Dans cet article, nous allons explorer comment combiner LangGraph et Elasticsearch pour créer une application intégrant une supervision humaine (HITL). Cette approche permet aux systèmes d’IA d’impliquer directement les utilisateurs dans le processus décisionnel, rendant les interactions plus fiables et contextualisées. Nous allons illustrer cela à travers un exemple concret, en nous appuyant sur un scénario orienté contexte pour montrer comment les workflows LangGraph peuvent s’intégrer à Elasticsearch pour récupérer des données, traiter les saisies utilisateur et produire des résultats affinés.
Conditions
- NodeJS version 18 ou plus récente
- Clé API OpenAI
- Déploiement Elasticsearch 8.x+
Pourquoi utiliser LangGraph pour des systèmes HITL en production
Dans un article précédent, nous avons présenté LangGraph et ses avantages pour construire un système RAG à l’aide de LLM et d’arêtes conditionnelles permettant de prendre automatiquement des décisions et d’afficher les résultats. Parfois, on ne souhaite pas que le système fonctionne de manière totalement autonome : on préfère que les utilisateurs puissent faire des choix et prendre des décisions dans la boucle d’exécution. C’est ce qu’on appelle la « supervision humaine ».
Supervision humaine ou humain dans la boucle
Il s’agit d’un concept d’IA qui permet à une personne réelle d’interagir avec des systèmes d’IA pour enrichir le contexte, évaluer ou modifier les réponses, demander des précisions, etc. Ce mécanisme est particulièrement utile dans des contextes à faible tolérance à l’erreur, comme la conformité, la prise de décision ou la génération de contenu, car il renforce la fiabilité des résultats produits par les modèles de langage (LLM).
Un exemple courant est celui d’un assistant de développement qui demande votre autorisation avant d’exécuter une commande dans le terminal, ou vous présente son raisonnement pas à pas avant de commencer à coder.
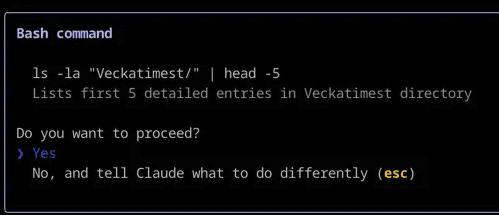
Claude Code utilise une supervision humaine pour vous demander de confirmer l’exécution d’une commande Bash
Elasticsearch + LangGraph : Comment ils interagissent
LangChain permet d’utiliser Elasticsearch comme magasin vectoriel et d’effectuer des requêtes dans des applications LangGraph – ce qui est particulièrement utile pour exécuter des recherches en texte intégral ou sémantiques –, tandis que LangGraph permet de définir le workflow, les outils et les interactions spécifiques. Cette architecture ajoute également la supervision humaine en tant que couche d’interaction supplémentaire avec l’utilisateur.
Mise en pratique : supervision humaine dans la boucle
Prenons l’exemple d’un avocat qui se pose une question sur une affaire qu’il vient d’accepter. Sans les bons outils, il devrait parcourir manuellement les textes juridiques et les précédents, les lire en intégralité, puis interpréter leur pertinence par rapport à son cas. Avec LangGraph et Elasticsearch, on peut créer un système capable d’interroger une base de données de précédents juridiques et de produire une analyse adaptée au cas en intégrant les détails et le contexte fournis par l’avocat.
