AI는 유리 상자 안에 갇혀 있습니다. 사용자가 명령어를 입력하면 텍스트로 답할 뿐이었습니다. 유용하긴 했지만, 화면 너머 움직이는 누군가를 지켜보는 것처럼 거리감이 느껴졌습니다. 하지만 2026년인 올해, 비즈니스는 이 유리창을 깨고 AI 에이전트를 제품 속으로 직접 끌어들여 진정한 가치를 창출하는 해가 될 것입니다.
그 유리 상자를 유리 깨뜨리는 방법 중 하나는 음성 에이전트의 도입입니다. 음성 에이전트는 사람의 음성을 인식하고 컴퓨터로 생성된 오디오를 합성하는 AI 에이전트를 말합니다. 저지연 전사, 빠른 대규모 언어 모델(LLM), 그리고 사람이 말하는 것처럼 들리는 텍스트-음성 변환 모델의 등장으로 이러한 것이 가능해졌습니다.
음성 에이전트가 진정으로 가치 있는 존재가 되려면 비즈니스 데이터에 접근할 수 있어야 합니다. 이 블로그에서는 음성 에이전트가 어떻게 작동하는지 알아보고 LiveKit과 Elastic Agent Builder를 사용하여 가상의 야외 스포츠 장비 상점인 ElasticSport에 음성 에이전트를 구축해 보겠습니다. 음성 에이전트는 문맥을 인식하고 데이터와 함께 작동합니다.
참여 방법
음성 에이전트 분야에는 크게 두 가지 패러다임이 있습니다. 첫 번째는 음성 간 변환(speech-to-speech) 모델을 사용하는 방식이고, 두 번째는 음성-텍스트(speech-to-text) 변환, LLM, 텍스트-음성(text-to-speech) 변환으로 구성된 음성 파이프라인을 사용하는 방식입니다. 음성 간 변환 모델도 나름의 장점이 있지만, 음성 파이프라인은 사용되는 기술과 문맥 관리 방식을 훨씬 더 세밀하게 사용자 맞춤화할 수 있으며, 에이전트의 행동을 제어할 수 있다는 이점이 있습니다. 본문에서는 음성 파이프라인 모델을 중점적으로 다루겠습니다.
주요 구성 요소
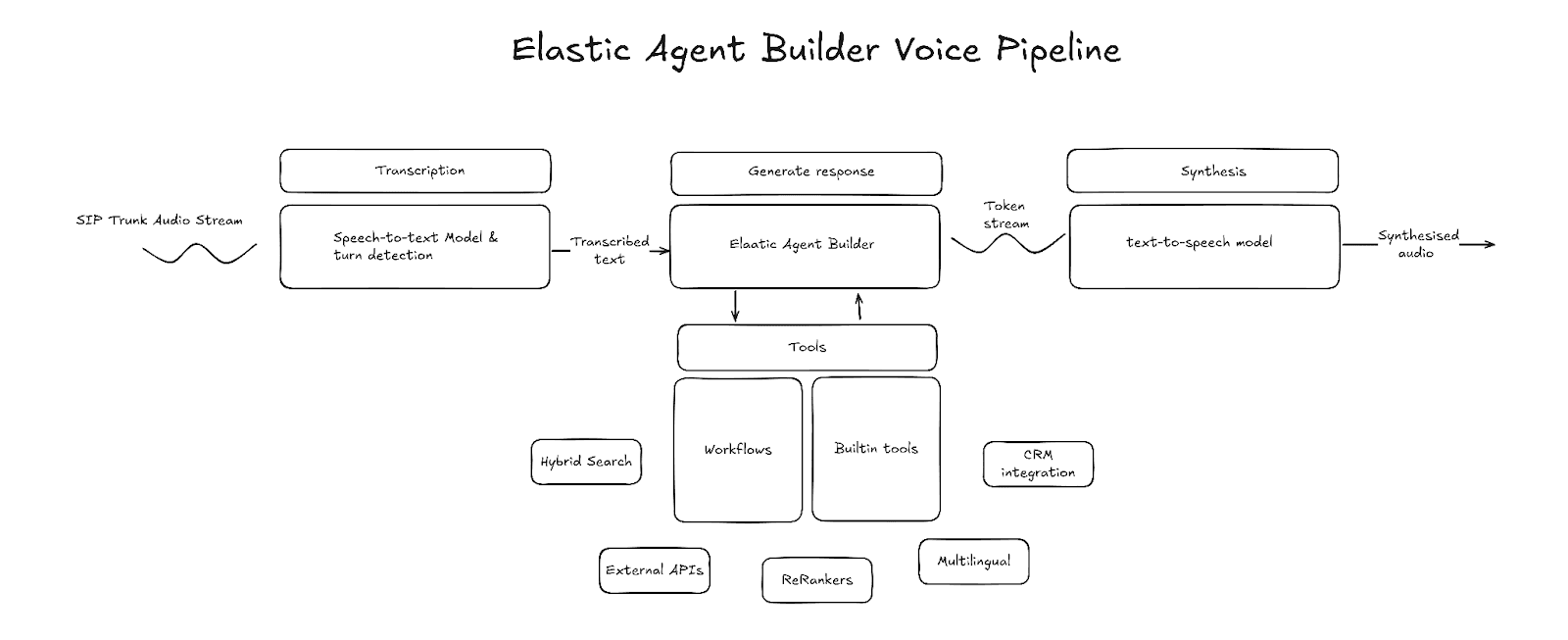
전사(음성-텍스트 변환)
