¿Alguna vez quisiste buscar en tu álbum de fotos por significado? Prueba con preguntas como "muéstrame mis fotos donde llevo una chaqueta azul y estoy sentado en un banco", "muéstrame fotos del Monte Everest" o "sake y sushi". Toma una taza de café (o tu bebida favorita) y sigue leyendo. En este blog, te mostramos cómo construir una aplicación de búsqueda híbrida multimodal. Multimodal significa que la app puede entender y buscar entre diferentes tipos de entradas—texto, imágenes y audio—no solo palabras. Híbrido significa que combina técnicas como la coincidencia de palabras clave, la búsqueda vectorial kNN y el geofencing para ofrecer resultados más precisos.

Para lograrlo, empleamos SigLIP-2 de Google para generar incrustaciones vectoriales tanto para imágenes como para texto, y las almacenamos en la base de datos vectorial Elasticsearch. En el momento de la consulta, convertimos la entrada de búsqueda, texto o imagen, en incrustaciones y realizamos búsquedas rápidas con vectores kNN para obtener resultados. Esta configuración permite una búsqueda eficiente de texto a imagen y de imagen a imagen. Una interfaz Streamlit da vida a este proyecto proporcionándonos una interfaz no solo para hacer búsquedas por texto para encontrar y ver las fotos coincidentes del álbum, sino también para identificar la cima de la montaña a partir de la imagen subida y ver otras fotos de esa montaña en el álbum.
También cubrimos los pasos que seguimos para mejorar la precisión de las búsquedas, junto con consejos y trucos prácticos. Para una exploración más profunda, proporcionamos un repositorio de GitHub y un cuaderno de Colab.
Cómo empezó todo
Esta entrada del blog fue inspirada por un niño de 10 años que me pidió que les mostrara todas las fotos del Monte Ama Dablam de mi travesía al campamento base del Everest. Mientras revisábamos el álbum de fotos, también me pidieron que identificara varias otras cumbres montañosas, algunas de las cuales no podía nombrar.
Eso me dio la idea de que esto puede ser un proyecto divertido de visión por computadora. Lo que queríamos conseguir:
- Encuentra fotos de un pico montañoso por nombre
- Adivina el nombre de la cima de la montaña a partir de una imagen y también encuentra picos similares en el álbum de fotos
- Haz que las consultas conceptuales funcionen (persona, río, banderas de oración, etc.)

Monte Ama Dablam
Formando el equipo soñado: SigLIP-2, Elasticsearch y Streamlit
Pronto quedó claro que, para que esto funcionara, tendríamos que convertir tanto el texto ("Ama Dablam") como las imágenes (fotos de mi álbum) en vectores que puedan comparar de forma significativa, es decir, en el mismo espacio vectorial. Una vez que hacemos eso, la búsqueda es simplemente "encontrar a los vecinos más cercanos".

SigLIP-2, lanzado recientemente por Google, encaja bien aquí. Puede generar incrustaciones sin entrenamiento específico de tarea (un ajuste de cero disparos ) y funciona bien para nuestro caso: fotos sin etiqueta y picos con diferentes nombres e idiomas. Como está capacitado para la coincidencia de imágenes de texto ↔, una foto de montaña de la travesía y un breve prompt de texto acaban siendo similares a incrustaciones, incluso cuando el idioma de consulta o la ortografía varían.
SigLIP-2 ofrece un fuerte equilibrio calidad-velocidad, soporta múltiples resoluciones de entrada y funciona tanto en CPU como en GPU. El SigLIP-2 está diseñado para ser más robusto para fotos exteriores en comparación con modelos anteriores como el CLIP original. Durante nuestras pruebas, SigLIP-2 generó resultados fiables de forma constante. Además, está muy bien apoyado, lo que lo convierte en la opción obvia para este proyecto.
