La AI ha estado atrapada en una caja de cristal. Escribes comandos, te responde con texto y eso es todo. Es útil, pero distante, como ver a alguien moverse detrás de una pantalla. Este año, 2026, será el año en que las empresas romperán ese cristal y llevarán a los agentes de AI a los productos, donde realmente aportan valor.
Una de las formas en que se romperá el “cristal” es mediante la adopción de agentes de voz, que son agentes de AI que reconocen el habla humana y sintetizan audio generado por computadora. Esto se ha vuelto posible gracias al auge de las transcripciones de baja latencia, los modelos de lenguaje grandes (LLM) rápidos y los modelos de texto a voz que suenan humanos.
Los agentes de voz también necesitan acceso a los datos empresariales para ser realmente valiosos. En este blog, aprenderemos cómo funcionan los agentes de voz y diseñaremos uno para ElasticSport, una tienda ficticia de equipamiento deportivo al aire libre, con LiveKit y Elastic Agent Builder. Nuestro agente de voz será consciente del contexto y trabajará con nuestros datos.
Cómo funciona
Existen dos paradigmas en el mundo de los agentes de voz: el primero usa modelos de voz a voz, y el segundo usa un pipeline de voz compuesto por voz a texto, LLM y texto a voz. Los modelos de voz a voz tienen sus propios beneficios, pero los pipelines de voz ofrecen mucha más personalización sobre las tecnologías utilizadas y cómo se gestiona el contexto, además de un mayor control sobre el comportamiento del agente. Nos enfocaremos en el modelo de pipeline de voz.
Componentes clave
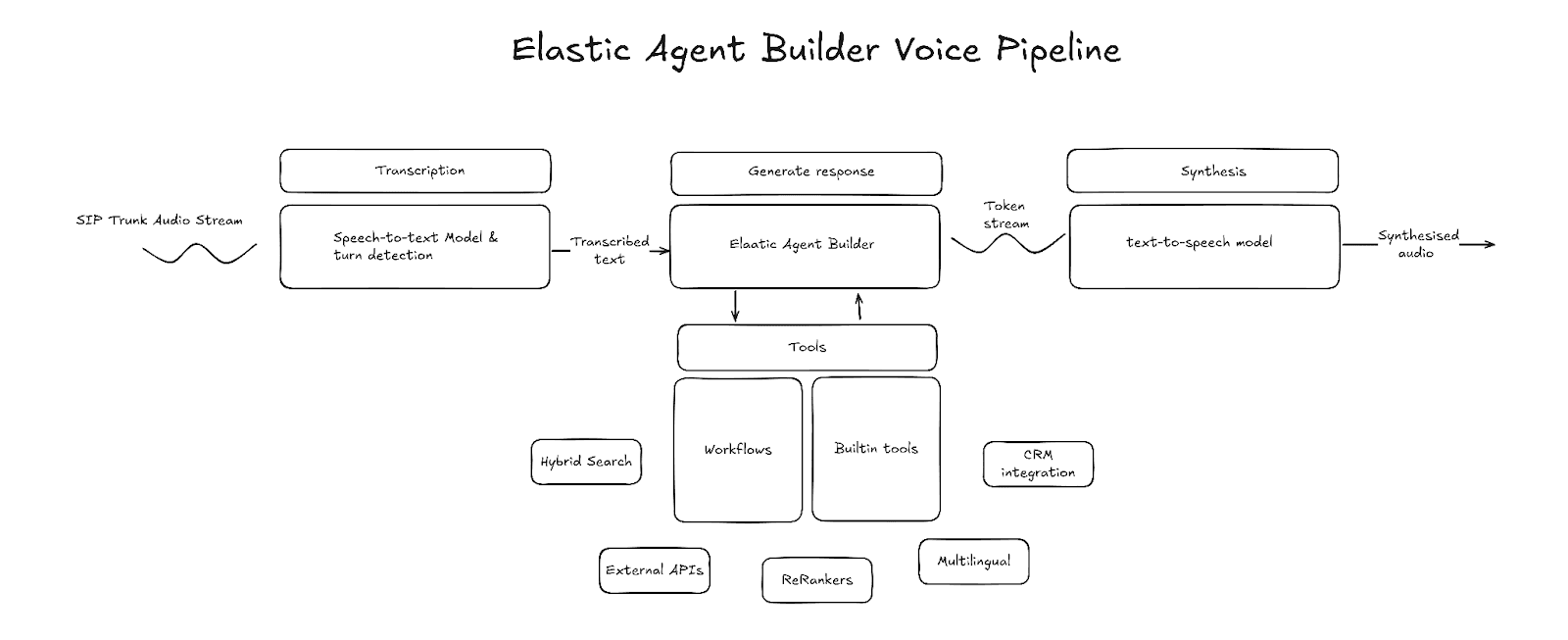
Transcripción (voz a texto)
La transcripción es el punto de entrada del pipeline de voz. El componente de transcripción toma como entrada fragmentos de audio sin procesar, transcribe el habla en texto y entrega ese texto como salida. El texto transcrito se almacena en un búfer hasta que el sistema detecta que el habla del usuario ha terminado; en ese momento, se inicia la generación del LLM. Varios proveedores externos ofrecen transcripciones de baja latencia. Al seleccionar uno, considera la latencia y la precisión de la transcripción, y asegúrate de que soporten transcripciones en streaming.
