Introducción
En un mundo de usuarios globales, la recuperación de información multilingüe (CLIR) es fundamental. En lugar de limitar las búsquedas a un solo idioma, CLIR te permite encontrar información en cualquier idioma, mejorando la experiencia del usuario y agilizando las operaciones. Imagina un mercado global donde los clientes de comercio electrónico puedan buscar artículos en su idioma, y los resultados adecuados aparezcan, sin necesidad de localizar los datos de antemano. O bien, donde los investigadores académicos pueden buscar artículos en su lengua materna, con matices y complejidad, incluso si la fuente está en otro idioma.
Los modelos de incrustación de texto multilingüe nos permiten hacer precisamente eso. Las incrustaciones son una forma de representar el significado del texto como vectores numéricos. Estos vectores están diseñados para que textos con significados similares estén situados cerca unos de otros en un espacio de alta dimensión. Los modelos de incrustación de texto multilingüe están diseñados específicamente para mapear palabras y frases con el mismo significado entre diferentes idiomas en un espacio vectorial similar.
Modelos como el Multilingüe E5 de código abierto se capacitan con enormes cantidades de datos textuales, a menudo empleando técnicas como el aprendizaje contrastivo. En este enfoque, el modelo aprende a distinguir entre pares de textos con significados similares (pares positivos) y aquellos con significados diferentes (pares negativos). El modelo se capacita para ajustar los vectores que produce de modo que se maximice la similitud entre pares positivos y se minimice la similitud entre pares negativos. Para modelos multilingües, estos datos de entrenamiento incluyen pares de texto en diferentes idiomas que son traducciones entre sí, permitiendo al modelo aprender un espacio de representación compartido para múltiples idiomas. Las incrustaciones resultantes pueden usar para diversas tareas de PLN, incluyendo la búsqueda cross-lingual, donde la similitud entre incrustaciones de texto se emplea para encontrar documentos relevantes independientemente del idioma de la consulta.
Beneficios de la búsqueda vectorial multilingüe
- Matiz: La búsqueda vectorial destaca en captar el significado semántico, yendo más allá de la simple búsqueda de palabras clave. Esto es crucial para tareas que requieren comprender el contexto y las sutilezas del lenguaje.
- Comprensión interlingüe: Permite una recuperación efectiva de información entre idiomas, incluso cuando la consulta y los documentos emplean vocabulario diferente.
- Relevancia: Ofrece resultados más relevantes centrar en la similitud conceptual entre consultas y documentos.
Por ejemplo, consideremos a un investigador académico que estudia el "impacto de las redes sociales en el discurso político" en diferentes países. Con la búsqueda vectorial, pueden introducir consultas como "l'impacto dei social media sul discorso politico" (italiano) o "ảnh hưởng của mạng xã hội đối với diễn ngôn chính trị" (vietnamita) y encontrar artículos relevantes en inglés, español o cualquier otro idioma indexado. Esto se debe a que la búsqueda vectorial identifica artículos que discuten el concepto de influencia de las redes sociales en la política, no solo aquellos que contienen las palabras clave exactas. Esto mejora enormemente la amplitud y profundidad de su investigación.
Primeros pasos
Así es como configurar CLIR usando Elasticsearch, con el modelo E5 que se proporciona de fábrica. Emplearemos el conjunto de datos multilingüe de código abierto COCO, que contiene pies de foto en varios idiomas, para ayudarnos a visualizar dos tipos de búsquedas:
- Consultas y términos de búsqueda en otros idiomas en un conjunto de datos en inglés, y
- Consultas en varios idiomas sobre un conjunto de datos que contiene documentos en varios idiomas.
Luego, aprovecharemos el poder de la búsqueda híbrida y el reposicionamiento para mejorar aún más los resultados de búsqueda.
Prerrequisitos
- Python 3.6+
- Elasticsearch 8+
- Cliente Python de Elasticsearch: instalación de pip elasticsearch
Conjunto de datos
El conjunto de datos COCO es un conjunto de datos de subtitulado a gran escala. Cada imagen del conjunto de datos está subtitulada en varios idiomas diferentes, con varias traducciones disponibles por idioma. Para fines demostrativos, indexaremos cada traducción como un documento individual, junto con la primera traducción al inglés disponible para referencia.
