Desde la búsqueda vectorial hasta las potentes API REST, Elasticsearch ofrece a los desarrolladores el conjunto de herramientas de búsqueda más completo. Explora nuestros cuadernos de muestra en el repositorio de Elasticsearch Labs para probar algo nuevo. También puedes iniciar tu prueba gratuita o ejecutar Elasticsearch localmente hoy mismo.
TLDR: Elasticsearch es hasta 12 veces más rápido - En Elastic hemos recibido numerosas solicitudes de nuestra comunidad para aclarar las diferencias de rendimiento entre Elasticsearch y OpenSearch, particularmente en el realm de la búsqueda semántica/búsqueda vectorial, por lo que hemos efectuado esta prueba de rendimiento para proporcionar una comparación clara y basada en datos: sin ambigüedades, solo datos directos para informar a nuestros usuarios. Los resultados muestran que Elasticsearch es hasta 12 veces más rápido que OpenSearch para la búsqueda de vectores y, por lo tanto, requiere menos recursos computacionales. Esto refleja el enfoque de Elastic en consolidar Lucene como la mejor base de datos vectorial para casos de uso de búsqueda y recuperación.
La búsqueda vectorial está revolucionando la forma en que hacemos búsquedas de similitud, particularmente en campos como la IA y el machine learning. Con la creciente adopción de modelos de incrustación de vectores, la capacidad de búsqueda eficiente a través de millones de vectores de alta dimensionalidad se vuelve crítica.
Cuando se trata de habilitar bases de datos vectoriales, Elastic y OpenSearch han adoptado enfoques notablemente diferentes. Elastic ha invertido mucho en la optimización de Apache Lucene junto con Elasticsearch para elevarlos como la opción de primer nivel para las aplicaciones de búsqueda vectorial. Por el contrario, OpenSearch ha ampliado su enfoque, integrando otras implementaciones de búsqueda vectorial y explorando más allá del alcance de Lucene. Nuestro enfoque en Lucene es estratégico, lo que nos permite brindar soporte sumamente integrado en nuestra versión de Elasticsearch, resultando en un conjunto de características mejorado en el que cada componente complementa y amplifica las capacidades del otro.
Este blog presenta una comparación detallada entre Elasticsearch 8.14 y OpenSearch 2.14, considerando diferentes configuraciones y motores vectoriales. En este análisis de rendimiento, Elasticsearch demostró ser la plataforma superior para las operaciones de búsqueda de vectores. Incluso las próximas características ampliarán las diferencias de forma más significativa. Cuando se enfrentó a OpenSearch, sobresalió en todas las pistas de referencia, con un rendimiento de 2 a 12 veces más rápido en promedio. Esto sucedió en todos los casos que utilizaban cantidades y dimensiones vectoriales variables, como so_vector (2M vectores, 768D), openai_vector (2.5M vectores, 1536D) y dense_vector (10M vectores, 96D), todos disponibles en este repositorio junto con los scripts de Terraform para provisionar toda la infraestructura requerida en Google Cloud y los manifiestos de Kubernetes para ejecutar las pruebas.
Los resultados detallados en este blog complementan los resultados de un estudio previamente publicado y validado por terceros que muestra que Elasticsearch es 40%–140% más rápido que OpenSearch para las operaciones de análisis de búsqueda más comunes: consulta de texto, clasificación, rango, histograma de fechas y filtrado de términos. Ahora podemos agregar otro diferenciador: la búsqueda vectorial.
Hasta 12 veces más rápido desde el primer momento
Nuestros puntos de referencia enfocados en los cuatro conjuntos de datos vectoriales involucraron tanto búsquedas de KNN aproximados como de KNN exactos, considerando diferentes tamaños, dimensiones y configuraciones, totalizando 40.189.820 solicitudes de búsqueda no almacenadas en caché. Los resultados: Elasticsearch es hasta 12 veces más rápido que OpenSearch para la búsqueda vectorial y, por lo tanto, requiere menos recursos computacionales.

Figura 1: Tareas agrupadas para ANN y KNN exacto en diferentes combinaciones en Elasticsearch y OpenSearch.
Los grupos como knn-10-100 implican una búsqueda KNN con y . En la búsqueda vectorial HNSW, determina el número de vecinos más cercanos a recuperar para un vector de consulta. Especifica cuántos vectores similares se deben encontrar como resultado. establece el número de vectores candidatos a recuperar en cada segmento. Más candidatos pueden mejorar la precisión, pero requieren mayores recursos computacionales.
También probamos con diferentes técnicas de cuantización y aprovechamos las optimizaciones específicas del motor; los resultados detallados para cada pista, tarea y motor vectorial están disponibles a continuación.