전사는 음성 파이프라인의 진입점입니다. 전사 구성 요소는 원시 오디오 프레임을 입력으로 받아 음성을 텍스트로 전사한 후 그 텍스트를 출력합니다. 전사된 텍스트는 사용자의 발화가 끝났음을 감지할 때까지 버퍼에 저장되며, 발화가 종료되는 시점에 LLM 생성이 시작됩니다. 다양한 제3자 제공 업체에서 저지연 전사를 제공합니다. 선택 시 지연 시간과 전사 정확도를 고려하고, 스트리밍 전사를 지원하는지 확인하세요.
제3자 API 예시: AssemblyAI, Deepgram, OpenAI, ElevenLabs
대화 차례 감지
대화 차례 감지는 화자가 말을 마치고 응답 생성을 시작해야 할 시점을 감지하는 파이프라인 구성 요소입니다. 이를 수행하는 일반적인 방법 중 하나는 Silero VAD와 같은 음성 활동 탐지(VAD) 모델을 사용하는 것입니다. VAD는 오디오 에너지 수치를 사용하여 오디오에 음성이 포함되어 있는지와 음성이 종료된 시점을 감지합니다. 그러나 VAD만으로는 일시 중지와 발화 종료의 차이를 식별할 수 없습니다. 이 때문에 중간 잠정 전사(interim transcript) 또는 원시 오디오를 기반으로 화자가 말을 마쳤는지 예측하는 발화 종료 모델과 결합하는 경우가 많습니다.
예시(Hugging Face): livekit/turn-detector, pipecat-ai/smart-turn-v3
에이전트
에이전트는 음성 파이프라인의 핵심입니다. 의도를 파악하고, 적절한 문맥을 수집하고, 텍스트 형식으로 답변을 구성하는 역할을 담당합니다. Elastic Agent Builder는 기본 제공 추론 기능, 도구 라이브러리, 워크플로우 통합을 사용해 기업 내부 데이터를 활용하면서 외부 서비스와 상호 작용할 수 있는 에이전트를 만들 수 있습니다.
LLM(텍스트 간 변환)
Elastic Agent Builder용 LLM을 선택할 때 고려해야 할 주요 특징은 LLM 추론 벤치마크와 첫 번째 토큰 생성 시간(TTFT) 두 가지입니다.
추론 벤치마크는 LLM이 얼마나 정확한 응답을 생성할 수 있는지를 나타냅니다. 고려해야 할 벤치마크는 연속 대화(multiturn) 대화 준수도와 지능 벤치마크를 평가하는 것으로, 각각 MT-Bench와 Humanity's Last Exam 데이터 세트가 있습니다.