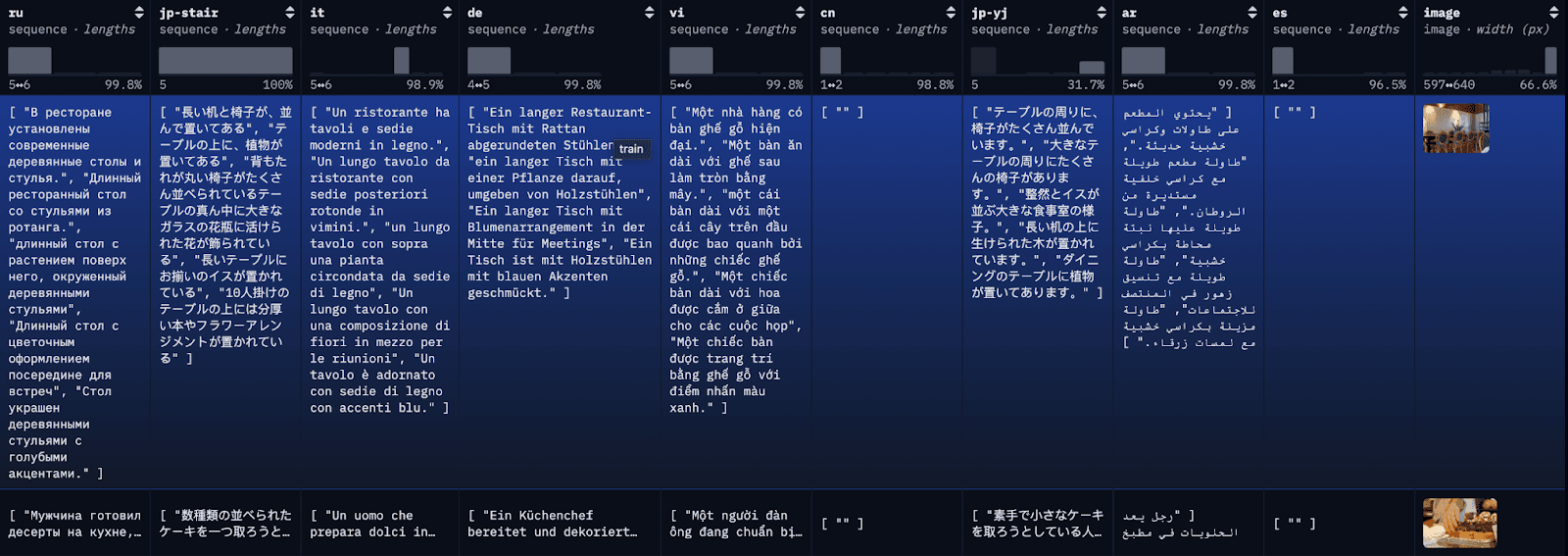
Paso 1: descargar el conjunto de datos multilingüe COCO
Para simplificar el blog y facilitar el seguimiento, aquí estamos cargando las primeras 100 filas de Restval en un archivo JSON local con una llamada API sencilla. Alternativamente, puedes usar los conjuntos de datos de la biblioteca de HuggingFace para cargar el conjunto de datos completo o subconjuntos del conjunto.
Si los datos se cargan correctamente en un archivo JSON, deberías ver algo similar a lo siguiente:
Data successfully downloaded and saved to multilingual_coco_sample.json
Paso 2: (Iniciar Elasticsearch) e indexar los datos en Elasticsearch
a) Inicia tu servidor local de Elasticsearch.
b) Iniciar el cliente Elasticsearch.
c) Datos de índice
Una vez indexados los datos, deberías ver algo similar a lo siguiente:
Successfully bulk indexed 4840 documents
Indexing complete!
