Ao ajustar o Elasticsearch para cargas de trabalho de alta simultaneidade, a abordagem padrão é maximizar a RAM para manter o conjunto de documentos em memória e alcançar baixa latência de busca. Consequentemente, best_compression raramente é considerado para cargas de trabalho de busca, pois é visto principalmente como uma medida de economia de armazenamento para casos de uso do Elastic Observability e Elastic Security, onde a eficiência do armazenamento tem prioridade.
Neste blog, demonstramos que, quando o tamanho do conjunto de dados excede significativamente o cache de páginas do SO, best_compression melhora o desempenho da busca e a eficiência dos recursos, reduzindo o gargalo de E/S.
A configuração
Nosso caso de uso é um aplicativo de busca de alta concorrência executado em instâncias otimizadas para CPU no Elastic Cloud.
- Volume de dados: ~500 milhões de documentos
- Infraestrutura: 6 instâncias Elastic Cloud (Elasticsearch Service) (cada instância: 1,76 TB de armazenamento | 60 GB de RAM | 31,9 vCPU)
- Relação memória-armazenamento: ~5% do conjunto de dados total cabe na RAM
Os sintomas: alta latência
Observamos que quando o número de solicitações atuais aumentou drasticamente por volta das 19:00, a latência na busca se deteriorou significativamente. Como mostrado na Figura 1 e na Figura 2, enquanto o tráfego atingiu o pico em torno de 400 solicitações por minuto por instância do Elasticsearch, o tempo médio de serviço de consulta se degradou para mais de 60 ms.
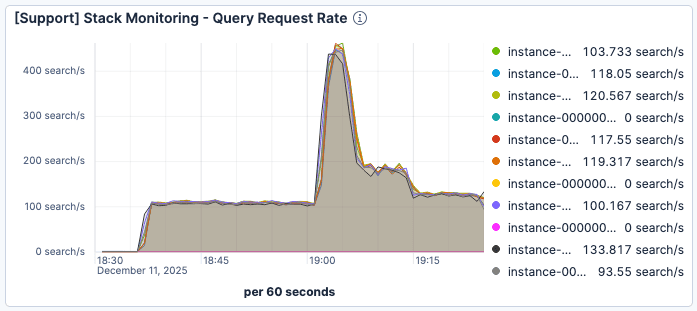
Figura 1. As solicitações por minuto por instância do Elasticsearch atingiram o pico logo após as 19h, com cerca de 400.
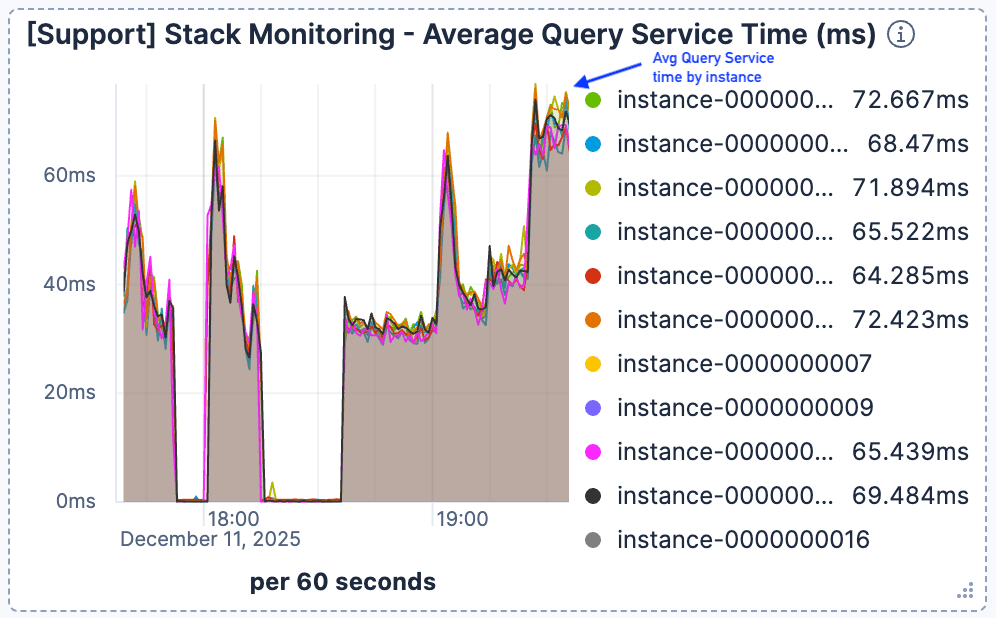
Figura 2. O tempo médio do serviço de consulta começou a aumentar, subiu e permaneceu em >60 ms.
