今年の初め、ElasticはNVIDIAとの協業を発表し、ElasticsearchにGPUアクセラレーションをもたらすためにNVIDIA cuVSと統合しました。これはNVIDIA GTCのセッションやさまざまなブログで詳しく説明されています。この投稿は、NVIDIAのベクトル検索チームとの共同エンジニアリング作業の最新情報です。
要約
まず、現状をお伝えしましょう。Elasticsearchは、強力なベクトルデータベースとして確立され、大規模な類似性検索に対して豊富な特徴と強力なパフォーマンスを提供しています。スカラー量子化、Better Binary Quantization(BBQ)、SIMDベクトル演算、DiskBBQのようなよりディスク効率の高いアルゴリズムなどの機能により、すでにベクトルワークロードの管理に効率的かつ柔軟な選択肢を提供しています。
NVIDIA cuVSをベクトル検索タスク用の呼び出し可能なモジュールとして統合することで、ベクトルインデキシングのパフォーマンスと効率を大幅に向上させ、大規模なベクトルワークロードをより良くサポートすることを目指しています。
課題
高性能ベクトルデータベースを構築する上で最も困難な課題の一つは、ベクトルインデックス(HNSWグラフ)を構築することです。インデックス構築は、すべてのベクトルが他の多数のベクトルと比較されるため、すぐに数百万、あるいは数十億の算術演算によって支配されるようになります。さらに、インデックスのライフサイクル操作、例えば圧縮やマージなどは、インデキシングの全体的な計算オーバーヘッドをさらに増加させる可能性があります。データ量と関連するベクトル埋め込みが指数関数的に増加するにつれ、大規模な並列処理と高スループットの数学演算用に構築された高速コンピューティングGPUは、これらのワークロードを処理するのに理想的な位置にあります。
Elasticsearch-GPUプラグインの登場
NVIDIA cuVSは、GPUによるベクトル検索とデータクラスタリングのためのオープンソースCUDA-Xライブラリであり、AIおよび推奨ワークロード向けの高速インデックス構築と埋め込み検索を可能にします。
ElasticsearchはcuVSをcuvs-javaを通じて使用しています。cuvs-javaはコミュニティが開発し、NVIDIAが保守するオープンソースライブラリです。cuvs-javaライブラリは軽量で、cuVS C APIをベースにPanama Foreign Functionを使用して、cuVSの特徴をJavaらしい方法で公開しつつ、モダンな高性能を維持しています。
