L’IA est restée enfermée dans une boîte en verre. Vous tapez des commandes, elle répond par du texte. Et c’est tout. C’est utile, mais distant. Comme observer quelqu’un derrière un écran. Cette année, 2026, marquera un tournant : les entreprises briseront cette vitre pour intégrer des agents d’IA dans leurs produits – là où ils apportent une vraie valeur.
L’un des moyens de briser la vitre : adopter des agents vocaux, autrement dit des agents IA capables de comprendre la voix humaine et de produire un son de synthèse. Grâce à l’essor des transcriptions à faible latence, des modèles de langage de grande taille (LLM) rapides et des systèmes de synthèse vocale au rendu naturel, cette vision devient réalité.
Pour réellement créer de la valeur, les agents vocaux doivent aussi avoir accès aux données métier. Dans ce billet, nous verrons comment fonctionnent les agents vocaux et comment en créer un pour ElasticSport, une boutique fictive d’équipements de sport de plein air, à l’aide de LiveKit et Elastic Agent Builder. Notre agent vocal sera sensible au contexte et s’appuiera sur nos données.
Fonctionnement
Le monde des agents vocaux repose sur deux grands paradigmes : le premier s’appuie sur des modèles de conversion vocale directe (speech-to-speech), le second sur une chaîne vocale composée de reconnaissance vocale, de LLM et de synthèse vocale. Les modèles speech-to-speech ont leurs avantages, mais les chaînes vocales permettent une personnalisation bien plus poussée des technologies employées et de la gestion du contexte, ainsi qu’un contrôle plus fin du comportement de l’agent. Nous allons nous concentrer sur le modèle basé sur la chaîne vocale.
Composants clés
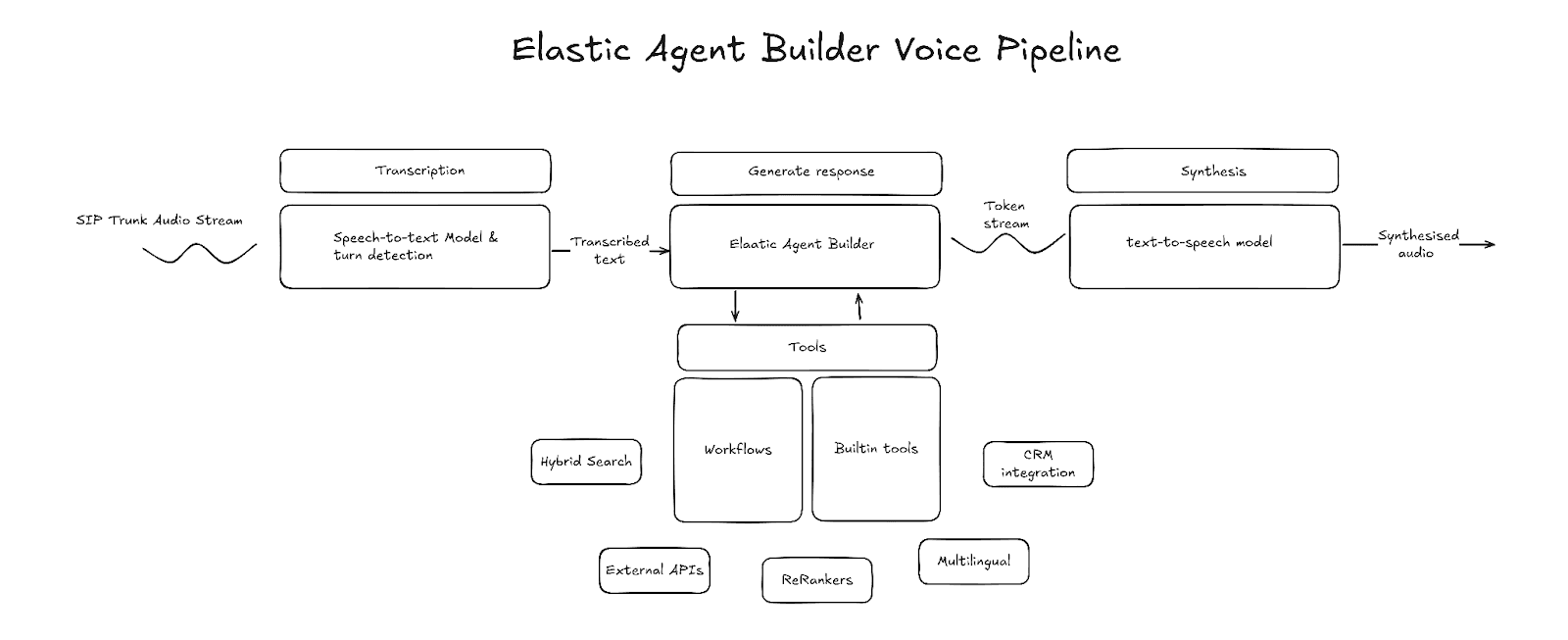
Transcription (reconnaissance vocale)
La transcription est le point d’entrée de la chaîne vocale. Le composant de transcription reçoit des trames audio brutes en entrée, convertit la voix en texte, puis restitue ce texte en sortie. Le texte transcrit est mis en mémoire tampon jusqu’à ce que le système détecte la fin de la prise de parole de l’utilisateur – c’est alors que la génération par le LLM démarre. Plusieurs prestataires tiers proposent des transcriptions à faible latence. Lors de votre sélection, tenez compte de la latence et de la précision de transcription, et vérifiez que le fournisseur prend en charge les transcriptions en flux continu.
Exemples d’API tierces : AssemblyAI, Deepgram, OpenAI, ElevenLabs
Détection de prise de parole