Paso 3: Desplegar el modelo capacitado con E5
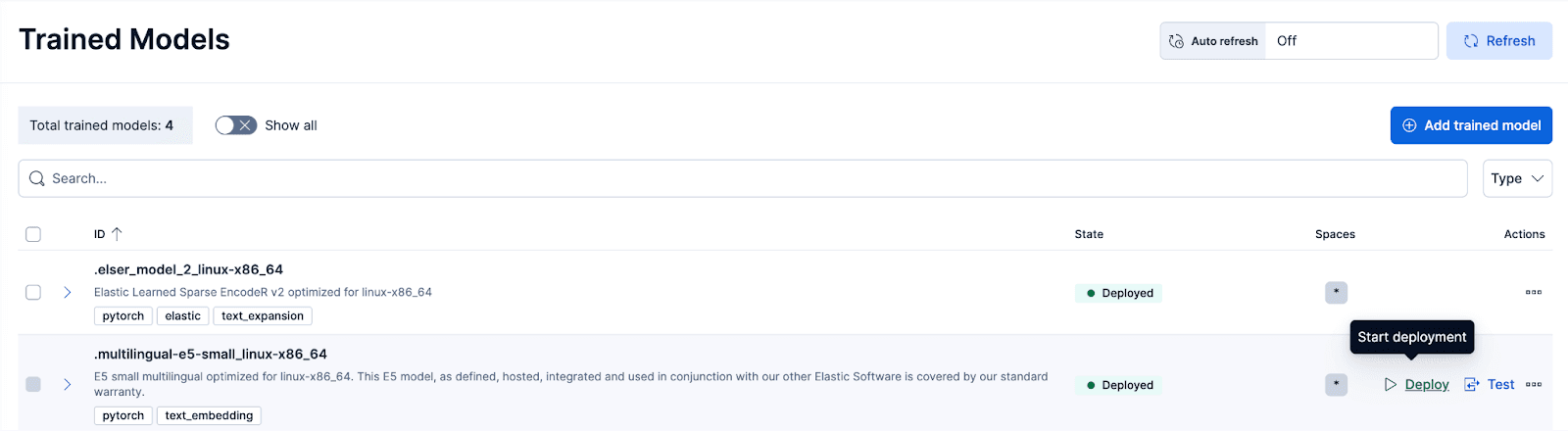
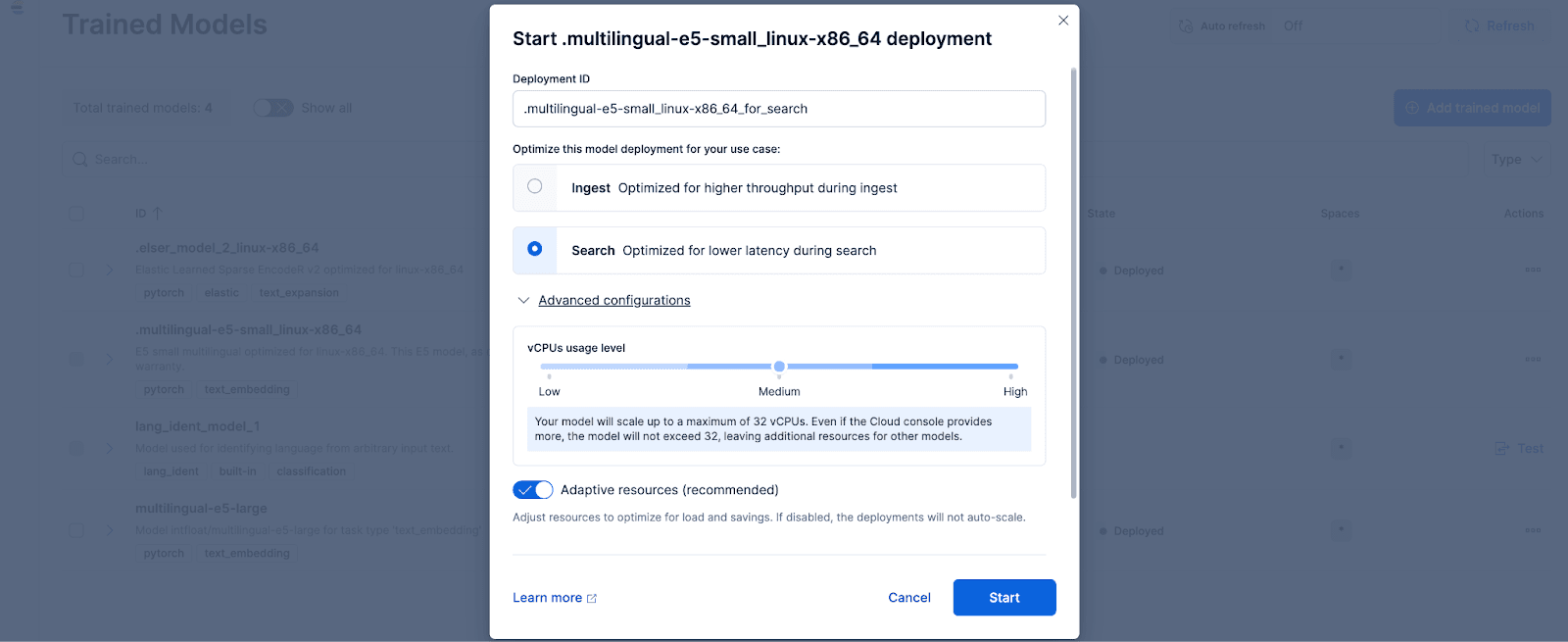
En Kibana, accede a la página de Stack Management > Trained Models y haz clic en Desplegar para el .multilingual-e5-small_linux-x86_64 opción. Este modelo E5 es un pequeño multilingüe optimizado para linux-x86_64, que podemos usar de fábrica. Al hacer clic en 'Desplegar' aparecerá una pantalla donde puedes ajustar la configuración de despliegue o las configuraciones de los vCPU. Para simplificar, optaremos por las opciones predeterminadas, con recursos adaptativos seleccionados, que escalarán automáticamente nuestro despliegue según el uso.
