在本文中,我们将探讨如何结合 LangGraph 与 Elasticsearch 来构建一个人机协同 (HITL) 应用。这种方法能够让 AI 系统直接将用户纳入决策流程,使交互更加可靠且具备情境感知能力。我们将通过一个基于情境的实例来展示,LangGraph 工作流如何与 Elasticsearch 集成,以实现数据检索、处理用户输入并生成精准结果。
要求
- NodeJS 18 或更高版本
- OpenAI API密钥
- Elasticsearch 8.x+ 部署
为何在生产级人机协同 (HITL) 系统里采用 LangGraph?
在先前的一篇文章中,我们介绍了 LangGraph 以及它借助 LLM 和条件边来构建 RAG 系统的优势,该系统能够自动做出决策并展示结果。然而,有时我们并不希望系统实现端到端的自主运行,而是期望用户在执行循环中能够选择选项并做出决策。这一概念被命名为“人机协同”。
人机协同或人工介入
这是一种 AI 理念,让真人与 AI 系统进行交互,从而提供更多背景信息、评估回应内容、编辑回应结果、请求更多信息等。在合规、决策制定或内容生成等容错率低的场景中,这种理念非常实用,有助于提升 LLM 输出结果的可靠性。
一个常见的例子是,当你的编程助手请求你授权在终端执行某个特定命令时,或者在开始编程前,向你展示分步思考过程以供你审批。
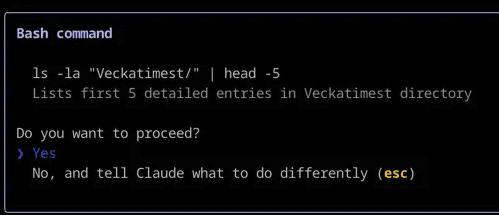
Claude Code 采用人机协同模式,在执行 Bash 命令前会向你请求确认
Elasticsearch + LangGraph:它们如何交互
LangChain 允许我们将 Elasticsearch 用作向量存储库,并在 LangGraph 应用中执行查询操作。这对于执行全文检索或语义搜索十分有用,而 LangGraph 则用于定义特定的工作流、工具以及交互方式。此外,它还引入 HITL 作为与用户的额外交互层。
实际应用:人机协同
让我们设想这样一种情形:一位律师就其近期承接的案件存在疑问。如果没有合适的工具,他需要手动查阅法律文章和判例,完整阅读后,再解读它们如何适用于自己所接的案件情况。然而,借助 LangGraph 和 Elasticsearch,我们能够构建一个系统,该系统可搜索法律判例数据库,并生成一份融入律师所提供具体细节和背景信息的案件分析报告。
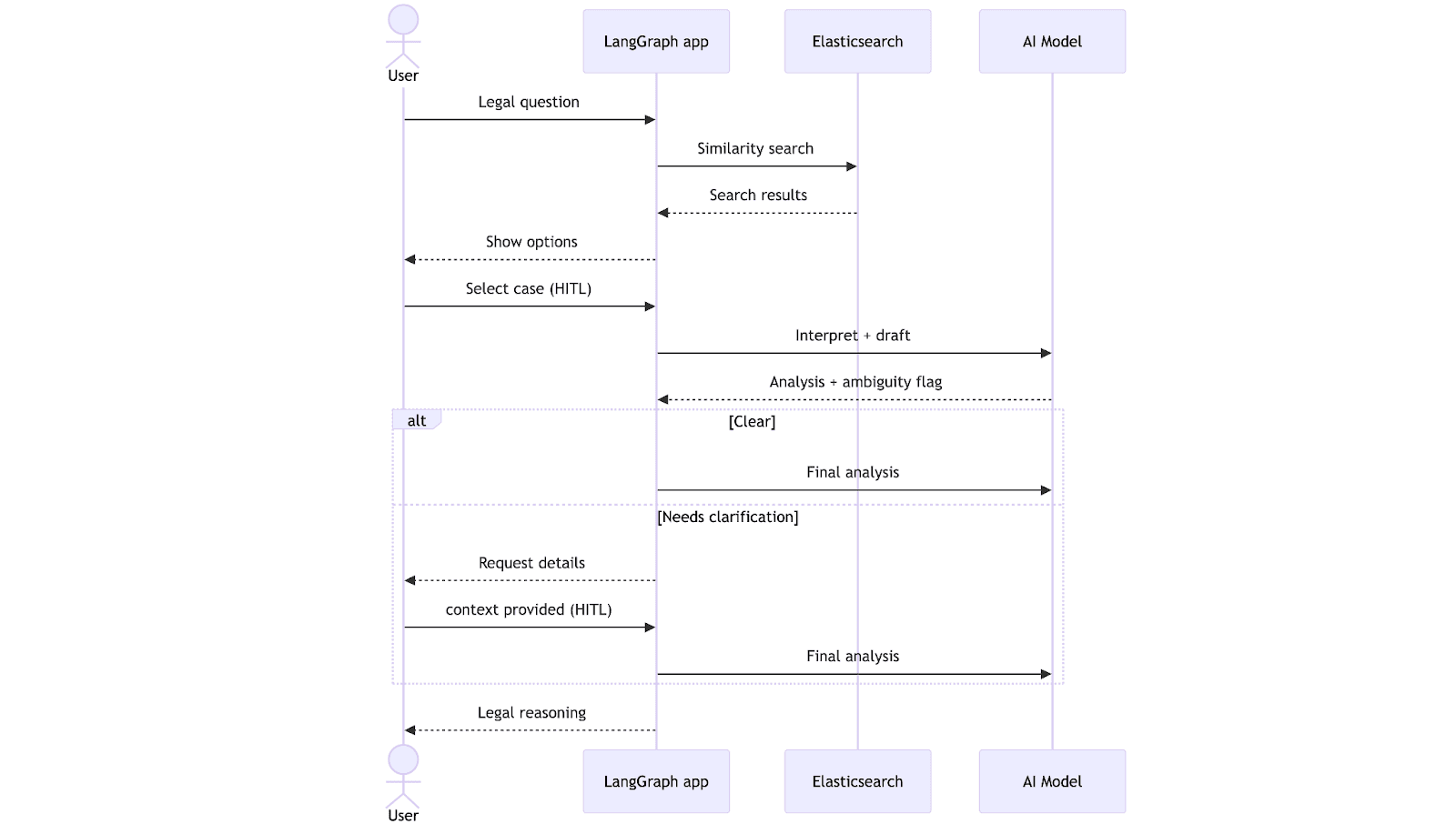
工作流始于律师提交法律问题。系统在 Elasticsearch 中执行向量搜索,检索出最相关的判例,并以自然语言的形式呈现给律师供其选择。律师选择后,LLM 生成分析草案,并检查信息是否完整。此时,工作流有两条路径:如果一切清晰明确,则直接生成最终分析报告;如果存在疑问,则暂停并请求律师作出澄清。待缺失的背景信息提供完毕后,系统会综合考虑这些澄清内容,完成分析并返回结果。
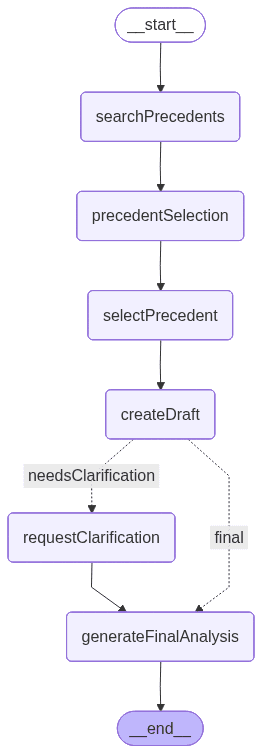
