Dans les piles d'observabilité modernes, l'ingestion de logs non structurés provenant de divers fournisseurs de données dans des plateformes comme Elasticsearch reste un défi. La dépendance à des règles de traitement manuellement créées engendre des pipelines fragiles, où même des mises à jour mineures du code en amont entraînent des échecs de traitement et des données non indexées. Cette fragilité est aggravée par le défi de la scalabilité : dans les environnements de microservices dynamiques, l’ajout continu de nouveaux services transforme la maintenance manuelle des règles en un cauchemar opérationnel.
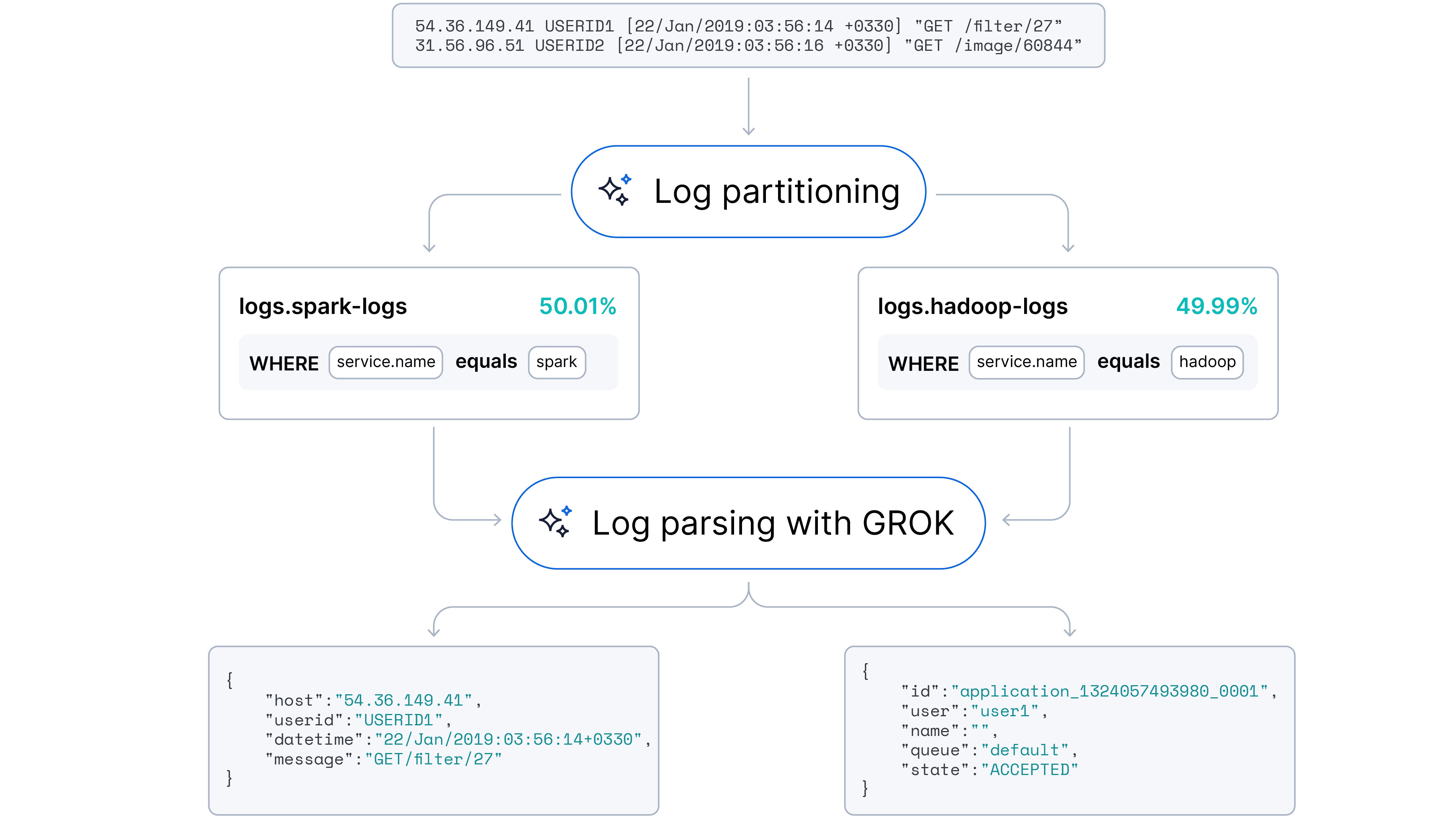
Notre objectif était de passer à une approche automatisée et adaptative capable de gérer à la fois l’analyse des logs (extraction de champs) et le partitionnement des logs (identification de la source). Nous avons émis l’hypothèse que les grands modèles de langage (LLM), grâce à leur compréhension inhérente de la syntaxe du code et des modèles sémantiques, pourraient automatiser ces tâches avec une intervention humaine minimale.