KNN exacto y KNN aproximado
Al tratar con conjuntos de datos y casos de uso variados, el enfoque correcto para la búsqueda vectorial será diferente. En este blog, todas las tareas indicadas como knn-* como knn-10-100 utilizan KNN aproximado y script-score-* se refieren a KNN exacto, pero ¿en qué se diferencian y por qué son importantes?
En definitiva, si estás manejando conjuntos de datos más sustanciales, el método preferido es Approximate K-Nearest Neighbor (ANN) debido a su escalabilidad superior. Para conjuntos de datos más modestos que pueden requerir un proceso de filtración, el método Exact KNN es ideal.
El KNN exacto utiliza un método de fuerza bruta, calculando la distancia entre un vector y todos los demás vectores en el conjunto de datos. Luego clasifica estas distancias para encontrar los vecinos más cercanos. Si bien este método garantiza una coincidencia exacta, enfrenta desafíos de escalabilidad para conjuntos de datos grandes y de alta dimensionalidad. Sin embargo, hay muchos casos en los que se necesita un KNN exacto:
- Recalificación: En escenarios que involucran búsquedas léxicas o semánticas seguidas de recalificación basada en vectores, el KNN exacto es esencial. Por ejemplo, en un motor de búsqueda de productos, los resultados de búsqueda iniciales se pueden filtrar en función de consultas textuales (por ejemplo, palabras clave, categorías) y luego se emplean vectores asociados con los elementos filtrados para una evaluación de similitud más precisa.
- Personalización: Al tratar con un gran número de usuarios, cada uno representado por un número relativamente pequeño (como 1 millón) de vectores distintos, la clasificación del índice por metadatos específicos del usuario (por ejemplo, user_id) y el cálculo de puntajes mediante fuerza bruta con vectores se vuelve eficiente. Este enfoque permite recomendaciones personalizadas o la entrega de contenido basadas en comparaciones vectoriales precisas adaptadas a las preferencias individuales del usuario.
Por lo tanto, Exact KNN garantiza que la clasificación final y las recomendaciones basadas en la similitud de vectores sean precisas y estén adaptadas a las preferencias del usuario.
Por otro lado, el KNN aproximado (o ANN) emplea métodos para que la búsqueda de datos sea más rápida y eficaz que el KNN exacto, especialmente en conjuntos de datos grandes y de alta dimensionalidad. En lugar de un enfoque de fuerza bruta, que mide la distancia más cercana exacta entre una consulta y todos los puntos, lo que plantea problemas de cálculo y escalado, el ANN emplea ciertas técnicas para reestructurar de forma eficiente los índices y las dimensiones de los vectores buscables en el conjunto de datos. Aunque esto puede provocar una ligera imprecisión, aumenta considerablemente la velocidad del proceso de búsqueda, lo que lo convierte en una alternativa eficaz para tratar con grandes conjuntos de datos.
En este blog, todas las tareas indicadas como knn-* como knn-10-100 usan KNN aproximado y script-score-* se refieren a KNN exacto.
Metodología de prueba
Si bien Elasticsearch y OpenSearch son similares en términos de API para las operaciones de búsqueda BM25, ya que este último es una bifurcación del primero, no ocurre lo mismo con la búsqueda vectorial, que se introdujo después de la bifurcación. OpenSearch adoptó un enfoque diferente al de Elasticsearch en lo que respecta a los algoritmos, al introducir otros dos motores — nmslib y faiss — además de lucene, cada uno con sus configuraciones y limitaciones específicas (por ejemplo, nmslib en OpenSearch no permite filtros, una característica esencial para muchos casos de uso).
Los tres motores utilizan el algoritmo Hierarchical Navigable Small World (HNSW), que es eficiente para la búsqueda aproximada de vecinos más cercanos y especialmente potente al trabajar con datos de alta dimensionalidad. Es importante señalar que faiss también admite un segundo algoritmo, ivf, pero dado que requiere entrenamiento previo en el conjunto de datos, nos centraremos únicamente en HNSW. La idea núcleo de HNSW es organizar los datos en varias capas de grafos conectados, donde cada capa representa una granularidad diferente del conjunto de datos. La búsqueda comienza en la capa superior con la vista más burda y progresa hacia capas cada vez más finas hasta llegar al nivel base.