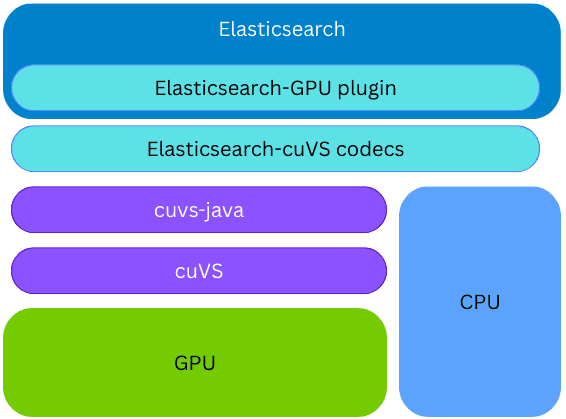
cuvs-javaライブラリは新しいElasticsearchプラグインに統合されています。そのため、GPU上でのインデキシングを同じElasticsearchノードとプロセスで実行でき、外部のコードやハードウェアを提供する必要はありません。CUVsライブラリがインストールされていて、GPUが存在して構成されている場合、インデキシング中にElasticsearchはGPUを使用してベクターインデキシング処理を高速化します。ベクトルはGPUに提供され、GPUはCAGRAグラフを構築します。その後、このグラフはHNSW形式に変換され、CPU上でのベクトル検索にすぐに利用可能になります。構築されたグラフの最終的な形式は、CPU上に構築されるものと同じです。これによりElasticsearchは、基盤となるハードウェアがサポートしている場合、GPUを活用して高スループットのベクトルインデックスを作成し、CPUのパワーを他のタスク(同時検索やデータ処理など)に解放することができます。
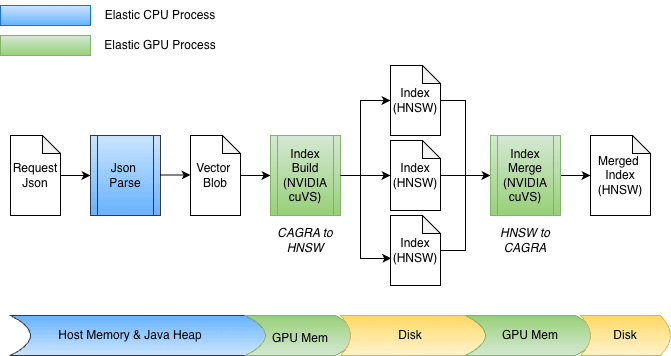
インデックス構築の加速
ElasticsearchにGPUアクセラレーションを統合する一環として、cuvs-javaにいくつかの機能強化が行われ、効率的なデータのインプット/出力と関数呼び出しに焦点が当てられました。主要な機能強化は、cuVSMatrixを使用して、Javaヒープ、オフヒープ、またはGPUメモリに存在するベクトルを透過的にモデル化することです。これにより、データをメモリとGPU間で効率的に移動でき、潜在的に数十億のベクトルの不要なコピーを回避できます。
この基礎となるゼロコピー抽象化のおかげで、GPUメモリへの転送とグラフの取得の両方が直接実行できます。インデキシング中、ベクトルは最初にJavaヒープ上のメモリにバッファリングされ、その後GPUに送られてCagraグラフを構築します。その後、グラフはGPUから取得され、HNSW形式に変換され、ディスクに保存されます。
マージ時には、ベクトルはすでにディスクに格納されており、Javaヒープを完全にバイパスします。インデックスファイルはメモリマップされ、データは直接GPUメモリに転送されます。この設計は、float32やint8などのさまざまなビット幅にも簡単に対応し、他の量子化スキームにも自然に拡張できます。
実際のパフォーマンス
