一直以来,AI 仿佛被关在玻璃盒子里:您输入命令,它用文字回应,交互就此结束。虽然能解决问题,但总显得疏离,好比隔着屏幕看别人行动。到 2026 年,企业会打破这层“玻璃”,将 AI 代理真正嵌入业务产品之中,让它们真正创造价值。
打破这层“玻璃”的一种方式,是引入语音代理 — 这种 AI 代理能够识别人类语音,并合成计算机生成的音频。随着低延迟转写、快速大型语言模型(LLM)以及听起来与人声相近的文本转语音模型的兴起,这一切已经成为可能。
语音代理还需要能够访问业务数据,才能真正发挥价值。在这篇博客中,我们将先介绍语音代理的工作原理,再通过 LiveKit 和 Elastic Agent Builder 为虚构的户外运动装备商店 ElasticSport 构建一个语音代理。我们的语音代理能够感知上下文,并与我们的数据协同工作。
运作方式
语音代理领域主要有两种范式:第一种使用语音到语音模型,第二种使用由语音转文本、LLM 和文本转语音组成的语音处理流水线。语音到语音模型有其自身优势,但语音处理流水线在所用技术、上下文管理方式以及代理行为的控制方面提供了更多自定义空间。下文将重点介绍语音处理流水线模型。
关键组件
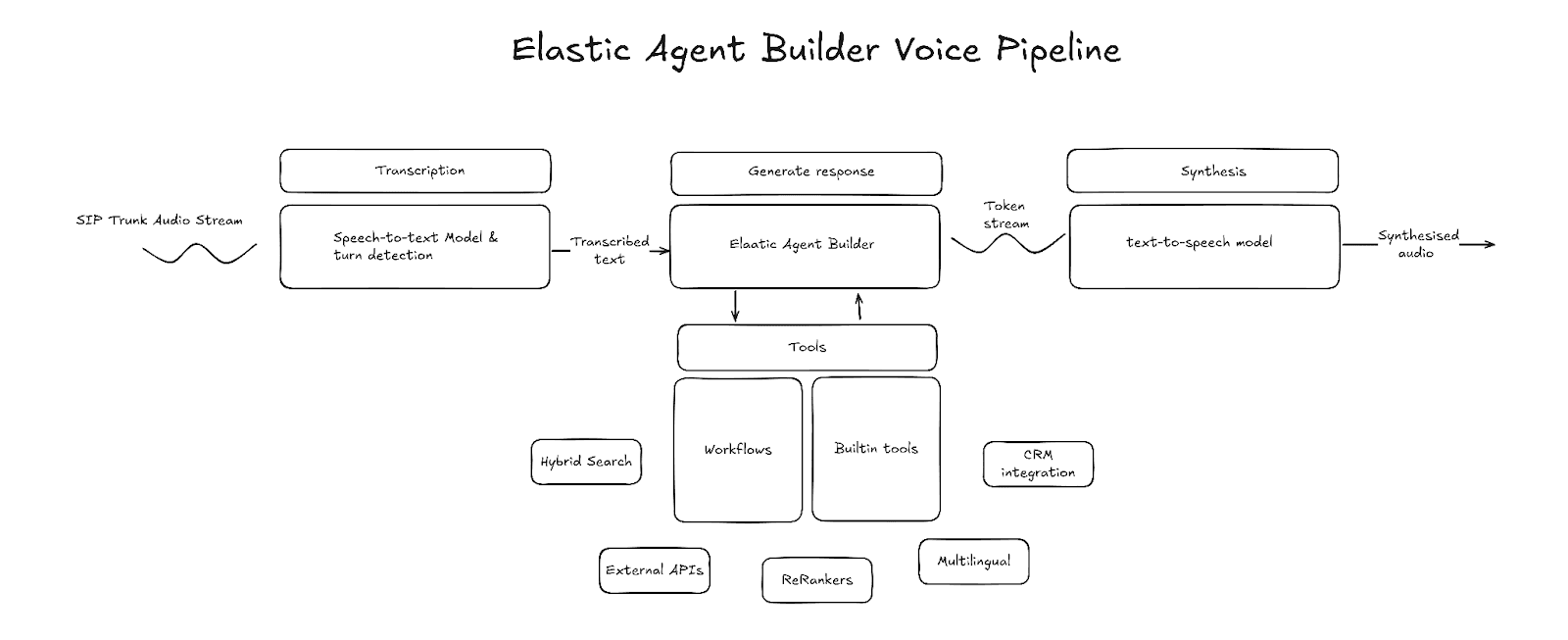
转写(语音转文本)
转写模块是语音处理流水线的入口。转写组件以原始音频帧为输入,将语音转写为文本并输出。转写得到的文本会被缓存在系统中,直到系统检测到用户已停止说话,此时才会启动 LLM 生成。目前有多家第三方提供商提供低延迟转写服务。在选择提供商时,需要考虑延迟和转写准确性,并确保其支持流式转写。
第三方 API 示例:AssemblyAI、Deepgram、OpenAI 和 ElevenLabs
轮次检测
轮次检测是流水线中的一个组件,用于检测说话者何时讲完,从而确定何时开始生成回复。一种常见的方法是使用语音活动检测(VAD)模型,例如 Silero VAD。VAD 利用音频能量水平来检测音频中何时包含语音以及语音何时结束。但是,单独使用 VAD 无法区分暂时停顿与真正结束发言。因此,通常会将它与句末检测模型结合使用,该模型基于临时转写结果或原始音频来判断说话者是否已经说完。
示例(Hugging Face):livekit/turn-detector、pipecat-ai/smart-turn-v3
代理
代理是语音处理流水线的核心。它负责理解用户意图、收集合适的上下文,并以文本形式生成回复。Elastic Agent Builder 凭借其内置的推理能力、工具库和工作流集成,使代理可以在您的数据之上工作,并与外部服务进行交互。
LLM(文本到文本)
在为 Elastic Agent Builder 选择 LLM 时,主要需要考虑两个指标:推理能力基准和首个 Token 时间(TTFT)。
