Depuis la version 8.16, les utilisateurs peuvent configurer la stratégie de découpage utilisée lors de l'ingestion de longs documents dans des champs de texte sémantique. Depuis la version 9.1 / 8.19, nous avons introduit une nouvelle stratégie de découpage récursif configurable qui utilise une liste d'expressions régulières pour découper le document. L'objectif du découpage en morceaux est de diviser un long document en sections qui encapsulent un contenu apparenté. Nos stratégies existantes permettent de diviser le texte selon une granularité de mots/phrases, mais les documents écrits dans des formats structurés (ex. Markdown) contiennent souvent des contenus connexes dans des sections définies par des chaînes de séparation (ex. ). Pour ces types de documents, nous introduisons la stratégie de découpage récursif afin d'exploiter le format des documents structurés pour créer de meilleurs morceaux !
Qu'est-ce que le découpage récursif ?
Le découpage récursif parcourt une liste de sections fournies en séparant les modèles afin de diviser progressivement un document en segments plus petits jusqu'à ce qu'ils atteignent une taille maximale souhaitée.
Comment configurer le découpage récursif ?
Les valeurs configurables fournies par l'utilisateur pour le découpage récursif sont les suivantes :
- (obligatoire)
max_chunk_size: Le nombre maximum de mots dans un bloc. - L'un ou l'autre :
separators: Une liste de motifs de chaînes regex qui seront utilisés pour découper le document en morceaux.separator_group: Une chaîne qui correspondra à une liste par défaut de séparateurs définis par Elastic à utiliser pour des types de documents spécifiques. Actuellement,markdownetplaintextsont disponibles.
Comment fonctionne le découpage récursif ?
Le processus de découpage récursif d'un document d'entrée, d'un max_chunk_size (mesuré en mots) et d'une liste de chaînes de séparation est le suivant :
- Si le document d'entrée est déjà compris dans la taille maximale des morceaux, il renvoie un seul morceau couvrant l'ensemble du document d'entrée.
- Découper le texte en morceaux potentiels sur la base des occurrences du séparateur. Pour chaque morceau potentiel :
- Si le morceau potentiel ne dépasse pas la taille maximale, il est ajouté à la liste des morceaux à renvoyer à l'utilisateur.
- Sinon, répétez l'étape 2, en utilisant uniquement le texte du morceau potentiel et en le séparant à l'aide du séparateur suivant dans la liste. S'il n'y a plus de séparateurs à essayer, il faut se rabattre sur le découpage en phrases.
Exemples de configuration du découpage récursif
Outre la taille des morceaux, la principale configuration du découpage récursif consiste à sélectionner les séparateurs à utiliser pour diviser vos documents. Si vous ne savez pas par où commencer, Elasticsearch propose quelques groupes de séparateurs par défaut qui peuvent être utilisés pour des cas d'utilisation courants.
Utilisation de groupes de séparation
Pour utiliser un groupe séparateur, il suffit d'indiquer le nom du groupe que vous souhaitez utiliser lors de la configuration des paramètres de regroupement. Par exemple :
Vous obtiendrez ainsi une stratégie de découpage récursif qui utilise la liste de séparateurs ["(?<!\\n)\\n\\n(?!\\n)", "(?<!\\n)\\n(?!\\n)")]. Cela fonctionne bien pour les applications génériques de texte brut, en séparant deux caractères de retour à la ligne, suivis d'un caractère de retour à la ligne.
Nous proposons également un groupe de séparateurs markdown qui utilisera la liste des séparateurs :
Cette liste de séparateurs fonctionnera bien pour les cas d'utilisation généraux de markdown, en séparant chacun des 6 niveaux d'en-tête et les caractères de coupure de section.
Lors de la création d'une ressource (point d'inférence/champ textuel sémantique), la liste des séparateurs correspondant au groupe de séparateurs du moment sera stockée dans vos configurations. Si le groupe de séparateurs est mis à jour ultérieurement, cela ne modifiera pas le comportement des ressources déjà créées.
Utilisation d'une liste de séparateurs personnalisée
Si l'un des groupes de séparateurs prédéfinis ne convient pas à votre cas d'utilisation, vous pouvez définir une liste personnalisée de séparateurs répondant à vos besoins. Notez que des expressions régulières peuvent être fournies dans la liste des séparateurs. Voici un exemple de paramètres de regroupement configurés avec des séparateurs personnalisés :
La stratégie de découpage en morceaux découpera 2 caractères de nouvelle ligne, suivis d'un caractère de nouvelle ligne, et enfin une chaîne de caractères “<my-custom-separator>”.