Opcionalmente, si quieres usar otros modelos de incrustación de texto, puedes hacerlo. Por ejemplo, para usar el BGE-M3, puedes usar el cliente Eland Python de Elastic para importar el modelo desde HuggingFace.
Luego, ve a la página de Modelos Capacitados para desplegar el modelo importado con las configuraciones deseadas.
Paso 4: Vectorizar o crear incrustaciones para los datos originales con el modelo desplegado
Para crear los embeddings, primero necesitamos crear un pipeline de ingesta que nos permita tomar el texto y pasarlo por el modelo de embedding de texto de inferencia. Puedes hacerlo en la interfaz de usuario de Kibana o a través de la API de Elasticsearch.
Para hacerlo a través de la interfaz Kibana, tras desplegar el Modelo Capacitado, haz clic en el botón Test . Esto te dará la posibilidad de probar y previsualizar los embeddings generados. Crea una nueva vista de datos para el índice de coco, configura la vista de datos en la vista de datos coco recién creada y pon el campo en description porque ese es el campo para el que queremos generar incrustaciones.
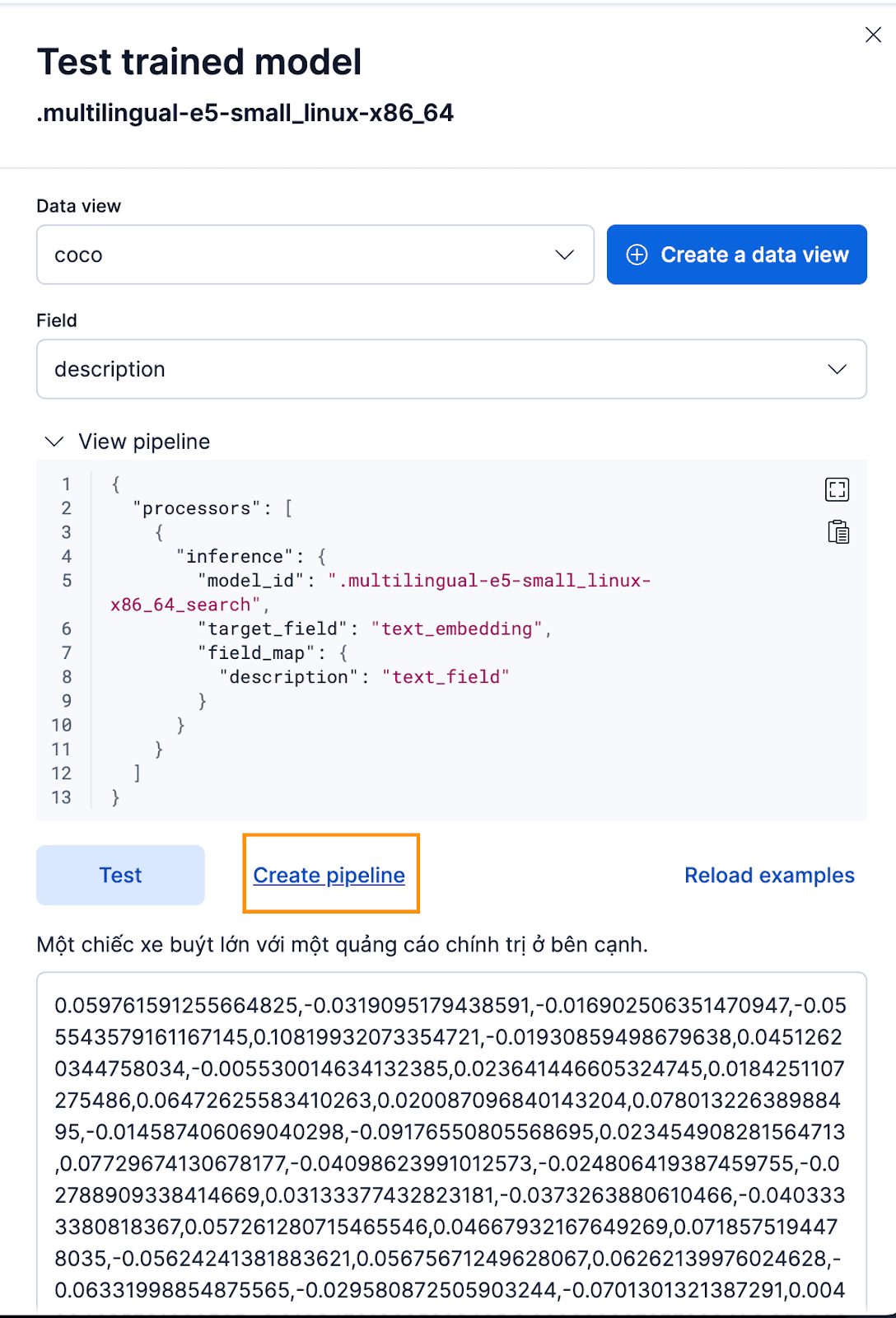
¡Eso funciona genial! Ahora podemos proceder a crear la pipeline de ingest, reindexar nuestros documentos originales, pasarlos por la pipeline y crear un nuevo índice con los embeddings. Puedes conseguirlo haciendo clic en Crear pipeline, lo que te guiará durante el proceso de creación de pipeline, con procesadores auto-repoblados necesarios para ayudarte a crear los embeddings.
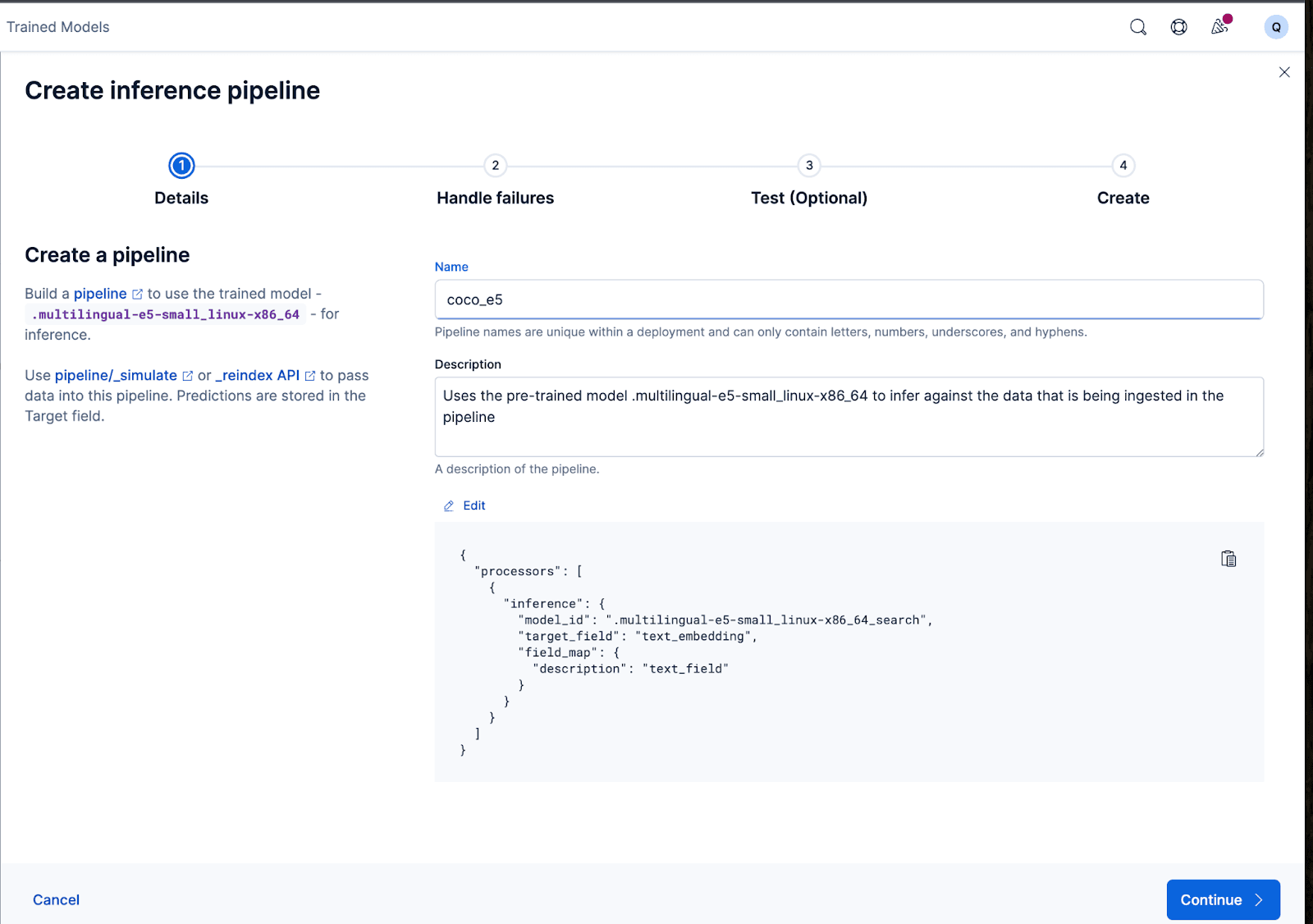
El asistente también puede rellenar automáticamente los procesadores necesarios para gestionar fallos mientras se ingieren y procesan los datos.
