在现代可观测性技术栈中,将来自不同数据源的非结构化日志摄入 Elasticsearch 等平台仍是一项挑战。依赖人工编写的解析规则会让数据管道变得脆弱 — 即使上游代码只有少量更新,也可能导致解析失败、数据无法建立索引。这种脆弱性还会因可扩展性问题而进一步恶化,在动态的微服务环境中,新服务不断加入,手动维护规则很快就会变成运维噩梦。
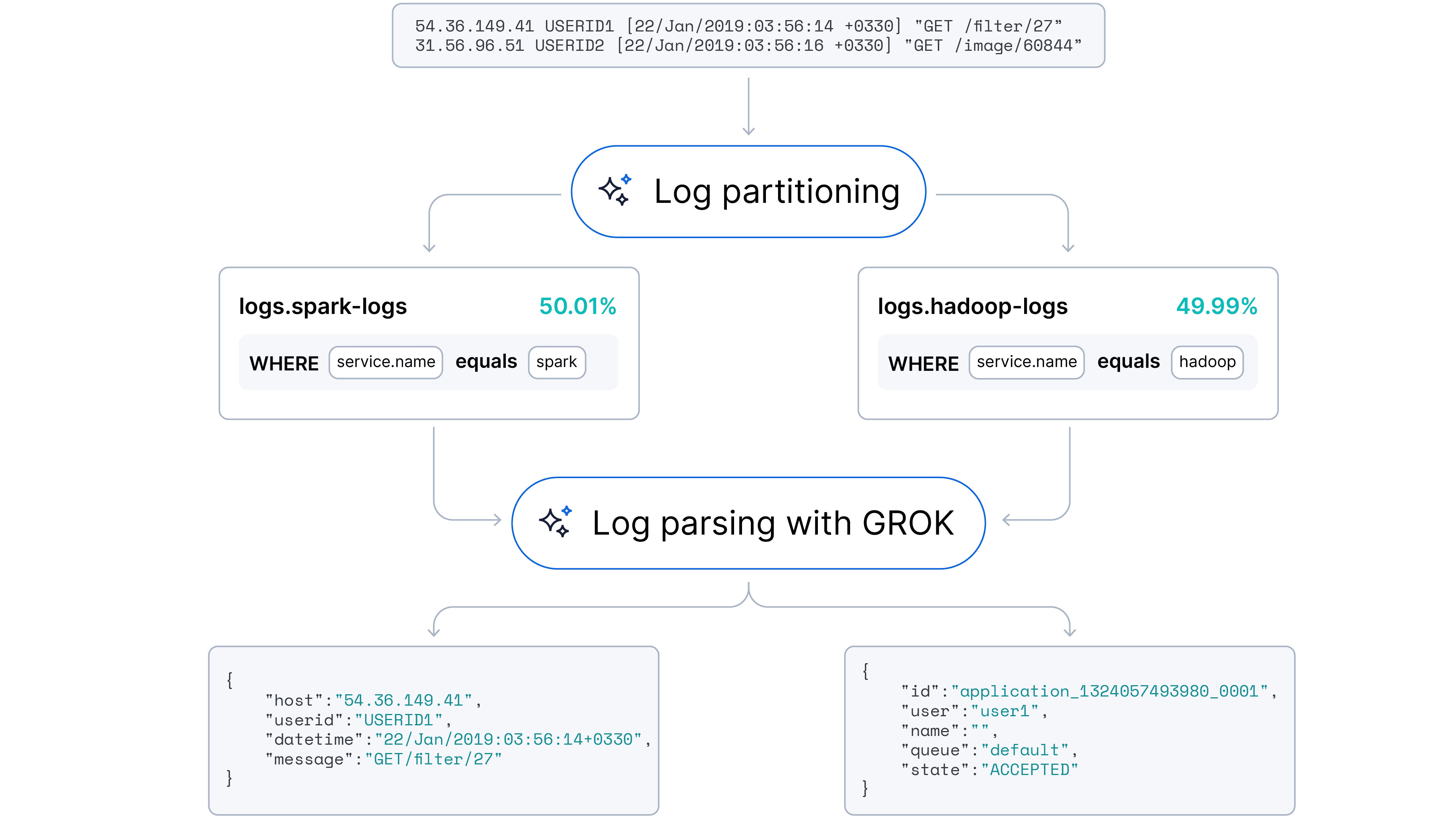
我们的目标是转向一种自动化、自适应的方法,能够同时处理日志解析(字段提取)和日志分区(来源识别)。我们假设,大语言模型(LLM)凭借对代码语法与语义模式的理解,能够在最少人工干预的情况下自动处理这些任务。
我们很高兴地宣布,此功能已在 Streams 中正式推出!
数据集描述
我们选择了Loghub 日志集合用于概念验证。我们的调查从以下关键领域选取了代表性样本:
- 分布式系统:我们使用了 Hadoop 分布式文件系统 (HDFS) 和 Spark 数据集。这些日志混合了大数据平台典型的信息、调试和错误消息。
- 服务器与 Web 应用:Apache Web 服务器和 OpenSSH 的日志提供了访问、错误以及与安全相关事件的重要信息来源,这对于监控 Web 流量和检测潜在威胁至关重要。
- 操作系统:我们纳入了 Linux 和 Windows 日志。这些数据集代表了运维团队日常处理的常见、半结构化系统级事件。
- 移动系统:为确保模型能处理移动环境日志,我们加入了 Android 数据集。这些日志通常较为冗长,涵盖了移动设备上广泛的应用程序和系统级活动。
- 超级计算机:为测试在高性能计算环境下的表现,我们引入了 BGL 数据集,其特点是包含使用特定领域术语的高度结构化日志。
Loghub 集合的一个关键优势在于,其日志基本未经清洗处理和标注,真实模拟了具有微服务架构的、嘈杂的线上生产环境。
日志示例:
此外,我们还搭建了一个包含典型 Web 应用与数据库的 Kubernetes 集群,用于在最常见的场景中采集更多日志。
常见日志字段示例:时间戳、日志级别(INFO、WARN、ERROR)、来源、消息内容。
使用 LLM 进行少样本日志解析
我们的首轮实验聚焦于一个根本问题:LLM 能否可靠地识别关键字段,并生成一致的解析规则来提取它们?
我们要求模型分析原始日志样本,并以正则表达式和 Grok 格式生成解析规则。结果显示,此方法潜力巨大,但也面临显著的实现挑战。
高置信度与上下文感知
初步结果令人鼓舞。LLM 展现出强大的能力,能高置信度地生成与提供的少数样本相匹配的解析规则。除了简单的模式匹配,模型还展现出对日志的理解能力 — 它能正确识别并命名产生日志的来源服务(例如健康追踪应用、Nginx Web 应用、Mongo 数据库)。
