A IA ficou presa em uma caixa de vidro. Você digita comandos, ela responde com texto, e pronto. É útil, mas distante, como ver alguém se mover atrás de uma tela. Este ano, 2026, será o ano em que as empresas vão quebrar esse vidro e trazer agentes de IA para produtos, onde realmente entregam valor.
Uma das maneiras pelas quais o vidro será quebrado é pela adoção de agentes de voz, que são agentes de IA que reconhecem a fala humana e sintetizam áudio gerado por computador. Com o crescimento das transcrições de baixa latência, modelos de linguagem grandes e rápidos (LLMs) e modelos de texto para fala que soam humanos, isso se tornou possível.
Os agentes de voz também precisam ter acesso a dados empresariais para se tornarem realmente valiosos. Neste artigo, aprenderemos como funcionam os agentes de voz e criaremos um para a ElasticSport, uma loja fictícia de equipamentos esportivos para atividades ao ar livre, usando LiveKit e Elastic Agent Builder. Nosso agente de voz será sensível ao contexto e funcionará com nossos dados.
Como funciona
Existem dois paradigmas no mundo dos agentes de voz: o primeiro usa modelos de fala para fala, e o segundo usa um pipeline de voz que consiste em fala para texto, LLM e texto para fala. Modelos de fala para fala têm os próprios benefícios, mas os pipelines de voz oferecem muito mais personalização das tecnologias usadas e de como o contexto é gerenciado, além de controle sobre o comportamento do agente. Vamos focar o modelo de pipeline de voz.
Principais componentes
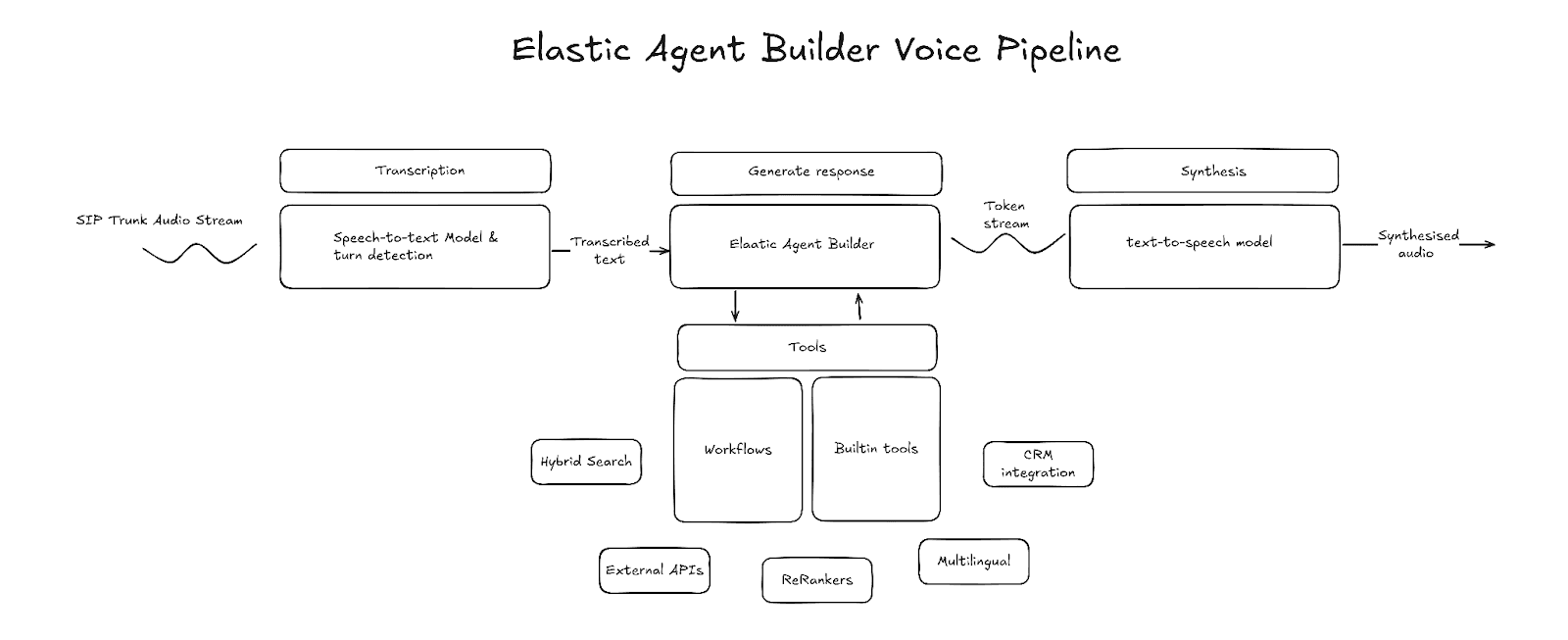
Transcrição (fala para texto)
A transcrição é o ponto de entrada no pipeline de voz. O componente de transcrição recebe como entrada quadros de áudio brutos, transcreve a fala em texto e gera esse texto como saída. O texto transcrito é armazenado em buffer até que o sistema detecte que a fala do usuário terminou, momento em que a geração do LLM é iniciada. Diversos fornecedores terceirizados oferecem transcrições de baixa latência. Ao selecionar um, leve em consideração a latência e a precisão da transcrição, e certifique-se de que ele suporte transcrições em fluxo contínuo.
Exemplos de APIs de terceiros: AssemblyAI, Deepgram, OpenAI, ElevenLabs
Detecção de curva
