Recientemente, OpenAI anunció la característica de conectores personalizados para ChatGPT en los planes Pro/Business/Enterprise y Edu. Además de los conectores listos para usar que permiten acceder a datos en Gmail, GitHub, Dropbox, etc. Es posible crear conectores personalizados utilizando servidores MCP.
Los conectores personalizados te permiten combinar tus conectores de ChatGPT existentes con otras fuentes de datos como Elasticsearch para obtener respuestas integrales.
En este artículo, crearemos un servidor MCP que conecta ChatGPT a un índice de Elasticsearch que contiene información sobre incidencias internas de GitHub y solicitudes de extracción. Esto permite responder a búsquedas en lenguaje natural mediante los datos de Elasticsearch.
Desplegaremos el servidor MCP utilizando FastMCP en Google Colab con ngrok para obtener una URL pública a la que ChatGPT pueda conectarse, lo que eliminará la necesidad de una infraestructura compleja.
Para una visión general del MCP y su ecosistema, consulta El estado actual de MCP.
Prerrequisitos
Antes de comenzar, necesitarás:
- Clúster de Elasticsearch (8.X o superior).
- Clave API de Elasticsearch con acceso de lectura a tu índice.
- Cuenta de Google (para Google Colab)
- Cuenta de Ngrok (el nivel gratuito funciona)
- Cuenta de ChatGPT con plan Pro/Enterprise/Business o Edu.
Comprensión de los requisitos del conector MCP de ChatGPT.
Los conectores MCP de ChatGPT requieren la implementación de dos herramientas: search y fetch. Para más detalles, consulta OpenAI Docs.
Herramienta de búsqueda
Devuelve una lista de resultados relevantes de tu índice de Elasticsearch según la búsqueda del usuario.
Lo que recibe:
- Un solo texto con la búsqueda de lenguaje natural del usuario.
- Ejemplo: “Encuentra incidencias relacionadas con la migración de Elasticsearch”.
Lo que devuelve:
- Un objeto con una clave
resultque contiene un arreglo de objetos de resultado. Cada resultado incluye:id- Identificador único de documentos.title- Título de la incidencia o PR.url- Enlace a la incidencia o PR.
En nuestra implementación:
Herramienta de extracción
Recupera el contenido completo de un documento específico.
Lo que recibe:
- Una sola cadena de texto con el ID del documento de Elasticsearch del resultado de la búsqueda.
- Ejemplo: “Consígueme los detalles de PR-578”.
Lo que devuelve:
- Un objeto de documento completo con:
id- Identificador único de documentos.title- Título de la incidencia o PR.text- Descripción completa del problema/PR y sus detallesurl- Enlace a la incidencia o PR.type- Tipo de documento (incidencia, pull_request).status- Estado actual (abierto, en progreso, resuelto)priority- Nivel de prioridad (bajo, medio, alto, crítico)assignee- Persona asignada al problema/PRcreated_date- Fecha de creación.resolved_date- Cuando se resolvió (si procede)labels- Etiquetas asociadas al documentorelated_pr- ID de solicitud de extracción relacionado
Nota: Este ejemplo usa una estructura plana donde todos los campos están en el nivel raíz. Los requisitos de OpenAI son flexibles y también admiten objetos de metadatos anidados.
Sets de datos de incidencias y PR de GitHub
Para este tutorial, vamos a usar un set de datos interno de GitHub que contenga incidencias y solicitudes de extracción. Esto representa un escenario en el que deseas buscar datos internos privados a través de ChatGPT.
Los sets de datos se pueden encontrar aquí. Y actualizaremos el índice de los datos mediante la API de bulk.
Este sets de datos incluye:
- Problemas con descripciones, estado, prioridad y responsables.
- Solicitudes de extracción con cambios de código, revisiones e información de despliegue.
- Relaciones entre incidencias y PR (p. ej., PR-578 soluciona ISSUE-1889).
- Etiquetas, fechas y otros metadatos
Mappings de índices
El índice utiliza los siguientes mappings para brindar soporte a la búsqueda híbrida con ELSER. El campo text_semantic se utiliza para la búsqueda semántica, mientras que los demás campos permiten la búsqueda por palabras clave.
Construye el servidor MCP
Nuestro servidor MCP implementa dos herramientas que siguen las especificaciones de OpenAI, y utilizan búsquedas híbridas para combinar coincidencia semántica y textual para obtener mejores resultados.
Herramienta de búsqueda
Usa la búsqueda híbrida con RRF (Fusión de Rango Recíproco), combinando la búsqueda semántica con la coincidencia de texto:
Puntos clave:
- Búsqueda híbrida con RRF: Combina búsqueda semántica (ELSER) y búsqueda por texto (BM25) para mejores resultados.
- Búsqueda de múltiples coincidencias: Busca en múltiples campos con mejores ponderaciones (título^3, texto^2, responsable^2). El símbolo de intercalación (^) multiplica las puntuaciones de relevancia, y prioriza las coincidencias en los títulos sobre el contenido.
- Correspondencia aproximada:
fuzziness: AUTOmaneja los errores tipográficos y ortográficos al permitir coincidencias aproximadas. - Ajuste de parámetros de RRF:
rank_window_size: 50- Especifica cuántos resultados principales de cada recuperador (semántico y textual) se consideran antes de combinarlos.rank_constant: 60- Este valor determina cuánta influencia tienen los documentos en los conjuntos de resultados individuales sobre el resultado final clasificado.
- Solo devuelve los campos obligatorios:
id,title,urlsegún la especificación de OpenAI, y evita exponer otros campos innecesariamente.
Herramienta de extracción
Recupera los detalles del documento por ID de documento, si existe:
Puntos clave:
- Búsqueda por campo de ID de documento: usa la búsqueda de término en el campo personalizado
id. - Devuelve el documento completo: incluye el campo completo
textcon todo el contenido. - Estructura plana: todos los campos en el nivel raíz, coincidiendo con la estructura de documentos de Elasticsearch.
Desplegar en Google Colab
Usaremos Google Colab para ejecutar nuestro servidor MCP y ngrok para exponerlo públicamente de forma tal que ChatGPT pueda conectarse.
Paso 1: Abre el cuaderno de Google Colab.
Accede a nuestro cuaderno preconfigurado Elasticsearch MCP para ChatGPT.
Paso 2: Configura tus credenciales
Necesitarás tres datos:
- URL de Elasticsearch: Tu URL del cluster de Elasticsearch.
- Clave API de Elasticsearch: Clave API con acceso de lectura a tu índice.
- Token de autenticación ngrok: Token gratis de ngrok. Usaremos ngrok para exponer la URL de MCP a internet y así ChatGPT pueda conectarse.
Obtener tu token ngrok
- Regístrate para una cuenta gratis en ngrok
- Ve a tu dashboard de ngrok
- Copia tu token de autenticación
Agregar secretos a Google Colab
En el cuaderno de Google Colab:
- Haz clic en el icono de llave en la barra lateral izquierda para abrir Secretos.
- Añade estos tres secretos:
3. Habilitar el acceso al cuaderno para cada secreto

