La búsqueda vectorial no es suficiente para encontrar resultados relevantes. Es muy común usar criterios de filtrado que ayudan a reducir los resultados de búsqueda y a filtrar los resultados irrelevantes.
Entender cómo funciona el filtrado en la búsqueda vectorial te ayudará a equilibrar los compromisos entre rendimiento y recordación, así como descubrir algunas de las optimizaciones que se usan para que la búsqueda vectorial sea eficiente al usar filtrado.
¿Por qué filtrar?
La búsqueda vectorial revolucionó la forma en que encontramos información relevante en grandes conjuntos de datos, permitiéndonos descubrir elementos que son semánticamente similares a una consulta.
Sin embargo, simplemente encontrar objetos similares no es suficiente. A menudo necesitamos reducir los resultados de búsqueda en función de criterios o atributos específicos.
Imagina que buscas un producto en una tienda online. Una búsqueda vectorial pura puede mostrarte artículos visualmente similares, pero también podrías filtrar por rango de precio, marca, disponibilidad o valoraciones de clientes. Sin filtrar, te presentarías con una gran variedad de productos similares, lo que dificultaría encontrar exactamente lo que buscas.
El filtrado permite un control preciso sobre los resultados de búsqueda, cerciorando que los elementos recuperados no solo se alineen semánticamente, sino que también cumplan todos los requisitos necesarios. Esto conduce a una experiencia de búsqueda mucho más precisa, eficiente y fácil de usar.
Aquí es donde Elasticsearch y Apache Lucene excelen: usar filtrado efectivo entre varios tipos de datos es una de las diferencias clave con otras bases de datos vectoriales.
Filtrado para búsqueda vectorial exacta
Existen dos formas principales de realizar búsquedas vectoriales exactas:
- Usar un tipo de índice
flatpara tu campo de dense_vector. Esto hace queknnbúsquedas empleen la búsqueda exacta en lugar de aproximada. - Emplear una consulta script_score que emplea funciones vectoriales para calcular el puntaje. Esto puede usar con cualquier tipo de índice.
Al ejecutar una búsqueda vectorial exacta, todos los vectores se comparan con la consulta. En este escenario, el filtrado ayudará al rendimiento, ya que solo se necesitan comparar los vectores que pasan el filtro.
Esto no afecta a la calidad del resultado, ya que todos los vectores se consideran de todos modos. Simplemente filtramos de antemano los resultados que no son interesantes, para poder reducir el número de operaciones.
Esto es muy importante, ya que puede ser más eficiente ejecutar una búsqueda exacta en lugar de una búsqueda aproximada cuando los filtros aplicados resultan en un pequeño número de documentos.
La regla general es usar la búsqueda exacta cuando menos de 10.000 documentos pasan el filtro. Los índices BBQ son mucho más rápidos para comparar, así que tiene sentido usar la búsqueda exacta cuando hay menos de 100k para los índices basados. Consulta esta entrada del blog para más detalles.
Si tus filtros siempre son muy restrictivos, puedes considerar indexar centrado en la búsqueda exacta en lugar de en la búsqueda aproximada, usando un tipo de índice flat en lugar de uno basado en HNSW. Para más detalles, ver las propiedades de index_options.
Filtrado para búsqueda vectorial aproximada
Al ejecutar búsqueda vectorial aproximada, cambiamos la precisión de los resultados por el rendimiento. Las estructuras de datos de búsqueda vectorial como HNSW buscan eficientemente vecinos aproximados en millones de vectores. Se centran en recuperar los vectores más similares haciendo la menor cantidad posible de comparaciones vectoriales, que son costosas de calcular.
Esto significa que otros atributos de filtrado no forman parte de los datos vectoriales. Diferentes tipos de datos tienen sus propias estructuras de indexación que son eficientes para encontrarlos y filtrarlos, como diccionarios de términos, listas de publicación y valores de documentos.
Dado que estas estructuras de datos son independientes del mecanismo de búsqueda vectorial, ¿cómo aplicamos el filtrado a la búsqueda vectorial? Hay dos opciones: aplicar filtros luego de la búsqueda vectorial (postfiltrado) o antes de la búsqueda vectorial (prefiltrado).
Cada una de esas opciones tiene sus pros y sus contras. ¡Vamos a profundizar en ellos!
Postfiltrado
El postfiltrado aplica filtros después de que se realizó la búsqueda vectorial. Esto significa que los filtros se aplican después de que se encontraron los k primeros resultados vectoriales más similares.
Obviamente, podemos obtener menos de k resultados aplicando los filtros a los resultados. Por supuesto, podríamos obtener más resultados de la búsqueda vectorial (valores k más altos), pero no estaremos seguros de obtener k o más tras aplicar los filtros.