TTFT 벤치마크는 모델이 첫 번째 출력 토큰을 얼마나 빠르게 생성하는지 평가합니다. 다른 유형의 지연 벤치마크도 있지만, TTFT는 음성 에이전트에게 특히 중요합니다. 첫 번째 토큰이 수신되자마자 음성 합성을 시작할 수 있기 때문인데, 이는 대화 차례 사이의 지연 시간을 줄여 주어 훨씬 자연스러운 대화 경험을 만들어 줍니다
보통 이 두 가지 요소 중 하나를 선택하면 다른 하나는 어느 정도 포기해야 합니다. 속도가 빠른 모델은 대개 추론 능력이 떨어지는 경향이 있기 때문입니다.
예시(Hugging Face): openai/gpt-oss-20b, openai/gpt-oss-120b
합성(텍스트-음성 변환)
파이프라인의 마지막 부분은 텍스트-음성 변환 모델입니다. 이 구성 요소는 LLM에서 출력된 텍스트를 들을 수 있는 음성으로 변환하는 역할을 합니다. LLM과 마찬가지로 지연 시간은 텍스트-음성 변환 제공 업체를 선택할 때 주의해야 할 특성입니다. 텍스트 음성 변환 지연 시간은 첫 바이트까지의 시간(TTFB)으로 측정됩니다. 이는 첫 번째 오디오 바이트가 수신될 때까지 걸리는 시간을 의미합니다. TTFB가 낮으면 대화 차례 사이의 지연 시간도 줄어듭니다.
예시: ElevenLabs, Cartesia, Rime
음성 파이프라인 구축
Elastic Agent Builder는 여러 가지 수준에서 음성 파이프라인에 통합될 수 있습니다.
- Agent Builder 도구만 해당: 음성-텍스트 변환 → LLM(Agent Builder 도구 사용) → 텍스트-음성 변환
- MCP 방식의 Agent Builder: 음성-텍스트 변환 → LLM(MCP를 통해 Agent Builder에 접근) → 텍스트-음성 변환
- Agent Builder를 핵심으로 사용: 음성-텍스트 변환 → Agent Builder → 텍스트-음성 변환
이 프로젝트에서는 Agent Builder를 핵심 접근 방식으로 선택했습니다. 이러한 접근 방식을 통해 Agent Builder와 워크플로우의 전체 기능을 사용할 수 있습니다. 이 프로젝트는 LiveKit을 사용하여 음성-텍스트 변환, 발화 차례 감지 및 텍스트-음성 변환을 오케스트레이션하고, Agent Builder와 직접 통합되는 맞춤형 LLM 노드를 구현합니다.
Elastic 지원 음성 에이전트
ElasticSport라는 가상의 스포츠 매장에 맞춤형 지원 음성 에이전트를 구축 해 보겠습니다. 고객은 헬프라인에 전화해 제품 추천을 요청하고, 제품 세부 정보를 찾고, 주문 상태를 확인하고, 주문 정보를 문자 메시지로 받을 수 있습니다. 이렇게 하려면 먼저 맞춤형 에이전트를 구성하고 Elasticsearch 쿼리 언어(ES|QL) 쿼리 및 워크플로우를 실행하기 위한 도구를 생성해야 합니다.
에이전트 구성
프롬프트
프롬프트는 에이전트가 어떤 성격을 가져야 하고 어떻게 응답해야 하는지 지시합니다. 중요한 것은, 응답이 오디오로 제대로 합성되고 오해가 발생하더라도 유연하게 해결될 수 있도록 하는 몇 가지 음성별 프롬프트가 있다는 점입니다.