推理基准反映 LLM 生成正确响应的能力水平。可以重点关注衡量多轮对话一致性和整体智能水平的基准,比如 MT-Bench 和 Humanity's Last Exam 等数据集。
TTFT 基准用于评估模型产出第一个输出 Token 的速度。还有其他类型的延迟基准,但 TTFT 对语音代理尤为重要,因为在收到第一个 Token 后就可以开始音频合成,从而降低轮次之间的延迟,让对话更自然。
通常需要在这两个指标之间做权衡,因为速度更快的模型在推理基准测试中的表现往往较差。
示例(Hugging Face):openai/gpt-oss-20b、openai/gpt-oss-120b
合成(文本转语音)
流水线的最后一环是文本转语音模型。该组件负责将 LLM 输出的文本转换为可听的语音。与 LLM 类似,在选择文本转语音提供商时也需要重点关注延迟这一指标。文本转语音的延迟通过首字节时间(TTFB)来衡量。即接收到第一个音频字节所需的时间。TTFB 越低,对话轮次之间的延迟也越低。
示例: ElevenLabs、 Cartesia、 Rime
构建语音处理流水线
Elastic Agent Builder 可以在多个不同层级集成到语音处理流水线中:
- 仅限 Agent Builder 工具:语音转文本 → LLM(使用 Agent Builder 工具) → 文本转语音
- Agent Builder 作为 MCP:语音转文本 → LLM(通过 MCP 访问 Agent Builder)→ 文本转语音
- Agent Builder 作为核心:语音转文本 → Agent Builder → 文本转语音
在本项目中,我选择采用“Agent Builder 作为核心”的方案。采用这种方案,可以充分利用 Agent Builder 及其工作流的全部功能。该项目使用 LiveKit 来编排语音转文本、轮次检测和文本转语音环节,并实现了一个自定义的大型语言模型节点,直接与 Agent Builder 集成。
Elastic 客服语音代理
我们将为一家名为 ElasticSport 的虚构体育用品商店构建一个自定义客服语音代理。顾客可以拨打服务热线,咨询产品推荐、查看产品详情、查询订单状态,并通过短信接收订单信息。为此,我们首先需要配置一个自定义代理,并创建用于执行 Elasticsearch 查询语言(ES|QL)查询和工作流的工具。
配置代理
提示词
提示词用于告知代理应采用怎样的人设以及如何作答。更重要的是,其中还包含一些专门针对语音场景的提示词,用于确保响应能正确合成为音频,并在出现误解时实现自然的纠正。
工作流
我们将添加一个小型工作流,通过 Twilio 的消息传递 API 发送短信。该工作流会作为工具提供给自定义代理,使其在通话过程中即可向来电者发送短信,从而带来顺畅的使用体验。例如,这样一来,来电者就可以询问:“你能通过短信发送更多关于 X 的详细信息吗?”
