En las pilas de observabilidad modernas, la ingesta de logs no estructurados de diversos proveedores de datos en plataformas como Elasticsearch sigue siendo un reto. La dependencia de reglas de análisis creadas manualmente crea pipelines frágiles, donde incluso las actualizaciones menores de código ascendente conducen a fallas en los análisis y datos no indexados. Esta fragilidad se agrava con el desafío de la escalabilidad: en entornos dinámicos de microservicios, la incorporación continua de nuevos servicios convierte el mantenimiento manual de las reglas en una pesadilla operativa.
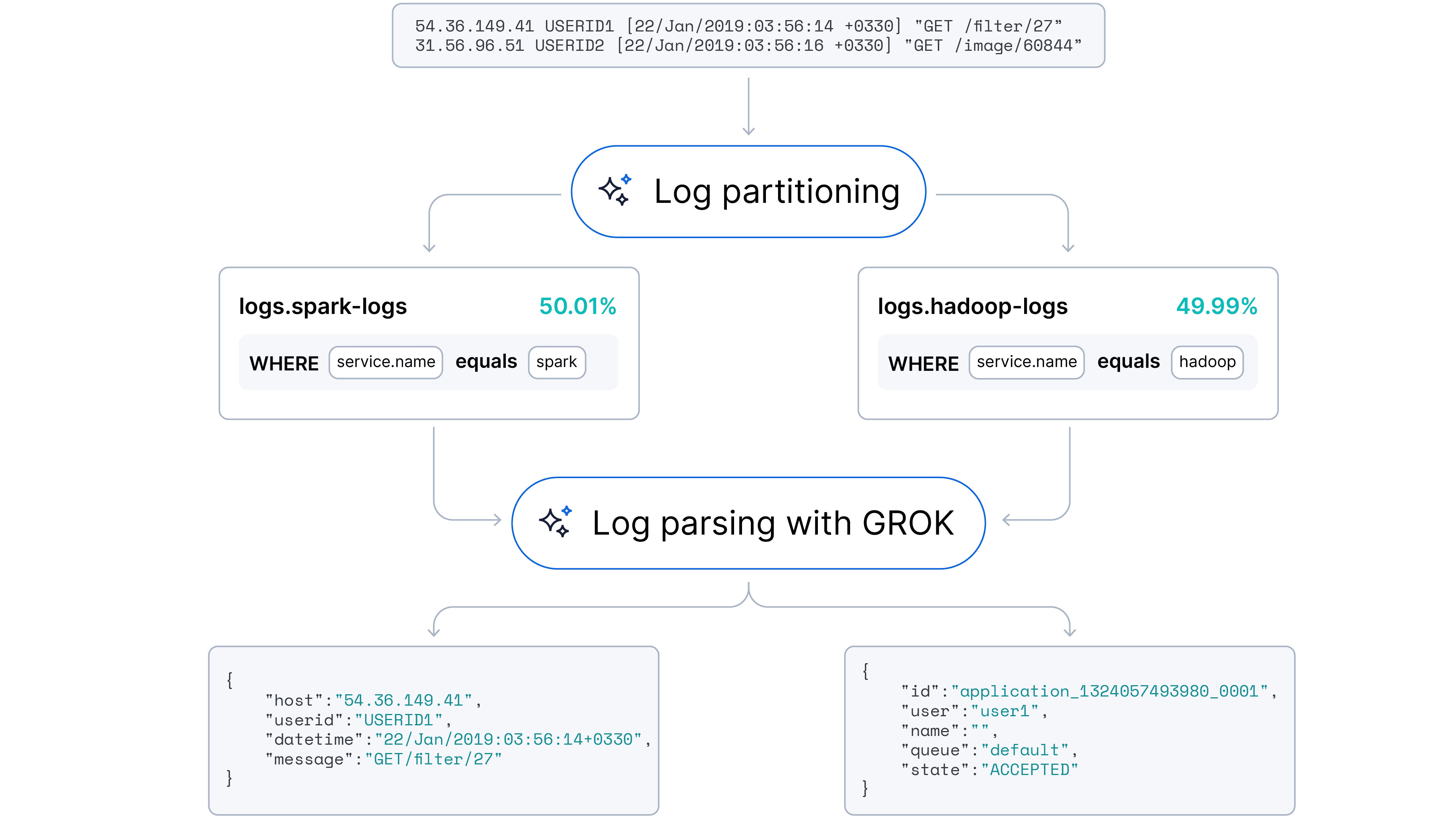
Nuestro objetivo era pasar a un enfoque automatizado y adaptable capaz de gestionar tanto el análisis de logs (extracción de campos) como la partición de logs (identificación de las fuentes). Planteamos la hipótesis de que los modelos de lenguaje grandes (LLMs), con su comprensión inherente de la sintaxis del código y los patrones semánticos, podrían automatizar estas tareas con una intervención humana mínima.