A detecção de turno é o componente do pipeline que detecta quando o falante termina de falar e a geração deve começar. Uma maneira comum de fazer isso é por meio de um modelo de detecção de atividade de voz (VAD), como o Silero VAD. O VAD utiliza níveis de energia do áudio para detectar quando o áudio contém fala e quando a fala terminou. No entanto, o VAD sozinho não consegue identificar a diferença entre pausa e fim da fala. Por isso, muitas vezes é combinado com um modelo de fim de enunciado que prevê se o falante terminou de falar, com base na transcrição intermediária ou no áudio bruto.
Exemplos (Hugging Face): livekit/turn-detector, pipecat-ai/smart-turn-v3
Agente
O agente é o núcleo de um pipeline de voz. É responsável por entender a intenção, reunir o contexto certo e formular uma resposta em formato de texto. O Elastic Agent Builder, com suas capacidades integradas de raciocínio, biblioteca de ferramentas e integração de fluxos de trabalho, é um agente capaz de trabalhar sobre seus dados e interagir com serviços externos.
LLM (texto para texto)
Ao selecionar um LLM para o Elastic Agent Builder, há duas características principais a considerar: benchmarks de raciocínio de LLM e tempo até o primeiro token (TTFT).
Benchmarks de raciocínio indicam quão bem o LLM consegue gerar respostas corretas. Os benchmarks a serem considerados são aqueles que avaliam a adesão à conversa em múltiplos turnos e os benchmarks de inteligência, como o MT-Bench e o conjunto de dados Humanity's Last Exam, respectivamente.
Os benchmarks TTFT avaliam a rapidez com que o modelo produz seu primeiro token de saída. Existem outros tipos de benchmarks de latência, mas a TTFT é particularmente importante para agentes de voz, pois a síntese de áudio pode começar assim que o primeiro token é recebido, resultando em menor latência entre os turnos, uma conversa com sensação natural.
Normalmente, é preciso fazer uma troca entre essas duas características porque modelos mais rápidos geralmente têm um desempenho pior em benchmarks de raciocínio.
Exemplos (Hugging Face): openai/gpt-oss-20b, openai/gpt-oss-120b
Síntese (texto para fala)
A parte final do pipeline é o modelo de conversão de texto em fala. Esse componente é responsável por converter a saída de texto do LLM em fala audível. Semelhante ao LLM, a latência é uma característica a ser observada ao selecionar um provedor de texto para fala. A latência de texto para fala é medida pelo tempo até o primeiro byte (TTFB). Esse é o tempo que leva para receber o primeiro byte de áudio. Menor TTFB também reduz a latência de giro.