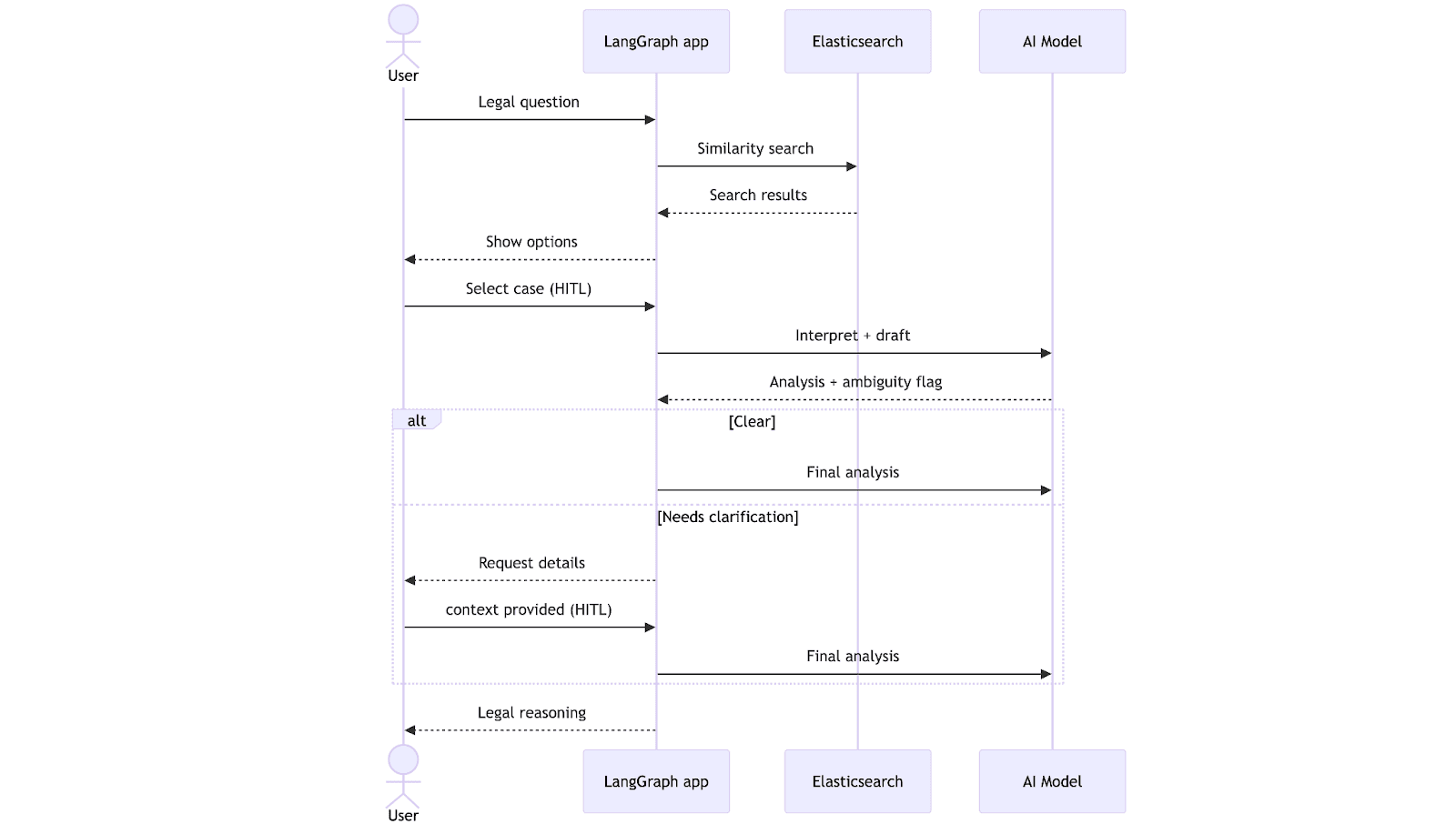
Le workflow démarre lorsque l’avocat soumet une question juridique. Le système effectue une recherche vectorielle dans Elasticsearch, identifie les précédents les plus pertinents et les présente à l’avocat sous forme de texte en langage naturel. Une fois les documents sélectionnés, le modèle de langage génère une première analyse et vérifie si les informations sont complètes. À ce stade, deux chemins sont possibles : si tout est clair, le système génère directement une analyse finale ; sinon, il interrompt le processus pour demander des précisions à l’avocat. Une fois les informations manquantes ajoutées, le système complète l’analyse en tenant compte des précisions apportées.
