同時実行性の高いワークロード向けにElasticsearchをチューニングする場合の標準的なアプローチは、RAMを最大化してドキュメントのワーキングセットをメモリに保持し、検索レイテンシを低くすることです。結果として、best_compressionは検索ワークロードにはほとんど考慮されません。これは主に、ストレージ効率が優先されるElastic ObservabilityおよびElastic Securityのユースケースでのストレージ節約対策として見なされているためです。
このブログでは、データセットのサイズがOSページキャッシュを大幅に超える場合、best_compressionがI/Oボトルネックを軽減することで検索パフォーマンスとリソース効率を向上させることを示します。
セットアップ
ユースケースは、Elastic CloudのCPUに最適化されたインスタンス上で実行される高同時性検索アプリケーションです。
- データ量:ドキュメント約5億件
- インフラ:6つのElastic Cloud(Elasticsearch Service)インスタンス(各インスタンス:1.76 TBのストレージ | 60 GB RAM | 31.9 vCPU)
- メモリとストレージの比率:総データセットの約5%がRAMに収まる
課題:高いレイテンシ
19:00頃に現在のリクエスト数が急増すると、検索のレイテンシが大幅に悪化することが確認されました。図1と図2に示すように、Elasticsearchインスタンスあたりのトラフィックはピーク時で毎分400リクエスト程度でしたが、平均クエリサービス時間は60ミリ秒以上に低下しました。