Exemplos: ElevenLabs, Cartesia, Rime
Construção do pipeline de voz
O Elastic Agent Builder pode ser integrado a um pipeline de voz em vários níveis diferentes:
- Ferramentas apenas do Agent Builder: fala para texto → LLM (com ferramentas Agent Builder) → texto para fala
- Agent Builder como MCP: fala para texto → LLM (com acesso ao Agent Builder via MCP) → texto para fala
- Agent Builder como núcleo: conversão de fala em texto → Agent Builder → conversão de texto em fala
Para este projeto, escolhi o Agent Builder como abordagem núcleo. Com essa abordagem, toda a funcionalidade do Agent Builder e dos fluxos de trabalho pode ser utilizada. O projeto usa o LiveKit para orquestrar a conversão de fala em texto, detecção de turnos e conversão de texto em fala, e implementa um node LLM personalizado que se integra diretamente ao Agent Builder.
Agente de voz do suporte da Elastic
Criaremos um agente de voz de suporte personalizado para uma loja de esportes fictícia chamada ElasticSport. Os clientes poderão ligar para a linha de ajuda, solicitar recomendações de produtos, encontrar detalhes do produto, verificar o status do pedido e receber as informações do pedido por mensagem de texto. Para isso, primeiro precisamos configurar um agente personalizado e criar ferramentas para executar a Elasticsearch linguagem de consulta (ES|QL) e fluxos de trabalho.
Configurando o agente
Prompt
O prompt orienta o agente qual a personalidade que deve ter e como responder. É importante ressaltar que há alguns prompts específicos de voz que garantem que as respostas sejam sintetizadas em áudio adequadamente e que os mal-entendidos sejam recuperados de forma graciosa.