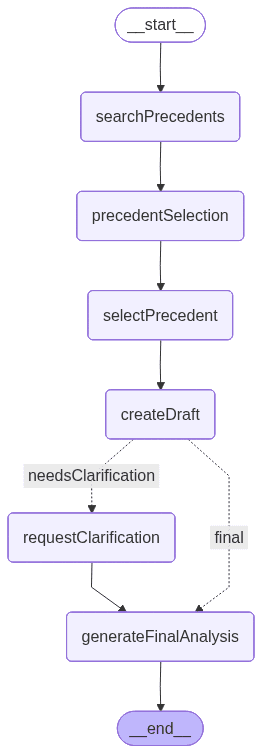
Voici un graphique généré par LangGraph qui illustre le fonctionnement de l’application une fois finalisée. Chaque nœud représente un outil ou une fonctionnalité :
Ensemble de données
Voici l’ensemble de données utilisé dans cet exemple. Cet ensemble de données regroupe plusieurs précédents juridiques, chacun décrivant un cas de retard de service, les motifs invoqués par la cour et la décision finale.
Ingestion et configuration de l'index
La configuration de l’index et la logique d’ingestion des données sont définies dans le fichier dataIngestion.ts, dans lequel on déclare les fonctions de création de l’index. Cette configuration est compatible avec l’interface de magasin vectoriel LangChain pour Elasticsearch.
Remarque : la configuration du mapping est également incluse dans le fichier dataIngestion.ts.
Installation des packages et configuration des variables d’environnement
Initialisons un projet Node.js avec les paramètres par défaut :
- @elastic/elasticsearch : client Elasticsearch pour Node.js Utilisé pour se connecter, créer des index et exécuter des requêtes.
- @langchain/community : propose des intégrations avec des outils soutenus par la communauté, y compris le magasin ElasticVectorSearch.
- @langchain/core : composants de base de LangChain, tels que les chaînes, prompts et utilitaires.
- @langchain/langgraph : permet l’orchestration basée sur des graphes, avec des workflows reposant sur des nœuds, des arêtes et une gestion d’état.
- @langchain/openai : fournit un accès aux modèles OpenAI (LLM et embeddings) via LangChain.
- dotenv : charge les variables d’environnement à partir d’un fichier .env dans process.env. fichier dans process.env.
- tsx : outil pratique pour exécuter du code TypeScript.
Exécutez la commande suivante dans la console pour les installer tous :
Créez un fichier .env pour configurer les variables d’environnement :
Nous utiliserons TypeScript pour écrire le code, car il offre une meilleure sécurité de typage et une expérience développeur plus fiable. Créez un fichier TypeScript nommé main.ts et insérez-y le code présenté dans la section suivante.
Importation des packages
Dans le fichier main.ts, nous commençons par importer les modules nécessaires et initialiser la configuration des variables d’environnement. Cela inclut les composants essentiels de LangGraph, les intégrations de modèles OpenAI et le client Elasticsearch.
Nous importons également les éléments suivants depuis le fichier dataIngestion.ts :
- ingestData : fonction qui crée l’index et ingère les données.
- Document et DocumentMetadata : interfaces définissant la structure des documents de l’ensemble de données.
Client du magasin vectoriel Elasticsearch, client d’embeddings et client OpenAI
Ce code initialise le magasin vectoriel, le client d’embeddings et un client OpenAI.
Le schéma d’état du workflow applicatif facilite la communication entre les nœuds :
L’objet d’état fera transiter, via les nœuds, la requête de l’utilisateur, les concepts extraits, les précédents juridiques identifiés et les éventuelles zones d’ambiguïté. Il conserve également une trace du précédent choisi par l’utilisateur, de l’analyse préliminaire générée en cours de route et de l’analyse finale, une fois toutes les clarifications apportées.
