Lors de l'optimisation d'Elasticsearch pour des charges de travail à forte simultanéité, l'approche standard consiste à maximiser la RAM afin de conserver l'ensemble des documents de travail en mémoire et d'obtenir une faible latence de recherche. Par conséquent, best_compression est rarement l'option choisie pour les charges de travail de recherche, car il est principalement perçu comme une mesure d'économie d'espace pour les cas d'utilisation d'Elastic Observability et d'Elastic Security où l'efficacité du stockage est prioritaire.
Dans ce blog, nous démontrons que lorsque la taille de l'ensemble de données dépasse nettement le cache de page du système d'exploitation, best_compression améliore les performances de recherche et l'efficacité des ressources en réduisant le goulot d'étranglement des E/S.
La configuration
Notre cas d'utilisation est une application de recherche à forte simultanéité qui s'exécute sur des instances Elastic Cloud optimisées pour le processeur.
- Volume de données : ~500 millions de documents
- Infrastructure : 6 instances Elastic Cloud (Elasticsearch Service) (chaque instance : 1,76 To de stockage | 60 Go de RAM | 31,9 vCPU)
- Rapport mémoire/stockage : la RAM peut recevoir environ 5 % du volume total de données
Les symptômes : latence élevée
Nous avons constaté qu'aux alentours de 19:00, lorsque le nombre de requêtes augmentait fortement, la latence de recherche s'est considérablement dégradée. Comme le montrent les figures 1 et 2, lorsque le trafic atteignait un pic d'environ 400 requêtes par minute et par instance Elasticsearch, le temps de réponse moyen des requêtes chutait à plus de 60 ms.
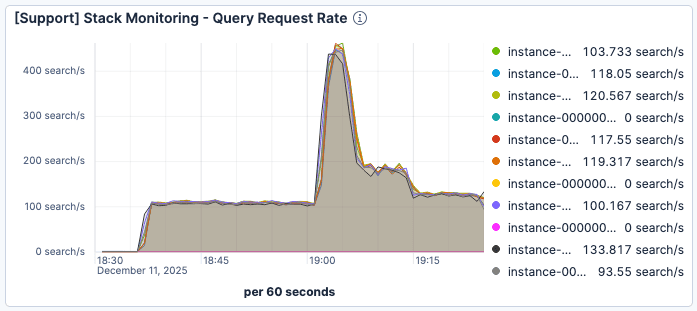
Figure 1. Le nombre de requêtes par minute par instance Elasticsearch atteint un pic juste après 19h00, à environ 400.
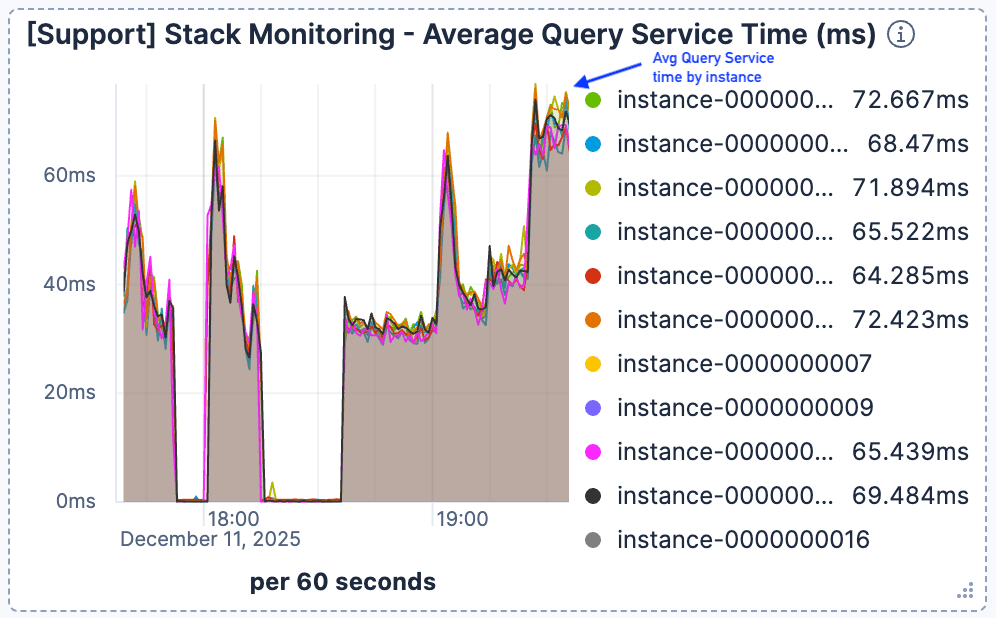
Figure 2. Le temps de réponse moyen aux requêtes commence à augmenter brusquement, puis atteint 60 ms et se maintient à ce niveau.