¡Nos complace anunciar que esta característica ya está disponible en Streams!
Descripción de los sets de datos
Elegimos un conjunto de logs Loghub para fines de prueba de concepto (POC). Para nuestra investigación, seleccionamos muestras representativas de las siguientes áreas clave:
- Sistemas distribuidos: utilizamos los sets de datos HDFS (Hadoop Distributed File System) y Spark. Estas contienen una mezcla de mensajes de información, depuración y error típicos de las plataformas de big data.
- Aplicaciones de servidor y web: los logs de los servidores web Apache y OpenSSH proporcionaron una fuente de acceso, error y eventos relevantes para la seguridad. Son fundamentales para supervisar el tráfico web y detectar posibles amenazas.
- Sistemas operativos: incluimos logs de Linux y Windows. Estos sets de datos representan los eventos comunes y semiestructurados a nivel de sistema que los equipos de operaciones encuentran a diario.
- Sistemas móviles: para asegurarnos de que nuestro modelo pueda manejar logs de entornos móviles, incluimos los sets de datos de Android. Estos logs suelen ser muy detallados y recogen una amplia gama de actividades a nivel de aplicación y de sistema en los dispositivos móviles.
- Supercomputadoras: para probar el rendimiento en entornos de computación de alto rendimiento (HPC), incorporamos el conjunto de datos BGL (Blue Gene/L), que presenta logs altamente estructurados con terminología específica de dominio.
Una ventaja clave de la colección Loghub es que los logs están en gran medida sin depurar y sin etiquetar, lo que refleja un entorno de producción en vivo ruidoso con arquitectura de microservicios.
Ejemplos de logs:
Además, creamos un clúster Kubernetes con una aplicación web típica y una base de datos configurada para extraer logs adicionales en el dominio más común.
Ejemplo de campos comunes de log: marca de tiempo, nivel de log (INFO, WARN, ERROR), fuente, mensaje.
Análisis de logs con pocos ejemplos con un LLM
Nuestro primer conjunto de experimentos se centró en una pregunta fundamental: ¿puede un LLM identificar de manera confiable los campos clave y generar reglas de análisis consistentes para extraerlos?
Pedimos a un modelo que analizara muestras de log sin procesar y generara reglas de análisis de log en formatos de expresión regular (regex) y Grok. Nuestros resultados demostraron que este enfoque tiene un gran potencial, pero también plantea desafíos importantes de implementación.
Alta confianza y conciencia del contexto
Los resultados iniciales fueron prometedores. El LLM demostró una gran capacidad para generar reglas de análisis sintáctico que coincidieran con los pocos ejemplos proporcionados con un alto grado de confianza. Además de la simple comparación de patrones, el modelo demostró su capacidad para comprender los logs: podía identificar y nombrar correctamente la fuente del log (por ejemplo, la aplicación de seguimiento de salud, la aplicación web Nginx, la base de datos Mongo).
El dilema "Goldilocks" de las muestras de entrada
Nuestros experimentos revelaron rápidamente una falta significativa de solidez debido a la extrema sensibilidad a la muestra de entrada. El rendimiento del modelo fluctúa drásticamente en función de los ejemplos específicos de logs que se incluyan en el prompt. Observamos un problema similar de log en el que la muestra debe incluir logs lo suficientemente diversos :
- Demasiado homogéneo (sobreajuste): si los registros de entrada son demasiado similares, el LLM tiende a sobreespecificar. Trata datos variables (como nombres de clases Java específicas en un seguimiento de pila) como partes estáticas de la plantilla. Esto genera reglas frágiles que cubren una proporción pequeña de logs y extraen campos inutilizables.
- Demasiado heterogéneo (confusión): por el contrario, si la muestra contiene una variación significativa de formato, o peor aún, "trash logs" como barras de progreso, tablas de memoria o arte ASCII, el modelo tendrá dificultades para encontrar un denominador común. Suele recurrir a generar regexes complejos y rotos o a generalizar descuidadamente toda la línea en un solo campo de mensajes.