以下是 LangGraph 绘制的图表,显示了应用程序在开发结束时的效果。每个节点代表一种工具或功能:
数据集
以下是为本次示例所使用的数据集。该数据集包含一系列法律判例,每个判例均描述了一起涉及服务延误的案件,涵盖法院的判决依据以及最终判决结果。
摄取和索引设置
索引设置和数据摄取逻辑在 dataIngestion.ts 文件中定义,在该文件中我们列出了用于处理索引创建的函数。此设置与 LangChain 针对 Elasticsearch 的向量存储接口兼容。
注意:映射设置也包含在 dataIngestion.ts 文件中。
安装软件包并设置环境变量
让我们使用默认设置初始化一个 Node.js 项目,并引入
- @elastic/elasticsearch:这是适用于 Node.js 的 Elasticsearch 客户端,用于建立连接、创建索引以及执行查询操作。
- @langchain/community:提供对社区支持工具的集成功能,其中包含 ElasticVectorSearch 存储库。
- @langchain/core:LangChain 的核心构建模块,涵盖链、提示词以及工具函数等。
- @langchain/langgraph:增添基于图形的编排功能,支持具备节点、边以及状态管理的工作流。
- @langchain/openai:通过 LangChain 提供对 OpenAI 模型(LLM 及嵌入向量模型)的访问接口。
- dotenv:将环境变量从 .env 文件加载至 process.env 中。
- tsx:是一个用于执行 TypeScript 代码的实用工具。
在控制台中运行以下命令以安装所有相关组件:
创建 .env 文件来设置环境变量:
我们将采用 TypeScript 进行代码编写,原因在于它能提供一层类型安全保障,同时带来更优的开发体验。创建一个名为 main.ts 的 TypeScript 文件,并将下一节的代码插入其中。
软件包导入
在 main.ts 文件中,我们首先导入所需的模块,并初始化环境变量配置。这涵盖核心的 LangGraph 组件、OpenAI 模型集成以及 Elasticsearch 客户端。
我们还从 dataIngestion.ts 文件导入以下各项:
- ingestData:创建索引并摄取数据的函数。
- Document 与 DocumentMetadata:用于定义数据集文档结构的接口。
Elasticsearch 向量存储客户端、嵌入客户端以及 OpenAI 客户端
此代码将初始化向量存储、嵌入客户端和一个 OpenAI 客户端。
应用程序工作流状态架构将有助于节点之间的通信:
在状态对象中,我们将传递用户查询内容、从查询中提取的概念、检索到的法律判例以及检测到的任何歧义信息至各节点。该状态对象还会跟踪用户选定的判例、过程中生成的草案分析,以及在所有澄清工作完成后生成的最终分析。
节点
searchPrecedents:此节点基于用户输入,在 Elasticsearch 向量存储库中执行相似性搜索。它最多可检索 5 份匹配文件,并打印出来供用户查看。
