De busca vetorial a poderosas APIs REST, o Elasticsearch oferece aos desenvolvedores o kit de ferramentas de busca mais completo. Confira nossos notebooks de amostra no repositório Elasticsearch Labs para experimentar algo novo. Você também pode começar uma avaliação gratuita ou executar o Elasticsearch localmente hoje mesmo.
TLDR: o Elasticsearch é até 12x mais rápido - Nós, da Elastic, recebemos inúmeras solicitações da nossa comunidade para esclarecer as diferenças de desempenho entre o Elasticsearch e o OpenSearch, particularmente no reinos da busca semântica / busca vetorial. Por isso, realizamos esse teste de desempenho para fornecer uma comparação clara e orientada por dados — sem ambiguidade, apenas fatos diretos para informar nossos usuários. Os resultados mostram que o Elasticsearch é até 12x mais rápido do que o OpenSearch para busca vetorial e, portanto, requer menos recursos computacionais. Isso reflete o foco da Elastic em consolidar o Lucene como o melhor banco de dados vetorial para casos de uso de busca e recuperação.
A busca vetorial está revolucionando a maneira como realizamos buscas de similaridade, principalmente em campos como IA e machine learning. Com a crescente adoção de modelos de incorporação vetorial, a capacidade de buscar com eficiência milhões de vetores de alta dimensão torna-se crítica.
Quando se trata de melhorar bancos de dados vetoriais, a Elastic e o OpenSearch adotaram abordagens notavelmente diferentes. A Elastic investiu muito na otimização do Apache Lucene junto com o Elasticsearch para elevá-los como a melhor opção para aplicações de busca vetorial. Em contraste, o OpenSearch ampliou seu foco, integrando outras implementações de busca vetorial e explorando além do escopo do Lucene. Nosso foco no Lucene é estratégico, permitindo-nos fornecer suporte altamente integrado na nossa versão do Elasticsearch, resultando em um conjunto aprimorado de recursos em que cada componente complementa e amplifica as capacidades do outro.
Este blog apresenta uma comparação detalhada entre o Elasticsearch 8.14 e o OpenSearch 2.14, levando em conta diferentes configurações e motores vetoriais. Nesta análise de desempenho, o Elasticsearch provou ser a plataforma superior para operações de busca vetorial, e os próximos recursos ampliarão as diferenças ainda mais significativamente. Quando comparado com o OpenSearch, ele se destacou em todas as faixas de benchmark — oferecendo desempenho de 2x a 12x mais rápido em média. Isso ocorreu em situações que usam quantidades e dimensões vetoriais variadas, incluindo so_vector (2 milhões de vetores, 768D), openai_vector (2,5 milhões de vetores, 1536D) e dense_vector (10 milhões de vetores, 96D), todos disponíveis neste repositório junto com os scripts do Terraform para provisão de toda a infraestrutura necessária nos manifestos do Google Cloud e do Kubernetes para executar os testes.
Os resultados detalhados neste blog complementam os resultados de um estudo publicado antes e validado por terceiros que mostra que o Elasticsearch é 40%–140% mais rápido do que o OpenSearch nas operações de análise de busca mais comuns: consulta de texto, ordenação, intervalo, histograma de data e filtro de termos. Agora podemos adicionar outro diferenciador: busca vetorial.
Até 12x mais rápido, pronto para uso
Nossos benchmarks focados nos quatro conjuntos de dados vetoriais envolveram buscas de KNN aproximado e KNN exato, considerando diferentes tamanhos, dimensões e configurações, totalizando 40.189.820 solicitações de busca não armazenadas em cache. Os resultados: o Elasticsearch é até 12 vezes mais rápido do que o OpenSearch para busca vetorial e, portanto, requer menos recursos computacionais.

Figura 1: Tarefas agrupadas para ANN e KNN Exato em diferentes combinações no Elasticsearch e OpenSearch.
Os grupos como knn-10-100 significam uma busca KNN com e . Na busca vetorial HNSW, determina o número de vizinhos mais próximos a serem recuperados para um vetor de consulta. Especifica quantos vetores semelhantes devem ser encontrados como resultado. define o número de vetores candidatos a serem recuperados em cada segmento. Mais candidatos podem melhorar a precisão, mas exigem maiores recursos computacionais.
