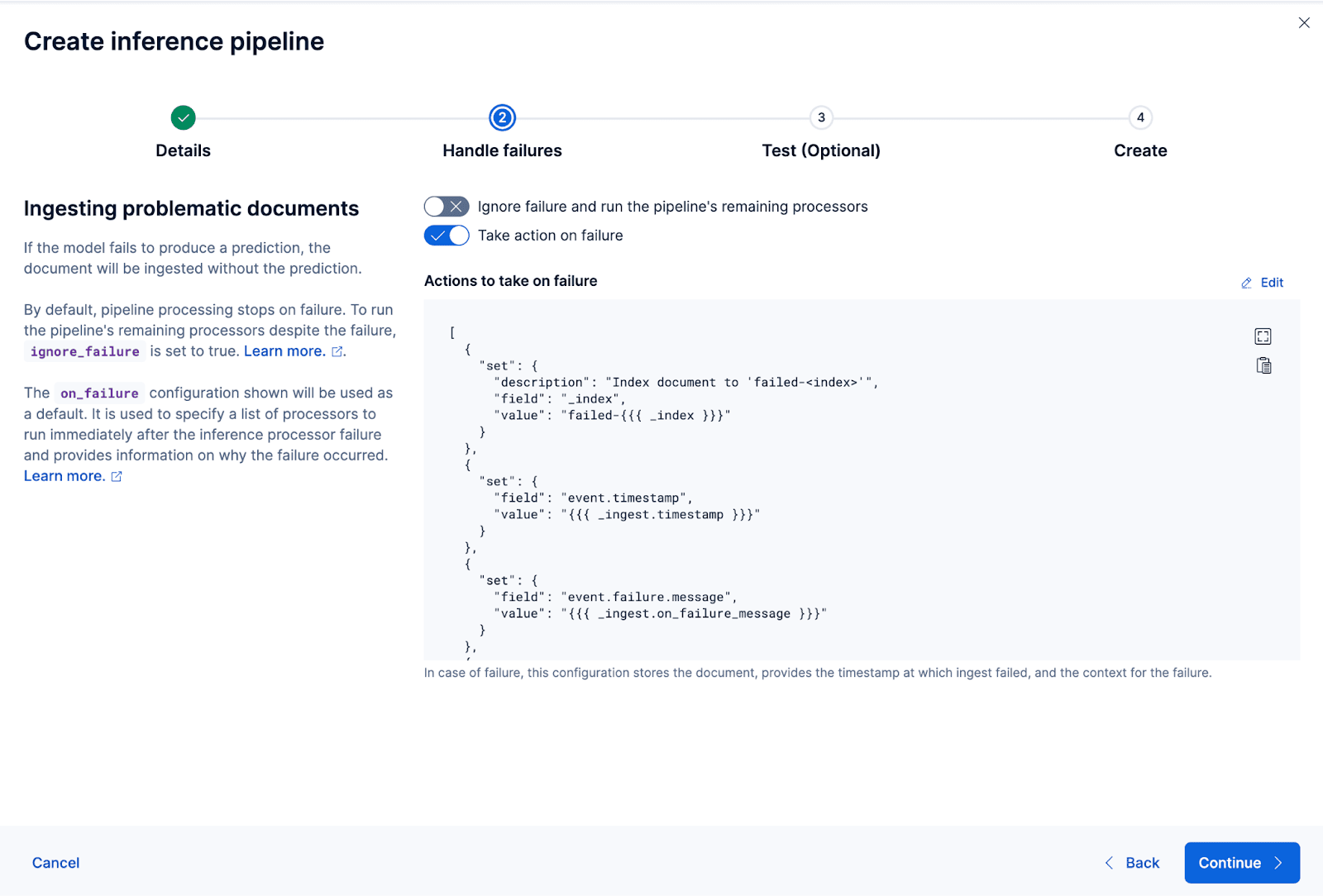
それでは、取り込みパイプラインを作成しましょう。パイプラインにcoco_e5という名前を付けます。パイプラインが正常に作成されたら、ウィザードで元のインデックス付きデータを新しいインデックスに再インデックスすることで、パイプラインをすぐに使用して埋め込みを生成できます。プロセスを開始するには、 「再インデックス」をクリックします。
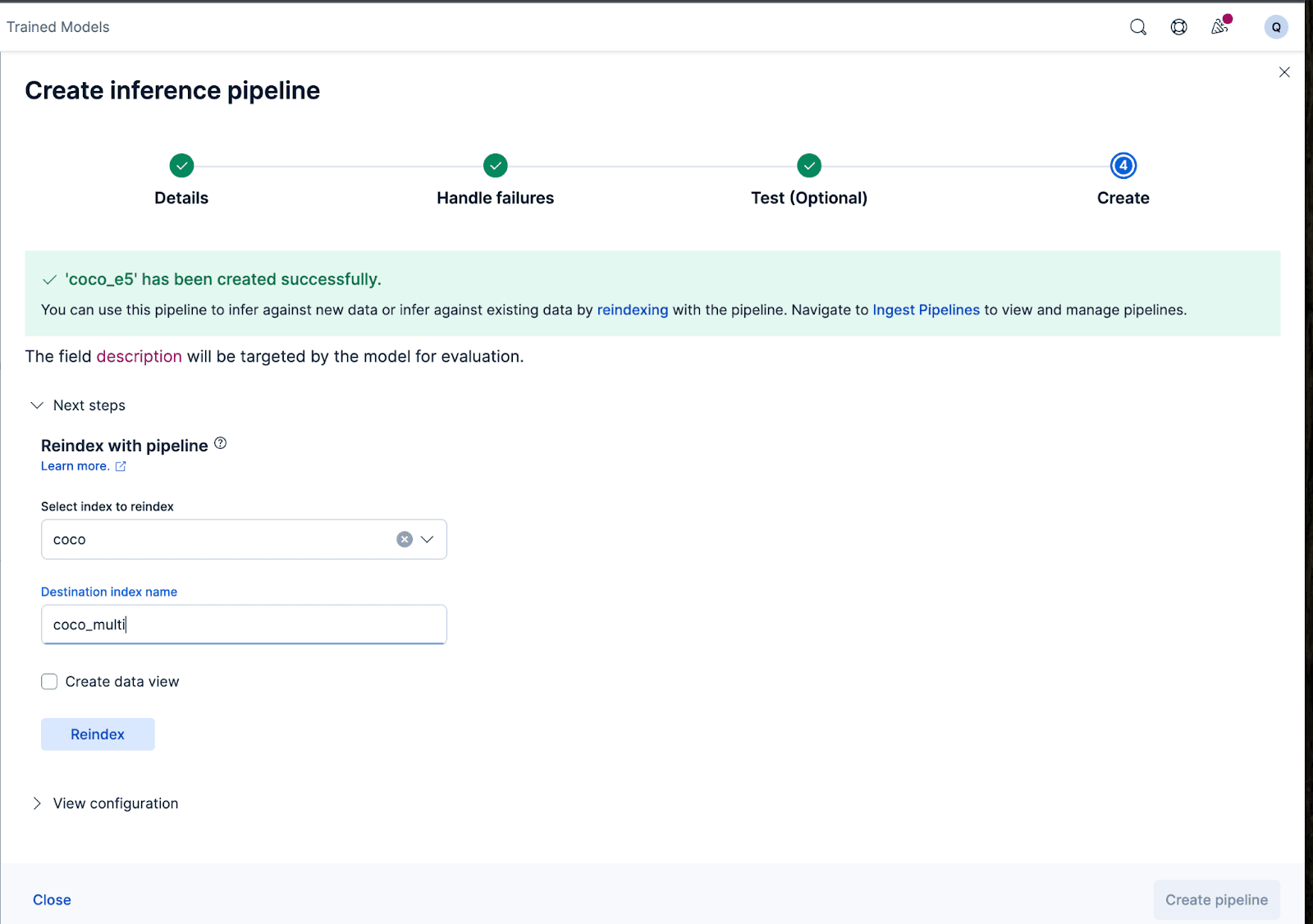
より複雑な構成の場合は、Elasticsearch API を使用できます。
一部のモデルでは、モデルのトレーニング方法により、埋め込みを生成する前に実際の入力の先頭または末尾に特定のテキストを追加する必要がある場合があります。そうしないと、パフォーマンスが低下します。
たとえば、e5 の場合、モデルは入力テキストが「passage: {content of passage} 」に続くことを想定します。これを実現するために、取り込みパイプラインを活用しましょう。新しい取り込みパイプラインvectorize_descriptions を作成します。このパイプラインでは、新しい一時的なtemp_descフィールドを作成し、 descriptionテキストの先頭に「passage:」を追加し、モデルでtemp_descを実行してテキスト埋め込みを生成し、 temp_descを削除します。
