Nas pilhas modernas de observabilidade, a ingestão de logs não estruturados de diversos provedores de dados em plataformas como o Elasticsearch continua sendo um desafio. A dependência de regras de análise sintática criadas manualmente gera fluxos de trabalho frágeis, onde até mesmo pequenas atualizações no código upstream levam a falhas de análise e dados não indexados. Esta fragilidade é agravada pelo desafio da escalabilidade: em ambientes dinâmicos de microsserviços, a adição contínua de novos serviços transforma a manutenção manual de regras em um pesadelo operacional.
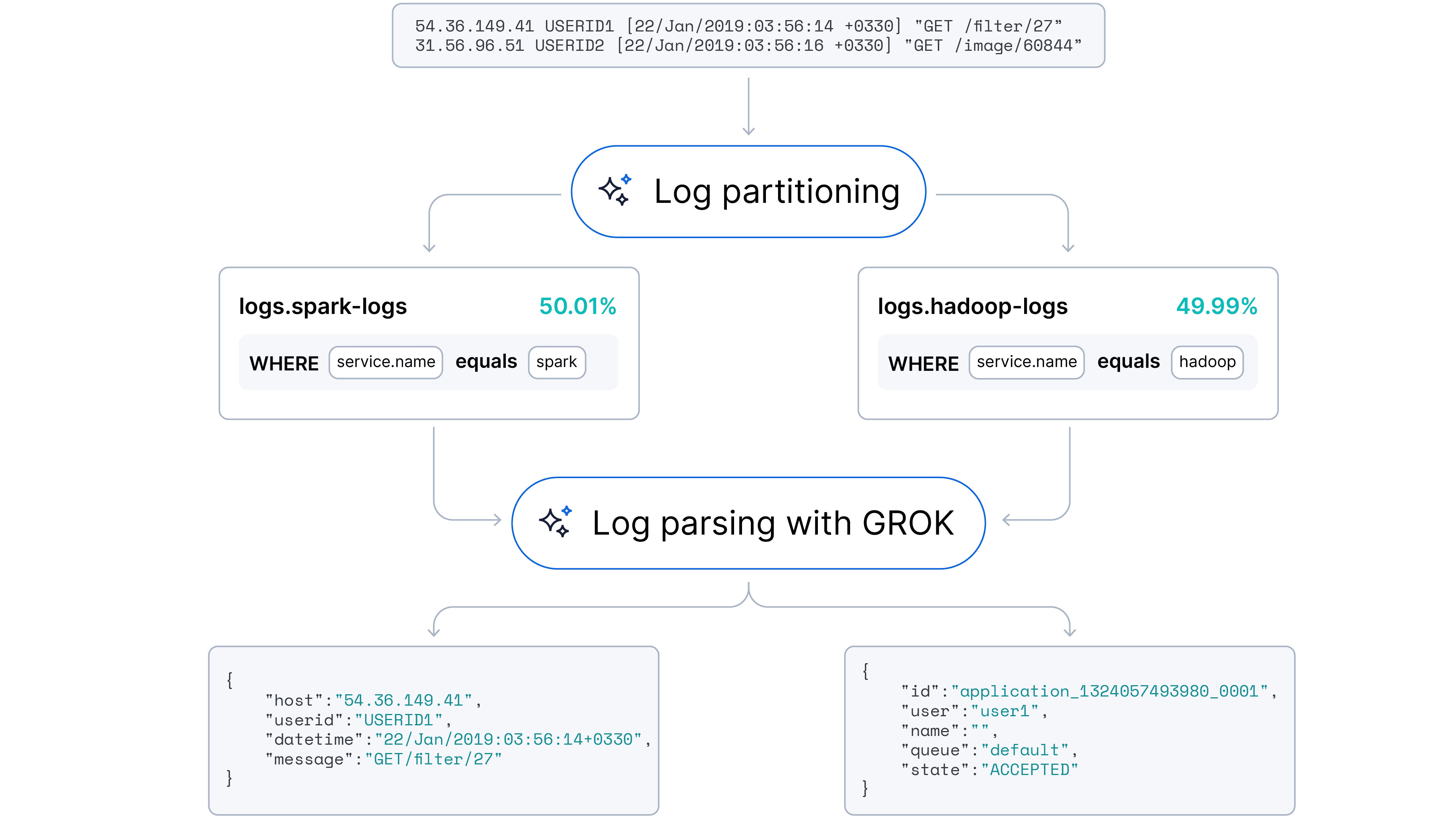
Nosso objetivo era fazer a transição para uma abordagem automatizada e adaptativa capaz de lidar com a análise de logs (extração de campos) e o particionamento de logs (identificação da fonte). Nossa hipótese é que os grandes modelos de linguagem (LLMs), com a compreensão inerente da sintaxe do código e dos padrões semânticos, poderiam automatizar essas tarefas com o mínimo de intervenção humana.
