La création d'applications de recherche IA implique souvent la coordination de plusieurs tâches, la récupération et l'extraction de données dans un workflow fluide. LangGraph simplifie ce processus en permettant aux développeurs d'orchestrer les agents d'IA à l'aide d'une structure basée sur des nodes. Dans cet article, nous allons construire une solution financière en utilisant LangGraph.js.
Qu'est-ce que LangGraph ?
LangGraph est un framework pour construire des agents d’IA et les orchestrer dans un workflow afin de créer des applications assistées par l’IA. LangGraph dispose d’une architecture de nodes où nous pouvons déclarer des fonctions représentant des tâches et les assigner comme nodes du workflow. Le résultat de l'interaction de plusieurs nodes sera un graphe. LangGraph fait partie du LangChain écosystème plus large, qui fournit des outils pour construire des systèmes d'IA modulaires et composables.
Pour mieux comprendre l’utilité de LangGraph, résolvons une situation problématique en l’utilisant.
Aperçu de la solution
Dans une société de capital-risque, les investisseurs ont accès à une vaste base de données avec de nombreuses options de filtrage, mais lorsqu'ils veulent combiner des critères, cela devient difficile et lent. Il se peut donc que certaines start-ups pertinentes ne soient pas trouvées pour l'investissement. Cela conduit à passer beaucoup de temps à essayer d'identifier les meilleurs candidats, voire à perdre des opportunités.
Avec LangGraph et Elasticsearch, vous pouvez effectuer des recherches filtrées en utilisant le langage naturel, ce qui évite aux utilisateurs de devoir construire manuellement des requêtes complexes avec des dizaines de filtres. Pour plus de flexibilité, le workflow choisit automatiquement, en fonction de l'entrée de l'utilisateur, entre deux types de requêtes :
- Requêtes d’investissement : elles visent les données financières et de financement des start-up, notamment les tours de table, la valorisation ou le CA. Exemple : « Trouvez des startups avec un financement de série A ou série B entre 8 millions et 25 millions de dollars et un chiffre d’affaires mensuel supérieur à 500 000 $. »
- Requêtes axées sur le marché: elles se concentrent sur les secteurs d’activité, les marchés géographiques ou les modèles économiques, en aidant à identifier des opportunités dans des secteurs ou régions spécifiques. Exemple : « Trouvez des startups de la fintech et de la santé à San Francisco, New York ou Boston. »
Pour garantir la robustesse des requêtes, nous allons faire en sorte que le LLM génère des modèles de recherche au lieu de requêtes DSL complètes. De cette façon, vous obtenez toujours la requête souhaitée, et le LLM n'a qu'à compléter les informations manquantes sans avoir à élaborer la requête dont vous avez besoin à chaque fois.
Ce dont vous avez besoin pour commencer
- Clé API Elasticsearch
- Clé d'API OpenAPI
- Node 18 ou version ultérieure
Instructions étape par étape
Dans cette section, voyons comment l'application sera présentée. Nous utiliserons TypeScript, un sur-ensemble de JavaScript qui ajoute des types statiques. Cela rend le code plus fiable, plus facile à maintenir et plus sûr en détectant les erreurs dès le début, tout en assurant une compatibilité totale avec JavaScript.
Le flux des nœuds se présentera comme suit :
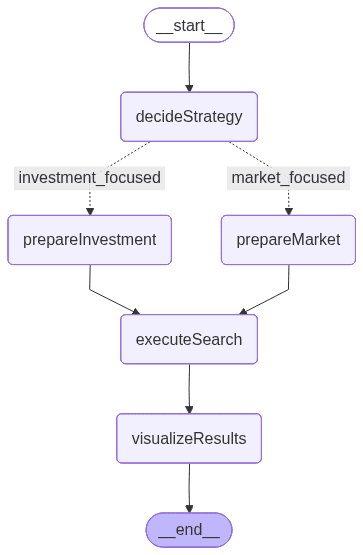
L'image ci-dessus est générée par LangGraph et représente le workflow qui définit l'ordre d'exécution et la logique conditionnelle entre les nodes :
- decideStrategy : utilise un LLM pour rechercher la requête de l'utilisateur et choisir entre deux stratégies de recherche spécialisées, axée sur l'investissement ou axée sur le marché.
- PrepareInvestmentSearch : extrait les valeurs de filtre de la requête et crée un modèle prédéfini mettant l'accent sur les paramètres financiers et liés au financement.
- PrepareMarketSearch: extrait également les valeurs des filtres, mais crée dynamiquement des paramètres en mettant l'accent sur le marché, le secteur et le contexte géographique.
- ExecuteSearch : envoie la recherche construite à Elasticsearch à l'aide d'un modèle de recherche et extrait les documents de démarrage correspondants.
