最近の他社と同様に、Elastic ではチャット、エージェント、RAG に全力を注いでいます。検索部門では最近、エージェント ビルダーとツール レジストリに取り組んでおり、その目的は、Elasticsearch 内のデータとの「チャット」を簡単に行えるようにすることです。
この取り組みの「全体像」について詳しくは、ブログ「Elasticsearch を使用した AI エージェントワークフローの構築」をお読みください。より実践的な入門書として、「初めての Elastic エージェント: 単一のクエリから AI を活用したチャットまで」もご覧ください。
ただし、このブログでは、チャットを開始したときに最初に起こることの 1 つに焦点を絞り、最近行った改善点のいくつかについて説明します。
ここで何が起こっているのですか?

Elasticsearch データとチャットする場合、デフォルトの AI エージェントが次の標準フローを実行します。
- プロンプトを検査します。
- どのインデックスにそのプロンプトの回答が含まれている可能性があるかを特定します。
- プロンプトに基づいて、そのインデックスのクエリを生成します。
- そのクエリでそのインデックスを検索します。
- 結果を統合します。
- 結果はプロンプトに対応できますか?はいの場合は応答してください。そうでない場合は、別の方法を試しながら繰り返します。
これはあまり目新しいものではないはずです。これは単に Retrieval Augmented Generation (RAG) です。そして当然のことですが、応答の質は最初の検索結果の関連性に大きく左右されます。そのため、応答品質の向上に取り組む中で、ステップ 3 で生成してステップ 4 で実行するクエリに細心の注意を払ってきました。そして、私たちは興味深いパターンに気づきました。
多くの場合、最初の応答が「悪い」場合、それは実行したクエリが悪かったからではありません。クエリを実行するために間違ったインデックスを選択したためです。通常、ステップ 3 と 4 は問題ではありません。問題はステップ 2 です。
私たちは何をしていたのでしょうか?
当初の実装はシンプルでした。私たちは、 _cat/indicesを効果的に実行して利用可能なすべてのインデックスをリストし、これらのインデックスのうちどれがユーザーのメッセージ/質問/プロンプトに最も一致するかを LLM に識別させるツール (index_explorer と呼ばれる) を構築しました。このオリジナルの実装はここで見ることができます。
