동시성이 높은 워크로드에 맞게 Elasticsearch를 조정할 때 일반적인 접근 방식은 검색 지연 시간을 줄이기 위해 작업 문서 세트를 메모리에 유지하도록 RAM을 최대화하는 것입니다. 따라서 best_compression 은(는) 주로 저장 공간 효율성이 우선시되는 Elastic Observability와 Elastic Security 사용 사례에서 저장 공간 절약 수단으로 간주되며, 검색 워크로드에는 거의 고려되지 않습니다.
이 블로그에서는 데이터 세트 크기가 OS 페이지 캐시를 크게 초과하는 경우, best_compression 이(가) I/O 병목 현상을 줄여 검색 성능과 리소스 효율성을 개선하는 방법을 보여줍니다.
설정
해당 사용 사례는 Elastic Cloud CPU에 최적화된 인스턴스에서 실행되는 동시성이 높은 검색 애플리케이션입니다.
- 데이터 볼륨: 약 5억 개의 문서
- 인프라: 6개의 Elastic Cloud(Elasticsearch Service) 인스턴스(각 인스턴스: 1.76TB 저장 공간 | 60GB RAM | 31.9 vCPU)
- 메모리 대 저장 공간 비율: 전체 데이터 세트의 약 5%를 RAM에 저장
증상: 긴 지연 시간
19시경에 현재 요청 수가 급증할 때 검색 지연 시간이 크게 악화되는 것을 확인했습니다. 그림 1과 그림 2에서 볼 수 있듯이, Elasticsearch 인스턴스당 분당 약 400건의 요청이 발생하는 최고 트래픽 수준에서 평균 쿼리 서비스 시간은 60ms 이상으로 저하되었습니다.
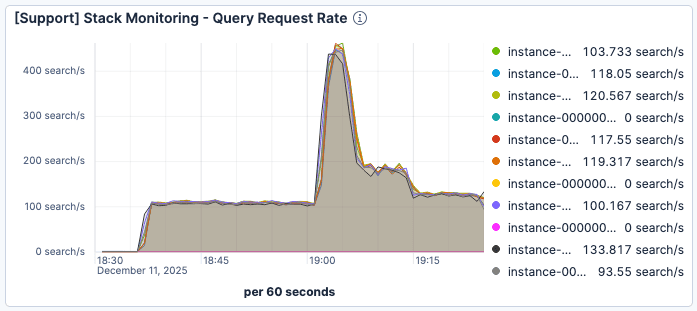
그림 1. Elasticsearch 인스턴스당 분당 요청 수는 19시 직후 약 400건으로 최고치를 기록했습니다.
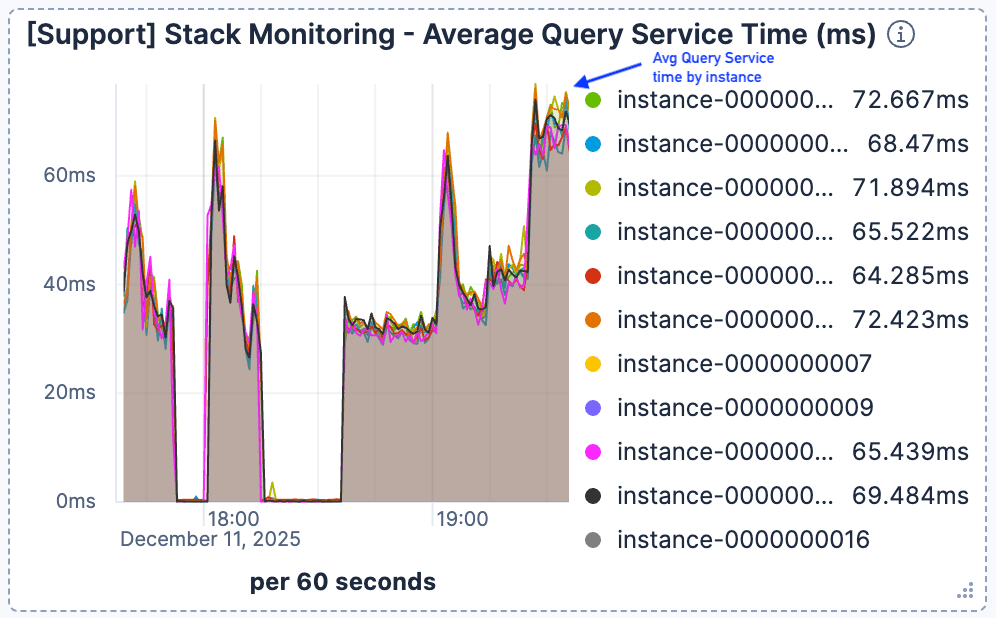
그림 2. 평균 쿼리 서비스 시간이 급증하기 시작하여 60ms 이상으로 상승한 후 그 수준을 유지했습니다.
