Elastic Open Web Crawlerとその CLI 駆動型アーキテクチャを使用すると、バージョン管理されたクローラー構成とローカル テストを備えた CI/CD パイプラインを実現するのが非常に簡単になります。
従来、クローラーの管理は手動で行われ、エラーが発生しやすいプロセスでした。これには、UI で直接構成を編集することや、クロール構成の複製、ロールバック、バージョン管理などに苦労することが含まれていました。クローラー構成をコードとして扱うことで、ソフトウェア開発で期待されるのと同じ利点(再現性、追跡可能性、自動化)が得られ、この問題が解決されます。
このワークフローにより、ロールバック、バックアップ、移行などのタスクを CI/CD パイプラインに Open Web Crawler を簡単に組み込むことができるようになります。これらのタスクは、Elastic Web Crawler や App Search Crawler などの以前の Elastic Crawler では非常に困難でした。
この記事では、次の方法を学習します。
- GitHubを使用してクロール設定を管理する
- デプロイ前にパイプラインをテストするためのローカルセットアップを用意する
- メインブランチに変更をプッシュするたびに、新しい設定でウェブクローラーを実行するための本番環境設定を作成します。
プロジェクトのリポジトリはこちらです。執筆時点では、Elasticsearch 9.1.3とOpen Web Crawler 0.4.2を使用しています。
要件
- Dockerデスクトップ
- Elasticsearchインスタンス
- SSH アクセス(AWS EC2 など)と Docker がインストールされた仮想マシン
ステップ
- フォルダ構造
- クローラー構成
- Docker-compose ファイル (ローカル環境)
- Githubアクション
- ローカルテスト
- 本番環境へのデプロイ
- 変更と再展開
フォルダ構造
このプロジェクトでは、次のファイル構造になります。
クローラー構成
crawler-config.yml,の下に次の内容を入力します。
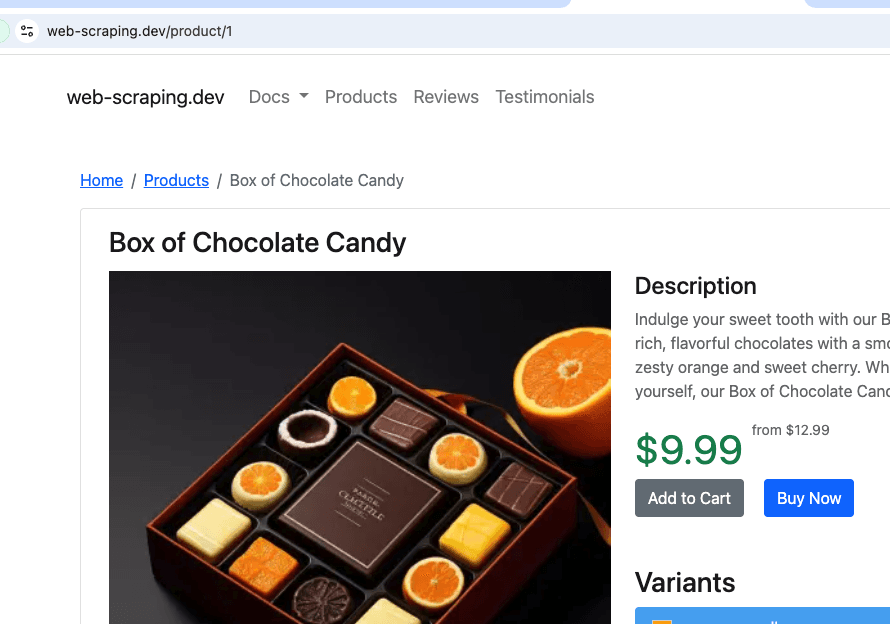
これは、製品の模擬サイトであるhttps://web-scraping.dev/productsからクロールします。最初の 3 つの製品ページのみをクロールします。max_crawl_depth設定により、クローラーはseed_urlsとして定義されたページよりも多くのページを検出することがなくなり、それらのページ内のリンクを開かなくなります。
Elasticsearch hostとapi_keyは、スクリプトを実行している環境に応じて動的に設定されます。
Docker-compose ファイル (ローカル環境)