La détection de prise de parole est le composant de la chaîne qui identifie la fin de l’intervention de l’utilisateur, déclenchant ainsi la génération. Une méthode courante consiste à utiliser un modèle de détection d’activité vocale (VAD), comme Silero VAD. Le VAD s’appuie sur le niveau d’énergie du signal audio pour détecter la présence de parole et identifier la fin de l’intervention. Cependant, un VAD seul ne peut pas distinguer une pause de la fin d’une prise de parole. C’est pourquoi on l’associe souvent à un modèle de fin d’énoncé, capable de prédire si l’utilisateur a terminé de parler, en se basant sur la transcription provisoire ou l’audio brut.
Exemples (Hugging Face) : livekit/turn-detector, pipecat-ai/smart-turn-v3
Agent
L’agent constitue le cœur de la chaîne vocale. Il est chargé de comprendre l’intention, de récupérer le bon contexte et de formuler une réponse sous forme de texte. Elastic Agent Builder, avec ses fonctions de raisonnement intégrées, sa bibliothèque d’outils et son intégration aux workflows, permet de créer un agent capable d’exploiter vos données et d’interagir avec des services externes.
LLM (texte à texte)
Pour choisir un LLM dans Elastic Agent Builder, deux critères principaux sont à prendre en compte : les benchmarks de raisonnement du LLM et le temps jusqu’au premier jeton (TTFT).
Les benchmarks de raisonnement mesurent la capacité du LLM à produire des réponses pertinentes. Les benchmarks à privilégier sont ceux qui évaluent la cohérence des conversations à plusieurs tours et les capacités cognitives, comme MT-Bench et le jeu de données Humanity’s Last Exam, respectivement.
Les benchmarks TTFT évaluent la rapidité avec laquelle le modèle génère son premier jeton en sortie. Il existe d’autres types de benchmarks de latence, mais le TTFT est particulièrement crucial pour les agents vocaux, car la synthèse vocale peut démarrer dès réception du premier jeton. Résultat : une latence réduite entre les prises de parole et une conversation plus naturelle.
Il faut souvent faire un compromis entre ces deux critères, car les modèles plus rapides obtiennent généralement de moins bons résultats aux tests de raisonnement.
Exemples (Hugging Face) : openai/gpt-oss-20b, openai/gpt-oss-120b
Synthèse (texte à la parole)
La dernière étape de la chaîne consiste à convertir le texte en parole grâce à un modèle de synthèse vocale. Ce composant est chargé de convertir le texte généré par le LLM en parole audible. Comme pour les LLM, la latence est un critère important lors du choix d’un fournisseur de synthèse vocale. La latence de la synthèse vocale se mesure au temps jusqu’au premier octet (TTFB). C’est le délai nécessaire pour recevoir le tout premier octet audio. Un TTFB plus court permet aussi de réduire la latence entre les prises de parole.