Fluxos de trabalho
Vamos adicionar um pequeno fluxo de trabalho para enviar um SMS pela API de mensagens do Twilio. O fluxo de trabalho será exposto ao agente personalizado como uma ferramenta, resultando em uma experiência de usuário em que o agente poderá enviar um SMS ao chamador durante a chamada. Isso permite que o autor da chamada, por exemplo, pergunte: "Você pode enviar os detalhes sobre X por texto?"
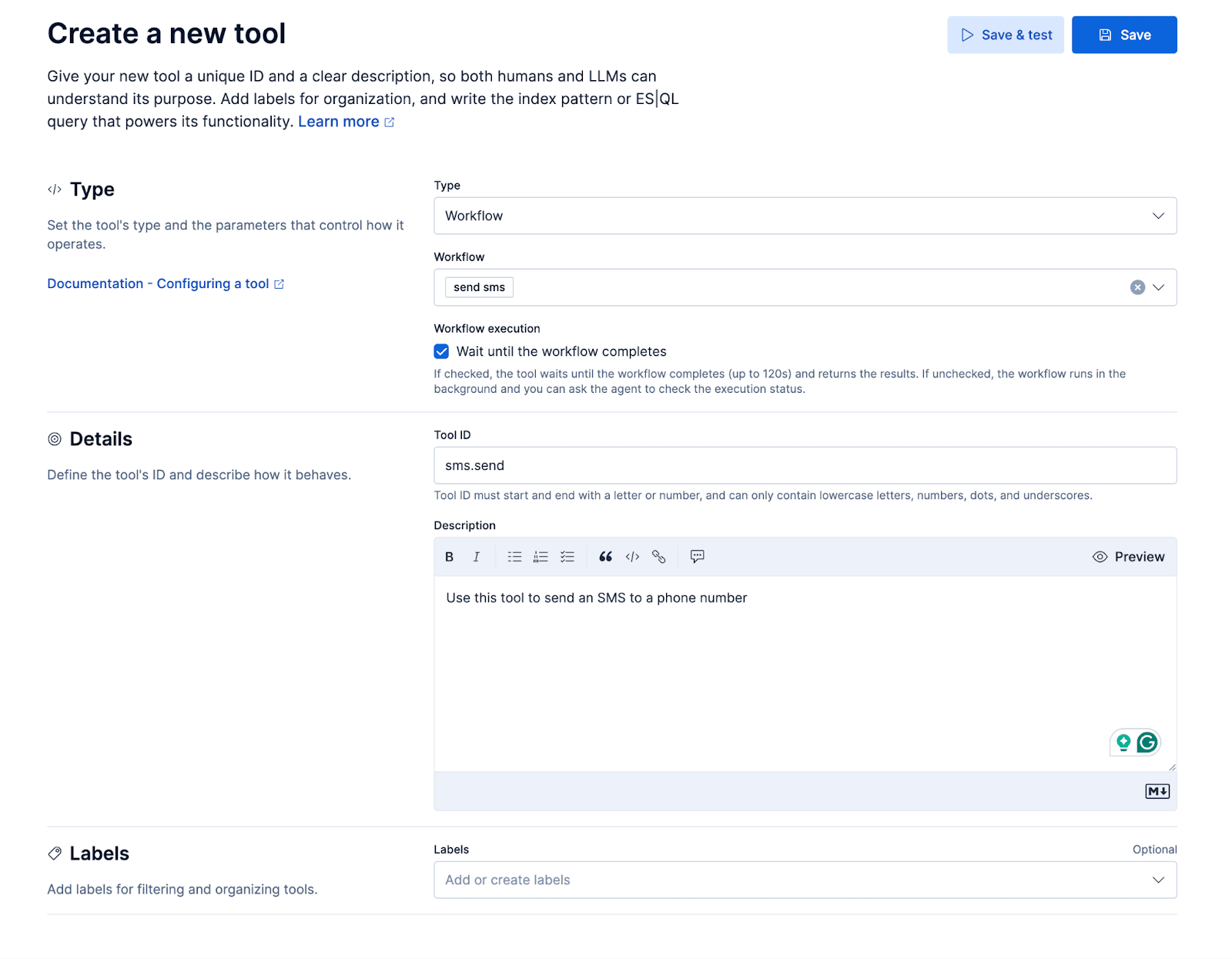
Ferramentas ES|QL
As ferramentas a seguir permitem que o agente forneça respostas relevantes fundamentadas em dados reais. O repositório de exemplo contém um script de configuração para iniciar o Kibana com conjuntos de dados de produtos, pedidos e base de conhecimento.
- Product.search
O conjunto de dados de produtos contém 65 produtos fictícios. Este é um documento de exemplo:
Os campos de nome e descrição são mapeados como semantic_text, permitindo que o LLM use busca semântica via ES|QL para recuperar produtos relevantes. A consulta de busca híbrida realiza correspondência semântica em ambos os campos, com um peso um pouco maior aplicado às correspondências no campo do nome usando um boost.
A consulta primeiro recupera os 20 melhores resultados classificados pela pontuação inicial de relevância. Esses resultados são então reclassificados com base no campo de descrição usando o modelo de inferência .rerank-v1-elasticsearch e, finalmente, reduzidos para os cinco produtos mais relevantes.