Também testamos com diferentes técnicas de quantização e aproveitamos otimizações específicas do mecanismo; os resultados detalhados para cada trilha, tarefa e mecanismo de vetor estão disponíveis abaixo.
KNN exato e KNN aproximado
Ao lidar com conjuntos de dados e casos de uso variados, a abordagem correta para busca vetorial será diferente. Neste blog, todas as tarefas declaradas como knn-* como knn-10-100 usam KNN aproximado e script-score-* se referem ao KNN exato, mas qual é a diferença entre elas e por que são importantes?
Em essência, se você estiver lidando com conjuntos de dados mais substanciais, o método preferido é o Approximate K-Nearest Neighbor (ANN) devido à escalabilidade superior. Para conjuntos de dados mais modestos que podem exigir um processo de filtragem, o método Exact K-Nearest Neighbor (KNN) é ideal.
O KNN exato utiliza um método de força bruta, calculando a distância entre um vetor e todos os outros vetores no conjunto de dados. Em seguida, classifica essas distâncias para encontrar os vizinhos mais próximos. Embora esse método garanta uma correspondência exata, ele enfrenta desafios de escalabilidade para conjuntos de dados grandes e de alta dimensão. No entanto, há muitos casos em que o KNN exato é necessário:
- Reclassificação: em casos que envolvem buscas lexicais ou semânticas seguidas de reclassificação baseada em vetores, o KNN exato é essencial. Por exemplo, em um mecanismo de busca de produtos, os resultados de busca iniciais podem ser filtrados com base em consultas textuais (por exemplo, palavras-chave, categorias) e, em seguida, os vetores associados aos itens filtrados são usados para uma avaliação de similaridade mais precisa.
- Personalização: ao lidar com um grande número de usuários, cada um representado por um número relativamente pequeno (como 1 milhão) de vetores distintos, a ordenação do índice por metadados específicos do usuário (por exemplo, user_id) e a pontuação de força bruta com vetores torna-se eficiente. Essa abordagem permite recomendações personalizadas ou entrega de conteúdo com base em comparações precisas de vetores adaptadas às preferências individuais do usuário.
O Exact KNN, portanto, garante que a classificação final e as recomendações baseadas na similaridade vetorial sejam precisas e adaptadas às preferências do usuário.
O KNN aproximado (ou ANN), por outro lado, utiliza métodos para deixar a busca de dados mais rápida e eficiente do que o KNN exato, principalmente em conjuntos de dados grandes e de alta dimensão. Em vez de uma abordagem de força bruta, que mede a distância exata mais próxima entre uma consulta e todos os pontos, gerando desafios de computação e redimensionamento, a ANN utiliza certas técnicas para reestruturar eficientemente os índices e as dimensões dos vetores buscáveis no conjunto de dados. Embora isso possa causar uma pequena imprecisão, aumenta significativamente a velocidade do processo de busca, sendo uma alternativa eficaz para lidar com grandes conjuntos de dados.
Neste blog, todas as tarefas declaradas como knn-*, como knn-10-100, usam KNN aproximado e script-score-* referem-se a KNN exato.
Metodologia de teste
Embora o Elasticsearch e o OpenSearch sejam semelhantes em termos de API para operações de busca do BM25, já que o último é uma bifurcação do primeiro, não é o caso do Vector Search, que foi introduzido após o fork. O OpenSearch adotou uma abordagem diferente do Elasticsearch quando se trata de algoritmos, introduzindo dois outros mecanismos — nmslib e faiss — além do lucene, cada um com configurações e limitações específicas (por exemplo, nmslib no OpenSearch não permite filtros, um recurso essencial para muitos casos de uso).