L'utilisation du processeur est restée relativement faible après le traitement initial des connexions, indiquant que le calcul n'était pas le facteur limitant.
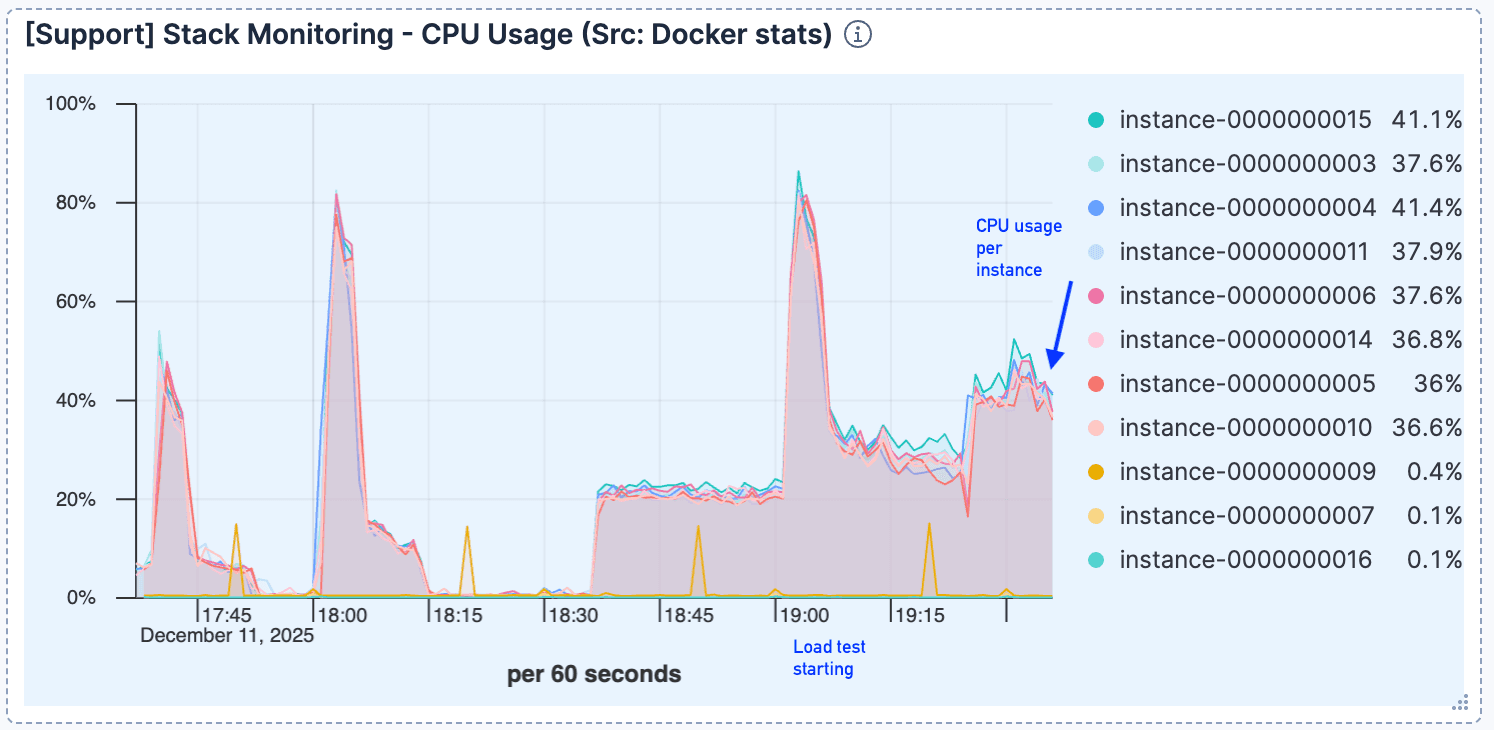
Figure 3. Après le saut initial, l'utilisation du processeur reste relativement faible.
