A principios de este año, Elastic anunció la colaboración con NVIDIA para llevar la aceleración por GPU a Elasticsearch, integrándola con NVIDIA cuVS, como se detalló en una sesión en NVIDIA GTC y en varios blogs. Esta publicación es una actualización sobre el esfuerzo de co-ingeniería con el equipo de búsqueda de vectores de NVIDIA.
Resumen
Primero, pongámonos al día. Elasticsearch se consolidó como una poderosa base de datos vectorial, que ofrece un amplio conjunto de características y un sólido rendimiento para la búsqueda de similitudes a gran escala. Con capacidades como la cuantificación escalar, Better Binary Quantization (BBQ), operaciones vectoriales SIMD y algoritmos más eficientes en disco como DiskBBQ, ya ofrece opciones eficientes y flexibles para gestionar cargas de trabajo vectoriales.
Al integrar NVIDIA cuVS como un módulo invocable para tareas de búsqueda vectorial, nuestro objetivo es ofrecer beneficios significativos en el rendimiento y la eficiencia de la indexación vectorial para soportar mejor las cargas de trabajo vectoriales a gran escala.
El desafío
Uno de los mayores desafíos al construir una base de datos vectorial de alto rendimiento es construir el índice vectorial: el grafo HNSW. La construcción de índices se ve dominada con rapidez por millones o incluso miles de millones de operaciones aritméticas a medida que cada vector se compara con muchos otros. Además, las operaciones del ciclo de vida del índice, como la compactación y las fusiones, pueden aumentar aún más la sobrecarga total de cálculo de la indexación. A medida que los volúmenes de datos y las incrustaciones vectoriales asociadas crecen de manera exponencial, las GPU de cómputo acelerado, diseñadas para el paralelismo masivo y las matemáticas de alto rendimiento, se posicionan idealmente para manejar estas cargas de trabajo.
Ingresa al plugin Elasticsearch-GPU
NVIDIA cuVS es una biblioteca open source de CUDA-X para la búsqueda vectorial acelerada por GPU y la agrupación de datos, que permite una rápida construcción de índices y recuperación de incrustaciones para cargas de trabajo de AI y de sistemas de recomendación.
Elasticsearch utiliza cuVS a través de cuvs-java, una biblioteca open source desarrollada por la comunidad y que mantiene NVIDIA. La biblioteca cuvs-java es ligera, se basa en la API C de cuVS y usa la función externa del Proyecto Panamá para exponer las características de cuVS de una manera idiomática en Java, al tiempo que es moderna y presenta un alto rendimiento.
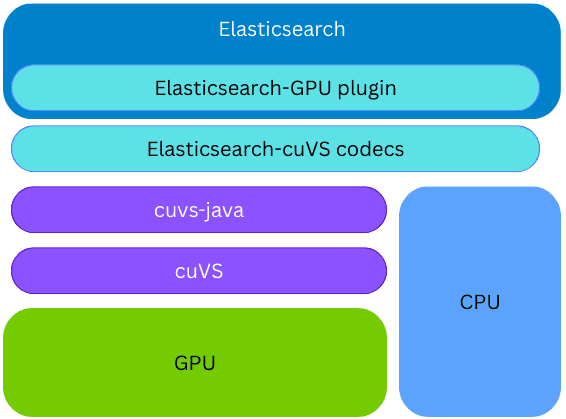
La biblioteca cuvs-java está integrada en un nuevo plugin de Elasticsearch; por lo tanto, la indexación vectorial en la GPU puede ocurrir en el mismo nodo y proceso de Elasticsearch, sin la necesidad de provisionar ningún código o hardware externo. Durante la construcción del índice, si se instala la biblioteca cuVS y hay una GPU presente y configurada, Elasticsearch usará la GPU para acelerar el proceso de indexación vectorial. Los vectores se asignan a la GPU, que construye un grafo CAGRA. Este grafo se convierte entonces al formato HNSW, y hace que esté disponible de inmediato para la búsqueda vectorial en la CPU. El formato final del grafo construido es el mismo que el que se construiría en la CPU; esto permite a Elasticsearch aprovechar las GPU para indexar vectores de alto rendimiento cuando el hardware subyacente lo admite, al tiempo que libera poder de la CPU para otras tareas (búsqueda simultánea, procesamiento de datos, etc.).
