関連する結果を見つけるには、ベクター検索だけでは不十分です。検索結果を絞り込み、無関係な結果を除外するのに役立つフィルタリング基準を使用することは非常に一般的です。
ベクトル検索でのフィルタリングの仕組みを理解すると、パフォーマンスとリコールのトレードオフのバランスをとるのに役立ちます。また、フィルタリングの使用時にベクトル検索のパフォーマンスを高めるために使用される最適化のいくつかを知ることもできます。
なぜフィルタリングするのですか?
ベクトル検索は、大規模なデータセット内で関連情報を検索する方法に革命をもたらし、クエリと意味的に類似する項目を発見できるようになりました。
ただし、類似アイテムを見つけるだけでは十分ではありません。多くの場合、特定の基準や属性に基づいて検索結果を絞り込む必要があります。
電子商取引ストアで商品を検索していると想像してください。純粋なベクター検索では視覚的に類似したアイテムが表示される場合がありますが、価格帯、ブランド、在庫状況、または顧客評価でフィルタリングすることもできます。フィルタリングがなければ、類似した製品が大量に表示され、探しているものを正確に見つけることが難しくなります。
フィルタリングにより、検索結果を正確に制御できるようになり、取得された項目が意味的に一致するだけでなく、必要な要件をすべて満たすことが保証されます。これにより、より正確で効率的、そしてユーザーフレンドリーな検索エクスペリエンスが実現します。
Elasticsearch と Apache Lucene が優れているのはこの点です。さまざまなデータ タイプにわたって効果的なフィルタリングを使用することが、他のベクター データベースとの主な違いの 1 つです。
正確なベクトル検索のためのフィルタリング
正確なベクトル検索を実行するには、主に 2 つの方法があります。
- dense_vector フィールドに
flatインデックス タイプを使用します。これにより、knn検索では近似検索ではなく正確な検索が使用されるようになります。 - ベクトル関数を使用してスコアを計算するscript_score クエリを使用します。これはどのインデックス タイプでも使用できます。
正確なベクトル検索を実行すると、すべてのベクトルがクエリと比較されます。このシナリオでは、フィルターを通過するベクトルのみを比較する必要があるため、フィルタリングによってパフォーマンスが向上します。
いずれにしてもすべてのベクトルが考慮されるため、結果の品質には影響しません。興味のない結果を事前にフィルタリングするだけで、操作の数を減らすことができます。
これは非常に重要です。適用したフィルターによって少数のドキュメントが生成される場合、近似検索ではなく正確な検索を実行するとパフォーマンスが向上する可能性があるためです。
経験則としては、フィルターを通過するドキュメントが 10,000 個未満の場合は完全一致検索を使用します。BBQインデックスは比較が非常に高速なので、ベース インデックスが 10 万未満の場合は、完全一致検索を使用するのが合理的です。詳細については、このブログ投稿をご覧ください。
フィルターが常に非常に制限的である場合は、HNSW ベースのインデックス タイプではなくflatインデックス タイプを使用して、近似検索ではなく完全検索に重点を置いたインデックス作成を検討してください。詳細については、 index_options のプロパティを参照してください。
近似ベクトル検索のためのフィルタリング
近似ベクトル検索を実行する場合、結果の精度とパフォーマンスをトレードオフします。HNSW のようなベクトル検索データ構造は、数百万のベクトルのおおよその最近傍を効率的に検索します。計算コストのかかるベクトル比較を最小限に抑えて、最も類似したベクトルを取得することに重点を置いています。
つまり、他のフィルタリング属性はベクター データの一部ではないということです。さまざまなデータ タイプには、用語辞書、投稿リスト、ドキュメント値など、検索やフィルタリングに効率的な独自のインデックス構造があります。
これらのデータ構造はベクトル検索メカニズムとは別であるため、ベクトル検索にフィルタリングをどのように適用すればよいでしょうか?フィルターには、ベクター検索の後にフィルターを適用する (ポストフィルタリング) か、ベクター検索の前にフィルターを適用する (プレフィルタリング) という 2 つのオプションがあります。
それぞれの選択肢には長所と短所があります。詳しく見ていきましょう!