Exemples : ElevenLabs, Cartesia, Rime
Construction du pipeline vocal
Elastic Agent Builder peut s’intégrer dans une chaîne vocale à différents niveaux :
- Outils Agent Builder uniquement : reconnaissance vocale → LLM (avec outils Agent Builder) → synthèse vocale
- Agent Builder en tant que MCP : reconnaissance vocale → LLM (avec accès Agent Builder via MCP) → synthèse vocale
- Agent Builder comme noyau central : reconnaissance vocale → Agent Builder → synthèse vocale
Pour ce projet, j’ai choisi d’utiliser Agent Builder comme solution centrale. Cette approche permet de tirer pleinement parti des fonctionnalités d’Agent Builder et des workflows. Le projet s’appuie sur LiveKit pour orchestrer la reconnaissance vocale, la détection de prise de parole et la synthèse vocale. Il implémente également un nœud LLM personnalisé, directement intégré à Agent Builder.
Agent vocal de support technique Elastic
Nous allons créer un agent vocal de support personnalisé pour une boutique de sport fictive, appelée ElasticSport. Les clients pourront appeler la ligne d’assistance, demander des recommandations de produits, consulter les fiches produit, vérifier le statut de leurs commandes, et recevoir les informations par message texte. Pour cela, nous devons commencer par configurer un agent personnalisé et créer des outils permettant d’exécuter des requêtes Elasticsearch Query Language (ES|QL) ainsi que des workflows.
Configuration de l'agent
Invite
