Al ajustar Elasticsearch para cargas de trabajo de alta concurrencia, el enfoque estándar es maximizar la RAM para mantener el conjunto de documentos en la memoria y lograr una baja latencia de búsqueda. En consecuencia, best_compression rara vez se considera para cargas de trabajo de búsqueda, ya que se ve principalmente como una medida de ahorro de almacenamiento para casos de uso de Elastic Observability y Elastic Security donde la eficiencia del almacenamiento tiene prioridad.
En este blog, demostramos que cuando el tamaño de los sets de datos supera significativamente la caché de la página del sistema operativo, best_compression mejora el rendimiento de búsqueda y la eficiencia de los recursos al reducir el cuello de botella de las E/S.
La configuración
Nuestro caso de uso es una aplicación de búsqueda de alta concurrencia que se ejecuta en instancias optimizadas para CPU de Elastic Cloud.
- Volumen de datos: ~500 millones de documentos
- Infraestructura: 6 instancias de Elastic Cloud (Elasticsearch Service) (cada instancia: 1,76 TB de almacenamiento | 60 GB de RAM | 31,9 vCPU).
- Proporción de memoria a almacenamiento: ~5 % del total de sets de datos que cabe en la RAM
Los síntomas: alta latencia
Observamos que cuando el número de solicitudes actuales aumenta alrededor de las 19:00, la latencia de búsqueda se deteriora significativamente. Como se muestra en la figura 1 y la figura 2, mientras que el tráfico alcanza un máximo de 400 solicitudes por minuto por instancia de Elasticsearch, el tiempo promedio del servicio de consulta se degrada a más de 60 ms.
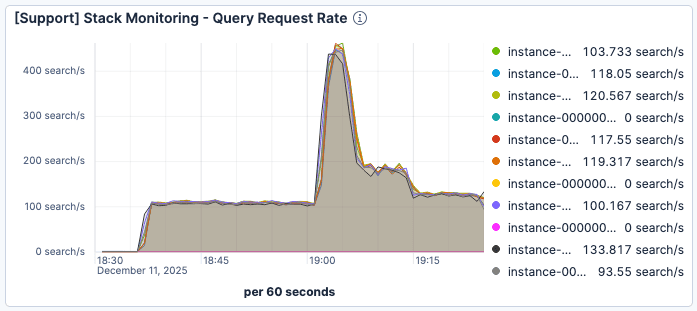
Figura 1. Las solicitudes por minuto por instancia de Elasticsearch alcanzaron su punto máximo justo después de las 19:00, con aproximadamente 400.
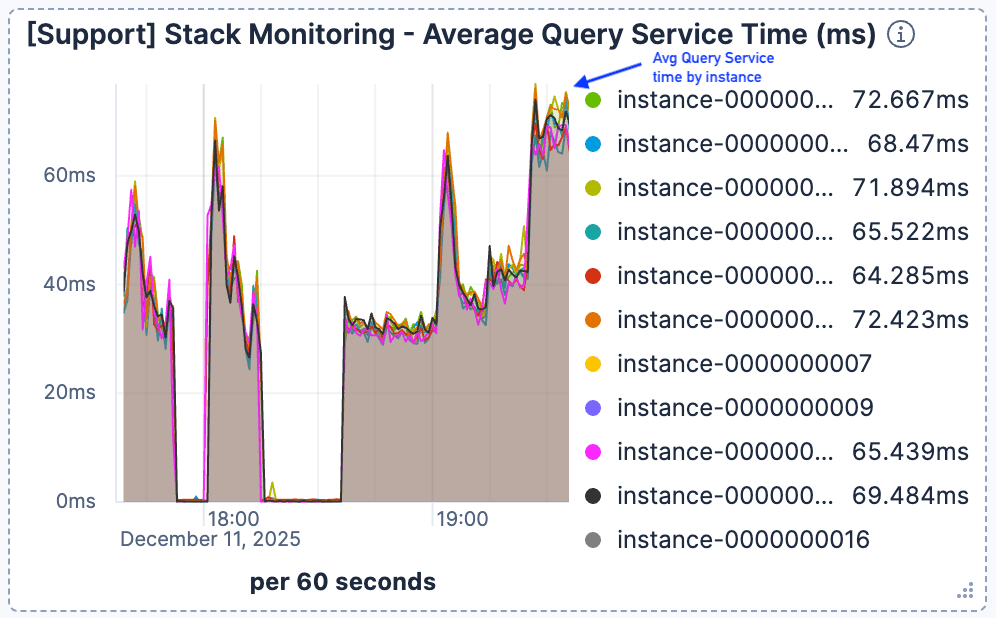
Figura 2. El tiempo promedio del servicio de consulta comenzó a aumentar repentinamente y se mantuvo en >60ms.