これはどれくらいうまく機能しましたか?よく分かりませんでした!うまく機能していない明確な例はありましたが、私たちにとっての本当の最初の課題は、現状を定量化することでした。
ベースラインの確立
それはデータから始まる
私たちが必要としていたのは、ユーザーのプロンプトと既存のインデックス セットに基づいて適切なインデックスを選択するツールの有効性を測定するためのゴールデン データ セットでした。そして、手元にそのようなデータセットがなかったので、それを生成しました。
謝辞: これは「ベスト プラクティス」ではないことは承知しています。しかし、時には、自転車を捨てるよりも前進する方が良いこともあります。進歩、シンプルな完璧さ。
このプロンプトを使用して、いくつかの異なるドメインのシードのインデックスを生成しました。次に、生成されたドメインごとに、このプロンプトを使用してさらにいくつかのインデックスを生成しました (ここでの目標は、ハードネガティブと分類が難しい例を使用して LLM に混乱を引き起こすことです)。次に、生成された各インデックスとその説明を手動で編集しました。最後に、このプロンプトを使用してテストクエリを生成しました。次のようなサンプルデータが得られました。

そして次のようなテストケース:
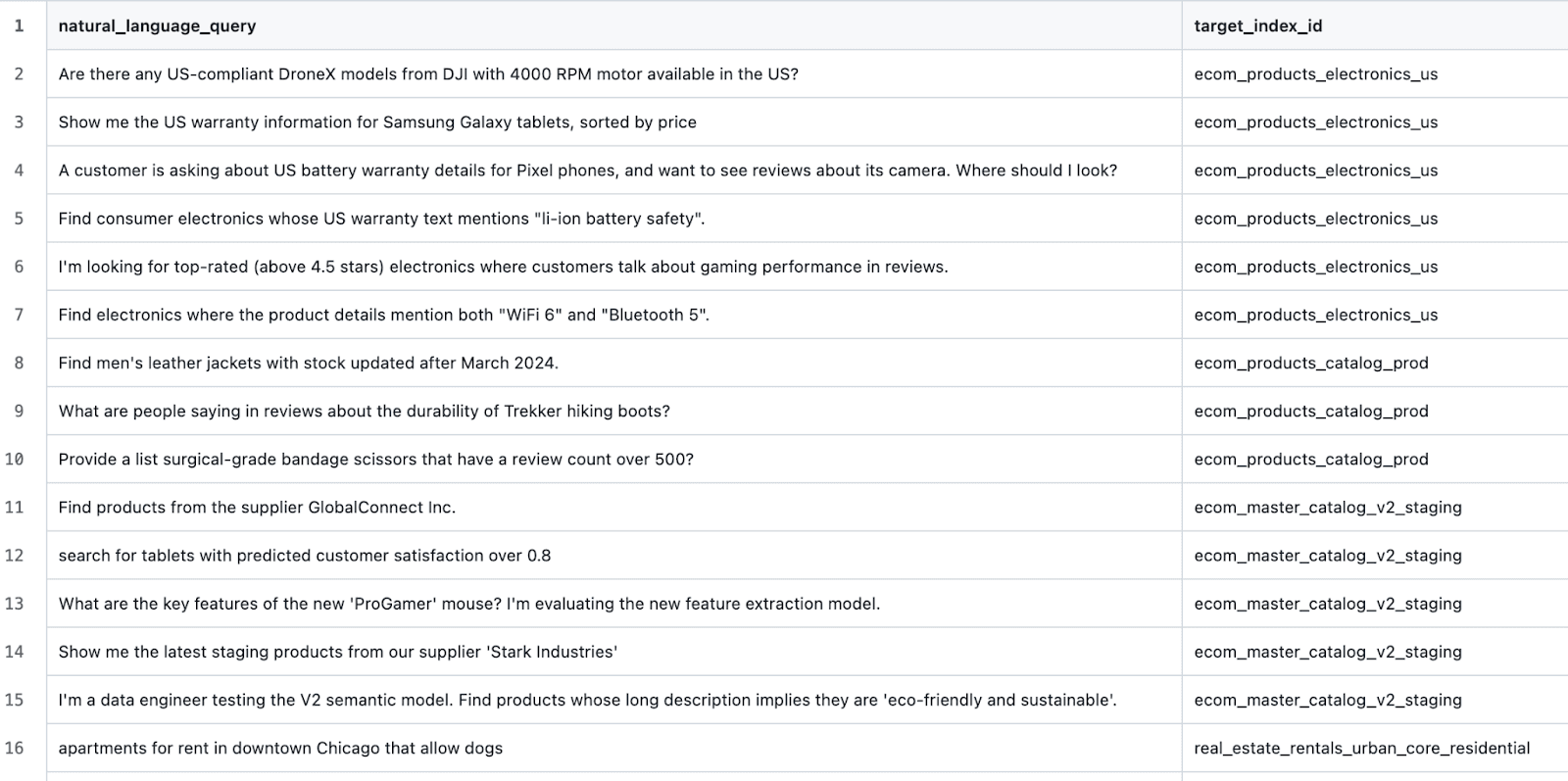
テストハーネスの作成
ここからのプロセスは非常に簡単でした。次の機能を備えたツールをスクリプト化します。
- ターゲット Elasticsearch クラスターを使用してクリーンな状態を確立します。
- ターゲット データセットで定義されているすべてのインデックスを作成します。
- 各テスト シナリオに対して、 i
ndex_explorerツールを実行します (便利なことに、実行ツール API があります)。 - 結果のインデックスを予想インデックスと比較し、結果を取得します。
- すべてのテストシナリオを終了したら、結果を表にまとめます。
調査によると…
当初の結果は予想通り平凡なものでした。
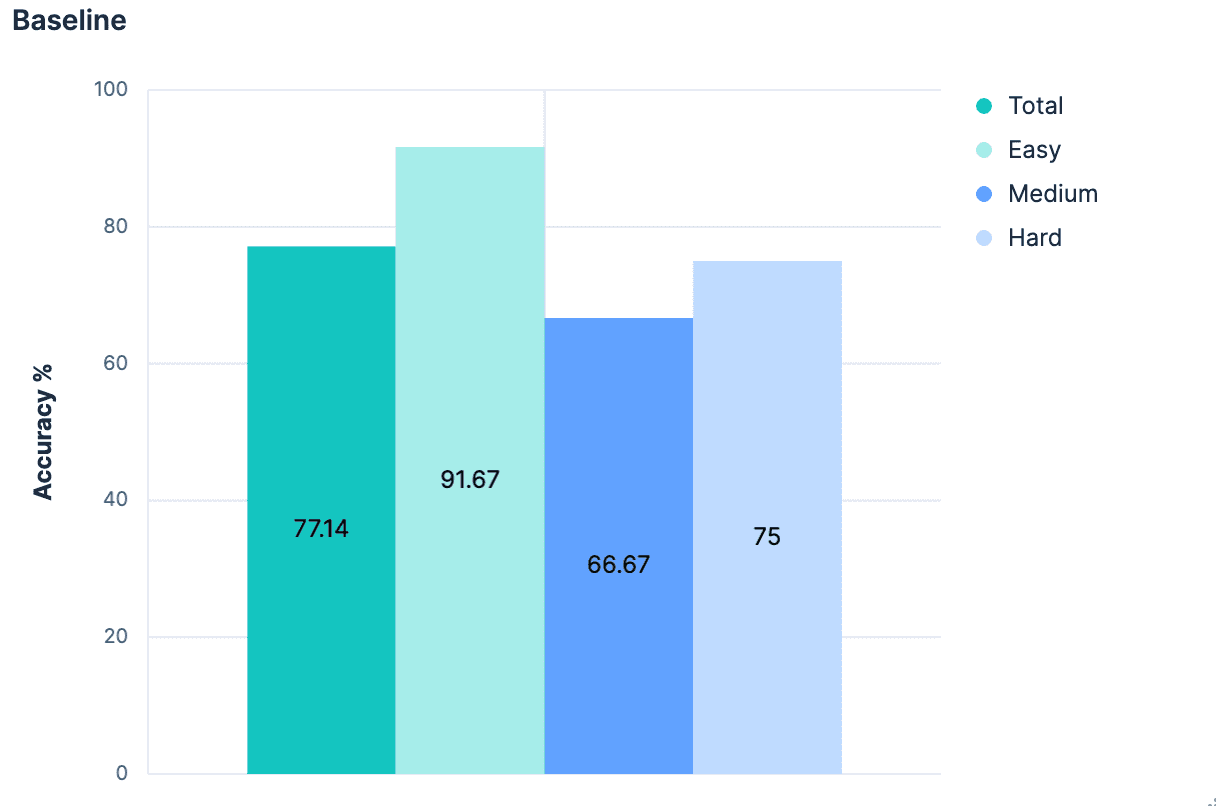
全体として、正しいインデックスを識別する精度は 77.14% です。これは、すべてのインデックスに意味的に意味のある適切な名前が付けられている「最良のケース」のシナリオでした。`PUT test2/_doc/foo {...} ` を実行したことがある人なら、インデックスの名前が必ずしも意味のあるものではないことはご存じでしょう。