Une forte corrélation est apparue entre le volume de requêtes et les défauts de page. À mesure que les requêtes augmentaient, nous avons observé une hausse proportionnelle des défauts de page, avec un pic aux alentours de 400k/minute. Cela indique que l'ensemble de données actif ne pouvait pas être contenu dans le cache de pages.
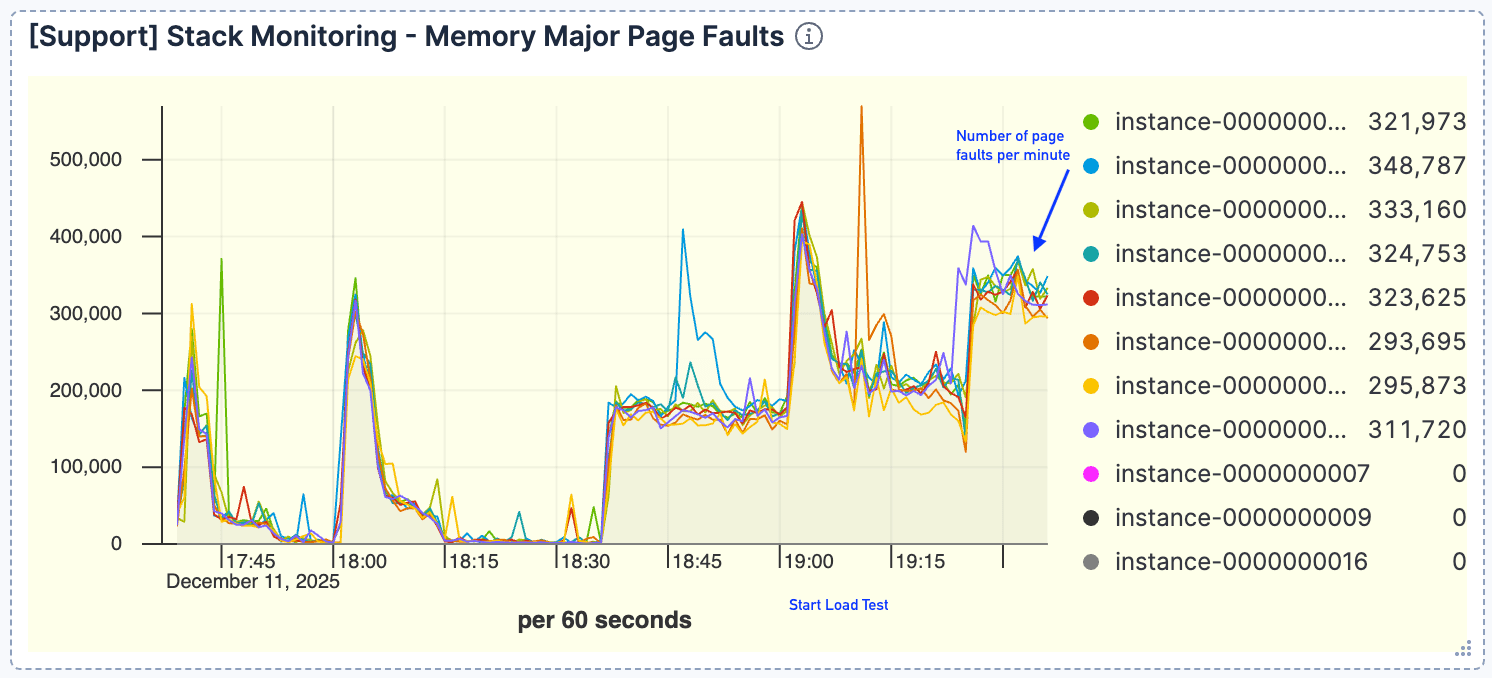
Figure 4. Le nombre de défauts de page est élevé, atteignant un pic d'environ 400k/minute.