O uso da CPU permaneceu relativamente baixo após o tratamento inicial das conexões, indicando que o processamento não era o gargalo.
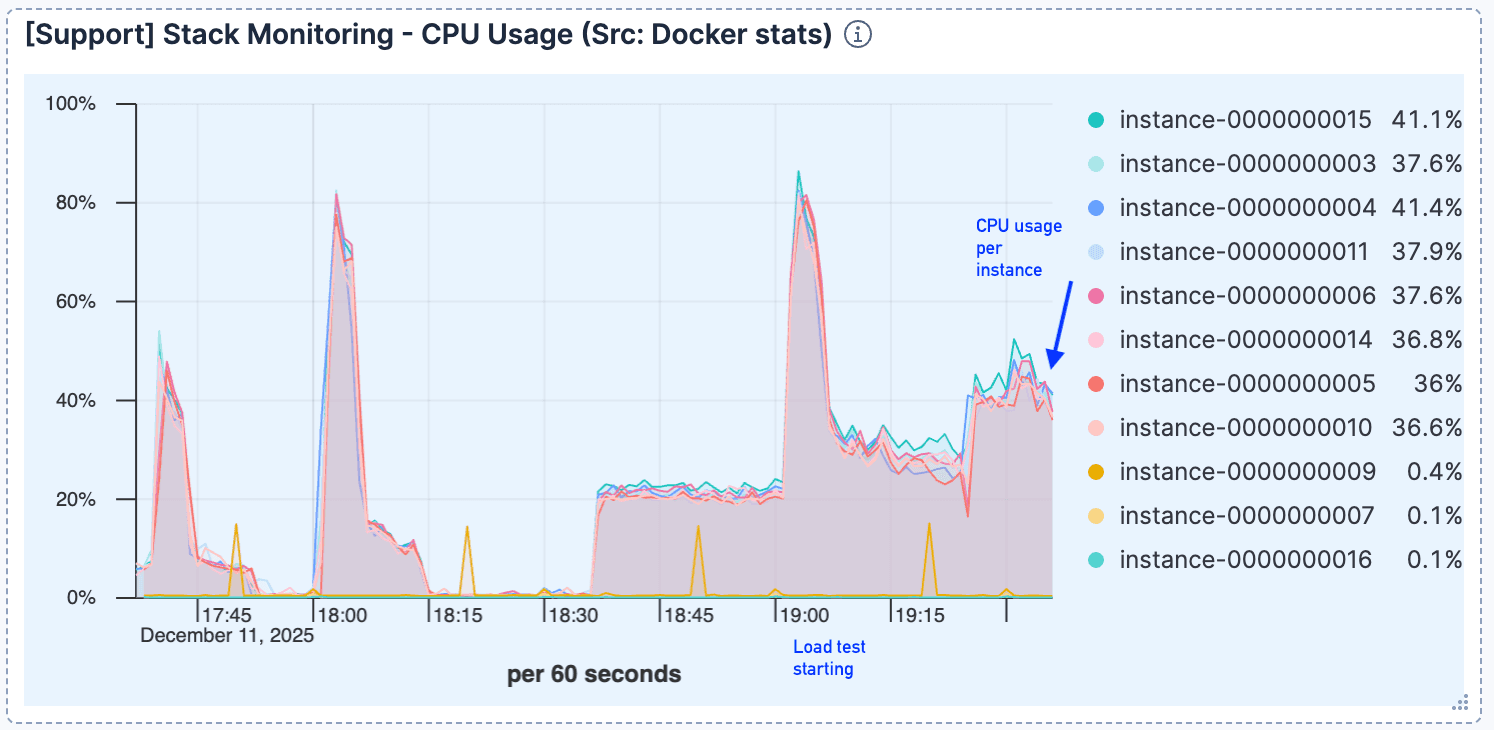
Figura 3. Após o salto inicial, o uso da CPU permanece relativamente baixo.