ローカルdocker-compose.yml,には、クローラーと単一の Elasticsearch クラスター + Kibana をデプロイして、本番環境にデプロイする前にクロール結果を簡単に視覚化できるようにします。
Elasticsearch の実行準備ができるまでクローラーが待機する方法に注意してください。
Githubアクション
ここで、新しい設定をコピーし、メインにプッシュするたびに仮想マシンでクローラーを実行する GitHub アクションを作成する必要があります。これにより、手動で仮想マシンにアクセスしてファイルを更新し、クローラーを実行する必要がなくなり、常に最新の構成が展開されます。仮想マシンプロバイダーとして AWS EC2 を使用します。
最初のステップは、ホスト ( VM_HOST )、マシン ユーザー ( VM_USER )、SSH RSA キー ( VM_KEY )、Elasticsearch ホスト ( ES_HOST )、Elasticsearch API キー ( ES_API_KEY ) を GitHub Action シークレットに追加することです。
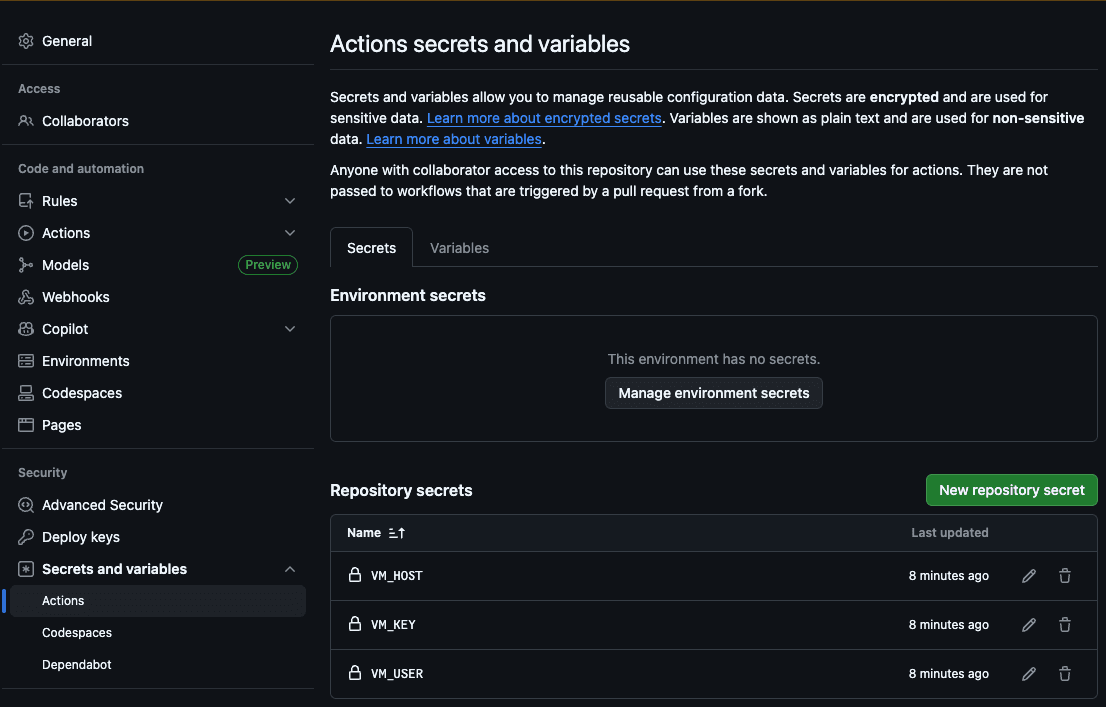
この方法により、アクションはサーバーにアクセスして新しいファイルをコピーし、クロールを実行できるようになります。
それでは、 .github/workflows/deploy.ymlファイルを作成しましょう。
このアクションは、クローラー構成ファイルに変更をプッシュするたびに、次の手順を実行します。
- yml config に Elasticsearch ホストと API キーを入力します。
- configフォルダをVMにコピーします
- SSH経由でVMに接続します
- リポジトリからコピーした設定でクロールを実行します
ローカルテスト
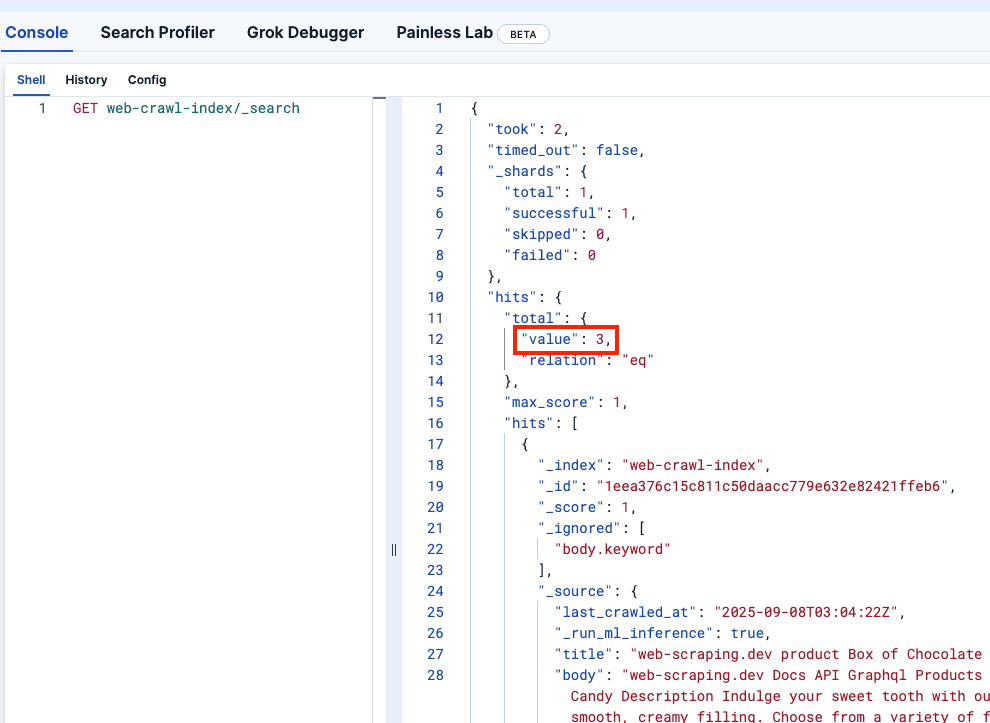
クローラーをローカルでテストするために、Docker からローカルのものを Elasticsearch ホストに入力してクロールを開始する bash スクリプトを作成しました。./local.shを実行して実行できます。
Kibana DevTools を見て、 web-crawler-indexが正しく入力されていることを確認しましょう。
本番環境へのデプロイ
これで、メイン ブランチにプッシュする準備が整いました。これにより、仮想マシンにクローラーがデプロイされ、Serverless Elasticsearch インスタンスにログの送信が開始されます。
これにより、GitHub アクションがトリガーされ、仮想マシン内でデプロイ スクリプトが実行され、クロールが開始されます。
アクションが実行されたかどうかを確認するには、GitHub リポジトリにアクセスして「アクション」タブにアクセスします。