Temos o prazer de anunciar que esse recurso já está disponível no Streams!
Descrição do conjunto de dados
Escolhemos uma coleção de logs do Loghub para fins de PoC. Para nossa investigação, selecionamos amostras representativas das seguintes áreas-chave:
- Sistemas distribuídos: utilizamos os conjuntos de dados HDFS (Hadoop Distributed File System) e Spark. Esses contêm uma mistura de informações, mensagens de debug e erros típicos das plataformas de big data.
- Servidores e aplicações web: logs dos servidores web Apache e do OpenSSH forneceram uma fonte valiosa de acesso, erro e eventos relevantes para a segurança. Esses são fundamentais para monitorar o tráfego web e detectar ameaças potenciais.
- Sistemas operacionais: incluímos logs do Linux e do Windows. Esses conjuntos de dados representam os eventos comuns e semiestruturados em nível de sistema que as equipes de operações enfrentam diariamente.
- Sistemas móveis: para garantir que nosso modelo pudesse lidar com logs de ambientes móveis, incluímos o conjunto de dados Android. Esses logs costumam ser extensos e captam uma ampla gama de atividades em nível de aplicação e sistema em dispositivos móveis.
- Supercomputadores: para testar o desempenho em ambientes de computação de alto desempenho (HPC), incorporamos o conjunto de dados BGL (Blue Gene/L), que apresenta logs altamente estruturados com terminologia específica de domínio.
Uma das principais vantagens da coleção Loghub é que os logs são, em grande parte, não higienizados e não rotulados, espelhando um ambiente de produção real e ruidoso com arquitetura de microsserviços.
Exemplos de logs:
Além disso, criamos um cluster Kubernetes com uma configuração típica de aplicação web + banco de dados para minerar logs extras no domínio mais comum.
Exemplo de campos de log comuns: carimbo de tempo, nível de log (INFO, AVISO, ERRO), origem, mensagem.
Análise de logs com poucos exemplos usando um LLM
Nosso primeiro conjunto de experimentos concentrou-se em uma questão fundamental: Um LLM pode identificar áreas-chave de forma confiável e gerar regras consistentes de análise para extraí-las?
Solicitamos a um modelo que analisasse amostras de registros brutos e gerasse regras de análise sintática de log nos formatos de expressão regular (regex) e Grok. Nossos resultados mostraram que essa abordagem tem muito potencial, mas também apresenta desafios significativos de implementação.
Alto nível de confiança e consciência contextual
Os resultados iniciais foram promissores. O LLM demonstrou uma forte habilidade de gerar regras de análise sintática que correspondiam aos exemplos de poucos disparos fornecidos com alta confiança. Além da simples correspondência de padrões, o modelo demonstrou capacidade de compreensão de logs, pois ele conseguiu identificar e nomear corretamente a fonte do log (por exemplo, aplicativo de monitoramento de saúde, aplicativo web Nginx, banco de dados MongoDB).
O dilema "Cachinhos Dourados" das amostras de entrada
Nossos experimentos logo revelaram uma falta significativa de robustez devido à extrema sensibilidade à amostra de entrada. O desempenho do modelo varia muito com base nos exemplos específicos de logs incluídos no prompt. Observamos um problema de similaridade de log, onde a amostra de logs precisa incluir logs diversos:
- Homogeneidade excessiva (sobreajuste): se os logs de entrada forem muito semelhantes, o LLM tende a superespecificar. Ele trata dados de variáveis, como nomes específicos de classes Java em um rastreio de pilha, como partes estáticas do template. Isso resulta em regras frágeis que cobrem uma proporção minúscula de logs e extraem campos inutilizáveis.
- Muito heterogêneo (confusão): por outro lado, se a amostra contiver uma variação significativa de formatação, ou pior, "registros de lixo" como barras de progresso, tabelas de memória ou arte ASCII, o modelo terá dificuldades para encontrar um denominador comum. Geralmente, ele recorre à geração de expressões regulares complexas e quebradas ou à generalização lenta de toda a linha em um único campo blob de mensagem.