L’invite détermine la personnalité que doit adopter l’agent et la façon dont il doit répondre. Il existe également quelques invites spécifiques à la voix, qui garantissent une synthèse vocale fluide et permettent de gérer élégamment les incompréhensions.
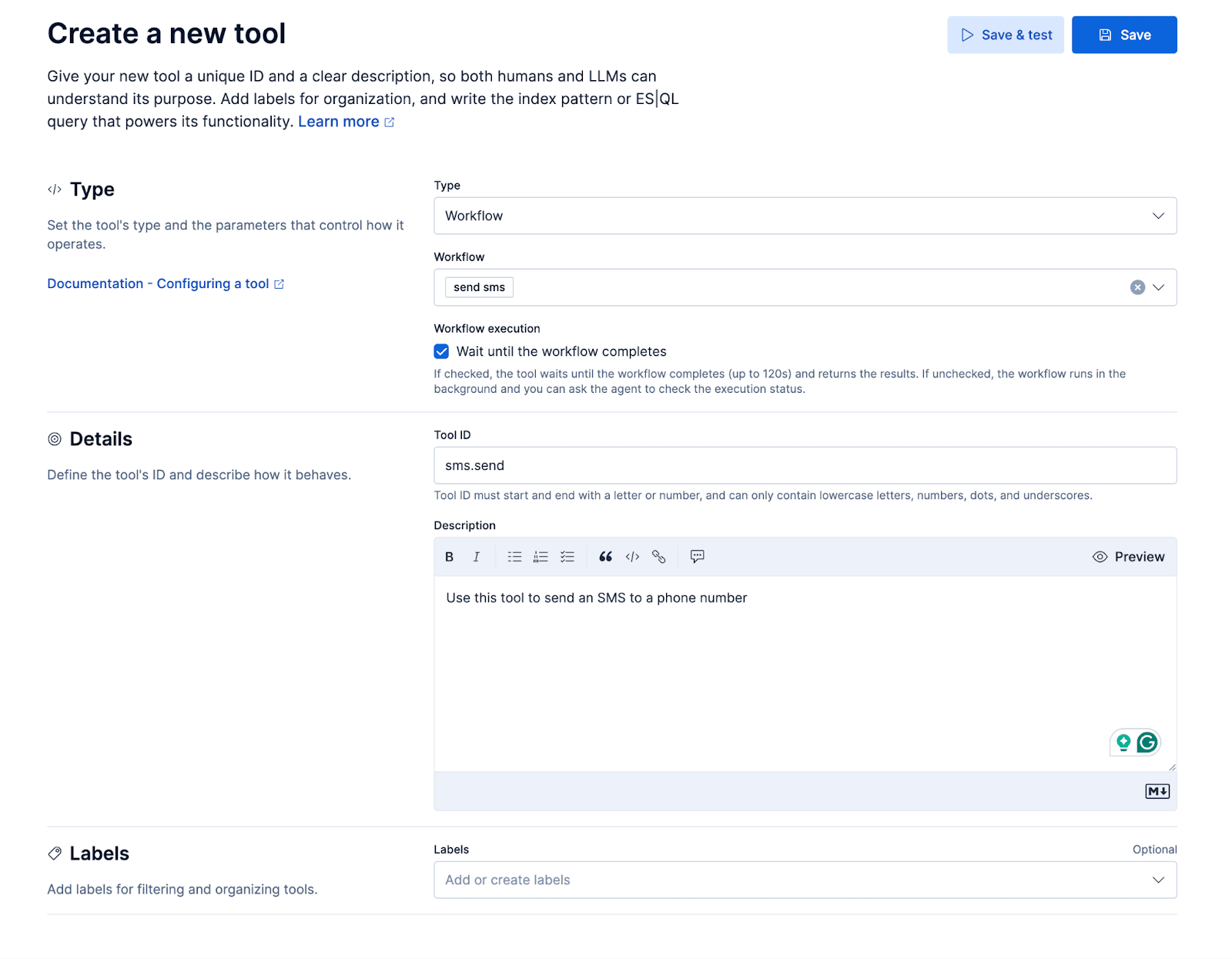
Workflows
Nous allons ajouter un petit workflow permettant d’envoyer un SMS via l’API de messagerie de Twilio. Ce workflow sera exposé à l’agent personnalisé sous forme d’outil, afin que l’agent puisse envoyer un SMS à l’appelant pendant l’appel. Cela permet à l’appelant, par exemple, de demander : « Pouvez-vous m’envoyer plus de détails sur X par SMS ? »
Outils ES|QL
Les outils suivants permettent à l’agent de fournir des réponses pertinentes, basées sur des données réelles. Le dépôt d’exemple contient un script d’initialisation de Kibana avec des jeux de données produits, commandes et base de connaissances.
- Product.search
Le jeu de données produit contient 65 produits fictifs. Voici un exemple de document :
Les champs « name » et « description » sont mappés sur semantic_text, ce qui permet au LLM d’effectuer une recherche sémantique via ES|QL pour retrouver les produits pertinents. La requête de recherche hybride effectue une correspondance sémantique sur les deux champs, en appliquant une pondération légèrement supérieure au champ « name » grâce à un boost.
La requête récupère d’abord les 20 meilleurs résultats, classés selon leur score de pertinence initial. Ces résultats sont ensuite reclassés en fonction de leur champ « description » à l’aide du modèle d’inférence .rerank-v1-elasticsearch , puis réduits aux cinq produits les plus pertinents.