Nous sommes heureux d'annoncer que cette fonctionnalité est déjà disponible dans Streams.
Description de l'ensemble de données
Nous avons choisi une Loghub collection de logs à des fins de PoC. Pour notre enquête, nous avons sélectionné des échantillons représentatifs issus des domaines clés suivants :
- Systèmes distribués : nous avons utilisé le HDFS (Hadoop Distributed File System) et les ensembles de données Spark. Ils contiennent un mélange de messages d'information, de débogage et d'erreur typiques des plateformes de big data.
- Applications serveur et web : les logs des serveurs web Apache et d’OpenSSH ont constitué une source précieuse d’informations sur les accès, les erreurs et les événements liés à la security. Ces éléments sont essentiels pour surveiller le trafic web et détecter les menaces potentielles.
- Systèmes d'exploitation : nous avons inclus les logs de Linux et Windows. Ces ensembles de données représentent les événements communs et semi-structurés au niveau du système auxquels les équipes d’opérations sont confrontés quotidiennement.
- Systèmes mobiles : pour garantir que notre modèle puisse gérer les logs provenant d'environnements mobiles, nous avons inclus l'ensemble de données Android. Ces logs sont souvent volumineux et capturent un large éventail d'activités au niveau de l'application et du système sur les appareils mobiles.
- Superordinateurs : pour tester les performances sur des environnements de calcul haute performance (HPC), nous avons intégré l'ensemble de données BGL (Blue Gene/L), qui présente des logs très structurés avec une terminologie de domaine spécifique.
L'un des principaux avantages de la collection Loghub est que les logs sont en grande partie non nettoyés et non étiquetés, reflétant un environnement de production en direct bruyant avec une architecture de microservices.
Exemples de logs :
De plus, nous avons créé un cluster Kubernetes avec une application web typique et une base de données pour extraire des logs supplémentaires dans le domaine le plus courant.
Exemple de champs de log communs : horodatage, niveau de log (INFO, AVERTISSEMENT, ERREUR), source, message.
Analyse de logs en few-shot avec un LLM
Notre premier ensemble d'expériences s'est concentré sur une question fondamentale : Un LLM peut-il identifier de manière fiable les champs clés et générer des règles de parsing cohérentes pour les extraire ?
Nous avons demandé à un modèle d'analyser des échantillons de journaux bruts et de générer des règles d'analyse de journaux sous forme d'expressions régulières (regex) et de formats Grok. Nos résultats ont montré que cette approche présente beaucoup de potentiel, mais aussi des défis importants dans sa mise en œuvre.
Confiance élevée et conscience du contexte
Les premiers résultats étaient prometteurs. Le LLM a démontré une forte capacité à générer des règles d'analyse qui correspondaient aux exemples fournis avec une grande confiance. Outre la simple correspondance de modèles, le modèle a démontré une capacité de compréhension des logs — il pouvait identifier et nommer correctement la source du log (par exemple, application de suivi de santé, application web Nginx, base de données Mongo).
Le dilemme des échantillons d'entrée « Boucles d'or »
Nos expériences ont rapidement mis en évidence un manque important de robustesse en raison d'une sensibilité extrême à l'échantillon d'entrée. Les performances du modèle fluctuent considérablement en fonction des exemples de logs spécifiques inclus dans l'invite. Nous avons observé un problème de similitude des logs, dans lequel l'échantillon de log devait inclure juste assez de logs diversifiés :
- Trop homogène (surapprentissage) : si les logs d'entrée sont trop similaires, le LLM a tendance à surspécifier. Il traite les données variables — telles que des noms spécifiques de classes Java dans une trace de pile — comme des parties statiques du modèle. Il en résulte des règles fragiles qui ne couvrent qu'une infime partie des logs et extraient des champs inutilisables.
- Trop hétérogène (confusion) : à l'inverse, si l'échantillon contient une variance de formatage significative, ou pire, des « logs poubelles » comme des barres de progression, des tableaux de mémoire ou de l'art ASCII, le modèle peine à trouver un dénominateur commun. Il en vient souvent à générer des regex complexes et cassés ou à généraliser paresseusement toute la ligne en un seul champ de bloc de message.
