Neste artigo, exploraremos como combinar LangGraph e Elasticsearch para criar um aplicativo com interação humana (HITL). Essa abordagem permite que os sistemas de IA envolvam os usuários diretamente no processo de tomada de decisão, tornando as interações mais confiáveis e sensíveis ao contexto. Implementaremos um exemplo prático usando um cenário orientado pelo contexto para demonstrar como os fluxos de trabalho do LangGraph podem se integrar ao Elasticsearch para recuperar dados, lidar com a entrada do usuário e produzir resultados refinados.
Requisitos
- NodeJS versão 18 ou mais recente
- Chave de API da OpenAI
- Implantação do Elasticsearch 8.x+
Por que usar o LangGraph para sistemas HITL de produção
Em um artigo anterior, apresentamos o LangGraph e os benefícios para a construção de um sistema RAG usando LLMs e bordas condicionais para tomar decisões automaticamente e exibir resultados. Às vezes, não queremos que o sistema atue de forma autônoma de ponta a ponta, mas queremos que os usuários selecionem opções e tomem decisões dentro do ciclo de execução. Esse conceito é chamado de "Human in the loop" ou interação humana.
Intervenção humana
Esse é um conceito de IA que permite que uma pessoa real interaja com sistemas de IA para fornecer mais contexto, avaliar respostas, editar respostas, solicitar mais informações etc. Isso é muito útil em cenários de baixa tolerância a erros, como conformidade, tomada de decisões ou geração de conteúdo, ajudando a melhorar a confiabilidade das saídas do LLM.
Um exemplo comum é quando seu assistente de programação pede permissão para executar um determinado comando no terminal ou mostra o processo de pensamento passo a passo para você aprovar antes de começar a programar.
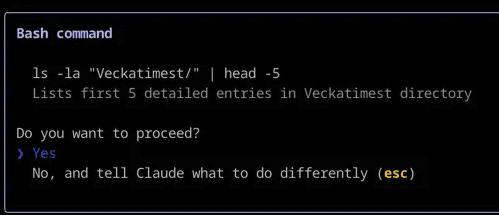
Claude Code utiliza o recurso de "intervenção humana" para solicitar sua confirmação antes de executar um comando Bash.
Elasticsearch + LangGraph: Como eles interagem
O LangChain permite usar o Elasticsearch como um repositório de vetores e executar consultas em aplicações LangGraph, o que é útil para realizar buscas de texto completo ou semânticas, enquanto o LangGraph é usado para definir o fluxo de trabalho, as ferramentas e as interações específicas. Além disso, adiciona a HITL (interação humana) como uma camada adicional de interação com o usuário.
Implementação prática: intervenção humana
Vamos imaginar que um advogado tenha uma pergunta sobre um caso que ele assumiu recentemente. Sem as ferramentas certas, ele precisaria buscar manualmente artigos legais e precedentes, ler tudo na íntegra e interpretar como eles se aplicam à situação. Com o LangGraph e o Elasticsearch, no entanto, podemos criar um sistema que busca em um banco de dados precedentes legais e gera uma análise do caso que incorpora os detalhes específicos e o contexto fornecido pelo advogado.
