La búsqueda híbrida es ampliamente reconocida como un enfoque de búsqueda poderosa, que combina la precisión y rapidez de la búsqueda léxica con las capacidades de lenguaje natural de la búsqueda semántica. Sin embargo, aplicarlo en la práctica puede ser complicado, ya que a menudo requiere un conocimiento profundo del índice y la construcción de consultas extensas con configuraciones no triviales. En este blog, exploraremos cómo el formato de consulta multicampo para retrievers lineales y RRF hace que la búsqueda híbrida sea más sencilla y accesible, eliminando los dolores de cabeza comunes y permitiéndote aprovechar todo su poder con mayor facilidad. También revisaremos cómo el formato de consulta multicampo te permite realizar consultas de búsqueda híbridas sin conocimiento previo de tu índice.
El problema del rango de puntaje

Para contextualizar, repasemos una de las principales razones por las que la búsqueda híbrida puede ser difícil: los rangos de puntaje variables. Nuestro viejo amigo BM25 produce puntajes ilimitados. En otras palabras, BM25 puede generar puntajes que van desde cerca de 0 hasta (teóricamente) infinitas. En cambio, las consultas contra dense_vector campos producirán puntajes acotados entre 0 y 1. Para empeorar este problema, semantic_text ofusca el tipo de campo empleado para indexar incrustaciones, así que a menos que tengas un conocimiento detallado sobre tu configuración de índices y endpoints de inferencia, puede ser difícil saber cuál será el rango de puntaje de tu consulta. Esto presenta un problema al intentar entrecalar resultados de búsqueda léxica y semántica, ya que los resultados léxicos pueden tener prioridad sobre los semánticos incluso si los resultados semánticos son más relevantes. La solución generalmente aceptada para este problema es normalizar los puntajes antes de entrelazar los resultados. Elasticsearch dispone de dos herramientas para esto: los retrievers lineales y RRF .
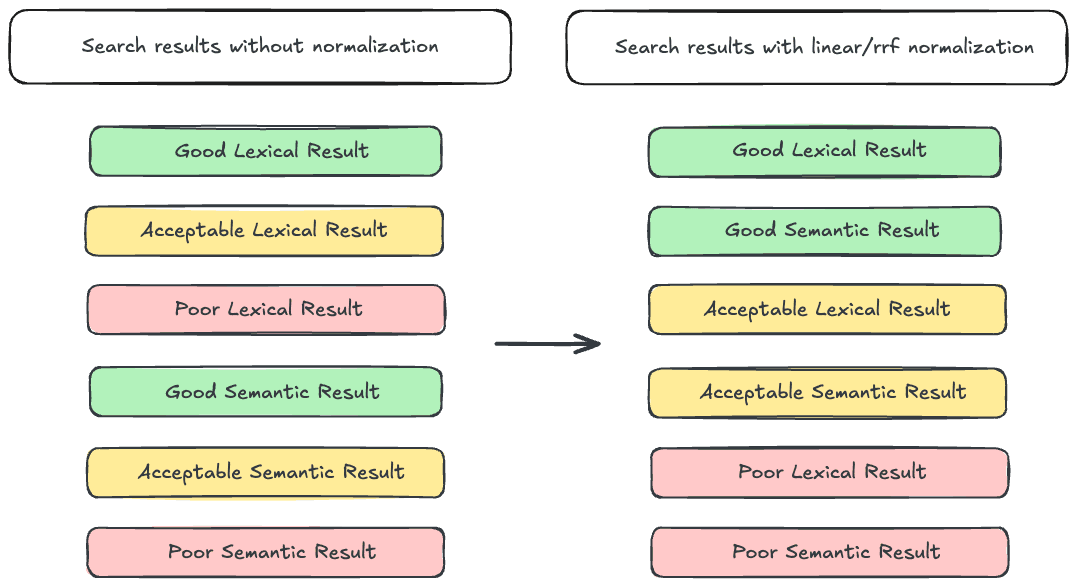
El recuperador RRF aplica el algoritmo RRF, usando el rango del documento como medida de relevancia y descartando el puntaje. Como el puntaje no se tiene en cuenta, las discrepancias en el rango de puntaje no son un problema.
El retriever lineal emplea una combinación lineal para determinar el puntaje final de un documento. Esto implica tomar el puntaje de cada consulta componente para el documento, normalizarla y sumarla para generar el puntaje total. Matemáticamente, la operación puede expresar como:
Donde N es la función de normalización, y SX es el puntaje para la consulta X. La función de normalización es clave aquí, ya que transforma el puntaje de cada consulta para usar el mismo rango. Puedes aprender más sobre el retriever lineal aquí.
Desglosándolo
Los usuarios pueden implementar una búsqueda híbrida eficaz con estas herramientas, pero requiere cierto conocimiento sobre tu índice. Veamos un ejemplo con el retriever lineal, donde consultaremos un índice con dos campos:
1. semantic_text_field es un campo semantic_text que emplea E5, un modelo de incrustación de texto
2. text_field es un campo estándar de text
1. Usamos una consulta match en nuestro campo semantic_text , para la que agregamos soporte en Elasticsearch 8.18/9.0