El uso de la CPU seguía siendo relativamente bajo tras el manejo inicial de las conexiones, lo que indica que el cálculo no era el cuello de botella.
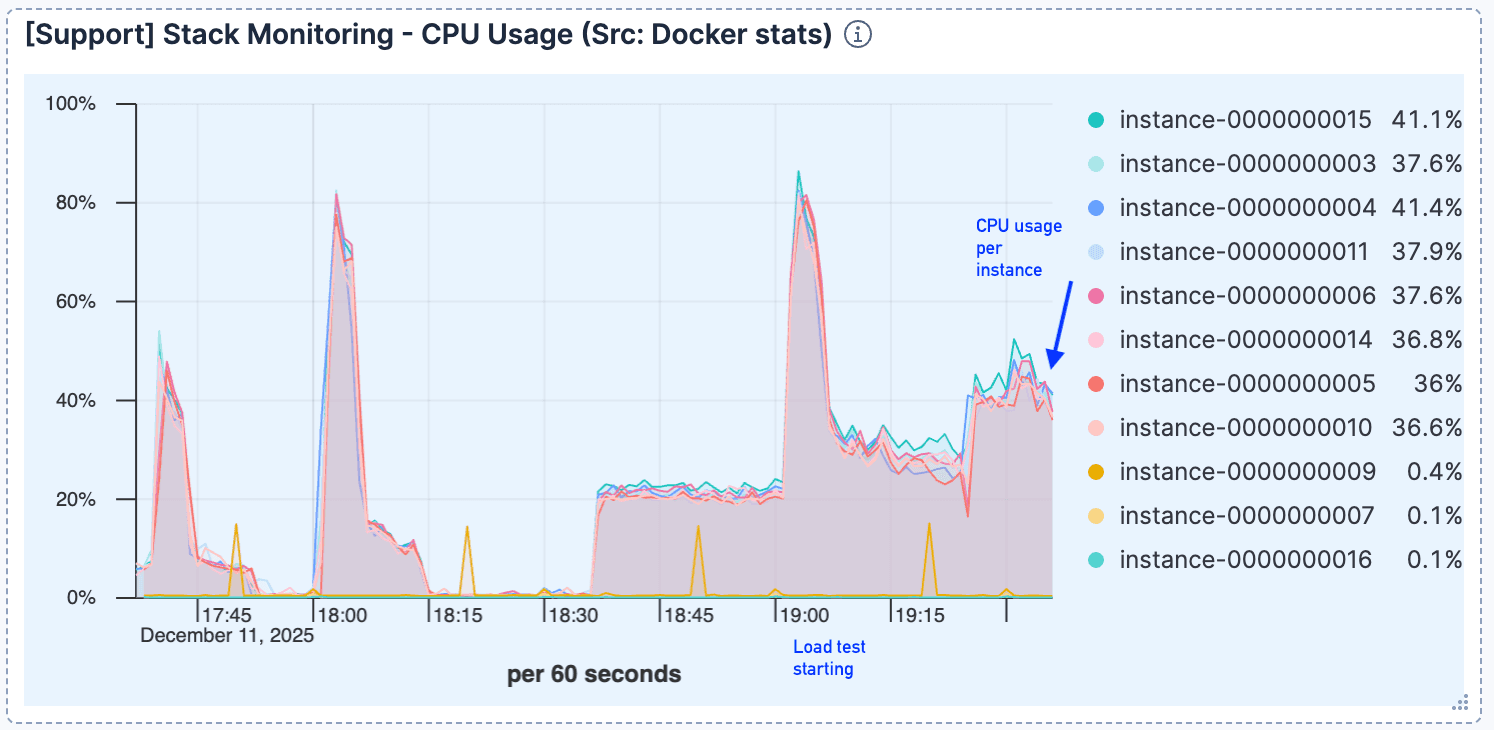
Figura 3. Tras el salto inicial, el uso de la CPU sigue siendo relativamente bajo.