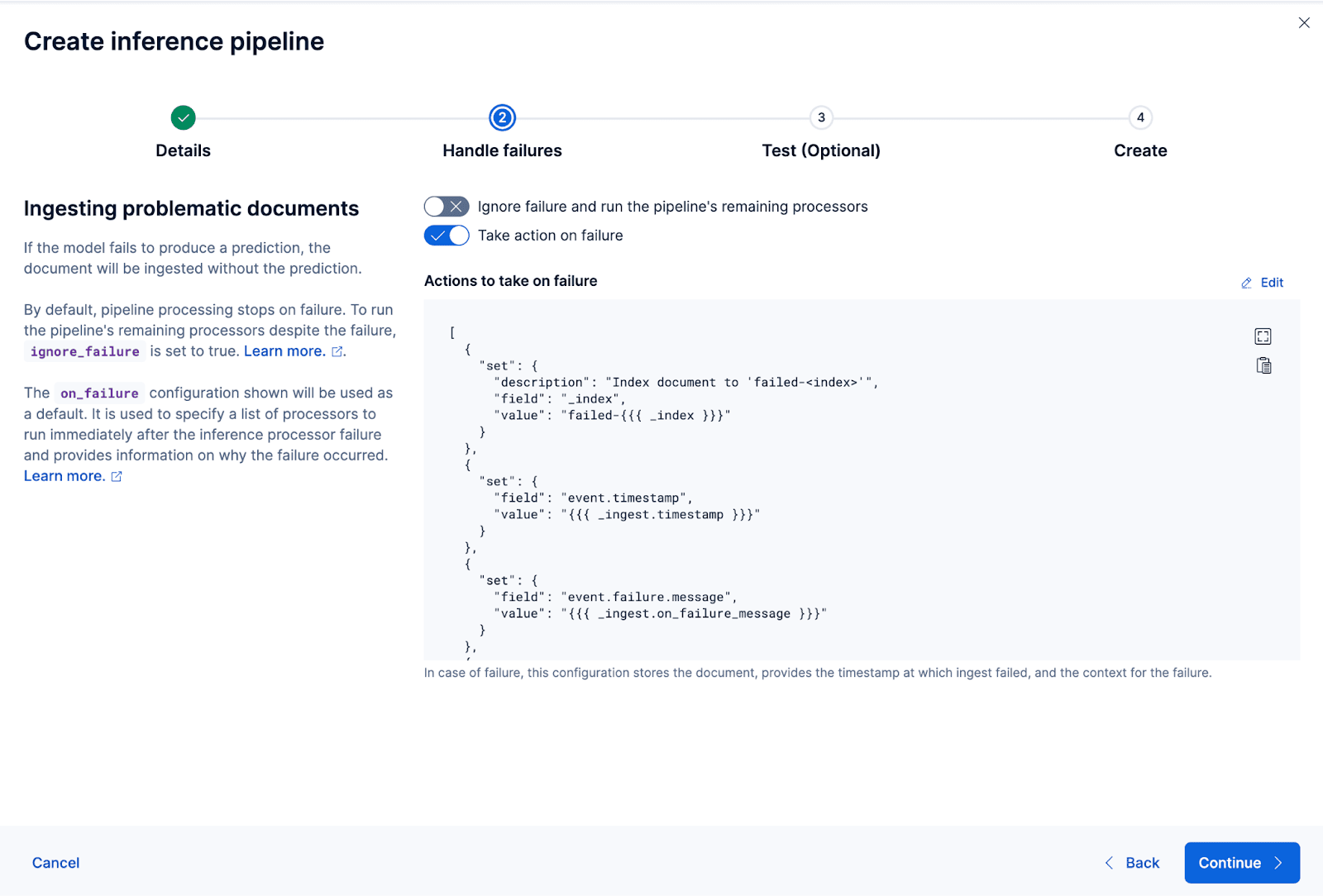
Ahora creemos la canalización de ingest. Voy a nombrar el oleoducto coco_e5. Una vez que la tubería se crea correctamente, puedes usarla inmediatamente para generar las incrustaciones reindexando los datos originales indexados a un nuevo índice en el asistente. Haz clic en Reindexar para iniciar el proceso.
