Con Elastic Open Sitio web Crawler y su arquitectura basada en CLI, tener configuraciones de rastreador versionado y una pipeline CI/CD con pruebas locales ahora es bastante sencillo de lograr.
Tradicionalmente, gestionar los rastreadores era un proceso manual y propenso a errores. Implicaba editar configuraciones directamente en la interfaz y luchar con clonar configuraciones de rastreo, retrocesos, versionear y más. Tratar las configuraciones de rastreadores como código resuelve esto al proporcionar los mismos beneficios que esperamos en el desarrollo de software: repetibilidad, trazabilidad y automatización.
Este flujo de trabajo facilita la incorporación del Open Sitio web Crawler a tu pipeline CI/CD para rollbacks, copias de seguridad y migraciones, tareas que eran mucho más complicadas con los Elastic Crawlers anteriores, como el Elastic Sitio web Crawler o el App Search Crawler.
En este artículo, vamos a aprender cómo:
- Gestiona nuestras configuraciones de rastreo usando GitHub
- Tener una configuración local para probar pipelines antes de desplegar
- Crea una configuración de producción para ejecutar el rastreador sitio web con nuevos ajustes cada vez que enviemos cambios a nuestra rama principal
Puedes encontrar el repositorio de proyectos aquí. Según escribo, estoy usando Elasticsearch 9.1.3 y Open Sitio web Crawler 0.4.2.
Prerrequisitos
- Escritorio Docker
- Instancia de Elasticsearch
- Máquina virtual con acceso SSH (por ejemplo, AWS EC2) y Docker instalados
Pasos
- Estructura de carpetas
- Configuración del orugador
- Docker-compose (entorno local)
- Acciones en Github
- Pruebas locales
- Desplegando a la producción
- Realización de cambios y re-despliegue
Estructura de carpetas
Para este proyecto, tendremos la siguiente estructura de archivos:
Configuración del orugador
Bajo crawler-config.yml, pondremos lo siguiente:
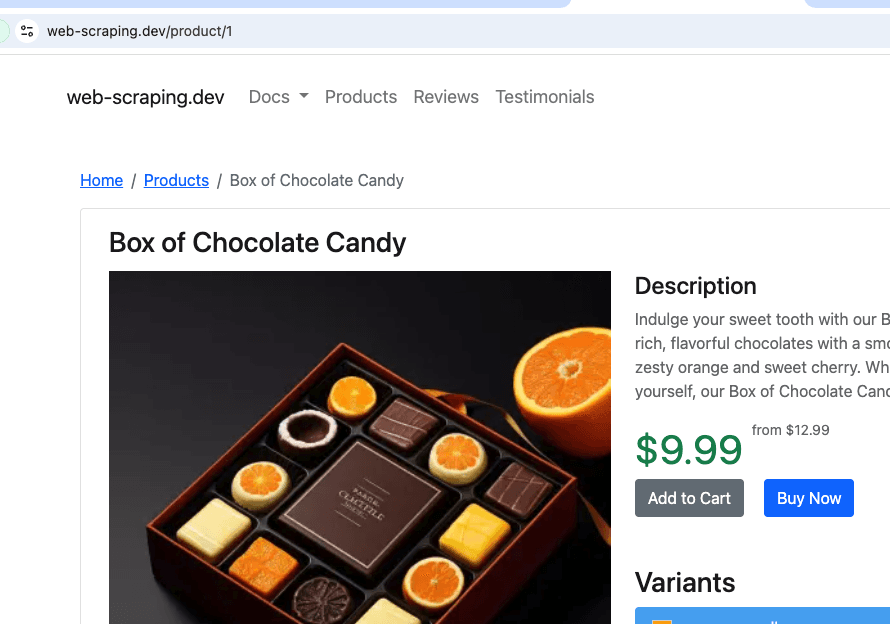
Esto se rastreará desde https://sitio web-scraping.dev/products, un sitio simulado de productos. Solo rastrearemos las tres primeras páginas del producto. La configuración max_crawl_depth evitará que el rastreador descubra más páginas de las definidas como seed_urls al no abrir los enlaces que contienen.
Elasticsearch host y api_key se llenarán dinámicamente dependiendo del entorno en el que ejecutemos el script.