Surgió una fuerte correlación entre el volumen de búsquedas y los errores de página. A medida que aumentaban las solicitudes, observamos un incremento proporcional en los errores de página, que alcanzaron un pico de alrededor de 400k/minuto. Esto indicaba que el set de datos activo no podía caber en la caché de la página.
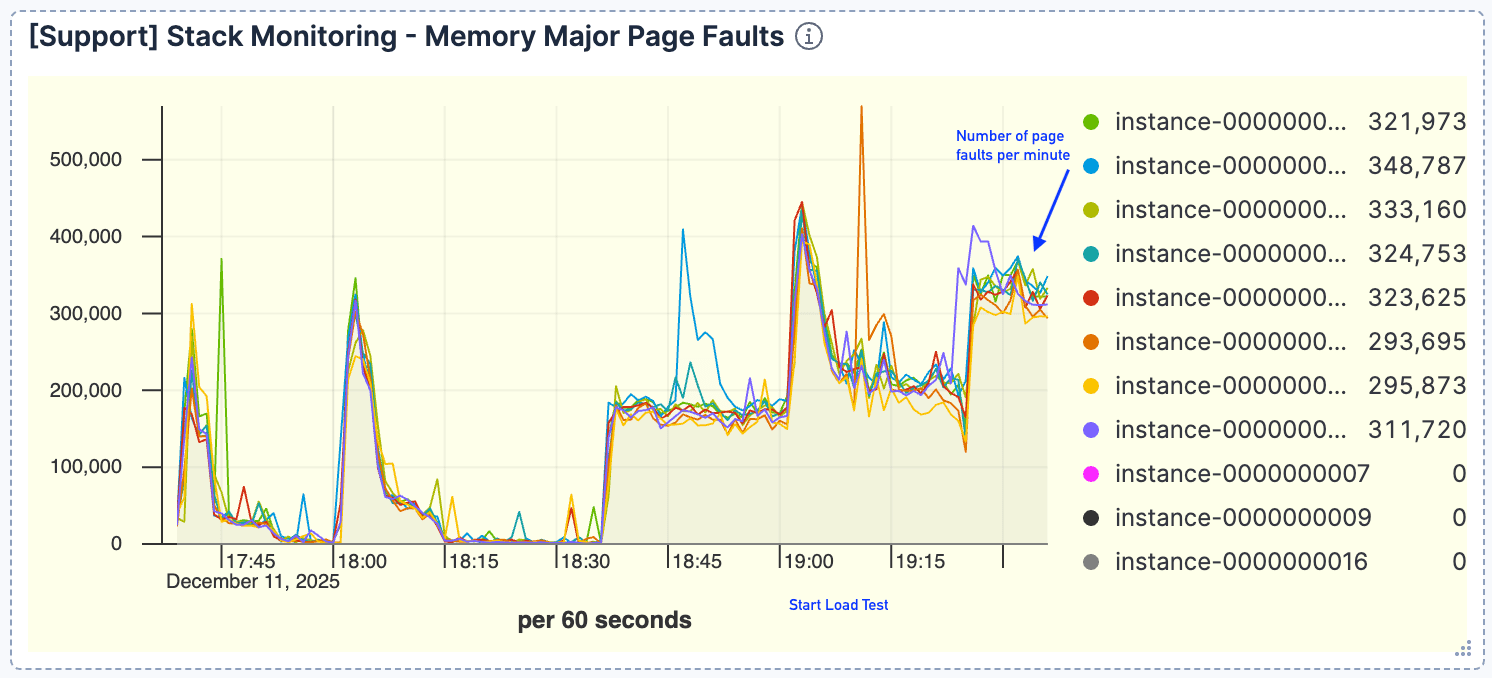
Figura 4. La cantidad de errores de página fue alta, con un pico de alrededor de 400k/minuto.