La restricción de la ventana de contexto
También encontramos un cuello de botella en la ventana de contexto. Cuando los logs de entrada eran largos, heterogéneos o ricos en campos extraíbles, la salida del modelo solía deteriorarse, y se "desordenaba" o era demasiado larga para caber en la ventana de contexto de salida. Naturalmente, la fragmentación (chunking) ayuda en este caso. Al dividir los logs mediante delimitadores basados en caracteres y entidades, podríamos ayudar al modelo a centrarse en extraer los campos principales sin sentirse abrumado por el ruido.
La brecha de consistencia y estandarización
Incluso cuando el modelo genera reglas correctamente, notamos ligeras inconsistencias:
- Variaciones en la denominación de servicios: el modelo propone diferentes nombres para la misma entidad (por ejemplo, etiquetar la fuente como "Spark", "Apache Spark" y "Spark Log Analytics" en diferentes ejecuciones).
- Variaciones en los nombres de los campos: los nombres de los campos carecían de estandarización (p. ej.:
idvs.service.idvs.device.id). Normalizamos los nombres al utilizar una nomenclatura de campos de Elastic estandarizada. - Variación de la resolución: la resolución de la extracción de campos variaba en función del grado de similitud entre los logs de entrada.
Huella digital en formato de log
Para abordar el reto de la similitud de logs, presentamos una heurística de alto rendimiento: la huella digital en formato de log (LFF).
En lugar de alimentar logs crudos y ruidosos directamente a un LLM, primero aplicamos una transformación determinista para revelar la estructura subyacente de cada mensaje. Este paso de preprocesamiento abstrae los datos de las variables y genera una "huella digital" simplificada que nos permite agrupar logs relacionados.
La lógica de mapping es sencilla para garantizar la velocidad y la consistencia:
- Abstracción de dígitos: cualquier secuencia de dígitos (0-9) se reemplaza por un solo "0".
- Abstracción de texto: cualquier secuencia de caracteres alfabéticos con espacios en blanco se reemplaza por una sola "a".
- Normalización de espacios en blanco: todas las secuencias de espacios en blanco (espacios, tabulaciones, saltos de línea) se colapsan en un solo espacio.
- Conservación de símbolos: se conservan los signos de puntuación y los caracteres especiales (por ejemplo: :, [, ], /), ya que suelen ser los indicadores más claros de la estructura del log.
Presentamos el enfoque de mapping de logs. Los patrones básicos de mapping incluyen lo siguiente:
- Dígitos de 0-9 de cualquier longitud -> a "0".
- Texto (caracteres alfabéticos con espacios) de cualquier longitud -> a "a".
- Espacios en blanco, tabulaciones y líneas nuevas -> a un solo espacio.
Veamos un ejemplo de cómo este mapping nos permite transformar los logs.

Como resultado, obtenemos las siguientes máscaras de log:

Mira las huellas dactilares de los dos primeros logs. A pesar de las diferentes marcas de tiempo, clases de origen y contenido de mensajes, sus prefijos (0/0/0 0:0:0 a a.a:) son idénticos. Esta alineación estructural nos permite agrupar automáticamente estos logs en el mismo clúster.
Sin embargo, el tercer log produce una huella digital completamente divergente (0-0-0...). Esto nos permite separarlo algorítmicamente del primer grupo antes de que invoquemos un LLM.
Parte adicional: Implementación instantánea con ES|QL
Es tan fácil como ingresar esta búsqueda en Discover.
Desglose de la búsqueda:
DE loghub: Se dirige a nuestro índice que contiene los datos de log sin procesar.
EVAL pattern = …: La lógica de mapping del núcleo. Encadenamos las funciones REPLACE para realizar la abstracción (por ejemplo, dígitos a '0', texto a 'a', etc.) y guardamos el resultado en un campo de “patrón”.
STATS[columna1 =] expresión1, … POR SUBSTRING(patrón, 0, 15):
Este es un paso de agrupación. Agrupamos logs que comparten los primeros 15 caracteres de su patrón y creamos campos agregados como recuento total de logs por grupo, lista de fuentes de datos de log, prefijo de patrón, 3 ejemplos de log
SORT total_count DESC | LIMIT 100: Destaca los 100 patrones log más frecuentes
A continuación, se muestran los resultados de la búsqueda en LogHub:


Como aparece en la visualización, este enfoque “sin LLM” particiona los logs con alta precisión. Agrupó con éxito 10 de las 16 fuentes de datos (basadas en etiquetas de LogHub) por completo (>90 %) y logró un agrupamiento mayoritario en 13 de 16 fuentes (>60 %), todo ello sin necesidad de realizar una limpieza, preprocesamiento o ajustes finos adicionales.