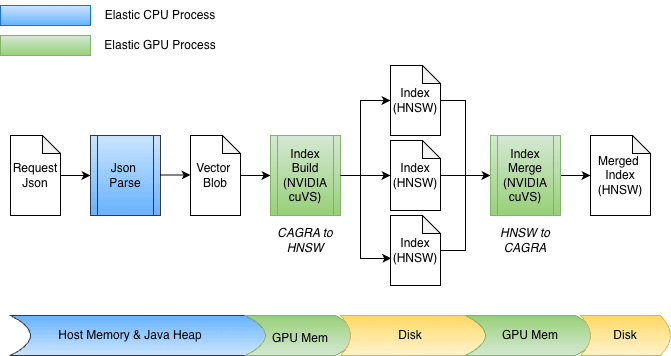
Aceleración en la generación de índices
Como parte de la integración de la aceleración de GPU en Elasticsearch, se realizaron varias mejoras en cuvs-java, centradas en la entrada/salida eficiente de datos y la invocación de funciones. Una mejora clave es el uso de cuVSMatrix para modelar vectores de forma transparente, ya sea que residan en la memoria heap de Java, fuera de la memoria heap o en la memoria de la GPU. Esto permite que los datos se muevan de manera eficiente entre la memoria y la GPU, lo que evita copias innecesarias de potencialmente miles de millones de vectores.
Gracias a esta abstracción subyacente de copia cero, tanto la transferencia a la memoria de la GPU como la recuperación del grafo se pueden realizar directamente. Durante la indexación, los vectores se almacenan primero en búfer en la memoria heap de Java, y luego se envían a la GPU para construir el grafo CAGRA. Después, el grafo se recupera de la GPU, se convierte al formato HNSW y se mantiene en el disco.
En el momento de la fusión, los vectores ya están almacenados en disco, sin pasar por la memoria heap de Java. Los archivos de índice se mapean en memoria, y los datos se transfieren directamente a la memoria de la GPU. El diseño también se adapta fácilmente a diferentes anchos de bits, como float32 o int8, y se extiende de forma natural a otros esquemas de cuantificación.
Redoble de tambores… entonces, ¿cómo se funciona?
Antes de entrar en los números, un poco de contexto es útil. La fusión de segmentos en Elasticsearch suele ejecutarse automáticamente en segundo plano durante la indexación, lo que dificulta hacer benchmarks de forma aislada. Para obtener resultados reproducibles, utilizamos la fusión forzosa para activar explícitamente la combinación de segmentos en un experimento controlado. Dado que la fusión forzosa hace las mismas operaciones de fusión subyacentes que la fusión en segundo plano, su rendimiento sirve como un indicador útil de las mejoras esperadas, aunque las ganancias exactas pueden diferir en las cargas de trabajo de indexación del mundo real.
Ahora, veamos los números.
Nuestros resultados iniciales de evaluaciones comparativas son muy prometedores. Ejecutamos la evaluación comparativa en una instancia de AWS g6.4xlarge con almacenamiento NVMe conectado a nivel local. Se configuró un único nodo de Elasticsearch para que use el número predeterminado y óptimo de subprocesos de indexación (8, uno por cada núcleo físico) y deshabilite la limitación de la fusión (que es menos aplicable con discos NVMe rápidos).
Para el conjunto de datos, utilizamos 2,6 millones de vectores con 1536 dimensiones del vector de pista de Rally de OpenAI, codificados como cadenas de texto base64 e indexados como float32 hnsw. En todos los escenarios, los grafos construidos alcanzan niveles de recuperación de hasta el 95 %. A continuación, presentamos nuestros hallazgos:
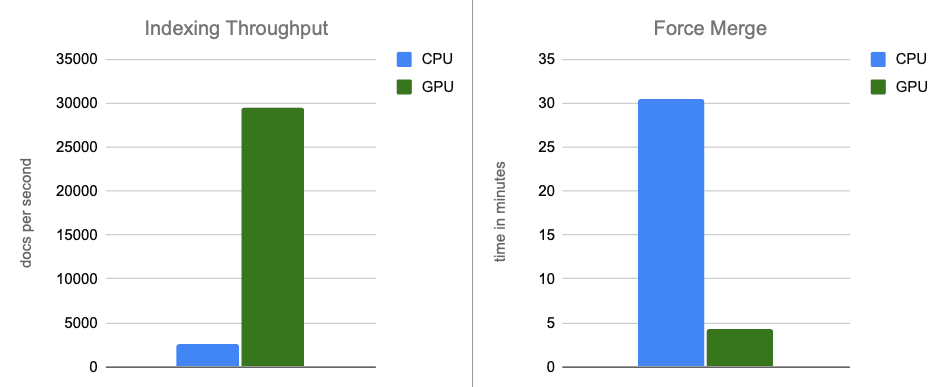
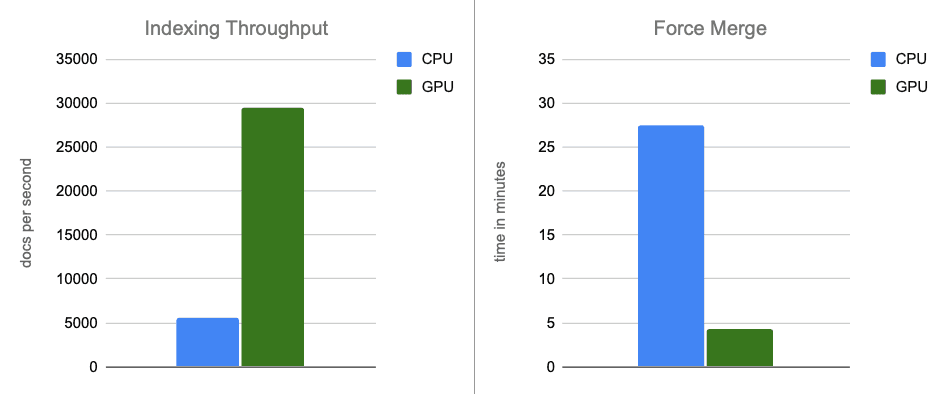
- Rendimiento de indexación: al trasladar la construcción de grafos a la GPU durante los vaciados de búferes en memoria, aumentamos el rendimiento en aproximadamente 12 veces.
