8.16 以降、ユーザーは長いドキュメントをセマンティック テキスト フィールドに取り込むときに使用するチャンキング戦略を構成できるようになりました。9.1 / 8.19 では、正規表現のリストを使用してドキュメントをチャンク化する、新しい構成可能な再帰チャンク化戦略を導入しました。チャンク化の目的は、長いドキュメントを関連するコンテンツをカプセル化するセクションに分割することです。既存の戦略では、テキストを単語/文の粒度で分割しますが、構造化された形式 (例:Markdown では、区切り文字列で定義されたセクション内に関連コンテンツが含まれることがよくあります (例:ヘッダー)。このような種類のドキュメントでは、構造化ドキュメントの形式を活用してより適切なチャンクを作成するための再帰チャンキング戦略を導入しています。
再帰チャンキングとは何ですか?
再帰チャンク化では、指定されたセクション分離パターンのリストを反復処理して、必要な最大チャンク サイズを満たすまで、ドキュメントを段階的に小さなセグメントに分割します。
再帰チャンクを構成するにはどうすればよいですか?
以下は、再帰チャンク化に対してユーザーが指定できる構成可能な値です。
- (必須)
max_chunk_size: チャンク内の最大単語数。 - 次のいずれか:
separators: ドキュメントをチャンクに分割するために使用される正規表現文字列パターンのリスト。separator_group: 特定の種類のドキュメントに使用するために Elastic によって定義された区切り文字のデフォルト リストにマップされる文字列。現在、markdownとplaintextが利用可能です。
再帰チャンキングはどのように機能しますか?
入力ドキュメント、 max_chunk_size (単語単位で測定)、および区切り文字列のリストが与えられた場合の再帰チャンク化のプロセスは次のとおりです。
- 入力ドキュメントがすでに最大チャンク サイズ内である場合は、入力全体にわたる単一のチャンクを返します。