Al mismo tiempo, el uso del heap de JVM parecía ser normal y saludable. Esto descartó problemas de recolección de basura y confirmó que el cuello de botella era de E/S.
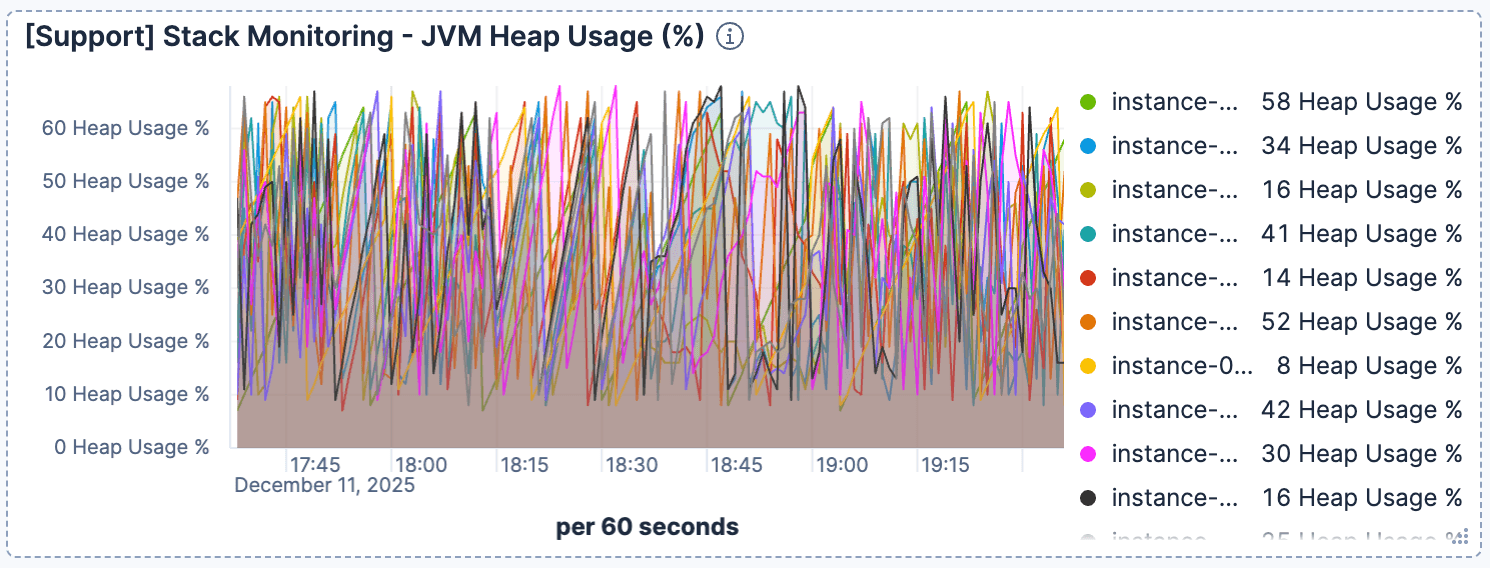
Figura 5. El uso de heap se mantuvo estable.