Parallèlement, l'utilisation du tas JVM semblait normale et saine. Cela a permis d'exclure les problèmes de récupération de mémoire et de confirmer que le goulot d'étranglement était lié aux entrées/sorties.
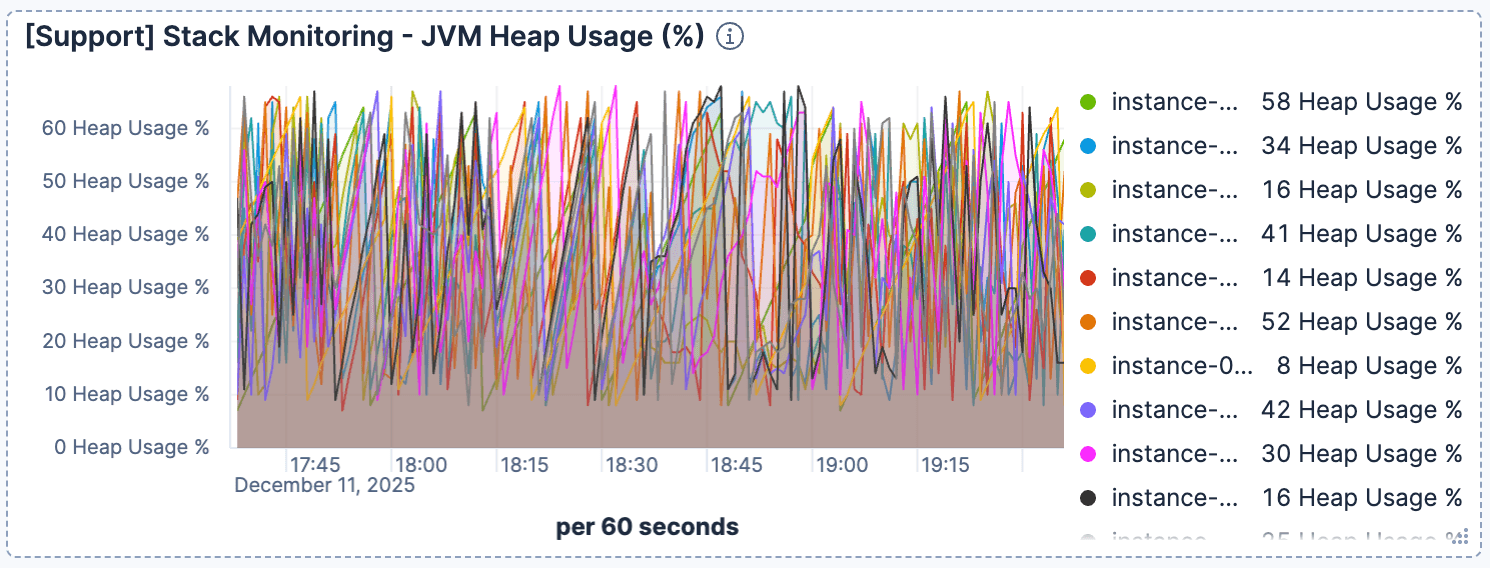
Figure 5. L'utilisation du tas est restée stable.