La contrainte de la fenêtre contextuelle
Nous avons également rencontré un goulot d'étranglement au niveau de la fenêtre contextuelle. Lorsque les logs d'entrée étaient longs, hétérogènes, ou riches en champs extractibles, la sortie du modèle se détériorait souvent, devenant « désordonnée » ou trop longue pour s'intégrer dans la fenêtre de contexte de sortie. Bien entendu, le découpage aide dans ce cas. En divisant les logs à l'aide de délimiteurs basés sur les caractères et sur les entités, nous pourrions aider le modèle à se concentrer sur l'extraction des champs principaux sans être submergé par le bruit.
L'écart de cohérence et de standardisation
Même lorsque le modèle a généré des règles avec succès, nous avons noté de légères incohérences :
- Variantes de dénomination des services : le modèle propose différents noms pour une même entité (par exemple, en étiquetant la source « Spark », « Apache Spark » et « Spark Log Analytics » dans différentes exécutions).
- Variations dans la dénomination des champs : les noms des champs n'étaient pas normalisés (par exemple,
idvs.service.idvs.device.id). Nous avons normalisé les noms en utilisant une nomenclature de champ Elastic standardisée. - Variance de résolution : la résolution de l'extraction de champ variait en fonction de la similarité des logs d'entrée les uns avec les autres.
Empreinte de format de log
Pour relever le défi de la similarité des logs, nous introduisons une heuristique haute performance : l'empreinte de format de log (LFF).
Au lieu d'introduire des logs bruts et bruyants directement dans un LLM, nous appliquons d'abord une transformation déterministe pour révéler la structure sous-jacente de chaque message. Cette étape de pré-traitement rend abstraites les données variables, générant une « empreinte » simplifiée qui nous permet de regrouper les logs connexes.
La logique de mapping est simple pour garantir la vitesse et la cohérence :
- Abstraction des chiffres : toute séquence de chiffres (0-9) est remplacée par un simple ‘0’.
- Abstraction du texte : toute séquence de caractères alphabétiques avec des espaces blancs est remplacée par un seul « a ».
- Normalisation des espaces blancs : toutes les séquences d'espaces blancs (espaces, tabulations, nouvelles lignes) sont regroupées en un seul espace.
- La préservation des symboles : la ponctuation et les caractères spéciaux (par exemple, :, [, ], /) sont préservés, car ils sont souvent les indicateurs les plus forts de la structure des logs.
Nous introduisons l'approche de mapping des logs. Les modèles de mapping de base comprennent les éléments suivants :
- Chiffres 0 à 9, quelle que soit leur longueur, de > à « 0 ».
- Texte (caractères alphabétiques avec espaces) de n'importe quelle longueur -> à 'a'.
- Espaces blancs, onglets et nouvelles lignes : > pour un seul espace.
Examinons un exemple de la manière dont ce mapping nous permet de transformer les logs.

Par conséquent, nous obtenons les masques de log suivants :

Remarquez les empreintes digitales des deux premiers logs. Malgré des horodatages, des classes de sources et un contenu de message différents, leurs préfixes (0/0/0 0:0:0 a a.a:) sont identiques. Cet alignement structurel nous permet de regrouper automatiquement ces logs dans le même cluster.
Le troisième log, cependant, produit une empreinte digitale complètement divergente (0-0-0...). Cela nous permet de le séparer algorithmiquement du premier groupe avant même d' invoquer un LLM.
Partie bonus : implémentation instantanée avec ES|QL
C'est aussi simple que de passer cette requête dans Discover.
Décomposition de la requête :
FROM loghub : cible notre index contenant les données de journal brut.
EVAL pattern = ... : la logique du mapping de base. Nous enchaînons les fonctions REPLACE pour effectuer l'abstraction (par exemple, les chiffres en '0', le texte en 'a', etc.) et enregistrons le résultat dans un champ "pattern".
STATS [column1 =] expression1, … BY SUBSTRING(pattern, 0, 15) :
Ceci est une étape du clustering. Nous regroupons les logs qui partagent les 15 premiers caractères de leur schéma et créons des champs agrégés tels que le nombre total de logs par groupe, la liste des sources de données des logs, le préfixe du schéma, 3 exemples de logs
SORT total_count DESC | LIMIT 100 : affiche les 100 schémas de log les plus fréquents
Les résultats de la requête sur LogHub sont affichés ci-dessous :


Comme démontré dans la visualisation, cette approche « sans LLM » partitionne les logs avec une grande précision. Elle a réussi à clusterer complètement 10 sources de données sur 16 (basées sur les étiquettes LogHub) (>90 %) et a atteint un clustering majoritaire dans 13 sources sur 16 (>60 %) — le tout sans nécessiter de nettoyage, de prétraitement ou de réglage fin supplémentaire.