Ambos motores de búsqueda se probaron en condiciones idénticas en un entorno controlado para asegurar la imparcialidad. El método aplicado es similar a esta comparación de rendimiento publicada anteriormente, con grupos de nodo dedicados para Elasticsearch, OpenSearch y Rally. El script de terraform está disponible (junto con todas las fuentes) para provisionar un clúster de Kubernetes con:
- 1 grupo de nodo para Elasticsearch con 3
e2-standard-32máquinas (128 GB de RAM y 32 CPU) - Grupo de 1 Node para OpenSearch con 3 máquinas
e2-standard-32(128 GB de RAM y 32 CPU) - Grupo de 1 Node para Rally con 2 máquinas
t2a-standard-16(64 GB de RAM y 16 CPU)
Cada "pista" (o prueba) se ejecutó 10 veces para cada configuración, que incluyó diferentes motores, diferentes configuraciones y diferentes tipos de vectores. Las pistas tienen tareas que se repiten entre 1000 y 10 000 veces, dependiendo de la pista. Si una de las tareas de una pista fallaba, por ejemplo, debido a un tiempo de espera de red, todas las tareas se descartaban, por lo que todos los resultados representan pistas que comenzaron y terminaron sin problemas. Todos los resultados de las pruebas se validan estadísticamente, lo que garantiza que las mejoras no sean una coincidencia.
Resultados detallados
¿Por qué comparar usando el percentil 99 y no el promedio de latencia? Consideremos un ejemplo hipotético de los precios promedio de las viviendas en un barrio determinado. El precio promedio puede indicar una zona cara, pero en una inspección más cercana, puede resultar que la mayoría de las viviendas estén valoradas mucho más bajo, con solo unas pocas propiedades de lujo inflando la cifra promedio. Esto ilustra cómo el precio promedio puede no representar con precisión el espectro completo de valores de las viviendas en esa zona. Esto es similar a examinar los tiempos de respuesta, en los que el promedio puede ocultar problemas críticos.
Tareas
- KNN aproximado con k:10 n:50
- KNN aproximado con k:10 n:100
- KNN aproximado con k:100 n:1000
- KNN aproximado con k:10 n:50 y filtros de palabras clave
- KNN aproximado con k:10 n:100 y filtros de palabras clave
- KNN aproximado con k:100 n:1000 y filtros de palabras clave
- KNN aproximado con k:10 n:100 en combinación con indexación
- KNN exacto (puntaje del script)
Motores vectoriales
luceneen Elasticsearch y OpenSearch, ambos en la versión 9.10faissen OpenSearchnmsliben OpenSearch
Tipos de vectores
hnswen Elasticsearch y OpenSearchint8_hnswen Elasticsearch (HNSW con cuantificación automática de 8 bits: enlace)sq_fp16 hnswen OpenSearch (HNSW con cuantificación automática de 16 bits: enlace)
Búsqueda de segmentos concurrentes y lista para usar
Como probablemente sabes, Lucene es una biblioteca de motor de búsqueda de texto de alto rendimiento escrita en Java que sirve como estructura para muchas plataformas de búsqueda como Elasticsearch, OpenSearch y Solr. Básicamente, Lucene organiza los datos en segmentos, que son esencialmente índices autónomos que permiten a Lucene ejecutar búsquedas de manera más eficiente. Entonces, cuando emites una búsqueda a cualquier motor de búsqueda basado en Lucene, tu búsqueda terminará siendo ejecutada en esos segmentos, ya sea secuencialmente o en paralelo.
OpenSearch introdujo la búsqueda de segmentos concurrentes como una opción adicional y no la utiliza por defecto; debes habilitarla mediante una configuración especial del índice index.search.concurrent_segment_search.enabled como se detalla aquí, con algunas limitaciones.
Elasticsearch, por otro lado, hace búsquedas en segmentos de forma concurrente listas para usar, por lo que las comparaciones que hacemos en este blog tendrán en cuenta, además de los diferentes motores de vectores y tipos de vectores, también las diferentes configuraciones:
- Elasticsearch ootb: Elasticsearch listo para usar, con búsqueda concurrente por segmentos;
- OpenSearch ootb: sin búsqueda concurrente de segmentos habilitada;
- OpenSearch css: con búsqueda concurrente de segmentos habilitada
Comencemos con algunos resultados detallados para cada conjunto de datos vectoriales probado:
2,5 millones de vectores, 1536 dimensiones (openai_vector)
Comenzando con la ruta más simple, pero también la más grande en términos de dimensiones, openai_vector, que utiliza el conjunto de datos NQ enriquecido con incrustaciones generadas usando el modelo text-embedding-ada-002 de OpenAI. Es el más simple ya que solo prueba KNN aproximado y tiene solo 5 tareas. Se prueba de forma independiente (sin indexar) así como junto con la indexación, y utilizando un solo cliente y 8 clientes simultáneos.