Le diagnostic : I/O bound
Le système était limité par les E/S. Elasticsearch s'appuie sur le cache de pages du système d'exploitation pour fournir les données d'index depuis la mémoire. Lorsque l'index est trop volumineux pour le cache, les requêtes entraînent des lectures disque coûteuses. Bien que la solution classique consiste à effectuer un scaling horizontal (ajout de nœuds/RAM), nous souhaitions d'abord optimiser au maximum nos ressources existantes.
La solution
Par défaut, Elasticsearch utilise la compression LZ4 pour ses segments d'index, qui offre un bon compromis entre vitesse et taille. Nous avons émis l'hypothèse que le passage à best_compression (qui utilise zstd) réduirait la taille des index. Une empreinte mémoire plus faible permet d'intégrer une plus grande partie de l'index dans le cache de pages, moyennant une augmentation négligeable de la charge CPU (pour la décompression) au profit d'une réduction des E/S disque.
Pour activer best_compression, nous avons réindexé les données avec le paramètre d'index index.codec: best_compression. Sinon, le même résultat pourrait être obtenu en fermant l'index, en réinitialisant le codec d'index à best_compression, puis en effectuant une fusion de segments.
Résultats
Les résultats ont confirmé notre hypothèse : l'amélioration de l'efficacité du stockage s'est directement traduite par une augmentation substantielle des performances de recherche sans augmentation concomitante de l'utilisation du processeur.
L'application de best_compression a réduit la taille de l'index d'environ 25 %. Bien qu'inférieure à la réduction observée dans les données de log répétitives, cette réduction de 25 % a effectivement augmenté la capacité de notre cache de pages dans les mêmes proportions.
Lors du test de charge suivant (à partir de 17:00), le trafic était encore plus élevé, avec un pic de 500 requêtes par minute et par nœud Elasticsearch.
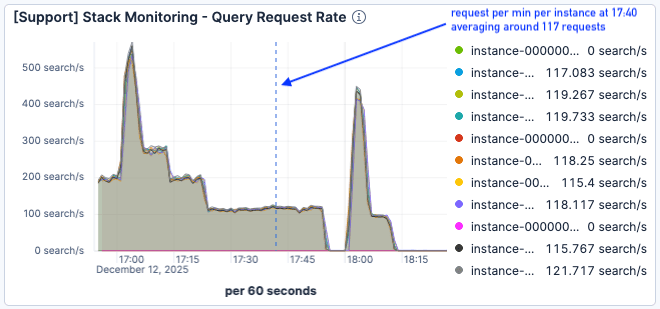
Figure 6. Le test de charge a commencé vers 17:00.
Malgré la charge plus élevée, l'utilisation du processeur était inférieure à celle de l'exécution précédente. L'utilisation élevée dans le test précédent était probablement due à la surcharge liée à la gestion excessive des défauts de page et à la gestion des E/S de disque.
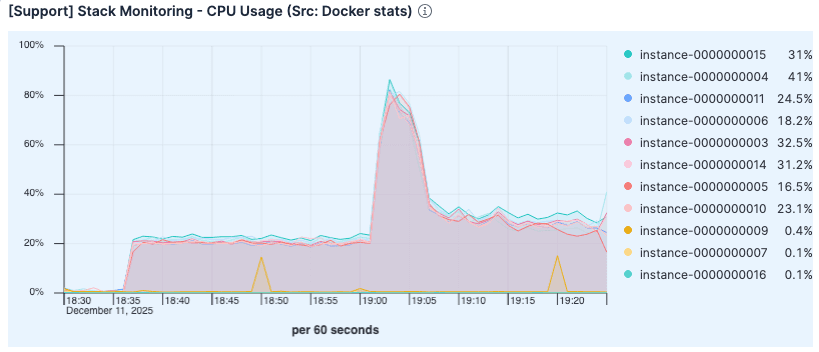
Figure 7. L'utilisation du processeur est inférieure à celle de l'exécution précédente.