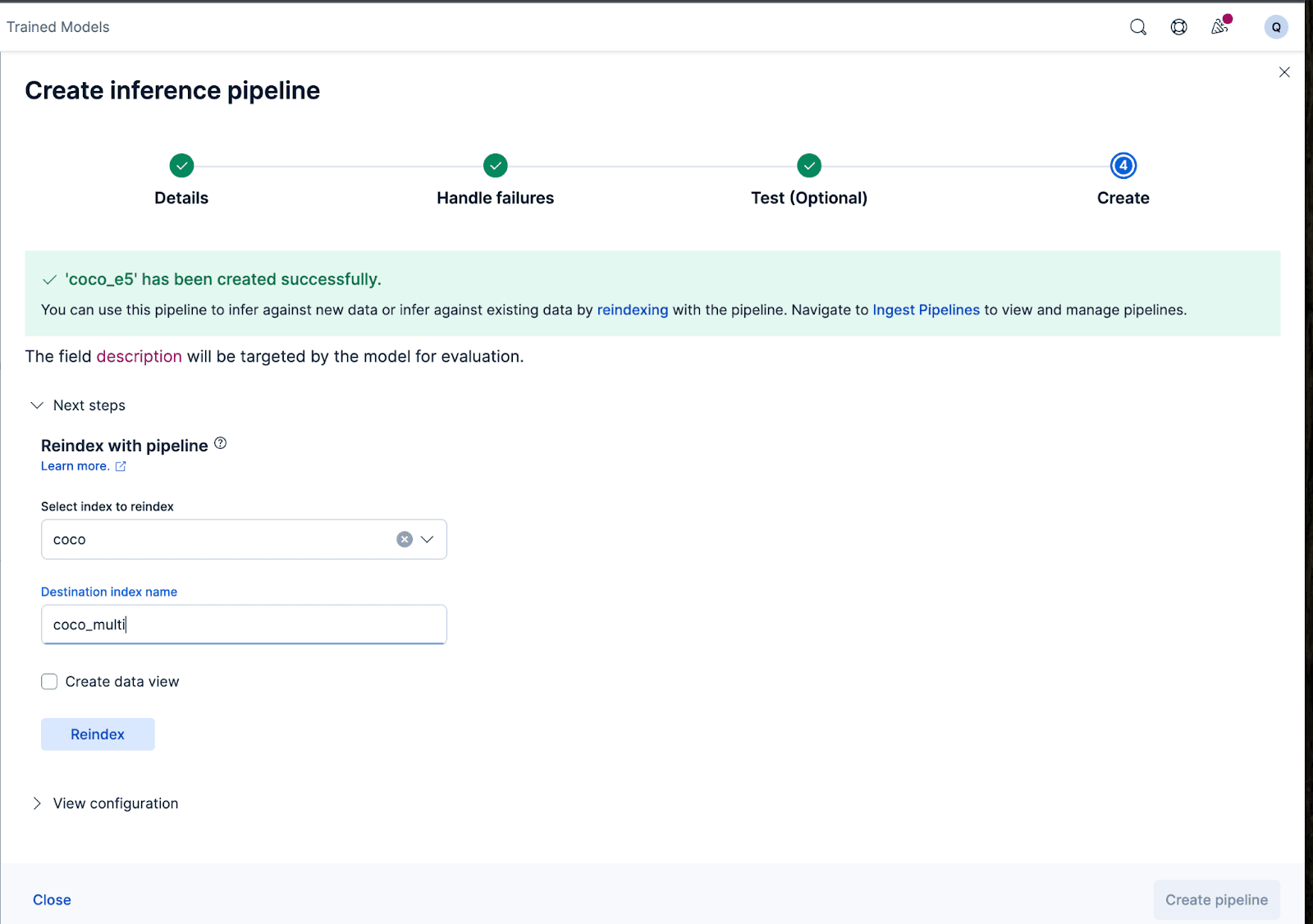
Para configuraciones más complejas, podemos usar la API de Elasticsearch.