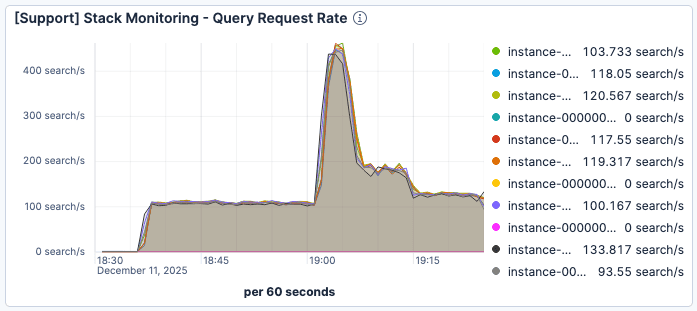
図1. Elasticsearchインスタンスあたりの1分あたりのリクエスト数は19:00過ぎに約400でピークに達しました。
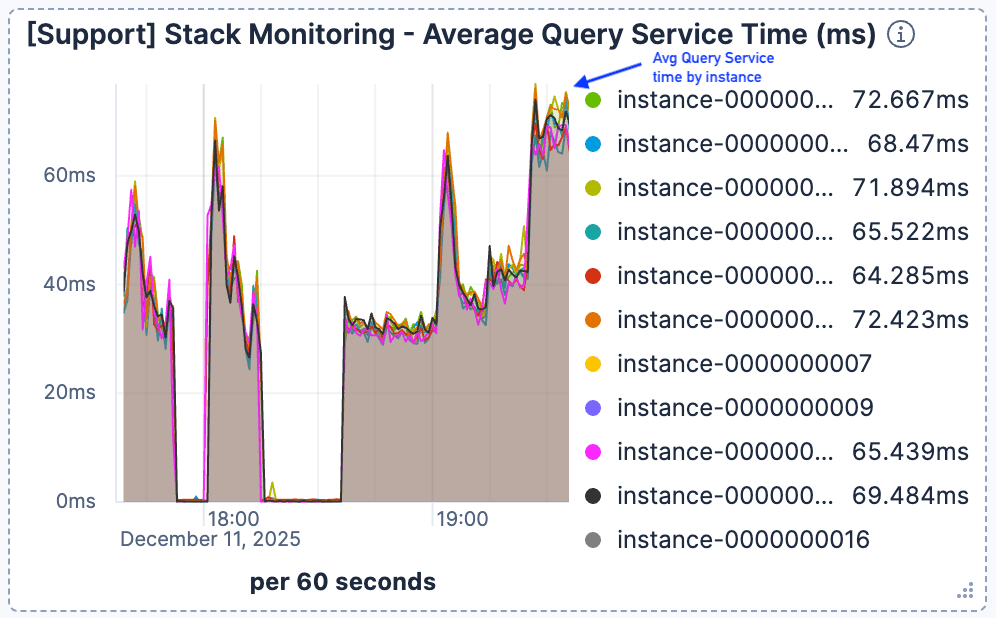
図2. 平均クエリサービス時間が急上昇し始め、60ミリ秒を超えて維持されました。
初期の接続処理後、CPU使用率は比較的低いままであり、コンピューティングがボトルネックではなかったことを示しています。
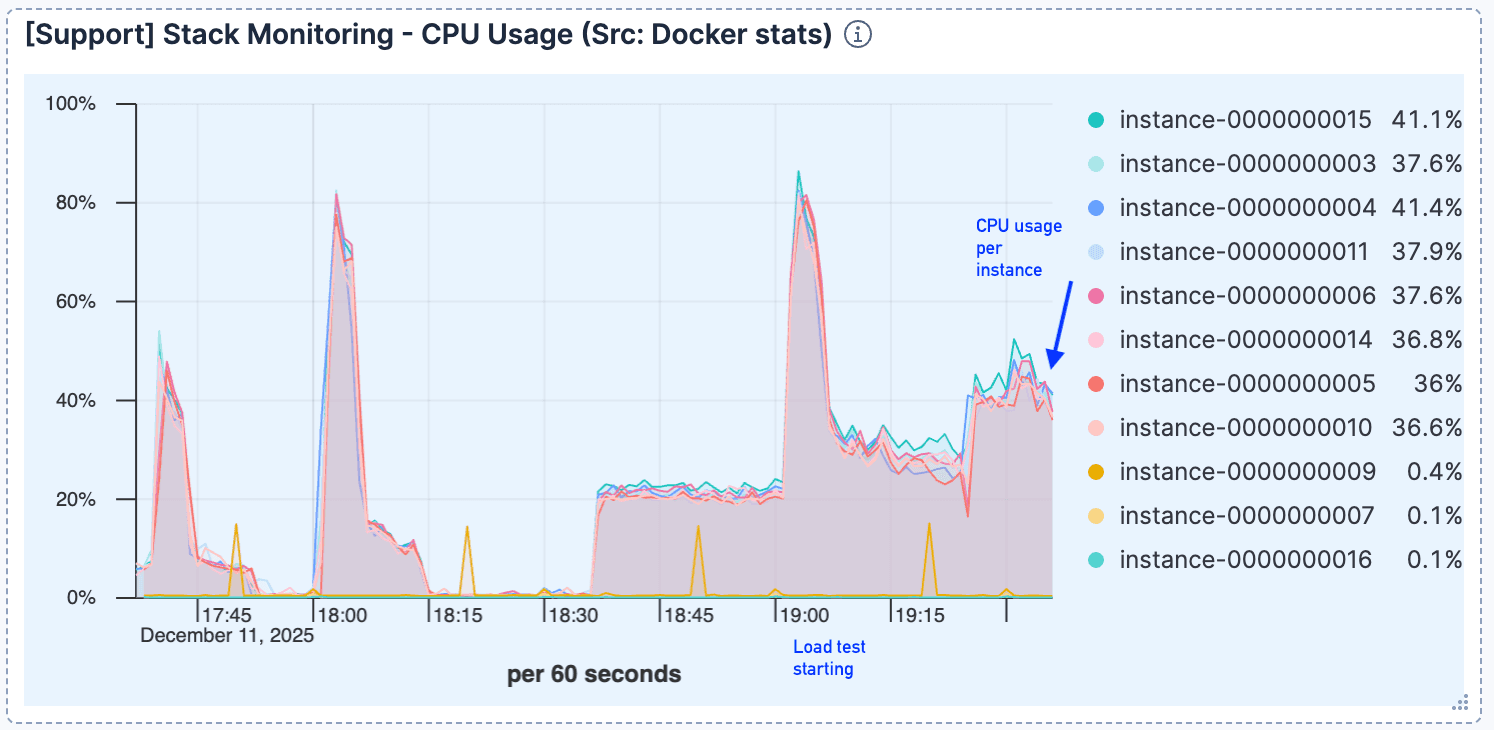
図3. 最初の急上昇の後、CPU使用率は比較的低いままです。
クエリボリュームとページフォールトの間の強い相関関係が明らかになりました。リクエストが増加するにつれて、ページフォールトも比例して増加し、ピークは約40万件/分に達しました。これは、アクティブなデータセットがページキャッシュに収まらなかったことを示しています。
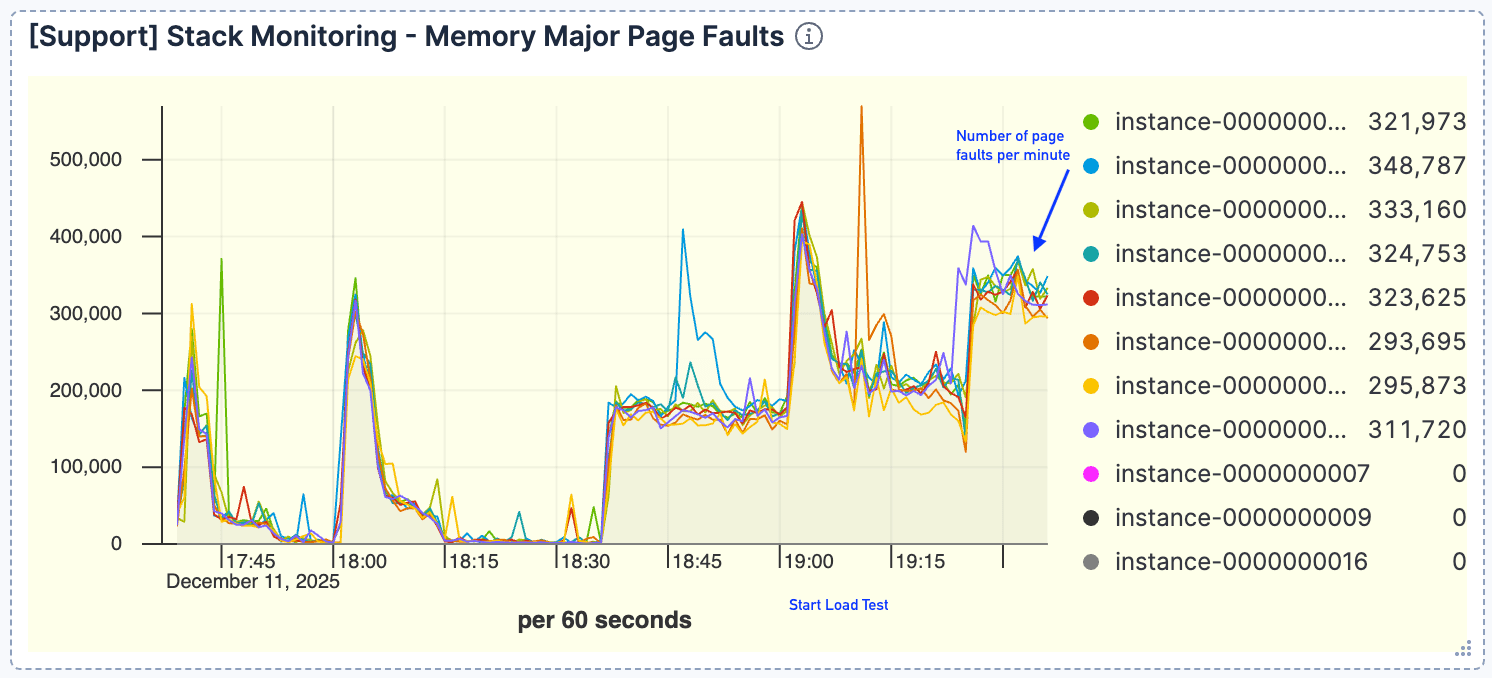
図4. ページフォールトの数は多く、ピーク時には40万件/分程度でした。
同時に、JVMヒープの使用量は正常かつ健全であるように見えました。これにより、ガベージコレクションの問題が排除され、ボトルネックが I/O であることが確認されました。
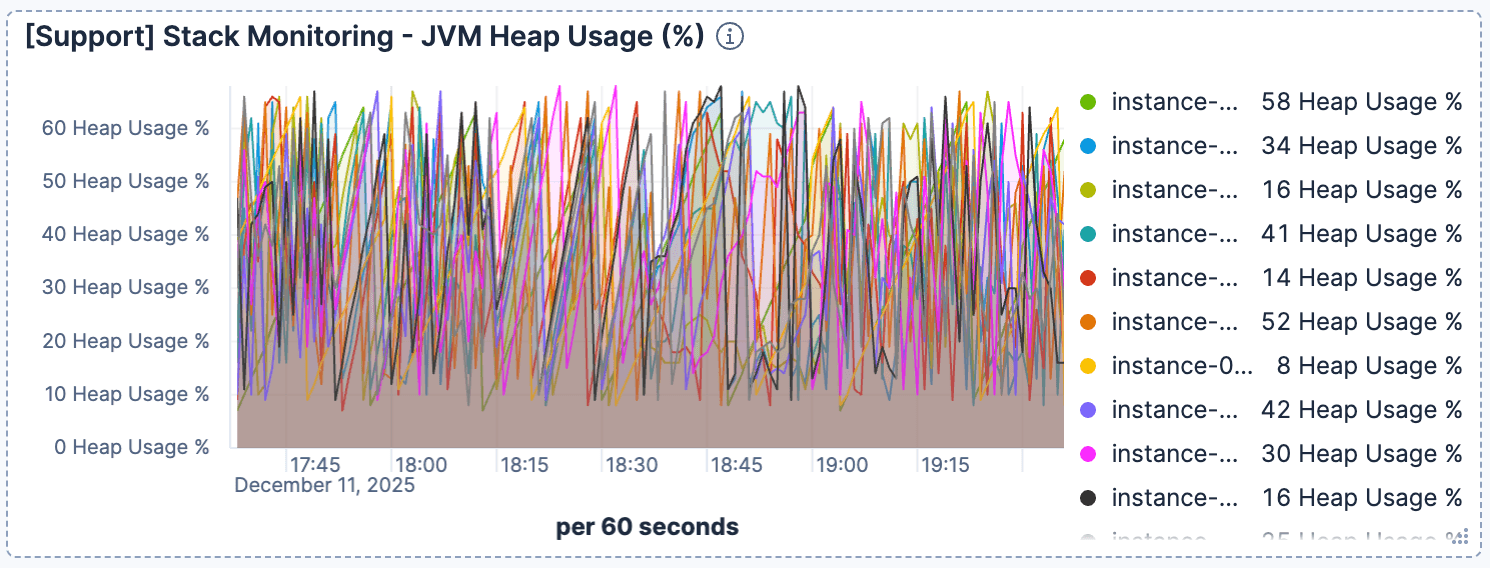
図5. ヒープ使用量は横ばいでした。