输入样本的“恰到好处”困境
我们的实验很快暴露出一个明显的鲁棒性问题,即对输入样本极其敏感。模型的性能会根据提示中包含的具体日志样本而剧烈波动。我们观察到一个日志相似性难题:样本里的日志需要达到适中的多样性水平,从而避免:
- 过于同质(过拟合):如果输入日志过于相似,LLM 倾向于过度具体化。它会把可变数据(例如堆栈跟踪里的具体 Java 类名)当成模板的固定部分。这导致生成的规则非常脆弱,只能覆盖极少部分日志,并提取出无用的字段。
- 过于异质(困惑):反之,如果样本包含显著的格式差异(或更糟,包含了“垃圾日志”),模型就难以找到共同模式。它往往会生成复杂但有缺陷的正则表达式,或直接将整行内容过度泛化为一个单一的消息块字段。
上下文窗口限制
我们还遇到了上下文窗口瓶颈。当输入日志较长、异构或包含大量可提取字段时,模型的输出质量常常会下降,变得“混乱”或过长而超出输出上下文窗口。在这种情况下,分块会有所帮助。通过使用基于字符和基于实体的分隔符来分割日志,我们可以帮助模型专注于提取主要字段,而不被噪声淹没。
一致性与标准化差距
即使模型成功生成规则,我们也注意到一些细微的不一致:
- 服务命名差异:模型在不同运行中会对同一实体使用不同名称(例如将来源标记为“Spark”“Apache Spark”“Spark Log Analytics”)。
- 字段命名差异:字段名称缺乏标准化(例如,
idvs.service.idvs.device.id)。我们使用标准化的 Elastic 字段命名规范对名称进行了统一。 - 解析粒度差异:字段提取的粒度因输入日志之间的相似程度而异。
日志格式指纹
为了解决日志相似性问题,我们引入了一种高性能的启发式方法:日志格式指纹(LFF)。
我们不再将原始、嘈杂的日志直接输入 LLM,而是首先应用一种确定性转换来揭示每条消息的底层结构。这个预处理步骤抽象掉变量数据,生成一个简化的“指纹”,使我们能够对相关日志进行分组。
映射逻辑很简单,以确保速度和一致性:
- 数字抽象:任何数字序列(0–9)都会替换为单个“0”。
- 文本抽象:任何由字母字符及其间空白组成的序列都会替换为单个“a”。
- 空白字符规范化:所有空白字符序列被压缩为单个空格。
- 符号保留:标点符号和特殊字符被保留,因为它们通常是日志结构最有力的指示符。
我们引入了日志映射方法。基本映射模式包括以下几种:
- 任意长度的数字(0–9)→ 替换为单个“0”。
- 任意长度的文本(字母字符及空白)→ 替换为单个“a”。
- 空格、制表符和换行符 → 合并为一个空格。
让我们看一个这种映射如何转换日志的例子。