Todos os três mecanismos usam o algoritmo Hierarchical Navigable Small World (HNSW), que é eficiente para busca aproximada do vizinho mais próximo e principalmente poderoso ao lidar com dados de alta dimensão. É importante observar que o faiss também aceita um segundo algoritmo, ivf, mas como ele requer pré-treinamento no conjunto de dados, vamos nos concentrar exclusivamente no HNSW. A ideia de núcleo do HNSW é organizar os dados em várias camadas de gráficos conectados, com cada camada representando uma granularidade diferente do conjunto de dados. A busca começa na camada superior com a visualização mais grosseira e avança para camadas cada vez mais finas até chegar ao nível básico.
Ambos os mecanismos de busca foram testados sob condições idênticas em um ambiente controlado para garantir condições de teste justas. O método aplicado é semelhante a esta comparação de desempenho já publicada, com pools de node dedicados para Elasticsearch, OpenSearch e Rally. O script terraform está disponível (junto com todas as fontes) para fazer a provisão de um cluster Kubernetes com:
- 1 Node pool para Elasticsearch com 3 máquinas
e2-standard-32(128 GB de RAM e 32 CPUs) - 1 Node pool para OpenSearch com 3 máquinas
e2-standard-32(128 GB de RAM e 32 CPUs) - 1 Node pool para Rally com 2
t2a-standard-16máquinas (64GB de RAM e 16 CPUs)
Cada "trilha" (ou teste) foi executada 10 vezes em cada configuração, que incluía diferentes motores, diferentes configurações e diferentes tipos de vetor. As trilhas têm tarefas que se repetem entre 1.000 e 10.000 vezes, dependendo da trilha. Se uma das tarefas em uma trilha falhou, por exemplo, devido a um tempo-limite de rede, então todas as tarefas foram descartadas, de modo que todos os resultados representam trilhas que começaram e terminaram sem problemas. Todos os resultados dos testes são validados estatisticamente, garantindo que as melhorias não sejam coincidência.
Resultados detalhados
Por que comparar usando o 99º percentil e não a latência média? Considere um exemplo hipotético de preços médios de casas em um determinado bairro. O preço médio pode indicar uma área cara, mas, em uma inspeção mais detalhada, pode ser que a maioria das casas tenha um valor muito mais baixo, com apenas algumas propriedades de luxo inflando o valor médio. Isso ilustra como o preço médio pode não representar com precisão todo o espectro de valores das casas na área. Isso é semelhante a examinar os tempos de resposta, onde a média pode ocultar problemas críticos.
Tarefas
- KNN aproximado com k:10 n:50
- KNN Aproximado com k:10 n:100
- KNN aproximado com k:100 n:1000
- KNN aproximado com k:10 n:50 e filtros de palavras-chave
- KNN aproximado com k:10 n:100 e filtros de palavras-chave
- KNN aproximado com k:100 n:1000 e filtros de palavras-chave
- KNN aproximado com k:10 n:100 em conjunto com indexação
- KNN exato (pontuação do script)
Motores vetoriais
luceneno Elasticsearch e OpenSearch, ambos na versão 9.10faissno OpenSearchnmslibno OpenSearch
Tipos de vetor
hnswno Elasticsearch e OpenSearchint8_hnswno Elasticsearch (HNSW com quantização automática de 8 bits: link)sq_fp16 hnswno OpenSearch (HNSW com quantização automática de 16 bits: link)
Busca de segmento simultânea e pronta para uso
Como você provavelmente sabe, o Lucene é uma biblioteca de mecanismo de busca de texto de alto desempenho escrita em Java que serve como espinha dorsal para muitas plataformas de busca, como Elasticsearch, OpenSearch e Solr. No núcleo, o Lucene organiza os dados em segmentos, que são essencialmente índices independentes que permitem ao Lucene executar buscas com mais eficiência. Portanto, quando você emite uma busca para qualquer mecanismo de busca baseado em Lucene, sua busca acabará sendo executada nesses segmentos, sequencialmente ou em paralelo.
O OpenSearch introduziu a busca simultânea por segmentos como uma opção e não a utiliza como padrão. Você deve habilitá-la usando uma configuração especial de índice index.search.concurrent_segment_search.enabled conforme detalhado aqui, com algumas limitações.