Surtout, le nombre de défauts de page diminue de manière significative. Même à un débit plus élevé, les erreurs se situent autour de <200k par minute, contre >300k dans le test de référence.
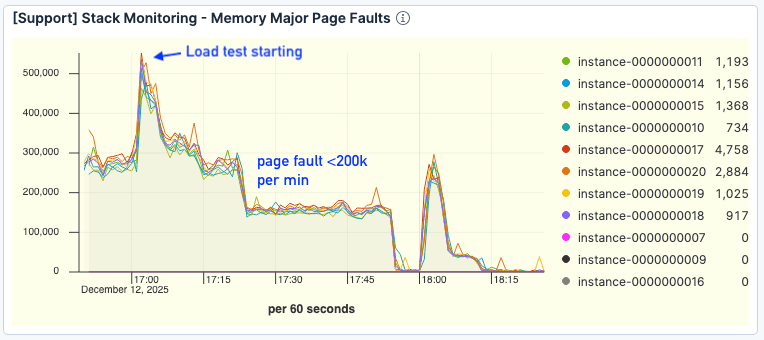
Figure 8. Le nombre de défauts de page s'améliore nettement.
Bien que les résultats concernant les défauts de page soient encore loin d'être optimaux, le temps de réponse aux requêtes a été réduit d'environ 50 %, se maintenant sous la barre des 30 ms même en cas de charge plus importante.
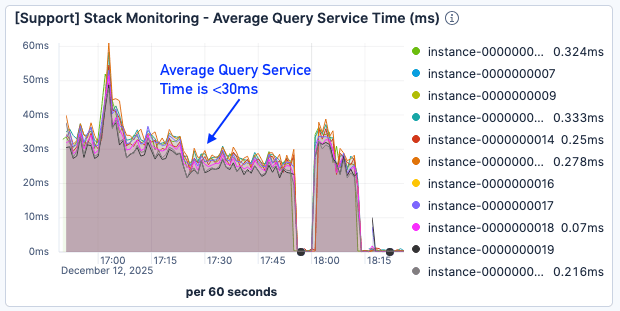
Figure 9. Le temps moyen de réponse aux requêtes est <30 ms.
Conclusion : best_compression pour la recherche
Pour les cas d'utilisation de recherche où le volume de données dépasse la mémoire physique disponible, best_compression est un levier puissant d'optimisation des performances.
La solution classique aux erreurs de cache consiste à scaler pour augmenter la RAM. Cependant, en réduisant l'empreinte de l'index, nous avons atteint le même objectif : maximiser le nombre de documents dans le cache de pages. Notre prochaine étape consistera à explorer l'index trié afin d'optimiser davantage l'espace de stockage et d'améliorer encore les performances de nos ressources existantes.
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

26 mars 2026
Annonce des autorisations en lecture seule pour les tableaux de bord Kibana
Présentation des tableaux de bord en lecture seule dans Kibana, offrant aux créateurs de tableaux de bord des contrôles de partage détaillés pour garantir l'exactitude des résultats et les protéger contre les modifications indésirables.
2 mars 2026
Arrêt précoce adaptatif pour HNSW dans Elasticsearch
Présentation d'une nouvelle stratégie adaptative d'arrêt précoce pour HNSW dans Elasticsearch.

11 décembre 2025
Évaluer la pertinence des requêtes de recherche à l’aide de listes de jugement
Découvrez comment créer des listes de jugement pour évaluer objectivement la pertinence des requêtes de recherche et améliorer des indicateurs de performance comme le rappel, dans le cadre de tests de recherche scalable avec Elasticsearch.

11 novembre 2025
Configurer le découpage récursif pour les documents structurés dans Elasticsearch
Apprenez à configurer le découpage récursif dans Elasticsearch avec la taille des morceaux, les groupes de séparateurs et les listes de séparateurs personnalisées pour une indexation optimale des documents structurés.