A restrição da janela de contexto
Também encontramos um gargalo na janela de contexto. Quando os registros de entrada eram longos, heterogêneos ou ricos em campos extraíveis, a saída do modelo geralmente se deteriorava, tornando-se "confusa" ou muito longa para caber na janela de contexto de saída. Naturalmente, a fragmentação ajuda nesse caso. Ao dividir os logs usando delimitadores baseados em caracteres e em entidades, podemos ajudar o modelo a se concentrar na extração dos campos principais sem ser sobrecarregado por ruídos.
A lacuna de consistência e padronização
Mesmo quando o modelo gerou regras com sucesso, notamos pequenas inconsistências:
- Variações de nomenclatura de serviço: o modelo propõe diferentes nomes para a mesma entidade (por exemplo, rotulando a fonte como "Spark", "Apache Spark" e "Spark Log Analytics" em diferentes execuções).
- Variações na nomenclatura dos campos: os nomes dos campos não tinham padronização (por exemplo,
idXservice.idXdevice.id). Normalizamos os nomes usando uma nomenclatura de campo padronizada do Elastic. - Variância de resolução: a resolução da extração de campo variava dependendo de o quão semelhantes eram os logs de entrada entre si.
Formato de log impressão digital
Para enfrentar o desafio da similaridade de log, apresentamos uma heurística de alto desempenho: impressão digital de formato de log (LFF).
Em vez de inserir logs brutos e ruidosos diretamente em um LLM, primeiro aplicamos uma transformação determinística para revelar a estrutura subjacente de cada mensagem. Essa etapa de pré-processamento abstrai os dados das variáveis, gerando uma "impressão digital" simplificada que nos permite agrupar logs relacionados.
A lógica de mapeamento é simples para garantir velocidade e consistência:
- Abstração de dígitos: qualquer sequência de dígitos (0-9) é substituída por um único "0".
- Abstração de texto: qualquer sequência de caracteres alfabéticos com espaço em branco é substituída por um único "a".
- Normalização de espaço em branco: todas as sequências de espaço em branco (espaços, tabulações, novas linhas) são reduzidos a um único espaço.
- Preservação de símbolos: pontuação e caracteres especiais (por exemplo, :, [, ], /) são preservados, pois normalmente são os indicadores mais fortes da estrutura log.
Apresentamos a abordagem de mapeamento de log. Os padrões básicos de mapeamento incluem os seguintes:
- Dígitos de 0 a 9 de qualquer comprimento -> até "0".
- Texto (caracteres alfabéticos com espaços) de qualquer comprimento -> para "a".
- Espaços em branco, abas e novas linhas -> para um único espaço.
Vamos ver um exemplo de como esse mapeamento nos permite transformar os logs.

Como resultado, obtemos as seguintes máscaras de log:

Observe as impressões digitais dos dois primeiros logs. Apesar dos diferentes carimbos de data e hora, classes de origem e conteúdo da mensagem, os prefixos (0/0/0 0:0:0 a a.a:) são idênticos. Esse alinhamento estrutural nos permite colocar automaticamente esses logs em buckets no mesmo cluster.
O terceiro log, no entanto, produz uma impressão digital completamente divergente (0-0-0...). Isso nos permite separá-lo algoritmicamente do primeiro grupo antes mesmo de invocarmos um LLM.
Parte bônus: Implementação instantânea com ES|QL
É tão simples quanto passar essa consulta no Discover.
Detalhamento da consulta:
DE loghub: direcionado para nosso índice contendo os dados de registro bruto.
Padrão EVAL = ...: a lógica de mapeamento do núcleo. Encadeamos funções REPLACE para realizar a abstração (por exemplo, dígitos para '0', texto para 'a', etc.) e salvamos o resultado em um campo "padrão".
STATS [column1 =] expression1, … POR SUBSTRING(pattern, 0, 15):
Esta é uma etapa de clustering. Agrupamos logs que compartilham os primeiros 15 caracteres de seu padrão e criamos campos agregados, como contagem total de log por grupo, lista de fontes de dados de log, prefixo do padrão, 3 exemplos de log
SORT total_count DESC | LIMITE 100: destaca os 100 padrões de log mais frequentes
Os resultados das consultas no LogHub estão exibidos abaixo:


Como demonstrado na visualização, essa abordagem "livre de LLM" particiona logs com alta precisão. Ela agrupou com sucesso 10 das 16 fontes de dados (com base nos rótulos do LogHub) (>90%) e alcançou clustering majoritário em 13 das 16 fontes (>60%), tudo isso sem necessidade de limpeza adicional, pré-processamento nem ajuste fino.