O Elasticsearch, por outro lado, busca em segmentos simultaneamente prontos para uso; portanto, as comparações que fazemos neste blog levarão em consideração, além dos diferentes mecanismos vetoriais e tipos de vetores, também as diferentes configurações:
- Elasticsearch ootb: Elasticsearch pronto para uso, com busca de segmento simultânea;
- OpenSearch ootb: sem busca de segmento simultânea habilitada;
- OpenSearch css: com busca de segmento simultânea habilitada
Agora vamos nos aprofundar em alguns resultados detalhados para cada conjunto de dados vetoriais testado:
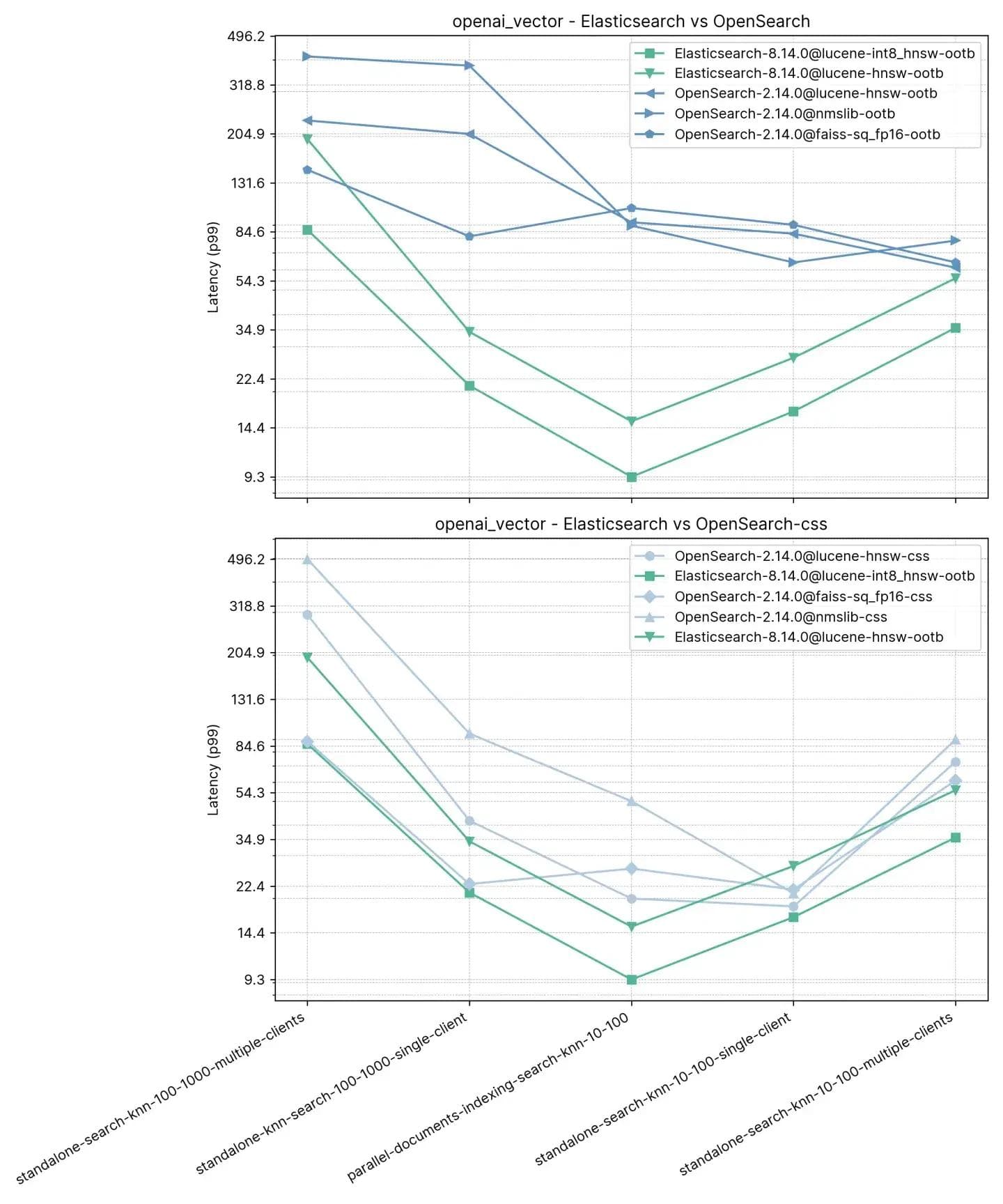
2,5 milhões de vetores, 1536 dimensões (openai_vector)
Começando com a faixa mais simples, mas também a maior em termos de dimensões, openai_vector - que usa o conjunto de dados NQ enriquecido com embeddings gerados usando o modelo text-embedding-ada-002 do OpenAI. É o mais simples, pois testa apenas o KNN aproximado e tem apenas 5 tarefas. Ele testa de forma autônoma (sem indexação) e junto com a indexação, usando um único cliente e 8 clientes simultâneos.