Tareas
- standalone-search-knn-10-100-multiple-clients: búsqueda en 2,5 millones de vectores con 8 clientes simultáneamente, k: 10 y n:100
- standalone-search-knn-100-1000-multiple-clients: búsqueda en 2,5 millones de vectores con 8 clientes simultáneamente, k: 100 y n:1000
- standalone-search-knn-10-100-single-client: búsqueda en 2,5 millones de vectores con un solo cliente, k: 10 y n:100
- standalone-search-knn-100-1000-single-client: búsqueda en 2,5 millones de vectores con un solo cliente, k: 100 y n: 1000
- parallel-documents-indexing-search-knn-10-100: búsqueda en 2.5 millones de vectores mientras se indexan 100 000 documentos adicionales, k:10 y n:100
El rendimiento promedio del p99 se describe a continuación:

Aquí observamos que Elasticsearch es de 3x a 8x más rápido que OpenSearch al realizar la búsqueda vectorial junto con la indexación (por ej. lectura+escritura) con :10 y :100 y de 2x a 3x más rápido sin indexar para los mismos k y n. Para :100 y :1000 (standalone-search-knn-100-1000-single-client y standalone-search-knn-100-1000-multiple-clients Elasticsearch es de 2x a 7x más rápido que OpenSearch, en promedio.
Los resultados detallados muestran los casos exactos y los motores vectoriales comparados:
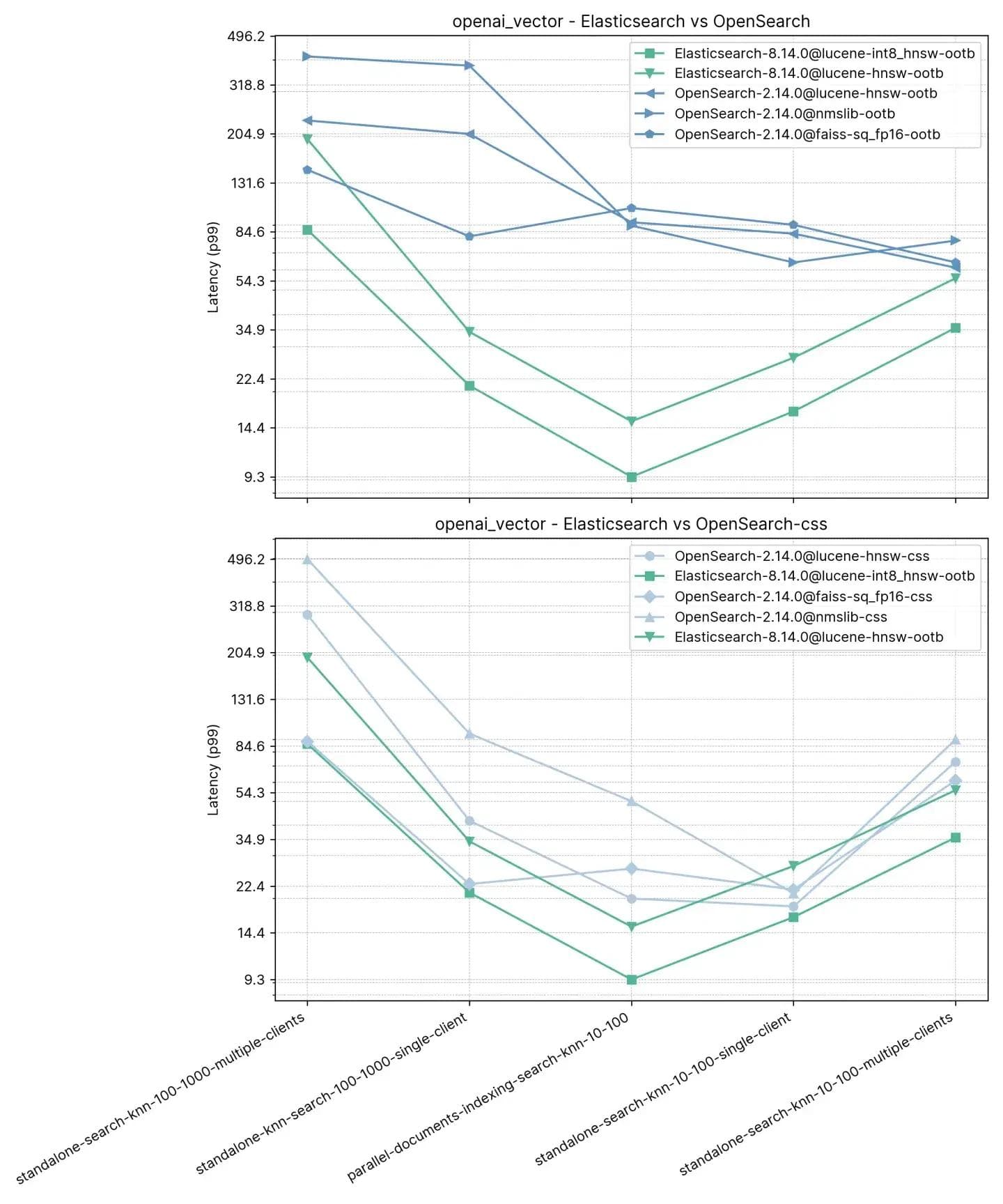
Recall
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0.969485 | 0.995138 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0.781445 | 0.784817 |