つまり、ベースラインがあり、改善の余地が十分にあることがわかります。さあ、科学の時間です!🧪
実験
仮説1: マッピングは役立つ
ここでの目標は、元のプロンプトに関連するデータが含まれるインデックスを識別することです。インデックスに含まれるデータを最もよく表す部分は、インデックスのマッピングです。インデックスの内容のサンプルを取得しなくても、インデックスに double 型の価格フィールドがあることがわかれば、そのデータは販売されるものを表していることがわかります。テキストタイプの著者フィールドは、何らかの非構造化言語データを意味します。これら 2 つを組み合わせると、データが書籍、物語、詩であることを意味する可能性があります。インデックスのプロパティを知るだけで、意味上の手がかりを数多く得ることができます。そこでローカルブランチで`.index_explorer`を調整しましたインデックスの完全なマッピング (およびその名前) を LLM に送信して決定を下すツール。
結果(Kibana ログより):
ツールの最初の作成者はこれを予期していました。インデックスのマッピングは情報の宝庫ですが、非常に冗長な JSON ブロックでもあります。そして、多数のインデックス (評価データセットでは 20 個が定義されています) を比較する現実的なシナリオでは、これらの JSON BLOB が加算されます。したがって、LLM に、すべてのオプションのインデックス名だけでなく、それぞれの完全なマッピングほどではなく、決定のためのより多くのコンテキストを提供したいと考えています。
仮説2: 妥協案としての「フラット化された」マッピング(フィールドリスト)
私たちは、インデックス作成者が意味的に意味のあるインデックス名を使用するという前提から始めました。その仮定をフィールド名にも拡張するとどうなるでしょうか?前回の実験は、JSON のマッピングに大量の煩わしいメタデータと定型句が含まれているため失敗しました。
たとえば、上記のブロックは 236 文字で、Elasticsearch マッピング内の 1 つのフィールドのみを定義します。一方、文字列「description_text」は 16 文字だけです。これは文字数が約 15 倍に増加していることを意味しますが、そのフィールドが利用可能なデータについて何を意味するかを説明する意味的な改善は見られません。すべてのインデックスのマッピングをフェッチしたが、それを LLM に送信する前に、フィールド名のリストだけに「フラット化」するとどうなるでしょうか?