El formato de huella de log ofrece una alternativa pragmática y de alto impacto, además de soluciones sofisticadas de ML como el Análisis de patrones de log. Aporta información inmediata sobre las relaciones entre los log y gestiona de forma eficaz grandes grupos de logs.
- Versatilidad como primitiva
Gracias a la implementación de ES|QL, LFF sirve como una herramienta independiente para diagnósticos y visualizaciones de datos rápidos y como un componente básico en los pipelines de análisis de registros para casos de uso de gran volumen.
- Flexibilidad
LFF es fácil de personalizar y ampliar para capturar patrones específicos, es decir, números hexadecimales y direcciones IP.
- Estabilidad determinista
A diferencia de los algoritmos de agrupamiento basados en ML, la lógica LFF es sencilla y determinista. Los nuevos logs entrantes no afectan retroactivamente a los grupos de logs existentes.
- Rendimiento y mMemory
Requiere memoria mínima, sin entrenamiento ni GPU, lo que lo hace ideal para entornos de alto rendimiento en tiempo real.
Combinación de la huella digital del formato de log con un LLM
Para validar la arquitectura híbrida propuesta, cada experimento contenía un subconjunto aleatorio del 20 % de los logs de cada fuente de datos. Esta restricción simula un entorno de producción real donde los logs se procesan en lotes en lugar de como un vertido histórico monolítico.
El objetivo era demostrar que el LFF actúa como una capa de compresión eficaz. Nuestro objetivo fue demostrar que las reglas de análisis de alta cobertura podrían generarse a partir de muestras pequeñas y seleccionadas, y generalizarse con éxito a todo el set de datos.
Pipeline de ejecución
Implementamos un pipeline de varias etapas que filtra, agrupa y aplica un muestreo estratificado a los datos antes de que lleguen al LLM.
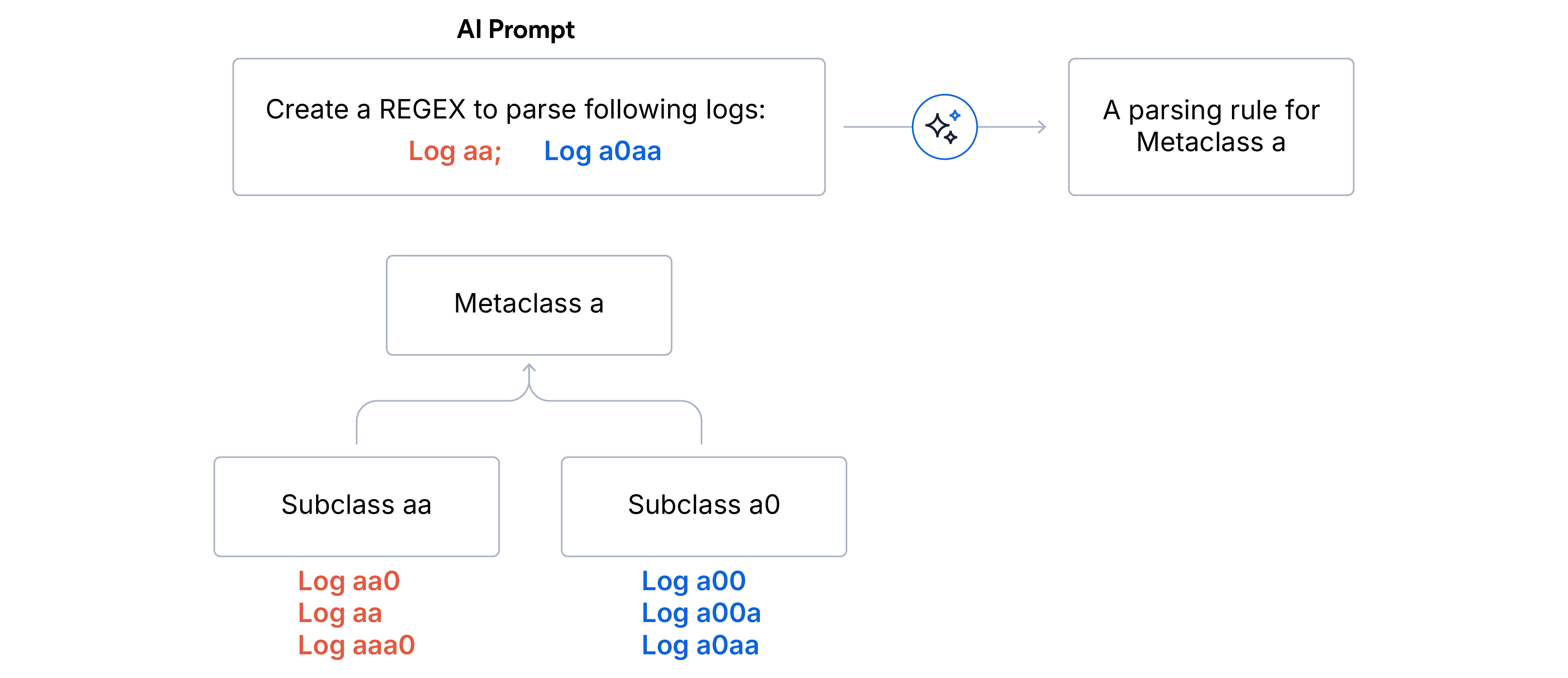
1. Agrupamiento jerárquico en dos etapas
- Subclases (coincidencia exacta): los logs se agregan por huellas idénticas. Cada log en una subclase comparte exactamente la misma estructura de formato.