A continuación, necesitamos una base de datos vectorial para almacenar los embebidos y la búsqueda de potencia. Debe soportar no solo búsqueda kNN coseno sobre incrustaciones de imágenes, sino también aplicar filtros de geocerca y texto en una sola consulta. Elasticsearch encaja bien aquí: maneja vectores (HNSW kNN en campos dense_vector), soporta búsqueda híbrida que combina texto, vectores y consultas geográficas, y ofrece filtrado y ordenación desde el principio. Además, escala horizontalmente, lo que facilita crecer de unas pocas fotos a miles. El cliente oficial de Python de Elasticsearch mantiene la fontanería sencilla y se integra perfectamente con el proyecto. Por último, necesitamos un frontend ligero donde podamos introducir consultas de búsqueda y ver resultados. Para una demostración rápida basada en Python, Streamlit es una opción ideal. Proporciona las primitivas que necesitamos: carga de archivos, una cuadrícula de imágenes responsiva y menús desplegables para ordenar y geovaller. Es fácil de clonar y ejecutar localmente, y también funciona en un cuaderno de Colab.
Implementación
Diseño y estrategia de indexación de Elasticsearch
Emplearemos dos índices para este proyecto: peaks_catalog y photos.
Peaks_catalog índice
Este índice sirve como un catálogo compacto de picos montañosos prominentes visibles durante la travesía al Campamento Base del Everest. Cada documento de este índice corresponde a una sola cima montañosa, como el Monte Everest. Para cada documento de pico de montaña, almacenamos nombres/alias, coordenadas opcionales de latitud-longitud y un único vector prototipo construido mediante la mezcla de prompts de texto SigLIP-2 (+ imágenes de referencia opcionales).
Mapeo indexado:
| Campo | Tipo | Ejemplo | Propósito/Notas | Vector/Indexación |
|---|---|---|---|---|
| identificación | palabra clave | ama-dablam | Slug/id estable | — |
| Nombres | Subcampo texto + palabra clave | ["Ama Dablam","Amadablam"] | Alias / nombres multilingües; names.raw para filtros exactos | — |
| Latlon | geo_point | {"lat":27.8617,"lon":86.8614} | Coordenadas GPS de pico como combinación de latitud/longitud (opcional) | — |
| elev_m | entero | 6812 | Elevación (opcional) | — |
| text_embed | dense_vector | 768 | Prototipo mezclado (prompts y, opcionalmente, 1–3 imágenes de referencia) para este pico | Index:True, Similitud:"Coseno", index_options:{type:"hnsw", m:16, ef_construction:128} |
Este índice se emplea principalmente para búsquedas imagen a imagen, como identificar picos montañosos a partir de imágenes. También empleamos este índice para mejorar los resultados de búsqueda de texto a imagen.
En resumen, el peaks_catalog transforma la pregunta "¿Qué montaña es esta?" en un problema enfocado del vecino más cercano, separando efectivamente la comprensión conceptual de las complejidades de los datos de imagen.
Estrategia de indexación para el índice peaks_catalog: Comenzamos creando una lista de los picos más destacados visibles durante la travesía por el EBC. Para cada pico, almacenamos su ubicación geográfica, nombre, sinónimos y elevación en un archivo yaml. El siguiente paso es generar la incrustación de cada pico y almacenarla en text_embed campo. Para generar incrustaciones robustas, empleamos la siguiente técnica:
- Crea un prototipo de texto usando:
- Nombres de los picos
- Conjunto de prompts (usando varios prompts diferentes para intentar responder a la misma pregunta), por ejemplo:
- "una foto natural de la cima de la montaña {name} en el Himalaya, Nepal"
- "{name} pico emblemático en la región del Khumbu, paisaje alpino"
- "{name} cima de montaña, nieve, cresta rocosa"
- anticoncepto opcional (indicar a SigLIP-2 en qué no debe coincidir): resta un pequeño vector para "pintura, ilustración, afiche, mapa, logo" para inclinarnos hacia fotos reales.
- Opcionalmente , crea un prototipo de imagen si se proporcionan imágenes de referencia del pico.
Luego mezclamos el prototipo de texto e imagen para generar la incrustación final. Finalmente, el documento está indexado con todos los campos requeridos:
Documento de ejemplo de peaks_catalog índice:

Índice de fotos
Este índice principal almacena información detallada sobre todas las fotos del álbum. Cada documento representa una sola foto, que contiene la siguiente información:
- Camino relativo a la foto del álbum. Esto puede usar para ver la imagen correspondiente o cargarla en la interfaz de búsqueda.