試してみました。

これは素晴らしいですね!全面的に改善されました。しかし、もっと良い方法はないでしょうか?
仮説3: マッピング_meta内の説明
追加のコンテキストのないフィールド名だけでこれほど大きな変化が生じたのであれば、実質的なコンテキストを追加すればさらに良くなると思われます。すべてのインデックスに説明を添付することが必ずしも慣例ではありませんが、マッピングの _meta オブジェクトにあらゆる種類のインデックス レベルのメタデータを追加することは可能です。生成されたインデックスに戻り、データセット内のすべてのインデックスに説明を追加しました。説明が極端に長くない限り、完全なマッピングよりも少ないトークンが使用され、インデックスに含まれるデータに関するはるかに優れた洞察が提供されるはずです。私たちの実験はこの仮説を検証しました。
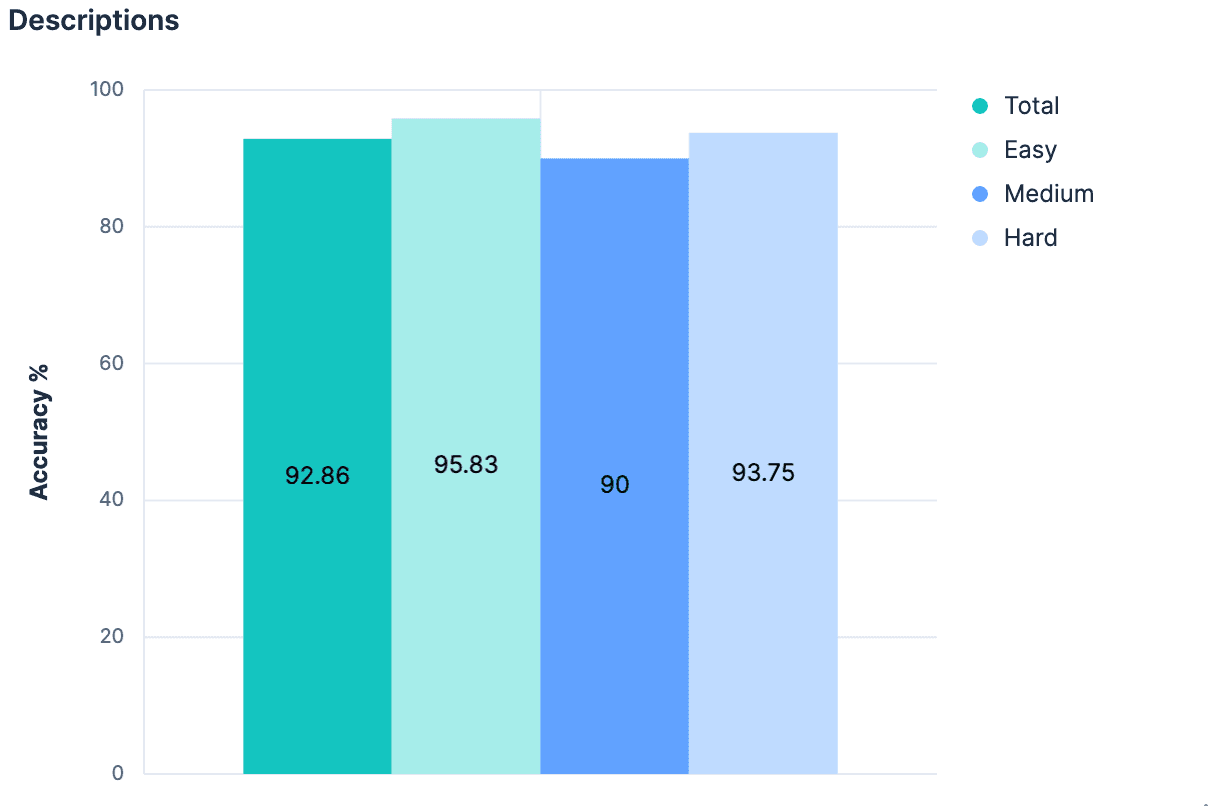
若干の改善があり、現在では全体的に 90% を超える精度を実現しています。
仮説4:全体は部分の合計よりも大きい