診断:I/Oバウンド
システムはI/Oバウンド状態でした。Elasticsearchは、メモリからインデックスデータを提供するためにOSページキャッシュに依存します。インデックスがキャッシュに対して大きすぎる場合、クエリによってコストのかかるディスク読み取りがトリガーされます。一般的な解決策は水平方向に拡張すること(ノード/RAMの追加)ですが、まずは既存のリソースの効率改善を最大限に図りたいと考えました。
修正
デフォルトでは、ElasticsearchはインデックスセグメントにLZ4圧縮を使用し、速度とサイズのバランスをとります。best_compression (zstdを使用)に切り替えるとインデックスのサイズが小さくなるという仮説を立てました。フットプリントが小さいほど、ページキャッシュに収まるインデックスの割合が大きくなり、CPUのわずかな増加(解凍用)と引き換えにディスクI/Oが削減されます。
best_compressionを有効にするために、インデックス設定index.codec: best_compressionでデータを再インデックスしました。あるいは、インデックスを閉じ、インデックスコーデックをbest_compressionにリセットしてから、セグメントのマージを実行することで、同じ結果を得ることができます。
結果
結果は、ストレージ効率の向上は、CPU使用率の増加を伴わずに検索パフォーマンスの大幅な向上に直接つながるという私たちの仮説を裏付けました。