- Limpieza de valores atípicos. Descartamos cualquier subclase que represente menos del 5 % del volumen total del log. Esto asegura que el LLM se centre en la señal dominante y no se desvíe por ruido o logs mal formados.
- Metaclases (coincidencia de prefijo): las subclases restantes se agrupan en metaclases por los primeros caracteres N del formato de coincidencia de huellas dactilares. Esta estrategia de agrupación divide efectivamente formatos léxicamente similares bajo un mismo paraguas. Elegimos N=5 para el análisis de log y N=15 para la partición de log cuando las fuentes de datos son desconocidas.
2. Muestreo estratificado. Una vez construido el árbol jerárquico, construimos la muestra de log para el LLM. El objetivo estratégico es maximizar la cobertura de las variaciones y minimizar el uso de tokens.
- Seleccionamos logs representativos de cada subclase válida dentro de la metaclase más amplia.
- Para gestionar un caso extremo de demasiadas subclases, aplicamos un muestreo aleatorio reducido para ajustarse al tamaño de la ventana objetivo.
3. Generación de reglas. Finalmente, le pedimos al LLM que genere una regla de análisis de regex que se ajuste a todos los logs de la muestra proporcionada para cada metaclase. Para nuestra prueba de concepto, utilizamos el modelo GPT-4o mini.
Resultados experimentales y observaciones
Logramos una precisión de análisis del 94 % y una precisión de partición del 91 % en los sets de datos de Loghub.

La matriz de confusión anterior ilustra los resultados de la partición de logs. El eje vertical representa las fuentes de datos reales, y el eje horizontal representa las fuentes de datos previstas. La intensidad del mapa de calor corresponde al volumen de logs, con mosaicos más ligeros que indican un recuento más alto. La alineación diagonal demuestra la alta fidelidad del modelo en la atribución de fuentes, con una dispersión mínima.
Nuestra información sobre los parámetros de rendimiento:
- Línea de base óptima: una ventana de contexto de 30–40 muestras de log por categoría demostró ser el "punto óptimo", que produce consistentemente un análisis robusto con patrones tanto de Regex como de Grok.
- Minimización de entrada: pusimos el tamaño de entrada a 10 logs por categoría para los patrones Regex y observamos solo una caída del 2 % en el rendimiento de análisis, lo que confirma que el muestreo basado en la diversidad es más crítico que el volumen bruto.
Contenido relacionado

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

13 de marzo de 2026
Resolución de entidades con Elasticsearch, parte 4: el desafío final
Resolver y evaluar los desafíos de resolución de entidades en sets de datos de "desafío final" altamente diversos, diseñados para prevenir atajos.

26 de febrero de 2026
Resolución de entidades con Elasticsearch y LLMs, parte 2: emparejamiento de entidades con evaluación de LLM y búsqueda semántica
Usar la búsqueda semántica y las evaluaciones transparentes de LLM para la resolución de entidades en Elasticsearch.

15 de diciembre de 2025
Primeros pasos con Elastic Agent Builder y Strands Agents SDK
Aprende a crear un agente con Elastic Agent Builder y, a continuación, descubre cómo utilizar el agente a través del protocolo A2A orquestado con el SDK de Strands Agents.