フィールド名により結果が向上しました。説明により結果が向上しました。したがって、説明とフィールド名の両方を利用すると、さらに良い結果が得られるはずです。
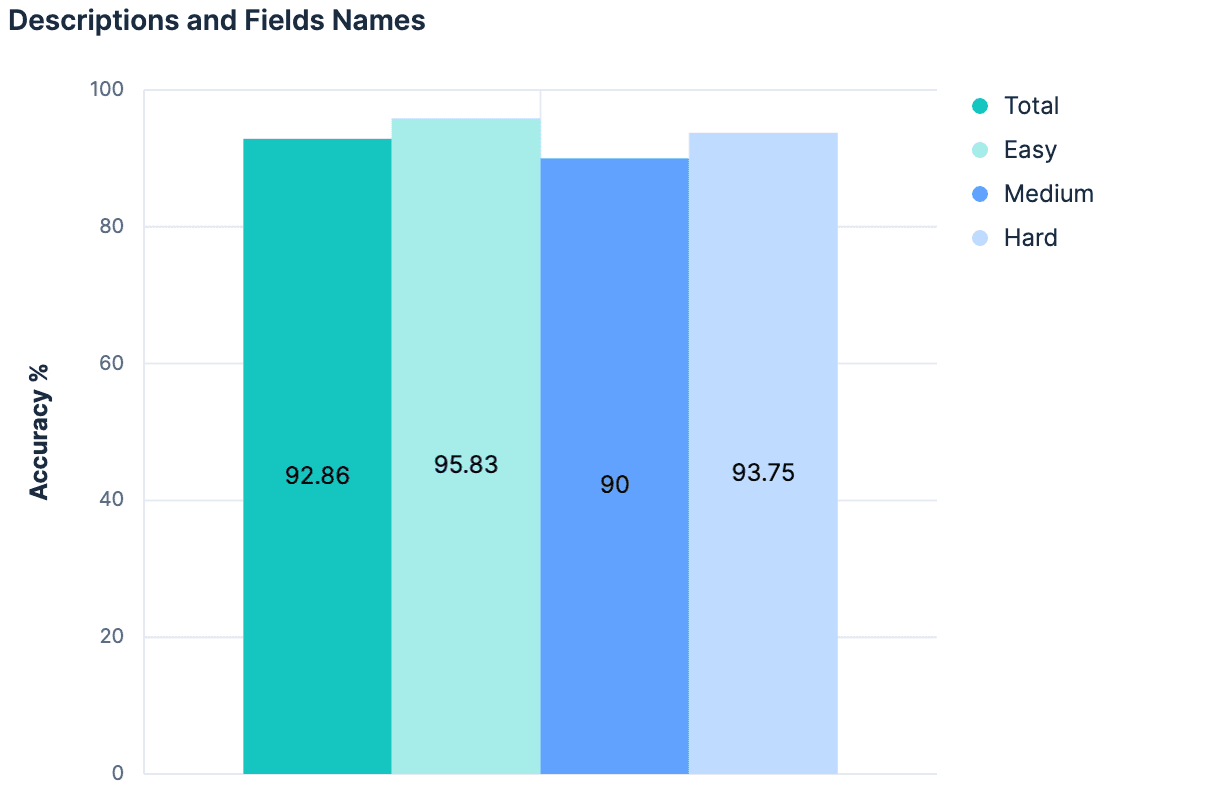
データは「いいえ」(前回の実験から変化なし)を示しました。ここでの主な理論は、説明はそもそもインデックス フィールド/マッピングから生成されたため、これら 2 つのコンテキストの間には、組み合わせたときに何か「新しい」ものを追加するのに十分な情報がないというものでした。さらに、20 個のテスト インデックスに送信するペイロードもかなり大きくなっています。これまで私たちが辿ってきた考え方はスケーラブルではありません。実際、これまでの私たちの実験は、数百または数千のインデックスから選択できる Elasticsearch クラスターでは機能しないと考えられる十分な理由があります。インデックスの合計数が増加するにつれて、LLM に送信されるメッセージ サイズが直線的に増加するアプローチは、おそらく一般化可能な戦略にはなりません。
私たちに本当に必要なのは、多数の候補から最も関連性の高い選択肢だけを絞り込むのに役立つアプローチです...