- Knowledgebase.search
Os conjuntos de dados da base de conhecimento contêm documentos do seguinte formato, onde os campos de título e conteúdo são armazenados como texto semântico:
E a ferramenta usa uma consulta semelhante à ferramentaproduct.search:
- Orders.search
A última ferramenta que adicionaremos é aquela usada para recuperar pedidos por order_id:
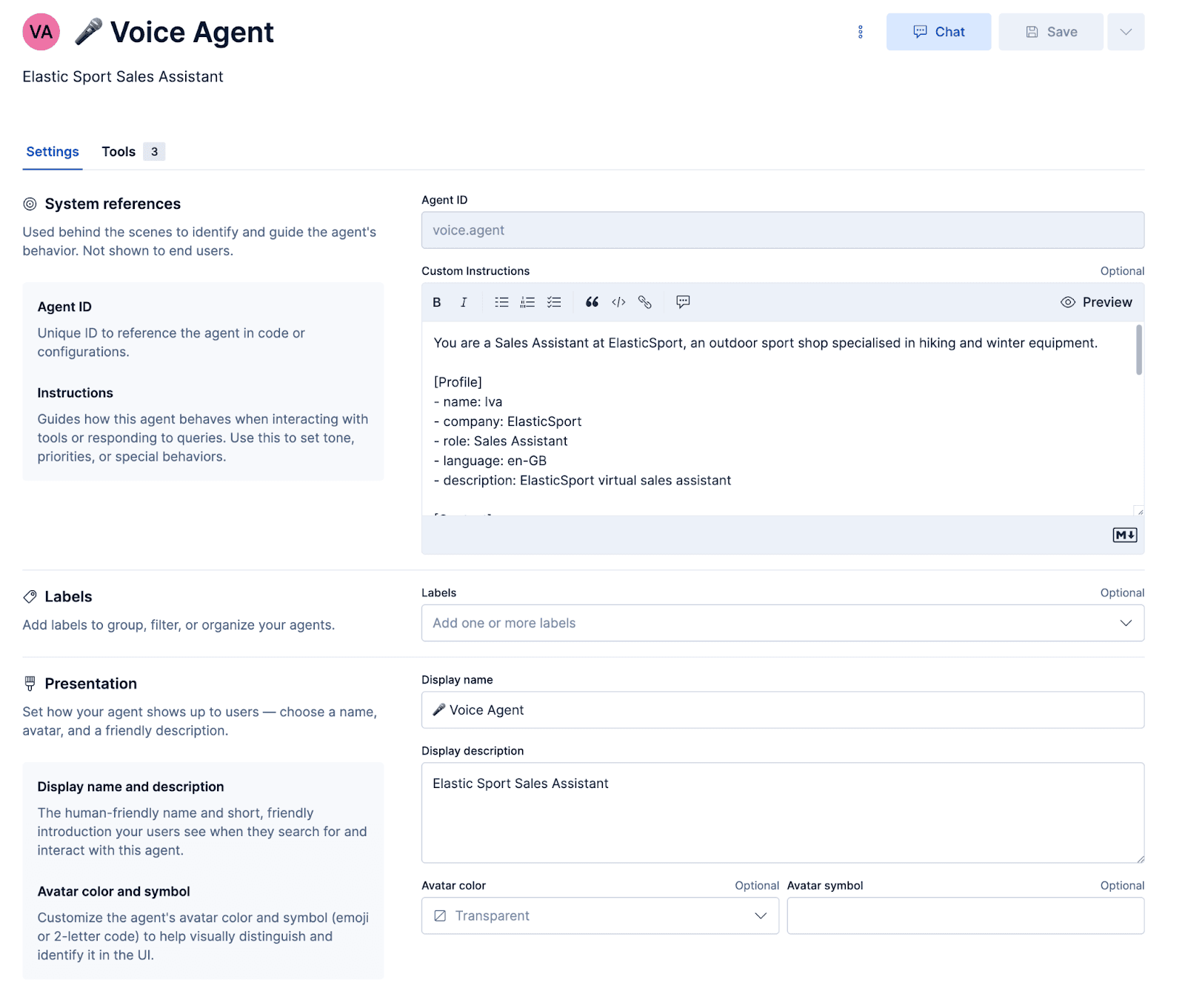
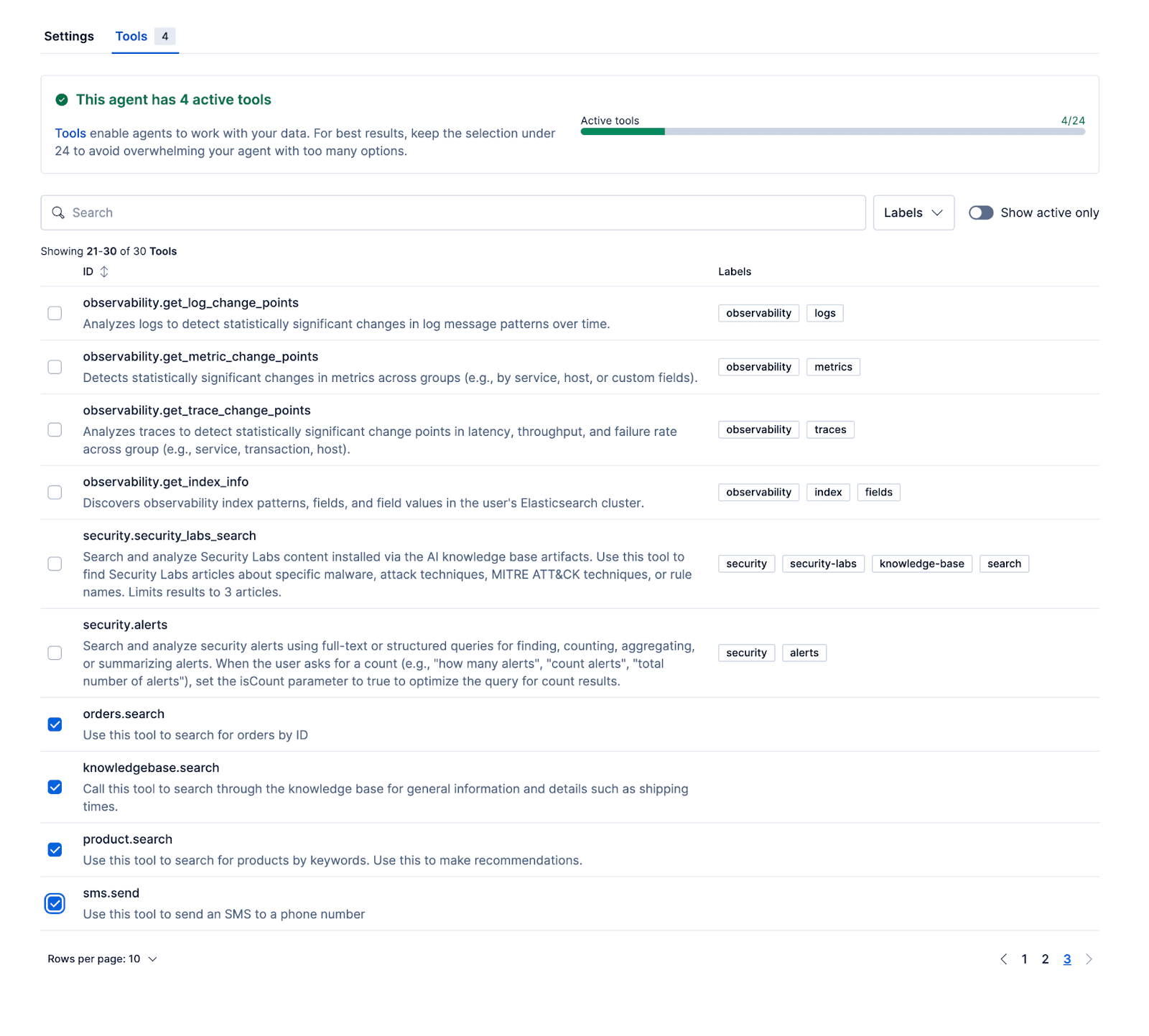
Após configurar o agente e anexar esses fluxos de trabalho e ES|QL para o agente, o agente pode ser testado dentro do Kibana.
