A criação de aplicativos de busca com IA geralmente envolve a coordenação de múltiplas tarefas, recuperação e extração de dados em um fluxo de trabalho integrado. O LangGraph simplifica esse processo ao permitir que os desenvolvedores orquestrem agentes de IA usando uma estrutura baseada em nós. Neste artigo, vamos construir uma solução financeira usando LangGraph.js
O que é LangGraph
LangGraph é um framework para construir agentes de IA e orquestrá-los em um fluxo de trabalho para criar aplicações assistidas por IA. O LangGraph possui uma arquitetura de nós onde podemos declarar funções que representam tarefas e atribuí-las como nós do fluxo de trabalho. O resultado de múltiplos nós interagindo será um gráfico. O LangGraph faz parte do ecossistema mais amplo LangChain, que oferece ferramentas para construir sistemas de IA modulares e componíveis.
Para entender melhor por que o LangGraph é útil, vamos resolver uma situação problemática usando-o.
Visão geral da solução
Em uma empresa de capital de risco, os investidores têm acesso a um grande banco de dados com muitas opções de filtragem, mas quando se deseja combinar critérios, o processo se torna difícil e lento. Isso pode fazer com que algumas startups relevantes não sejam encontradas para investimento. Isso resulta em gastar muitas horas tentando identificar os melhores candidatos, ou até mesmo em perder oportunidades.
Com o LangGraph e o Elasticsearch, podemos realizar buscar filtradas utilizando linguagem natural, eliminando a necessidade de os usuários construírem manualmente solicitações complexas com dezenas de filtros. Para torná-lo mais flexível, o fluxo de trabalho decide automaticamente com base na entrada do usuário entre dois tipos de consultas:
- Consultas focadas em investimento: essas consultas visam aspectos financeiros e de financiamento de startups, como rodadas de financiamento, avaliação ou receita. Exemplo: "Encontre startups com financiamento Série A ou Série B entre US$ 8 milhões e US$ 25 milhões e receita mensal acima de US$ 500 mil."
- Consultas focadas no mercado: essas consultas concentram-se em verticais da indústria, mercados geográficos ou modelos de negócios, ajudando a identificar oportunidades em setores ou regiões específicos. Exemplo: “Encontre startups de fintech e saúde em São Francisco, Nova York ou Boston.”
Para manter a robustez das consultas, faremos com que o LLM crie modelos de busca em vez de consultas DSL completas. Assim, você sempre recebe a consulta que quer, e o LLM só precisa preencher as lacunas e não carregar a responsabilidade de construir a consulta que você precisa toda vez.
O que você precisa para começar
- APIKey do Elasticsearch
- APIKey do OpenAPI
- Node 18 ou mais recente
Instruções passo a passo
Nesta seção, vamos ver como o app ficará. Para isso, usaremos o TypeScript, um superconjunto do JavaScript que adiciona tipos estáticos para tornar o código mais confiável, fácil de manter e mais seguro, detectando erros precocemente e, ao mesmo tempo, permanecendo totalmente compatível com o JavaScript existente.
O fluxo dos nós terá a seguinte aparência:
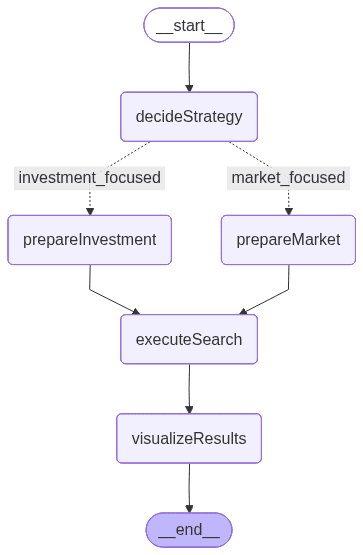
A imagem acima é gerada pelo LangGraph e representa o fluxo de trabalho que define a ordem de execução e a lógica condicional entre nós:
- decideStrategy: utiliza um LLM para analisar a consulta do usuário e decidir entre duas estratégias de busca especializadas: focada em investimento ou focada no mercado.
- prepareInvestSearch: extrai valores de filtro da consulta e constrói um modelo pré-definido enfatizando parâmetros financeiros e relacionados ao financiamento.
- prepareMarketSearch: também extrai valores de filtro, mas constrói parâmetros dinamicamente enfatizando o mercado, o setor e o contexto geográfico.
- executeSearch: envia a consulta construída para o Elasticsearch usando um modelo de busca e recupera os documentos correspondentes de inicialização.