Docker-compose (entorno local)
Para la docker-compose.yml, local desplegaremos el rastreador y un único clúster Elasticsearch + Kibana, para poder visualizar fácilmente los resultados del rastreo antes de desplegarlos en producción.
Fíjate en cómo el rastreador espera hasta que Elasticsearch esté listo para ejecutar.
Acciones en Github
Ahora necesitamos crear una acción en GitHub que copie la nueva configuración y ejecute el rastreador en nuestra máquina virtual en cada envío a main. Esto garantiza que siempre tengamos la última configuración desplegada, sin tener que entrar manualmente en la máquina virtual para actualizar archivos y ejecutar el rastreador. Vamos a usar AWS EC2 como proveedor de máquinas virtuales.
El primer paso es agregar el host (VM_HOST), el usuario de la máquina (VM_USER), la clave SSH RSA (VM_KEY), el host de Elasticsearch (ES_HOST) y la clave API de Elasticsearch (ES_API_KEY) a los secretos de acción de GitHub:
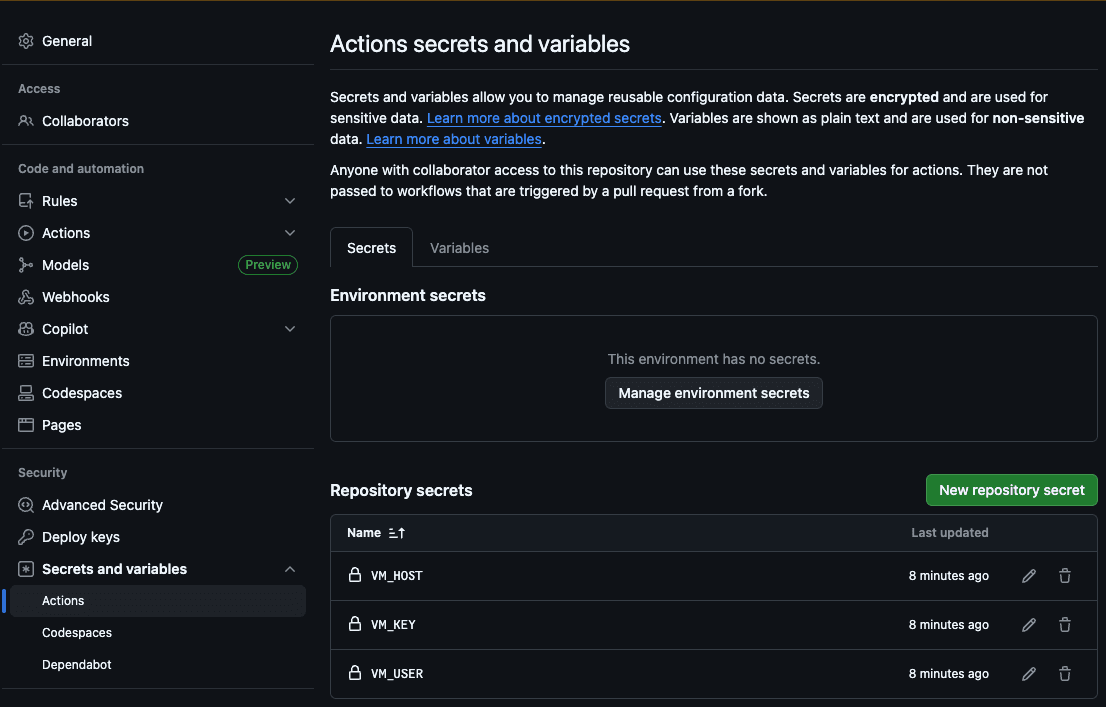
De este modo, la acción podrá acceder a nuestro servidor para copiar los archivos nuevos y ejecutar el rastreo.
Ahora, creemos nuestro archivo .github/workflows/deploy.yml :
Esta acción ejecutará los siguientes pasos cada vez que empujemos cambios en el archivo de configuración del rastreador:
- Llenar el host y la clave API de Elasticsearch en la configuración de yml
- Copia la carpeta config a nuestra máquina virtual
- Conéctate vía SSH a nuestra máquina virtual
- Ejecuta el rastreo con la configuración que acabamos de copiar del repositorio
Pruebas locales
Para probar nuestro rastreador localmente, creamos un script bash que llena el host de Elasticsearch con el local de Docker y comienza un rastreo. Puedes ejecutar ./local.sh para ejecutarlo.
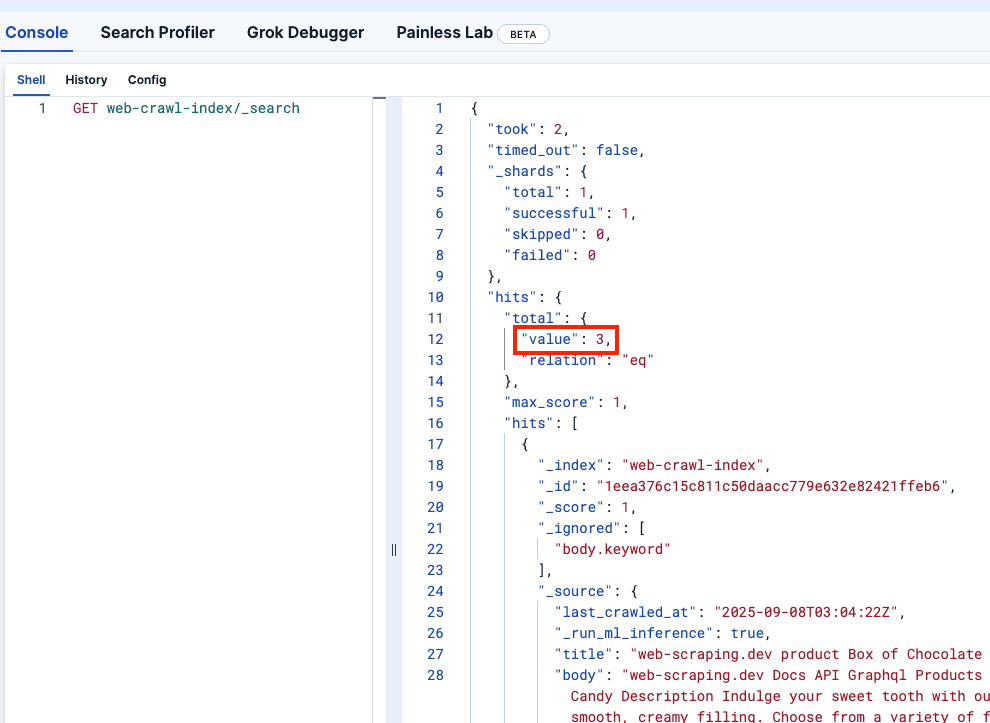
Veamos Kibana DevTools para confirmar que el web-crawler-index se rellenó correctamente:
Desplegando a la producción
Ahora estamos listos para enviar a la rama principal, que desplegará el rastreador en tu máquina virtual y comenzará a enviar registros a tu instancia Serverless Elasticsearch.
Esto activará la Acción de GitHub, que ejecutará el script de despliegue dentro de la máquina virtual y comenzará a rastrear.
Puedes confirmar que la acción se ejecutó yendo al repositorio de GitHub y visitando la pestaña "Acciones":