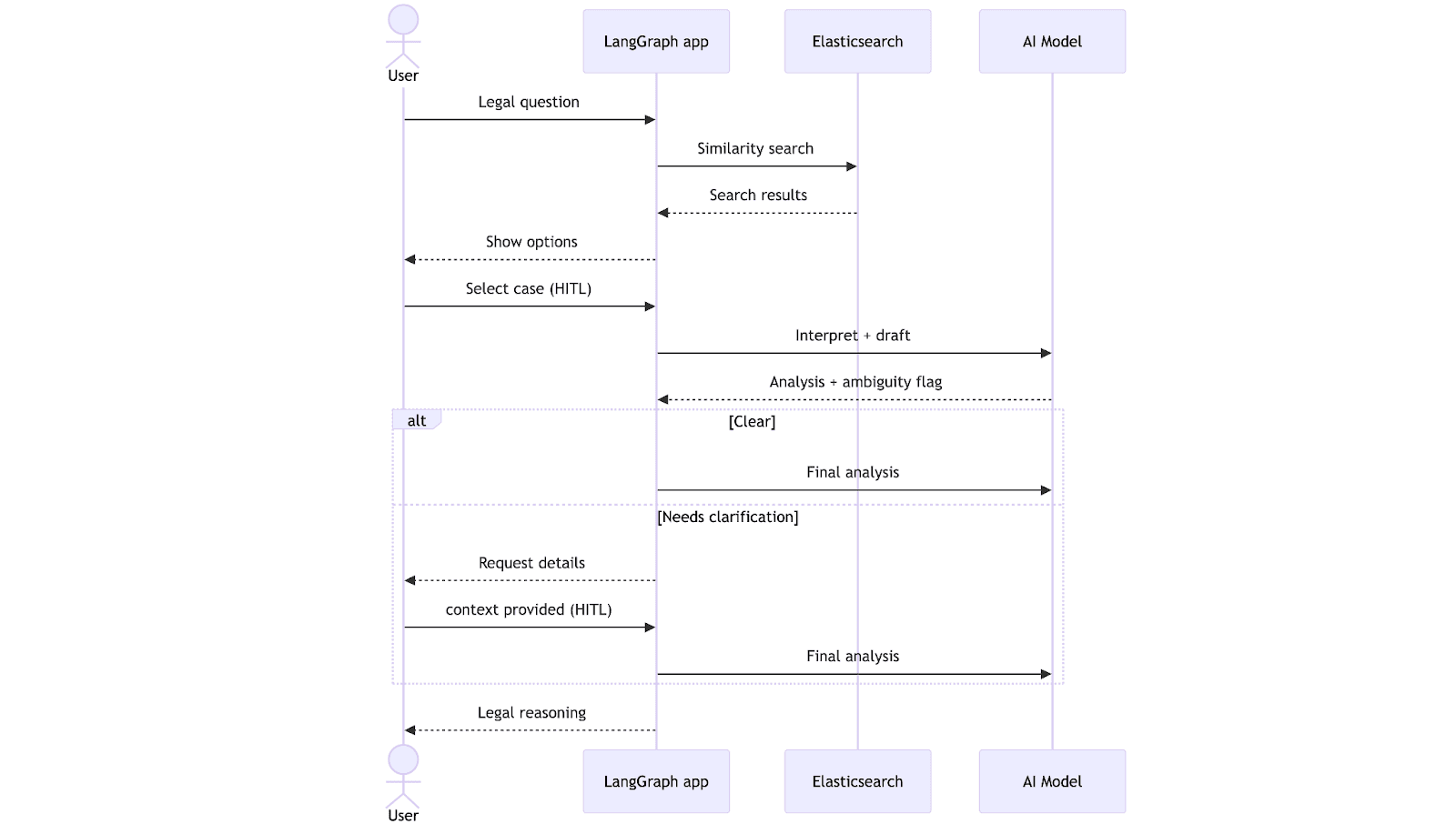
O fluxo de trabalho começa quando o advogado envia uma dúvida jurídica. O sistema realiza uma busca vetorial no Elasticsearch, recupera os precedentes mais relevantes e os apresenta para o advogado escolher usando linguagem natural. Após a seleção, o LLM gera um rascunho de análise e verifica se as informações estão completas. Nesse ponto, o fluxo de trabalho pode seguir dois caminhos: se tudo estiver claro, ele prossegue diretamente para gerar uma análise final; caso contrário, ele faz uma pausa para solicitar esclarecimentos ao advogado. Assim que o contexto em falta for fornecido, o sistema completa a análise e a retorna, levando em consideração os esclarecimentos.