A impressão digital do formato de Log oferece uma alternativa pragmática e de alto impacto, além de ser um complemento para soluções sofisticadas de ML, como a análise de padrões de log. Ele fornece insights imediatos sobre relacionamentos de logs e gerencia efetivamente grandes clusters de logs.
- Versatilidade como primitiva
Graças à implementação do ES|QL, o LFF funciona tanto como uma ferramenta independente para diagnósticos/visualizações de dados rápidos, quanto como um componente essencial em pipelines de análise de logs para casos de uso de alto volume.
- Flexibilidade
O LFF é fácil de personalizar e estender para captar padrões específicos, ou seja, números hexadecimais e endereços IP.
- Estabilidade determinística
Ao contrário dos algoritmos de clustering baseados em ML, a lógica LFF é direta e determinística. Novos logs recebidos não afetam retroativamente os clusters de logs existentes.
- Desempenho e memória
Requer memória mínima, sem treinamento nem GPU, tornando-o ideal para ambientes de alta taxa em tempo real.
Combinando a impressão digital do formato de log com um LLM
Para validar a arquitetura híbrida proposta, cada experimento continha um subconjunto aleatório de 20% dos registros de cada fonte de dados. Essa restrição simula um ambiente de produção real onde os logs são processados em lotes, em vez de um despejo histórico monolítico.
O objetivo era demonstrar que o LFF atua como uma camada de compressão eficaz. Nosso objetivo era provar que regras de análise de alta cobertura poderiam ser geradas a partir de amostras pequenas e selecionadas e generalizadas com sucesso para todo o conjunto de dados.
Pipeline de execução
Implementamos um pipeline de múltiplas etapas que filtra, agrupa e aplica amostragem estratificada aos dados antes que cheguem ao LLM.
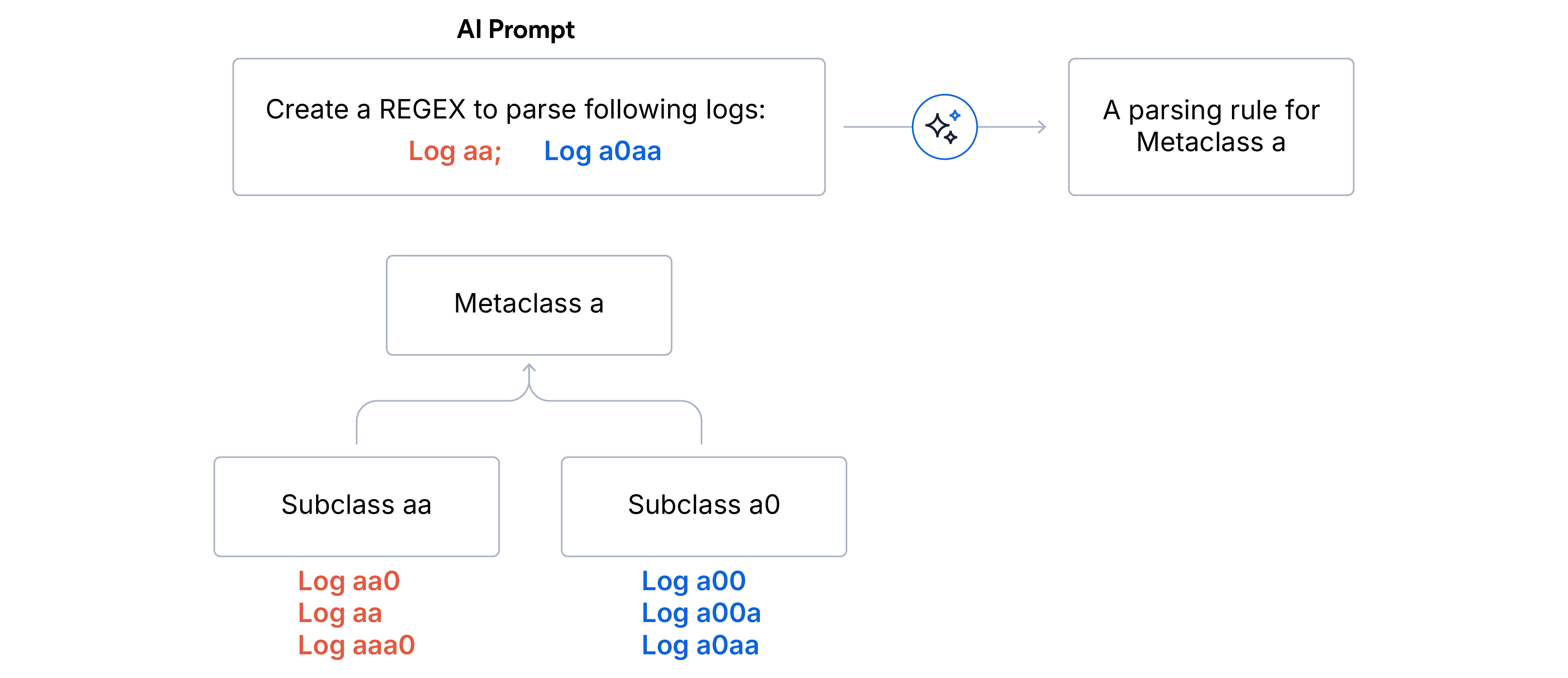
1. Clustering hierárquico em dois estágios
- Subclasses (correspondência exata): os logs são agregados por impressões digitais idênticas. Todo log em uma subclasse compartilha exatamente a mesma estrutura de formato.