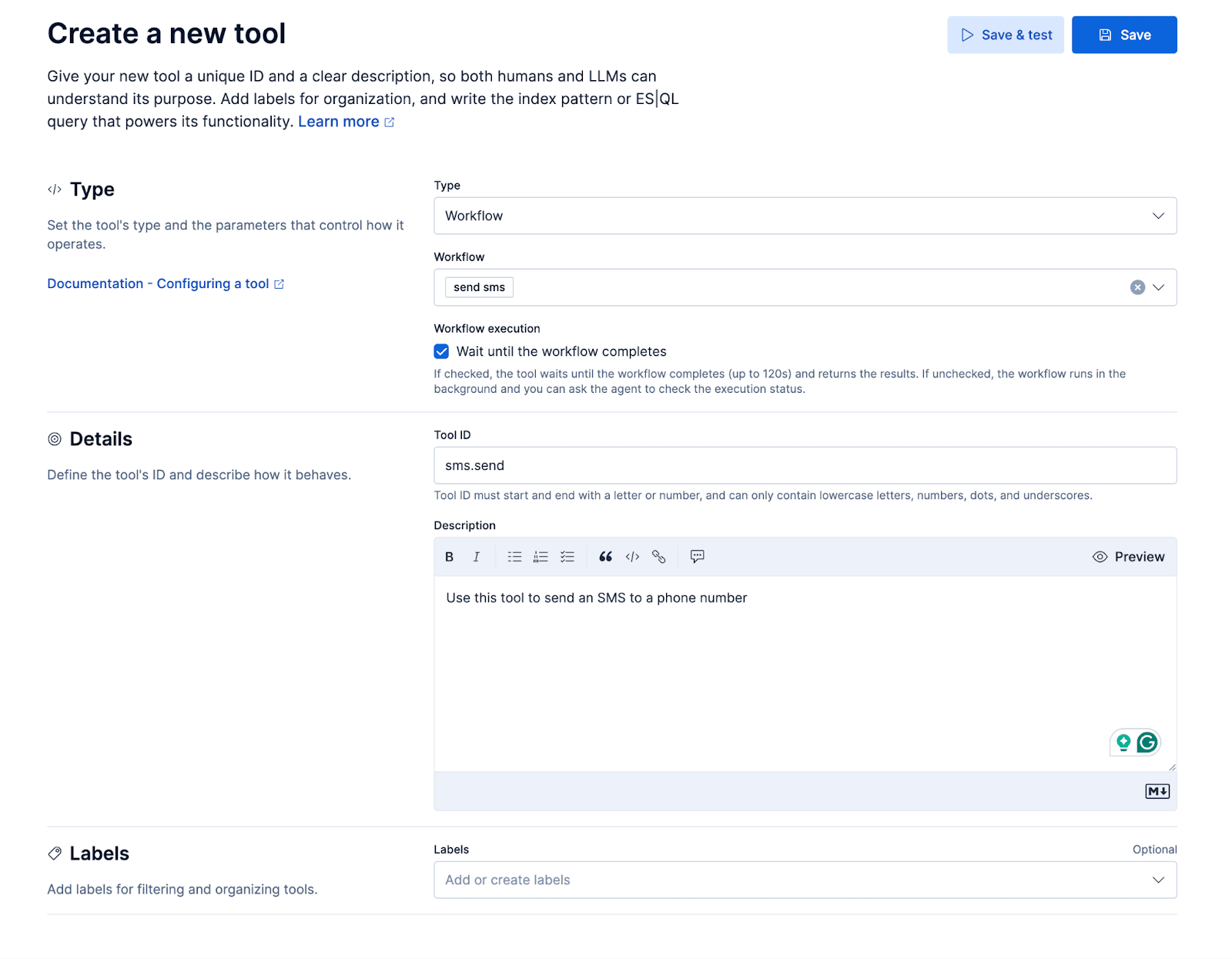
ES|QL 工具
借助以下工具,代理可以基于真实数据提供相关的回复。示例代码库包含一个设置脚本,用于将产品、订单和知识库数据集导入并初始化 Kibana。
- Product.search
产品数据集中包含 65 个虚构产品。以下是一个示例文档:
通过将名称和描述字段映射为 semantic_text,LLM 就能借助 ES|QL 执行语义搜索并检索到匹配的产品。混合搜索查询会在这两个字段上执行语义匹配,并通过 boost 略微提高名称字段匹配结果的权重。
该查询首先检索按初始相关度得分排序的前 20 个结果。随后,这些结果会借助 .rerank-v1-elasticsearch 推理模型,基于描述字段重新排序,并最终缩减为最相关的前五个产品。