L'empreinte digitale du format du log offre une alternative pragmatique et à fort impact, ainsi qu'un complément aux solutions de ML sophistiquées telles que l'analyse du modèle de log. Il offre des informations immédiates sur les relations entre les logs et gère efficacement les grands ensembles de logs.
- Polyvalence en tant que primitif
Grâce à la mise en œuvre d'ES|QL, LFF sert à la fois d'outil autonome pour des diagnostics/visualisations rapides des données, et d'élément de base dans les pipelines d'analyse des journaux pour les cas d'utilisation à grand volume.
- Flexibilité
LFF est facile à personnaliser et à étendre pour capturer des modèles spécifiques, c'est-à-dire des nombres hexadécimaux et des adresses IP.
- Stabilité déterministe
Contrairement aux algorithmes de clustering basés sur le ML, la logique LFF est simple et déterministe. Les nouveaux logs entrants n'affectent pas rétroactivement les clusters de logs existants.
- Performance et mémoire
Il nécessite peu de mémoire, pas de formation ni de GPU, ce qui le rend idéal pour les environnements à haut débit et en temps réel.
Combiner une empreinte digitale au format log avec un LLM
Pour valider l'architecture hybride proposée, chaque expérience contenait un sous-ensemble aléatoire de 20 % des logs de chaque source de données. Cette contrainte simule un environnement de production réel où les logs sont traités par lots plutôt que comme un bloc monolithique de données historiques.
L’objectif était de démontrer que le LFF agit comme une couche de compression efficace. Nous avons cherché à prouver que des règles d’analyse à haute couverture pouvaient être générées à partir de petits échantillons sélectionnés et généralisées avec succès à l’ensemble de l’ensemble de données.
Pipeline d'exécution
Nous avons mis en œuvre un pipeline à plusieurs étapes qui filtre, regroupe et applique un échantillonnage stratifié aux données avant qu'elles n'atteignent le LLM.
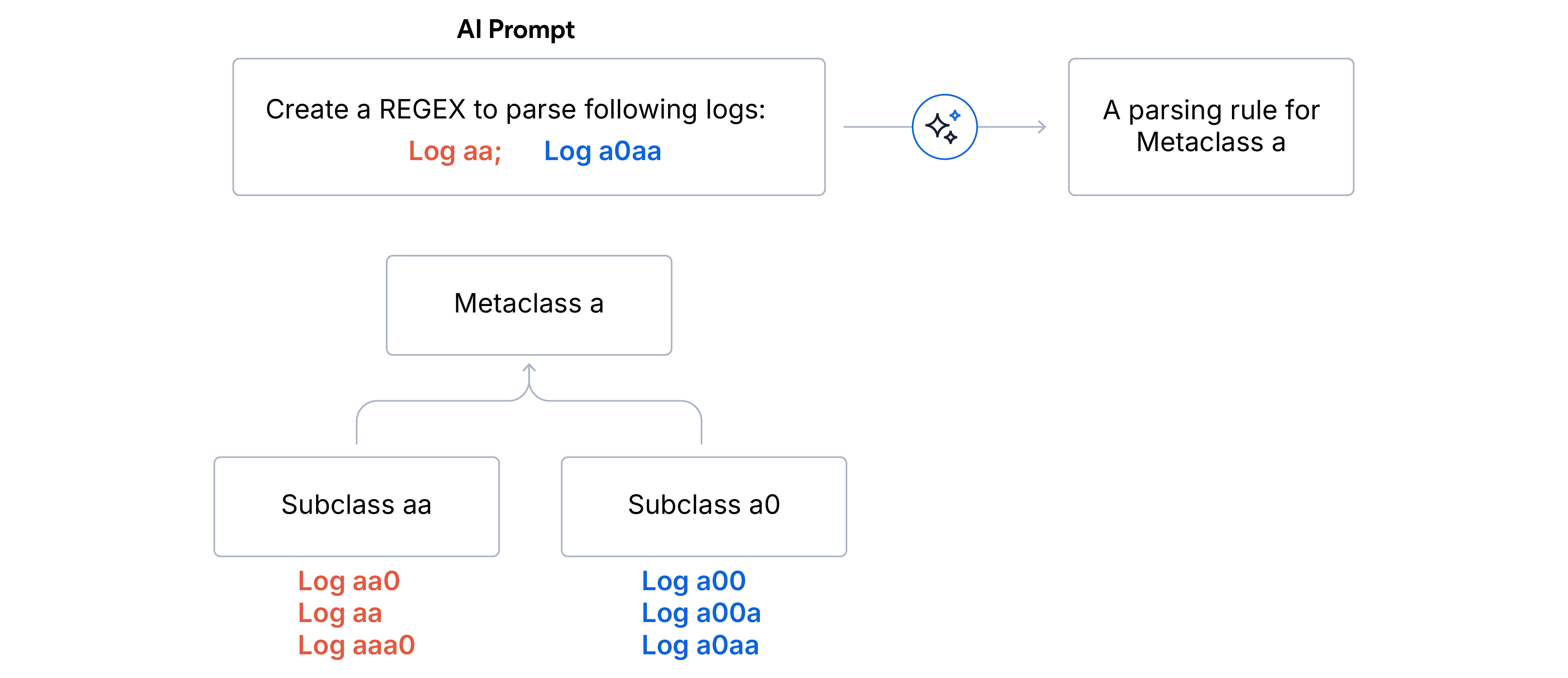
1. clustering hiérarchique en deux étapes
- Sous-classes (correspondance exacte) : les logs sont agrégés par empreintes identiques. Tous les logs d'une sous-classe partagent exactement la même structure de format.