| OpenSearch-2.14.0@lucene-hnsw | 0.96519 | 0.995422 |
| OpenSearch-2.14.0@faiss | 0.984154 | 0.98049 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0.980012 | 0.97721 |
| OpenSearch-2.14.0@nmslib | 0.982532 | 0.99832 |
10 millones de vectores, 96 dimensiones (dense_vector)
En dense_vector con 10M vectores y 96 dimensiones. Se basa en el conjunto de datos de imágenes Yandex DEEP1B. El conjunto de datos se crea a partir de los primeros 10 millones de vectores del archivo "sample data" llamado learn.350M.fbin. Las operaciones de búsqueda utilizan vectores de la búsqueda de archivos "query data".public.10K.fbin.
Tanto Elasticsearch como OpenSearch funcionan muy bien en este conjunto de datos, especialmente después de un force merge, que generalmente se realiza en índices de solo lectura y es similar a desfragmentar el índice para tener una sola "tabla" en la que realizar la búsqueda.
Tareas
Cada tarea se prepara para 100 solicitudes y luego se miden 1000 solicitudes
- knn-search-10-100: búsqueda en 10 millones de vectores, k: 10 y n:100
- knn-search-100-1000: búsqueda en 10 millones de vectores, k: 100 y n: 1000
- knn-search-10-100-force-merge: búsqueda en 10 millones de vectores después de una fusión forzada, k: 10 y n:100
- knn-search-100-1000-force-merge: búsqueda en 10 millones de vectores después de una fusión forzada, k: 100 y n:1000