Tarefas
- standalone-search-knn-10-100-multiple-clients: buscando em 2,5 milhões de vetores com 8 clientes simultaneamente, k: 10 e n:100
- standalone-search-knn-100-1000-multiple-clients: buscando em 2,5 milhões de vetores com 8 clientes simultaneamente, k: 100 e n:1000
- standalone-search-knn-10-100-single-client: buscando em 2,5 milhões de vetores com um único cliente, k: 10 e n:100
- standalone-search-knn-100-1000-single-client: buscando em 2,5 milhões de vetores com um único cliente, k: 100 e n:1000
- parallel-documents-indexing-search-knn-10-100: buscando em 2,5 milhões de vetores e, ao mesmo tempo, indexando 100.000 documentos adicionais, k:10 e n:100
O desempenho médio do p99 é descrito abaixo:

Aqui, observamos que o Elasticsearch é entre 3x-8x mais rápido do que o OpenSearch ao realizar a busca vetorial junto com a indexação (i.e. leitura+escrita) com :10 e :100 e 2x-3x mais rápido sem indexação para os mesmos k e n. Para :100 e :1000 (standalone-search-knn-100-1000-single-client e standalone-search-knn-100-1000-multiple-clients ), o Elasticsearch é 2x a 7x mais rápido que o OpenSearch, em média.
Os resultados detalhados mostram os casos exatos e os mecanismos vetoriais comparados:
Recall
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0,969485 | 0,995138 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0,781445 | 0,784817 |
| OpenSearch-2.14.0@lucene-hnsw | 0,96519 | 0,995422 |
| OpenSearch-2.14.0@faiss | 0,984154 | 0,98049 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0,980012 | 0,97721 |
| OpenSearch-2.14.0@nmslib | 0,982532 | 0,99832 |
10 milhões de vetores, 96 dimensões (dense_vector)
Em dense_vector com 10 milhões de vetores e 96 dimensões. Ele é baseado no conjunto de dados de imagens Yandex DEEP1B. O conjunto de dados é criado a partir dos primeiros 10 milhões de vetores do arquivo "sample data" chamado learn.350M.fbin. As operações de busca usam vetores da consulta do arquivo "query data".public.10K.fbin.
Tanto o Elasticsearch quanto o OpenSearch têm um desempenho muito bom nesse conjunto de dados, principalmente após uma fusão forçada, que geralmente é feita em índices somente leitura e é semelhante à desfragmentação do índice para ter uma única "tabela" para buscas.
Tarefas
Cada tarefa é aquecida para 100 solicitações e, em seguida, 1.000 solicitações são medidas
- knn-search-10-100: buscando em 10 milhões de vetores, k: 10 e n:100
- knn-search-100-1000: buscando em 10 milhões de vetores, k: 100 e n:1000
- knn-search-10-100-force-merge: buscando em 10 milhões de vetores após uma fusão forçada, k: 10 e n:100
- knn-search-100-1000-force-merge: buscando em 10 milhões de vetores após uma fusão forçada, k: 100 e n:1000
- knn-search-100-1000-concorrente-com-indexação: buscando em 10 milhões de vetores enquanto também atualiza 5% do conjunto de dados, k: 100 e n:1000
- script-score-query: busca KNN exata de 2000 vetores específicos.