- visualizeResults: formata os resultados finais em um resumo claro e legível que mostra atributos-chave da startup, como financiamento, setor e receita.
Esse fluxo inclui uma ramificação condicional, funcionando como uma instrução “if”, que determina se deve usar o caminho de busca de investimentos ou de mercado com base na entrada do usuário. Essa lógica de decisão, conduzida pelo LLM, torna o fluxo de trabalho adaptável e sensível ao contexto, um mecanismo que exploraremos com mais detalhes nas próximas seções.
Estado do LangGraph
Antes de ver cada nó individualmente, precisamos entender como os nós se comunicam e compartilham dados. Para isso, o LangGraph nos permite definir o estado do fluxo de trabalho. Isso define o estado compartilhado que será passado entre os nós.
O estado funciona como um container compartilhado que armazena dados intermediários ao longo do fluxo de trabalho: começa com a consulta em linguagem natural do usuário, depois mantém a estratégia de busca selecionada, os parâmetros preparados para o Elasticsearch, os resultados de busca recuperados e, finalmente, a saída formatada.
Essa estrutura permite que cada nó leia e atualize o estado, garantindo um fluxo consistente de informações desde a entrada do usuário até a visualização final.
Configure o aplicativo
Todo o código desta seção pode ser encontrado no repositório elasticsearch-labs.
Abra um terminal na pasta em que o app estará localizado e inicialize um app Node.js com o comando:
Agora podemos instalar as dependências necessárias para este projeto:
@elastic/elasticsearch: Nos ajuda a lidar com requisições do Elasticsearch, como ingestão e recuperação de dados.@langchain/langgraph: dependência de JS para fornecer todas as ferramentas LangGraph.@langchain/openaiCliente OpenAI LLM para LangChain.- @langchain/núcleo: fornece os blocos de construção fundamentais para apps LangChain, incluindo modelos de prompt.
dotenv: Dependência necessária para usar variáveis de ambiente em JavaScript.zod: Dependência para digitar dados.
@types/node tsx typescript nos permite escrever e executar o código TypeScript.
Agora, crie os seguintes arquivos:
elasticsearchSetup.ts: Criará os mapeamentos de índice, carregará o conjunto de dados de um arquivo JSON e fará a ingestão dos dados no Elasticsearch.main.ts: incluirá o aplicativo LangGraph..env: arquivo para armazenar as variáveis de ambiente
No arquivo .env, vamos adicionar as seguintes variáveis de ambiente:
O APIKey da OpenAPI não será usado diretamente no código; em vez disso, será usado internamente pela biblioteca @langchain/openai.
Toda a lógica relacionada à criação de mapeamentos, modelos de busca e ingestão de conjuntos de dados pode ser encontrada no arquivo elasticsearchSetup.ts. Nos próximos passos, vamos focar no arquivo main.ts . Além disso, você pode verificar o conjunto de dados para entender melhor como os dados aparecem no dataset.json.
Aplicativo LangGraph
No arquivo main.ts, vamos importar algumas dependências necessárias para consolidar a aplicação LangGraph. Neste arquivo, você também deve incluir as funções de nós e a declaração de estado. A declaração do gráfico será feita em um método main nos próximos passos. O arquivo elasticsearchSetup.ts conterá ajudantes Elasticsearch que vamos usar dentro dos nós em etapas futuras.
Como mencionado anteriormente, o cliente LLM será usado para gerar os parâmetros de busca do Elasticsearch com base na pergunta do usuário.
O método acima gera a imagem do gráfico em formato PNG e usa a API Mermaid.INK nos bastidores. Isso é útil se você quiser ver como os nós do app interagem entre si com uma visualização estilizada.
Nós do LangGraph
Agora vamos analisar cada nó em detalhes:
nó decideSearchStrategy
O node decideSearchStrategy analisa a entrada do usuário e determina se realiza uma buscar focada em investimento ou no mercado. Ele utiliza um LLM com um esquema de saída estruturado (definido com Zod) para classificar o tipo de consulta. Antes de tomar a decisão, o sistema recupera os filtros disponíveis do índice por meio de uma agregação, garantindo que o modelo tenha um contexto atualizado sobre setores, locais e dados de financiamento.
Para extrair os valores possíveis dos filtros e enviá-los ao LLM, vamos usar uma consulta de agregação para recuperá-los diretamente do índice do Elasticsearch. Essa lógica é alocada em um método chamado getAvailableFilters:
Com a consulta de agregação acima, temos os seguintes resultados:
Veja todos os resultados aqui.