Para algunos modelos, debido a la forma en que se capacitaron, puede que necesitemos anteponer o agregar ciertos textos a la entrada real antes de generar los embeddings; de lo contrario, veremos una degradación del rendimiento.
Por ejemplo, con el e5, el modelo espera que el texto de entrada siga a "passage: {content of passage}". Empleemos los pipelines de ingest para lograrlo: crearemos un nuevo pipeline de ingest vectorize_descriptions. En esta canalización, crearemos un nuevo campo de temp_desc temporal, antepondremos "passage: " al texto description , pasaremos temp_desc por el modelo para generar incrustaciones de texto y luego eliminaremos el temp_desc.
Además, podríamos querer especificar qué tipo de cuantización queremos usar para el vector generado. Por defecto, Elasticsearch usa int8_hnsw, pero aquí quiero Better Binary Quantization (o bqq_hnsw), que reduce cada dimensión a una precisión de un solo bit. Esto reduce la huella de memoria en un 96% (o 32 veces) a un costo mayor en la precisión. Opto por este tipo de cuantización porque sé que usaré un reclasificador más adelante para mejorar la pérdida de precisión.
Para ello, crearemos un nuevo índice llamado coco_multi y especificaremos los mapeos. La magia aquí está en el campo vector_description, donde especificamos que el tipo del index_optionsdebe ser bbq_hnsw.
Ahora, podemos reindexar los documentos originales a un nuevo índice, con nuestra pipeline de ingesta que "vectorizará" o creará incrustaciones para el campo de descripciones.
¡Y eso es todo! Desplegamos con éxito un modelo multilingüe con Elasticsearch y Kibana y aprendido paso a paso cómo crear las incrustaciones vectoriales con tus datos con Elastic, ya sea a través de la interfaz de usuario de Kibana o con la API de Elasticsearch. En la segunda parte de este serial, exploraremos los resultados y las particularidades del uso de un modelo multilingüe. Mientras tanto, puedes crear tu propio clúster en la nube para probar la búsqueda semántica multilingüe usando nuestro modelo E5 estándar en el idioma y conjunto de datos que elijas.
Contenido relacionado

18 de mayo de 2026
Búsqueda con IA de agentes y barreras de protección determinísticas en Elasticsearch para una ejecución segura de consultas
Los sistemas de búsqueda con IA de agentes suelen fallar cuando los LLM generan consultas directamente. Aprende cómo las barreras de protección deterministas y la arquitectura de plano de control permiten una ejecución de consultas segura, fiable y regulada con Elasticsearch.

11 de mayo de 2026
Personalización de la búsqueda en comercio electrónico: integración del historial de compras y cohortes de usuarios
Aprende a crear una experiencia de búsqueda personalizada en Elasticsearch sin infringir la gobernanza. En esta publicación se explica cómo destacar los productos que un comprador ha adquirido previamente y cómo activar políticas específicas de cohortes basadas en perfiles de usuario.

4 de mayo de 2026
Percolador de Elasticsearch para la gobernanza de búsquedas en comercio electrónico: traducir búsquedas ambiguas en estrategias de recuperación controladas
Aprende a usar el percolador de Elasticsearch para implementar la gobernanza de búsquedas. En este blog, describimos los patrones necesarios para crear un motor de políticas regulado en producción y establecer una estrategia de recuperación controlada.

1 de mayo de 2026
Creación de un plano de control para gestionar las búsquedas en el comercio electrónico
Cómo construir un plano de control gobernado para el comercio electrónico que integre políticas de búsqueda conflictivas en un solo plan de ejecución (sin cambios de código).

24 de abril de 2026
Reindexación de flujos de datos debido a conflictos de mapping
Descubre cómo solucionar los conflictos de mapeo de Elasticsearch reindexando los flujos de datos. Este blog explica el proceso de reindexación y la verificación del mapeo correcto.