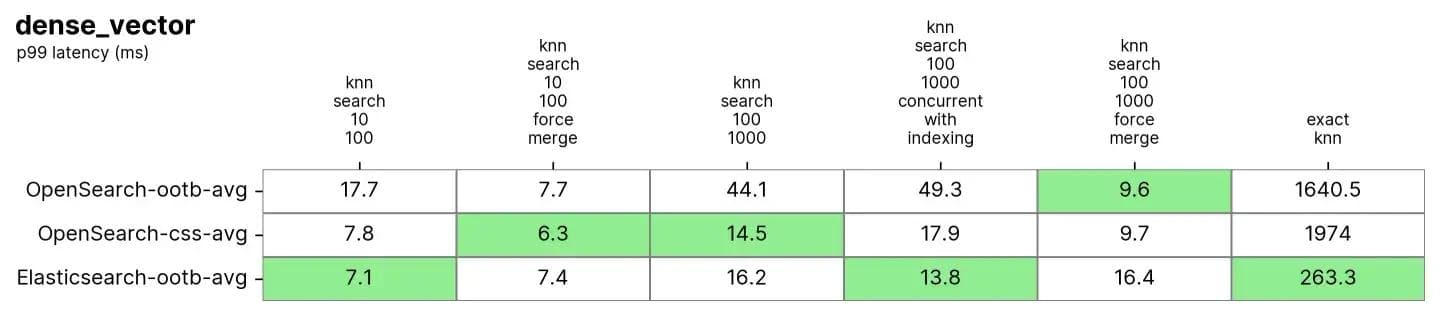
Tanto o Elasticsearch quanto o OpenSearch tiveram bom desempenho para Approximate KNN. Quando o índice é mesclado (tem apenas um único segmento) em knn-search-100-1000-force-merge e knn-search-10-100-force-merge, o OpenSearch tem um desempenho melhor do que os outros ao usar nmslib e faiss, mesmo que todos estejam em torno de 15ms e muito próximos.
No entanto, quando o índice tem múltiplos segmentos (situação típica em que um índice recebe atualizações nos documentos) em knn-search-10-100 e knn-search-100-1000, o Elasticsearch mantém a latência em cerca de ~7 ms e ~16 ms, enquanto todos os outros mecanismos OpenSearch são mais lentos.
Além disso, quando o índice está sendo buscado e gravado ao mesmo tempo (knn-search-100-1000-concurrent-with-indexing), o Elasticsearch mantém a latência abaixo de 15ms (13,8ms), sendo quase 4 vezes mais rápido do que o OpenSearch pronto para uso (49,3ms) e ainda mais rápido quando a busca de segmento simultânea está ativada (17,9ms), mas muito próximo para ser significativo.
Quanto ao Exact KNN, a diferença é muito maior: o Elasticsearch é 6x mais rápido que o OpenSearch (~260ms vs ~1600ms).