초기 연결 처리 이후 CPU 사용량은 비교적 낮은 수준을 유지했는데, 이는 컴퓨팅이 병목 현상이 아님을 나타냅니다.
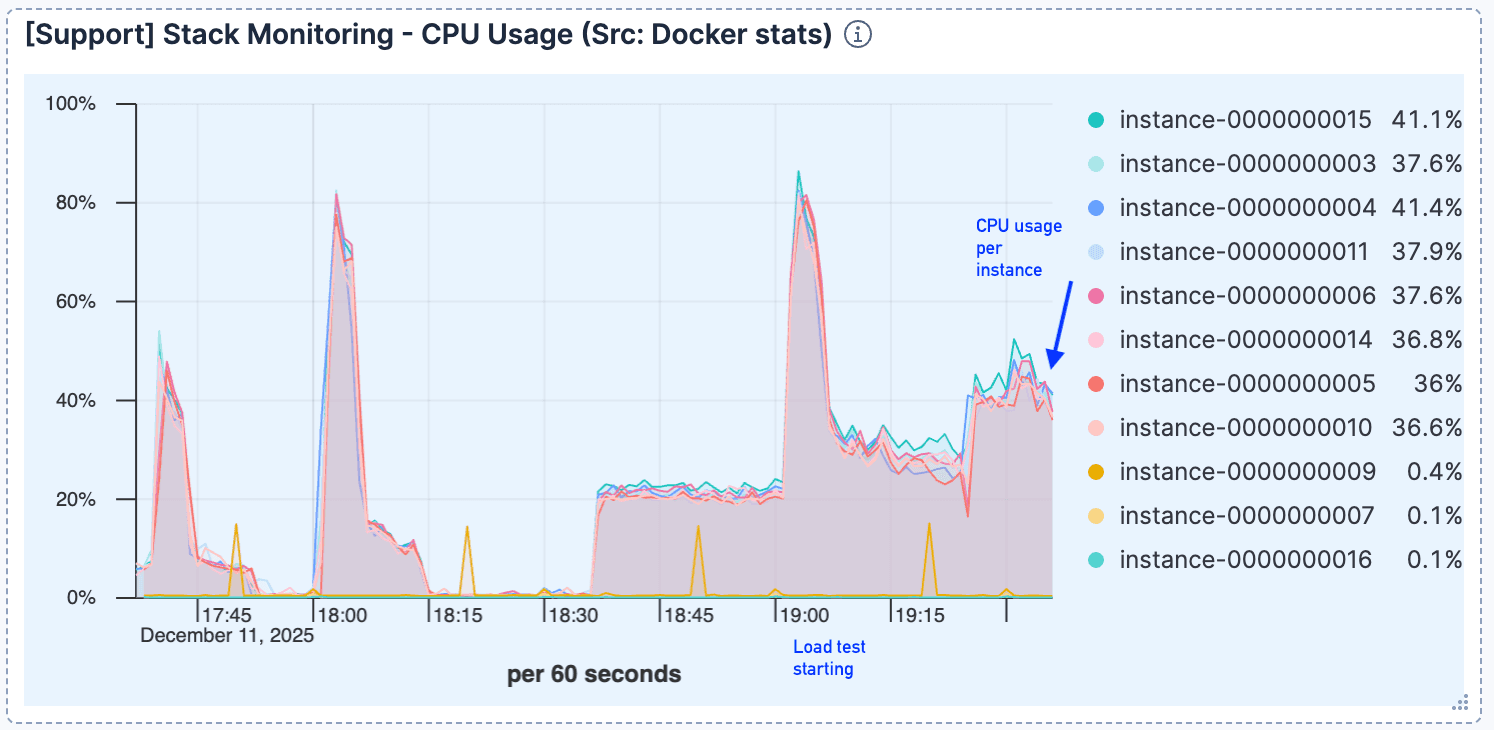
그림 3. 초기 사용량 급증 이후에는 CPU 사용량이 비교적 낮은 수준을 유지합니다.