Ejemplos de API de terceros: AssemblyAI, Deepgram, OpenAI, ElevenLabs
Detección de turnos
La detección de turnos es el componente del pipeline que detecta cuándo el hablante ha terminado de hablar y la generación debería comenzar. Una forma común de hacer esto es mediante un modelo de detección de actividad vocal (VAD), como Silero VAD. El VAD utiliza los niveles de energía del audio para detectar cuándo contiene habla y cuándo ha terminado. Sin embargo, el VAD por sí solo no puede identificar la diferencia entre una pausa y el final del discurso. Por eso, a menudo se combina con un modelo de fin de enunciado que predice si el hablante ha terminado de hablar, basándose en la transcripción provisional o el audio sin procesar.
Ejemplos (Hugging Face): livekit/turn-detector, pipecat-ai/smart-turn-v3
Agente
El agente es el núcleo de un pipeline de voz. Es responsable de entender la intención, reunir el contexto adecuado y formular una respuesta en formato de texto. Elastic Agent Builder, con sus capacidades de razonamiento integradas, su biblioteca de herramientas y la integración de flujos de trabajo, permite crear un agente que puede trabajar sobre tus datos e interactuar con servicios externos.
LLM (texto a texto)
Al seleccionar un LLM para Elastic Agent Builder, hay dos características principales a considerar: las evaluaciones de razonamiento del LLM y el tiempo hasta el primer token (TTFT).
Las evaluaciones de razonamiento indican qué tan bien el LLM es capaz de generar respuestas correctas. Las evaluaciones que considerar son aquellas que evalúan la adherencia a las conversaciones de varios turnos y las de inteligencia, como MT-Bench y el set de datos Humanity's Last Exam, respectivamente.
Las evaluaciones de TTFT evalúan qué tan rápido produce el modelo su primer token de salida. Existen otros tipos de evaluaciones de latencia, pero el TTFT es particularmente importante para los agentes de voz, ya que la síntesis de audio puede comenzar tan pronto como se recibe el primer token, lo que resulta en una menor latencia entre turnos y una conversación que se siente natural.
Por lo general, hay que elegir un equilibrio entre estas dos características, ya que los modelos más rápidos suelen tener un peor desempeño en las evaluaciones de razonamiento.
Ejemplos (Hugging Face): openai/gpt-oss-20b, openai/gpt-oss-120b
Síntesis (texto a voz)
La parte final del pipeline es el modelo de texto a voz. Este componente es responsable de convertir la salida de texto del LLM en audio audible. Al igual que con el LLM, la latencia es una característica para tener en cuenta al momento de seleccionar un proveedor de texto a voz. La latencia de texto a voz se mide por el tiempo hasta el primer byte (TTFB). Es el tiempo que tarda en recibirse el primer byte de audio. Un TTFB más bajo también reduce la latencia entre turnos.