A seguir, você verá um gráfico elaborado pelo LangGraph que mostra como o app ficará no final do desenvolvimento. Cada nó representa uma ferramenta ou funcionalidade:
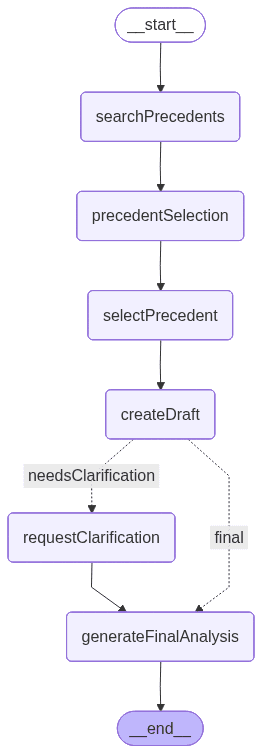
Conjunto de dados
Aqui está o conjunto de dados que será usado para este exemplo. Este conjunto de dados contém uma coleção de precedentes legais, cada um descrevendo um caso envolvendo atrasos no serviço, o raciocínio do tribunal e o resultado.
Ingestão e configuração do índice
A configuração do índice e a lógica de ingestão de dados são definidas no arquivo dataIngestion.ts, onde declaramos funções para lidar com a criação do índice. Essa configuração é compatível com a interface de armazenamento vetorial LangChain para Elasticsearch.
Atenção: a configuração do mapeamento também está incluída no arquivo dataIngestion.ts.
Instale pacotes e configure variáveis de ambiente
Vamos iniciar um projeto Node.js com as configurações padrão:
- @elastic/elasticsearch: cliente Elasticsearch para Node.js. Usado para conectar, criar índices e executar consultas.
- @langchain/community: oferece integrações para ferramentas compatíveis com a comunidade, incluindo o ElasticVectorSearch.
- @langchain/core: blocos núcleo do LangChain, como chains, prompts e utilitários.
- @langchain/langgraph: adiciona orquestração baseada em gráficos, permitindo fluxos de trabalho com nós, bordas e gerenciamento de estados.
- @langchain/openai: oferece acesso aos modelos da OpenAI (LLMs e integrações) por meio do LangChain.
- dotenv: carrega variáveis de ambiente de um arquivo .env em process.env.
- tsx: é uma ferramenta útil para executar código TypeScript.
Execute o seguinte comando no console para instalar todos eles:
Crie um arquivo .env para configurar as variáveis de ambiente:
Usaremos o TypeScript para escrever o código porque ele oferece uma camada de segurança de tipos e uma melhor experiência para o desenvolvedor. Crie um arquivo TypeScript chamado main.ts e insira o código da próxima seção.
Importações de pacotes
No arquivo main.ts, começamos importando os módulos necessários e inicializando a configuração da variável de ambiente. Isso inclui os componentes do núcleo do LangGraph, as integrações do modelo OpenAI e o cliente Elasticsearch.
Também importamos o seguinte do arquivo dataIngestion.ts:
- ingestData: uma função que cria o índice e ingere os dados.
- Document e DocumentMetadata: interfaces que definem a estrutura do documento do conjunto de dados.
Cliente de armazenamento vetorial Elasticsearch, cliente de interações e cliente OpenAI
Esse código inicializará o armazenamento vetorial, o cliente de integrações e um cliente OpenAI.
O esquema de estado do fluxo de trabalho da aplicação ajudará na comunicação entre os nós:
No objeto de estado, passaremos a consulta do usuário, os conceitos extraídos dela, os precedentes legais recuperados e qualquer ambiguidade detectada sempre pelos nós. O estado também rastreia o precedente selecionado pelo usuário, o rascunho de análise gerado ao longo do caminho e a análise final quando todos os esclarecimentos forem concluídos.