- 区切り文字の出現に基づいてテキストを潜在的なチャンクに分割します。潜在的なチャンクごとに:
- 潜在的なチャンクが最大チャンク サイズ内である場合は、ユーザーに返すチャンクのリストに追加します。
- それ以外の場合は、潜在的なチャンクのテキストのみを使用して、リスト内の次のセパレーターを使用して分割し、手順 2 から繰り返します。試す区切り文字がもう残っていない場合は、文ベースのチャンクに戻ります。
再帰チャンクの設定例
チャンク サイズとは別に、再帰チャンク化の主な構成は、ドキュメントを分割するために使用するセパレーターを選択することです。どこから始めればよいかわからない場合は、Elasticsearch では一般的なユースケースに使用できるデフォルトのセパレーター グループがいくつか用意されています。
セパレーターグループの活用
セパレーター グループを利用するには、チャンク設定を構成するときに使用するグループの名前を指定するだけです。例えば:
これにより、区切りリスト["(?<!\\n)\\n\\n(?!\\n)", "(?<!\\n)\\n(?!\\n)")]を利用する再帰的なチャンク化戦略が提供されます。これは、2 つの改行文字とそれに続く 1 つの改行文字で分割する、一般的なプレーン テキスト アプリケーションに適しています。
セパレーターリストを利用するセパレーターグループmarkdownも提供しています。
この区切りリストは、6 つの見出しレベルとセクション区切り文字のそれぞれに分割する一般的なマークダウンの使用例に適しています。
リソース (推論エンドポイント/セマンティック テキスト フィールド) を作成すると、その時点のセパレーター グループに対応するセパレーターのリストが構成に保存されます。セパレーター グループが後日更新されても、既に作成されたリソースの動作は変更されません。
カスタム区切りリストの利用