Paso 3: Ejecutar el cuaderno
- Haz clic en Tiempo de ejecución y, a continuación, en Ejecutar todo para ejecutar todas las celdas.
- Espera que el servidor se inicie (aproximadamente 30 segundos).
- Busque la salida que muestre su URL pública de ngrok

4. La salida mostrará algo como:

Conéctate a ChatGPT.
Ahora conectaremos el servidor MCP a tu cuenta de ChatGPT.
- Abre ChatGPT y ve a Configuración.
- Navega a Conectores.Si estás usando una cuenta Pro, debes activar el modo de desarrollador en los conectores.
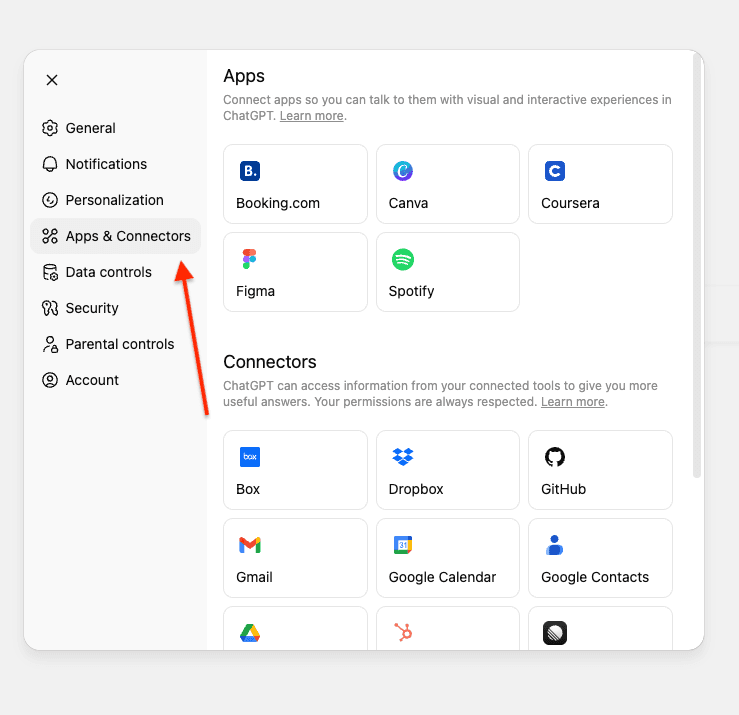
Si estás usando la versión Enterprise o Business de ChatGPT, debes publicar el conector en tu lugar de trabajo.
3. Haz clic en Crear.