Al construir la consulta, debemos tener en cuenta que semantic_text_field emplea un modelo de incrustación de texto, por lo que cualquier consulta generará un puntaje entre 0 y 1. También necesitamos saber que text_field es un campo de text estándar y, por tanto, las consultas sobre él generarán un puntaje no acotada. Para crear un conjunto de resultados con la relevancia adecuada, necesitamos usar un retriever que normalice los puntajes de consulta antes de combinarlas. En este ejemplo, usamos el retriever lineal con minmax normalización, que normaliza el puntaje de cada consulta a un valor entre 0 y 1.
La construcción de la consulta en este ejemplo es bastante sencilla porque solo están involucrados dos campos. Sin embargo, puede complicar muy rápido a medida que se agregan más campos, y de diferentes tipos. Esto demuestra cómo escribir una consulta híbrida eficaz suele requerir un conocimiento más profundo del índice que se consulta, de modo que los puntajes de los componentes se normalicen correctamente antes de la combinación. Esto supone una barrera para la adopción más amplia de la búsqueda híbrida.
Agrupación de consultas
Ampliemos el ejemplo: ¿Y si quisiéramos consultar un campo text y dos campos semantic_text ? Podríamos construir una consulta así:
Eso parece bueno a simple vista, pero hay un posible problema. Ahora los semantic_text partidos de campo representan dos tercios del total del puntaje:
Probablemente esto no es lo que buscas porque crea un puntaje desequilibrado. Los efectos pueden no ser tan evidentes en un ejemplo como este con solo 3 campos, pero se vuelve problemático cuando se consultan más campos. Por ejemplo, la mayoría de los índices contienen muchos más cuerpos léxicos que la semántica (es decir, dense_vector, sparse_vector, o semantic_text). ¿Y si consultáramos un índice con 9 campos léxicos y 1 campo semántico usando el patrón anterior? Las coincidencias léxicas representarían el 90% del puntaje, lo que reduce la efectividad de la búsqueda semántica.
Una forma común de abordar esto es agrupar las consultas en categorías léxicas y semánticas y ponderar ambas de forma uniforme. Esto impide que cualquiera de las dos categorías domine el puntaje total.
Pongámoslo en práctica. ¿Cómo sería este enfoque de consultas agrupadas en este ejemplo al usar el retriever lineal?
¡Vaya, esto se está poniendo muy extenso! ¡Puede que incluso tuviste que desplazarte arriba y abajo varias veces para revisar toda la consulta! Aquí, usamos dos niveles de normalización para crear los grupos de consultas. Matemáticamente, puede expresar como:
Este segundo nivel de normalización garantiza que las consultas contra los campos semantic_text y text campo tengan un peso uniforme. Ten en cuenta que en este ejemplo omitimos la normalización de segundo nivel para text_field ya que solo hay un cuerpo léxico, lo que te ahorra aún más verbosidad.
Esta estructura de consulta ya es engorrosa y solo estamos consultando tres campos. Se vuelve cada vez más inmanejable, incluso para los profesionales experimentados en búsqueda, a medida que consultas más campos.
El formato de consulta multicampo