ここで問題となるのは検索の問題です。
仮説5:意味検索による選択
インデックスの名前に意味がある場合は、ベクトルとして保存し、意味的に検索することができます。
インデックスのフィールド名に意味がある場合は、それらをベクトルとして保存し、意味的に検索することができます。
インデックスに意味を持つ記述がある場合は、それもベクトルとして保存し、意味的に検索することができます。
現在、Elasticsearch インデックスではこの情報を検索可能にしていません (検索可能にすべきかもしれませんが) が、そのギャップを回避できるものをハックするのは非常に簡単でした。Elastic のコネクタ フレームワークを使用して、クラスター内のすべてのインデックスのドキュメントを出力するコネクタを構築しました。出力ドキュメントは次のようになります。
これらのドキュメントを、次のように手動でマッピングを定義した新しいインデックスに送信しました。
これにより、単一の semantic_content フィールドが作成され、セマンティックな意味を持つ他のすべてのフィールドがチャンク化され、インデックスが作成されます。このインデックスの検索は、次のようにするだけで簡単になります。
修正されたindex_explorerツールは、LLM へのリクエストを行う必要がなくなり、代わりに指定されたクエリに対して単一の埋め込みをリクエストして効率的なベクトル検索操作を実行できるため、大幅に高速化されました。トップヒットを選択したインデックスとして取得すると、次の結果が得られました。

このアプローチはスケーラブルです。このアプローチは効率的です。しかし、このアプローチはベースラインよりわずかに優れているだけです。しかし、これは驚くことではありません。ここでの検索アプローチは信じられないほど単純です。ニュアンスがない。インデックスの名前と説明は、インデックスに含まれる任意のフィールド名よりも重視されるべきであるという認識がありません。正確な語彙の一致を同義語の一致よりも重視するアフォーダンスはありません。ただし、非常に微妙なニュアンスのあるクエリを構築するには、手元のデータについて多くのことを想定する必要があります。