쿼리 볼륨과 페이지 오류 사이에 강한 상관관계가 나타났습니다. 요청량이 증가함에 따라 페이지 오류도 비례적으로 증가하여 분당 약 40만 건에 달하는 최고치를 기록했습니다. 이는 활성 데이터 세트가 페이지 캐시에 저장될 수 없음을 의미합니다.
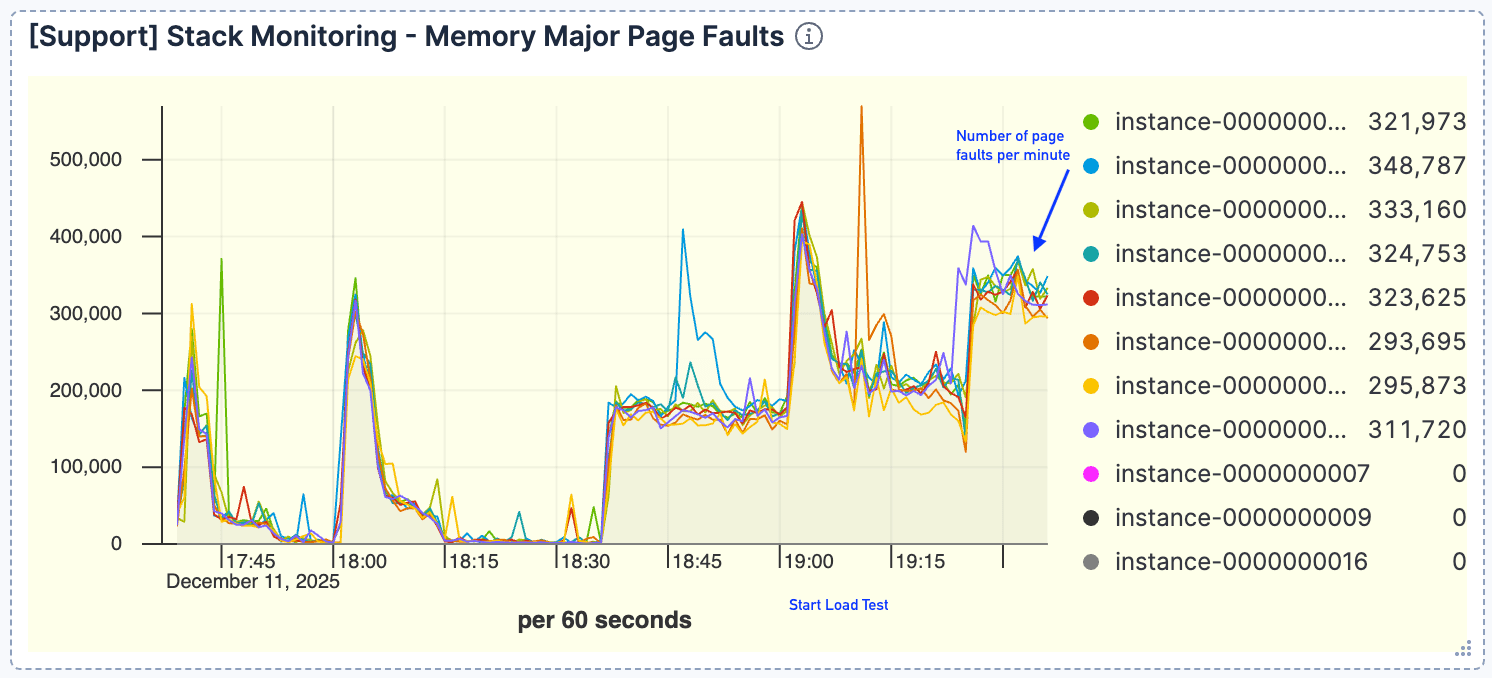
그림 4. 페이지 오류 수가 높았으며, 분당 약 40만 건으로 최고치를 기록했습니다.
동시에 JVM 힙 사용량은 정상적인 수준을 보였습니다. 이는 가비지 컬렉션 문제가 아님을 시사하며, 병목 현상이 I/O에 있음을 확인시켜 줍니다.