Para ambas as estratégias, usaremos busca híbrida para detectar tanto a parte estruturada da pergunta (filtros) quanto as partes mais subjetivas (semântica). Aqui está um exemplo de ambas as consultas usando templates de busca:
Veja as consultas detalhadas no arquivo elasticsearchSetup.ts . No nó a seguir, será decidido qual das duas consultas será usada:
nós prepareInvestmentSearch e prepareMarketSearch
Ambos os nós usam uma função auxiliar compartilhada, extractFilterValues, que utiliza o LLM para identificar filtros relevantes mencionados na entrada do usuário, como setor, localização, estágio de financiamento, modelo de negócios, etc. Estamos usando este esquema para construir nosso modelo de busca.
Dependendo da intenção detectada, o fluxo de trabalho seleciona um de dois caminhos:
prepareInvestmentSearch: desenvolve parâmetros de busca orientados financeiramente, incluindo estágio de financiamento, valor do investimento, investidor e informações de renovação. Você pode encontrar o modelo completo de consulta no arquivo elasticsearchSetup.ts:
prepareMarketSearch: cria parâmetros orientados pelo mercado, focados em setores, geografias e modelos de negócios. Veja a consulta completa no arquivo elasticsearchSetup.ts :
nó executeSearch
Este nó pega os parâmetros de busca gerados do estado e os envia primeiro para o Elasticsearch, usando a API _render para visualizar a consulta para fins de depuração, e então envia uma solicitação para buscar os resultados.
nó visualizeResults
Por fim, este nó exibe os resultados do Elasticsearch.
Programaticamente, o gráfico completo tem a seguinte aparência:
Como você pode ver, temos uma aresta condicional onde o app decide qual "caminho" ou nó será executado em seguida. Esse recurso é útil quando fluxos de trabalho precisam de lógica de ramificação, como escolher entre várias ferramentas ou incluir uma etapa com uma pessoa no ciclo.
Com os recursos do núcleo do LangGraph entendidos, podemos configurar o aplicativo onde o código será executado:
Junte tudo em um método main; aqui declaramos o gráfico com todos os elementos sob a variável fluxo de trabalho:
A variável de consulta simula a entrada do usuário inserida em uma barra de busca hipotética:

A partir da frase em linguagem natural "Encontre startups com financiamento Série A ou Série B entre US$ 8M–US$ 25M e receita mensal acima de US$ 500K", todos os filtros serão extraídos.
Finalmente, invoque o método principal:
Resultados
Para a entrada enviada, a aplicação escolhe o caminho focado no investimento e, como resultado, podemos ver a consulta Elasticsearch gerada pelo fluxo de trabalho LangGraph, que extrai os valores e intervalos a partir da entrada do usuário. Também podemos ver a consulta enviada para o Elasticsearch com os valores extraídos aplicados e, finalmente, os resultados formatados pelo node visualizeResults com os resultados.
Agora vamos testar o nó focado no mercado usando a consulta "Encontre startups de fintech e saúde em São Francisco, Nova York ou Boston":
Aprendizados
Durante o processo de escrita, aprendi:
- Devemos mostrar ao LLM os valores exatos dos filtros; caso contrário, dependemos de o usuário digitar os valores exatos das coisas. Para baixa cardinalidade, essa abordagem é válida; mas, quando a cardinalidade é alta, precisamos de algum mecanismo para filtrar os resultados.
- Usar templates para busca torna os resultados muito mais consistentes do que deixar o LLM escrever a consulta Elasticsearch, e também é mais rápido
- Arestas condicionais são um mecanismo poderoso para construir aplicações com múltiplas variantes e caminhos ramificados.
- A saída estruturada é extremamente útil ao gerar informações com LLMs porque impõe respostas previsíveis e seguras para tipos. Isso melhora a confiabilidade e reduz as interpretações errôneas imediatas.
Combinar busca semântica e estruturada por meio da recuperação híbrida produz resultados melhores e mais relevantes, equilibrando precisão e compreensão do contexto.
Conclusão
Neste exemplo, combinamos LangGraph.js com o Elasticsearch para criar um fluxo de trabalho dinâmico capaz de interpretar consultas em linguagem natural e decidir entre estratégias de busca voltadas para finanças ou para o mercado. Essa abordagem reduz a complexidade de elaborar consultas manuais, ao mesmo tempo em que melhora a flexibilidade e a precisão para analistas de capital de risco.
Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.