- knn-search-100-1000-concurrent-with-indexing: búsqueda en 10 millones de vectores mientras también se actualiza el 5 % del conjunto de datos, k: 100 y n: 1000
- script-score-query: búsqueda KNN exacta de 2000 vectores específicos.
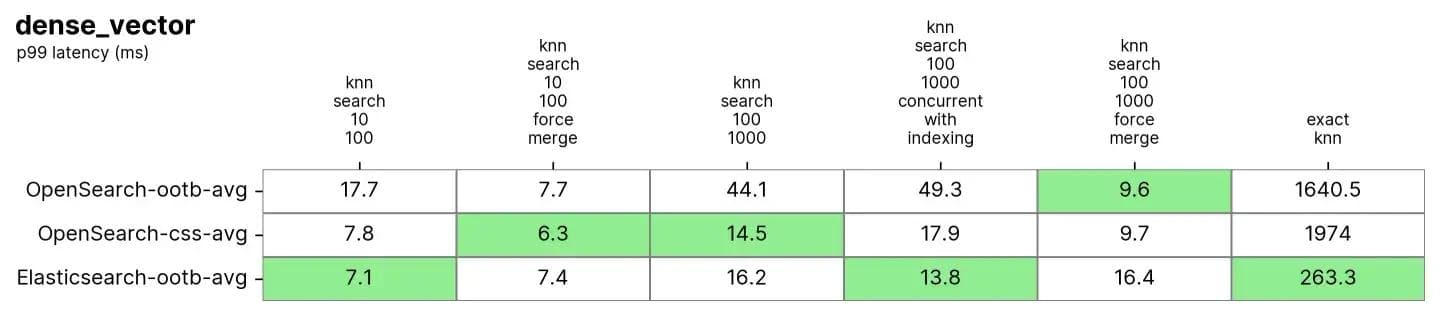
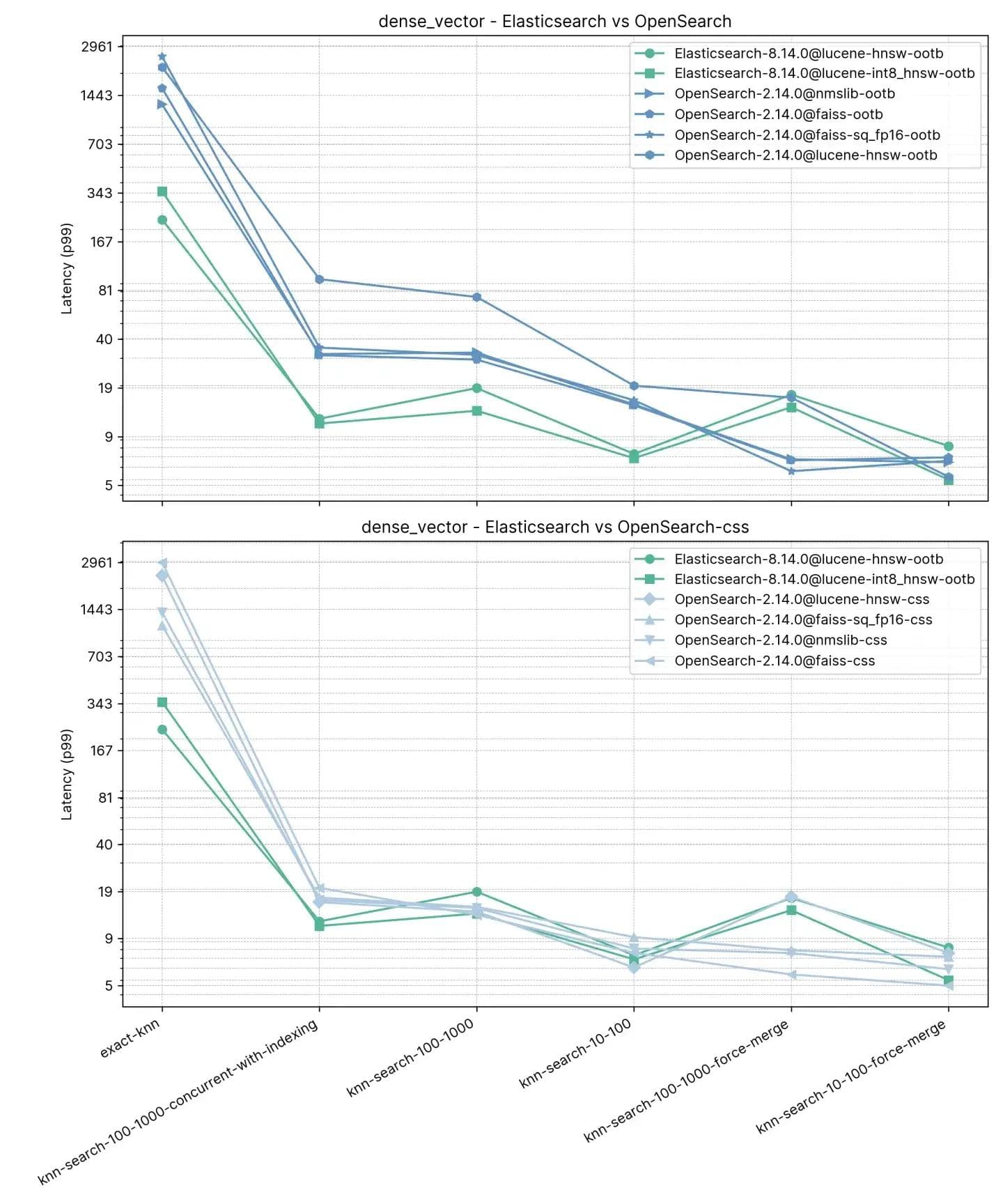
Tanto Elasticsearch como OpenSearch tuvieron un buen desempeño para el KNN aproximado. Cuando el índice se fusiona (es decir, tiene un solo segmento) en knn-search-100-1000-force-merge y knn-search-10-100-force-merge, OpenSearch funciona mejor que los demás cuando se usan nmslib y faiss, aunque todos estén alrededor de 15 ms y todos muy cerca.
Sin embargo, cuando el índice tiene varios segmentos (una situación típica en la que un índice recibe actualizaciones de sus documentos) en knn-search-10-100 y knn-search-100-1000, Elasticsearch mantiene la latencia en aproximadamente ~7 ms y ~16 ms, mientras que todos los demás motores de OpenSearch son más lentos.
También cuando se busca en el índice y se indexa en él al mismo tiempo (knn-search-100-1000-concurrent-with-indexing), Elasticsearch mantiene la latencia por debajo de 15 ms (a 13.8 ms), siendo casi 4x más rápido que OpenSearch out-of-the-box (49.3 ms) y aún más rápido cuando se habilita la búsqueda concurrente por segmentos (17.9 ms), pero demasiado cerca para ser significativo.
En cuanto al KNN exacto, la diferencia es mucho mayor: Elasticsearch es 6 veces más rápido que OpenSearch (~260 ms vs ~1600 ms).