그림 5. 힙 사용량은 변동 없이 유지되었습니다.
진단: I/O 바운드
시스템이 I/O 바운드 상태였습니다. Elasticsearch는 OS 페이지 캐시를 활용하여 메모리에서 인덱스 데이터를 제공합니다. 인덱스가 캐시에 비해 너무 크면 쿼리는 값비싼 디스크 읽기를 트리거합니다. 일반적인 해결책은 수평적 확장(노드/RAM 추가)이지만, 먼저 기존 리소스를 활용하여 효율성을 개선하고자 했습니다.
수정 사항
기본적으로 Elasticsearch는 인덱스 세그먼트에 LZ4 압축을 사용하여 속도와 크기 사이의 균형을 유지합니다. best_compression ( zstd 방식 사용)로 전환하면 인덱스 크기가 줄어들 것이라는 가설을 세웠습니다. 설치 공간이 작아지면 페이지 캐시에 더 많은 비율의 인덱스가 들어갈 수 있으므로 압축 해제에 필요한 CPU 사용량의 미미한 증가와 디스크 I/O의 감소를 맞바꿀 수 있습니다.
best_compression 을(를) 활성화하기 위해 인덱스 설정 index.codec: best_compression (으)로 데이터를 다시 색인했습니다. 또는 인덱스를 닫고 인덱스 코덱을 best_compression (으)로 재설정한 다음 세그먼트 병합을 수행해도 동일한 결과를 얻을 수 있습니다.
결과
결과는 가설을 뒷받침했습니다. 저장 공간 효율성 개선은 CPU 사용률의 증가 없이 검색 성능의 상당한 향상으로 직결되었습니다.
best_compression 을(를) 적용함으로써 인덱스 크기가 약 25% 감소했습니다. 반복적인 로그 데이터에서 나타난 감소율보다는 낮지만, 이 25% 감소는 페이지 캐시 용량을 동일한 수준으로 실질적으로 증가시켰습니다.
다음 로드 테스트(17시 시작) 동안 트래픽은 훨씬 더 높아져 Elasticsearch 노드당 분당 최대 500건의 요청을 기록했습니다.
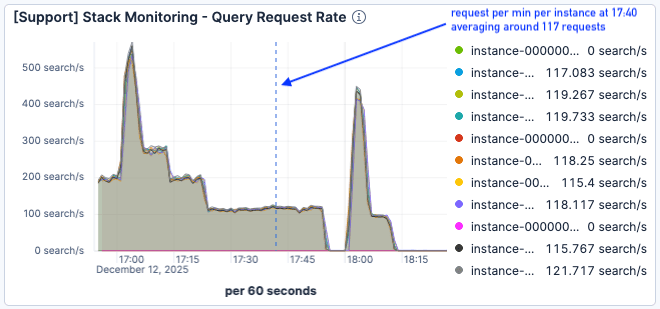
그림 6. 로드 테스트는 17시경에 시작되었습니다.
로드가 높아졌음에도 CPU 사용률은 이전 실행보다 낮았습니다. 이전 테스트에서 사용률이 높았던 것은 과도한 페이지 오류 처리 및 디스크 I/O 관리로 인한 오버헤드 때문이었을 가능성이 큽니다.
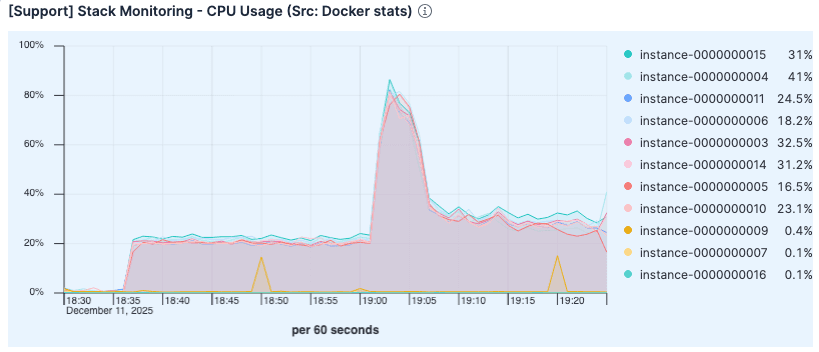
그림 7입니다. CPU 사용률이 이전 실행보다 낮았습니다.