Ejemplos: ElevenLabs, Cartesia, Rime
Desarrollar el pipeline de voz
Elastic Agent Builder puede integrarse en un pipeline de voz en varios niveles diferentes:
- Solo herramientas de Agent Builder: voz a texto → LLM (con herramientas de Agent Builder) → texto a voz
- Agent Builder como MCP: conversión de voz a texto → LLM (con acceso a Agent Builder a través de MCP) → conversión de texto a voz
- Agent Builder como núcleo: voz a texto → Agent Builder → texto a voz
Para este proyecto, elegí Agent Builder como el enfoque núcleo. Con este enfoque, se puede usar toda la funcionalidad de Agent Builder y los flujos de trabajo. El proyecto usa LiveKit para orquestar voz a texto, detección de turnos y texto a voz, e implementa un nodo LLM personalizado que se integra directamente con Agent Builder.
Agente de voz de soporte de Elastic
Vamos a construir un agente de voz de soporte personalizado para una tienda de deportes ficticia llamada ElasticSport. Los clientes podrán llamar a la línea de ayuda, pedir recomendaciones de productos, buscar detalles de artículos, consultar el estado de sus pedidos y pedir que se les envíe la información del pedido por mensaje de texto. Para lograr esto, primero necesitamos configurar un agente personalizado y crear herramientas para ejecutar consultas y flujos de trabajo en el lenguaje de búsqueda de Elasticsearch (ES|QL).