El diagnóstico: limitado por E/S
El sistema estaba vinculado a E/S. Elasticsearch se basa en la caché de páginas del sistema operativo para servir datos de índice desde la memoria. Cuando el índice es demasiado grande para la caché, las consultas desencadenan lecturas de disco costosas. Aunque la solución habitual es escalar horizontalmente (agregar nodos/RAM), quisimos agotar primero las mejoras de eficiencia de nuestros recursos existentes.
La solución
De forma predeterminada, Elasticsearch utiliza la compresión LZ4 para sus segmentos de índice, que logra un equilibrio entre la velocidad y el tamaño. Planteamos la hipótesis de que cambiarse a best_compression (que usa zstd) reduciría el tamaño de los índices. Un espacio más pequeño permite que un mayor porcentaje del índice encaje en la caché de páginas, lo que cambia un aumento insignificante en la CPU (para la descompresión) por una reducción en la E/S del disco.
Para habilitar best_compression, reindexamos los datos con la configuración de índice index.codec: best_compression. Alternativamente, el mismo resultado podría lograrse al cerrar el índice, que restablece el códec de índice a best_compression, y luego realiza una fusión de segmentos.
Los resultados
Los resultados confirmaron nuestra hipótesis: la eficiencia mejorada del almacenamiento se tradujo directamente en un aumento sustancial en el rendimiento de búsqueda sin un aumento asociado en la utilización de la CPU.
La aplicación de best_compression redujo el tamaño del índice en aproximadamente un 25 %. Aunque es menor que la reducción observada en los datos de log repetitivos, esta reducción del 25 % aumentó efectivamente nuestra capacidad de caché de página en el mismo margen.
Durante la siguiente prueba de carga (que comenzó a las 17:00), el tráfico fue aún mayor, y alcanzó un pico de 500 solicitudes por minuto por nodo de Elasticsearch.
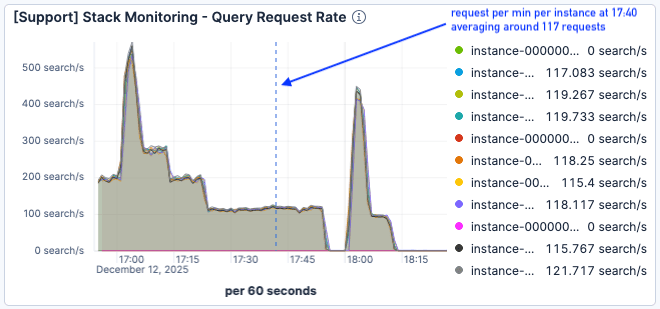
Figura 6. La prueba de carga comenzó alrededor de las 17:00.
A pesar de la mayor carga, la utilización de la CPU fue menor que en la ejecución anterior. El uso elevado en la prueba anterior probablemente se debió a la sobrecarga del manejo excesivo de errores de página y la gestión de E/S del disco.
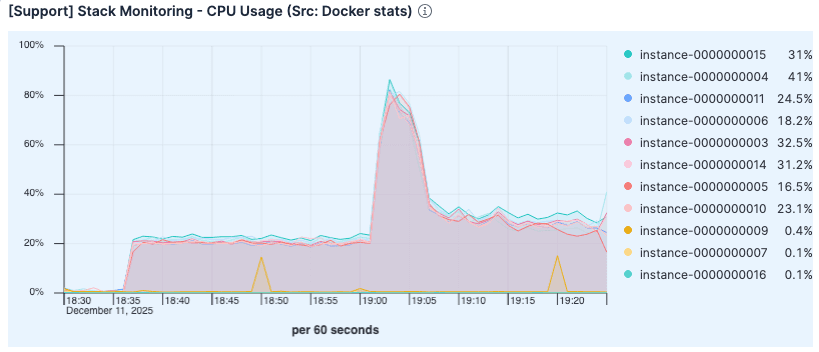
Figura 7. La utilización de la CPU fue menor que en la ejecución anterior.