- Fusión forzada: una vez que finaliza la indexación, la GPU continúa acelerando la fusión de segmentos, lo que acelera la fase de fusión forzada en alrededor de 7 veces.
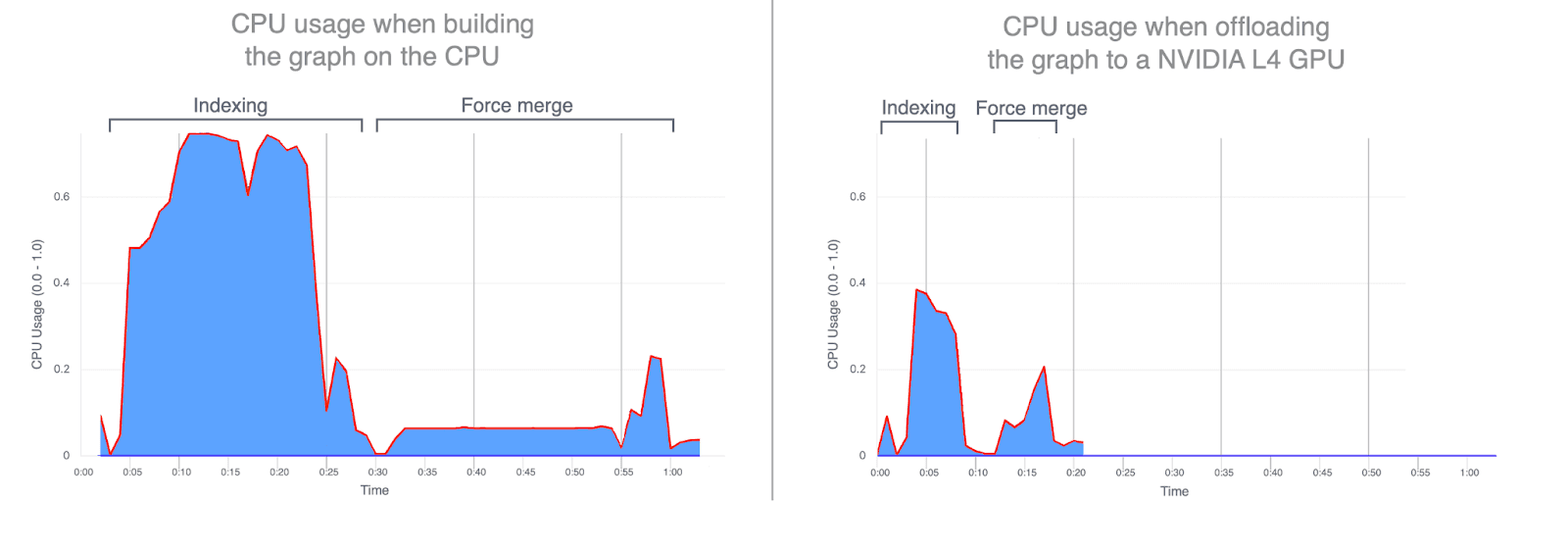
- Uso de la CPU: descargar la construcción de grafos a la GPU reduce de manera significativa el uso promedio y máximo de la CPU. Los grafos a continuación ilustran el uso de la CPU durante la indexación y la fusión, y permiten ver cuánto menor es cuando estas operaciones se ejecutan en la GPU. Un menor uso de la CPU durante la indexación por GPU libera ciclos de CPU que pueden redirigirse para mejorar el rendimiento de la búsqueda.