Nós
searchPrecedents: Este nó realiza uma busca por similaridade no armazenar vetorial do Elasticsearch baseada na entrada do usuário Ele recupera até 5 documentos correspondentes e os imprime para que possam ser revisados pelo usuário.
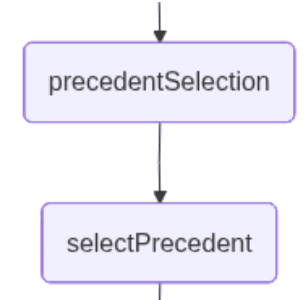
precedentSelection: este nó permite ao usuário selecionar, usando linguagem natural, o caso de uso recuperado pela pesquisa com a proximidade que melhor corresponde à pergunta. Nesse ponto, o aplicativo interrompe o fluxo de trabalho e aguarda a entrada do usuário.
selectPrecedent: este no envia a entrada do usuário, juntamente com os documentos recuperados, para serem interpretados de forma que um deles possa ser selecionado. O LLM realiza essa tarefa retornando um número que representa o documento que ele infere a partir da entrada em linguagem natural do usuário.
createDraft: este nó gera a análise legal inicial com base no precedente selecionado pelo usuário. Ele usa um LLM para avaliar como o precedente escolhido se aplica à pergunta do advogado e determina se o sistema tem informações suficientes para prosseguir.
Se o precedente puder ser aplicado diretamente, o nó produz uma análise preliminar e, seguindo o caminho correto, salta para o nó final. Se o LLM detectar ambiguidades, como termos contratuais indefinidos, detalhes do cronograma ausentes ou condições pouco claras, ele retorna com uma bandeira indicando que é necessário esclarecimento, junto com uma lista das informações específicas que devem ser fornecidas. Neste caso, a ambiguidade desencadeia o caminho à esquerda do gráfico.
Os dois caminhos que o gráfico pode seguir são os seguintes:
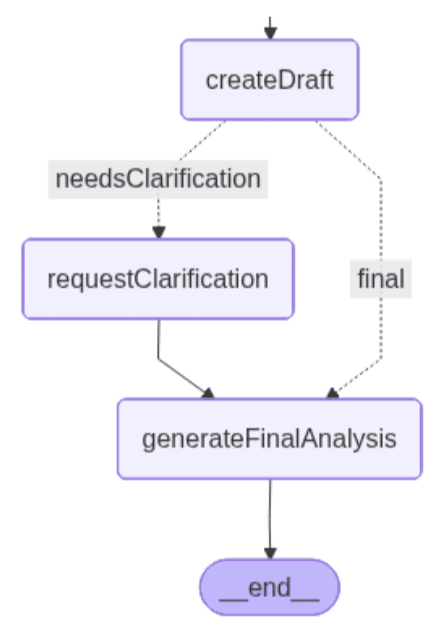
O caminho à esquerda inclui um nó adicional que cuida da clarificação.
requestClarification: este nó aciona a segunda etapa de intervenção humana quando o sistema identifica que a análise preliminar precisa de contexto essencial. O fluxo de trabalho é interrompido e é solicitado o usuário que ele esclareça os detalhes do contrato ausentes detectados pelo nó anterior.
generateFinalAnalysis: este nó gera a análise jurídica final combinando o precedente selecionado com o contexto adicional fornecido pelo usuário, se necessário. Utilizando os esclarecimentos obtidos na etapa HITL anterior, o LLM sintetiza o raciocínio do precedente, os detalhes do contrato fornecidos pelo usuário e as condições que determinam se pode ter ocorrido uma violação.
O nó gera uma análise completa que integra interpretação jurídica e recomendações práticas.
Construindo um gráfico:
No gráfico, podemos ver que a borda condicional define a condição para a escolha do caminho "final". Conforme demonstrado, a decisão agora depende do fato de a análise preliminar ter detectado ambiguidade que exija esclarecimentos adicionais.