Recall
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0.969843 | 0.996577 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0.775458 | 0.840254 |
| OpenSearch-2.14.0@lucene-hnsw | 0.971333 | 0.996747 |
| OpenSearch-2.14.0@faiss | 0.9704 | 0.914755 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0.968025 | 0.913862 |
| OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 |
2 millones de vectores, 768 dimensiones (so_vector)
Esta pista, so_vector, se deriva de un volcado de publicaciones de StackOverflow descargadas el 21 de abril de 2022. Solo contiene documentos de preguntas; se eliminaron todos los documentos que representan respuestas. Cada título de pregunta se codificó en un vector usando el modelo de transformador de oraciones multi-qa-mpnet-base-cos-v1. Este conjunto de datos contiene los primeros 2 millones de preguntas.
A diferencia de la pista anterior, cada documento aquí contiene otros campos además de vectores para soportar características de prueba como KNN aproximado con filtrado y búsqueda híbrida. nmslib para OpenSearch está notablemente ausente en esta prueba ya que no admite filtros.
Tareas
Cada tarea se calienta con 100 solicitudes y luego se miden 100 solicitudes. Tenga en cuenta que las tareas se agruparon por simplicidad, ya que la prueba contiene 16 tipos de búsqueda * 2 valores k diferentes * 3 valores n diferentes.
- knn-10-50: búsqueda en 2 millones de vectores sin filtros, k:10 y n:50
- knn-10-50-filtered: búsqueda en 2 millones de vectores con filtros, k:10 y n:50
- knn-10-50-after-force-merge: búsqueda en 2 millones de vectores con filtros y después de una fusión forzosa, k:10 y n:50
- knn-10-100: búsqueda en 2 millones de vectores sin filtros, k:10 y n:100
- knn-10-100-filtered: búsqueda en 2 millones de vectores con filtros, k:10 y n:100
- knn-10-100-after-force-merge: búsqueda en 2 millones de vectores con filtros y luego de una fusión forzada, k: 10 y n: 100
- knn-100-1000: búsqueda en 2 millones de vectores sin filtros, k:100 y n:1000
- knn-100-1000-filtered: búsqueda en 2 millones de vectores con filtros, k:100 y n:1000
- knn-100-1000-after-force-merge: búsqueda en 2 millones de vectores con filtros y luego de una fusión forzada, k:100 y n:1000
- exact-knn: búsqueda de KNN exacto con y sin filtros.

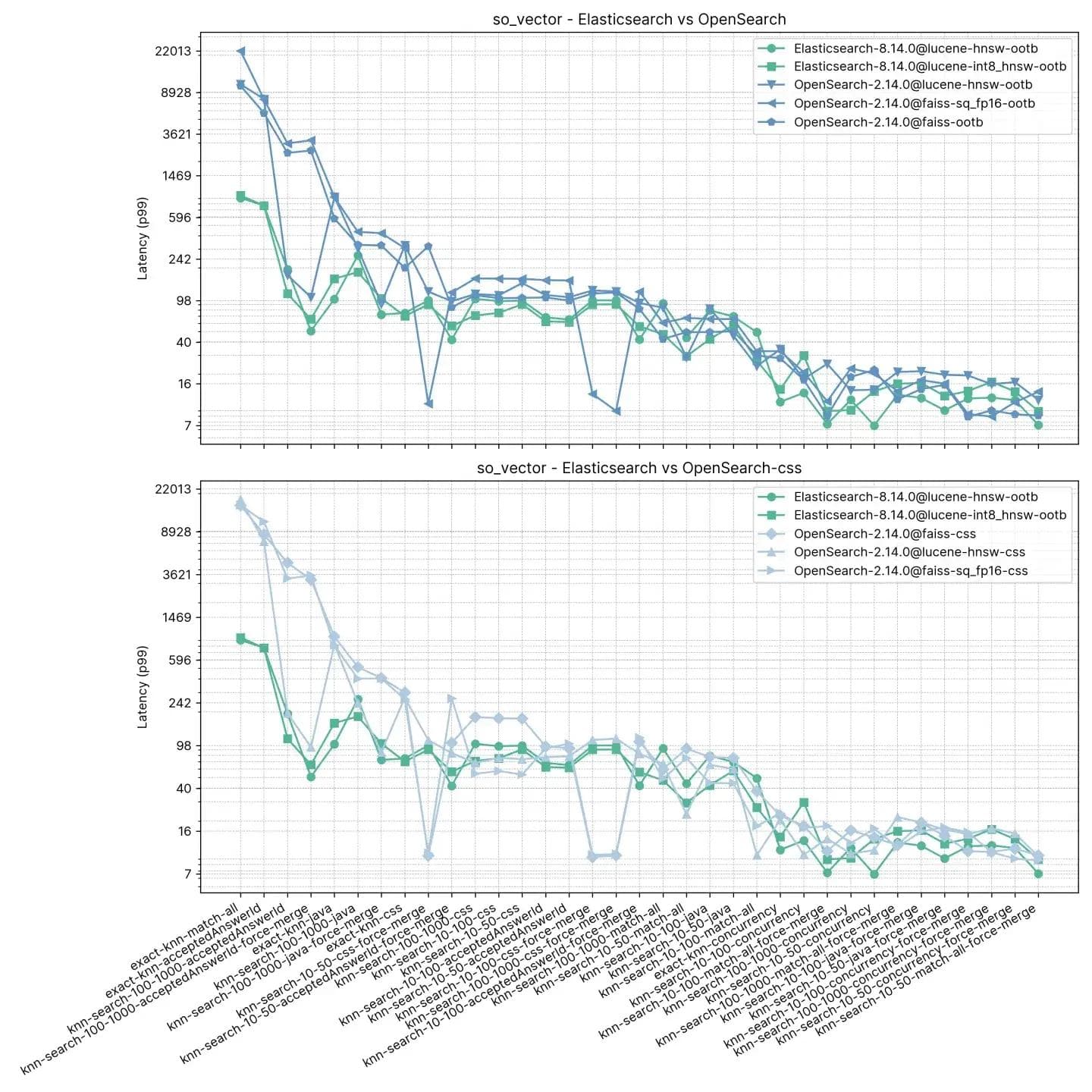
Elasticsearch es consistentemente más rápido que OpenSearch de manera inmediata en esta prueba, solo en dos casos OpenSearch es más rápido, y no por mucho (knn-10-100 y knn-100-1000). Las tareas que involucran knn-10-50, knn-10-100 y knn-100-1000 en combinación con filtros muestran una diferencia de hasta 7 veces (112 ms versus 803 ms).