- GPS e información horaria de la imagen.
- Vector denso para codificación de imágenes generado por SigLIP-2.
predicted_peaksEso nos permite filtrar por nombre de pico.
Mapeo de índices
| Campo | Tipo | Ejemplo | Propósito/Notas | Vector / Indexación |
|---|---|---|---|---|
| camino | palabra clave | datos/imágenes/IMG_1234.HEIC | Cómo se abre la interfaz en miniatura/imagen completa | — |
| clip_image | dense_vector | 768 | Incrustación de imágenes SigLIP-2 | Index:True, Similitud:"Coseno", index_options:{type:"hnsw", m:16, ef_construction:128} |
| predicted_peaks | palabra clave | ["ama-dablam", "pumori"] | Top-K suposiciones en el tiempo del índice (filtro UX barato / facet) | — |
| GPS | geo_point | {"lat":27.96,"lon":86.83} | Activa los filtros geográficos | — |
| shot_time | date | 2023-10-18T09:41:00Z | Tiempo de captura: ordenar/filtrar | — |
Estrategia de indexación para el índice de fotos: Para cada foto del álbum, hacemos lo siguiente:
Extrae shot_time de imagen y gps información de los metadatos de las imágenes.
- Embedding de imagen SigLIP-2: pasar la imagen por el modelo y normalizar el vector en modo L2. Almacena el embedding en
clip_imagecampo. - Predecir los picos y almacenarlos en el campo
predicted_peaks. Para ello, primero tomamos el vector de imagen de la foto generado en el paso anterior y luego ejecutamos una búsqueda rápida kNN en el campo text_embed en el índice depeaks_catalog. Mantenemos los 3-4 primeros picos e ignoramos el resto. - Calculamos el campo
_idhaciendo un hash en el nombre y el camino de la imagen. Esto cerciora que no acabemos con duplicados tras varias partidas.
Una vez que determinamos todos los campos para la foto, los documentos fotográficos se indexan en lotes usando indexación masiva :
Documento de ejemplo del índice de fotos:
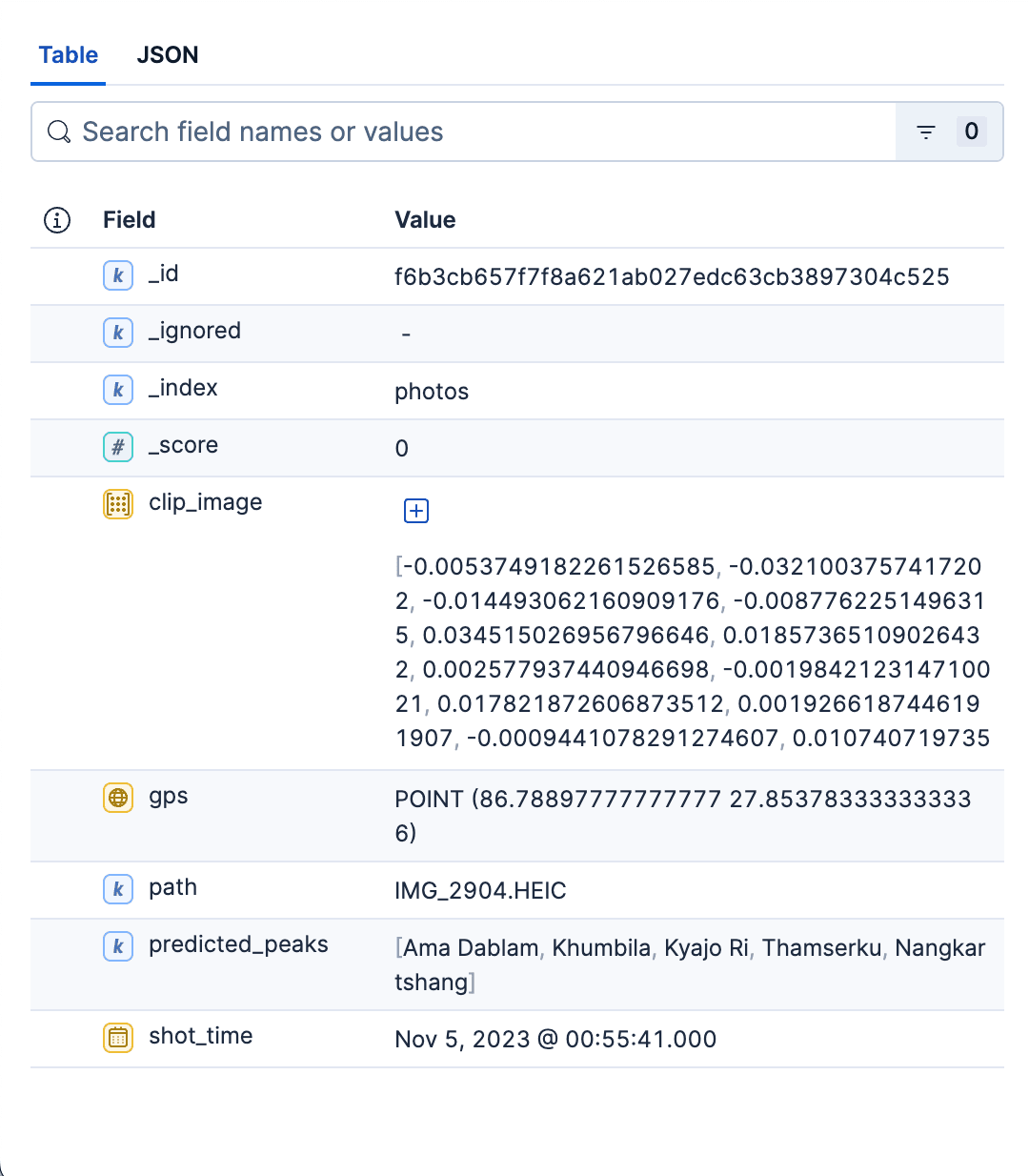