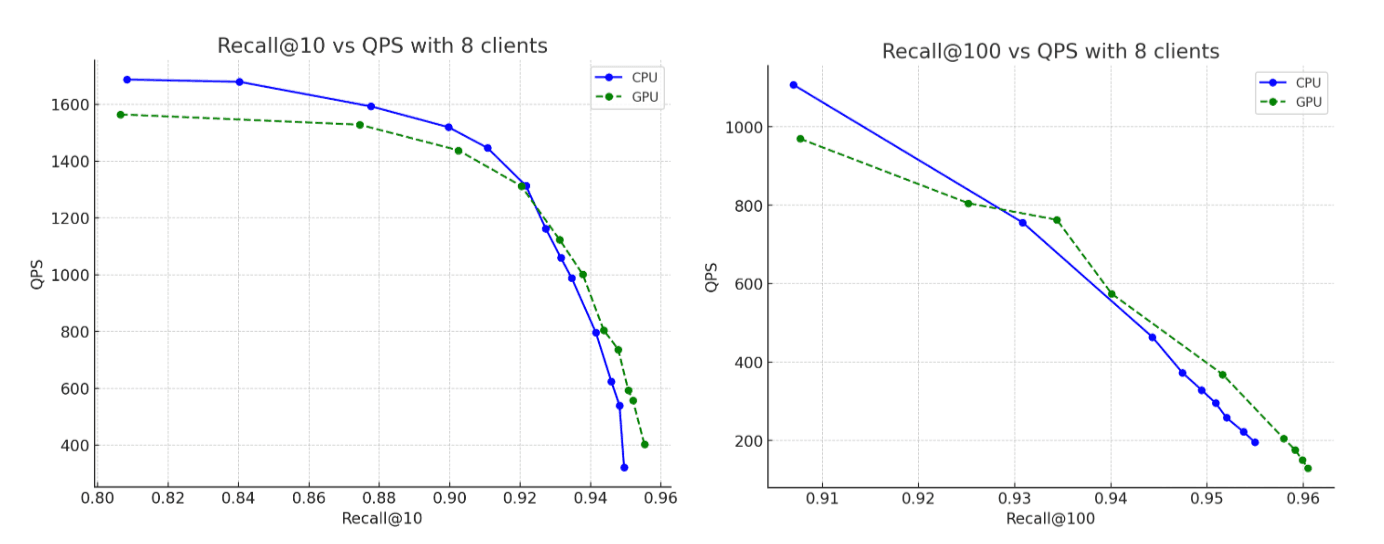
- Recuperación: la precisión se mantiene prácticamente igual entre las ejecuciones de CPU y GPU, y el grafo construido por la GPU alcanza una recuperación un poco mayor.
Comparación en otra dimensión: el precio
La comparación anterior utilizaba intencionalmente hardware idéntico, y la única diferencia era si se usaba la GPU durante la indexación o no. Esa configuración es útil para aislar los efectos de la computación en bruto, pero también podemos analizar la comparación desde una perspectiva de costos.
A un precio horario similar al de la configuración acelerada por GPU, se puede provisionar una configuración de solo CPU con aproximadamente el doble de recursos comparables de CPU y memoria: 32 vCPUs (AMD EPYC) y 64 GB de RAM, lo que permite duplicar el número de hilos de indexación a 16.
Para mantener la comparación justa y consistente, ejecutamos este experimento solo de CPU en una instancia AWS g6.8xlarge, con la GPU explícitamente desactivada. Esto nos permitió mantener constantes todas las demás características del hardware mientras evaluábamos la compensación entre costo y rendimiento de la aceleración de GPU frente al indexado solo con CPU.
Como era de esperar, la instancia de CPU más potente sí muestra un mejor rendimiento en comparación con las evaluaciones comparativas de la sección anterior. Sin embargo, cuando comparamos esta instancia de CPU más potente con los resultados acelerados por GPU originales, la GPU aún ofrece beneficios sustanciales en cuanto al rendimiento: ~ 5 veces de mejora en el rendimiento de indexación y ~ 6 veces en la fusión forzada, todo ello mientras se construyen grafos que alcanzan niveles de recuperación de hasta un 95 %.
Conclusión
En escenarios completos, la aceleración por GPU con NVIDIA cuVS ofrece una mejora de casi 12 veces en el rendimiento de la indexación y una disminución de 7 veces en la latencia de fusión forzada, con un uso de CPU significativamente menor. Esto demuestra que la indexación vectorial y las cargas de trabajo de fusión se benefician de manera significativa de la aceleración por GPU. En una comparación ajustada por costos, la aceleración por GPU continúa mostrando beneficios sustanciales en cuanto al rendimiento, con alrededor de 5 veces más rendimiento de indexación y 6 veces más rapidez en las operaciones de fusión forzada.
La indexación vectorial acelerada por GPU tiene planificada hoy en día una vista previa técnica en Elasticsearch 9.3, cuyo lanzamiento está programado para principios de 2026.
Mantente atento a lo que viene.
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.