定義済みの区切り文字グループのいずれかが使用ケースに適していない場合は、ニーズに合った区切り文字のカスタム リストを定義できます。区切りリスト内に正規表現を指定できることに注意してください。以下は、カスタムセパレーターを使用して構成されたチャンク設定の例です。
上記のチャンク化戦略では、 2 つの改行文字、続いて 1 つの改行文字、最後に文字列“<my-custom-separator>”で分割されます。
再帰チャンキングの実際の例
再帰チャンキングの実際の例を見てみましょう。この例では、上位 2 つのヘッダー レベルを使用してマークダウン ドキュメントを分割するセパレーターのカスタム リストとともに、次のチャンク設定を使用します。
単純なチャンクなしの Markdown ドキュメントを見てみましょう。

ここで、上で定義したチャンク設定を使用してドキュメントをチャンク化してみましょう。
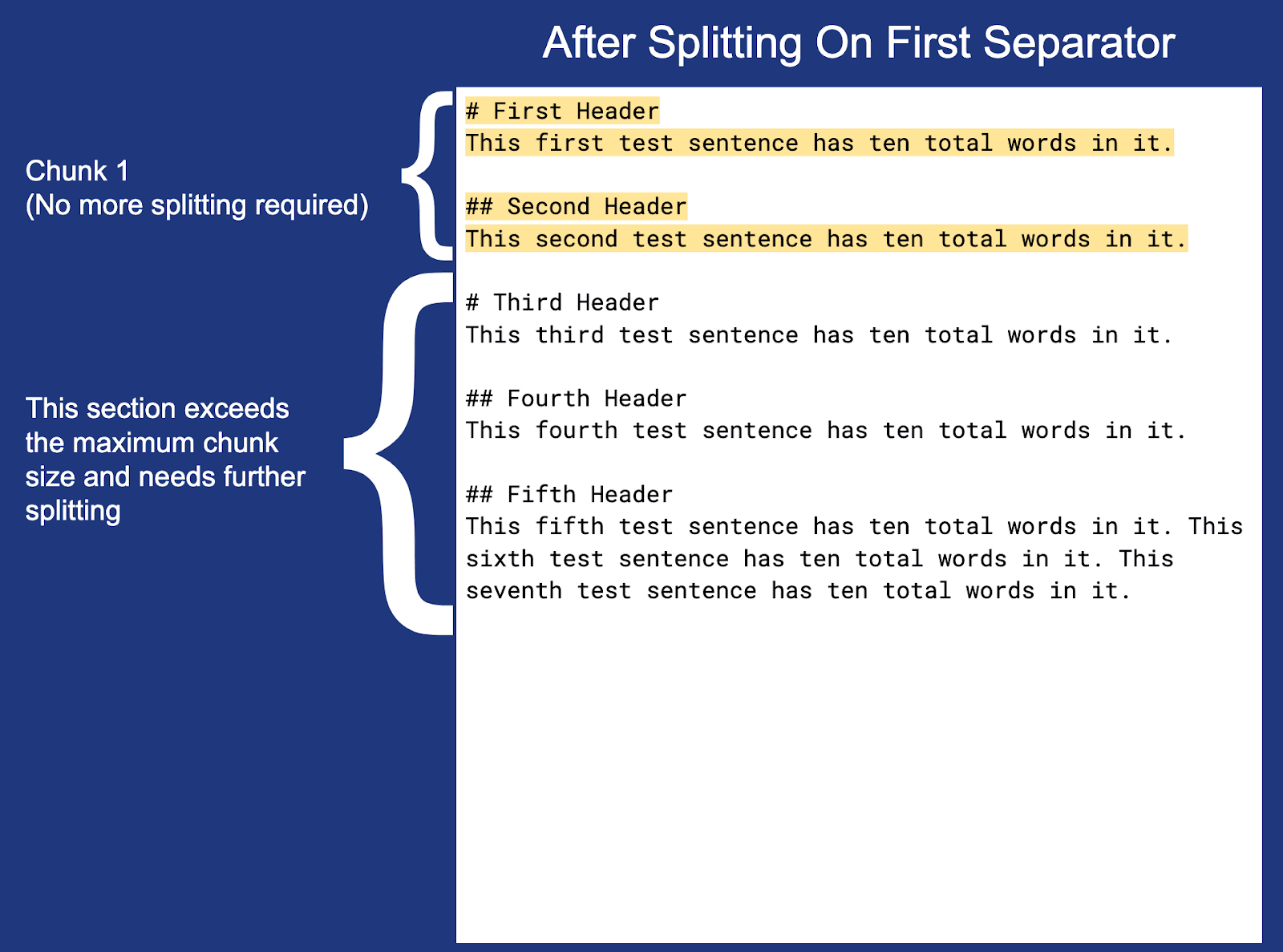

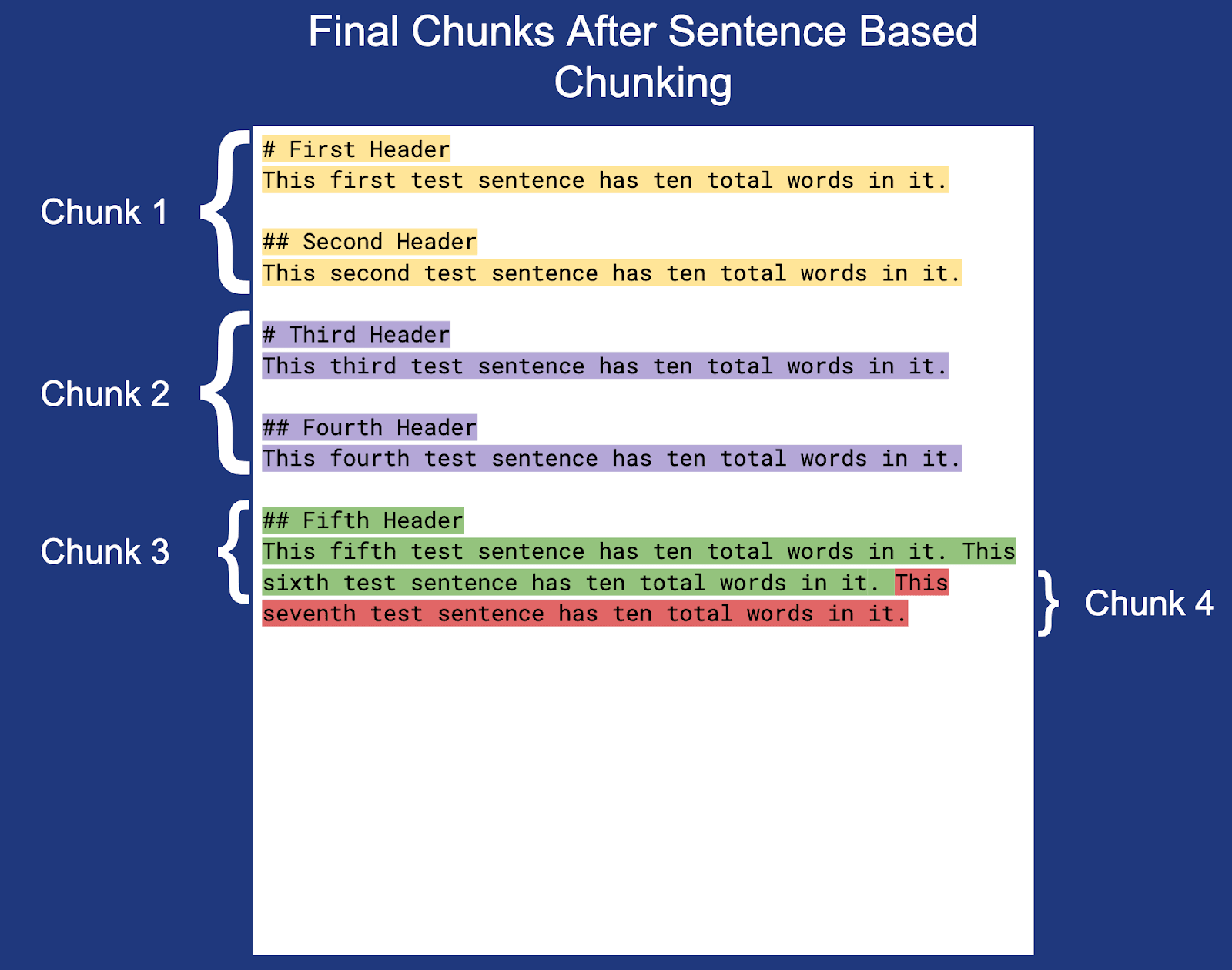
注: 各チャンク (チャンク 3 を除く) の末尾の改行は強調表示されませんが、実際のチャンク境界内に含まれます。
今すぐ再帰チャンキングを始めましょう!
この機能の利用方法の詳細については、チャンク設定の構成に関するドキュメントを参照してください。
関連記事

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年3月26日
Kibanaのダッシュボードに読み取り専用権限を追加
Kibanaに読み取り専用のダッシュボードを導入し、ダッシュボード作成者に詳細な共有制御を提供して、結果の正確性を保ち、不要な変更から保護します。

Elasticsearchによるエンティティ解決、パート4:究極のチャレンジ
ショートカットを防ぐために設計された、非常に多様な「究極のチャレンジ」データセットにおけるエンティティ解決の課題の解決と評価。