これまで、インデックス名とフィールド名には意味があるという大きな仮定をすでに立ててきましたが、さらに一歩進んで、インデックス名とフィールド名がどの程度の意味を持ち、互いにどのように関連しているかを仮定する必要があります。そうしないと、最上位の結果として最適な一致を確実に特定することはできないかもしれませんが、最上位 N 個の結果のどこかに最上位の一致があると言える可能性が高くなります。意味情報をそれが存在するコンテキスト内で消費し、意味的に異なる方法で自身を表現する別のエンティティと比較し、それらを判断できるものが必要です。LLM のようなものです。
仮説6: 候補セットの削減
他にも簡単に触れる実験はいくつかありましたが、重要な突破口となったのは、純粋にセマンティック検索から最適な一致を選択したいという欲求を捨て、代わりにセマンティック検索をフィルターとして活用して、LLM の検討対象から無関係なインデックスを除外したことです。検索では、リニア リトリーバー、RRF を使用したハイブリッド検索、 semantic_textを組み合わせて、一致する上位 5 つのインデックスに結果を制限しました。
次に、一致ごとに、インデックスの名前、説明、フィールド名を LLM のメッセージに追加しました。結果は素晴らしかったです。
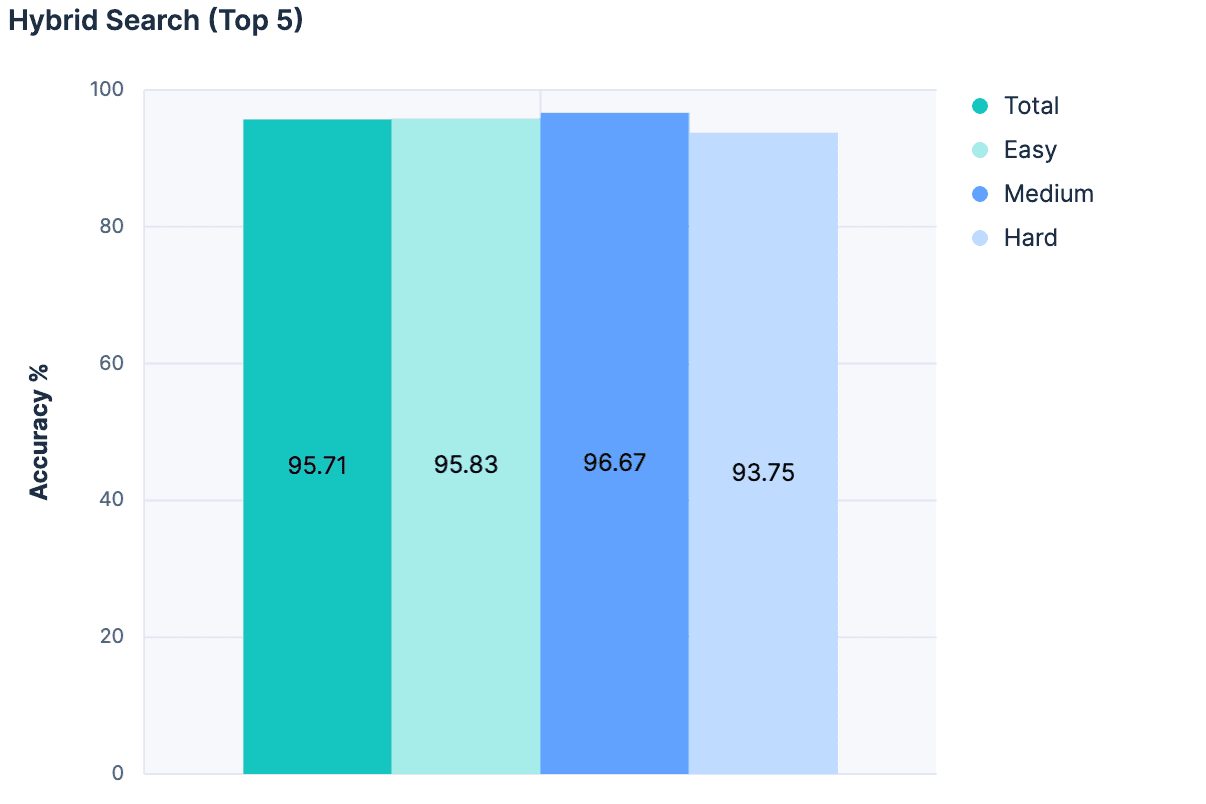
これまでのどの実験よりも最高の精度です!また、このアプローチではインデックスの合計数に比例してメッセージ サイズが増加しないため、このアプローチははるかにスケーラブルです。
成果
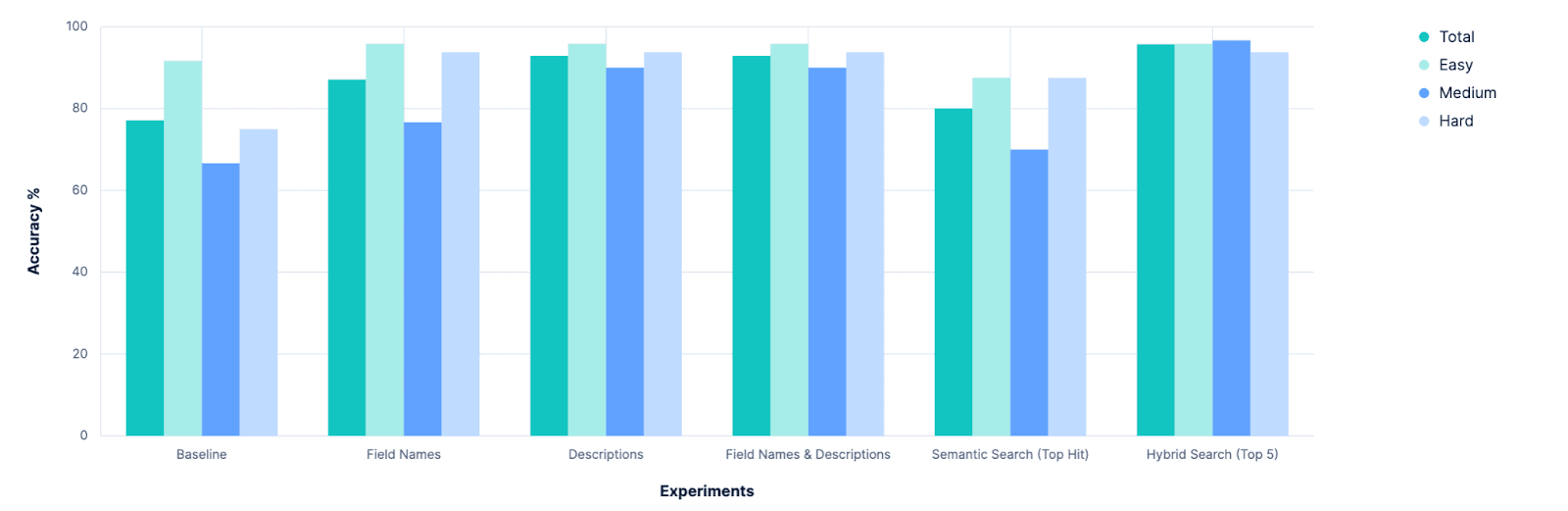
最初の明らかな結果は、ベースラインを改善できるということでした。振り返ってみるとこれは明らかなようですが、実験が始まる前に、 index_explorerツールを完全に放棄して、ユーザーからの明示的な構成に依存して検索空間を制限すべきかどうかについて真剣な議論がありました。これはまだ実行可能かつ有効なオプションですが、この調査では、そのようなユーザー入力が利用できない場合にインデックス選択を自動化するための有望な道筋があることが示されています。