Uma forte correlação surgiu entre volume de consultas e falhas de página. À medida que os pedidos aumentavam, observamos um aumento proporcional nas falhas de página, atingindo o pico em torno de 400 mil por minuto. Isso indicava que o conjunto de dados ativo não cabia no cache da página.
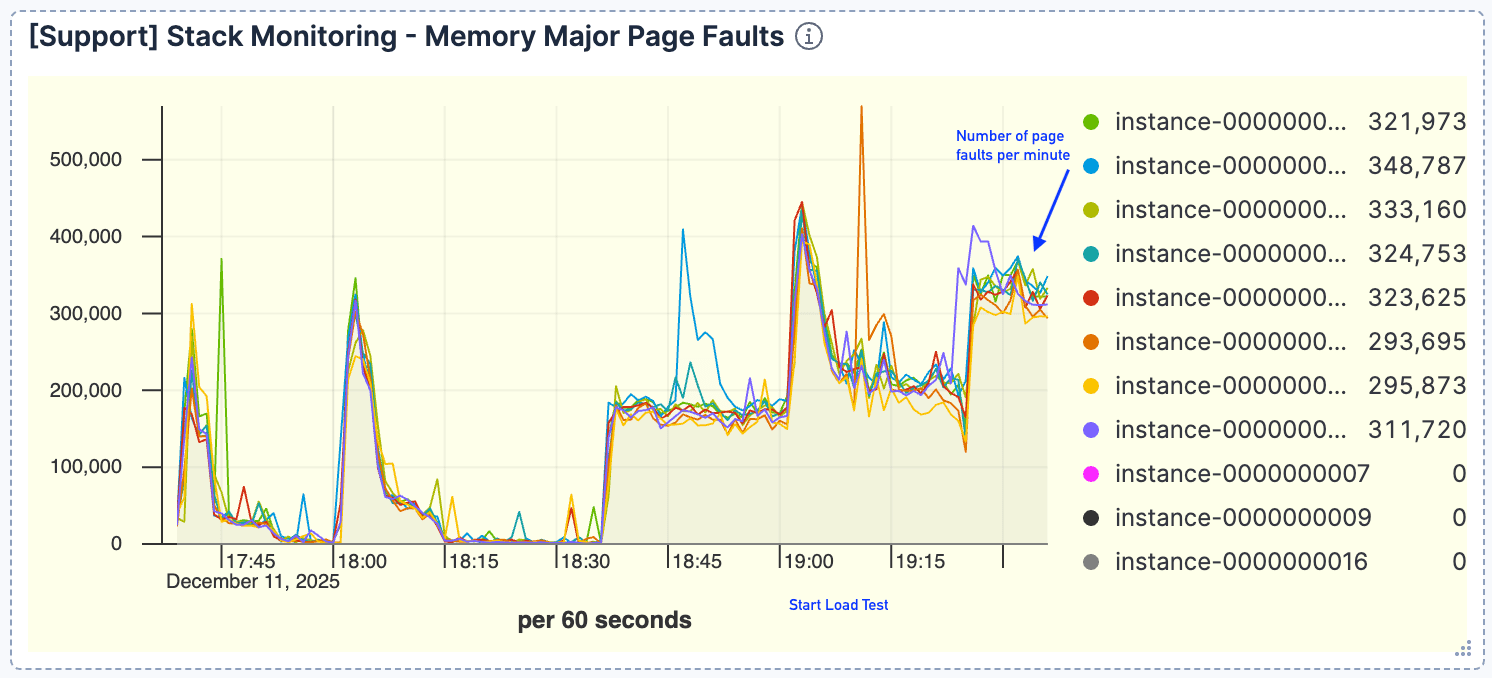
Figura 4. O número de falhas de página foi alto, atingindo o pico em torno de 400 mil por minuto.