El beneficio del postfiltrado es que no cambia el comportamiento en tiempo de ejecución de la búsqueda vectorial: la búsqueda vectorial no es consciente del filtrado. Pero sí cambia el número final de resultados obtenidos.
A continuación se muestra un ejemplo de postfiltrado usando la consulta knn. Comprueba que la cláusula de filtrado esté separada de la consulta knn:
El filtrado de postfiltrado también está disponible para la búsqueda de knn usando el filtro de postfiltro:
Ten en cuenta que necesitas usar una sección explícita de filtro posterior con la búsqueda de knn. Si no usas un filtro de post, la búsqueda de knn combinará los resultados de vecinos más cercanos con otras consultas o filtros en lugar de hacer un filtro de post.
Prefiltrado
Aplicar filtros antes de la búsqueda vectorial primero recuperará los documentos que cumplan con los filtros y luego transmitirá esa información a la búsqueda vectorial.
Lucene emplea BitSets para almacenar eficientemente los documentos que cumplen la condición de filtro. La búsqueda vectorial recorre entonces el grafo HNSW, teniendo en cuenta los documentos que cumplen la condición. Antes de agregar un candidato a los resultados, comprueba que esté contenido en el BitSet de documentos válidos.
Sin embargo, el candidato debe ser explorado y comparado con la consulta, aunque no sea un documento válido. La efectividad de HNSW depende de la conexión entre los vectores del grafo: si dejáramos de explorar un candidato, significaría que podríamos estar saltándonos también sus vecinos.
Piénsalo como manejar para llegar a una gasolinera. Si descartas cualquier carretera que no tenga gasolinera, es poco probable que llegues a tu destino. Puede que otras carreteras no sean lo que necesitas, pero te conectan con tu destino. ¡Lo mismo ocurre con los vectores en un grafo HNSW!
Por tanto, aplicar prefiltrado es menos eficiente que no aplicar filtros. Tenemos que trabajar en todos los vectores que visitamos en nuestra búsqueda, y desechar aquellos que no coinciden con el filtro. Estamos trabajando más y tardando más en conseguir los mejores resultados de la k.
A continuación se muestra un ejemplo de pretfiltering en la DSL de Elasticsearch Consult. Comprueba que la cláusula de filtrado ahora forma parte de la sección knn:
El prefiltrado está disponible tanto para la búsqueda como para la consulta knn:
Optimizaciones de prefiltrado
Hay un par de optimizaciones que podemos aplicar para cerciorar que el prefiltrado sea eficiente.
Podemos cambiar a búsqueda exacta si el filtro es muy restrictivo. Cuando hay pocos vectores para comparar, es más rápido realizar una búsqueda exacta en los pocos documentos que cumplen con el filtro.
Esta es una optimización que se aplica automáticamente en Lucene y Elasticsearch.
Otro método de optimización implica ignorar los vectores que no satisfacen el filtro. En su lugar, este método comprueba los vecinos de los vectores filtrados que sí pasan el filtro. Este enfoque reduce efectivamente el número de comparaciones ya que no se consideran los vectores filtrados, y continúa explorando vectores conectados al camino actual.
Este algoritmo es ACORN-1, y el proceso se describe en detalle en esta entrada del blog.
Filtrado usando la seguridad a nivel de documento
La Seguridad a Nivel de Documento (DLS) es una función de Elasticsearch que especifica los documentos que los roles de usuario pueden recuperar.
DLS se realiza mediante consultas. Un rol puede tener una consulta asociada a índices, lo que limita efectivamente los documentos que un usuario que pertenece a ese rol puede recuperar de los índices.
La consulta de rol se emplea como filtro para recuperar los documentos que coinciden con ella, y se almacenan en caché como un BitSet. Este BitSet se emplea entonces para envolver el lector Lucene subyacente, de modo que solo los documentos que se devolvieron de la consulta se consideran activos,es decir, existen en el índice y no fueron eliminados.
A medida que los documentos en tiempo real se recuperan del lector para realizar la consulta knn, solo se considerarán los documentos disponibles para el usuario. Si hay un prefiltro, se agregarán los documentos DLS a él.
Esto significa que el filtrado DLS funciona como prefiltro para la búsqueda vectorial aproximada, con las mismas participaciones de rendimiento y optimizaciones.
DLS con búsqueda exacta tendrá los mismos beneficios que aplicar cualquier filtro: cuantos menos documentos se recuperen de DLS, más eficiente será una búsqueda exacta. Considera también el número de documentos devueltos por DLS; si los roles DLS son muy restrictivos, puedes considerar usar búsqueda exacta en lugar de búsqueda aproximada.