- VisualiserResults : met en forme les résultats finaux sous la forme d'un résumé clair et lisible présentant les principaux attributs de la start-up tels que le financement, le secteur d'activité et le chiffre d'affaires.
Ce flux comprend un branchement conditionnel, fonctionnant comme une instruction « si », qui détermine s'il faut rechercher le chemin d'investissement ou de recherche de marché en fonction de l'entrée de l'utilisateur. Cette logique de décision, pilotée par le LLM, rend le workflow adaptatif et conscient du contexte, un mécanisme que nous explorerons plus en détail dans les sections suivantes.
État de LangGraph
Avant de voir chaque node individuellement, nous devons comprendre comment les nodes communiquent et partagent les données. Pour cela, LangGraph nous permet de définir l'état du workflow. Cela définit l'état partagé qui sera transmis entre les nodes.
L’état agit comme un conteneur partagé stockant les données intermédiaires du workflow : il enregistre d’abord la requête en langage naturel de l’utilisateur, puis la stratégie de recherche choisie, les paramètres prêts pour Elasticsearch, les résultats de recherche et, pour finir, le résultat formaté.
Cette architecture permet à chaque nœud de lire et de modifier l’état, ce qui garantit un flux d’informations constant, de l’entrée de l’utilisateur jusqu’à la visualisation finale.
Configurer l'application
Tout le code de cette section se trouve dans le dépôt elasticsearch-labs.
Dans le dossier où l’application sera installée, ouvrez un terminal et initialisez une application Node.js avec la commande :
Nous pouvons maintenant installer les dépendances nécessaires à ce projet :
@elastic/elasticsearch: Permet de gérer les requêtes Elasticsearch, comme l’ingestion et la récupération des données.@langchain/langgraph: Dépendance JS pour fournir tous les outils LangGraph.@langchain/openai: Client OpenAI LLM pour LangChain.- @langchain/core : Offre les composantes de base essentielles aux applications LangChain, notamment les modèles d’invite.
dotenv: Dépendance nécessaire pour utiliser les variables d'environnement en JavaScript.zod: Dépendance au type de données.
@types/node tsx typescript nous permet d'écrire et d'exécution du code TypeScript.
Créez maintenant les fichiers suivants :
elasticsearchSetup.ts: Créera les mapping d'index, chargera les données à partir d'un fichier JSON, et ingérera les données dans Elasticsearch.main.ts: inclura l’application LangGraph..env: fichier pour stocker les variables d’environnement
Dans le fichier .env, ajoutons les variables d’environnement suivantes :
La clé APIK de l'OpenAPI ne sera pas utilisée directement dans le code ; elle sera utilisée en interne par la bibliothèque @langchain/openai.
Toute la logique concernant la création de mappages, la création de modèles de recherche et l’ingestion des ensembles de données se trouve dans le fichier elasticsearchSetup.ts. Dans les prochaines étapes, nous nous concentrerons sur le fichier main.ts. Vous pouvez également consulter l'ensemble de données pour mieux comprendre l'aspect des données sur le site dataset.json.
Application LangGraph
Dans le fichier main.ts, importons certaines dépendances nécessaires pour consolider l'application LangGraph. Dans ce fichier, vous devez également inclure les fonctions node et la déclaration d’état. La déclaration du graphe sera effectuée dans une méthode main dans les prochaines étapes. Le fichier elasticsearchSetup.ts contiendra les aides Elasticsearch que nous allons utiliser dans les Nodes dans les étapes suivantes.
Ainsi que nous l’avons vu, le client LLM sera mobilisé pour générer les paramètres du modèle de recherche Elasticsearch en fonction de la question de l’utilisateur.
La méthode ci-dessus génère l'image du graphe au format png et utilise l'API Mermaid.INK en arrière-plan. Ceci est utile si vous souhaitez voir comment les nodes de l'application interagissent dans le cadre d'une visualisation stylisée.
Nodes LangGraph
À présent, voyons chaque node en détail :
Node decideSearchStrategy
Le node decideSearchStrategy analyse les entrées de l'utilisateur et détermine s'il convient d'effectuer une rechercher axée sur les investissements ou axée sur le marché. Il utilise un LLM avec un schéma de sortie structuré (défini avec Zod) pour classer le type de requête. Avant de prendre la décision, il récupère les filtres disponibles de l'index en utilisant une agrégation, en garantissant que le modèle dispose d'un contexte à jour sur les industries, les localisations et les données de financement.
Pour extraire les valeurs possibles des filtres et les envoyer au LLM, utilisons une requête d'agrégation pour les récupérer directement depuis l'index Elasticsearch. Cette logique est allouée dans une méthode appelée getAvailableFilters:
Avec la requête d'agrégation ci-dessus, nous avons les résultats suivants :
Découvrez tous les résultats ici.