次の明らかな結果は、問題に対して説明文字をさらに追加するだけでは、効果は減少するということです。この調査を行う前、Elasticsearch のフィールドレベルのメタデータ保存機能を拡張することに投資すべきかどうかについて議論していました。現在、これらのmeta値は 50 文字に制限されており、フィールドの意味を理解できるようにするにはこの値を増やす必要があると想定されていました。これは明らかに事実ではなく、LLM はフィールド名だけでかなりうまく機能しているようです。これについては後でさらに調査するかもしれませんが、もはや緊急の問題ではないように思われます。
逆に言えば、これは「検索可能な」インデックス メタデータを持つことの重要性を明確に示しています。これらの実験のために、インデックスのインデックスをハッキングしました。しかし、これを Elasticsearch に直接組み込むか、管理するための API を構築するか、少なくとも規則を確立することを調査することはできます。私たちは選択肢を検討し、社内で議論する予定ですので、お楽しみに。
最後に、この取り組みにより、時間をかけて実験し、データに基づいた意思決定を行うことの価値が確認されました。実際、これにより、Agent Builder 製品には強力な製品内評価機能が必要になることが再確認されました。インデックスを選択するツール専用のテスト ハーネス全体を構築する必要がある場合、お客様は反復的な調整を行う際にカスタム ツールを定性的に評価する方法が絶対に必要になります。
私たちが何を構築するのか楽しみにしています。皆さんも楽しみにしていただければ幸いです。
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

2026年3月26日
Kibanaのダッシュボードに読み取り専用権限を追加
Kibanaに読み取り専用のダッシュボードを導入し、ダッシュボード作成者に詳細な共有制御を提供して、結果の正確性を保ち、不要な変更から保護します。