- Nettoyage des aberrations. Nous écartons toutes les sous-classes qui représentent moins de 5 % du volume total des logs. Cela garantit que le LLM se concentre sur le signal dominant et ne sera pas distrait par le bruit ou les logs malformés.
- Métaclasses (correspondance avec le préfixe) : les sous-classes restantes sont regroupées en métaclasses en fonction des N premiers caractères de l'empreinte digitale du format. Nous avons choisi N=5 pour le Log parsing et N=15 pour le Log partitioning lorsque les sources de données sont inconnues.
2. Échantillonnage stratifié. Une fois l'arbre hiérarchique établit, nous construisons l'échantillon de log pour le LLM. L'objectif stratégique est de maximiser la couverture de variance tout en minimisant l'utilisation des jetons.
- Nous sélectionnons des logs représentatifs de chaque sous-classe valide au sein de la métaclasse plus large.
- Pour gérer un cas limite de sous-classes trop nombreuses, nous appliquons un échantillonnage aléatoire pour s'adapter à la taille de la fenêtre cible.
3. Génération de règles Finally, nous demandons au LLM de générer une règle d'analyse regex qui convient à tous les logs dans l'échantillon fourni pour chaque Métaclasse. Pour notre PoC, nous avons utilisé le mini-modèle GPT-4o.
Résultats expérimentaux et observations
Nous avons atteint une précision de parsing de 94 % et une précision de partitionnement de 91 % sur l'ensemble de données Loghub.

La matrice de confusion ci-dessus illustre les résultats du partitionnement des logs. L’axe vertical représente les sources de données réelles, et l’axe horizontal représente les sources de données prédites. L'intensité de la carte thermique correspond au volume de logs, les vignettes plus claires indiquant un nombre plus élevé. L'alignement diagonal démontre la haute fidélité du modèle dans l'attribution des sources, avec un minimum de dispersion.
Nos informations sur les benchmarks de performance :
- Base optimale : une fenêtre contextuelle de 30 à 40 échantillons de logs par catégorie s'est avérée être le « point idéal », produisant régulièrement une analyse syntaxique robuste avec des motifs Regex et Grok.
- Minimisation de l'entrée : nous avons réduit la taille de l'entrée à 10 logs par catégorie pour les motifs Regex et n'avons observé qu'une baisse de 2 % des performances d'analyse, ce qui confirme que l'échantillonnage basé sur la diversité est plus critique que le volume brut.
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

13 mars 2026
Résolution d'entités avec Elasticsearch, partie 4 : le défi ultime
Relever et évaluer les problématiques de réconciliation d’entités dans un ensemble de données complexe et varié, dont la structure interdit l’usage de méthodes simplifiées ou de contournements.

26 février 2026
Résolution d’entités avec Elasticsearch et les LLM, partie 2 : mise en correspondance d’entités avec le jugement des LLM et la recherche sémantique
Utiliser la recherche sémantique et le jugement transparent des LLM pour la résolution d’entités dans Elasticsearch.

5 janvier 2026
Créer des agents avec supervision humaine à l’aide de LangGraph et Elasticsearch
Découvrez comment concevoir des agents avec supervision humaine grâce à LangGraph et Elasticsearch, en intégrant l’humain dans la boucle pour combler les lacunes contextuelles et valider les appels d’outils avant leur exécution.