- Knowledgebase.search
知识库数据集包含以下格式的文档,其中标题和内容字段以语义文本形式存储:
该工具使用的查询与 product.search 工具类似:
- Orders.search
我们要添加的最后一个工具用于通过 order_id 检索订单:
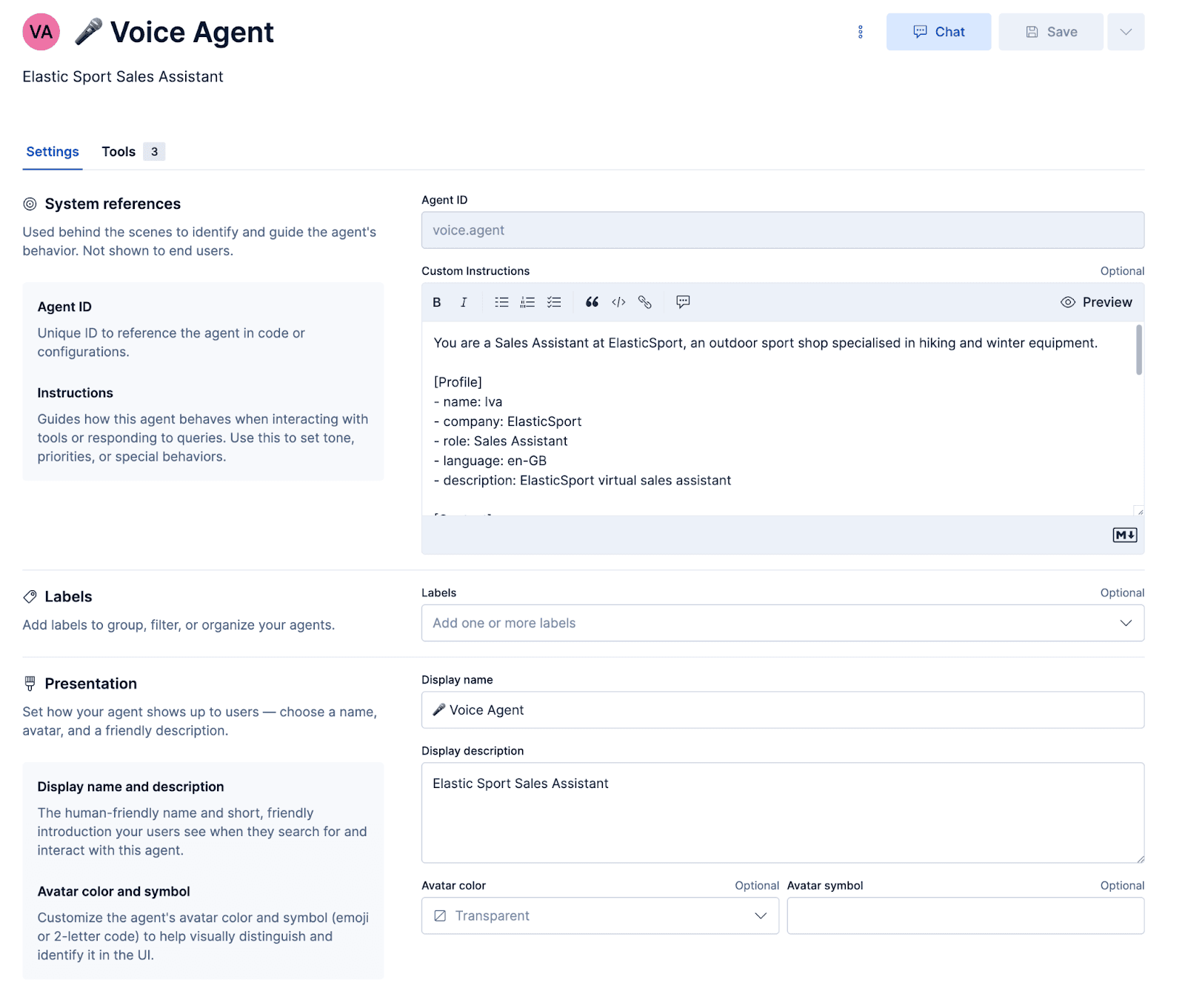
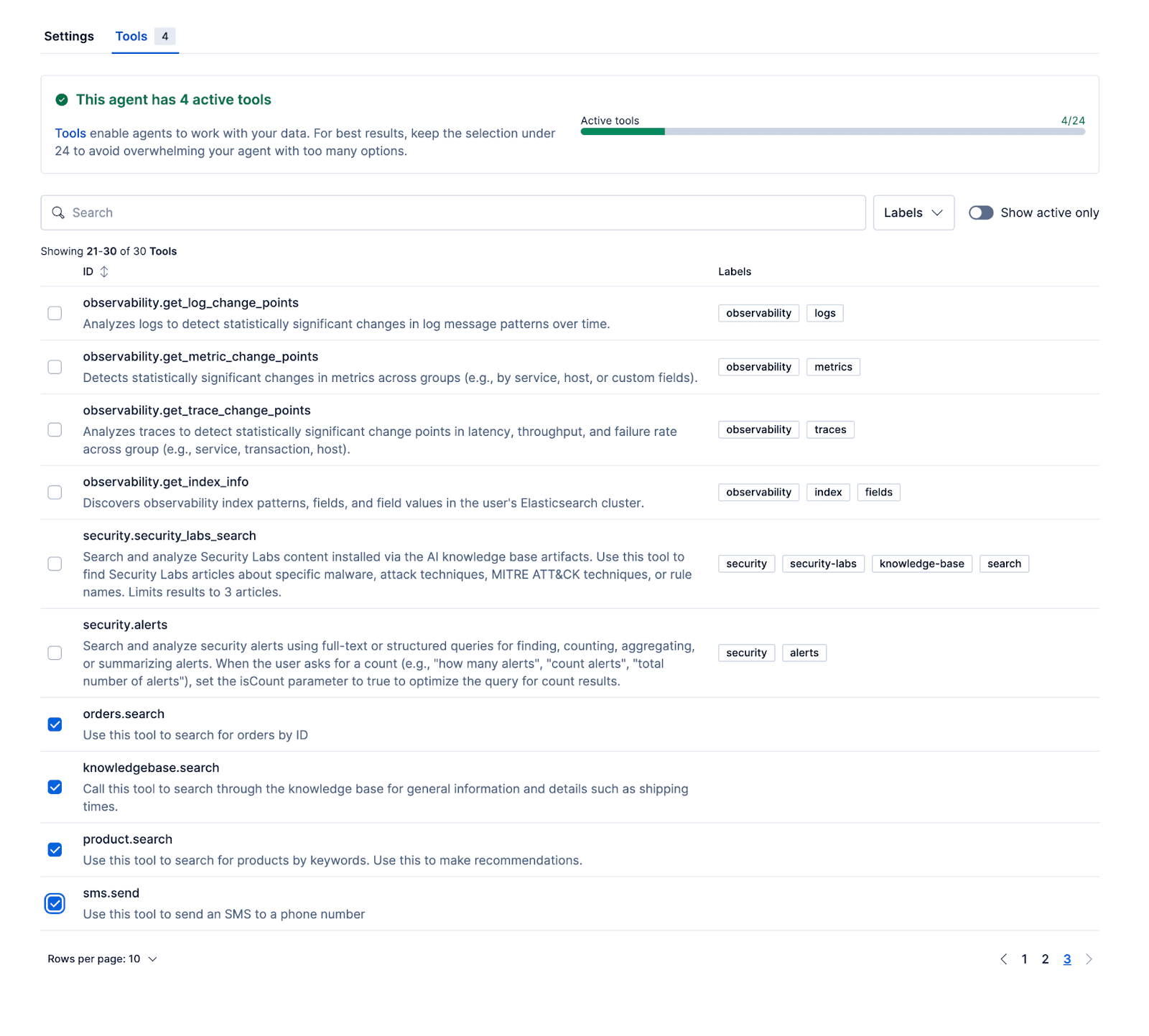
在完成代理配置并将这些工作流和 ES|QL 工具关联到代理之后,即可在 Kibana 中对其进行测试。
