构建 AI 搜索应用并不轻松:多重任务、数据拉取与抽取都需要紧密配合,才能形成流畅连贯的工作流。LangGraph 通过节点式结构让开发者轻松编排 AI 代理,从而大幅简化了整个流程。在本文中,我们将运用 LangGraph.js 构建一个面向金融场景的 AI 搜索解决方案。
什么是 LangGraph
LangGraph 是一个用于构建 AI 代理,并将其编排进工作流,从而打造 AI 辅助应用的框架。LangGraph 采用节点式架构,我们可以声明代表不同任务的函数,并将这些函数指定为工作流中的节点。多个节点相互作用后形成的便是一个图结构。LangGraph 是更广泛的 LangChain 生态系统的一部分,该生态为构建模块化、可组合的 AI 系统提供了丰富的工具。
为了更直观地理解 LangGraph 有何用处,我们不妨用它来解决一个真实的业务难题。
解决方案概述
在一家风险投资公司中,投资人可以访问一个带有大量筛选条件的大型数据库,但一旦需要组合多重条件,查询就会变得既繁琐又缓慢。这可能会导致一些本应纳入投资视野的优质初创公司被漏掉。结果就是,团队要耗费大量时间去筛选最佳标的,甚至因此错失投资机会。
借助 LangGraph 和 Elasticsearch,我们能够使用自然语言进行过滤搜索,从而无需用户手动构建包含数十个筛选器的复杂请求。为了提高灵活性,工作流会根据用户输入在两种查询类型之间自动选择:
- 聚焦投资维度的查询:这类查询专注于初创公司的财务与融资维度,例如融资轮次、估值或营收等指标。示例:“查找已完成 A 轮或 B 轮融资、融资额在 800 万至 2,500 万美元之间且月收入超过 50 万美元的初创公司。”
- 聚焦市场维度的查询:这类查询侧重于行业垂直领域、目标市场或商业模式,帮助识别特定领域或地区中的投资机会。示例:“查找位于旧金山、纽约或波士顿的金融科技和医疗健康领域初创公司。”
为了让查询更稳健,我们会让 LLM 生成搜索模板,而不是直接构造完整的 DSL 查询。通过这种方式,你获得的始终是预期的查询结果,LLM 只需填入参数,而不必每次从头构建整条查询。
开始前的准备工作
- Elasticsearch API密钥
- OpenAPI API密钥
- Node 18 或更高版本
分步操作指南
在本节中,我们先来看一下这个应用的外观。为此,我们将使用 TypeScript,这是 JavaScript 的一个超集,添加了静态类型,使代码更可靠且更易维护,并能更早发现错误,同时又与现有 JavaScript 完全兼容。
节点的流程将如下所示:
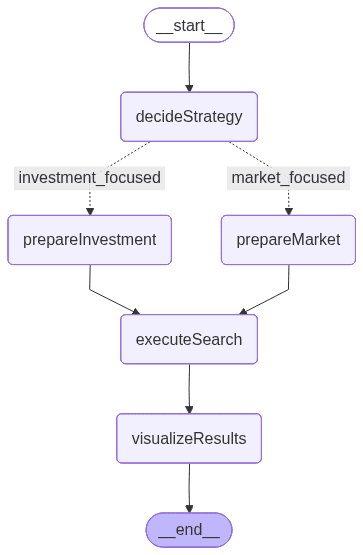
上图由 LangGraph 生成,直观地呈现了工作流结构,包括各节点的执行顺序和它们之间的条件分支关系:
- decideStrategy:使用 LLM 分析用户查询,在“聚焦投资维度”与“聚焦市场维度”这两种专门搜索策略之间做出选择。
- PrepareInvestmentSearch:从查询中提取筛选值并构建一个强调财务和资金相关参数的预定义模板。
- prepareMarketSearch:同样会提取筛选条件,但重点是围绕市场、行业和地域背景,动态生成相应的搜索参数。
- ExecuteSearch:通过搜索模板将构建好的查询发送到 Elasticsearch,检索并返回所有匹配的初创公司文档。
- visualizeResults:将最终结果整理成清晰易读的摘要,呈现融资、行业、营收等关键创业公司属性。
该流程包括一个条件分支,相当于一条“if”语句,可根据用户输入决定使用投资还是市场搜索路径。这种由 LLM 驱动的决策机制让工作流具备自适应和上下文感知能力,后续章节将对这一机制进行更详细的说明。
LangGraph 状态
在查看各个节点之前,我们需要先理解节点之间的通信和数据共享方式。为此,LangGraph 可支持定义工作流状态。这个状态就是在各个节点之间传递的共享状态。
该状态相当于一个共享容器,在整个工作流中保存中间数据:从最开始的用户自然语言查询,到选定的搜索策略、为 Elasticsearch 准备好的参数、检索到的搜索结果,一直到最后的格式化输出,都会依次写入其中。
这种结构让每个节点都能读取和更新状态,确保从用户输入到可视化实现顺畅一致的信息流动。
设置应用程序
本节所有代码均可在 elasticsearch-labs 仓库 中找到。
在应用所在的文件夹中打开终端,并通过以下命令初始化一个 Node.js 应用:
现在我们可以为这个项目安装必要的依赖项:
@elastic/elasticsearch:帮助我们处理 Elasticsearch 请求,例如数据摄取和检索。@langchain/langgraph:用于提供所有 LangGraph 工具的 JS 依赖项。@langchain/openai:适用于 LangChain 的 OpenAI LLM 客户端。- @langchain/core:为 LangChain 应用提供基础构建模块,包括提示模板。
dotenv:在 JavaScript 中使用环境变量所需的依赖项。zod: 对类型数据的依赖。
@types/node tsx typescript 允许我们编写和运行 TypeScript 代码。
现在创建以下文件:
elasticsearchSetup.ts:将创建索引映射,从 JSON 文件加载数据集,并将数据摄取到 Elasticsearch。main.ts:将包含 LangGraph 应用。.env:用于存储环境变量的文件
在 .env 文件中,我们添加以下环境变量:
OpenAPI APIKey 不会直接在代码中使用,而是由 @langchain/openai 库在内部调用。
所有关于映射创建、搜索模板创建和数据集摄取的逻辑都可以在 elasticsearchSetup.ts 文件中找到。在接下来的步骤中,我们将重点关注 main.ts 文件。此外,您可以查看该数据集,以便更好地理解 dataset.json 中数据结构。
LangGraph 应用程序
在 main.ts 文件中,我们导入一些必要的依赖项来构建整个 LangGraph 应用。在此文件中,您还必须定义各个节点函数以及工作流状态的声明。在后续步骤中,我们会在 main 方法中完成这个图结构的声明。elasticsearchSetup.ts 文件中包含一组 Elasticsearch 辅助函数,我们会在后续步骤的各个节点中使用这些函数。
如前所述,LLM 客户端将根据用户的问题生成 Elasticsearch 搜索模板参数。
上面的方法会生成一张 png 格式的图结构图像,并在后台调用 Mermaid.ink API。当你希望通过一张带有样式的可视化图来直观了解应用中各个节点之间的交互时,这个功能就会非常有用。
LangGraph 节点
现在让我们看看每个节点的详细信息:
decideSearchStrategy 节点
decideSearchStrategy 节点分析用户输入,并确定是执行投资聚焦搜索还是市场聚焦搜索。它使用具有结构化输出模式(用 Zod 定义)的 LLM 对查询类型进行分类。在做出决策之前,它会通过聚合从索引中检索可用的筛选条件,确保模型掌握最新的行业、地域和融资等上下文信息。
为了提取过滤器可能的值并将其发送到 LLM,让我们使用聚合查询直接从 Elasticsearch 索引中检索它们。这个逻辑被分配到一个名为 getAvailableFilters 的方法中:
通过上述聚合查询,我们得到以下结果:
点击此处查看所有结果。
对于这两种策略,我们将使用混合搜索来检测问题的结构化部分(过滤器)和主观部分(语义)。以下是使用搜索模板的两个查询示例:
查看 elasticsearchSetup.ts 文件中详细的查询。在接下来的节点中,将决定使用这两个查询中的哪一个:
prepareInvestmentSearch 和 prepareMarketSearch 节点
两个节点都使用共享的辅助函数 extractFilterValues,该函数利用 LLM 来识别用户输入中提到的相关过滤器,例如行业、地点、资金阶段、商业模式等。我们正在使用这个架构来构建我们的 搜索模板。
根据检测到的意图,工作流会选择以下两种路径之一:
PrepareInvestmentSearch:构建以财务为导向的搜索参数,包括融资阶段、融资金额、投资者以及营收相关信息。您可以在 elasticsearchSetup.ts 文件中找到整个查询模板:
prepareMarketSearch:创建以行业、地域和商业模式为重点的市场驱动参数。在 elasticsearchSetup.ts 文件中查看完整查询:
executeSearch 节点
该节点从状态中获取生成的搜索参数,首先将其发送到 Elasticsearch,使用_render API来可视化查询以便调试,然后发送请求以检索结果。
visualizeResults 节点
最后,此节点显示 Elasticsearch 结果。
从程序角度来看,整个图结构如下所示:
正如你所见,我们有一个条件边,应用在此决定接下来运行哪个“路径”或节点。当工作流需要分支逻辑时,例如在多个工具之间进行选择或包含人机交互步骤,此功能非常有用。
了解了 LangGraph 的核心功能后,我们可以设置代码运行的应用程序:
将所有内容在 main 方法中整合起来,在名为 workflow 的变量中声明这个包含所有元素的图结构:
查询变量用来模拟用户在一个虚拟搜索框中输入的内容:

系统会从这句自然语言“查找已完成 A 轮或 B 轮、融资额在 800 万至 2,500 万美元之间且月收入高于 50 万美元的初创公司”中,自动抽取出所有筛选条件。
最后,调用主方法:
实施结果
对于这条输入,应用会选择聚焦投资维度的路径,由此我们可以看到 LangGraph 工作流生成的 Elasticsearch 查询,它会从用户输入中抽取出各类数值与区间。此外,我们还能看到应用了这些提取参数后实际发送到 Elasticsearch 的查询,以及最后由 visualizeResults 节点格式化输出的结果。
现在,我们再用这条查询来测试聚焦市场维度的节点:“查找位于旧金山、纽约或波士顿的金融科技和医疗健康初创公司”:
学习经验
在写作过程中我学到了:
- 我们必须向 LLM 提供筛选器的精确取值,否则就要完全依赖用户输入这些值。对于低基数,这种方法很好,但当基数很高时,我们需要通过一些机制来过滤结果
- 使用搜索模板比让大语言模型编写 Elasticsearch 查询能使结果更加一致,而且速度也更快
- 条件边是一种强大的机制,用于构建具有多个变体和分支路径的应用程序。
- 结构化输出在使用大型语言模型生成信息时非常有用,因为它能强制执行可预测且类型安全的响应。这不仅提高了整体可靠性,还减少了对提示词的误解。
通过混合检索结合语义和结构化搜索,可以产生更好、更相关的结果,在精确性和上下文理解之间取得平衡。
结论
在这个例子中,我们将 LangGraph.js 与 Elasticsearch 结合,创建一个动态工作流,能够解释自然语言查询并决定使用金融或市场聚焦的搜索策略。这种方法减少了手工查询的复杂性,同时提升了风险投资分析师的灵活性和准确性。
相关内容

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。

2026年4月8日
如何使用 Mastra 和 Elasticsearch 构建代理式 AI 应用程序
通过一个实际示例,了解如何使用 Mastra 和 Elasticsearch 构建智能体 AI 应用。


使用 Elasticsearch 推理 API 以及 Hugging Face 模型
了解如何使用推理终端将 Elasticsearch 连接到 Hugging Face 模型,并利用语义搜索和聊天补全功能构建多语言博客推荐系统。

使用 TypeScript 构建 Elasticsearch MCP 服务器
学习如何使用 TypeScript 和 Claude Desktop 创建 Elasticsearch MCP 服务器。