El rendimiento de ambas soluciones parece igualarse después de un "force merge" (fusión forzada), lógicamente, como lo demuestran knn-10-50-after-force-merge, knn-10-100-after-force-merge y knn-100-1000-after-force-merge. En esas tareas, faiss es más rápido.
Como mencionamos, el rendimiento para Exact KNN es muy diferente, ya que Elasticsearch fue 13 veces más rápido que OpenSearch esta vez (~385 ms vs ~5262 ms).
Recall
| knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0.986667 | 1 |
| OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
| OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 | 0.976394 |
Elasticsearch y Lucene como claros vencedores
En Elastic, estamos innovando incansablemente Apache Lucene y Elasticsearch para garantizar que podamos proporcionar la base de datos vectorial de primer nivel para casos de uso de búsqueda y recuperación, incluido RAG (Retrieval Augmented Generation). Nuestros últimos avances han aumentado significativamente el rendimiento, haciendo que la búsqueda vectorial sea más rápida y eficiente en cuanto a espacio que antes, basándose en las mejoras de Lucene 9.10. En este blog, se presentó un estudio que muestra que al comparar versiones actualizadas, Elasticsearch es hasta 12 veces más rápido que OpenSearch.
Vale la pena señalar que ambos productos usan la misma versión de Lucene (Notas de lanzamiento de Elasticsearch 8.14 y Notas de lanzamiento de OpenSearch 2.14).
El ritmo de innovación en Elastic ofrecerá aún más, no solo para nuestros clientes locales y de Elastic Cloud, sino también para aquellos que utilizan nuestra plataforma sin estado. Las características como el soporte para la cuantificación escalar a int4 se ofrecerán con pruebas rigurosas para garantizar que los clientes puedan utilizar estas técnicas sin una caída significativa en la recuperación, similar a nuestras pruebas para int8.
La eficiencia de la búsqueda vectorial se está convirtiendo en una característica no negociable en los motores de búsqueda modernos debido a la proliferación de aplicaciones de inteligencia artificial y machine learning. Para las organizaciones que buscan un motor de búsqueda poderoso capaz de mantenerse al día con las demandas de datos vectoriales de alto volumen y alta complejidad, Elasticsearch es la respuesta definitiva.
Ya sea que quieres expandir una plataforma establecida o iniciar nuevos proyectos, integrar Elasticsearch para las necesidades de búsqueda vectorial es un movimiento estratégico que generará beneficios tangibles a largo plazo. Con su ventaja de rendimiento comprobada, Elasticsearch está a punto de apuntalar la próxima ola de innovaciones en búsqueda.
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.