Realización de cambios y re-despliegue
Algo que quizá notaste es que el price de cada producto forma parte del cuerpo del documento. Lo ideal sería almacenar el precio en un campo aparte para poder aplicar filtros sobre él.
Vamos a agregar este cambio al archivo crawler.yml para usar reglas de extracción que extraigan el precio de la clase CSS de product-price :
También vemos que el precio incluye un signo de dólar ($), que debemos eliminar si queremos hacer consultas por rango. Podemos usar una canalización de ingesta para eso. Ten en cuenta que lo estamos haciendo referencia en nuestro nuevo archivo de configuración del rastreador arriba:
Podemos ejecutar ese comando en nuestro clúster de Elasticsearch en producción. Para el desarrollo, al ser efímero, podemos hacer que la creación de pipeline forme parte del archivo docker-compose.yml agregando el siguiente servicio. Ten en cuenta que también agregamos un depends_on al servicio de rastreo para que empiece después de que la tubería se creó con éxito.
Ahora vamos a ejecutar `./local.sh` para ver el cambio localmente:

¡Bien! Ahora impulsemos el cambio:
Para confirmar que todo funciona, puedes comprobar tu Kibana de producción, que debería reflejar los cambios y mostrar el precio como un nuevo campo sin el signo del dólar.
Conclusión
El Elastic Open Sitio web Crawler te permite gestionar tu rastreador como código, lo que significa que puedes automatizar toda la pipeline —desde el desarrollo hasta el despliegue— y agregar entornos locales efímeros y pruebas programáticas contra los datos rastreados, por nombrar algunos ejemplos.
Se te invita a clonar el repositorio oficial y empezar a indexar tus propios datos usando este flujo de trabajo. También puedes leer este artículo para aprender a realizar búsqueda semántica en índices producidos por el rastreador.
Contenido relacionado

18 de mayo de 2026
Búsqueda con IA de agentes y barreras de protección determinísticas en Elasticsearch para una ejecución segura de consultas
Los sistemas de búsqueda con IA de agentes suelen fallar cuando los LLM generan consultas directamente. Aprende cómo las barreras de protección deterministas y la arquitectura de plano de control permiten una ejecución de consultas segura, fiable y regulada con Elasticsearch.

11 de mayo de 2026
Personalización de la búsqueda en comercio electrónico: integración del historial de compras y cohortes de usuarios
Aprende a crear una experiencia de búsqueda personalizada en Elasticsearch sin infringir la gobernanza. En esta publicación se explica cómo destacar los productos que un comprador ha adquirido previamente y cómo activar políticas específicas de cohortes basadas en perfiles de usuario.

4 de mayo de 2026
Percolador de Elasticsearch para la gobernanza de búsquedas en comercio electrónico: traducir búsquedas ambiguas en estrategias de recuperación controladas
Aprende a usar el percolador de Elasticsearch para implementar la gobernanza de búsquedas. En este blog, describimos los patrones necesarios para crear un motor de políticas regulado en producción y establecer una estrategia de recuperación controlada.

1 de mayo de 2026
Creación de un plano de control para gestionar las búsquedas en el comercio electrónico
Cómo construir un plano de control gobernado para el comercio electrónico que integre políticas de búsqueda conflictivas en un solo plan de ejecución (sin cambios de código).

24 de abril de 2026
Reindexación de flujos de datos debido a conflictos de mapping
Descubre cómo solucionar los conflictos de mapeo de Elasticsearch reindexando los flujos de datos. Este blog explica el proceso de reindexación y la verificación del mapeo correcto.