- Limpeza de discrepâncias. Nós descartamos quaisquer subclasses que representam menos de 5% do volume total de log. Isso garante que o LLM se concentre no sinal dominante e não seja desviado por ruído ou logs malformados.
- Metaclasses (correspondência de prefixo): as subclasses restantes são agrupadas em metaclasses pelos primeiros N caracteres da correspondência da impressão digital do formato. Essa estratégia de agrupamento divide efetivamente formatos lexicalmente semelhantes sob uma mesma categoria. Escolhemos N=5 para análise de log e N=15 para particionamento de log quando as fontes de dados são desconhecidas.
2. Amostragem estratificada. Após a construção da árvore hierárquica, construímos a amostra de log para o LLM. O objetivo estratégico é maximizar a cobertura de variações enquanto minimiza o uso de tokens.
- Selecionamos logs representativos de cada subclasse válida dentro da metaclasse mais ampla.
- Para gerenciar um caso extremo de subclasses muito numerosas, aplicamos subamostragem aleatória para ajustar ao tamanho da janela alvo.
3. Geração de regras Final, solicitamos ao LLM que gere uma regra de análise regex que se encaixe em todos os logs da amostra fornecida para cada metaclasse. Para nossa PoC, usamos o modelo mini GPT-4o.
Resultados experimentais e observações
Alcançamos 94% de precisão de análise sintática e 91% de precisão de particionamento no conjunto de dados do Loghub.

A matriz de confusão acima ilustra os resultados da partição log. O eixo vertical representa as fontes de dados reais e o eixo horizontal representa as fontes de dados previstas. A intensidade do heatmap corresponde ao volume do log, com blocos mais claros indicando uma contagem maior. O alinhamento diagonal demonstra a alta fidelidade do modelo na atribuição da fonte, com espalhamento mínimo.
Nossos insights sobre benchmarks de desempenho:
- Linha de base ideal: uma janela de contexto de 30 a 40 amostras de log por categoria provou ser o ponto ideal, produzindo consistentemente uma análise robusta com padrões Regex e Grok.
- Minimização da entrada: aumentamos o tamanho da entrada para 10 registros por categoria para padrões Regex e observamos uma queda de apenas 2% no desempenho da análise, confirmando que a amostragem baseada na diversidade é mais importante do que o volume bruto.
Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

13 de março de 2026
Resolução de entidades com Elasticsearch, parte 4: O desafio definitivo
Resolvendo e avaliando desafios de resolução de entidades em um conjunto de dados de desafio definitivo altamente diversificado, projetado para evitar atalhos.

26 de fevereiro de 2026
Resolução de entidades com Elasticsearch & LLMs, Parte 2: Correspondência de entidades com julgamento LLM e busca semântica
Uso de busca semântica e julgamento transparente de LLM para a resolução de entidades no Elasticsearch.

5 de janeiro de 2026
Criação de agentes humanos com o LangGraph e o Elasticsearch
Saiba como criar agentes humanos com LangGraph e Elasticsearch que envolvem pessoas no processo de tomada de decisão para preencher lacunas contextuais e revisar chamadas de ferramentas antes da execução.