Simultaneamente, o uso do heap da JVM parecia normal e saudável. Isso descartou problemas de coleta de lixo e confirmou que o gargalo era de E/S.
Figura 5. A utilização de heap permaneceu estável.
O diagnóstico: limitado por E/S
O sistema estava limitado por E/S. O Elasticsearch depende do cache de páginas do sistema operacional para fornecer dados de índice a partir da memória. Quando o índice é grande demais para o cache, consultas acionam leituras de disco caras. Embora a solução típica seja redimensionar horizontalmente (adicionar nodes/RAM), queríamos primeiro esgotar as melhorias de eficiência em nossos recursos existentes.
A correção
Como padrão, o Elasticsearch usa a compressão LZ4 para seus segmentos de índice, buscando um equilíbrio entre velocidade e tamanho. Hipotetizamos que mudar para best_compression (que usa zstd) reduziria o tamanho dos índices. Um espaço menor permite que uma porcentagem maior do índice caiba no cache da página, trocando um aumento insignificante na CPU (por descompressão) por uma redução na E/S do disco.
Para habilitar best_compression, reindexamos os dados com a configuração de índice index.codec: best_compression. O mesmo resultado poderia ser alcançado fechando o índice, resetando o codec do índice para best_compression, e então realizando uma fusão de segmentos.
Os resultados
Os resultados confirmaram nossa hipótese: a eficiência aprimorada do armazenamento se traduziu diretamente em um aumento substancial no desempenho da busca, sem nenhum aumento na utilização da CPU.
A aplicação de best_compression reduziu o tamanho do índice em aproximadamente 25%. Embora menor do que a redução observada em dados de log repetitivos, essa redução de 25% aumentou efetivamente nossa capacidade de cache de páginas pela mesma margem.
Durante o próximo teste de carga (começando às 17:00), o tráfego foi ainda maior, atingindo o pico de 500 solicitações por minuto por nó Elasticsearch.
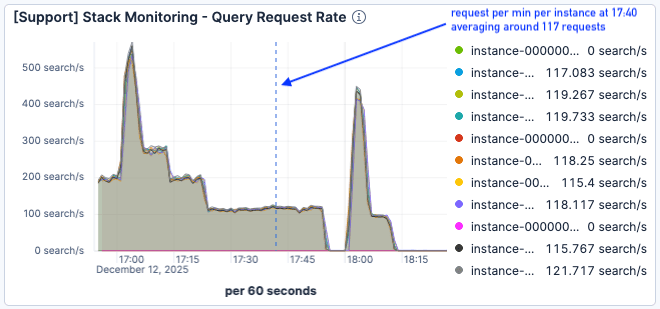
Figura 6. O teste de carga começou por volta das 17h.
Apesar da maior carga, a utilização da CPU foi menor do que na execução anterior. O uso elevado no teste anterior provavelmente se deveu à sobrecarga do tratamento excessivo de falhas de página e gerenciamento de E/S de disco.
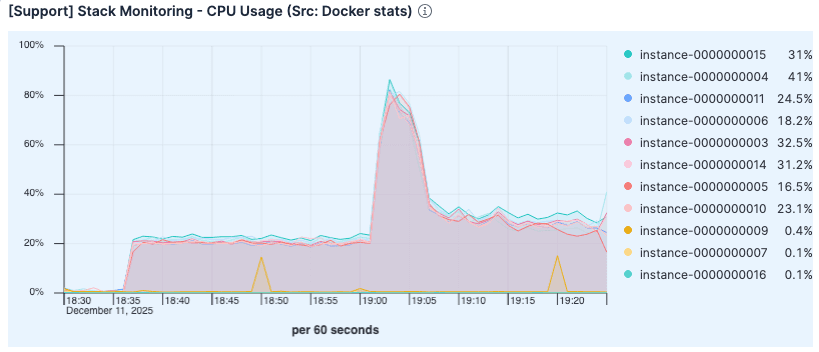
Figura 7. A utilização da CPU foi menor do que na execução anterior.