Nota: En los espacios de trabajo Business, Enterprise y Edu, solo los propietarios, administradores y usuarios que tengan habilitada la correspondiente configuración (para Enterprise/Edu) pueden agregar conectores personalizados. Los usuarios con un rol de miembro común no tienen la capacidad de agregar conectores personalizados por su cuenta.
Una vez que un propietario o usuario administrador agrega un conector y lo habilita, estará disponible para que lo usen todos los miembros del espacio de trabajo.
4. Introduce la información requerida y la URL de tu ngrok que termina en /sse/. Recuerda la “/” después de “sse”. No funcionará si no la agregas:
- Nombre: Elasticsearch MCP
- Descripción: MCP personalizado para buscar y extraer información interna de GitHub.

5. Presione Crear para guardar el MCP personalizado.

La conexión es instantánea si tu servidor está en funcionamiento. No se necesita ninguna otra autenticación, ya que la clave API de Elasticsearch está configurada en tu servidor.
Prueba el servidor MCP
Antes de hacer preguntas, necesitas seleccionar qué conector ChatGPT debe usar.

Indicación 1: Buscar incidencias
Pregunta: “Encuentre incidencias relacionadas con la migración de Elasticsearch” y confirma la llamada a la herramienta de acciones.
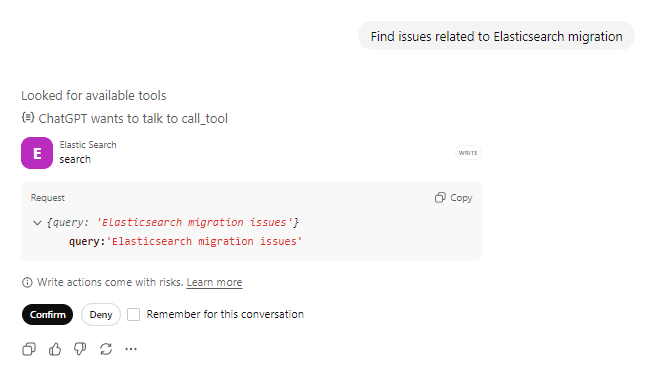
ChatGPT llamará a la herramienta search con tu búsqueda. Puedes ver que está buscando herramientas disponibles y preparándose para llamar a la herramienta Elasticsearch y confirma con el usuario antes de tomar cualquier acción en relación con la herramienta.
Solicitud de llamada a la herramienta:
Respuesta de la herramienta:
ChatGPT procesa los resultados y los presenta en un formato natural y conocido.

Entre bastidores
Indicación: “Busca incidencias relacionadas con la migración de Elasticsearch”
1. Llamadas de ChatGPT search(“Elasticsearch migration”)
2. Elasticsearch realiza una búsqueda híbrida
- La búsqueda semántica entiende conceptos como “actualización” y “compatibilidad de versiones”.
- La búsqueda de texto encuentra coincidencias exactas de "Elasticsearch" y "migración".
- RRF combina y clasifica los resultados de ambos enfoques
3. Devuelve los 10 mejores eventos que coinciden con id, title, url
4. ChatGPT identifica “ISSUE-1712: migrar de Elasticsearch 7.x a 8.x” como el resultado más relevante.
Indicación 2: Obtén los detalles completos
Pregunta: “Obtén detalles de ISSUE-1889”

ChatGPT reconoce que deseas información detallada sobre una incidencia específica, llama a la herramienta fetch y confirma con el usuario antes de tomar cualquier acción con la herramienta.
Solicitud de llamada a la herramienta:
Respuesta de la herramienta:
ChatGPT sintetiza la información y la presenta de manera clara.


Entre bastidores
Indicación: «Obtén los detalles de ISSUE-1889»
- Llamadas de ChatGPT
fetch(“ISSUE-1889”) - Elasticsearch recupera el documento completo
- Devuelve un documento completo con todos los campos a nivel raíz.
- ChatGPT sintetiza la información y responde con citas adecuadas.
Conclusión
En este artículo, creamos un servidor MCP personalizado que conecta ChatGPT a Elasticsearch con herramientas MCP dedicadas de búsqueda y extracción, lo cual permite realizar búsquedas en lenguaje natural sobre datos privados.
Este patrón MCP funciona para cualquier índice, documentación, productos, logs o cualquier otro dato de Elasticsearch que quieras buscar mediante lenguaje natural.
Contenido relacionado

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

23 de marzo de 2026
Uso de la API de inferencia de Elasticsearch junto con modelos de Hugging Face
Aprende a conectar Elasticsearch a modelos de Hugging Face usando endpoints de inferencia y crea un sistema multilingüe de recomendación de blogs con búsqueda semántica y finalización de chat.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.