En resumen, el índice de las fotos es el almacén rápido, filtrable y listo para kNN de todas las fotos del álbum. Su mapeo es mínimo a propósito: la estructura justa para recuperar rápidamente, mostrar limpiamente y recortar los resultados por espacio y tiempo. Este índice sirve tanto para casos de búsqueda como para el uso. Aquí se puede encontrar un script en Python para crear ambos índices.
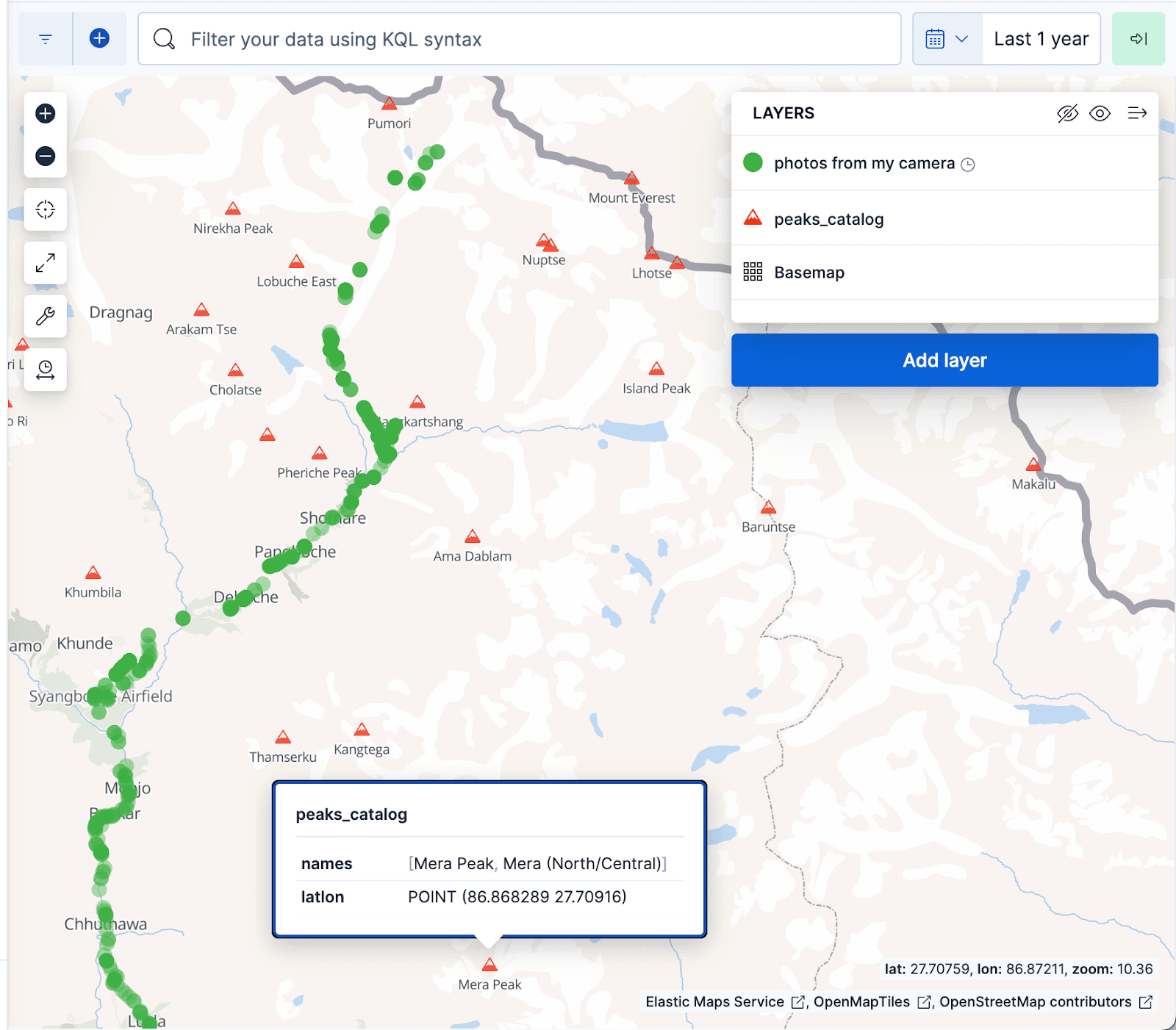
La visualización de mapas de Kibana que aparece a continuación muestra documentos del álbum de fotos como puntos verdes y picos montañosos del índice de peaks_catalog como triángulos rojos, con los puntos verdes alinear bien con el sendero de la ruta del campamento base del Everest.
Casos de uso de búsqueda
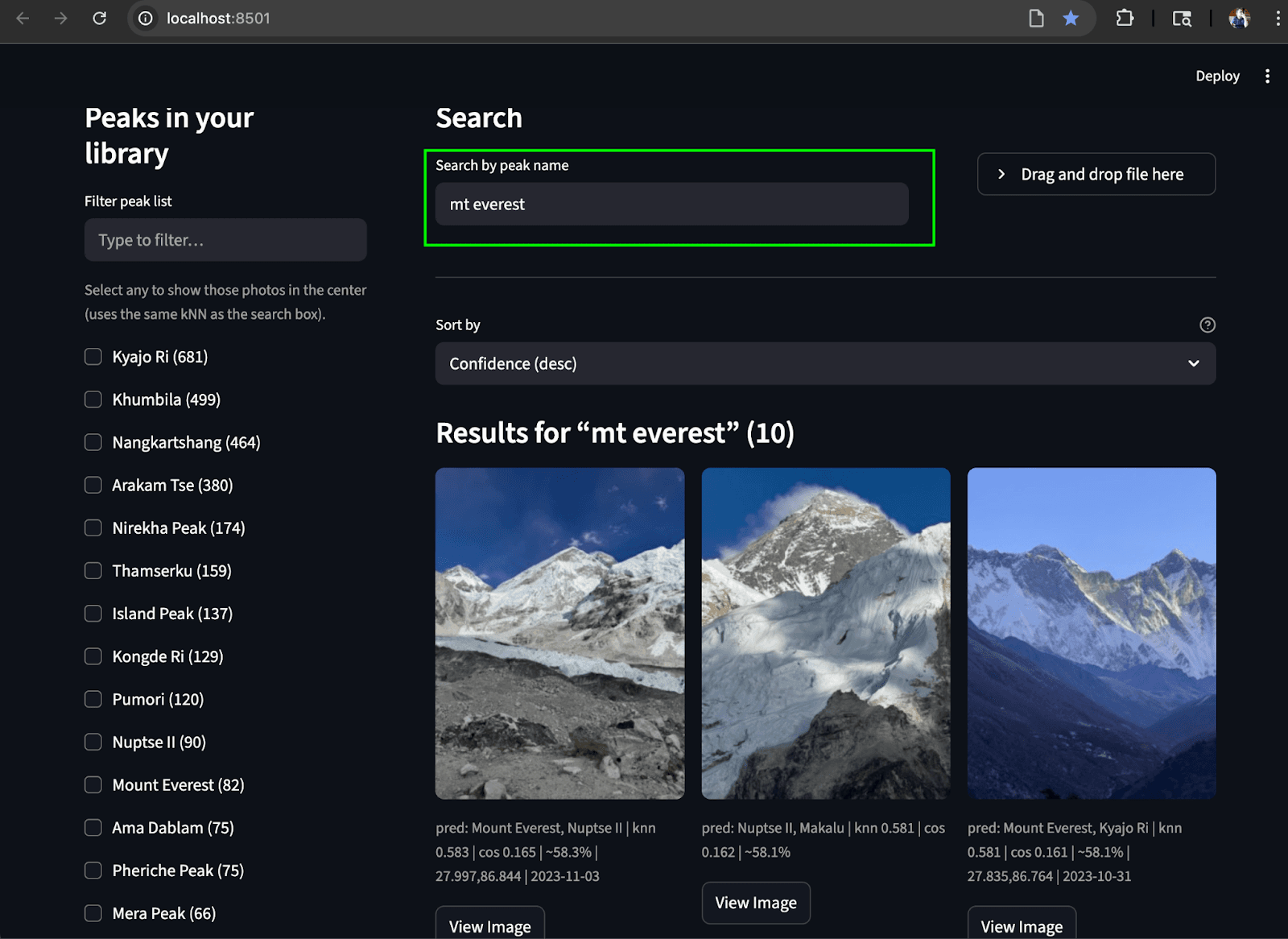
Buscar por nombre (texto a imagen): Esta función permite a los usuarios localizar fotos de picos montañosos (e incluso conceptos abstractos como "banderas de oración") mediante consultas de texto. Para lograrlo, la entrada de texto se convierte en un vector de texto usando SigLIP-2. Para una generación robusta de vectores de texto, empleamos la misma estrategia que se usa para crear incrustaciones de texto en el índice peaks_catalog : combinar la entrada de texto con un pequeño conjunto de prompts, restar un pequeño vector anti-concepto y aplicar la normalización L2 para producir el vector de consulta final. A continuación, se ejecuta una consulta kNN en el campo photos.clip_image para recuperar los picos que coinciden con la parte superior, basar en la similitud coseno para encontrar las imágenes más cercanas. Opcionalmente, los resultados de búsqueda pueden ser más relevantes aplicando filtros geográficos y de fecha, y/o un filtro de photos.predicted_peaks términos como parte de la consulta (ver ejemplos de consultas más abajo). Esto ayuda a excluir picos que se parecen y que en realidad no se ven durante la travesía.