결정적으로 페이지 오류가 많이 감소했습니다. 처리량이 높아진 상황에서도 오류 수는 분당 20만 건 미만으로, 기준 테스트의 30만 건 이상에 비해 현저히 줄어들었습니다.
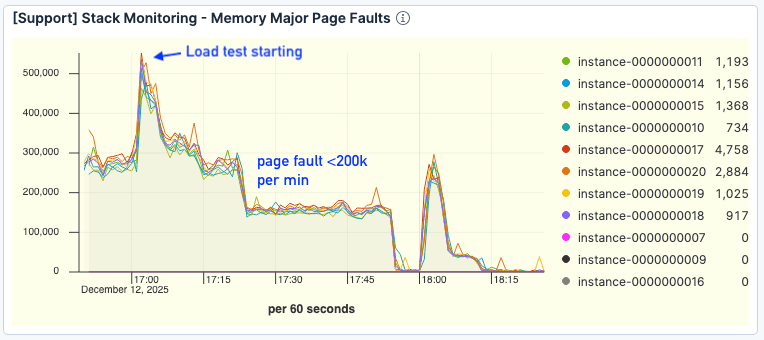
그림 8. 페이지 오류 수가 크게 개선되었습니다.
페이지 오류 결과는 여전히 최적에 미치지 못했지만, 쿼리 서비스 시간은 약 50% 단축되었습니다. 로드가 많은 상황에서도 30ms 미만으로 유지되었습니다.
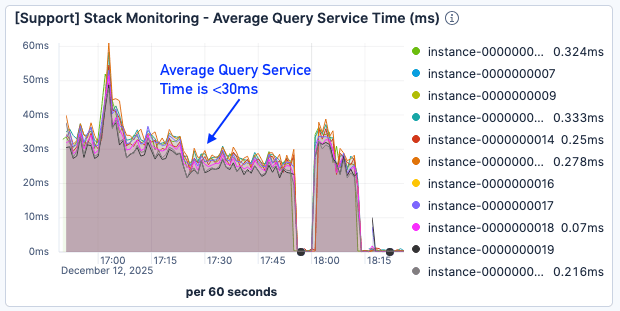
그림 9. 평균 쿼리 서비스 시간이 30ms 미만입니다.
결론: 검색을 위한 best_compression
데이터 볼륨이 사용 가능한 물리적 메모리를 초과하는 검색 사용 사례에서 best_compression은(는) 강력한 성능 조정 수단입니다.
캐시 미스를 해결하는 일반적인 해결책은 RAM을 늘려 확장하는 것입니다. 하지만 인덱스 공간을 줄임으로써 페이지 캐시의 문서 수를 최대화하는 동일한 목표를 달성했습니다. 다음 단계에서는 인덱스 정렬을 통해 저장 공간 최적화를 더 강화하고 기존 리소스에서 성능을 극대화할 것입니다.
관련 콘텐츠

2026년 4월 23일
세계에서 가장 빠른 벡터 검색을 위해 Elasticsearch simdvec을 구축한 방법
Elasticsearch의 모든 벡터 검색 쿼리 뒤에 있는 수동 조정 SIMD 커널 라이브러리인 Elasticsearch simdvec을 어떻게 구축했는지 알아보세요.

2026년 3월 26일
Kibana 대시보드 읽기 전용 권한 출시 안내
Kibana에 읽기 전용 대시보드 기능이 도입되었습니다. 이제 대시보드 작성자는 세분화된 공유 제어 기능을 통해 분석 결과의 정확성을 유지하고 의도치 않은 변경으로부터 데이터를 안전하게 보호할 수 있습니다.

2025년 12월 11일
판단 목록을 사용하여 검색 쿼리의 관련성을 평가합니다.
Elasticsearch에서 확장 가능한 검색 테스트를 위해 검색 쿼리 관련성을 객관적으로 평가하고 리콜과 같은 성능 메트릭을 개선하기 위해 판단 목록을 구축하는 방법을 살펴보세요.

2025년 11월 11일
Elasticsearch에서 구조화된 문서에 대한 재귀 청크 구성하기
최적의 구조화된 문서 색인을 위해 청크 크기, 구분자 그룹, 사용자 정의 구분자 목록을 사용하여 Elasticsearch에서 재귀적 청크를 구성하는 방법을 알아보세요.