Un exemple de découpage récursif en action
Voyons un exemple de découpage récursif en action. Pour cet exemple, nous utiliserons les paramètres de découpage suivants avec une liste personnalisée de séparateurs qui découpent un document markdown en utilisant les deux premiers niveaux d'en-tête :
Examinons un simple document Markdown non tronqué :

Utilisons maintenant les paramètres de découpage définis ci-dessus pour découper le document en morceaux :
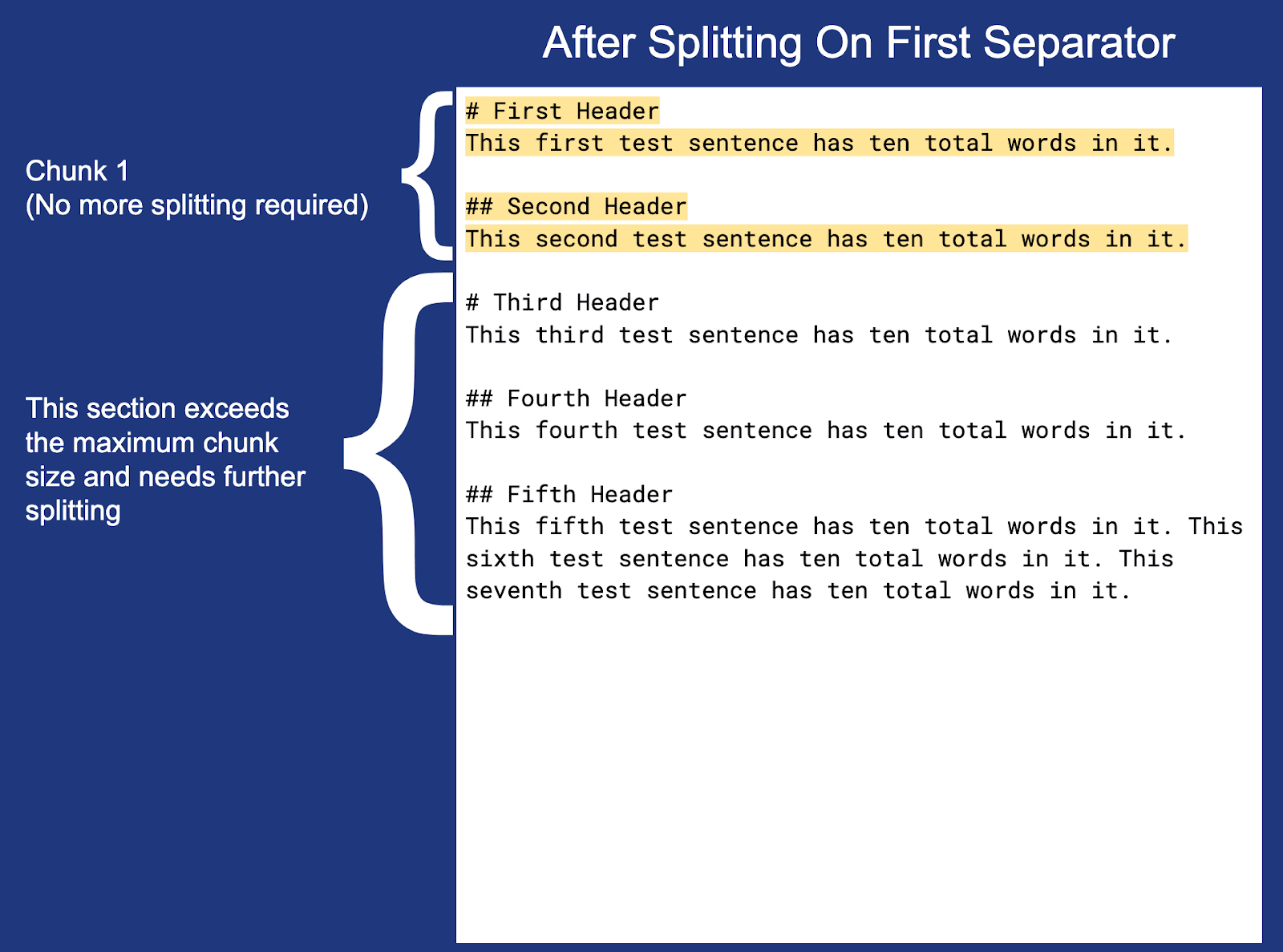

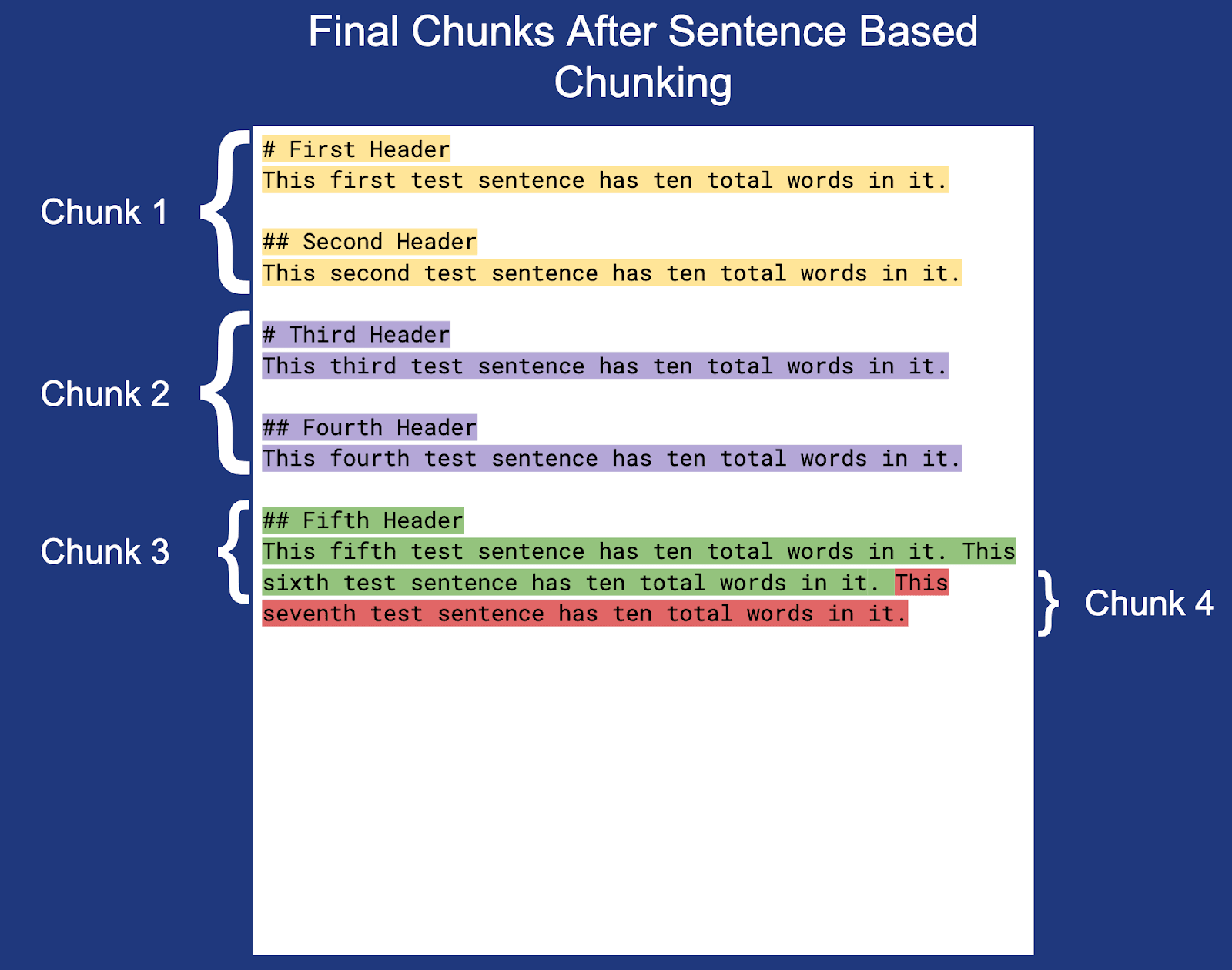
Remarque : la nouvelle ligne à la fin de chaque morceau (à l'exception du morceau 3) n'est pas mise en évidence, mais elle est incluse dans les limites du morceau.
Commencez dès aujourd'hui à utiliser le découpage récursif !
Pour plus d'informations sur l'utilisation de cette fonctionnalité, consultez la documentation sur la configuration des paramètres de regroupement.
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

26 mars 2026
Annonce des autorisations en lecture seule pour les tableaux de bord Kibana
Présentation des tableaux de bord en lecture seule dans Kibana, offrant aux créateurs de tableaux de bord des contrôles de partage détaillés pour garantir l'exactitude des résultats et les protéger contre les modifications indésirables.

13 mars 2026
Résolution d'entités avec Elasticsearch, partie 4 : le défi ultime
Relever et évaluer les problématiques de réconciliation d’entités dans un ensemble de données complexe et varié, dont la structure interdit l’usage de méthodes simplifiées ou de contournements.
2 mars 2026
Arrêt précoce adaptatif pour HNSW dans Elasticsearch
Présentation d'une nouvelle stratégie adaptative d'arrêt précoce pour HNSW dans Elasticsearch.