さらに、生成されたベクトルに使用する量子化の種類を指定することもできます。デフォルトでは、Elasticsearch はint8_hnswを使用しますが、ここでは各次元を 1 ビットの精度に削減するBetter Binary Quantization (またはbqq_hnsw ) を使用します。これにより、精度は犠牲になりますが、メモリ フットプリントが 96% (または 32 倍) 削減されます。後で再ランク付けを使用して精度の低下を改善することが分かっているため、この量子化タイプを選択しています。
そのためには、 coco_multiという名前の新しいインデックスを作成し、マッピングを指定します。ここでの魔法は vector_description フィールドにあり、そこでindex_optionsのタイプをbbq_hnswに指定します。
これで、説明フィールドを「ベクトル化」または埋め込みを作成する取り込みパイプラインを使用して、元のドキュメントを新しいインデックスに再インデックスできます。
以上です!Elasticsearch と Kibana を使用して多言語モデルを正常にデプロイし、Kibana ユーザー インターフェースまたは Elasticsearch API を使用して Elastic でデータにベクトル埋め込みを作成する方法を段階的に学習しました。このシリーズの第 2 部では、多言語モデルを使用した場合の結果とニュアンスについて説明します。その間、独自のクラウド クラスターを作成し、選択した言語とデータセットですぐに使用できる E5 モデルを使用して多言語セマンティック検索を試すことができます。
関連記事

2026年5月18日