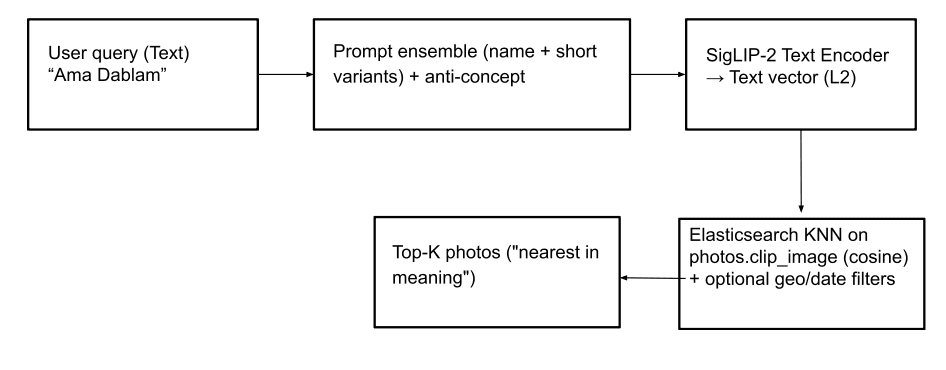
Consulta de Elasticsearch con filtro geográfico:
Buscar por imagen (imagen a imagen): Esta función nos permite identificar una montaña en una imagen y encontrar otras imágenes de esa misma montaña dentro del álbum. Cuando se sube una imagen, el codificador de imagen SigLIP-2 la procesa para generar un vector de imagen. A continuación, se realiza una búsqueda kNN en el campo peaks_catalog.text_embed para identificar los nombres de picos que mejor coinciden. Posteriormente, se genera un vector de texto a partir de estos nombres de picos coincidentes, y se realiza otra búsqueda kNN en el índice de fotos para localizar las imágenes correspondientes.

Consulta Elasticsearch:
Paso 1: Encontrar los nombres de picos que coincidan
Paso 2: Realiza una búsqueda en el índice de photos para encontrar las imágenes coincidentes (misma consulta que se muestra en el caso de búsqueda text-to-image):
Interfaz Streamlit
Para unir todo, creamos una interfaz sencilla de Streamlit que nos permite realizar ambos casos de uso de búsqueda. El riel izquierdo muestra una lista desplazable de picos (agregados a partir de photos.predicted_peaks) con casillas de verificación y un minimapa/filtro geográfico. En la parte superior hay una caja de búsqueda por nombre y un botón de identificación por subida de fotos . El panel central presenta una cuadrícula en miniatura sensible que muestra puntajes kNN, insignias de picos predichos y tiempos de captura. Cada imagen incluye un botón para ver imagen para vistas previas en resolución completa.
Busca subiendo una imagen: Predecimos el pico y encontramos picos coincidentes del álbum de fotos.
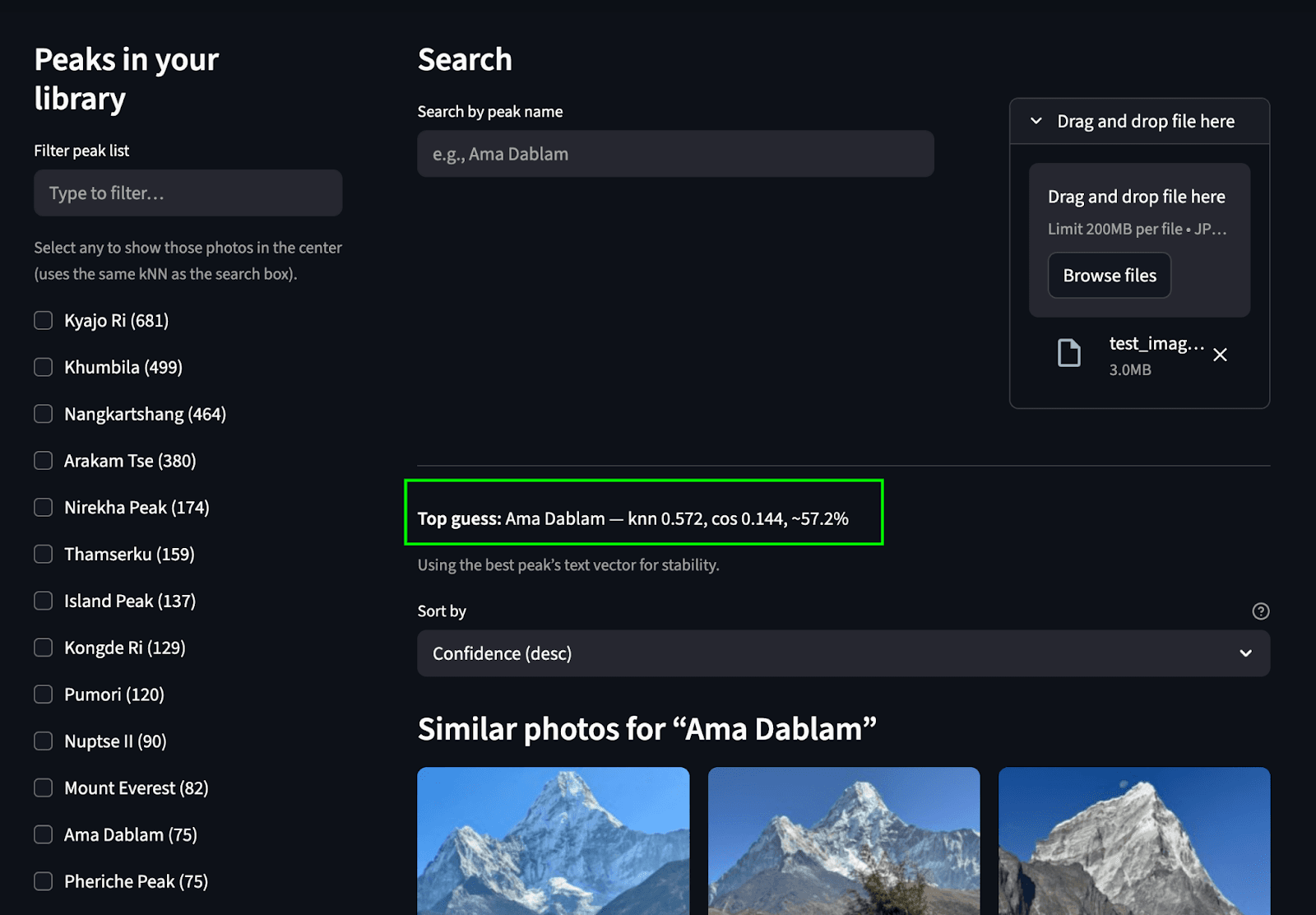
Buscar por texto: Encuentra los picos coincidentes en el álbum a partir del texto
Conclusión