Lo más importante es que los errores de página disminuyeron significativamente. Incluso a un rendimiento más alto, los errores rondaron los <200k por minuto, en comparación con >300k en la prueba de referencia.
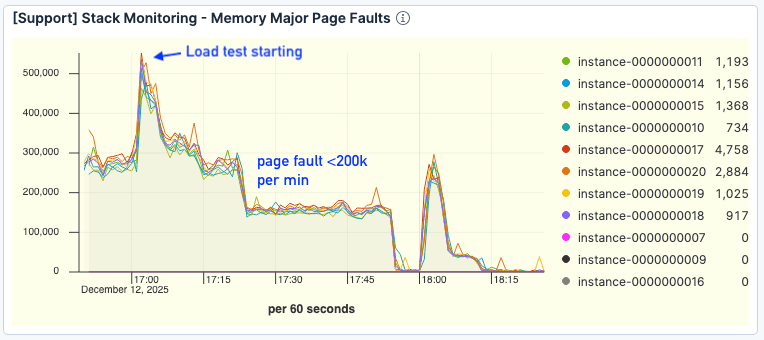
Figura 8. La cantidad de errores de página vio una mejora significativa.
Aunque los resultados del error de página aún fueron menos que óptimos, el tiempo de servicio de consulta se redujo en aproximadamente un 50 %, y se mantuvo por debajo de los 30 ms incluso bajo una carga más pesada.
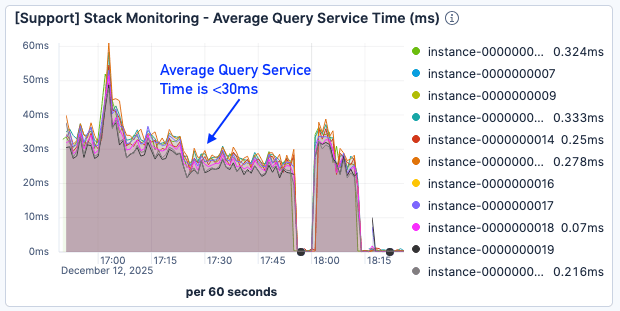
Figura 9. El tiempo promedio del servicio de consulta fue <30ms.
La conclusión: best_compression para la búsqueda
Para casos de uso donde el volumen de datos supera la memoria física disponible, best_compression es una palanca poderosa para ajustar el rendimiento.
La solución convencional a los errores de caché es escalar para aumentar la RAM. Sin embargo, al reducir la huella del índice, logramos el mismo objetivo: maximizar el recuento de documentos en la memoria caché de páginas. Nuestro siguiente paso es explorar la clasificación de índices para optimizar aún más el almacenamiento y obtener más rendimiento de los recursos existentes.
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

26 de marzo de 2026
Anuncio de los permisos de solo lectura para los dashboards de Kibana
Presentamos los dashboards de solo lectura en Kibana, que ofrecen a los creadores de dashboards controles granulares para compartir y mantener los resultados precisos y protegidos de cambios no deseados.
2 de marzo de 2026
Terminación temprana adaptativa para HNSW en Elasticsearch
Presentamos una nueva estrategia adaptativa de terminación temprana para HNSW en Elasticsearch.

11 de diciembre de 2025
Evaluación de la relevancia de las consultas de búsqueda con listas de evaluaciones
Explora cómo crear listas de evaluación para evaluar objetivamente la relevancia de las consultas de búsqueda y mejorar métricas de rendimiento como la recuperación, para pruebas de búsqueda escalables en Elasticsearch.

11 de noviembre de 2025
Configuración del fragmento recursivo para documentos estructurados en Elasticsearch
Aprende a configurar el chunking recursivo en Elasticsearch con tamaño de bloque, grupos de separadores y listas de separadores personalizadas para una indexación óptima de documentos estructurados.