ポストフィルタリング
ポストフィルタリングは、ベクトル検索が完了した後にフィルターを適用します。これは、最も類似した上位 k 個のベクトル結果が見つかった後にフィルターが適用されることを意味します。
明らかに、結果にフィルターを適用した後、 k 件未満の結果が返される可能性があります。もちろん、ベクトル検索 (より高い k 値) からより多くの結果を取得できますが、フィルターを適用した後に k 以上の結果が得られるかどうかはわかりません。
ポストフィルタリングの利点は、ベクトル検索の実行時の動作を変更しないことです。つまり、ベクトル検索はフィルタリングを認識しません。ただし、取得される結果の最終的な数は変わります。
以下は、 knn クエリを使用したポストフィルタリングの例です。フィルタリング句が knn クエリとは別であることを確認します。
post-filterを使用した knn 検索では、ポストフィルタリングも利用できます。
knn 検索では明示的なポストフィルター セクションを使用する必要があることに注意してください。ポストフィルターを使用しない場合、knn 検索はポストフィルターを実行する代わりに、最近傍の結果を他のクエリまたはフィルターと組み合わせます。
プレフィルタリング
ベクトル検索の前にフィルターを適用すると、まずフィルターを満たすドキュメントが取得され、次にその情報がベクトル検索に渡されます。
Lucene はBitSetsを使用して、フィルター条件を満たすドキュメントを効率的に保存します。次に、ベクトル検索は条件を満たすドキュメントを考慮して、HNSW グラフを走査します。候補を結果に追加する前に、それが有効なドキュメントの BitSet に含まれているかどうかを確認します。
ただし、有効なドキュメントでない場合でも、候補を調査してクエリと比較する必要があります。HNSW の有効性は、グラフ内のベクトル間の接続に依存します。つまり、候補の探索を停止すると、その近傍もスキップされる可能性があることを意味します。
ガソリンスタンドに行くために車を運転するのを想像してください。ガソリンスタンドのない道路を無視すると、目的地にたどり着く可能性は低くなります。他の道はあなたにとって必要なものではないかもしれませんが、目的地まであなたを繋いでくれます。HNSW グラフ上のベクトルも同様です。
したがって、プレフィルタリングを適用すると、フィルタを適用しない場合よりもパフォーマンスが低下します。検索で訪れるすべてのベクトルに対して作業を実行し、フィルターに一致しないベクトルを破棄する必要があります。私たちは、トップ k の結果を得るために、より多くの作業とより多くの時間をかけています。
以下は、Elasticsearch クエリ DSL での事前フィルタリングの例です。フィルタリング句が knn セクションの一部になっていることを確認します。
事前フィルタリングは、 knn 検索とknn クエリの両方で利用できます。
プレフィルタリングの最適化
プレフィルタリングのパフォーマンスを確保するために適用できる最適化がいくつかあります。
フィルターの制限が厳しい場合は、完全一致検索に切り替えることができます。比較するベクトルが少ない場合は、フィルターを満たす少数のドキュメントに対して正確な検索を実行する方が高速です。
これは、 Luceneおよび Elasticsearch で自動的に適用される最適化です。
別の最適化方法では、フィルターの条件を満たさないベクトルを無視します。代わりに、このメソッドは、フィルターを通過するフィルター処理されたベクトルの近傍をチェックします。このアプローチでは、フィルタリングされたベクトルは考慮されず、現在のパスに接続されたベクトルの探索が継続されるため、比較の回数が効果的に削減されます。