因此我们得到如下日志“掩码”(指纹):

请注意前两个日志的指纹。尽管时间戳、来源类名和消息内容不同,但它们的前缀(0/0/0 0:0:0 a a.a:)完全一致。这种结构上的一致性使我们能够自动将这些日志归入同一个聚类。这种结构上的一致性使我们能自动把这些日志分桶到同一个聚类中。
第三个日志会生成完全不同的指纹(0-0-0...),这使我们能够在调用 LLM 之前就用算法将其与第一组区分开来。这使我们在调用LLM 之前 ,通过算法将其与第一组分离。
奖励部分:使用 ES|QL 进行即时实施
在 Discover 中运行这条查询就能做到这一点,非常简单。
查询解析:
FROM loghub:指向包含原始日志数据的索引。
EVAL pattern =…:核心映射逻辑。我们通过链式 REPLACE 函数执行抽象化处理(例如将数字替换为“0”、文本替换为“a”等),并将结果保存至“pattern”字段。
STATS [column1 =] expression1, … BY SUBSTRING(pattern, 0, 15):
这是一个集群步骤。我们将具有前 15 个字符相同的日志进行分组,并创建聚合字段,例如每组的日志总数、日志数据源列表、模式前缀以及 3 条日志示例。
SORT total_count DESC | LIMIT 100:显示出现频率最高的前 100 个日志模式
查询结果的可视化如下所示:


如可视化所示,这种“无需 LLM”的方法能够以很高的准确率对日志进行分区/归因分组。它(基于 LogHub 标签)在 16 个数据源中有 10 个实现了几乎完全的聚类(>90%),并在 16 个数据源中的 13 个实现了多数聚类(>60%),且无需额外清洗、预处理或微调。
日志格式指纹为日志模式分析等复杂的 ML 解决方案提供了一种务实、高效的替代与补充方案。它能立即洞察日志间的关系,并有效管理大型日志集群。
- 作为基础组件的多功能性
借助 ES|QL 实现,LFF 既可作为独立工具用于快速数据诊断/可视化,也可作为日志分析流水线中的基础构件,支撑高吞吐量场景。
- 灵活性
LFF 易于定制和扩展以捕获特定模式,例如十六进制数和 IP 地址。
- 确定性稳定性
与基于 ML 的聚类算法不同,LFF 逻辑简单且确定。新传入的日志不会追溯性地影响现有的日志聚类。
- 性能与内存
它需要最少的内存,无需训练或 GPU,非常适合实时高吞吐量环境。
结合日志格式指纹与 LLM
为了验证所提出的混合架构,每个实验都包含来自每个数据源的日志的随机 20% 子集。此约束模拟了现实世界的生产环境,在该环境中,日志是批量处理的,而不是作为一个整体的历史转储进行处理。
目标是证明 LFF 能作为有效的压缩层。我们希望证明,即使只用少量经过筛选的样本,也能生成高覆盖率的解析规则,并成功泛化到整个数据集。
执行管道
我们实现了一个多阶段流程,在数据到达 LLM 之前对其进行过滤、聚类和应用分层抽样。
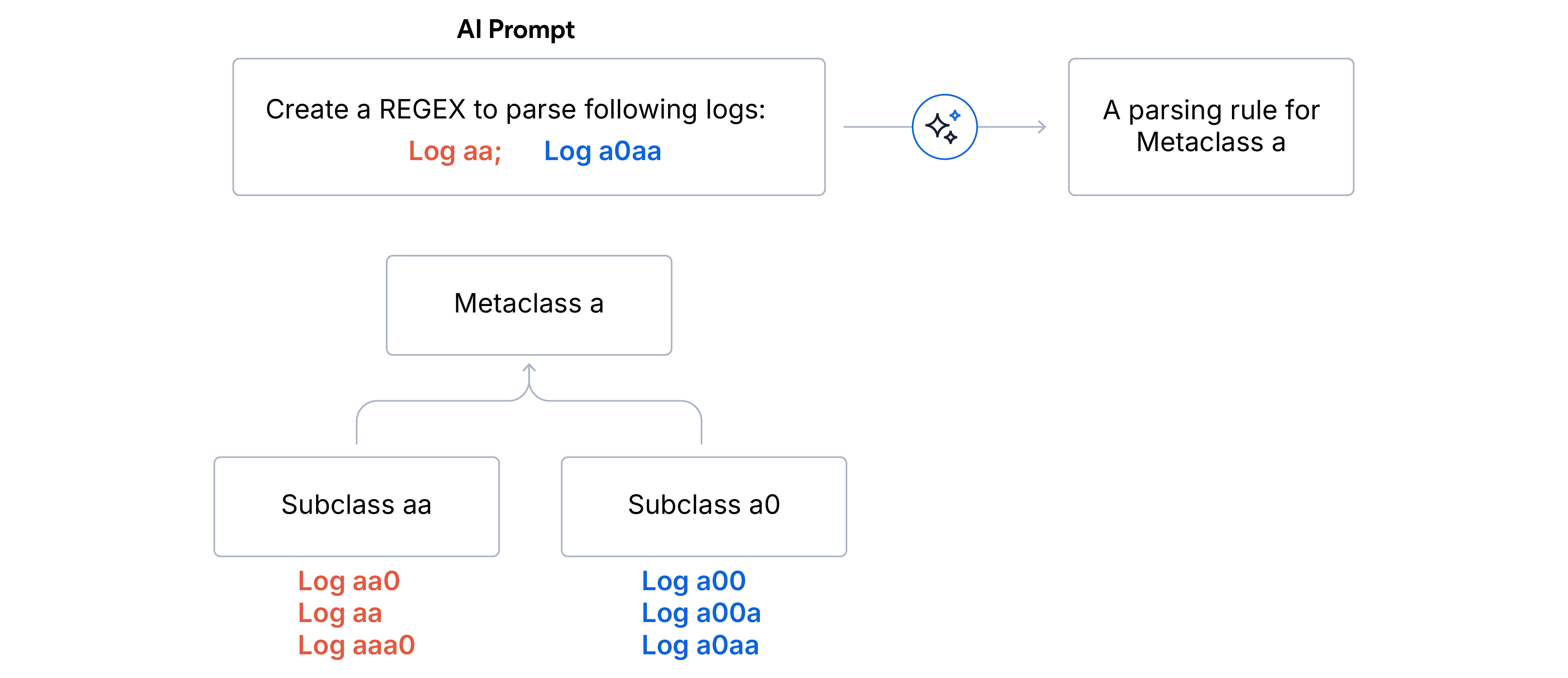
1. 两阶段分层聚类
- 子类(精确匹配):通过完全相同的指纹对日志进行聚合。同一子类的每个日志共享完全相同的格式结构。
- 异常值清理:丢弃占总日志量少于 5% 的任何子类,这确保 LLM 聚焦于主要信号,不会被噪声或格式异常的日志带偏。
- 元类(前缀匹配):剩余的子类通过格式指纹的前 N 个字符匹配分组到元类中。这种分组策略可有效将词汇相似的格式归并到同一个大类下。当数据源未知时,我们选择 N=5 用于日志解析,N=15 用于数据源未知时的日志分区。
2. 分层抽样。一旦分层树构建完成,我们为 LLM 构建日志样本。战略目标是最大化方差覆盖,同时最小化 Token 使用。
- 我们从更广泛的元类中,为每个有效子类选取具有代表性的日志。
- 为处理子类过多的边缘情况,应用随机下采样以适应目标窗口大小。
3. 规则生成:最后,我们提示 LLM 为每个元类生成一个适用于所提供样本中所有日志的正则表达式解析规则。在概念验证中,我们使用了 GPT-4o mini 模型。
实验结果与观察
我们在 Loghub 数据集上实现了 94% 的解析准确率和 91% 的分区准确率。

混淆矩阵展示了日志分区结果。垂直轴代表实际数据源,水平轴代表预测的数据源。热图颜色深浅对应日志量,颜色越浅表示数量越多。对角线排列显示了模型在来源归因上的高保真度,且分散极少。
我们的性能基准测试洞察:
- 最佳基线:每个类别 30–40 条日志样本的上下文窗口被证明是“最佳区间”,能稳定生成稳健的 Regex 与 Grok 解析模式。
- 输入最小化:我们将每个类别的输入大小推至 10 个日志(用于正则表达式模式),仅观察到解析性能下降 2%,这证实了基于多样性的抽样比原始数量更为关键。
相关内容

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。


使用 Elasticsearch 与 LLM 进行实体解析,第 2 部分:通过 LLM 判断和语义搜索匹配实体
在 Elasticsearch 中使用语义搜索和透明 LLM 判断进行实体解析。

借助 LangGraph 与 Elasticsearch 打造具人机协作功能的智能体
了解如何借助 LangGraph 与 Elasticsearch 打造具人机协作功能的智能体,让人类参与决策流程,从而填补情境信息缺口,并在工具调用执行前进行审核。