best_compressionを適用するとインデックスの大きさは約25%減少しました。反復ログデータで確認された削減よりは少ないものの、この25%の削減により、ページキャッシュ容量が同じだけ実質的に増加しました。
次のロードテスト(17:00から)では、トラフィックはさらに増加し、Elasticsearchノードあたり1分あたり500リクエストでピークに達しました。
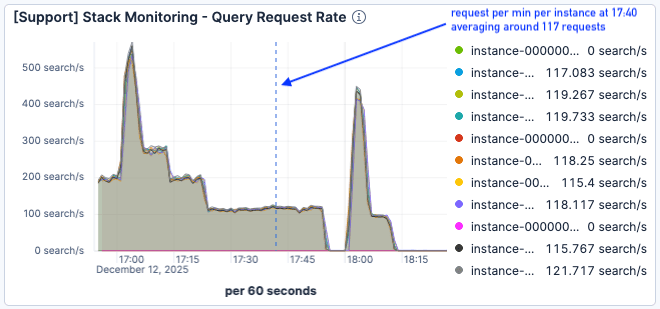
図6. 負荷テストは17:00頃に開始しました。
負荷が高まったにもかかわらず、CPU使用率は前回の実行時よりも低くなりました。前のテストで使用率が高かったのは、過剰なページフォールト処理とディスクI/O管理のオーバーヘッドが原因である可能性があります。
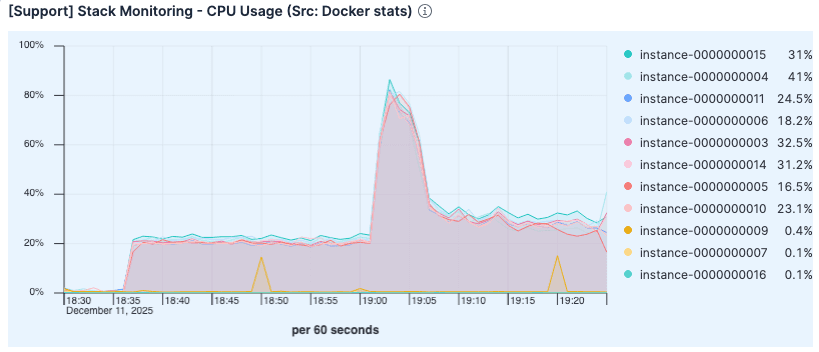
図7. CPU 使用率は前回の実行よりも低くなりました。
重要なのは、ページフォールトが大幅に減少したことです。ベースラインテストの30万件超に比較して、より高いスループットでもフォールトは1 分あたり20万件未満に留まりました。
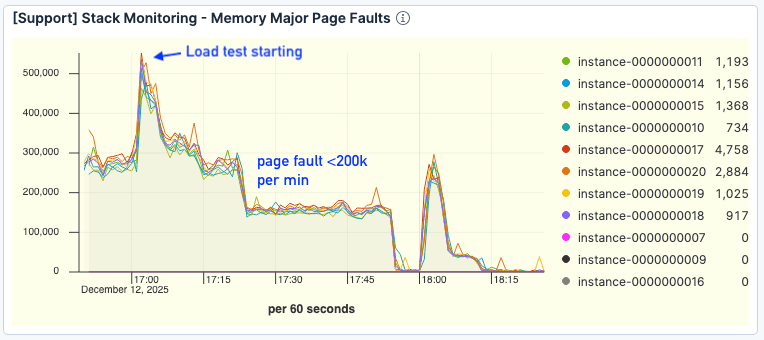
図8. ページフォールトの数が大幅に改善されました。
ページフォールトの結果はまだ最適とは言えませんでしたが、クエリサービス時間は約50%削減され、負荷が高まった場合でも30ミリ秒未満に留まりました。
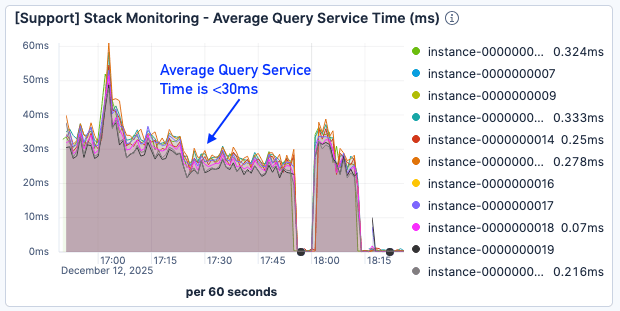
図9. 平均クエリサービス時間は30ミリ秒未満でした。
結論:検索にはbest_compressionを