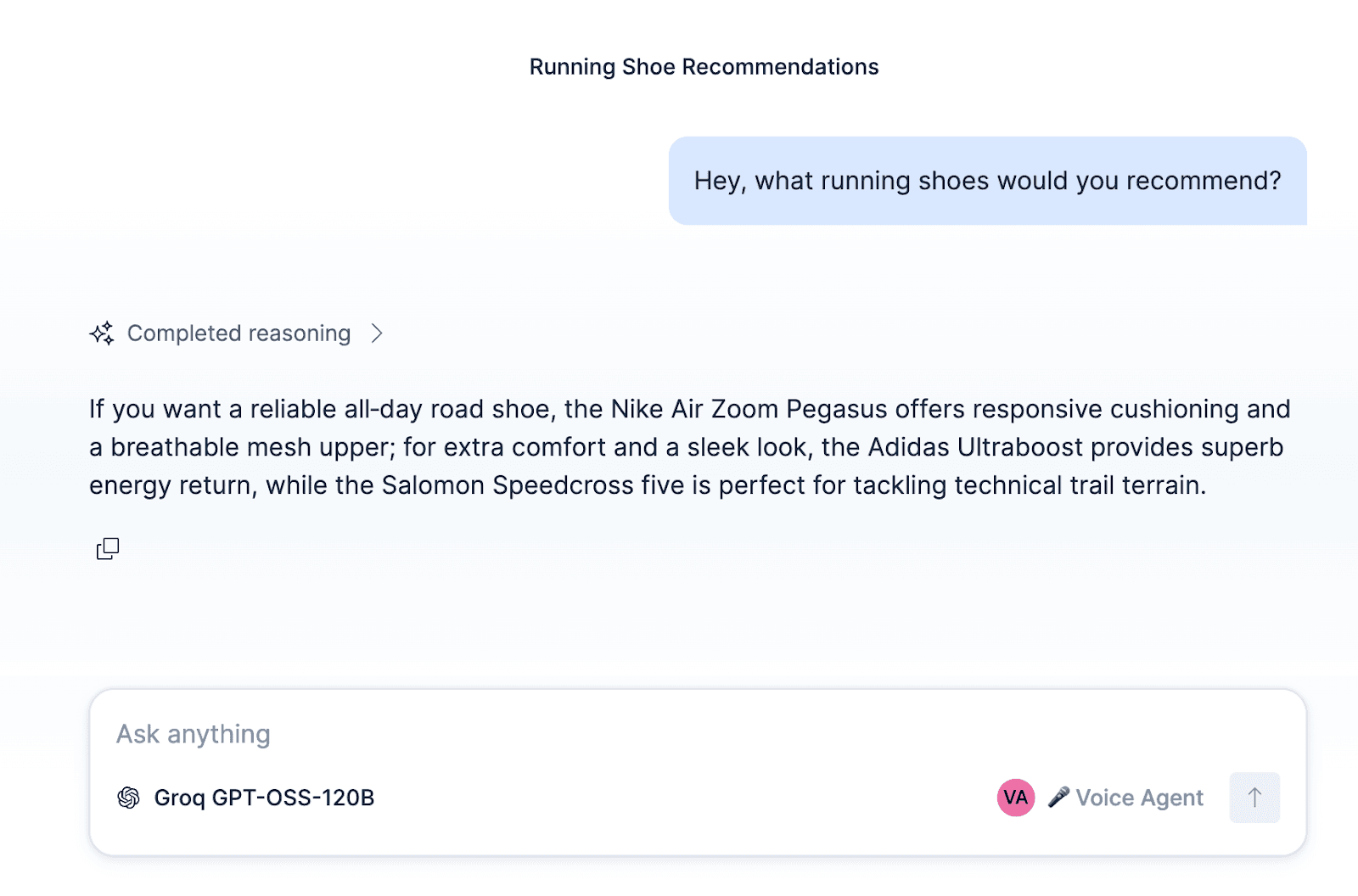
Além de construir um agente de suporte ElasticSport, o agente, fluxos de trabalho e ferramentas podem ser adaptados a outros casos de uso, como um agente de vendas que qualifica leads, um agente de serviço para reparos residenciais, reservas para um restaurante ou um agente de agendamento de consultas.
A parte final é conectar o agente que acabamos de criar com modelos LiveKit, texto para fala e fala para texto. O repositório (link no fim do artigo) contém um node personalizado do LLM Elastic Agent Builder que pode ser usado com o LiveKit. Basta trocar o AGENT_ID pelo seu e vinculá-lo com sua instância Kibana.
Para começar
Confira o código e experimente você mesmo aqui.
Conteúdo relacionado

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.
17 de março de 2026
A extensão Gemini CLI para Elasticsearch com ferramentas e recursos
Apresentamos a extensão da Elastic para a CLI Gemini do Google, que permite buscar, extrair e analisar dados do Elasticsearch em fluxos de trabalho de desenvolvedores e agentes.