- Knowledgebase.search
Les jeux de données de la base de connaissances contiennent des documents structurés comme suit, avec les champs de titre et de contenu stockés sous forme de texte sémantique :
L’outil utilise une requête similaire à celle de product.search :
- Orders.search
Le dernier outil que nous allons ajouter permet de récupérer les commandes à partir de order_id :
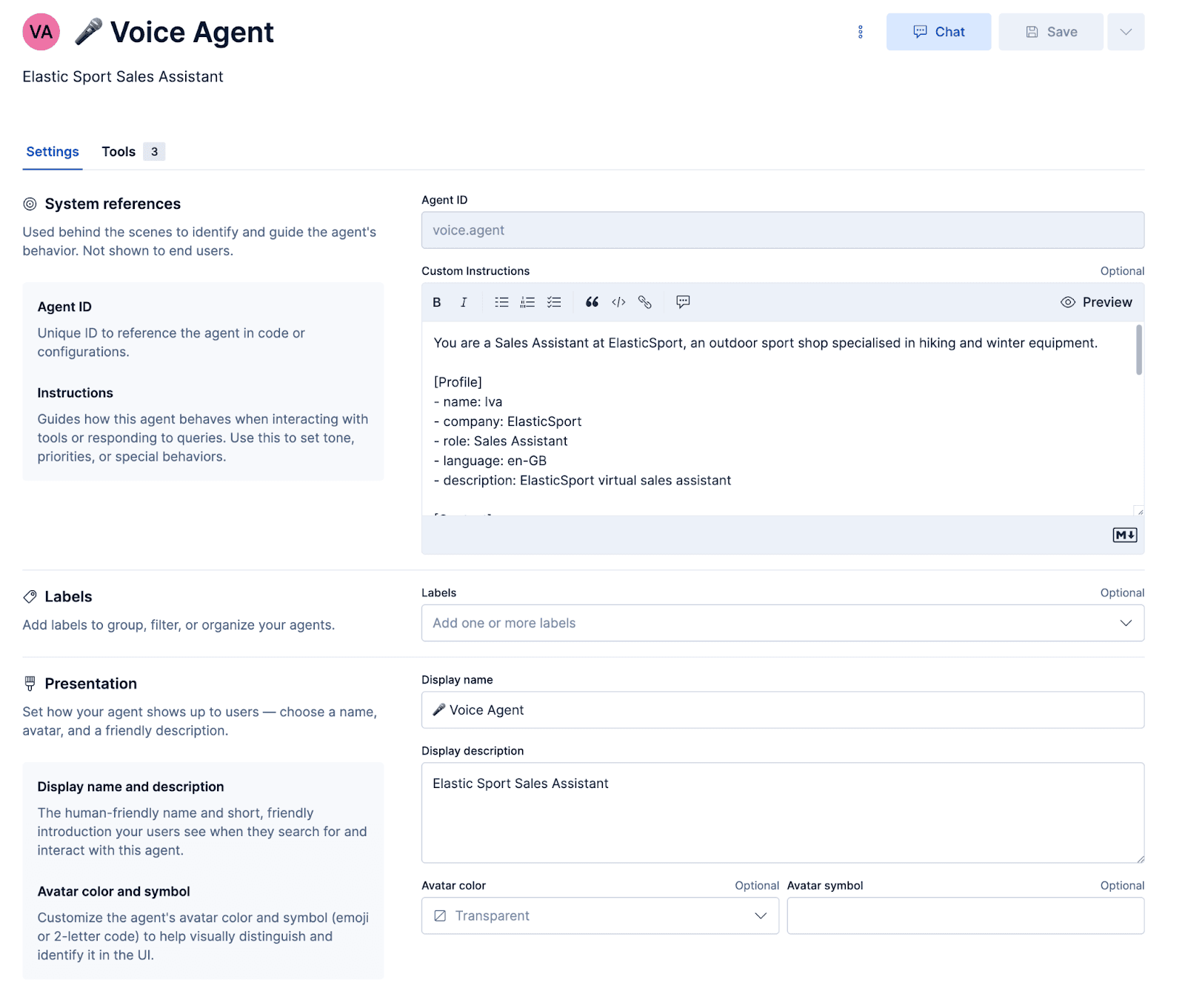
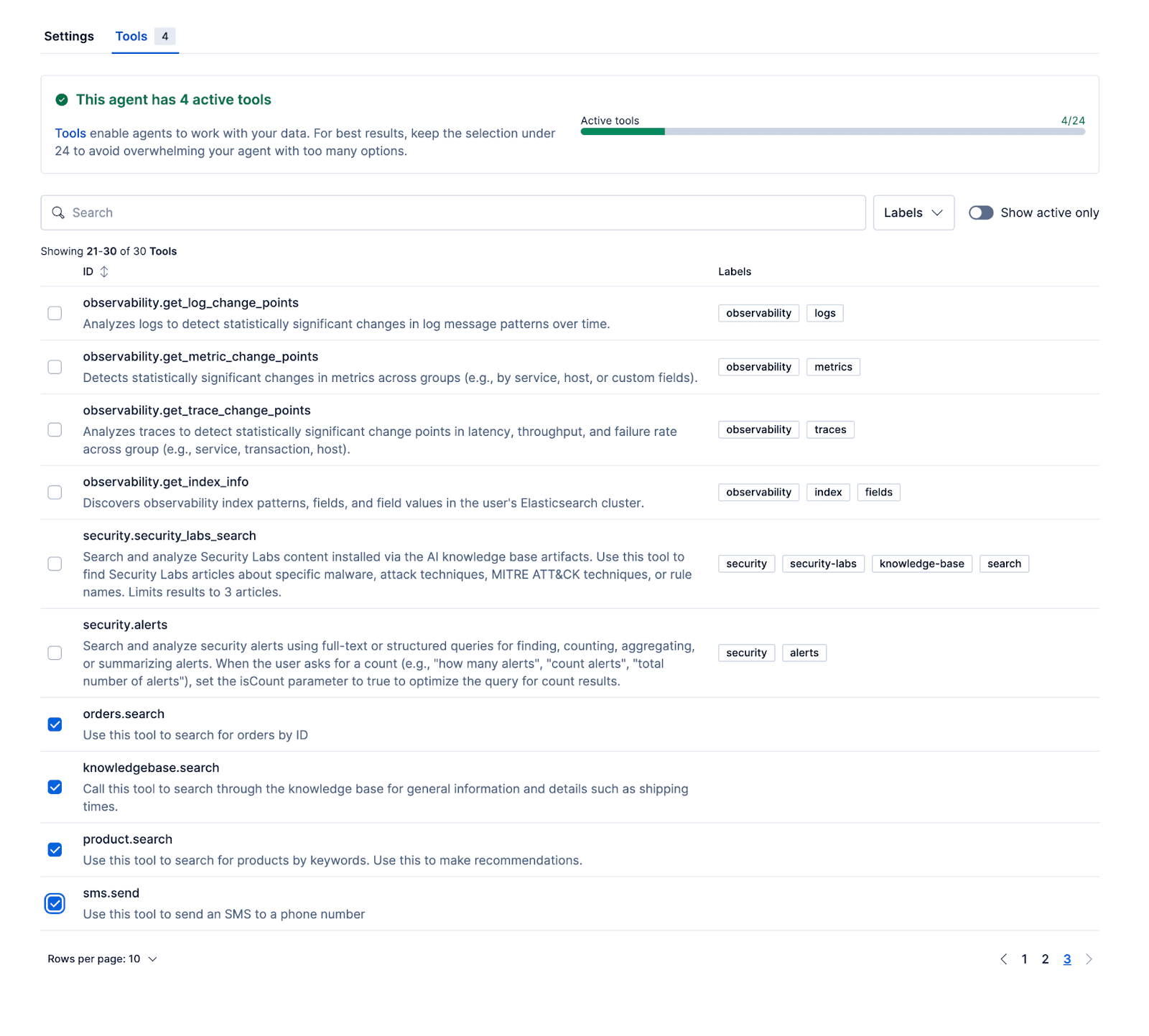
Une fois l’agent configuré et les workflows ainsi que les outils ES|QL associés, vous pouvez tester l’agent dans Kibana.