Nœuds
searchPrecedents : ce nœud effectue une recherche de similarité dans le magasin vectoriel d’Elasticsearch, en se basant sur les données saisies par l’utilisateur. Il récupère jusqu’à 5 documents pertinents et les affiche afin qu’ils puissent être examinés par l’utilisateur.
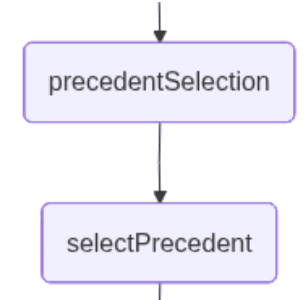
precedentSelection : ce nœud permet à l’utilisateur de sélectionner, en langage naturel, le cas d’usage correspondant le mieux à sa requête parmi ceux trouvés par la recherche par similarité. À ce stade, l’application interrompt le workflow et attend une entrée utilisateur.
selectPrécédent : ce nœud transmet la saisie de l’utilisateur ainsi que les documents récupérés, afin d’en interpréter le contenu et d’en sélectionner un. Le LLM accomplit cette tâche en renvoyant un numéro correspondant au document qu’il estime le plus pertinent à partir de la saisie en langage naturel.
createDraft : ce nœud génère une première analyse juridique à partir du précédent choisi par l’utilisateur Le modèle LLM évalue dans quelle mesure le précédent s’applique à la question posée par l’avocat et détermine si les informations disponibles sont suffisantes pour continuer.
Si le précédent est directement applicable, le nœud produit une analyse préliminaire et, en suivant la branche de droite, passe au nœud final. Si le LLM détecte des ambiguïtés – termes contractuels non définis, détails temporels manquants ou conditions floues –, il signale qu’une clarification est nécessaire et fournit la liste des informations à compléter. Dans ce cas, l’ambiguïté déclenche la branche gauche du graphe.
Voici les deux chemins que le graphe peut suivre :
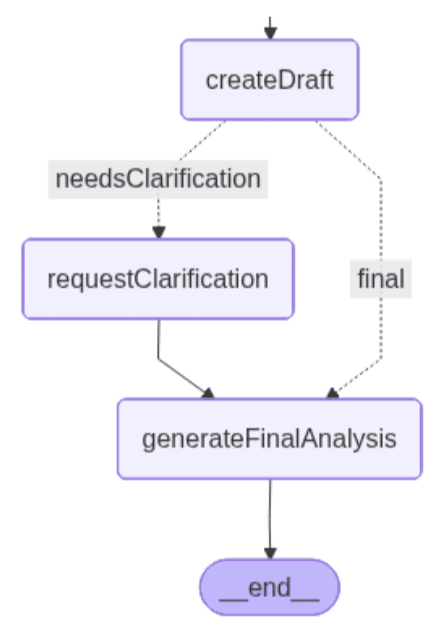
La branche gauche comprend un nœud supplémentaire chargé de gérer la clarification.
requestClarification : ce nœud active la seconde étape de supervision humaine lorsque le système estime que l’analyse préliminaire manque de contexte essentiel. Le workflow est interrompu et l’utilisateur est invité à préciser les éléments contractuels manquants détectés par le nœud précédent.
generateFinalAnalysis : ce nœud génère l’analyse juridique finale en combinant le précédent sélectionné avec les informations supplémentaires fournies par l’utilisateur, si nécessaire. Grâce aux clarifications obtenues lors de l’étape précédente de supervision humaine, le LLM synthétise le raisonnement juridique, les éléments contractuels fournis par l’utilisateur et les conditions permettant d’établir s’il y a eu violation.
Le nœud final fournit une analyse complète, intégrant l’interprétation juridique et des recommandations concrètes.
Construction du graphe :
Dans le graphe, on observe que l’arête conditionnelle définit le critère permettant de choisir la branche « finale ». Comme on le voit, la décision repose désormais sur la détection ou non d’ambiguïtés dans l’analyse préliminaire, nécessitant des clarifications supplémentaires.