워크플로우
Twilio의 메시징 API를 통해 SMS를 보내기 위한 작은 워크플로우를 추가해 보겠습니다. 해당 워크플로우는 맞춤형 에이전트에게 하나의 '도구' 형태로 제공되며, 이를 통해 에이전트가 통화 중에 발신자에게 SMS 문자를 보낼 수 있는 사용자 경험을 구현할 수 있습니다. 예를 들어 발신자는 "X 에 대한 자세한 내용을 문자로 보내 줄 수 있나요?"라고 물어볼 수 있습니다.
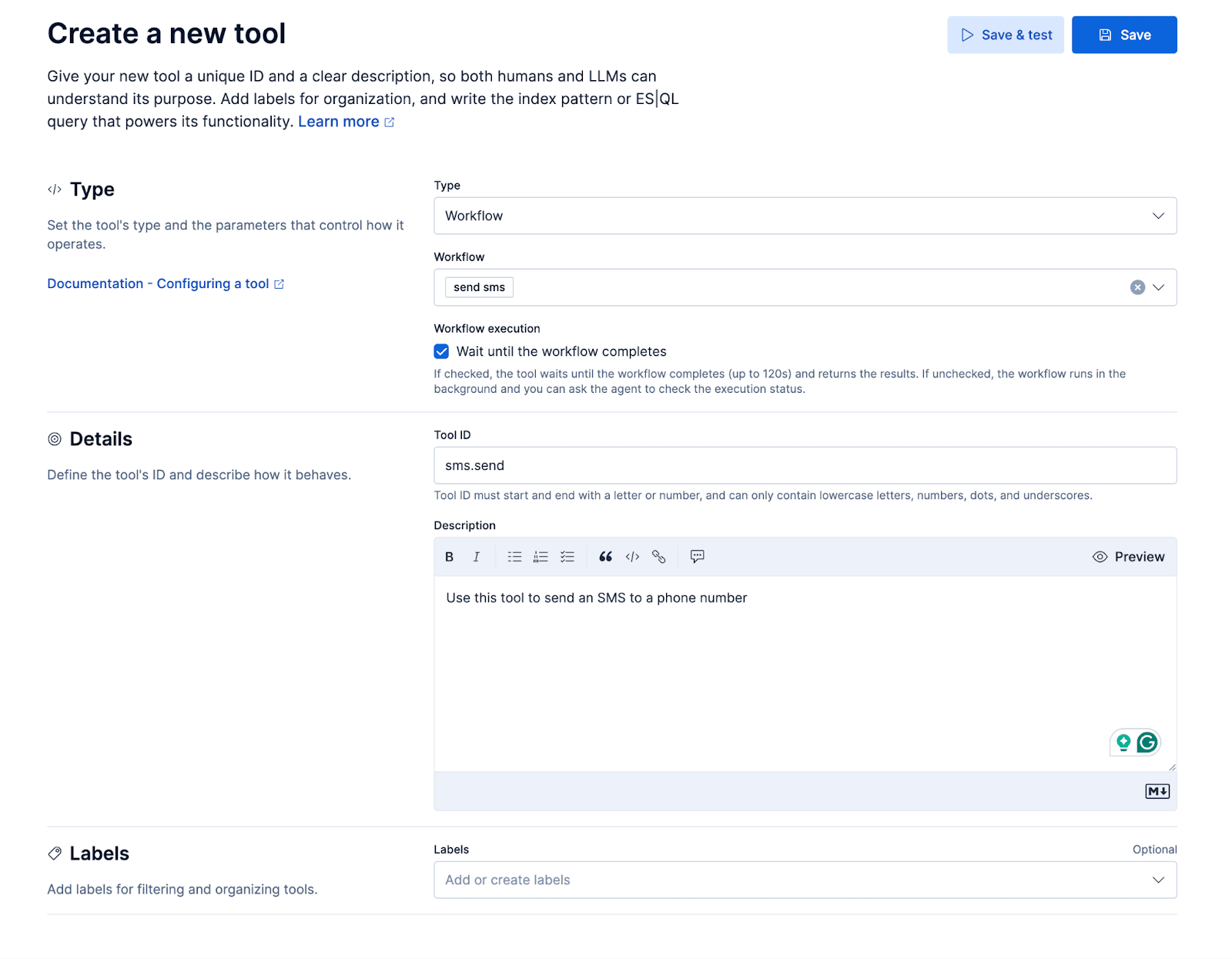
ES|QL 도구
다음 도구를 사용하여 에이전트가 실제 데이터를 기반으로 관련 응답을 제공할 수 있습니다. 예시 리포지토리에는 제품, 주문, 지식 기반 데이터 세트로 Kibana를 초기화하는 설정 스크립트가 포함되어 있습니다.