データ量が利用可能な物理メモリを超える検索ユースケースでは、 best_compressionは強力なパフォーマンス調整手段となります。
キャッシュミスに対する従来の解決策はスケールアウトしてRAMを増やすことですが、インデックスのフットプリントを削減することで、ページ キャッシュ内のドキュメント数を最大化するという同じ目標を達成しました。次のステップは、インデックスの並べ替えを探求し、ストレージをさらに最適化し、既存のリソースからさらにパフォーマンスを引き出すことです。
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年3月26日
Kibanaのダッシュボードに読み取り専用権限を追加
Kibanaに読み取り専用のダッシュボードを導入し、ダッシュボード作成者に詳細な共有制御を提供して、結果の正確性を保ち、不要な変更から保護します。

2025年12月11日
判断リストによる検索クエリの関連性の評価
Elasticsearchで検索クエリの関連性を客観的に評価し、リコールなどのパフォーマンス指標を改善するための判断リストの構築方法を探ります。スケーラブルな検索のテストの拡張性についても学びます。

2025年11月11日
Elasticsearch で構造化ドキュメントの再帰チャンクを構成する
チャンク サイズ、セパレーター グループ、カスタム セパレーター リストを使用して Elasticsearch で再帰チャンクを設定し、構造化ドキュメントのインデックスを最適に作成する方法を学びます。