変更と再展開
お気づきかもしれませんが、各製品のpriceはドキュメントの本文フィールドの一部です。価格を別のフィールドに保存して、それに対してフィルターを実行できるようにするのが理想的です。
抽出ルールを使用してproduct-price CSS クラスから価格を抽出するために、 crawler.ymlファイルに次の変更を追加してみましょう。
また、価格にはドル記号 ( $ ) が含まれていますが、範囲クエリを実行する場合はこれを削除する必要があります。そのために、取り込みパイプラインを使用できます。上記の新しいクローラー構成ファイルでこれを参照していることに注意してください。
このコマンドは本番環境の Elasticsearch クラスターで実行できます。開発用の場合は一時的なものなので、次のサービスを追加することで、パイプライン作成部分をdocker-compose.ymlファイルにすることができます。パイプラインが正常に作成された後にクローラー サービスが起動するように、 depends_onもクローラー サービスに追加されていることに注意してください。
次に、 `./local.sh`を実行してローカルで変更を確認してみましょう。

素晴らしい!変更をプッシュしてみましょう。
すべてが機能していることを確認するには、本番環境の Kibana をチェックします。変更が反映され、価格がドル記号なしの新しいフィールドとして表示されるはずです。
まとめ
Elastic Open Web Crawler を使用すると、クローラーをコードとして管理できるため、開発からデプロイメントまでのパイプライン全体を自動化したり、一時的なローカル環境を追加したり、クロールされたデータに対してプログラムでテストを実行したりすることができます。
公式リポジトリのクローンを作成し、このワークフローを使用して独自のデータのインデックス作成を開始してください。クローラーによって生成されたインデックスに対してセマンティック検索を実行する方法については、この記事を読むこともできます。
関連記事

2026年5月18日
Elasticsearchにおける決定論的なガードレールを備えたエージェント型AI検索による安全なクエリ実行
LLMがクエリを直接生成すると、エージェント型AI検索システムが失敗することがよくあります。決定論的なガードレールと制御プレーンアーキテクチャーが、Elasticsearchでどのように安全で信頼性が高く、統制されたクエリ実行を実現するかを学びましょう。

2026年5月11日
eコマース検索のパーソナライズ:購入履歴とユーザーコホートの統合
ガバナンスを損なうことなく、Elasticsearchでパーソナライズされたeコマース検索エクスペリエンスを作成する方法を学びましょう。この記事では、顧客が過去に購入した商品をブーストする方法と、ユーザープロファイルに基づいて顧客レイヤー固有のポリシーを有効にする方法について説明します。

2026年5月4日
eコマース検索ガバナンスのためのElasticsearchパーコレーター:曖昧なクエリをガバナンスを備えた検索戦略に変換
Elasticsearchパーコレーターを使用して検索ガバナンスを実装する方法を学びましょう。このブログでは、本番環境で統制されたポリシーエンジンを構築し、制御されたデータ取得戦略を作成するために必要なパターンについて概説します。


2026年4月24日
マッピングの競合を解決するデータストリームの再インデックス
データストリームの再インデックスでElasticsearchマッピングの競合を修正する方法を学びます。このブログでは、インデックス再構築のプロセスと、新しいデータが正しくマッピングされるようにする方法について説明します。