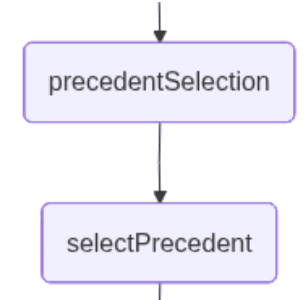
precedentSelection:此node允许用户使用自然语言选择由最接近搜索检索到的、最匹配问题的用例。此时,应用程序中断工作流并等待用户输入。
selectPrecedent:此节点会将用户输入内容以及检索到的文档一并发送,以供解析,进而从中选出一个文档。LLM 通过返回一个数字来完成该任务,此数字代表模型依据用户自然语言输入所推断出的文档。
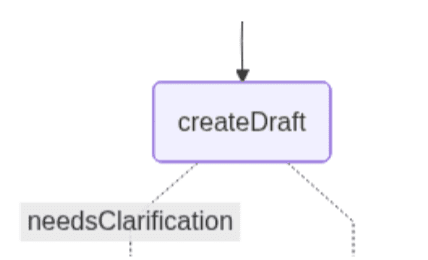
createDraft:此节点根据用户选择的判例生成初步法律分析。它借助 LLM 评估所选判例如何适用于律师提出的问题,并判断系统是否具备足够信息以继续推进后续流程。
如果判例可直接适用,该节点将生成一份草案分析,并沿着正确路径直接跳转至最终节点。若 LLM 检测到模棱两可之处,例如未明确的合同条款、缺失的时间线细节或模糊的条件,它会返回一个提示需要澄清的标识,同时附上必须提供的具体信息列表。在此情况下,歧义将触发图中的左侧路径。
图中的两条路径如下所示:
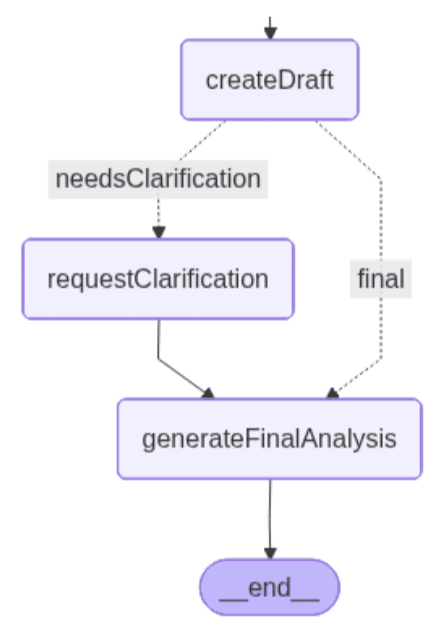
左侧路径包含一个额外的节点,用于处理澄清。
requestClarification:当系统判定草稿分析缺少关键背景信息时,此节点会触发第二轮人机协同步骤。工作流会被中断,系统会要求用户对前一节点检测到的缺失合同细节进行说明。
generateFinalAnalysis:此节点在必要时会将用户所选判例与用户提供的额外背景信息相结合,从而生成最终法律分析。借助上一轮 HITL 步骤中收集到的澄清信息,LLM 会综合判例的判决依据、用户提供的合同细节以及判定违约是否可能发生的条件,形成最终分析结果。
该节点可提供完整的分析,将法律解释和实际建议融为一体。
构建图表:
从图中,我们可以看出条件边定义了选择“最终”路径的条件。如图所示,现在的决策取决于草案分析是否检测到存在需要额外澄清的歧义。
将所有内容汇总起来执行:
执行脚本:
分配好所有代码后,让我们在终端上执行 main.ts 文件,编写以下命令:
脚本执行后,问题“即便每次单独的延误都较为轻微,一连串重复出现的延误是否构成违约?”将被发送至 Elasticsearch 以执行邻近搜索,从索引中检索到的结果将予以展示。应用程序检测到多个相关判例与查询匹配,因此暂停执行,并请求用户协助明确哪个法律判例最为适用:
这款应用程序的有趣之处在于,我们能够使用自然语言来选择一个选项,让 LLM 解析用户输入内容,从而确定正确选择。让我们看看,若输入文本“Case H”会发生什么。
模型会采纳用户的澄清信息,并将其整合进工作流,在提供足够背景信息后开展最终分析。在此步骤中,系统还会利用先前检测到的歧义:草案分析指出合同中缺失的细节,这些细节可能对法律解释产生实质性影响。这些“缺失信息”项为模型提供指引,助其确定在给出可靠最终意见前,为消除不确定性而必须获取的关键澄清内容。