Evaluación comparativa
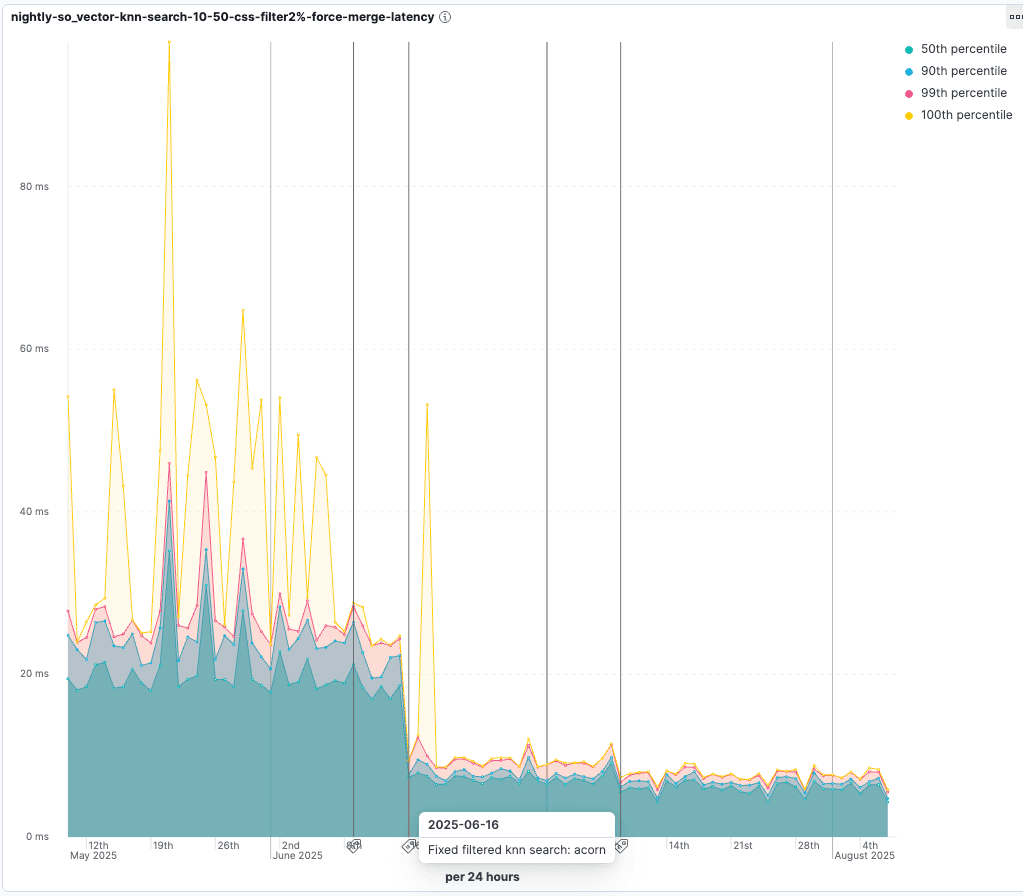
En Elasticsearch, queremos cerciorarnos de que el filtrado de búsqueda vectorial sea eficiente. Disponemos de un benchmark específico para el filtrado vectorial que realiza búsquedas vectoriales aproximadas con diferentes filtros para cerciorar que la búsqueda vectorial siga recuperando resultados relevantes lo más rápido posible.
Consulta las mejoras cuando se introdujo ACORN-1. Para pruebas en las que solo el 2% de los vectores pasan el filtro, la latencia de consulta se reduce al 55% de la duración original:
Conclusión
El filtrado es una parte integral de la búsqueda. Cerciorar que el filtrado sea eficiente en la búsqueda vectorial y comprender los compromisos y optimizaciones es lo que hace que una búsqueda sea eficiente y precisa o fracase.
El filtrado afecta al rendimiento de la búsqueda vectorial:
- La búsqueda exacta es más rápida cuando se usa filtrado. Deberías considerar usar la búsqueda exacta en lugar de la aproximada si tu filtrado es lo suficientemente restrictivo. Esta es una optimización automática en Elasticsearch.
- La búsqueda aproximada es más lenta cuando se emplea prefiltrado. El prefiltrado nos permite obtener los k primeros resultados que coinciden con el filtro, a costa de una búsqueda más lenta.
- El postfiltrado no necesariamente recupera los k primeros resultados, ya que pueden filtrar mediante el filtro cuando se aplica.
¡Feliz filtrado!
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.