Agregamos el formato de consulta multicampo para los retrievers lineales y RRF en Elasticsearch 8.19, 9.1 y serverless para simplificar todo esto. Ahora puedes realizar la misma consulta que antes con simplemente:
¡Lo que reduce la consulta de 55 líneas a solo 9! Elasticsearch emplea automáticamente los mapeos de índice para:
- Determinar el tipo de cada campo consultado
- Agrupa cada cuerpo en una categoría léxica o semántica
- Pondera cada categoría de forma equitativa en el puntaje final
Esto permite a cualquiera ejecutar una consulta híbrida eficaz sin necesidad de conocer detalles sobre el índice o los endpoints de inferencia empleados.
Al usar RRF, puedes omitir la normalizer, ya que rango se usa como indicador de relevancia:
Impulso por campo
Al usar el retriever lineal, puedes aplicar un aumento por campo para ajustar la importancia de los combates en ciertos campos. Por ejemplo, supongamos que consultas cuatro campos: dos campos semantic_text y dos campos text :
Por defecto, cada cuerpo tiene un peso igual en su grupo (léxico o semántico). El desglose del puntaje es el siguiente:

En otras palabras, cada campo representa el 25% del puntaje total.
Podemos usar la sintaxis field^boost para agregar un impulso por campo a cualquier campo. Vamos a aplicar un aumento de 2 a semantic_text_field_1 y text_field_1:
Ahora el desglose del puntaje es así:
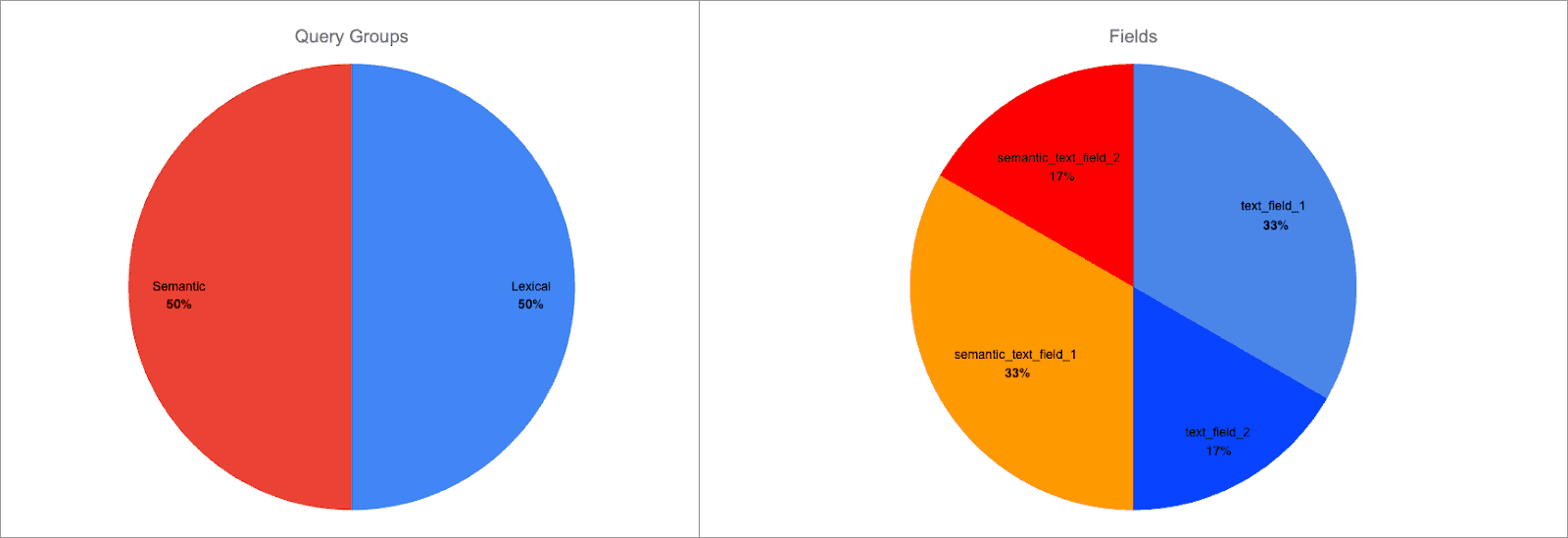
Cada grupo de consulta sigue teniendo un peso igual, pero ahora el peso del campo dentro de los grupos cambió:
semantic_text_field_1es el 66% del puntaje del grupo de consultas semánticas, 33% del puntaje totaltext_field_1es el 66% del puntaje del grupo de consultas léxicas, 33% del puntaje total
| i️ Ten en cuenta que el rango total de puntaje no cambiará cuando se aplica un aumento por campo. Este es un efecto secundario previsto de la normalización de puntajes, que garantiza que los puntajes de consulta léxica y semántica sigan siendo directamente comparables entre sí. |
|---|
| i️ El aumento por campo también puede usar con el recuperador RRF en Elasticsearch 9.2+ |
Resolución comodín
Puedes usar el comodín * en el parámetro fields para que coincida con varios campos. Continuando con el ejemplo anterior, esta consulta es funcionalmente equivalente a consultar semantic_text_field_1, semantic_text_field_2, y text_field_1 explícitamente:
Es interesante notar que el patrón de *_field_1 coincide tanto con text_field_1 como con semantic_text_field_1. Esto se gestiona automáticamente; La consulta se ejecutará como si cada uno de los campos fuera consultado explícitamente. También está bien que el semantic_text_field_1 coincida con ambos patrones; Todas las coincidencias de nombres de campo se deduplican antes de la ejecución de la consulta.
Puedes usar el comodín de varias maneras:
- Coincidencia de prefijos (ej:
*_text_field) - Emparejamiento en línea (ej:
semantic_*_field) - Coincidencia de sufijos (ej:
semantic_text_field_*)
También puedes usar varios comodines para aplicar una combinación de lo anterior, como *_text_field_*.