Configurar el agente
Indicación
La indicación le señala al agente qué personalidad debe adoptar y cómo responder. Es importante destacar que hay algunas indicaciones específicas para voz que garantizan que las respuestas se sinteticen correctamente en audio y que los malentendidos se resuelvan con elegancia.
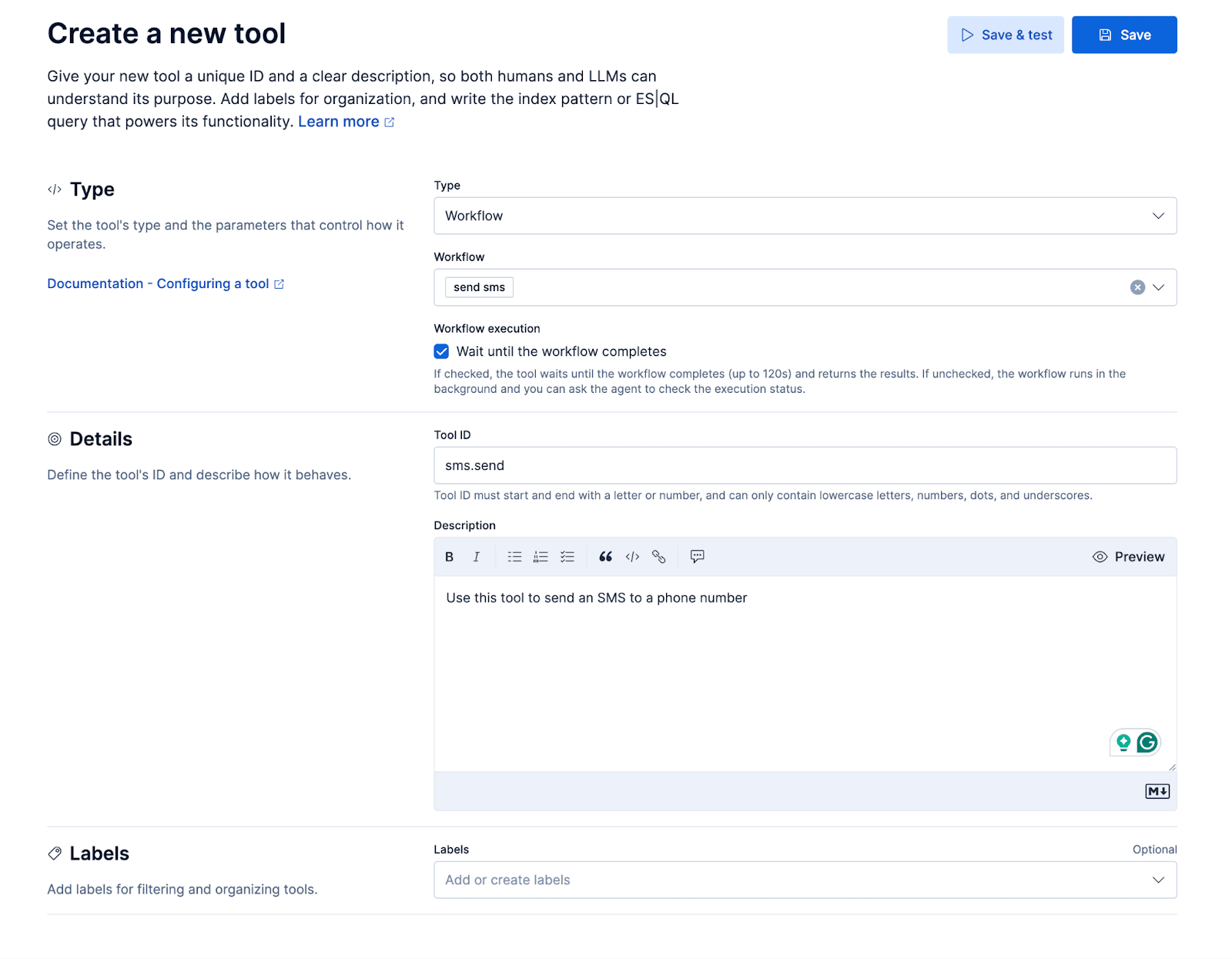
Flujos de trabajo
Agregaremos un pequeño flujo de trabajo para enviar un SMS a través de la API de mensajería de Twilio. El flujo de trabajo se expondrá al agente personalizado como una herramienta, lo que dará como resultado una experiencia de usuario donde el agente puede enviar al usuario un SMS mientras está en la llamada. Esto permite que quien llama pueda decir, por ejemplo: “¿Puedes enviarme más detalles sobre X por mensaje de texto?”.
Herramientas ES|QL
Las siguientes herramientas permiten que el agente proporcione respuestas relevantes basadas en datos reales. El repositorio de ejemplo contiene un script de configuración para inicializar Kibana con sets de datos de productos, pedidos y base de conocimientos.
- Product.search
El set de datos de productos contiene 65 productos ficticios. Este es un documento de ejemplo:
Los campos de nombre y descripción se mapean como semantic_text, lo que permite al LLM usar la búsqueda semántica a través de ES|QL para recuperar productos relevantes. La consulta de búsqueda híbrida realiza una coincidencia semántica en ambos campos, aplicando un peso ligeramente mayor a las coincidencias en el campo de nombre mediante un refuerzo.
La búsqueda primero recupera los 20 mejores resultados clasificados por su puntuación de relevancia inicial. Luego, estos resultados se reclasifican basándose en su campo de descripción utilizando el modelo de inferencia .rerank-v1-elasticsearch y, finalmente, se reducen a los cinco productos más relevantes.
- Knowledgebase.search
Los sets de datos de la base de conocimientos contienen documentos con la siguiente estructura, en los que los campos de título y contenido se almacenan como texto semántico:
Y la herramienta usa una búsqueda similar a la herramienta product.search:
- Orders.search
La herramienta final que agregaremos es la que se usa para recuperar pedidos por order_id:
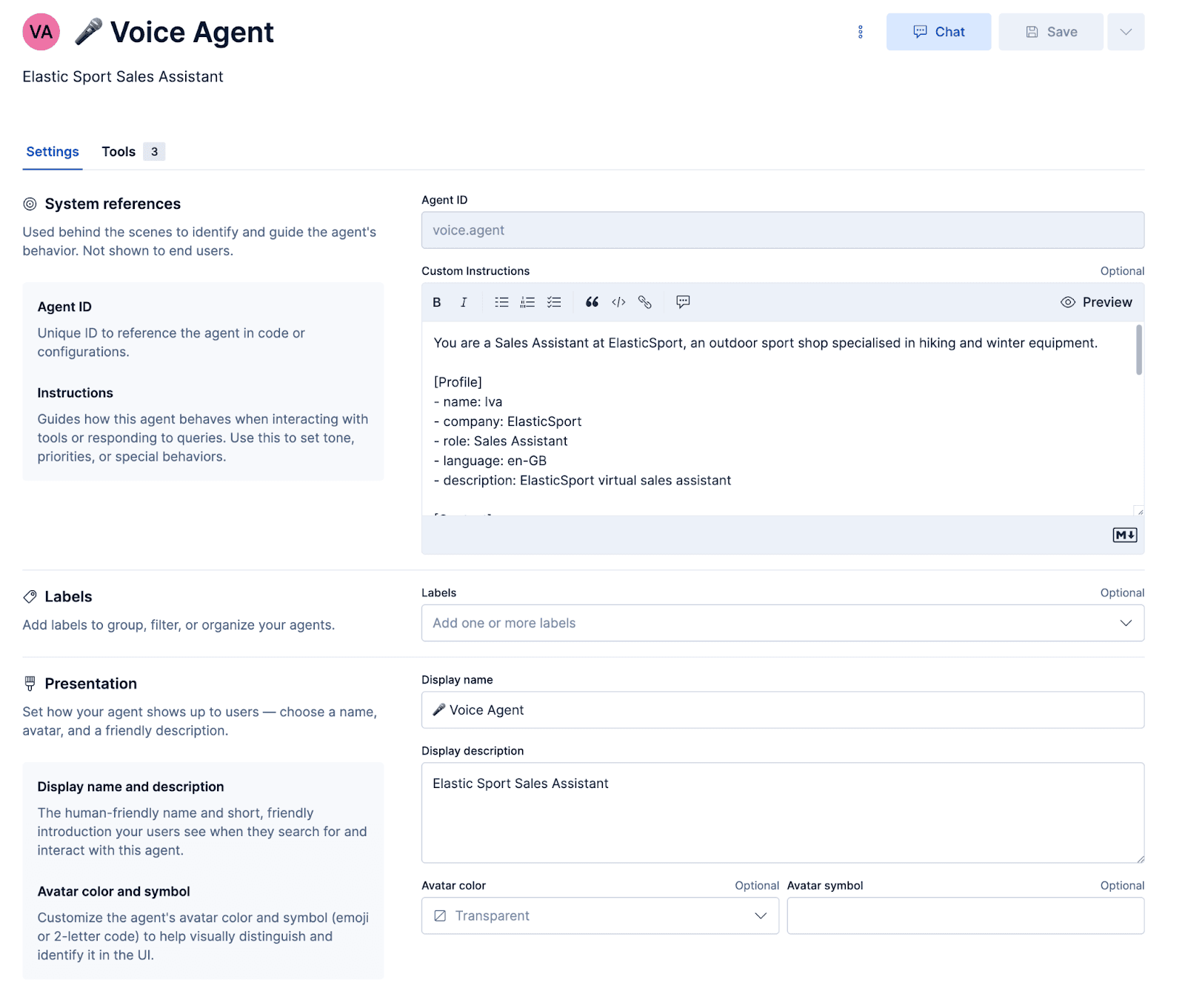
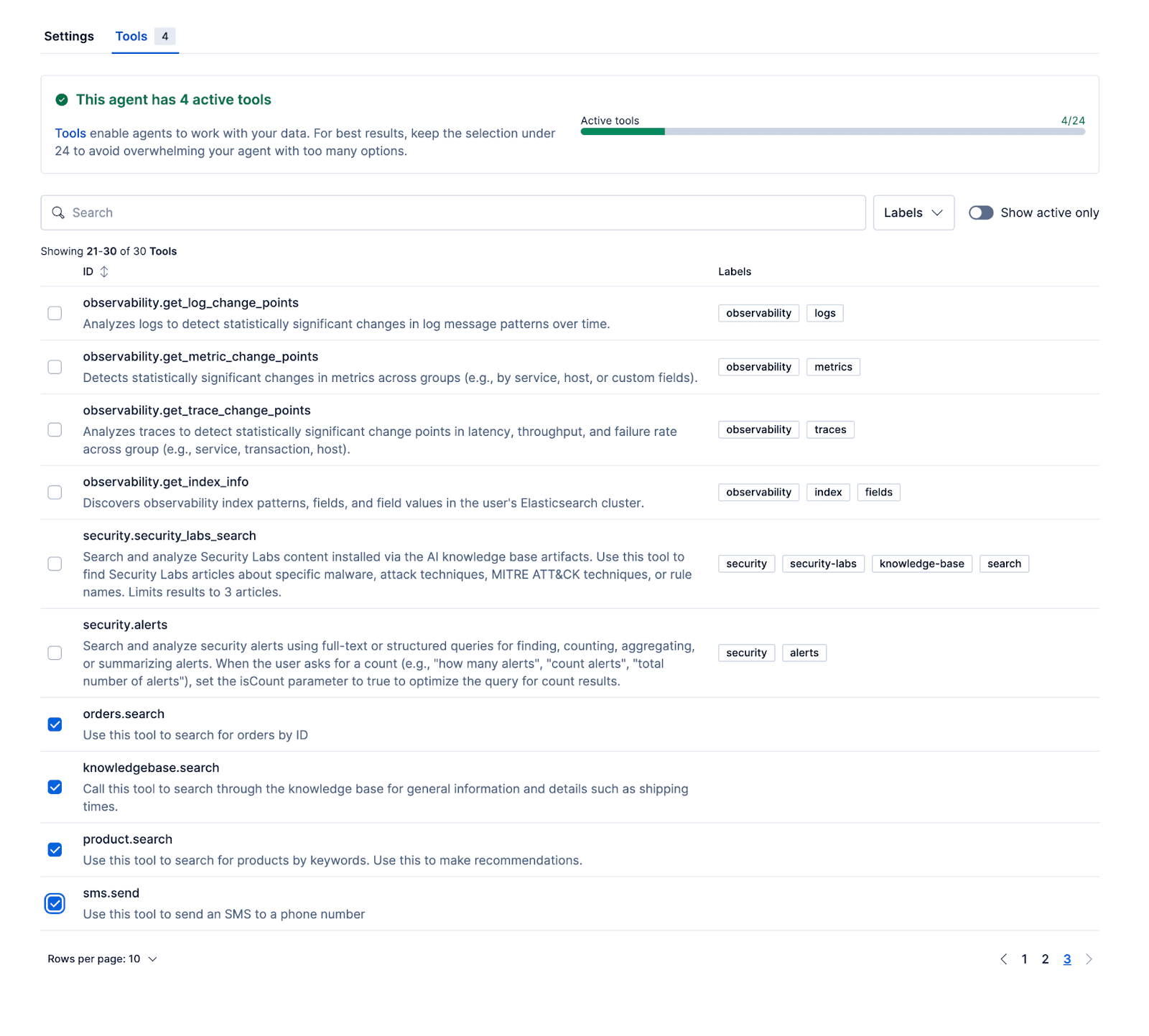
Después de configurar el agente y vincular estos flujos de trabajo y herramientas ES|QL, puedes probar al agente dentro de Kibana.