Mise en œuvre de l’ensemble :
Exécutez le script :
Tout étant prêt, exécutez le fichier main.ts en saisissant la commande suivante dans le terminal :
Une fois le script lancé, la question « Une série de retards répétés constitue-t-elle une violation, même si chaque retard est mineur ? » est envoyée à Elasticsearch pour une recherche par similarité. Les résultats extraits de l’index s’affichent ensuite. L’application détecte que plusieurs précédents juridiques pertinents correspondent à la requête. Elle suspend donc l’exécution et sollicite l’utilisateur pour identifier le précédent le plus approprié :
Ce qui rend cette application intéressante, c’est qu’il est possible d’utiliser le langage naturel pour faire un choix, le LLM interprétant l’entrée utilisateur pour identifier la bonne option. Voyons ce qui se passe si l’on saisit « Case H »
Le modèle intègre les précisions fournies par l’utilisateur dans le workflow, puis poursuit avec l’analyse finale dès que le contexte est jugé suffisant. À ce stade, le système exploite également l’ambiguïté identifiée plus tôt : l’analyse préliminaire avait révélé des éléments contractuels manquants, susceptibles d’influencer l’interprétation juridique. Ces éléments « manquants » guident le modèle pour identifier les clarifications indispensables à lever les incertitudes et formuler une analyse finale fiable.
L’utilisateur doit fournir les précisions demandées dans la saisie suivante. Essayons avec : « Le contrat exige une “livraison rapide” sans calendrier. Huit retards de 2 à 4 jours sur six mois. 50 000 $ de pertes dues à trois délais clients non respectés. Le fournisseur a été prévenu, mais le schéma s’est répété. »
Ce résultat correspond à la dernière étape du workflow : le modèle y intègre le précédent sélectionné (Case H) ainsi que les précisions de l’avocat pour produire une analyse juridique complète. Le système explique pourquoi le schéma de retards observé constitue vraisemblablement une violation, identifie les facteurs à l’appui de cette interprétation et propose des recommandations concrètes. Au final, le résultat montre comment les clarifications liées à la supervision humaine permettent de lever les ambiguïtés et de générer une analyse juridique contextualisée et solide.
Autres cas d’usage concrets
Ce type d’application, reposant sur Elasticsearch, LangGraph et la supervision humaine, peut également être utile dans d’autres types d’applications, comme :
- Examen préalable des appels d’outils avant leur exécution : par exemple, en finance, une personne valide les ordres d’achat/vente avant leur passage.
- Ajout de paramètres complémentaires si nécessaire : par exemple, dans le tri des tickets en support client, où un agent humain choisit la bonne catégorie de problème lorsque l’IA propose plusieurs interprétations possibles.
Et de nombreux cas d’usage restent à explorer, dans lesquels la supervision humaine pourrait véritablement changer la donne.
Conclusion
Avec LangGraph et Elasticsearch, il est possible de créer des agents capables de prendre des décisions de manière autonome et de suivre un workflow linéaire, ou d’adapter leur cheminement selon certaines conditions. Avec la supervision humaine, les agents peuvent faire intervenir l’utilisateur dans le processus de décision pour combler les lacunes contextuelles et valider les choix dans des systèmes où la tolérance aux erreurs est critique.
L’un des atouts de cette approche, c’est qu’elle permet de filtrer un vaste ensemble de données via Elasticsearch, puis d’utiliser un LLM pour extraire un seul document correspondant à la sélection de l’utilisateur. Cette dernière étape serait bien plus complexe avec Elasticsearch seul, car un humain peut exprimer une même intention de recherche de multiples façons en langage naturel.
Cette approche rend le système plus rapide et économe en jetons, car seul le strict nécessaire est transmis au LLM pour prendre la décision finale, et non l’ensemble du jeu de données. Dans le même temps, cette approche reste très efficace pour détecter l’intention de l’utilisateur et affiner les itérations jusqu’à obtenir l’option souhaitée.
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.