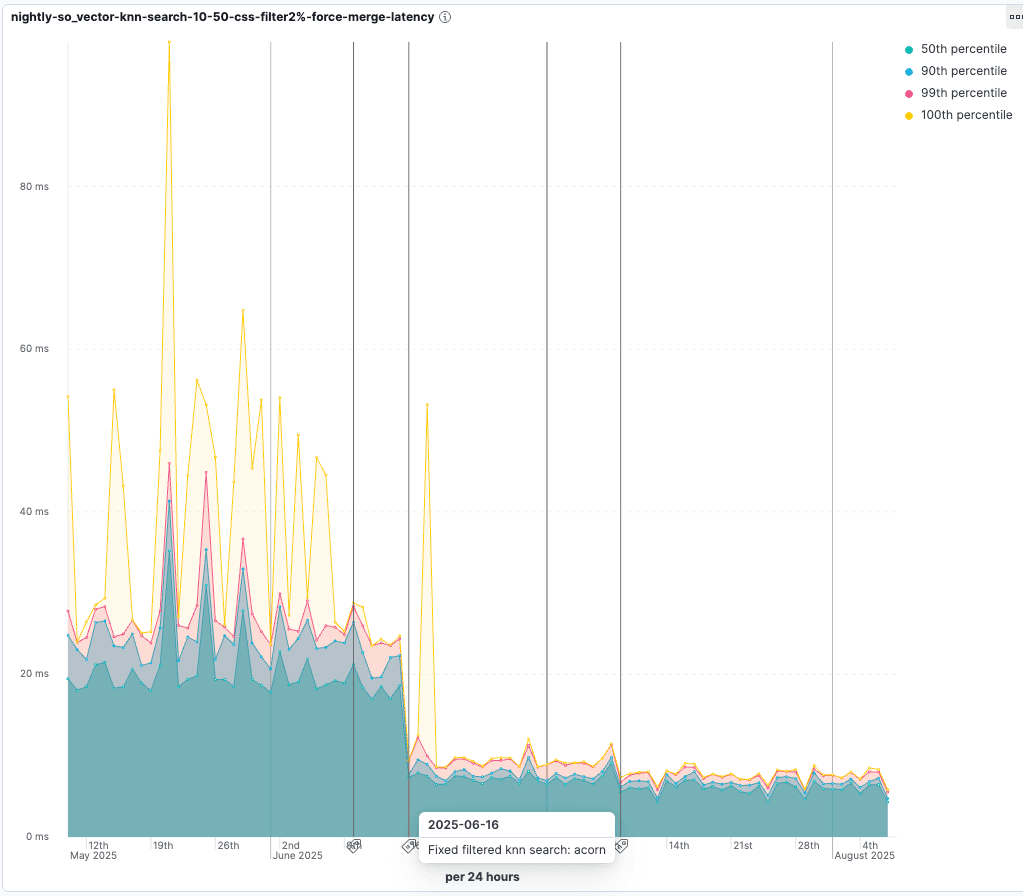
このアルゴリズムは ACORN-1 であり、そのプロセスについてはこちらのブログ記事で詳しく説明されています。
ドキュメントレベルのセキュリティを使用したフィルタリング
ドキュメント レベル セキュリティ (DLS)は、ユーザー ロールが取得できるドキュメントを指定する Elasticsearch 機能です。
DLS はクエリを使用して実行されます。ロールにはインデックスに関連付けられたクエリを持たせることができ、これにより、そのロールに属するユーザーがインデックスから取得できるドキュメントを効果的に制限できます。
ロール クエリは、それに一致するドキュメントを取得するためのフィルターとして使用され、BitSet としてキャッシュされます。この BitSet は、基盤となる Lucene リーダーをラップするために使用されるため、クエリから返されたドキュメントのみがライブであると見なされます。つまり、それらのドキュメントはインデックス上に存在し、削除されていません。
knn クエリを実行するためにリーダーからライブ ドキュメントが取得されるため、ユーザーが利用できるドキュメントのみが考慮されます。プレフィルターがある場合は、DLS ドキュメントがそれに追加されます。
つまり、DLS フィルタリングは、近似ベクトル検索のプレフィルタとして機能し、同じパフォーマンスへの影響と最適化を実現します。
完全一致検索を使用した DLS には、任意のフィルターを適用する場合と同じ利点があります。つまり、DLS から取得されるドキュメントが少ないほど、完全一致検索のパフォーマンスが向上します。DLS によって返されるドキュメントの数も考慮してください。DLS ロールの制限が非常に厳しい場合は、近似検索ではなく完全検索の使用を検討してください。
ベンチマーク
Elasticsearch では、ベクトル検索フィルタリングが効率的であることを確認したいと考えています。当社には、さまざまなフィルタリングを使用して近似ベクトル検索を実行するベクトル フィルタリング用の特定のベンチマークがあり、ベクトル検索で関連する結果を可能な限り高速に取得し続けることができるようにします。
ACORN-1 が導入されたときの改善点を確認します。ベクトルの 2% のみがフィルターを通過するテストでは、クエリの待機時間は元の期間の 55% に短縮されます。
まとめ
フィルタリングは検索の不可欠な部分です。ベクトル検索でフィルタリングのパフォーマンスを確保し、トレードオフと最適化を理解することが、効率的で正確な検索の成否を左右します。
フィルタリングはベクトル検索のパフォーマンスに影響します。
- フィルタリングを使用すると、正確な検索が高速になります。フィルタリングが十分に制限されている場合は、近似検索ではなく完全検索の使用を検討する必要があります。これは Elasticsearch での自動最適化です。
- 事前フィルタリングを使用すると近似検索が遅くなります。事前フィルタリングを使用すると、検索速度は遅くなりますが、フィルターに一致する上位 k 件の結果を取得できます。
- ポストフィルタリングでは、フィルターの適用時にフィルターによってフィルタリングされる可能性があるため、必ずしも上位 k 件の結果が取得されるわけではありません。
フィルタリングをお楽しみください!
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。