数字を見てみる前に、少し背景を説明しておきましょう。Elasticsearchのセグメントマージは通常、インデキシング中にバックグラウンドで自動的に実行されるため、分離してベンチマークをとることが難しくなります。再現可能な結果を得るために、制御された実験でforce-mergeを使用してセグメントのマージを明示的にトリガーしました。force-mergeはバックグラウンドマージと同じ基礎となるマージ操作を実行するので、実際のインデキシングワークロードでは正確な効果が異なる場合でも、そのパフォーマンスは期待される改善を示す有用な指標となります。
さて、数字を見てみましょう。
最初のベンチマーク結果は非常に有望です。ベンチマークは、ローカルに接続されたNVMeストレージを持つAWS g6.4xlargeインスタンスで実行しました。Elasticsearchのシングルノードは、デフォルトの最適なインデキシングスレッド数(各物理コアに1つずつの計8つ)を使用し、マージスロットリング(高速NVMeディスクではあまり適用されません)を無効にするように設定しました。
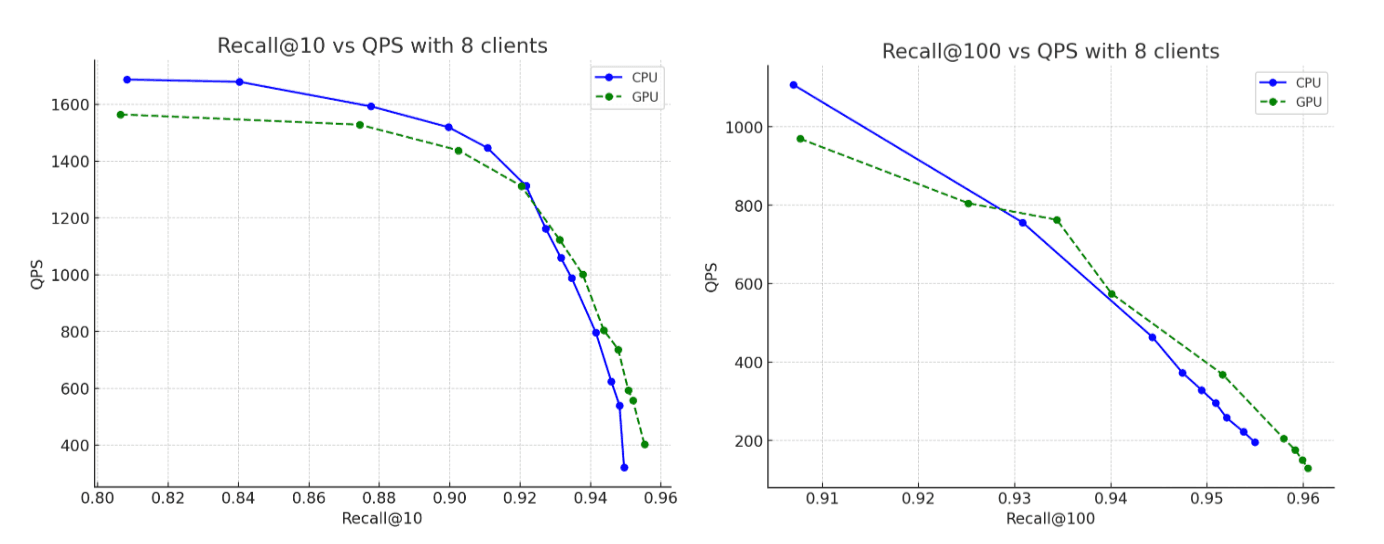
データセットにはOpenAI Rallyベクトルトラックから取得した1,536次元のベクトル260万個をbase64文字列としてエンコードし、float32 hnswとしてインデックスして使用しました。すべてのシナリオにおいて、構築されたグラフは最大95%のリコールレベルを達成します。結果は以下となりました。
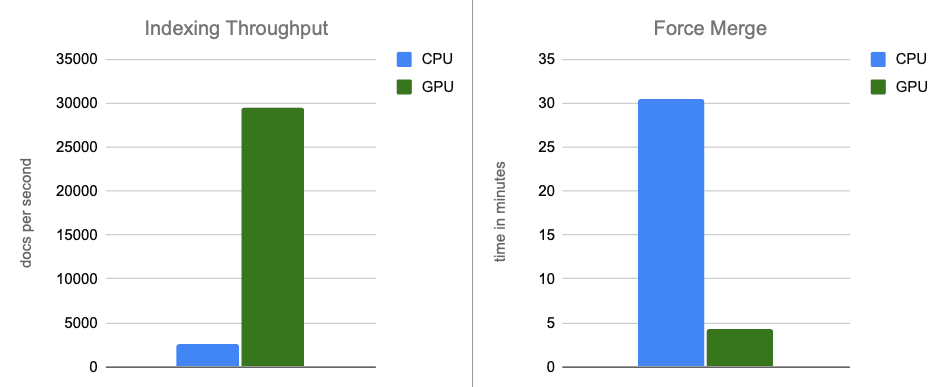
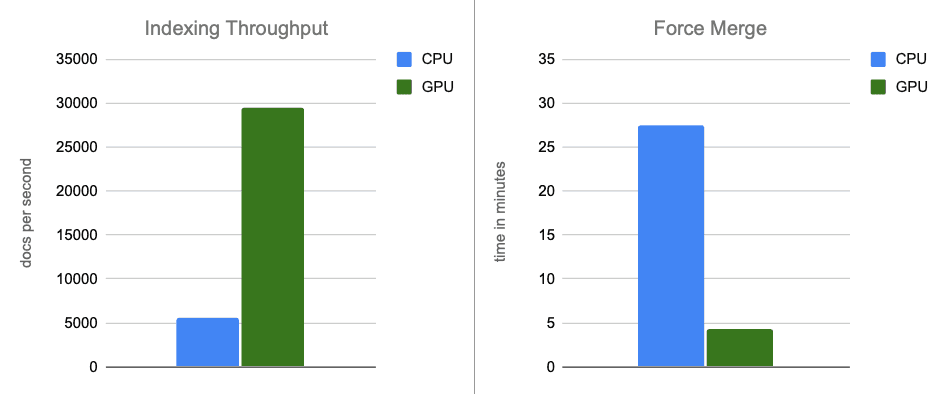
- インデキシングのスループット:メモリ内バッファのフラッシュ中にグラフ構築を GPU に移動することで、スループットが約 12 倍向上します。
- 強制マージ:インデキシングが完了した後、GPUはセグメントのマージを加速し続け、強制マージフェーズを約7倍高速化します。
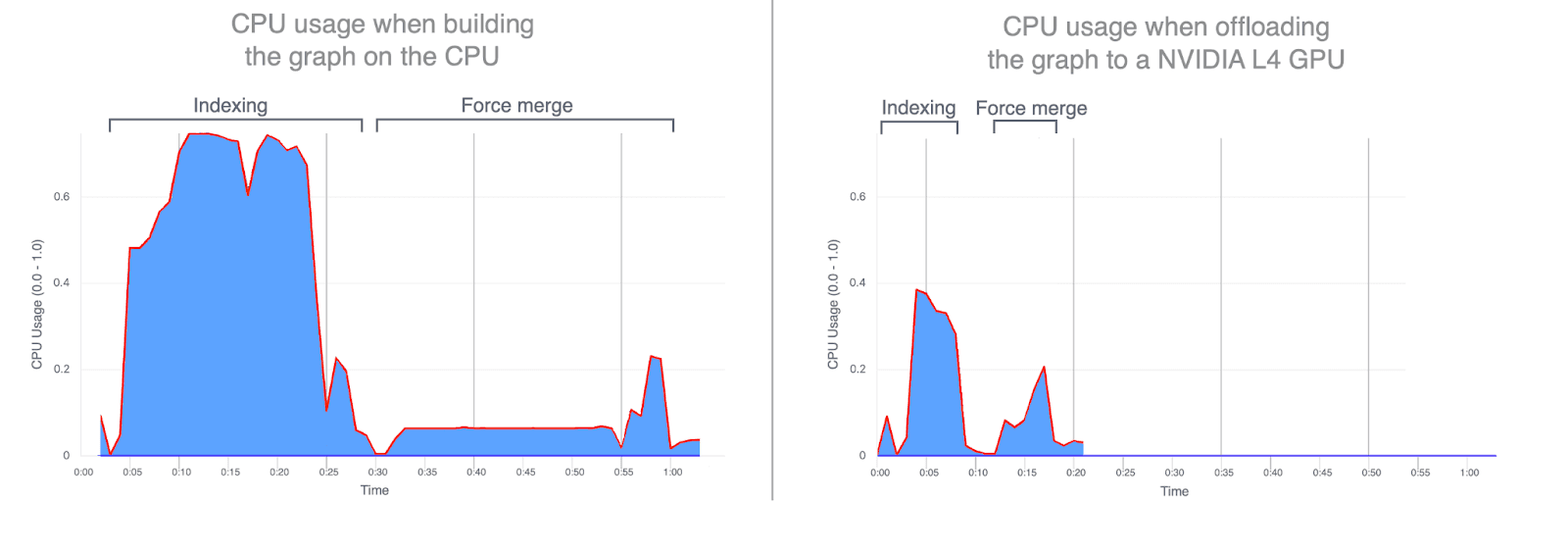
- CPU使用率:グラフ構築をGPUにオフロードすると、平均およびピーク時のCPU使用率が大幅に削減されます。以下のグラフは、インデキシングとマージ中のCPU使用率を示しており、これらの操作をGPUで実行すると使用率がどれだけ低くなるかを強調しています。GPUインデキシング中のCPU使用率が低下すると、CPUサイクルが解放され、検索パフォーマンスの向上に向けることができます。