Junte tudo para ser executado:
Execute o script:
Com todo o código alocado, vamos executar o arquivo main.ts escrevendo o seguinte comando no terminal:
Após a execução do script, a pergunta "Um padrão de atrasos repetidos constitui uma violação, mesmo que cada atraso individual seja pequeno?" será enviada ao Elasticsearch para realizar uma busca por proximidade e os resultados recuperados do índice serão exibidos. O app detecta que vários precedentes relevantes correspondem à consulta, então ele pausa a execução e pede que o usuário ajude a fazer a desambiguação de qual precedente legal for mais aplicável:
O interessante sobre este aplicativo é que podemos usar linguagem natural para escolher uma opção, permitindo que o LLM interprete a entrada do usuário para determinar a escolha correta. Vamos ver o que acontece se inserirmos o texto: “Caso H”
O modelo pega o esclarecimento do usuário e o integra ao fluxo de trabalho, prosseguindo com a análise final quando o contexto suficiente for fornecido. Nesta etapa, o sistema também utiliza a ambiguidade previamente detectada: a análise preliminar destacou detalhes contratuais ausentes que poderiam afetar e muito a interpretação jurídica. Esses itens de “informações ausentes” orientam o modelo na determinação de quais esclarecimentos são essenciais para resolver a incerteza antes de produzir uma opinião final confiável.
O usuário deve incluir na próxima entrada as solicitações de esclarecimentos. Vamos tentar com "O contrato exige 'pronta entrega' sem cronogramas. 8 atrasos de 2 a 4 dias em 6 meses. US$ 50 mil em perdas devido a 3 prazos não cumpridos pelo cliente. O fornecedor foi notificado, mas o padrão continuou."
Essa saída mostra a etapa final do fluxo de trabalho, em que o modelo integra o precedente selecionado (Caso H) e os esclarecimentos do advogado para gerar uma análise jurídica completa. O sistema explica por que o padrão de atrasos provavelmente constitui uma violação, destaca os fatores que sustentam essa interpretação e fornece recomendações práticas. No geral, a saída demonstra como os esclarecimentos do HITL resolvem a ambiguidade e permitem que o modelo produza uma opinião jurídica bem fundamentada e específica do contexto.
Outros cenários do mundo real
Esse tipo de aplicação, usando Elasticsearch, LangGraph e humanos, pode ser útil em outros tipos de apps como:
- Revisando ferramentas de chamadas antes da execução, por exemplo, em negociações financeiras, um humano aprova pedidos de compra/venda antes que eles sejam feitos.
- Forneça parâmetros adicionais quando necessário, por exemplo, na triagem de suporte ao cliente, onde um agente humano seleciona a categoria correta de problema quando a IA encontra múltiplas possíveis interpretações do problema do cliente.
E há muitos casos de uso que precisam ser descobertos em que a intervenção humana será um divisor de águas.
Conclusão
Com o LangGraph e o Elasticsearch, podemos criar agentes que tomem as próprias decisões e atuem como fluxos de trabalho lineares ou tenham condições de seguir um caminho ou outro. Com a intervenção humana, os agentes podem envolver o usuário real no processo de tomada de decisão para preencher lacunas contextuais e solicitar confirmações em sistemas em que a tolerância a falhas é fundamental.
Uma das vantagens dessa abordagem é que você pode filtrar um grande conjunto de dados usando os recursos do Elasticsearch e usar um LLM para ter um único documento como seleção do usuário. Essa última etapa seria muito mais complicada se você usasse apenas o Elasticsearch, pois há muitas maneiras de um ser humano se referir a um resultado usando linguagem natural.
Essa abordagem mantém o sistema rápido e eficiente em termos de tokens, pois enviamos ao LLM apenas o necessário para tomar a decisão final e não o conjunto de dados completo. Ao mesmo tempo, isso mantém a precisão na detecção da intenção do usuário e permite iterar até que a opção desejada seja escolhida.
Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.