Elasticsearchにおける決定論的なガードレールを備えたエージェント型AI検索による安全なクエリ実行
LLMがクエリを直接生成すると、エージェント型AI検索システムが失敗することがよくあります。決定論的なガードレールと制御プレーンアーキテクチャーが、Elasticsearchでどのように安全で信頼性が高く、統制されたクエリ実行を実現するかを学びましょう。

2026年5月11日
eコマース検索のパーソナライズ:購入履歴とユーザーコホートの統合
ガバナンスを損なうことなく、Elasticsearchでパーソナライズされたeコマース検索エクスペリエンスを作成する方法を学びましょう。この記事では、顧客が過去に購入した商品をブーストする方法と、ユーザープロファイルに基づいて顧客レイヤー固有のポリシーを有効にする方法について説明します。

2026年5月4日
eコマース検索ガバナンスのためのElasticsearchパーコレーター:曖昧なクエリをガバナンスを備えた検索戦略に変換
Elasticsearchパーコレーターを使用して検索ガバナンスを実装する方法を学びましょう。このブログでは、本番環境で統制されたポリシーエンジンを構築し、制御されたデータ取得戦略を作成するために必要なパターンについて概説します。


2026年4月24日
マッピングの競合を解決するデータストリームの再インデックス
データストリームの再インデックスでElasticsearchマッピングの競合を修正する方法を学びます。このブログでは、インデックス再構築のプロセスと、新しいデータが正しくマッピングされるようにする方法について説明します。