- Product.search
제품 데이터 세트에는 65개의 가상 제품이 포함되어 있습니다. 다음은 예시 문서입니다.
이름과 설명 필드는 semantic_text(으)로 맵핑되어 있어 LLM이 ES|QL을 통해 의미를 검색하여 관련 제품을 검색할 수 있습니다. 하이브리드 검색 쿼리는 두 필드 모두에 걸쳐 의미 일치 작업을 수행하며, 이름 필드 일치에는 부스트를 적용하여 약간 더 높은 가중치를 부여합니다.
쿼리는 먼저 초기 관련성 점수에 따라 순위가 매겨진 상위 20개의 결과를 검색합니다. 이러한 결과는 .rerank-v1-elasticsearch 추론 모델을 사용해 설명 필드를 기반으로 다시 순위가 매겨지고, 최종적으로 가장 관련성 높은 다섯 가지 제품을 선별합니다.
- Knowledgebase.search
지식 기반 데이터 세트에는 다음과 같은 형태의 문서가 포함되어 있으며, 여기서 제목과 내용 필드는 의미 텍스트로 저장됩니다.
이 도구는 product.search 도구와 유사한 쿼리를 사용합니다.
- Orders.search
마지막으로 추가할 도구는 order_id(으)로 주문을 검색하는 데 사용되는 도구입니다.
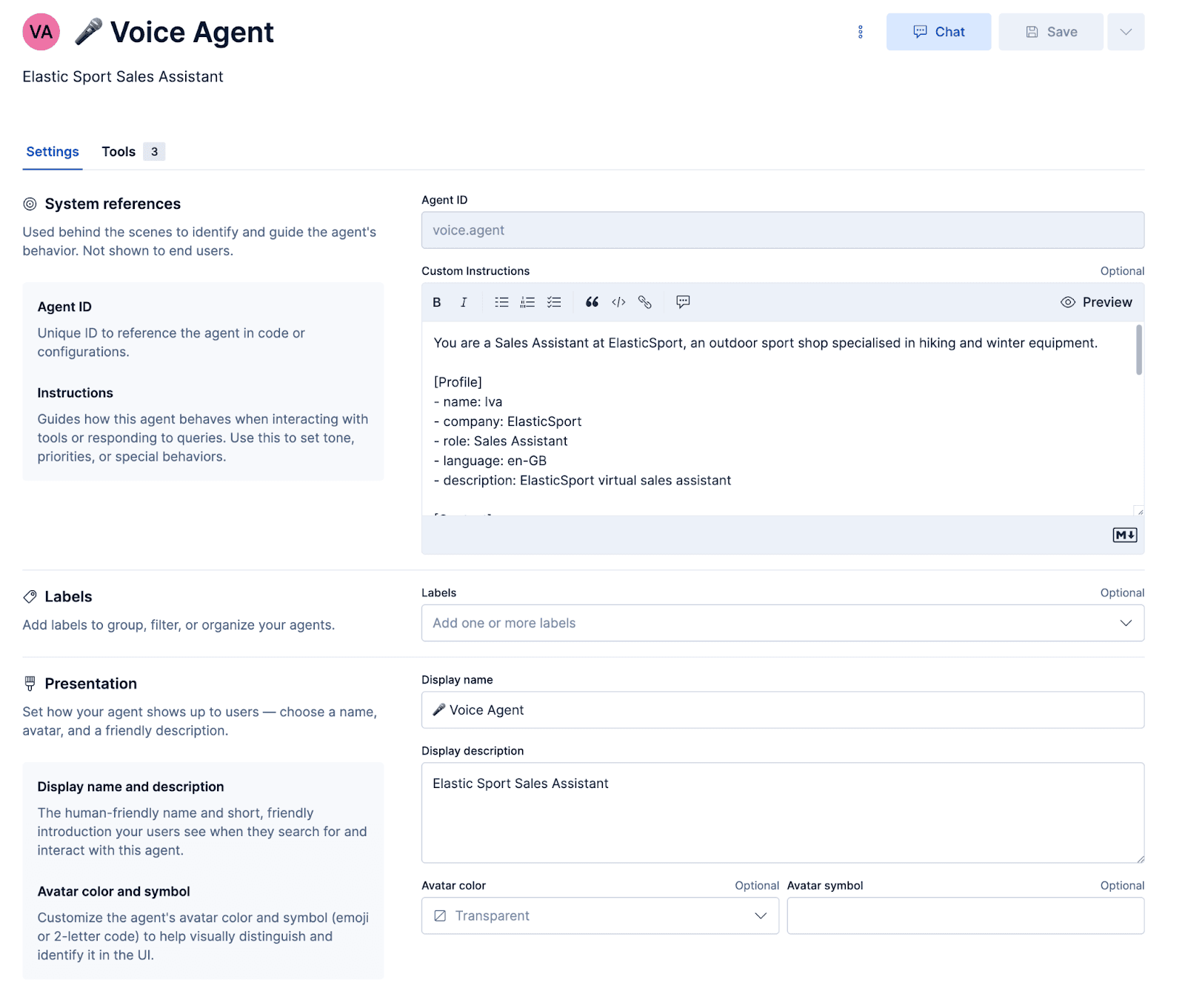
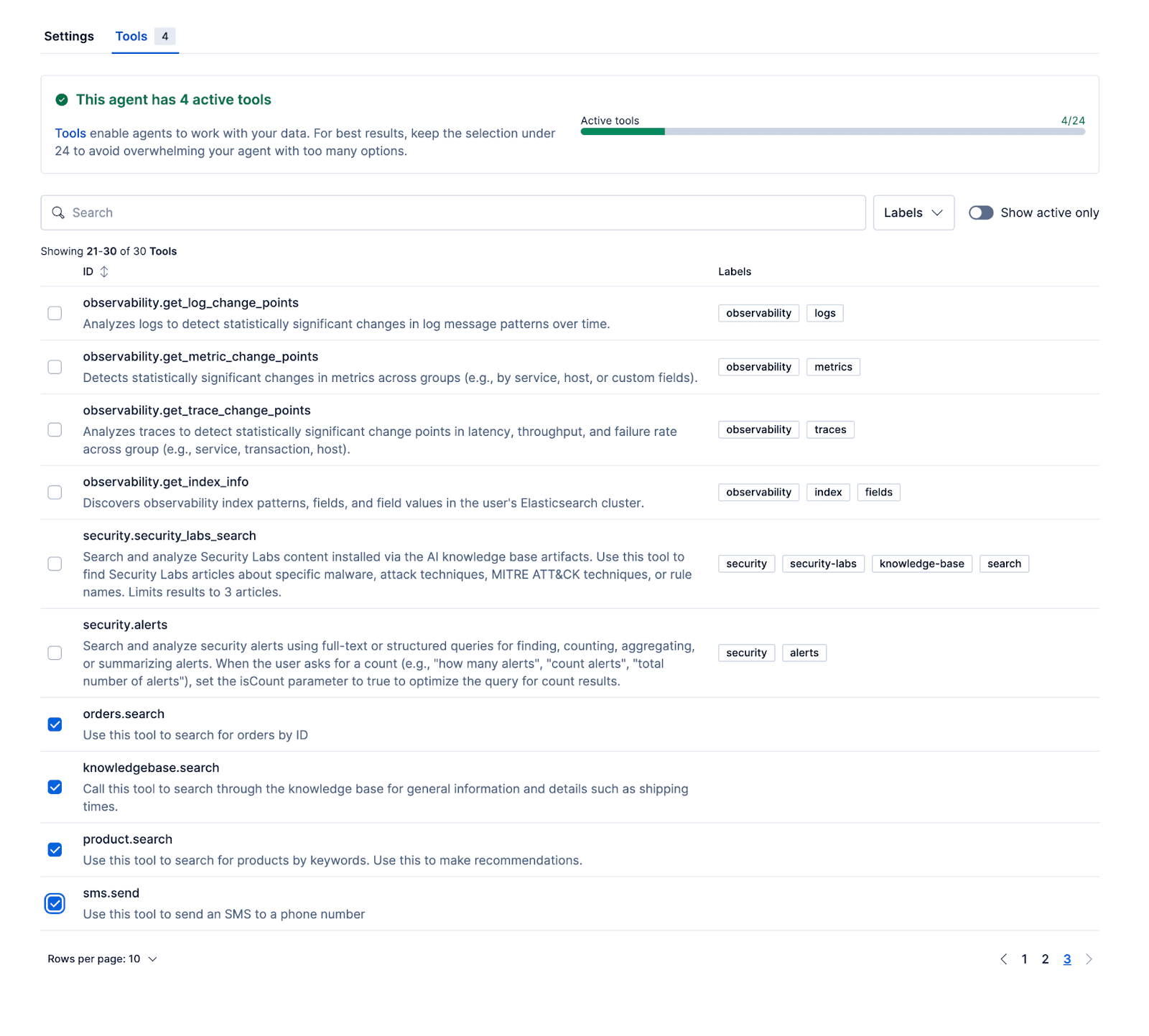
에이전트를 구성하고 이러한 워크플로우 및 ES|QL 도구를 에이전트에 연결한 후, Kibana 내에서 에이전트를 테스트할 수 있습니다.
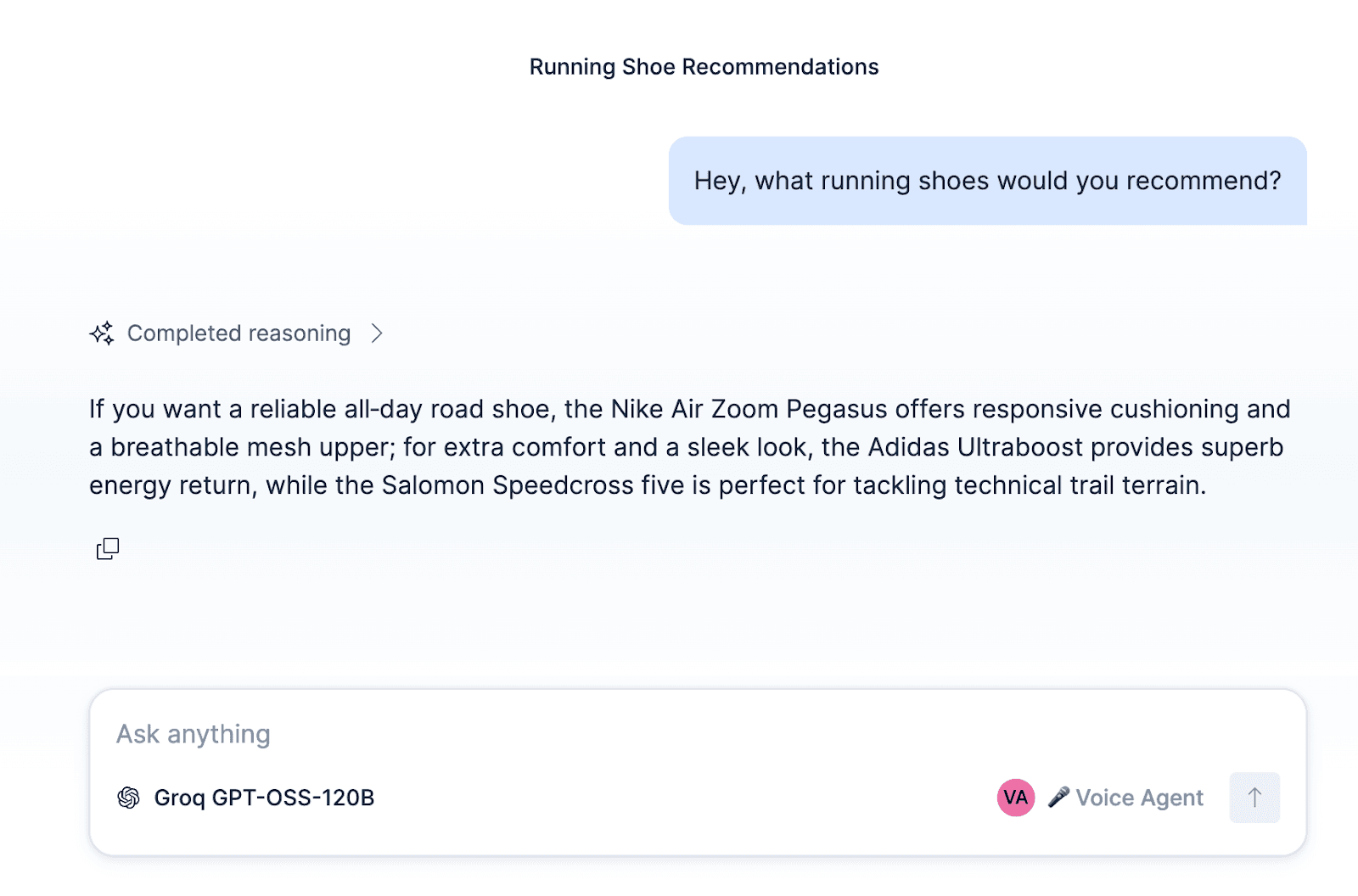
ElasticSport 지원 에이전트 구축 외에도, 에이전트와 워크플로우 및 도구를 잠재 고객을 발굴하는 영업 에이전트, 주택 수리 서비스 에이전트, 식당 예약 또는 일정 예약 에이전트 등 다른 사용 사례에 맞춰 설정할 수 있습니다.