Recall
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0,969843 | 0,996577 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0,775458 | 0,840254 |
| OpenSearch-2.14.0@lucene-hnsw | 0,971333 | 0,996747 |
| OpenSearch-2.14.0@faiss | 0,9704 | 0,914755 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0,968025 | 0,913862 |
| OpenSearch-2.14.0@nmslib | 0,9674 | 0,910303 |
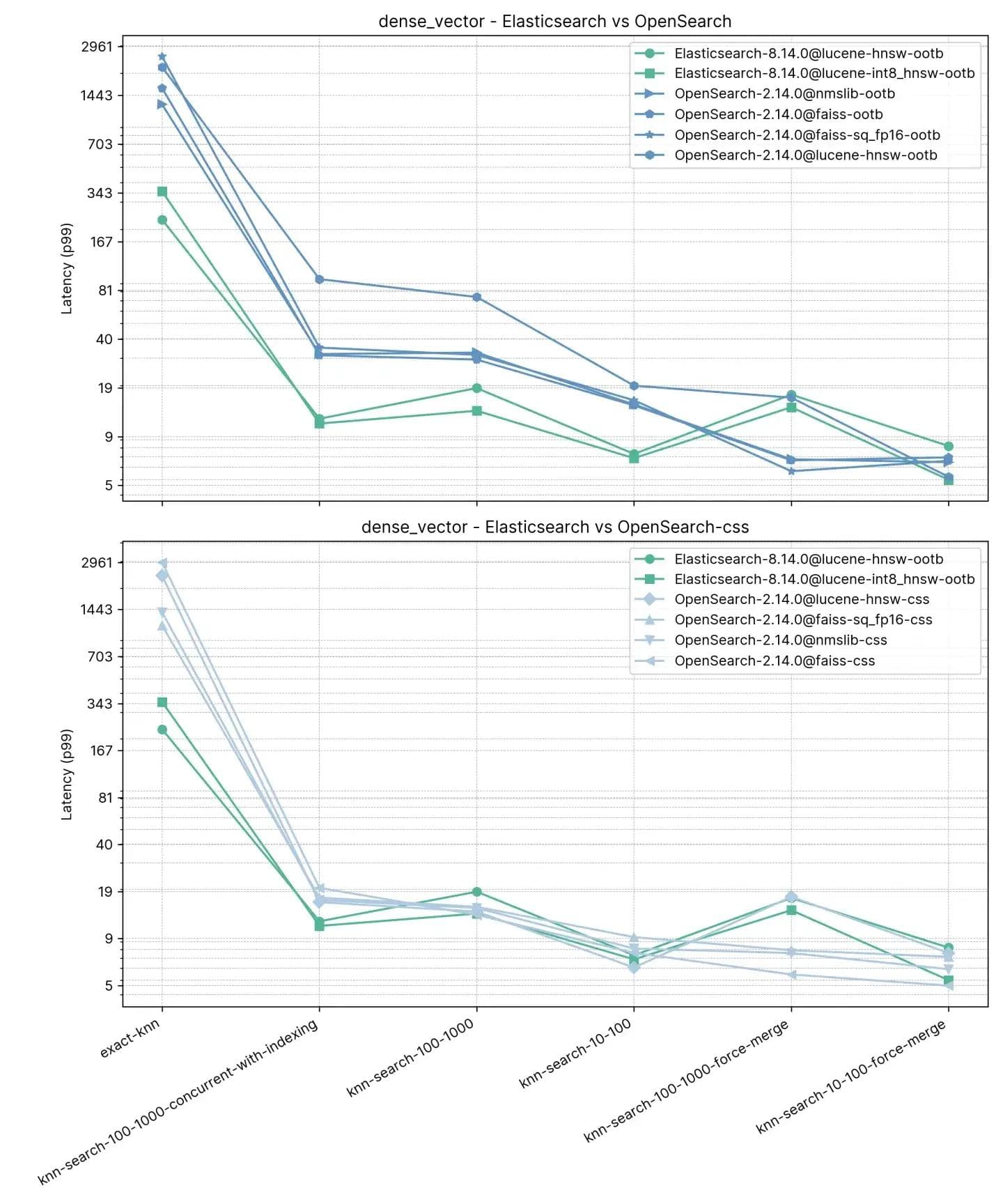
2 milhões de vetores, 768 dimensões (so_vector)
Essa trilha, so_vector, é derivada de um dump de postagens do StackOverflow baixadas em 21 de abril de 2022. Ele contém apenas documentos de perguntas — todos os documentos que representam respostas foram retirados. O título de cada pergunta foi codificado em um vetor usando o modelo de transformador de sentença multi-qa-mpnet-base-cos-v1. Este conjunto de dados contém as primeiras 2 milhões de perguntas.
Diferente da trilha anterior, cada documento aqui contém outros campos além de vetores para aceitar recursos de teste como KNN Aproximado com filtragem e busca híbrida. nmslib para OpenSearch está notavelmente ausente neste teste, já que ele não aceita filtros.
Tarefas
Cada tarefa é aquecida com 100 solicitações e, em seguida, 100 solicitações são medidas. Observe que as tarefas foram agrupadas para simplificar, pois o teste contém 16 tipos de busca * 2 valores de k diferentes * 3 valores de n diferentes.