Pour les deux stratégies, nous allons utiliser la recherche hybride afin de détecter à la fois la partie structurée de la question (filtres) et les parties plus subjectives (sémantique). Voici un exemple des deux requêtes utilisant des modèles de recherche :
Regardez les requêtes détaillées dans le fichier elasticsearchSetup.ts . Dans le node suivant, il sera décidé laquelle des deux requêtes sera utilisée :
Nodes prepareInvestmentSearch et prepareMarketSearch
Les deux nœuds utilisent une fonction d’assistance partagée, extractFilterValues, qui exploite le LLM pour identifier les filtres pertinents mentionnés dans les entrées de l’utilisateur, tels que l’industrie, la localisation, le stade de financement, le modèle économique, etc. Nous utilisons ce schéma pour construire notre modèle de recherche.
Selon l'intention détectée, le workflow sélectionne l'un des deux chemins :
prepareInvestmentSearch : définit des paramètres de rechercher orientés sur la finance, notamment l''étape du financement, le montant du financement, les informations relatives à l''investisseur et au renouvellement. Vous pouvez trouver le modèle complet de requête dans le fichier elasticsearchSetup.ts :
prepareMarketSearch : crée des paramètres orientés vers le marché, axés sur les industries, les régions géographiques et les modèles économiques. Voir l’intégralité de la requête dans le fichier elasticsearchSetup.ts :
Node executeSearch
Ce node prend les paramètres de rechercher générés à partir de l'état et les envoie d'abord à Elasticsearch, en utilisant l'API _render pour visualiser la requête à des fins de débogage, puis envoie une demande pour récupérer les résultats.
Node visualizeResults
Enfin, ce node affiche les résultats d’Elasticsearch.
Par programmation, l'ensemble du graphe ressemble à ceci :
Comme vous pouvez le constater, nous avons une arête conditionnelle où l'application décide quel « chemin » ou node sera exécuté ensuite. Cette fonctionnalité est utile lorsque les workflows nécessitent une logique de branchement, comme le choix entre plusieurs outils ou l’inclusion d’une étape humaine dans la boucle.
Maintenant que vous maîtrisez les fonctionnalités clés de LangGraph, nous pouvons préparer l’application qui exécutera le code :
Rassemblons tout dans une méthode main , ici nous déclarons le graphe avec tous les éléments sous la variable workflow :
La variable de requête simule l'entrée utilisateur saisie dans une barre de recherche hypothétique :

D’après la phrase en langage naturel « Trouvez des startups avec un financement de la série A ou de la série B entre 8 millions et 25 millions de dollars et un chiffre d’affaires mensuel supérieur à 500 000 $ », tous les filtres seront extraits.
Enfin, invoquez la méthode principale :
Résultats
Pour l'entrée envoyée, l'application choisit le chemin axé sur l'investissement et, par conséquent, nous pouvons voir la requête Elasticsearch générée par le workflow, qui extrait les valeurs et les plages de l'entrée de l'utilisateur. Nous pouvons également voir la requête envoyée à Elasticsearch avec les valeurs extraites appliquées, et enfin, les résultats formatés par le nœud visualizeResults avec les résultats.
Testons maintenant le node axé sur le marché en utilisant la requête « Trouver des startups fintech et de la santé à San Francisco, New York ou Boston » :
Enseignements
Pendant le processus d'écriture, j'ai appris :
- Nous devons montrer au LLM les valeurs exactes des filtres, sinon nous attendons de l'utilisateur qu'il saisisse les valeurs exactes des éléments. Pour une faible cardinalité, cette approche convient, mais lorsque la cardinalité est élevée, nous avons besoin d'un mécanisme pour filtrer les résultats
- Utiliser des modèles de recherche rend les résultats bien plus cohérents que de laisser le LLM écrire la requête Elasticsearch, et c’est aussi plus rapide
- Les arêtes conditionnelles constituent un mécanisme puissant pour construire des applications avec de multiples variantes et chemins de branchement.
- La sortie structurée est extrêmement utile lors de la génération d'informations avec des LLM, car elle applique des réponses prévisibles et sécurisées. Cela améliore la fiabilité et réduit les erreurs d'interprétation.
La combinaison de la recherche sémantique et de la recherche structurée par le biais d'une recherche hybride produit des résultats meilleurs et plus pertinents, en équilibrant précision et compréhension du contexte.
Conclusion
Dans cet exemple, nous combinons LangGraph.js avec Elasticsearch pour créer un workflow dynamique capable d'interpréter les requêtes en langage naturel et de décider entre des stratégies de recherche axées sur la finance ou le marché. Cette approche réduit la complexité de la création de requêtes manuelles tout en améliorant la flexibilité et la précision pour les analystes en capital-risque.
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.