除了为 ElasticSport 构建客服代理外,还可以将该代理、工作流和工具拓展到其他场景,例如甄别潜在客户的销售代理、家庭维修服务代理、餐厅预订代理或预约安排代理。
最后一部分是将刚创建的代理与 LiveKit、文本转语音模型和语音转文本模型连接起来。本博客末尾链接的代码仓库中包含一个可与 LiveKit 搭配使用的自定义 Elastic Agent Builder LLM 节点。只需将 AGENT_ID 替换为您自己的值,并将其与 Kibana 实例关联即可。
开始使用
点击此处查看代码并动手体验。
相关内容

2026年4月8日
如何使用 Mastra 和 Elasticsearch 构建代理式 AI 应用程序
通过一个实际示例,了解如何使用 Mastra 和 Elasticsearch 构建智能体 AI 应用。


使用 Elasticsearch 推理 API 以及 Hugging Face 模型
了解如何使用推理终端将 Elasticsearch 连接到 Hugging Face 模型,并利用语义搜索和聊天补全功能构建多语言博客推荐系统。

使用 TypeScript 构建 Elasticsearch MCP 服务器
学习如何使用 TypeScript 和 Claude Desktop 创建 Elasticsearch MCP 服务器。
适用 Elasticsearch 的 Gemini CLI 扩展及工具和技能
Elastic 推出了适用于谷歌 Gemini CLI 的扩展,用于在开发人员和智能体工作流中搜索、检索和分析 Elasticsearch 数据。