- knn-10-50: buscando em 2 milhões de vetores sem filtros, k:10 e n:50
- knn-10-50-filtrado: buscando em 2 milhões de vetores com filtros, k:10 e n:50
- knn-10-50-após-fusão-forçada: buscando em 2 milhões de vetores com filtros e após uma fusão forçada, k:10 e n:50
- knn-10-100: buscando em 2 milhões de vetores sem filtros, k:10 e n:100
- knn-10-100-filtered: buscando em 2 milhões de vetores com filtros, k:10 e n:100
- knn-10-100-after-force-merge: buscando em 2 milhões de vetores com filtros e após uma fusão forçada, k:10 e n:100
- knn-100-1000: buscando em 2 milhões de vetores sem filtros, k:100 e n:1000
- knn-100-1000-filtered: buscando em 2 milhões de vetores com filtros, k:100 e n:1000
- knn-100-1000-after-force-merge: buscando em 2 milhões de vetores com filtros e após uma fusão forçada, k:100 e n:1000
- exact-knn: busca KNN exata com e sem filtros.

O Elasticsearch é consistentemente mais rápido que o OpenSearch pronto para uso neste teste, apenas em dois casos o OpenSearch é mais rápido, e não muito (knn-10-100 e knn-100-1000). Tarefas envolvendo knn-10-50, knn-10-100 e knn-100-1000 em combinação com filtros mostram uma diferença de até 7x (112ms vs 803ms).
O desempenho de ambas as soluções parece se equilibrar após uma "force merge", o que é compreensível, conforme evidenciado por knn-10-50-after-force-merge, knn-100-after-force-merge e knn-100-1000-after-force-merge. Nessas tarefas, faiss é mais rápido.
O desempenho do Exact KNN mais uma vez é muito diferente, com o Elasticsearch sendo 13 vezes mais rápido que o OpenSearch desta vez (~385ms vs ~5262ms).
Recall
| knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0,986667 | 1 |
| OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
| OpenSearch-2.14.0@nmslib | 0,9674 | 0,910303 | 0,976394 |
Elasticsearch e Lucene como vencedores claros
Na Elastic, estamos inovando incessantemente o Apache Lucene e o Elasticsearch para garantir que sejamos capazes de fornecer o principal banco de dados vetorial para casos de uso de busca e recuperação, incluindo RAG (retrieval-augmented generation). Nossos avanços recentes aumentaram drasticamente o desempenho, tornando a busca vetorial mais rápida e mais eficiente em termos de espaço do que antes, com base nos ganhos do Lucene 9.10. Esse blog apresentou um estudo que mostra que, ao comparar versões atualizadas, o Elasticsearch é até 12 vezes mais rápido que o OpenSearch.
Vale a pena observar que ambos os produtos usam a mesma versão do Lucene (notas de lançamento do Elasticsearch 8.14 e notas de lançamento do OpenSearch 2.14).
O ritmo de inovação na Elastic proporcionará ainda mais não apenas para nossos clientes no local e do Elastic Cloud, mas também para aqueles que usam nossa plataforma sem estado. Recursos como suporte para quantização escalar para int4 serão oferecidos com testes rigorosos para que os clientes possam utilizar essas técnicas sem uma queda significativa no recall, semelhante aos nossos testes para int8.
A eficiência da busca vetorial está sendo um recurso inegociável nos mecanismos de busca modernos devido à proliferação de aplicações de IA e machine learning. Nas organizações que procuram um mecanismo de busca poderoso, capaz de acompanhar as demandas de dados vetoriais de alto volume e alta complexidade, o Elasticsearch é a resposta definitiva.
Seja expandindo uma plataforma estabelecida ou iniciando novos projetos, a integração do Elasticsearch para as necessidades de busca vetorial é um movimento estratégico que produzirá benefícios tangíveis e de longo prazo. Com a vantagem de desempenho comprovada, o Elasticsearch está pronto para sustentar a próxima onda de inovações em busca.
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.