- リコール:CPU実行とGPU実行の精度は実質的に同じですが、GPUで構築されたグラフのリコールはわずかに高くなります。
別の次元での比較:価格
先ほどの比較では、意図的に同一のハードウェアが使用されており、唯一の違いはインデキシング中にGPUが使用されたかどうかでした。この設定は、生のコンピューティング効果を分離するのに役立ちますが、コストの観点から比較することもできます。
GPUアクセラレーション構成とほぼ同じ時間単価で、同等のCPUおよびメモリリソースの約2倍(32個のvCPU(AMD EPYC)と64GBのRAM)を備えたCPUのみのセットアップをプロビジョニングでき、インデキシングスレッドの数を2倍の16に増やすことができます。
比較を公平かつ一貫性のあるものにするために、このCPUのみの実験をAWS g6.8xlargeインスタンスで実行しました。GPUは明示的に無効になっています。これにより、GPUアクセラレーションとCPUのみのインデキシングのコストパフォーマンスのトレードオフを評価する際、他のすべてのハードウェア特性を一定に保つことができました。
予想どおり、より強力なCPUインスタンスでは、上記のセクションのベンチマークと比較してパフォーマンスが向上しています。しかし、このより強力なCPUインスタンスを元のGPUアクセラレーション結果と比較すると、GPUは、リコールレベル最大95%に達するグラフを構築しながら最大5倍のインデキシングスループット向上、最大6倍のフォースマージと、依然として大幅なパフォーマンス向上を提供します。
結論
エンドツーエンドのシナリオでは、NVIDIA cuVSによるGPUアクセラレーションにより、インデキシングのスループットが約12倍向上し、force-mergeのレイテンシが7倍減少し、CPU使用率が大幅に低下します。これは、ベクトルインデキシングとマージワークロードがGPUアクセラレーションから大きな恩恵を受けることを示しています。コスト調整後の比較では、GPUアクセラレーションは引き続き大幅なパフォーマンス向上をもたらし、インデキシングのスループットは約5倍、force-merge操作は6倍高速化されます。
GPUアクセラレーションによるベクトルインデキシングは、現在Elasticsearch 9.3の技術プレビューで計画されており、2026年初頭にリリース予定です。
続報をお楽しみに。
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。