Campos de consulta predeterminados
El formato de consulta multicampo también te permite consultar un índice del que no sabes nada. Si omites el parámetro fields , consultará todos los campos especificados por la configuración de índice index.query.default_field:
Por defecto, index.query.default_field está configurado como *. Este comodín se resolverá a todos los tipos de campo del índice que admitan consultas de término, que es la mayoría. Las excepciones son:
dense_vectorCamposrank_vectorCampos- Campos geométricos:
geo_point,shape
Esta funcionalidad es especialmente útil cuando se quiere realizar una consulta de búsqueda híbrida sobre un índice proporcionado por un tercero. El formato de consulta multicampo permite ejecutar una consulta adecuada de forma sencilla. Simplemente excluye el parámetro fields y se consultarán todos los campos aplicables.
Conclusión
El problema del rango de puntaje puede hacer que la búsqueda híbrida efectiva sea un dolor de cabeza de implementar, especialmente cuando hay poca comprensión del índice que se consulta o de los endpoints de inferencia empleados. El formato de consulta multicampo para los retrievers lineales y RRF alivia este problema al empaquetar un enfoque automatizado de búsqueda híbrida basado en agrupación de consultas en una API simple y accesible. Funcionalidades adicionales, como el aumento por campo, la resolución de comodines y los campos de consulta por defecto, amplían la funcionalidad para cubrir muchos casos de uso.
Prueba hoy el formato de consulta multicampo
Puedes consultar los retrievers lineales y RRF con el formato de consulta multicampo en proyectos Serverless totalmente gestionados de Elasticsearch con una prueba gratis. También está disponible en versiones de pila a partir de la 8.19 y 9.1.
Empieza en minutos en tu entorno local con un solo comando:
Contenido relacionado

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

13 de marzo de 2026
Resolución de entidades con Elasticsearch, parte 4: el desafío final
Resolver y evaluar los desafíos de resolución de entidades en sets de datos de "desafío final" altamente diversos, diseñados para prevenir atajos.

26 de febrero de 2026
Resolución de entidades con Elasticsearch y LLMs, parte 2: emparejamiento de entidades con evaluación de LLM y búsqueda semántica
Usar la búsqueda semántica y las evaluaciones transparentes de LLM para la resolución de entidades en Elasticsearch.

20 de febrero de 2026
Garantizar la precisión semántica con una puntuación mínima
Mejora la precisión semántica con umbrales de puntuación mínima. El artículo incluye ejemplos concretos de búsqueda semántica e híbrida.

11 de diciembre de 2025
Evaluación de la relevancia de las consultas de búsqueda con listas de evaluaciones
Explora cómo crear listas de evaluación para evaluar objetivamente la relevancia de las consultas de búsqueda y mejorar métricas de rendimiento como la recuperación, para pruebas de búsqueda escalables en Elasticsearch.