¿Qué empezó como , ¿podemos simplemente ver las imágenesde Ama Dablam? se convirtió en un pequeño sistema de búsqueda multimodal funcional. Tomamos fotos en bruto de trekking, las convertimos en incrustaciones SigLIP-2 y usamos Elasticsearch para hacer kNN rápido sobre vectores, además de filtros geo/temporales simples para mostrar las imágenes correctas por significado. En el camino, separamos las preocupaciones con dos índices: un pequeño peaks_catalog de prototipos combinados (para identificación) y un índice escalable de photos de vectores de imagen y EXIF (para recuperación). Es práctica, reproducible y fácil de ampliar.
Si quieres afinarla, hay algunos ajustes con los que puedes experimentar:
- Ajustes de tiempo de consulta:
k(cuántos vecinos quieres que devuelvan) ynum_candidates(qué ancho buscar antes del puntaje final). Estos ajustes se discuten en el blog aquí. - Ajustes de tiempo de índice:
m(conectividad de grafos) yef_construction(precisión en tiempo de construcción frente a memoria). Para consultas, experimenta también conef_search: más alto suele significar mejor recordación con cierto compromiso de latencia. Consulta este blog para más detalles sobre estos entornos.
De cara al futuro, los modelos nativos/reclasificadores para búsqueda multimodal y multilingüe pronto llegarán al ecosistema Elastic, lo que debería mejorar aún más la recuperación de imágenes/texto y el ranking híbrido desde el primer momento. ir.elastic.co+1
Si quieres probar esto tú mismo:
- Repositorio de GitHub: https://github.com/navneet83/multimodal-mountain-peak-search
- Inicio rápido de Colab: https://github.com/navneet83/multimodal-mountain-peak-search/blob/main/notebooks/multimodal_mountain_peak_search.ipynb
Con esto, nuestro viaje llegó a su fin y es hora de volar de regreso. Espero que esto te fue útil y si lo rompes (o lo mejoras), me encantaría saber qué cambiaste.

Contenido relacionado

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.