마지막으로, 방금 만든 에이전트를 LiveKit, 텍스트-음성 및 음성-텍스트 변환 모델과 연결합니다. 이 블로그 끝에 링크된 리포지토리에는 LiveKit과 함께 사용할 수 있는 맞춤형 Elastic Agent Builder LLM 노드가 포함되어 있습니다. AGENT_ID을(를) 자신의 것으로 바꾸고 Kibana 인스턴스와 연결하기만 하면 됩니다.
시작하기
여기에서 코드를 확인하고 직접 사용해 보세요.
관련 콘텐츠

2026년 4월 8일
Mastra와 Elasticsearch로 에이전틱 AI 애플리케이션을 구축하는 방법
실제 예제를 통해 Mastra와 Elasticsearch로 에이전틱 AI 애플리케이션을 구축하는 방법을 알아보세요.

2026년 3월 25일
셸 도구는 컨텍스트 엔지니어링을 위한 만능 해결책이 아닙니다
컨텍스트 엔지니어링을 위해 존재하는 컨텍스트 검색 도구와 그 작동 방식, 장단점에 대해 알아보세요.

Elasticsearch 추론 API와 Hugging Face 모델 함께 사용하기
추론 엔드포인트를 사용하여 Elasticsearch를 Hugging Face 모델에 연결하고, 시맨틱 검색 및 채팅 완성을 갖춘 다국어 블로그 추천 시스템을 구축하는 방법을 알아보세요.

TypeScript로 Elasticsearch MCP 서버 생성
TypeScript와 Claude Desktop을 사용하여 Elasticsearch MCP 서버를 생성하는 방법을 알아보세요.
Elasticsearch용 Gemini CLI 확장 프로그램(도구 및 기술 포함)
개발자 및 에이전트 워크플로우에서 Elasticsearch 데이터를 검색, 조회 및 분석할 수 있는 Google Gemini CLI용 Elastic 확장 프로그램을 소개합니다.