用户必须在下一次输入中包含此前被要求澄清的内容。我们以如下内容为例进行尝试:“合同要求‘及时交付’,但未规定时间期限。在 6 个月内出现 8 次 2-4 天的延误。因错过 3 次客户截止日期,造成 5 万美元损失。已通知供应商,但此类情况仍持续发生。”
此输出展示了工作流的最终阶段,在该阶段,模型将所选判例 (Case H) 与律师的澄清信息相结合,以生成一份完整的法律分析报告。系统解释了延误交付很可能构成违约的原因,列举了支持这一解释的各项因素,并给出了切实可行的建议。总体而言,该输出展示了 HITL 澄清如何消除歧义,并使模型能够生成有充分依据、贴合具体情境的法律意见。
其他真实场景
这种借助 Elasticsearch、LangGraph 以及人机协同技术的应用,在其他各类应用程序中也可能颇具价值,例如:
- 在工具调用执行前对其进行审查,例如在金融交易领域,人类会在下买入/卖出订单前予以批准。
- 在需要时提供额外参数,例如在客户支持分流场景中,当 AI 对客户问题存在多种可能的解读时,人类客服人员会选择正确的问题类别。
还有大量有待发掘的用例,在这些用例中,人机协同将成为具有变革性的关键因素。
结论
借助 LangGraph 和 Elasticsearch,我们能够构建具备自主决策能力且可作为线性工作流运行的智能体,或者构建具有条件判断功能、可依据不同条件选择不同路径的智能体。引入人机协同机制后,这些智能体能在决策过程中让实际用户参与进来,以填补背景信息空白,并在容错性至关重要的系统中请求用户确认。
此方法的优势之一在于,能够借助 Elasticsearch 的功能对大规模数据集进行筛选,随后利用 LLM 获取用户所选的单一文档。若仅使用 Elasticsearch 完成最后这一步骤,难度会大得多,因为人类在运用自然语言指代某个结果时,方式多种多样。
这种方法能够确保系统保持高速运行且令牌使用高效,因为我们仅向 LLM 发送做出最终决策所需的信息,而非整个数据集。与此同时,该方法还能使系统在检测用户意图方面保持高度精准,并不断迭代,直至选定用户期望的选项。
相关内容

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。

2026年4月8日
如何使用 Mastra 和 Elasticsearch 构建代理式 AI 应用程序
通过一个实际示例,了解如何使用 Mastra 和 Elasticsearch 构建智能体 AI 应用。


使用 Elasticsearch 推理 API 以及 Hugging Face 模型
了解如何使用推理终端将 Elasticsearch 连接到 Hugging Face 模型,并利用语义搜索和聊天补全功能构建多语言博客推荐系统。

使用 TypeScript 构建 Elasticsearch MCP 服务器
学习如何使用 TypeScript 和 Claude Desktop 创建 Elasticsearch MCP 服务器。