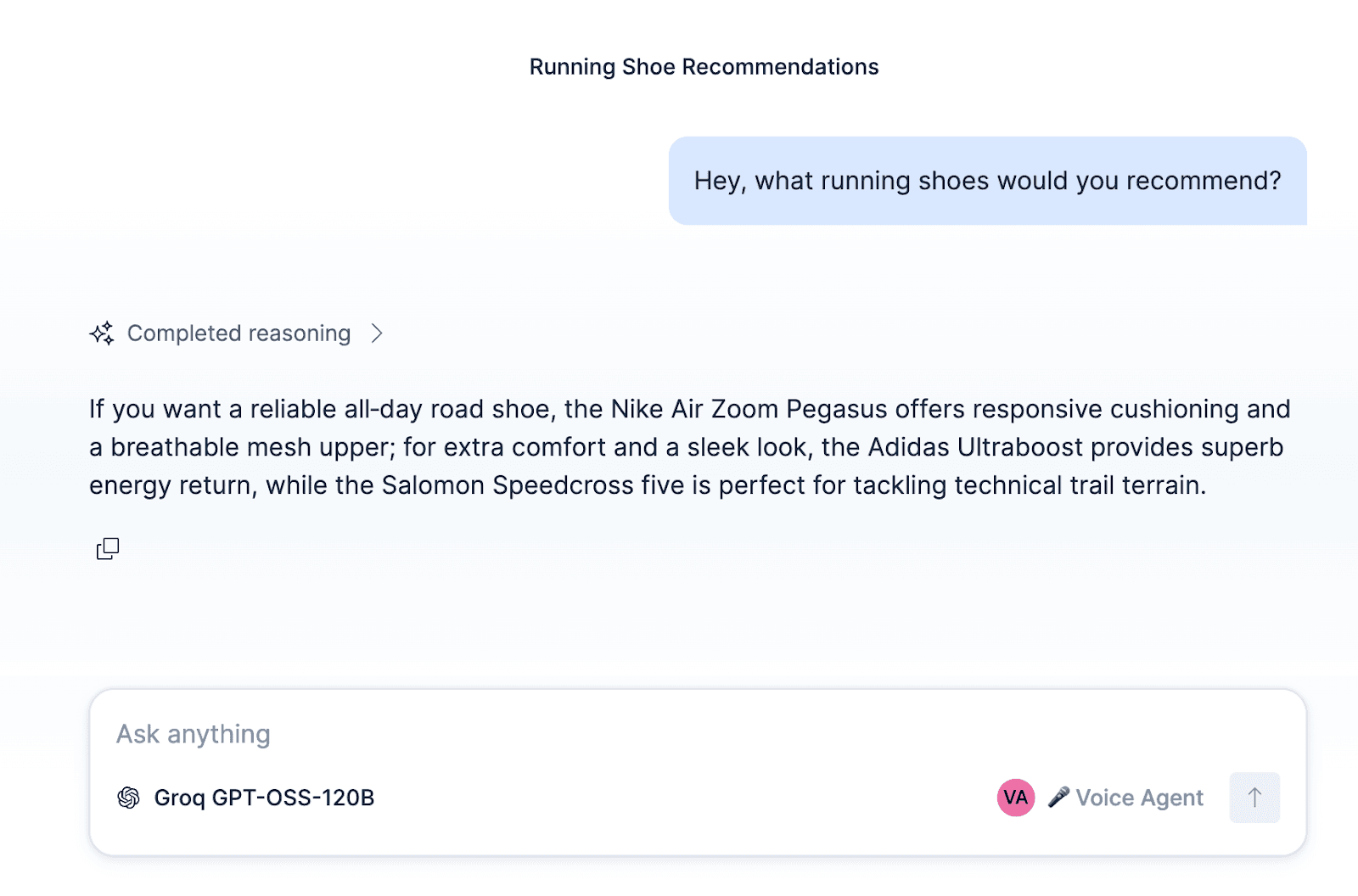
Au-delà de l’agent de support ElasticSport, l’agent, les workflows et les outils peuvent être adaptés à d’autres cas d’usage, comme un agent commercial pour qualifier des prospects, un agent de dépannage à domicile, un système de réservation pour restaurant ou encore un agent de planification de rendez-vous.
La dernière étape consiste à connecter l’agent que nous venons de créer à LiveKit, à la synthèse vocale et à la reconnaissance vocale. Le dépôt mentionné à la fin de ce billet contient un nœud LLM personnalisé pour Elastic Agent Builder, compatible avec LiveKit. Il vous suffit de remplacer AGENT_ID par le vôtre et de le connecter à votre instance Kibana.
Premiers pas
Consultez le code et testez-le vous-même ici.
Pour aller plus loin

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.
17 mars 2026
L'extension Gemini CLI pour Elasticsearch avec des outils et des fonctionnalités
Présentation de l’extension Elastic pour le CLI Gemini de Google, afin de rechercher, récupérer et analyser les données Elasticsearch dans les workflows des développeurs et des agents.