Crucialmente, as falhas de página caíram significativamente. Mesmo em maior débito, as falhas ficaram em torno de <200 mil por minuto, comparado a >300 mil no teste inicial.
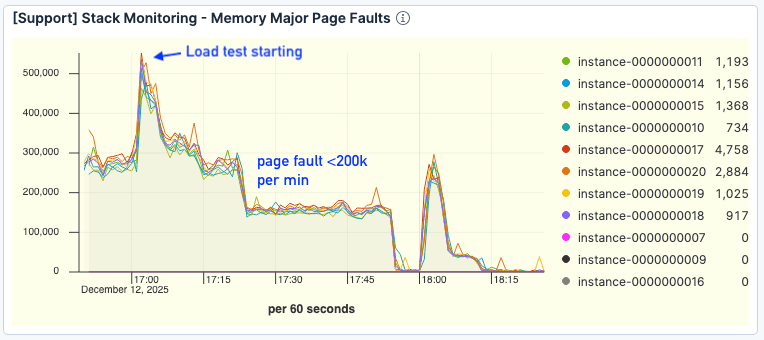
Figura 8. O número de falhas de página teve uma melhora significativa.
Embora os resultados de falha na página ainda não tenham sido ideais, o tempo de serviço de consulta foi reduzido em cerca de 50%, pairando abaixo de 30 ms, mesmo sob carga mais pesada.
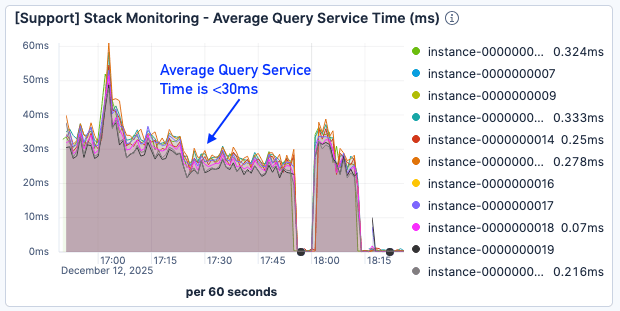
Figura 9. O tempo médio de serviço de consulta foi <30ms.
A conclusão: best_compression para busca
Para casos de uso de busca em que o volume de dados excede a memória física disponível, best_compression é uma poderosa alavanca de ajuste de desempenho.
A solução convencional para falhas de cache é redimensionar para aumentar a RAM. No entanto, ao reduzir a pegada do índice, alcançamos o mesmo objetivo: maximizar a contagem de documentos no cache da página. Nosso próximo passo é explorar a classificação de índices para otimizar ainda mais o armazenamento e extrair ainda mais desempenho de nossos recursos existentes.
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

26 de março de 2026
Apresentando permissões de somente leitura para dashboards do Kibana
Apresentamos dashboards de somente leitura no Kibana, oferecendo aos criadores de dashboards controles detalhados de compartilhamento para manter os resultados precisos e protegidos contra alterações indesejadas.
2 de março de 2026
Terminação adaptativa precoce para HNSW no Elasticsearch
Introdução de uma nova estratégia adaptativa de terminação antecipada para HNSW no Elasticsearch.

11 de dezembro de 2025
Avaliação da relevância de consultas de pesquisa com listas de julgamento
Saiba como criar listas de julgamento para avaliar objetivamente a relevância das consultas de pesquisa e melhorar métricas de desempenho, como recall, para testes de buscas escaláveis no Elasticsearch.

11 de novembro de 2025
Configurando o particionamento recursivo para documentos estruturados no Elasticsearch
Aprenda como configurar o particionamento recursivo no Elasticsearch com tamanho de partição, grupos de separadores e listas de separadores personalizadas para indexação ideal de documentos estruturados.