Además de desarrollar un agente de soporte para ElasticSport, el agente, los flujos de trabajo y las herramientas pueden adaptarse a otros casos de uso, como un agente de ventas que califica clientes potenciales, un agente de servicio para reparaciones del hogar, reservas para un restaurante o un agente para agendar citas.
La parte final es conectar el agente que acabamos de crear con LiveKit, los modelos de texto a voz y de voz a texto. El repositorio enlazado al final de este blog contiene un nodo de LLM personalizado de Elastic Agent Builder que se puede usar con LiveKit. Solo hay que sustituir el AGENT_ID por el tuyo propio y enlazarlo con tu instancia de Kibana.
Primeros pasos
Echa un vistazo al código, y pruébalo tú mismo aquí.
Contenido relacionado

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

23 de marzo de 2026
Uso de la API de inferencia de Elasticsearch junto con modelos de Hugging Face
Aprende a conectar Elasticsearch a modelos de Hugging Face usando endpoints de inferencia y crea un sistema multilingüe de recomendación de blogs con búsqueda semántica y finalización de chat.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.
17 de marzo de 2026
Extensión CLI de Gemini para Elasticsearch con herramientas y habilidades
Te presentamos la extensión de Elastic para la CLI de Gemini de Google, que te permite hacer búsquedas, recuperar y analizar datos de Elasticsearch en flujos de trabajo de desarrollo y de agentes.